@Otokaze
2018-03-29T00:18:58.000000Z
字数 4925
阅读 807
XML 笔记
html
XML 简介
XML 全称:Extensible Markup Language,即 可扩展标记语言。
XML 被设计用来 传输 和 存储 数据。HTML 被设计用来 显示 数据。
<?xml version="1.0" encoding="UTF-8"?><urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"><url><loc>https://www.zfl9.com/ss-redir.html</loc><lastmod>2018-03-12T07:01:15.514Z</lastmod></url><url><loc>https://www.zfl9.com/array-search-sort-algo.html</loc><lastmod>2018-01-16T10:14:44.059Z</lastmod></url><url><loc>https://www.zfl9.com/data-structures-algorithms.html</loc><lastmod>2018-01-14T08:20:42.631Z</lastmod></url><url><loc>https://www.zfl9.com/java-collection.html</loc><lastmod>2018-01-14T02:46:44.095Z</lastmod></url></urlset>
- XML 是一种很像 HTML 的标记语言。
- XML 的设计宗旨是传输数据,而不是显示数据。
- XML 标签没有被预定义。您需要自行定义标签。
- XML 被设计为具有自我描述性。
- XML 是 W3C 的推荐标准。
XML 不会做任何事情
这也许有点难以理解,但是 XML 不会做任何事情。
XML 被设计用来 结构化、存储 以及 传输 信息。
下面实例是 Jani 写给 Tove 的便签,存储为 XML:
<note><to>Tove</to><from>Jani</from><heading>Reminder</heading><body>Don't forget me this weekend!</body></note>
上面的这条便签具有自我描述性。它包含了发送者和接受者的信息,同时拥有标题以及消息主体。但是,这个 XML 文档仍然没有做任何事情。它仅仅是包装在 XML 标签中的纯粹的信息。我们需要编写软件或者程序,才能传送、接收和显示出这个文档。
- XML 可作为配置文件使用
- XML 可作为小型数据库使用
XML 语法
XML 文档形成了一种树结构,它从"根部"开始,然后扩展到"枝叶"。
XML 文档必须包含根元素,根元素有且只有一个,其它情况均视为错误。
XML 文档由一系列的 Element 构成,Element 可以包含文本、属性、Element。
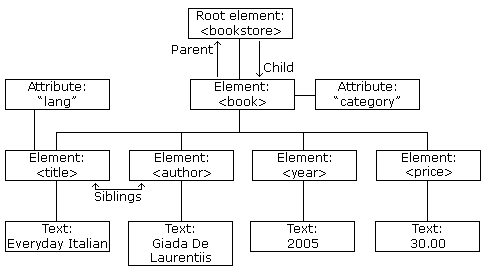
<?xml version="1.0" encoding="UTF-8"?><bookstore><book category="cooking"><title lang="en">Everyday Italian</title><author>Giada De Laurentiis</author><year>2005</year><price>30.00</price></book><book category="children"><title lang="en">Harry Potter</title><author>J K. Rowling</author><year>2005</year><price>29.99</price></book><book category="web"><title lang="en">Learning XML</title><author>Erik T. Ray</author><year>2003</year><price>39.95</price></book></bookstore>
XML 声明
XML 声明不是必选项,但是如果使用 XML 声明,必须在文档的第一行,前面不得包含任何其他内容或空白。虽然 XML 声明是可选的,但是强烈建议使用 XML 声明。
XML 声明包含下列内容:
<?xml version="1.0"?>,xml 版本号,必选项
目前的 XML 版本为 1.0,以后的 XML 版本可能会更改该数字<?xml version="1.0" encoding="UTF-8"?>,字符编码,可选项
编码声明必须位于版本声明的后面,字符编码名称是大小写不敏感的<?xml version="1.0" encoding="UTF-8" standalone="yes"?>,独立声明,可选项
独立声明必须位于 XML 声明的尾部,它的取值为yes/no,默认值为no
根元素:XML 文档有且只有一个根元素,根元素是其余元素的共同祖先元素。
关闭标签:所有 XML 元素必须有关闭标签,不可省略。<tag></tag> 或 <tag />。
大小写敏感:XML 标签对大小写是敏感的,这是与 HTML 不同的地方之一。
正确嵌套:XML 标签之间必须正确的嵌套,<a><b></a></b>错,<a><b></b></a>对。
属性值必须加引号:单双引号都行,单引号中允许双引号,反之亦然,否则需要转义。
XML 字符实体:文本、属性值中有 5 个特殊字符,要表示它们,建议使用实体引用:
<实体引用:<,英文:less than>实体引用:>,英文:greater then&实体引用:&,英文:ampersand'实体引用:',英文:apostrophe"实体引用:",英文:quotation mark
XML 注释:语法同 HTML,<!-- 注释内容 -->,多个注释之间不允许嵌套。
XML 连续空白符:HTML 中的连续空白符将被缩减为一个,但 XML 中不会被缩减。
XML 使用 LF 换行符:Windows 使用 CRLF、Linux 使用 LF、旧的 MAC 使用 CR。
XML 元素命名规则
- 元素名是大小写敏感的
- 元素名必须以 字母、下划线 开头
