@CQUyh
2023-04-20T12:53:27.000000Z
字数 1882
阅读 244
卷积种类
深度学习八股
一、转置卷积
https://blog.csdn.net/tsyccnh/article/details/87357447
https://blog.csdn.net/qq_39478403/article/details/121181904
1)实现上采样,只能恢复图像的大小,但不是卷积的逆运算。是针对同一个卷积核,但结果不能恢复到原来的数值。
2)过程:Y=CX-->X=Ct*Y (X,Y都是向量)
正向:假设4x4特征图通过3x3卷积得到2x2的输出。
将输入和输出拉成一维向量,卷积通过滑窗的方式组合成一个矩阵和X计算
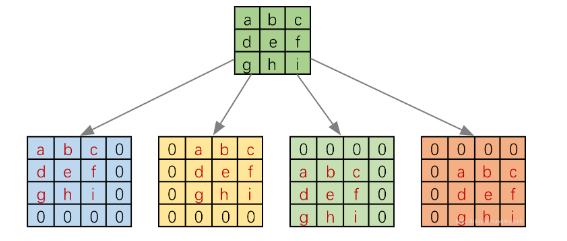
左边是输入的拉长,右边是滑窗的矩阵
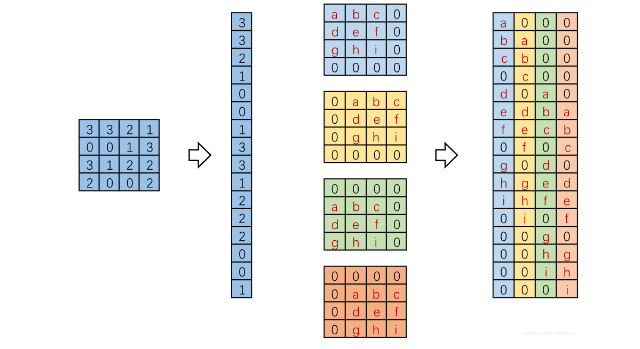
那么Y=CX就是下图:
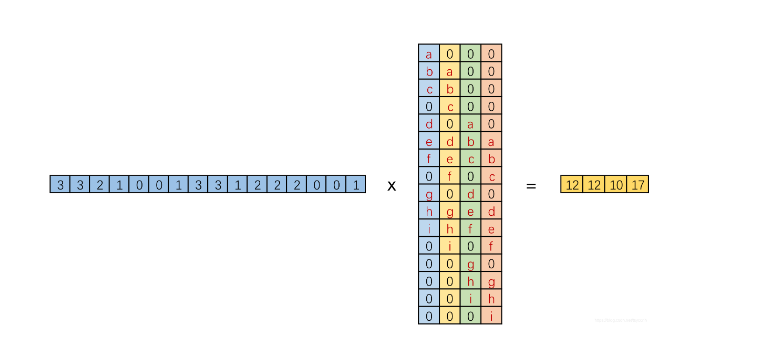
因此反卷积就是将C进行转置,得到X=Ct*Y,但是只是大小可逆,数值不可逆。

3)缺点:
网格效应,反卷积的结果会出现重叠不均匀,空洞卷积也有


4)输出大小:卷积的大小计算公式倒过来就行
二、空洞卷积
也叫做扩张卷积和膨胀卷积,通过在卷积核加入空格(0)来扩大卷积核,实现扩大感受野的效果。一般对于大物体的分割较好,需要全局感受野获得语义信息。
1.参数:dilation,扩张率,填充的个数
rate表示一个点到另一个点的步数
rate=1:正常卷积
rate=2:等价5x5卷积
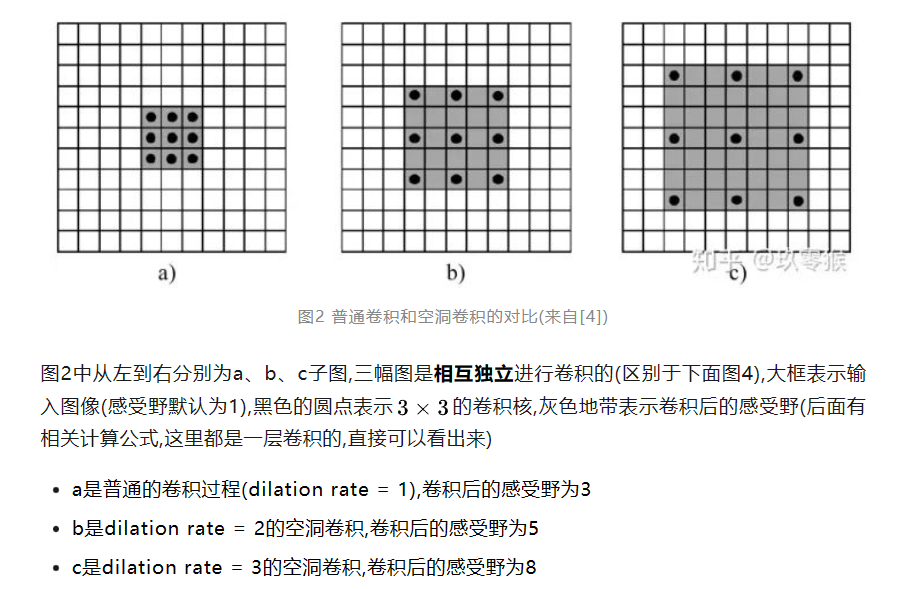
