@aloxc
2017-12-05T06:36:07.000000Z
字数 14167
阅读 1118
ignite 知识点分享
ignite share
一、简介
1、ignite 是什么
Apache Ignite内存数据组织(in-memory data fabric)是高性能的、集成化的以及分布式的内存平台,他可以实时地在大数据集中执行事务和计算,和传统的基于磁盘或者闪存的技术相比,性能有数量级的提升。 是GridGain公司于2014年3月将该软件的90%以后的功能和代码开源,仅在商业版中保留了高端企业级功能,如安全性,数据中心复制,先进的管理和监控等。2015年1月,GridGain通过Apache 2.0许可进入Apache的孵化器进行孵化,很快就于8月25日毕业并且成为Apache的顶级项目,当前版本1.7.0/
2、ignite 能干什么
| 功能名称 | 功能描述 |
|---|---|
| Data Grid | 缓存服务。实现了实现了JCache(JSR107)规范;可做为hibernate、mybatis的2级缓存;支持标准的sql查询;使用堆外内存 |
| Compute Grid | 计算网格。支持分布式的闭包;map reduce; |
| Service Grid | 服务网格。 |
| Streaming | 流式计算及CEP,支持kafka、camel |
| Hadoop Acceleration | hadoop加速 |
| Advanced Clustering | 高级集群化。集群分组;leader选举;零部署 |
| File System | 分布式文件系统igfs,基于内存的文件系统 |
| Messaging | 分布式消息 |
| Events | 分布式事件 |
| Data Struction | 分布式数据结构。队列;集合;原子数 |
ignite的技术特点:
开源
完全使用java开发
支持java7及以上版本
基于spring
3、其他类似产品
ignite集成的功能点较多,目前市面上没有与之相差不多的产品,但是每个功能点背后基本上能找到近似的产品,
缓存类:memcache、redis、timesten、mongodb等。
分布式计算:hadoop
流式计算:storm,spark,
文件系统:tfs、gfs、hdfs
分布式消息:ActiveMQ、RocketMQ
4、如何获得及安装使用
4.1、ignite官方网站下载
下载到压缩包apache-ignite-fabric-1.7.0-bin.zip
- 1、安装jdk(7以上)及设置JAVA_HOME
- 2、解压
- 3、设置环境变量IGNITE_HOME
- 4、
bin/ignite.sh ../config/default-config.xml或者bin/ignite.bat ../config/default-config.xml,配置文件路径可省略,默认../config/example-cache.xml
启动后可看到如下画面

4.2、maven依赖
<dependency><groupId>org.apache.ignite</groupId><artifactId>ignite-core</artifactId><version>1.7.0</version></dependency>
其他模块:
ignite-spring:基于Spring的配置支持
ignite-indexing:SQL查询和索引
ignite-geospatial:地理位置索引
ignite-hibernate:Hibernate集成
ignite-web:Web Session集群化
ignite-schedule:基于Cron的计划任务
ignite-log4j:Log4j日志
ignite-jcl:Apache Commons logging日志
ignite-jta:XA集成
ignite-hadoop2-integration:HDFS2.0集成
ignite-rest-http:HTTP REST请求
ignite-scalar:Ignite Scalar API
ignite-slf4j:SLF4J日志
ignite-ssh;SSH支持,远程机器上启动网格节点
ignite-urideploy:基于URI的部署
ignite-aws:AWS S3上的无缝集群发现
ignite-aop:网格支持AOP
ignite-visor-console:开源的命令行管理和监控工具
5、入门
5.1、计算应用,通过ignite计算网格进行分布式计算字符串的长度ComputeCallableExample.java
5.2、缓存操作,读取写入及更新一些缓存CachePutGetExample.java