- 元素名不能以
xml、XML、Xml等保留字符开头 - 元素名可包含 字母、数字、下划线、连字符、英文句点
元数据应存储为属性,数据本身应存储为元素,千万不要混用、滥用。
XML 解析
目前解析 XML 文档的两种基本方式:DOM、SAX。
大名鼎鼎的 DOM(Document Object Model,文档对象模型)
说它大名鼎鼎可是一点不为过,DOM 是 W3C 处理 XML 的标准 API,它是许多其它与 XML 处理相关的标准的基础,不仅是 Java,其它诸如 Javascript,PHP,MS .NET 等等语言都实现了该标准, 成为了应用最为广泛的 XML 处理方式。当然,为了能提供更多更加强大的功能,Java 对于 DOM 直接扩展工具类有很多,比如很多 Java 程序员耳熟能详的 JDOM,DOM4J 等等, 它们基本上属于对 DOM 接口功能的扩充,保留了很多 DOM API 的特性,许多原本的 DOM 程序员甚至都没有任何障碍就熟练掌握了另外两者的使用,直观、易于操作的方式使它深受广大 Java 程序员的喜爱。
绿色环保的 SAX(Simple API for XML,事件驱动模型)
SAX 的应运而生有它特殊的需要,为什么说它绿色环保呢,这是因为 SAX 使用了最少的系统资源和最快速的解析方式对 XML 处理提供了支持。但随之而来繁琐的查找方式也给广大程序员带来许多困扰,常常令人头痛不已,同时它对 XPath 查询功能的支持,令人们对它又爱又恨。
DOM、SAX 优缺点对比
DOM
优缺点:实现 W3C 标准,有多种编程语言支持这种解析方式,并且这种方法本身操作上简单快捷,十分易于初学者掌握。其处理方式是将 XML 整个作为类似树结构的方式读入内存中以便操作及解析,因此支持应用程序对 XML 数据的内容和结构进行修改,但是同时由于其需要在处理开始时将整个 XML 文件读入到内存中去进行分析,因此其在解析大数据量的 XML 文件时会遇到类似于内存泄露以及程序崩溃的风险,请对这点多加注意。
适用范围:小型 XML 文件解析、需要全解析或者大部分解析 XML、需要修改 XML 树内容以生成自己的对象模型。
SAX
SAX 从根本上解决了 DOM 在解析 XML 文档时产生的占用大量资源的问题。其实现是通过类似于流解析的技术,通读整个 XML 文档树,通过事件处理器来响应程序员对于 XML 数据解析的需求。由于其不需要将整个 XML 文档读入内存当中,它对系统资源的节省是十分显而易见的,它在一些需要处理大型 XML 文档以及性能要求较高的场合有起了十分重要的作用。支持 XPath 查询的 SAX 使得开发人员更加灵活,处理起 XML 来更加的得心应手。但是同时,其仍然有一些不足之处也困扰广大的开发人员:首先是它十分复杂的 API 接口令人望而生畏,其次由于其是属于类似流解析的文件扫描方式,因此不支持应用程序对于 XML 树内容结构等的修改,可能会有不便之处。
适用范围:大型 XML 文件解析、只需要部分解析或者只想取得部分 XML 树内容、有 XPath 查询需求、有自己生成特定 XML 树对象模型的需求。
XML 命名空间
在 XML 中,元素名称是由开发者定义的,当两个不同的文档使用相同的元素名时,就会发生命名冲突。
使用 XML namespace 机制可以有效的避免命名冲突问题。XML 命名空间类似于 C++ 的命名空间、Java 的全限定类名,它们的作用都是类似的,为了避免命名冲突。
XML 命名空间(XML namespace,也译作 XML 名称空间、XML 名字空间)用于在一个 XML 文档中提供 名字唯一 的 元素 和 属性。XML 命名空间在 W3C 推荐规范《Namespaces in XML》中定义。XML 命名空间于 1999年1月14日成为 W3C 的推荐规范。
W3C 将 XML 命名空间定义为以 国际化资源标识符(Internationalized Resource Identifier,IRI)引用为标识的 元素名 和 属性名 的集合。但通常都是使用 URI(统一资源标识符)作为 XML 命名空间的标识符。
声明一个命名空间使用属性 xmlns,语法如下:xmlns[:prefix]="uri",其中 :prefix 前缀部分是可选的,未定义前缀的命名空间将被用作 缺省命名空间。命名空间的 URI 仅仅是唯一的标识符,推荐规范并不要求,也不建议通过其获取信息。XML 解析器处理命名空间 URI 时,也仅仅将其作为普通字符串。之所以使用 URI 而不是普通字符串,是因为 URI 的重名概率很小。
XML 文档中的元素名和属性名可以使用限定名或非限定名,限定名由命名空间前缀和原始名组合而成,如 xhtml:table,非限定名只有原始名,没有前缀部分。非限定名被认为属于缺省命名空间,如果缺省命名空间没有定义,则属于 无命名空间。
在一个元素中声明的命名空间,对它自己和它所有子元素都是有效的,一种通常的做法是,在 XML 文档的根元素中声明所使用的默认命名空间。在子元素中声明的命名空间前缀可以覆盖父元素中声明的命名空间前缀。
XML CDATA
XML 文档中的所有文本均会被解析器解析。
只有 CDATA 区段中的文本会被解析器忽略。
CDATA(Character Data) 是不应该由 XML 解析器解析的文本数据。
在 XML 中,像 < 和 & 等字符出现在文本值、属性值中都是非法的。
< 会产生错误,因为解析器会把该字符解释为新元素的开始。
& 会产生错误,因为解析器会把该字符解释为字符实体的开始。
某些文本,比如 JS 代码,包含大量 < 或 & 字符。
为了避免错误,我们可以将脚本代码定义为 CDATA。
<?xml version="1.0" encoding="utf-8"?><html xmlns="http://www.w3.org/html5"><head><title>hello, world!</title></head><body><h1>hello, world!</h1><script><![CDATA[function compare(a, b) {if (a < b)return -1;else if (a === b)return 0;else if (a > b)return 1;}]]></script></body></html>
