@MatheMatrix
2025-04-29T08:20:40.000000Z
字数 1330
阅读 1222
可以在 ZStack AIOS 上体验最新的 Qwen3 模型了!
Qwen3 已于今天早上发布,如何在 ZStack AIOS 上立刻体验最新的 Qwen3 模型?
由于 Qwen3 模型的支持需要较新的推理框架(vllm、sglang 等),因此本篇文章将先向大家介绍如何一步步升级推理模板,管理员或者 AI 开发者完成推理模板升级后可以共享给云平台所有用户,所有用户即可体验最新的 Qwen3 模型。
准备环节
创建推理模板
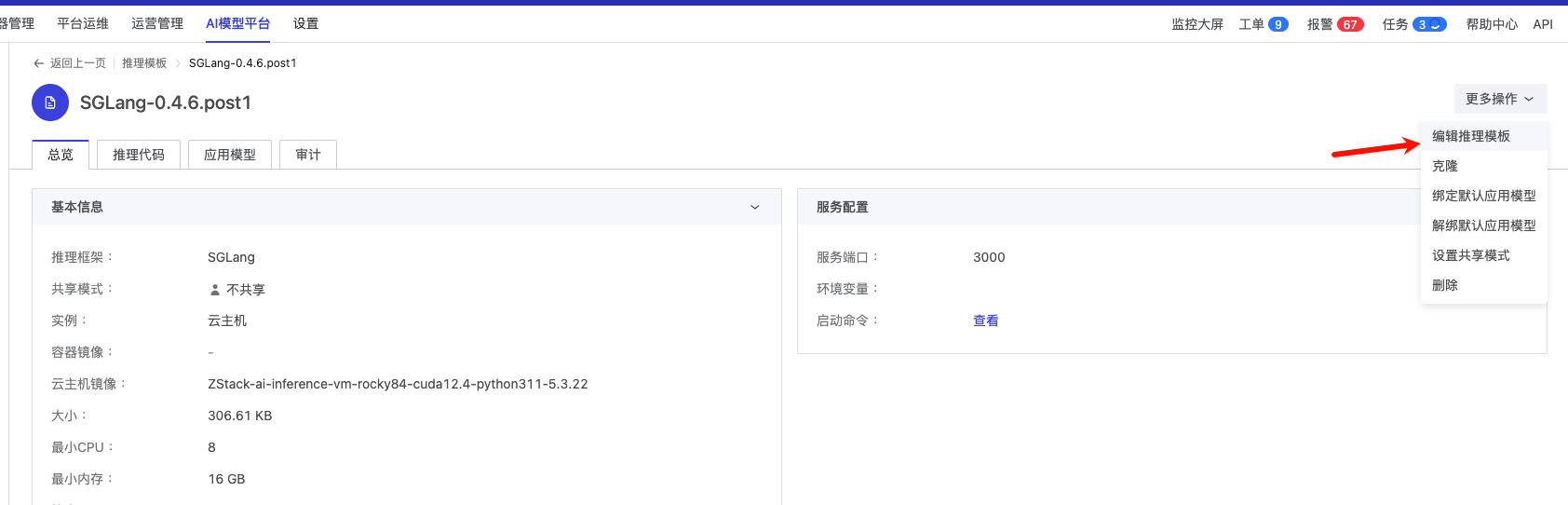
首先进入到 ZStack AIOS 模型平台,克隆一个系统自带 SGlang 的推理模板
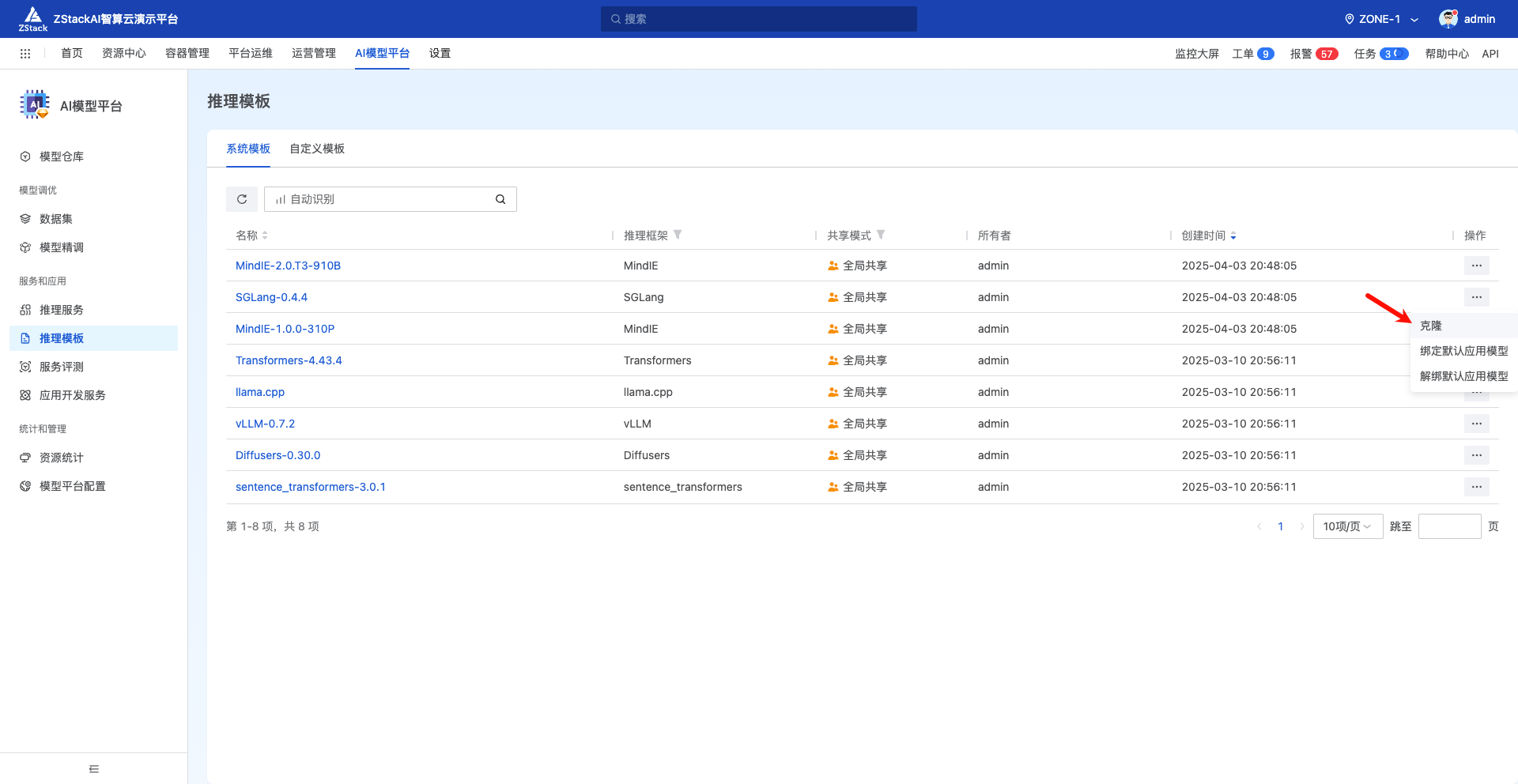
最新的 SGLang 版本为名字改为 SGLang-0.4.6.post1,实例配置设置为 “云主机”
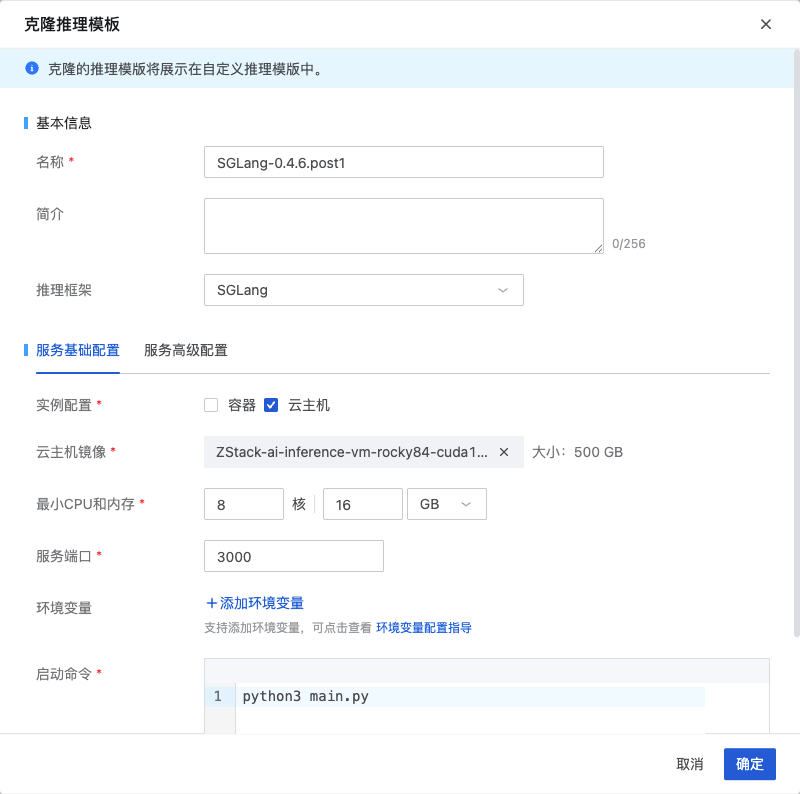