6、配置文件default-config.xml
7、异步支持
ignite绝大多数操作都同时支持同步和异步操作。
异步操作的时候,一般是在同步操作的方法后面跟上.withAsync(),然后通过操作的future方法获取IgniteFuture对象,并在该IgniteFuture对象注册异步监听方法即可。
二、集群化
Ignite具有非常先进的集群能力,包括逻辑集群组和自动发现。
Ignite节点之间会自动发现对方,这有助于必要时扩展集群,而不需要重启整个集群。
1、集群api
1.1、IgniteCluster 集群
集群的功能是通过IgniteCluster接口提供的,可以像下面这样从Ignite中获得一个IgniteCluster的实例:
Ignite ignite = Ignition.ignite();IgniteCluster cluster = ignite.cluster();
通过IgniteCluster接口可以:
- 获取集群成员的列表;
- 创建逻辑集群组;
1.2、ClusterNode 集群节点
处理集群中的节点,把他视为网络中的逻辑端点,他有一个唯一的ID,可以通过ClusterNode获取节点的元数据信息,静态属性集以及一些其他的参数。
Collection<ClusterNode> nodeList = cluster.nodes();
1.3、ClusterMetrics 集群节点各指标数据
ClusterMetrics metrics = node.metrics();
1.4、ClusterGroup 集群组
ClusterGroup表示集群内节点的一个逻辑组。
从设计上讲,所有集群节点都是平等的,所以没有必要以一个特定的顺序启动任何节点,或者给他们赋予特定的规则。然而,Ignite可以因为一些应用的特殊需求而创建集群节点的逻辑组,比如,可能希望只在远程节点上部署一个服务,或者给部分worker节点赋予一个叫做‘worker’的规则来做作业的执行。
特别注意,IgniteCluster接口也是一个集群组,只不过包括集群内的所有节点。
以上部分可以见代码:ClusterGroupExample.java
2、DiscoverySpi集群配置
Ignite中,通过DiscoverySpi节点可以彼此发现对方,Ignite提供了TcpDiscoverySpi作为DiscoverySpi的默认实现,它使用TCP/IP来作为节点发现的实现,可以配置成基于组播的或者基于静态IP的。
2.1、TcpDiscoveryMulticastIpFinder基于组播的发现
TcpDiscoveryMulticastIpFinder使用组播来发现网格内的每个节点。他也是默认的IP搜索器。
<bean class="org.apache.ignite.configuration.IgniteConfiguration">...<property name="discoverySpi"><bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi"><property name="ipFinder"><bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.multicast.TcpDiscoveryMulticastIpFinder"><property name="multicastGroup" value="228.10.10.157"/></bean></property></bean></property></bean>
2.2、TcpDiscoveryVmIpFinder基于静态IP的发现
对于组播被禁用的情况,TcpDiscoveryVmIpFinder会使用预配置的IP地址列表。
唯一需要提供的就是至少一个远程节点的IP地址,但是为了保证冗余一个比较好的做法是在未来的某些时间点提供2-3个计划启动的网格节点的IP地址。只要建立了与任何一个已提供的IP地址的连接,Ignite就会自动地发现其他的所有节点。
<property name="discoverySpi"><bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi"><property name="ipFinder"><bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.vm.TcpDiscoveryVmIpFinder"><property name="addresses"><list><value>192.168.16.68:47500..47509</value><value>192.168.16.69:47500..47509</value></list></property></bean></property>
