@JunQiu
2018-09-18T13:17:43.000000Z
字数 5046
阅读 2872
分布式CAP理论、mongo_连接数、driver(连接池)、分表分表:避免数据迁移和热点数据
summary_2018/08 arch mongodb database
1、日常
1.1、mongodb:连接数、driver连接池
1.2、分布式中的CAP理论浅读
1.3、一种可以避免数据迁移、热点数据的分库分表策略
2、技术
2.1、mongo的连接数与driver(连接池)
- mongod的最大连接数通过 net.maxIncomingConnections 指定,默认值为1000000,相当于没有限制,生产环境强烈建议根据实际需求配置,以避免客户端误用导致 mongod 负载过高。
- 为什么需要连接限制??
- Mongodb每个线程配置了1MB的栈空间,当网络连接数太多时,过多的线程会导致上下文切换开销变大(线程切换开销也比较大),同时内存开销也会上涨。
一些指标:1、TPS: 每秒事务量2、IOPS:(Input/Output Operations Per Second),即每秒进行读写(I/O)操作的次数,多用于数据库等场合,衡量随机访问的性能。3、QPS: 每秒Query量资源占用:1、内存:MongoDB为例,每个线程都要分配1MB的栈内存出来。1000个连接,1G内存就这么没了,甭管是否是活跃连接2、文件句柄:每个连接都要打开一个文件句柄,当然从成本上讲,这个消耗相对内存是小了很多。但换个角度,文件句柄也被其他模块消耗着,比如WT存储引擎,就需要消耗大量的文件句柄
- driver
- MongoDB 各个语言的Driver 基本都会封装包含一个 MongoClient 的对象(不同语言的 Driver 名字可能稍有不同),通常应用在使用时通过 MongoDB connection string URI 来构造一个全局的 MongoClient,然后在后续的请求中使用该全局对象来发送请求给Mongod。
- 通常每个 MongoClient 会包含一个连接池,默认大小为100(具体的有所不同),也可以在构造MongoClient 的时候通过maxPoolSize/minPoolSize(部分不支持)选项来指定。
- Tips:一种典型的错误使用方式是,用户为每个请求都构造一个MongoClient.connect,请求结束释放 MongoClient.connect(或根本没释放),这样做问题是请求模型从长连接变成了短连接,每次短连接都会增加『建立 tcp 连接 + mongodb鉴权』的开销,并且并发的请求数会受限于连接数限制,极大的影响性能;另外如果 MongoClient.connect 忘记释放,会导致MongoClient 连接池里连接一直保持着,最终耗光所有的可用连接。
- MongoClient 连接池配置多大合适?
通常 MongoClient 使用默认100的连接池(具体默认值以 Driver 的文档为准)都没问题,当访问同一个 Mongod 的源比较多时,则需要合理的规划连接池大小。举个例子,Mongod的连接数限制为2000,应用业务上有40个服务进程可能同时访问 这个Mongod,这时每个进程里的 MongoClient 的连接数则应该限制在 2000 / 40 = 50 以下 (连接复制集时,MongoClient 还要跟复制集的每个成员建立一条连接,用于监控复制集后端角色的变化情况)。
- native : Node.js MongoDB Driver API一些注意点
- 默认长连接(MongoClient)(比如mysql连接8小时后自动断开,当然也有长连接),为当前连接建立连接池
- The maximum size of the individual server pool。(Default:5)
- 参考
- mongo Connection String URI Format
- 什么是连接池?我们为什么需要它?
- Deep Dive into Connection Pooling
- 复用某个连接(打开/关闭数据库连接开销很大),维护当前建立的连接,可以是数据库/表等
2.2、分布式中的CAP理论浅读
- 概述
- 一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
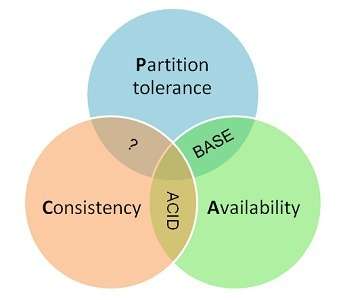
- 一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
1、一致性一致性指“all nodes see the same data at the same time”,即所有节点在同一时间的数据完全一致。对于一致性,可以分为从客户端和服务端两个不同的视角。客户端从客户端来看,一致性主要指的是多并发访问时更新过的数据如何获取的问题。服务端从服务端来看,则是更新如何分布到整个系统,以保证数据最终一致。对于一致性,可以分为强/弱/最终一致性三类从客户端角度,多进程并发访问时,更新过的数据在不同进程如何获取的不同策略,决定了不同的一致性。// 强一致性对于关系型数据库,要求更新过的数据能被后续的访问都能看到,这是强一致性。// 弱一致性如果能容忍后续的部分或者全部访问不到,则是弱一致性。// 最终一致性如果经过一段时间后要求能访问到更新后的数据,则是最终一致性。2、Availability 可用性可用性指“Reads and writes always succeed”,即服务在正常响应时间内一直可用。3、Partition Tolerance分区容错性分区容错性指“the system continues to operate despite arbitrary message loss or failure of part of the system”,即分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性或可用性的服务。
- 如何理解CAP理论呢??
一个分布式系统里面,节点组成的网络本来应该是连通的。然而可能因为一些故障,使得有些节点之间不连通了,整个网络就分成了几块区域。数据就散布在了这些不连通的区域中。这就叫分区。当你一个数据项只在一个节点中保存,那么分区出现后,和这个节点不连通的部分就访问不到这个数据了。这时分区就是无法容忍的。提高分区容忍性的办法就是一个数据项复制到多个节点上,那么出现分区之后,这一数据项就可能分布到各个区里。容忍性就提高了。然而,要把数据复制到多个节点,就会带来一致性的问题,就是多个节点上面的数据可能是不一致的。要保证一致,每次写操作就都要等待全部节点写成功,而这等待又会带来可用性的问题。总的来说就是,数据存在的节点越多,分区容忍性越高,但要复制更新的数据就越多,一致性就越难保证。为了保证一致性,更新所有节点数据所需要的时间就越长,可用性就会降低。// 或者想象两个节点分处分区两侧。允许至少一个节点更新状态会导致数据不一致,即丧失了C性质。如果为了保证数据一致性,将分区一侧的节点设置为不可用,那么又丧失了A性质。除非两个节点可以互相通信,才能既保证C又保证A,这又会导致丧失P性质。
- CAP的权衡??
// 实际上情况根据场景而言对于多数大型互联网应用的场景,主机众多、部署分散,而且现在的集群规模越来越大,所以节点故障、网络故障是常态,而且要保证服务可用性,即保证P和A,舍弃C(退而求其次保证最终一致性)。虽然某些地方会影响客户体验,但没达到造成用户流程的严重程度。对于涉及到钱财这样不能有一丝让步的场景,C必须保证。网络发生故障宁可停止服务,这是保证CA,舍弃P。
2.3、一种可以避免数据迁移、热点数据的分库分表策略
- 目前采用比较多的分库分表策略:
1、mod方式2、dayofweek系列日期方式(所有星期1的数据在一个库/表,或所有?月份的数据在一个库表)本质的特点:离散性加周期性。存在的问题:1、随着数据量的增大,每个表或库的数据量都是各自增长。当一个表或库的数据量增长到了一个极限,要加库或加表的时候,介于这种分库分表算法的离散性,必需要做数据迁移才能完成。2、考虑到数据增长的特点,如果我们以代表时间增长的字段,按递增的范围分库,则可以避免数据迁移。但是这样的方式会带来一个热点问题:当前的数据量达到某个库表的范围时,所有的插入操作,都集中在这个库/表了。因此:我们在分库分表的时候应该尽量避免这两个问题:数据迁移、热点
- 结合离散分库/分表和连续分库/分表的优点,我们考虑这样的模式
## 比如// 阶段一:一个数据库,两个表分库规则dbRule: “DB0”分表规则tbRule: “t” + (id % 2)