配置推理镜像
下面使用一个 Qwen2.5 模型来配置这个推理模板,例如 Qwen2-0.5B 或平台内置的 Qwen2-7B 均可,主要是验证新版本 SGLang 的可用性。创建推理服务的时候推理模板选择 SGLang-0.4.6.post1:
启动后进入 juypter notebook,选择 terminal,执行:
pip install sglang[all]==0.4.6.post1 -Uwget https://bj20013.api.aliyunfile.com/v2/redirect\?id\=9b8b2fa73e484893a5f567e6be22c1921745913012094149418 -O flashinfer_python-0.2.3+cu124torch2.6-cp38-abi3-linux_x86_64.whlpip install flashinfer_python-0.2.3+cu124torch2.6-cp38-abi3-linux_x86_64.whldnf -y install gcc-toolset-9-gcc gcc-toolset-9-gcc-c++systemctl restart zstack_ai.serviceecho -e "\nsource /opt/rh/gcc-toolset-9/enable" >> /etc/profile
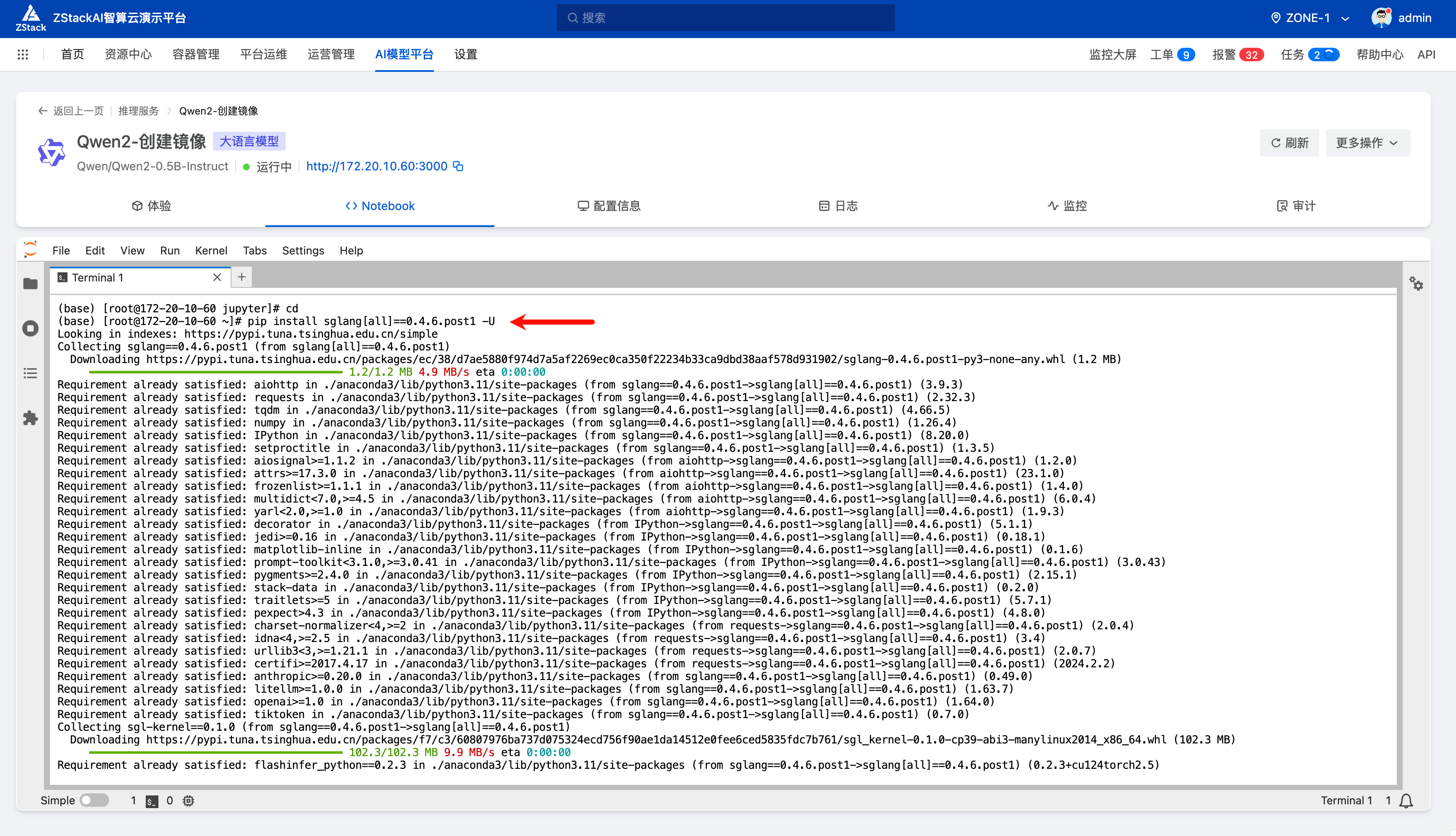
执行完 systemctl restart zstack_ai.service 之后模型服务会显示启动中,是正常的
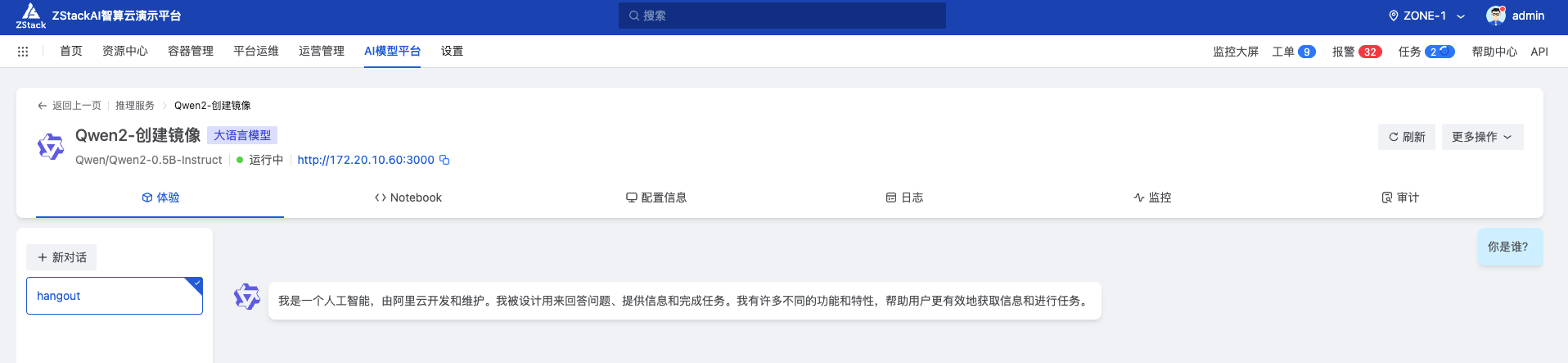