2.3、基于其它形式的发现
基于Apache Jcloud的发现
基于Amazon S3的发现
基于谷歌云的发现
基于jdbc的发现
基于自定义的发现,实现org.apache.ignite.spi.discovery.tcp.TcpDiscoveryIpFinder接口
3、零部署
计算所需的闭包和任务可能是任意自定义的类,也包括匿名类。Ignite中,远程节点会自动感知这些类,不需要显式地将任何jar文件部署或者移动到任何远程节点上。
这个行为是通过对等类加载(P2P类加载)实现的,他是Ignite中的一个特别的分布式类加载器,实现了节点间的字节码交换。当对等类加载启用时,不需要在网格内的每个节点上手工地部署Java代码,也不需要每次在发生变化时重新部署。
<bean class="org.apache.ignite.configuration.IgniteConfiguration"><property name="peerClassLoadingEnabled" value="true"/></bean>
对等类加载的工作步骤如下:
1.Ignite会检查类是否在本地CLASSPATH(libs目录)中有效(是否在系统启动时加载),如果有效,就会被返回。这时不会发生从对等节点加载类的行为。
2.如果类本地不可用,会向初始节点发送一个提供类定义的请求,初始节点会发送类字节码定义然后类会在工作节点上加载。这个每个类只会发生一次,一旦一个节点上一个类定义被加载了,他就不会再次加载了。
另外建议在每个节点的类路径里包含所有的第三方库,这可以通过将jar文件复制到Ignite的libs文件夹实现,这样就可以避免每次只改变了一行代码然后还需要向远程节点上传输若干第三方库文件。
4、部署模式
对等类加载行为的特性是由不同的部署模式控制的。特别地,当发起节点离开网格时的卸载行为也会依赖于部署模式。另一方面,由部署模式,是用户资源管理和类版本管理。
SHARED,这是默认的部署模式,这个模式中,来自不同主节点的、用户版本相同的类会在worker节点上共享同一个类加载器,当所有的主节点离开集群时,类会卸载。
CONTINUOUS这个模式中,即使所有的主节点离开集群,类都不会卸载。只有当用户版本发生变化的时候类才会卸载。
这两中部署模式下,可以使来自不同主节点的任务在worker节点共享同一个用户资源的实例(资源注入),这使得在worker节点上执行的所有任务可以复用,比如,连接池或者缓存的同一个实例。
关于部署模式说明:本次分享的由于使用到了缓存通读通写无法使用PRIVATE模式,所以本次的所有代码都打包放到远程节点libs目录中。
三、数据网格(缓存功能)
1、数据网格基本简介
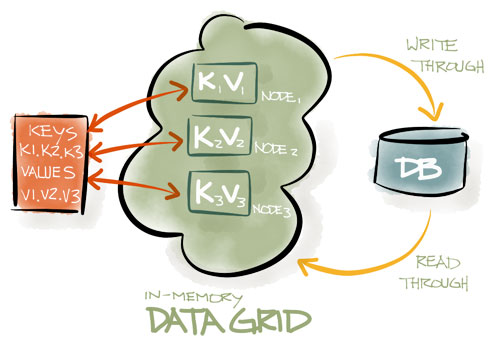
Ignite数据网格是一个基于内存的分布式键值存储,他可以视为一个分布式的分区化哈希,每个集群节点都持有所有数据的一部分,这意味着随着集群节点的增加,就可以缓存更多的数据。 增加集群节点后,数据会自动再平衡,与其他键值存储系统不同,Ignite通过可插拔的哈希算法来决定数据的位置,每个客户端都可以通过一个加入一个哈希函数决定一个键属于哪个节点,而不需要任何特定的映射服务器或者name节点。 Ignite数据网格支持本地、复制的、分区化的数据集,允许使用标准SQL语法方便地进行跨数据集查询,同时还支持在内存数据中进行分布式SQL关联。
数据一致性,只要集群仍然处于活动状态,即使节点崩溃或者网络拓扑发生变化,Ignite都会保证不同集群节点中的数据的一致性。
ignite实现了Jcache(JSR107,javax.cache.*包)的全部规范,
<dependency><groupId>javax.cache</groupId><artifactId>cache-api</artifactId><version>1.0.0</version></dependency>
实现了jcache的全部规范,并且超越了该规范,该规范忽略了任何有关数据如何分布及一致性等的相关细节,ignite完成了这些事情。并且ignite还提供了ACID事务,数据查询能力(包括sql查询),各种内存模型及数据加载,异步操作模型。
2、IgniteCache
IgniteCache接口是Ignite缓存实现的一个入口,提供了保存和获取数据,执行查询,包括SQL,迭代和扫描等等的方法。
可以从Ignite中直接获取到IgniteCache的示例:
Ignite ignite = Ignition.ignite();IgniteCache<Integer, String> cache = ignite.cache("myCache");
该示例代码中从缓存中获取name=myCache的缓存对象,其缓存的key类型是整形,value类型是字符串。这个name=myCache的缓存信息可以定义在ignite的配置文件中,也可以动态的创建缓存的一个实例,这时ignite会在所有的集群成员中创建和部署该缓存服务,创建代码如下:
Ignite ignite = Ignition.ignite();CacheConfiguration cfg = new CacheConfiguration();cfg.setName("myCache");cfg.setAtomicityMode(TRANSACTIONAL);IgniteCache<Integer, String> cache = ignite.getOrCreateCache(cfg);
测试实例代码见CachePutGetExample.java
3、异步支持
和Ignite中的所有API一样,IgniteCache实现了IgniteAsynchronousSupport接口,因此可以以异步的方式使用。
测试代码见CacheAsyncApiExample.java
注意当异步操作的时候直接通过操作方法读取操作的返回值都是null,需要从过future.get()才能读取到返回值。
也可以给future加监听代码。
4、缓存操作模式
Ignite提供了三种不同的缓存操作模式,分区PARTITIONED、复制REPLICATED和本地LOCAL。缓存模型可以为每个缓存单独配置,缓存模型是通过CacheMode枚举定义的。
4.1、分区模式PARTITIONED
分区模式是扩展性最好的分布式缓存模式,这种模式下,所有数据被均等地分布在分区中,所有的分区也被均等地拆分在相关的节点中,实际上就是为缓存的数据创建了一个巨大的内存内分布式存储。这个方式可以在所有节点上只要匹配总可用内存就可以存储尽可能多的数据,因此,可以在集群的所有节点的内存中可以存储TB级的数据,也就是说,只要有足够多的节点,就可以存储足够多的数据。 这个和我们平常使用memcache中的分布式模式一致,每个节点保存部分数据。
下图简单描述了一下一个分区缓存,实际上,键A赋予了运行在JVM1上的节点,B赋予了运行在JVM3上的节点,等等。
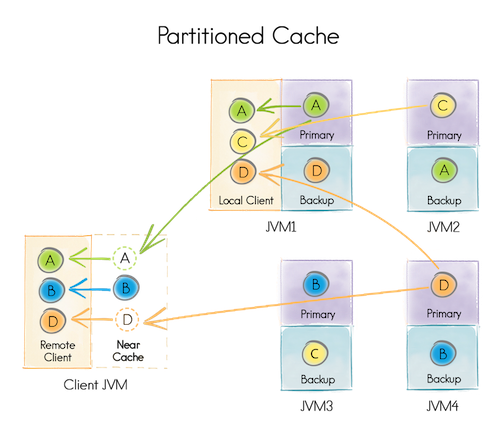
分区模式适合于数据量很大而更新频繁的场合。
4.2、复制模式REPLICATED
复制模式中,所有数据都被复制到集群内的每个节点,因为每个节点都有效所以这个缓存模式提供了最大的数据可用性。然而,这个模式每个数据更新都要传播到其他所有节点,因而会对性能和可扩展性产生影响。
Ignite中,复制缓存是通过分区缓存实现的,每个键都有一个主拷贝而且在集群内的其他节点也会有备份。 类似memcache中的复制模式,每个节点保存相同的数据。
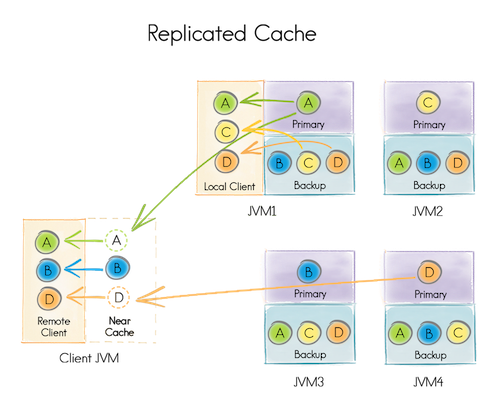
复制模式适用于数据集不大而且更新不频繁的场合。
4.3、本地模式LOCAL
本地模式是最轻量的模式,因为没有数据被分布化到其他节点。他适用于或者数据是只读的,或者需要定期刷新的场景中。当缓存数据失效需要从持久化存储中加载数据时,他也可以工作与通读模式。除了分布化以外,本地缓存包括了分布式缓存的所有功能,比如自动数据回收,过期,磁盘交换,数据查询以及事务。
几种模式的区别
| 比较项 | 分区模式 | 复制模式 | 本地模式 |
|---|---|---|---|
| 数据分布 | 每节点只有部分数据 | 每个节点缓存相同的全量数据 | 只在客户端本地保存 |
| 数据量 | 很大 | 很小 | 很小 |
| 更新成本 | 很小 | 很大 | 很小 |
| 读取特点 | 分布式读取 | 随机抽取节点 | 从本地读取 |
| 使用场景 | 数据量很大而更新频繁的场合 | 数据集不大而且更新不频繁的场合 | 数据是只读的,或者需要定期刷新 |
4.4、配置
<bean class="org.apache.ignite.configuration.IgniteConfiguration"><property name="cacheConfiguration"><bean class="org.apache.ignite.configuration.CacheConfiguration"><property name="name" value="cacheName"/><property name="cacheMode" value="PARTITIONED"/></bean></property></bean>