优点:1)能够在不改变参数量的情况下,获得更大的感受野;这样对于大物体的检测更加准确 2)可以通过设置不同dilation获取多尺度的信息
缺点:1)网格影响,不是每个像素参与计算,失去信息的连续性。2)获取更深的感受野对于小目标检测不友好。
2.输出大小计算
空洞卷积等效的卷积核大小:
ke = k + (k-1)(r-1)
(计算多的部分,(r-1)代表间隔长度,实际间隔是rate-1,(k-1)代表间隔数量,有多少个间隔,为k-1个)
输出计算同卷积运算
三、可分离卷积
1.空间可分离卷积:将3x3分离为3x1和1x3,可以减少计算量
例如sobel算子进行拆分
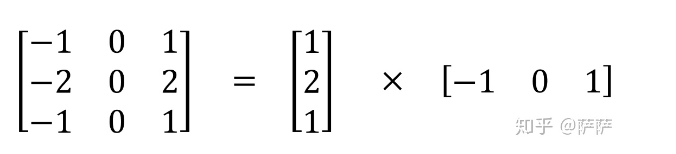
2.深度可分离卷积
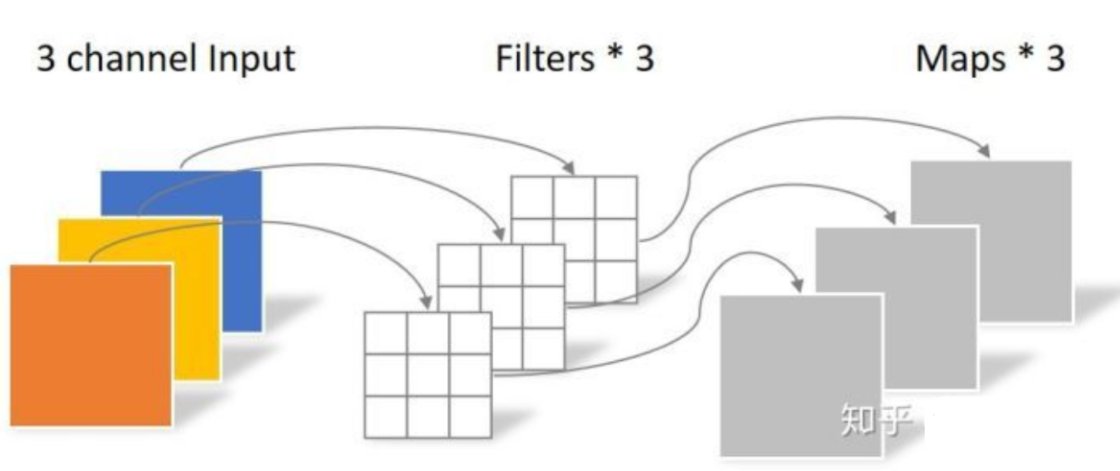
目的:将w*h*c1的特征图 转为 m*n*c2的特征图
第一步:逐通道卷积:对通道进行卷积,卷积核大小,为3x3x1,c1个,最后输出mxnxc1
第二步,逐点卷积:利用1x1卷积改变维度,mxnxc1通过c2个1x1卷积后,得到mxnxc2的特征图
参数量计算:原本为c1*k1*k2*c2
逐通道卷积:k1*k2*1*c1; 逐点卷积:1x1xc1xc2 total= k1xk2xc1 + c1xc2
优点:1)降低了参数量 2)实现了区域和通道的分离,先只考虑区域,再只考虑通道
import torchimport torch.nn as nn...model = nn.Sequential(nn.Conv2d(in_channels = in_channel, out_channels = in_channel,kernel_size = kernel_size, stride = stride, padding = 