检查模型输出正常:
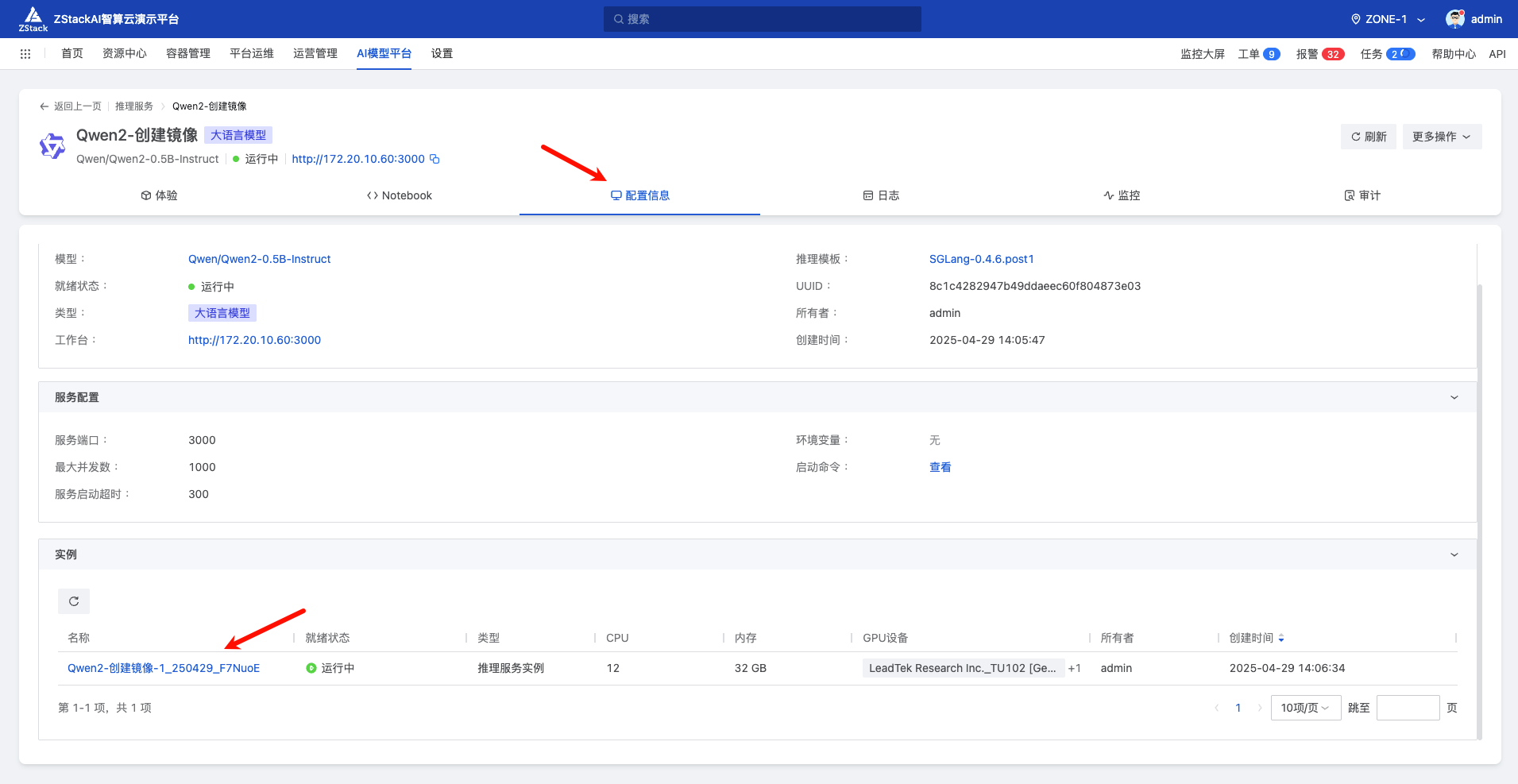
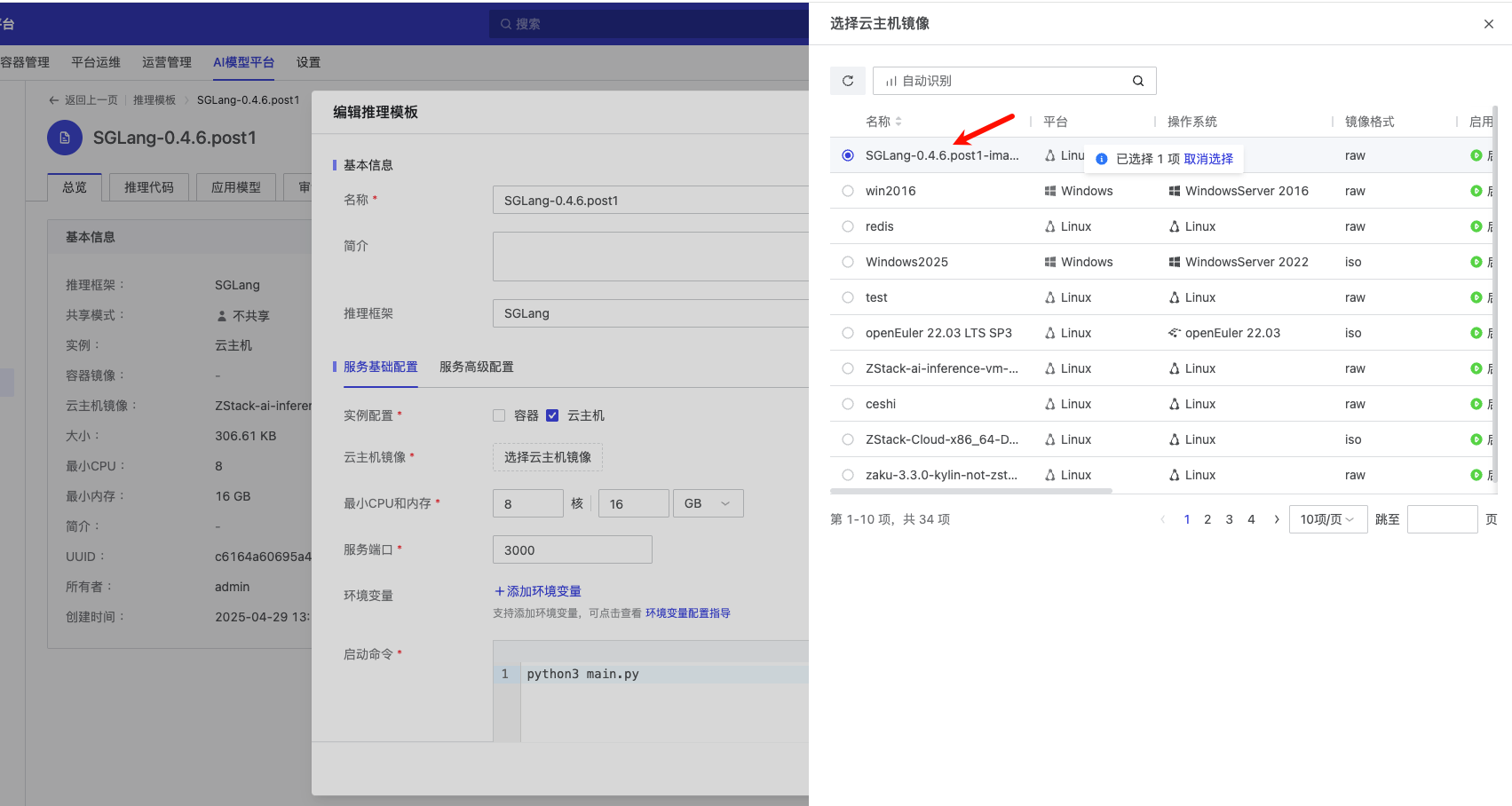
下面我们进入模型服务的“配置信息”页面,找到这个实例,创建一个实例镜像:
将云主机停止,点击创建镜像,命名为 SGLang-0.4.6.post1-image
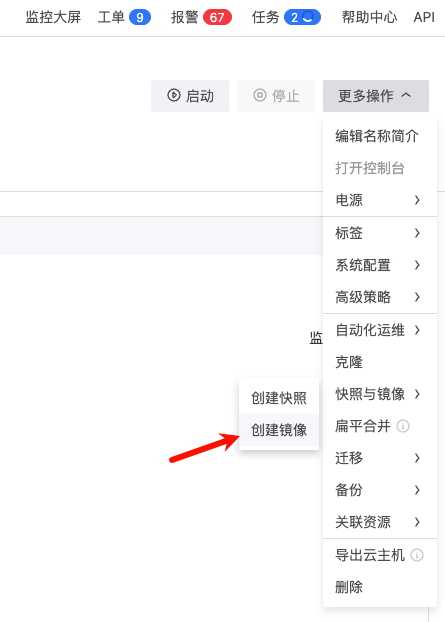