CacheConfiguration cacheCfg = new CacheConfiguration("myCache");cacheCfg.setCacheMode(CacheMode.PARTITIONED);IgniteConfiguration cfg = new IgniteConfiguration();cfg.setCacheConfiguration(cacheCfg);
4.5、主节点及备份副本
在分区模式下,赋予键的节点叫做这些键的主节点,对于缓存的数据,也可以有选择地配置任意多个备份节点。如果副本数量大于0,那么Ignite会自动地为每个独立的键赋予备份节点,比如,如果副本数量为1,那么数据网格内缓存的每个键都会有2个备份,一主一备。
因为性能原因备份默认是被关闭的。
5、缓存查询
Ignite提供了非常优雅的查询API,支持基于谓词的扫描查询、SQL查询(ANSI-99兼容)、文本查询。对于SQL查询,Ignite提供了内存内的索引,因此所有的数据检索都是非常快的,如果是在堆外内存中缓存数据的,那么查询索引也会缓存在堆外内存中。
5.1、主要的抽象
IgniteCache有若干个查询方法,这些方法可以获得一些Query的子类以及返回QueryCursor。
查询
Query抽象类表示一个在分布式缓存上执行的抽象分页查询。可以通过Query.setPageSize(...)方法设置返回游标的每页大小(默认值是1024)。
查询游标
QueryCursor表示查询的结果集,可以透明地进行一页一页地迭代。每当迭代到每页的最后时,会自动地在后台请求下一页的数据,当不需要分页时,可以使用QueryCursor.getAll()方法,他会获得整个查询结果集然后存储在集合里。
关闭游标
如果调用了QueryCursor.getAll()方法,游标会自动关闭。如果通过for循环迭代一个游标或者显式地获得Iterator,必须显式地关闭或者使用AutoCloseable语法。
5.2、各种查询方式
5.2.1、通过注解进行查询相关配置@QuerySqlField、@QueryTextField
通过在实体类需要查询的字段上添加@QuerySqlField和@QueryTextField注解来配置允许的查询。
如需索引的话在@QuerySqlField注解的index设置true即可,也可以通过CacheConfiguration.setIndexedTypes(Collection<QueryIndex>)方法来设置。
如下bean的配置
public class Person implements Serializable {/** Person ID (indexed). */@QuerySqlField(index = true)private long id;/** Organization ID (indexed). */@QuerySqlField(index = true)private long orgId;/** First name (not-indexed). */@QuerySqlFieldprivate String firstName;/** Last name (not indexed). */@QuerySqlFieldprivate String lastName;/** Resume text (create LUCENE-based TEXT index for this field). */@QueryTextFieldprivate String resume;/** Salary (indexed). */@QuerySqlField(index = true)private double salary;...}
5.2.2、使用QueryEntity进行查询配置
索引和字段也可以通过org.apache.ignite.cache.QueryEntity进行配置,他便于通过Spring使用XML进行配置,详细信息可以参照JavaDoc。他与@QuerySqlField注解是等价的,因为在内部类注解会被转换成查询实体。
5.2.2、扫描查询SanQuery
本节示例测试代码 CacheQueryExample.java
扫描查询可以通过用户定义的谓词以分布式的形式进行缓存的查询。
5.2.3、文本查询 TextQuery
Ignite的文本查询也支持通过Lucene索引实现的基于文本的查询。
5.2.4、sql查询SqlQuery和SqlFieldsQuery
一点经验:尽量不要在sql语句中使用like语句对某字段查询,可能会有你预想不到的结果(错误结果),这个点在下面再讲!