1, dilation = dilation, group =in_channel),nn.Conv2d(in_channels = in_channel, out_channels = out_channel kernel_size = 1, padding = 0))
四、分组卷积
参考链接:https://zhuanlan.zhihu.com/p/226448051
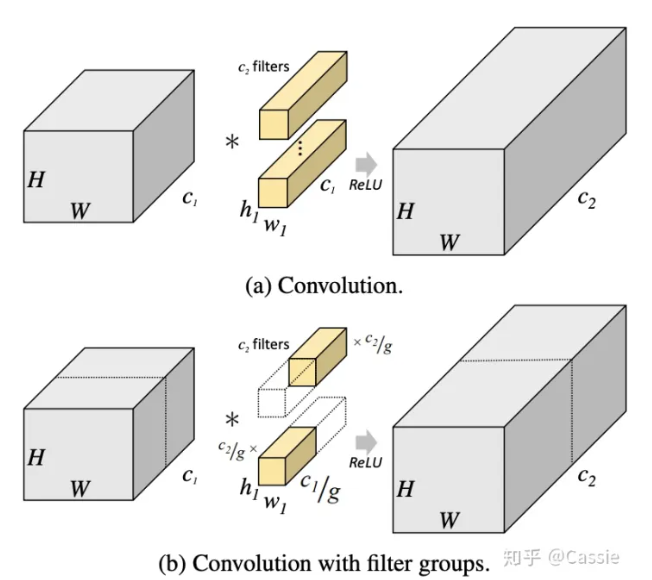
1.分组卷积的概念和参数量计算
①概念:它没有逐通道卷积,直接一步出来,深度可分离卷积是分组成inchannel。
将输入通道分为g个组,然后卷积核的大小就是kxkxc1/g*c2/g。最后得到g个分组堆叠在一起得到输出。
②参数计算:如图设分为g个组,g要能被c1,c2整除,因为卷多少分之一输入,生成的特征图个数也为原本的多少分之一。那么,卷积核深度为c1/g,同时负责卷积输入的c1/g个通道,同时卷积核个数也为c2/g。因为卷积后的特征图的数量(channel)为c2/g,计算量为:k1*k2*c1/g * c2/g。一共分了g个组,总参数量为:k1*k2*c1/g c2/g g = k1*k1*c1*c2/g ,比正常的卷积要少了g分之一的参数量。
③代码实现:
import torchimport torch.nn as nn...model = nn.Conv2d(in_channels = in_channel, out_channels = out_channel,kernel_size = kernel_size, stride = stride, padding = 1, dilation = dilation, group = group_num)
2.优点
减少参数和计算量