然后编辑刚刚创建的推理模板,将云主机镜像改为刚刚封装的这个 SGLang-0.4.6.post1-image
启动 Qwen3 模型
下载模型
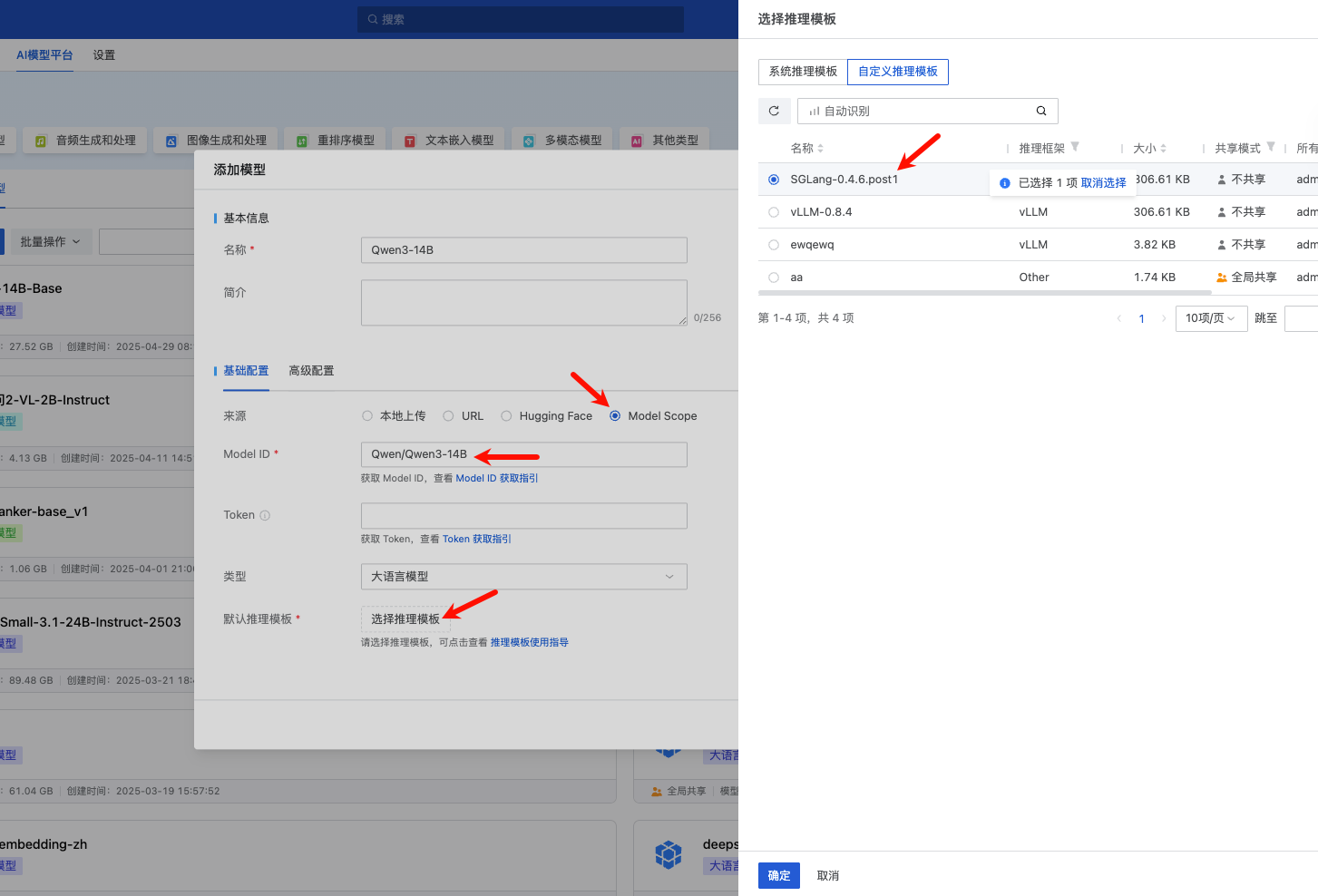
此时进入模型仓库,添加模型,假设我们从 ModelScope 下载,在来源选择 ModelScope,Model ID 填入我们计划使用的模型,例如 Qwen/Qwen3-14B,在推理模板选择我们刚刚克隆得到的 SGLang-0.4.6.post1