5.3、SQL查询如何工作
ignite中处理查询主要有两种方式:
- 如果在复制缓存中执行查询,那么Ignite会假定所有数据都是本地有效的然后只是在H2数据库引擎中执行一个简单的查询,本地缓存中也是一样的。
- 如果在分区缓存中执行查询,工作方式如下:查询会被解析并且拆分成多个Map查询和一个Reduce查询,然后所有的Map查询在分区缓存的所有数据节点上执行,再把结果提供给Reduce节点,他会在这些中间结果上依次执行Reduce查询。
5.4、持续查询ContinuousQuery
持续查询对于当执行一个查询之后希望持续地获得该查询结果数据更新的通知时,是很有用的。
6、堆外内存
由于ignite是使用java编写的软件,为了避免jvm做gc操作的时候导致的暂把堆内数据删除了,ignite可配置实用堆外内存。特别当数据集特别大的时候,应该配置堆外内存来缓存数据。memoryMode
使用堆外内存的来存储数据的时候,ignite会把数据及数据的索引都保存在堆外。
其提供了3中存储模型
| 存储模型 | 描述 |
|---|---|
| ONHEAP_TIERED | 保存在堆内,逐出到堆外以及可选的存储在交换空间 |
| OFFHEAP_TIERED | 保存在堆外,避开堆内以及可选的逐出到交换空间 |
| OFFHEAP_VALUES | 将键存储在堆内,将值存储在堆外 |
ignite默认把数据及索引保存在堆内ONHEAP_TIERED,当堆内内存用完后会移动到堆外,堆外也用完后会移动到交换空间(可配置关闭),而不是抛弃这些数据。
移动哪些数据是通过逐出策略配置的,ignite默认实现了4种逐出策略
lur 最近最少使用
fifo 先进先出
sorted 有序,和fifo很像,不同点在于通过默认或者自定义的比较器定义数据的顺序,然后排序最小的数据会被逐出
random 随机,一般用于调试测试
igfs
7、持久化存储
什么是持久化存储?
JCache提供了javax.cache.integration.CacheLoader和javax.cache.integration.CacheWriter API,他们分别用于底层持久化存储(一般为关系数据库)的通读和通写。ignite中提供了一个接口CacheStore,它同时扩展了CacheLoader和CacheWriter接口。
7.1、通读readThrough和通写writeThrough
通读意味着当缓存无效时会从持久化存储中读取,通写意味着当缓存更新时会自动地进行持久化。
7.2、后写缓存
在一个简单的通写模式中每个缓存的put和remove操作都会涉及一个持久化存储的请求,因此整个缓存更新的持续时间可能是相对比较长的。另外,密集的缓存更新频率也会导致非常高的存储负载。
为了解决这个问题,ignite提供了一个异步的持久化存储更新,这就是后写缓存。
更新顺序
对于后写的方式只有数据的最后一次更新会被写入底层存储。如果键为key1的缓存数据分别依次地更新为值value1、value2和value3,那么只有(key1,value3)对这一个存储请求会被传播到持久化存储。
7.3、CacheStore
上面说了通读和通写,最终如何把数据更新到持久化存储还得通过CacheStore来实现,我们只要实现该接口,完成该接口中的相关方法即可。
示例代码CacheLoadOnlyStoreExampleUsingMysql.java
8、逐出策略evictionPolicy
逐出策略控制着堆内内存中缓存可以存储的元素的最大值,如果可能的话当达到堆内缓存的最大值时,数据会被逐出到堆外空间。
默认有几个ignite实现了的逐出策略:
LruEvictionPolicy最近最少使用;
FifoEvictionPolicy先进先出;
SortedEvictionPolicy有序;
RandomEvictionPolicy随机.
