@867976167
2020-03-24T11:46:56.000000Z
字数 1001
阅读 1359
缓存算法简介————LRU算法
LRU 算法
缓存算法简介
缓存是存储用户经常需要的数据,减少读取数据的时间。一个缓存应当存储尽可能多的有用的数据,但是当缓存数据满了的时候,我们需要将一些可能没有用的数据淘汰出去,这就涉及到了常见的缓存淘汰算法;
- 先进先出算法(FIFO):最先进入的内容作为替换对象
- 最近最少使用算法(LRU):最近最少使用的内容作为替换对象
- 最少使用算法(LFU):为每个对象设置一个频率,数量最少的作为替换对象
- 非最近使用算法(NMRU):在最近没有使用的内容中随机选择一个作为替换对象
LRU算法
这里简单介绍一下LRU算法,LRU是Least Recently Used 最近最少使用算法。算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
LRU算法最常见的实现是通过一个链表来实现:
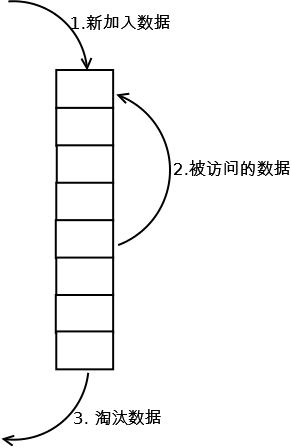
- 新数据插入到链表头部;
- 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
- 当链表满的时候,将链表尾部的数据丢弃。
下面是LeetCode上关于LRU的题的解法
public class LRUCache {//使用linkedHashMap可以保证顺序LinkedHashMap<Integer, Integer> map = null;int count;public LRUCache(int capacity) {this.count = capacity;// 重写 LinkedHashMap方法,true代表排序模式map = new LinkedHashMap<Integer, Integer>(capacity, 0.75f, true) {// 在调用put方法时调用此方法,若返回true,则移除最旧的条目protected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {return map.size() > count;}};}public int get(int key) {if (map.containsKey(key)) {return map.get(key);} else {return -1;}}public void set(int key, int value) {map.put(key, value);}}
本文参考:http://blog.csdn.net/yunhua_lee/article/details/7599671