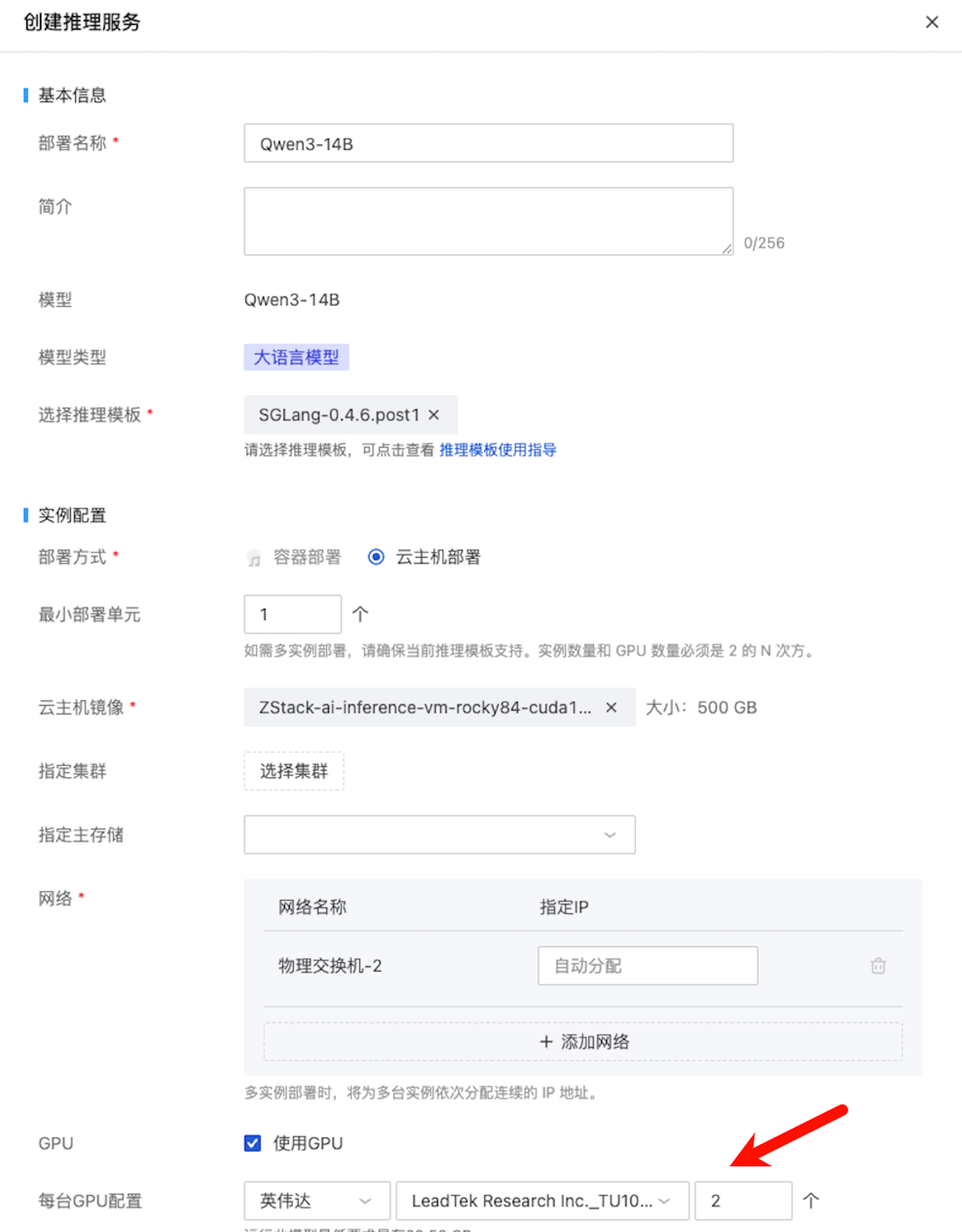
运行模型
由于 14B 模型有 28GB 的权重,因此这里我们使用两张 22GB GPU 进行部署:
启动即可,可以通过界面对话或者通过其他客户端如等 chatwise 接入:
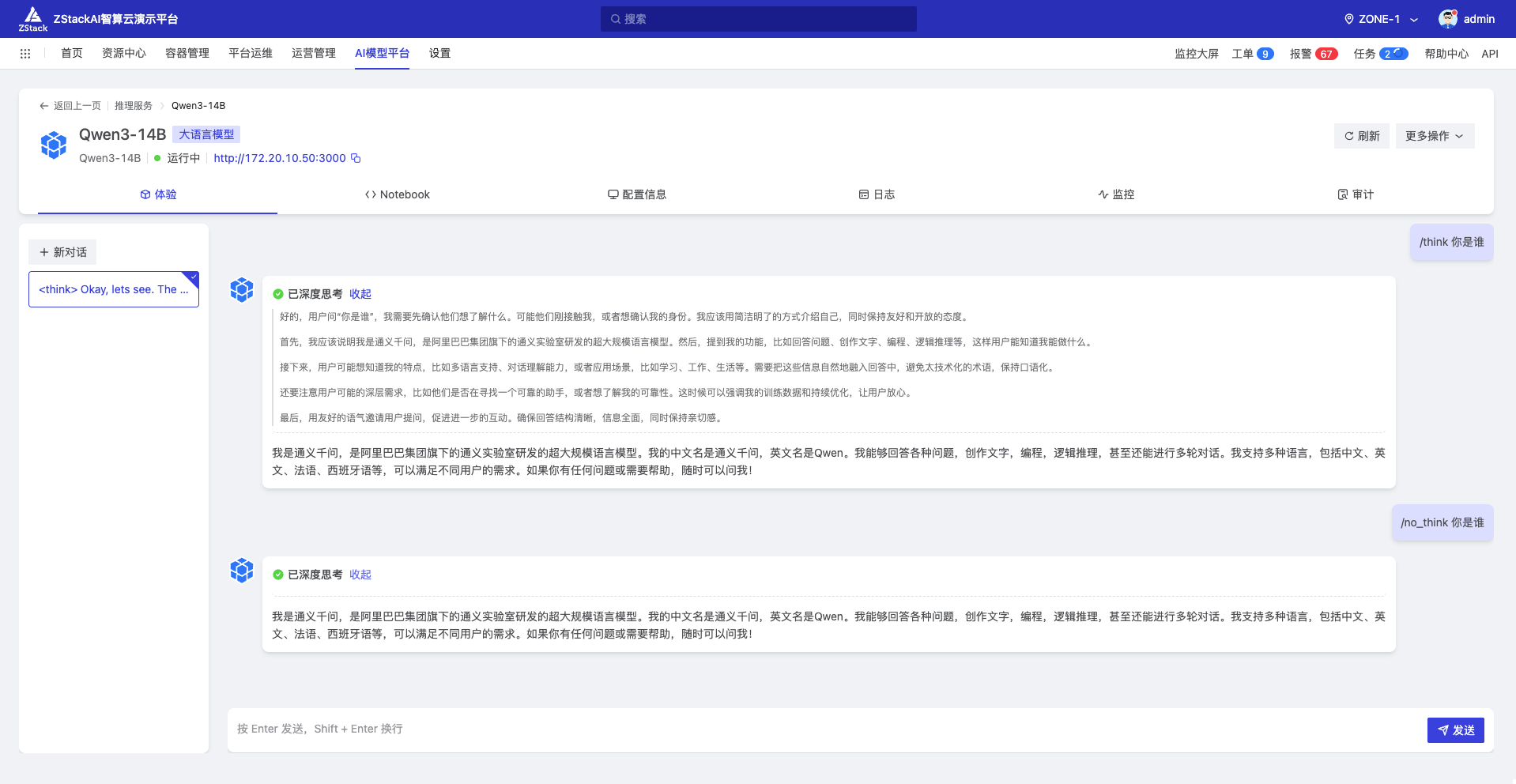
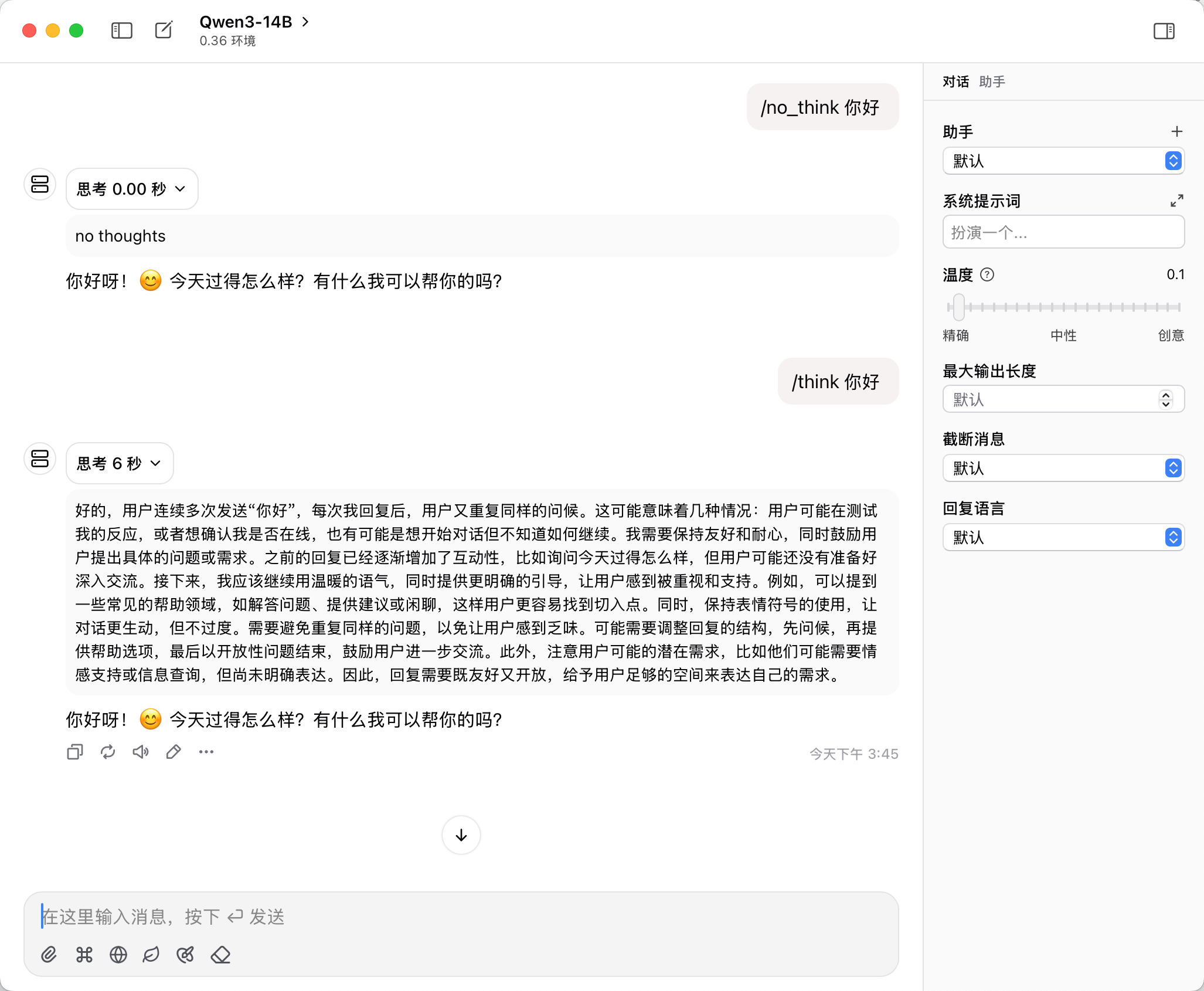
在 Qwen3 模型中 /think、/no_think 可以作为特殊 token 来控制是否打开思考。
