@Lervard
2015-11-21T11:46:29.000000Z
字数 2953
阅读 3865
zookeeper集群配置管理实现分析
技术类
zookeeper简介
zookeeper是apache旗下的开源软件,是一套为分布式系统提协调服务的服务,主要的功能包括配置维护、名字服务、分布式同步、组服务。因为在开发中很难设计一个完美正确的分布式系统中的协调服务。很容易碰到竟态状态和死锁问题。zookeeper的目标是封装好在分布式系统中复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
zookeeper的设计目标:
zookeeper简单好用
zookeepr通过让所有的节点共享一个有层级关系的空间,其空间的组织形式和标准的文件系统相似。在该空间的节点被称为znode类似于文件系统的文件夹或文件,所以zookeepr是易于理解和使用的。和文件系统不同的是,这些节点是用来存储的,zookeepr的所有数据是常驻内存的,所以zookeepr可以提供高吞吐,低延迟的服务。
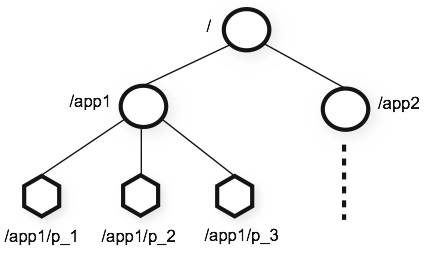
提供的接口是简单好操作的:
- create : creates a node at a location in the tree
- delete : deletes a node
- exists : tests if a node exists at a location
- get data: reads the data from a node
- set data: writes data to a node
- get children: retrieves a list of children of a node
- sync: waits for data to be propagated
zookeeper容易扩展的
组成zookeeper的服务的server必须知道彼此的存在,所有的server都会维护一个状态在内存中,通过事务日志和快照持久化到内存中。只要一半以上服务器是可用的,则zookeepr服务就是可用的。所以在生产环境中,你最好部署3,5,7个节点。部署的越多,可靠性就越高,当然最好是部署奇数个,偶数个不是不可以的,但是zookeeper集群是以宕机个数过半才会让整个集群宕机的,所以奇数个集群更佳。
使用zookeepr服务的客户端,会和zookeepr集群中的一台机器维护一个长连接,通过长连接来发送请求,得到回应,得到监控事件,发送心跳协议。如果长连接断开,则会与新的zookeeper集群中的一台机器建立长连接。
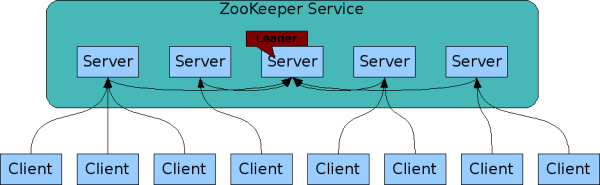
zookeeper简要剖析
提供实现配置管理服务的保证:
znode节点管理
zookeeper空间中每个节点上都会存储一些协调需要的数据:状态信息,配置,位置信息等,所以每个节点的数据大小都是非常小的几B到几K的范围。下面的讨论会使用znode来代替。
Znodes维护一个状态数据结构,其中包括监控数据变化的version,ACL(访问控制链表),时间戳(做cache校验和协同更新),每次znode的数据变化,version会增加。client每次取数据的时候,同时会获得数据的version。znode中的数据的读和写都是原子性的,Reads会一次性得到znode上所有的数据,write会更新znode上所有的数据。同时znode提供一种暂时性的znode,叫(ephemeral nodes),这种节点生命周期和session的生命周期一致。
znode提供的watch机制
znode提供的watch机制类似于设计模式中的观察者模式(订阅和发布),每个client都可以在znode上设置一个watch,当znode改变时,watch就会被触发或删除。当watch被触发,client会接收到数据通知znode已经发生变化。
基于以上两点,可以利用zookeeper实现配置管理服务,将需要管理的配置信息放置到zookeeper集群,当配置信息改变时,通过watch机制,服务器会根据配置信息的改变来作出调整。
提供同步的服务的保证:
Sequential Consistency - 来自客户端的更新会根据发送顺序来执行。
Atomicity - 更新的原子性,更新操作要么成功,要么失败,没有中间态。
Single System Image - 不管client连接是那台机器,所有clint看到的zookeeper的信息都是一样的
Reliability - 可靠性,一旦提交被更新,则会一直生效直到被覆盖。
Timeliness- client和zookeepr服务在一定的时间范围内保持同步。
实现机理:
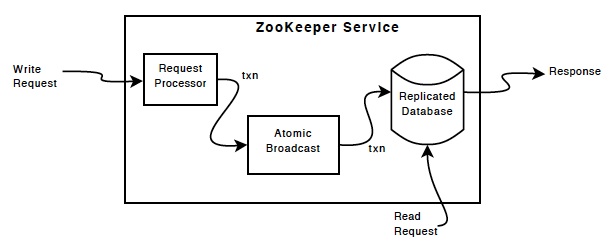
备份数据库(replicated database)是一个内存数据库,里面包含整个znode树的data。将log持久化到disk上,同时所有的写操作在请求内存数据库前,都会序列化到本地disk上。
所有的client只能连接zookeeper服务中的一台机器。读请求是直接从本地server的数据库来读。
写请求是通过同步协议来实现的:所有的写请求都会被转发到一个server上,leader(具体的leader产生算法是通过Paxos选举算法产生的),剩下的zookeepr servers被称为followers, 接收从leader发送的消息,同时根据消息内容做回应。消息层需要关心的是当leader挂掉后的处理和同步leader和follower的数据。
由于zookeeper采用的是原子性的消息协议,能保证本地的数据不会出现中间态的问题。当leader收到一个写请求,它会计算系统当前的state,同时将其转换为事务来进行监控。
zookeeper在Ynote中的使用
zookeeper 统一命名服务(Name Service)和 配置管理(Configuration Management)
统一命名服务
分布式应用中,通常需要有一套完整的命名规则,既能够产生唯一的名称又便于人识别和记住,通常情况下用树形的名称结构是一个理想的选择,树形的名称结构是一个有层次的目录结构,既对人友好又不会重复。说到这里你可能想到了 JNDI,没错 Zookeeper 的 Name Service 与 JNDI 能够完成的功能是差不多的,它们都是将有层次的目录结构关联到一定资源上,但是 Zookeeper 的 Name Service 更加是广泛意义上的关联,也许你并不需要将名称关联到特定资源上,你可能只需要一个不会重复名称,就像数据库中产生一个唯一的数字主键一样。
Name Service 已经是 Zookeeper 内置的功能,你只要调用 Zookeeper 的 API 就能实现。如调用 create 接口就可以很容易创建一个目录节点。
配置管理(Configuration Management)
配置的管理在分布式应用环境中很常见,例如同一个应用系统需要多台 PC Server 运行,但是它们运行的应用系统的某些配置项是相同的,如果要修改这些相同的配置项,那么就必须同时修改每台运行这个应用系统的 PC Server,这样非常麻烦而且容易出错。
像这样的配置信息完全可以交给 Zookeeper来管理,将配置信息保存在 Zookeeper 的某个目录节点中,然后将所有需要修改的应用机器监控配置信息的状态,一旦配置信息发生变化,每台应用机器就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中。