我们也可以设置自己定义的逐出策略(需要实现EvictionPolicy接口),
9、过期策略expiryPolicy
过期策略指定了在缓存条目过期之前必须经过的时间量,时间可以从创建,最后访问或者修改时间开始计算。
过期策略可以通过任何预定义的ExpiryPolicy实现进行设置。
10、jdbc支持
ignite支持直接使用jdbc来操作ignite的数据网格,
如下代码
// Register JDBC driver.Class.forName("org.apache.ignite.IgniteJdbcDriver");// Open JDBC connection (cache name is not specified, which means that we use default cache).Connection conn = DriverManager.getConnection("jdbc:ignite:cfg://file:///etc/config/ignite-jdbc.xml");// Query names of all people.ResultSet rs = conn.createStatement().executeQuery("select name from Person");while (rs.next()) {String name = rs.getString(1);...}// Query people with specific age using prepared statement.PreparedStatement stmt = conn.prepareStatement("select name, age from Person where age = ?");stmt.setInt(1, 30);ResultSet rs = stmt.executeQuery();while (rs.next()) {String name = rs.getString("name");int age = rs.getInt("age");...}
11、memcached协议支持
可以通过各语言的memcached客户端连接到ignite使用ignite的缓存。
四、流式计算
五、分布式数据结构
1、数据结构
Ignite可以以一个分布式的方式使用java.util.concurrent框架中的大多数数据结构。
当前,Ignite中支持如下的分布式数据结构:
队列和集合
原子化类型
CountDownLatch
ID生成器IgniteCacheAtomicSequence