// 阶段二:当单库的数据量接近1千万,单表的数据量接近500万时,进行扩容(数据量只是举例,具体扩容量要根据数据库和实际压力状况决定增加一个数据库DB1,将DB0.t1整表迁移到新库DB1。每个库各增加1个表,未来10M-20M的数据mod2分别写入这2个表:t0_1,t1_1分库规则dbRule:“DB” + (id % 2)分表规则tbRule:if(id < 1千万){return “t”+ (id % 2); //1千万之前的数据,仍然放在t0和t1表。t1表从DB0搬迁到DB1库}else if(id < 2千万){return “t”+ (id % 2) +”_1”; //1千万之后的数据,各放到两个库的两个表中: t0_1,t1_1}else{throw new IllegalArgumentException(“id outof range[20000000]:” + id);}10M以后的新生数据会均匀分布在DB0和DB1;插入更新和查询热点仍然能够在每个库中均匀分布。每个库中同时有老数据和不断增长的新数据。每表的数据仍然控制在500万以下。

// 阶段三:当两个库的容量接近上限继续水平扩展时,进行如下操作新增加两个库:DB2和DB3. 以id % 4分库。余数0、1、2、3分别对应DB的下标. t0和t1不变,将DB0.t0_1整表迁移到DB2; 将DB1.t1_1整表迁移到DB320M-40M的数据mod4分为4个表:t0_2,t1_2,t2_2,t3_2,分别放到4个库中:// 分库规则dbRule:if(id < 2千万){//2千万之前的数据,4个表分别放到4个库if(id < 1千万){return “db”+ (id % 2); //原t0表仍在db0, t1表仍在db1}else{return “db”+ ((id % 2) +2); //原t0_1表从db0搬迁到db2; t1_1表从db1搬迁到db3}}else if(id < 4千万){return “db”+ (id % 4); //超过2千万的数据,平均分到4个库}else{throw new IllegalArgumentException(“id out of range. id:”+id);}// 分表规则tbRule:if(id < 2千万){ //2千万之前的数据,表规则和原先完全一样,参见阶段二if(id < 1千万){return “t”+ (id % 2); //1千万之前的数据,仍然放在t0和t1表}else{return “t”+ (id % 2) +”_1”; //1千万之后的数据,仍然放在t0_1和t1_1表}}else if(id < 4千万){return “t”+ (id % 4)+”_2”; //超过2千万的数据分为4个表t0_2,t1_2,t2_2,t3_2}else{throw new IllegalArgumentException(“id out of range. id:”+id);}

随着时间的推移,当第一阶段的t0/t1,第二阶段的t0_1/t1_1逐渐成为历史数据,不再使用时,可以直接truncate掉整个表。省去了历史数据迁移的麻烦。(TDDL2.x中已经实现)当然还可以成倍数的继续扩充,但也可以不成倍的扩充,有兴趣可以阅读原文。
- 总结
1、离散映射:如mod或dayofweek,这种类型的映射能够很好的解决热点问题,但带来了数据迁移和历史数据问题。2、连续映射;如按id或gmt_create_time的连续范围做映射。这种类型的映射可以避免数据迁移,但又带来热点问题。因此,我们应该两者结合,合理的根据需求构建,基于以上考量,分库分表规则的设计和配置,长远说来必须满足以下要求:1、规则可以分层级叠加,旧规则可以在新规则下继续使用,新规则是旧规则在更宽尺度上的拓展,以此支持新旧规则的兼容,避免数据迁移2、用mod方式时,最好选2的指数级倍分库分表,这样方便以后切割。