信号量Semaphore
2、队列和集合
Ignite除了提供了标准的键-值的类似于Map的存储以外,也提供了一个快速的分布式阻塞队列和分布式集合的实现。
IgniteQueue和IgniteSet分别是java.util.concurrent.BlockingQueue和java.util.Set接口的实现,也支持java.util.Collection接口的所有功能。
3、原子化类型
Ignite支持分布式的原子类型long和reference,分别类似于java.util.concurrent.atomic.AtomicLong和java.util.concurrent.atomic.AtomicReference。
4、CountDownLatch同步锁
5、ID生成器
IgniteCacheAtomicSequence接口提供的分布式原子性序列类似于分布式原子性的long类型,但是它的值只能增长。
六、分布式计算
七、服务网络
服务网格可以在集群上部署任意用户定义的服务,执行自定义的业务逻辑代码。类似rpc和rmi。
直接看示例代码,ServicesExample.java
八、消息和事件
Ignite分布式消息可以在集群内的所有节点间进行基于主题的通信,带有特定消息主题的消息可以分布到订阅了该主题的所有节点或者节点的子集。
Ignite消息基于发布-订阅范式,发布者和订阅者通过一个通用的主题连接在一起。当一个节点针对主题T发布了一个消息A,他会被分布到所有订阅了主题T的节点。
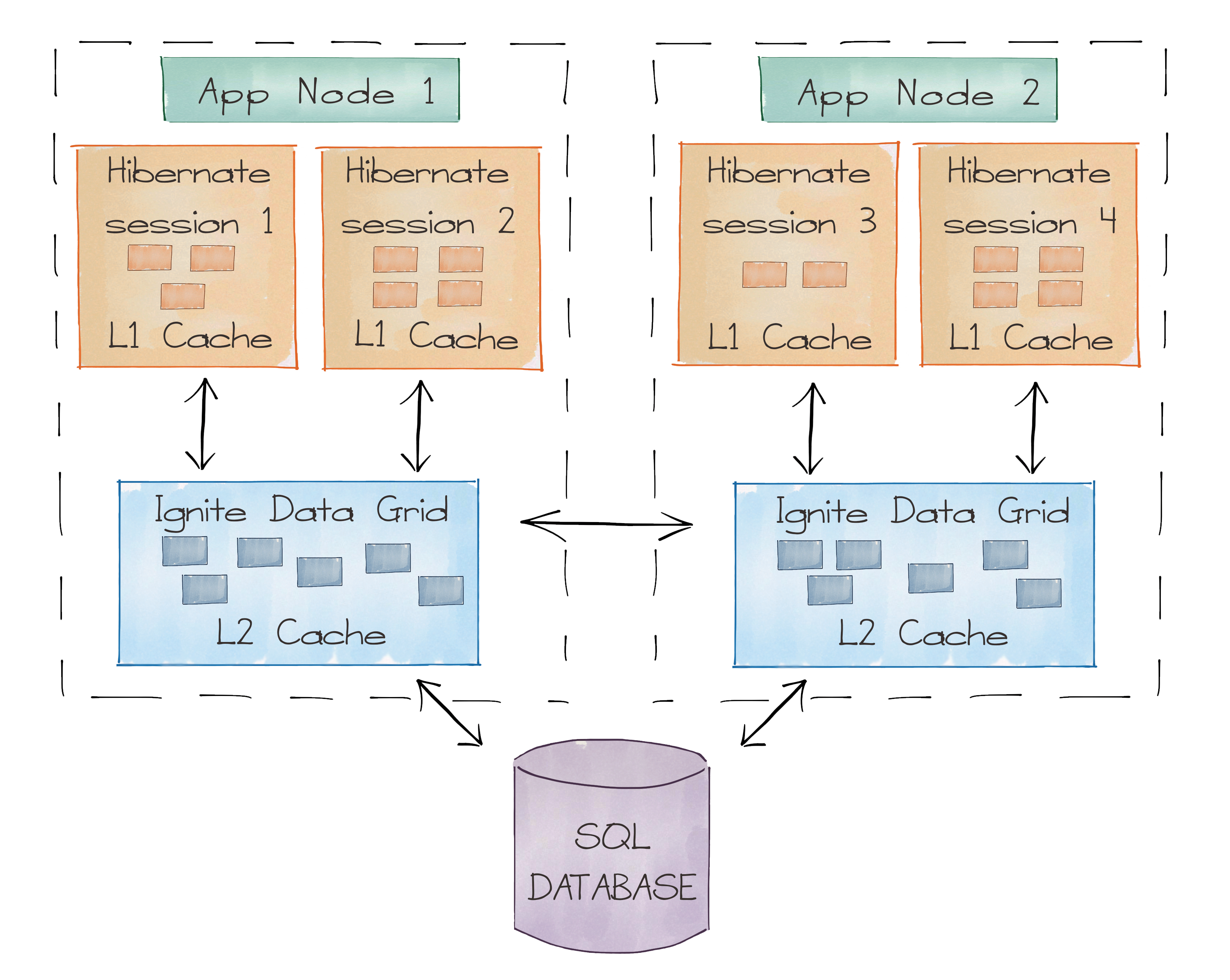
九、二级缓存
可以作为mybatis、hibernate等orm框架的二级缓存,
十、内存文件系统
Ignite有一个独特的功能,叫做Ignite文件系统(IGFS),就是一个分布式的内存文件系统,IGFS提供了和Hadoop HDFS类似的功能,但是只在内存中。事实上,除了他自己的API,IGFS还实现了Hadoop的文件系统API,可以透明地加入Hadoop或者Spark的运行环境。
十一、其他
spring支持
ignite已经提供好了,使用在spring中使用ignite功能的入口,在spring配置文件中配置相关的bean,在java代码中使用该bean id即可,具体可以见SpringBeanExample.java和spring-bean.xml。
最后给下性能测试
https://my.oschina.net/liyuj/blog/614595
http://www.cnblogs.com/5207/p/6089209.html
有用的网址

