@gone
2014-10-30T19:44:06.000000Z
字数 9082
阅读 1364
Chapter 15 Process & Thread & Synchronization
Thread Synchronizaiton
Thread vs. Process
- A process can have multiple threads. Each process is created with a single thread, based on which can create additional threads.
- Threads within a process are scheduled by the process, they share same the process' virtual address space and system resources
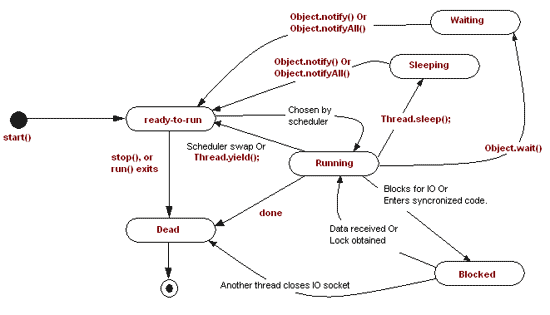
What are the different states of a thread's lifecycle?
1) New – When a thread is instantiated it is in New state until the start() method is called on the thread instance. In this state the thread is not considered to be alive.
2) Runnable – The thread enters into this state after the start method is called in the thread instance. The thread may enter into the Runnable state from Running state. In this state the thread is considered to be alive.
3) Running – When the thread scheduler picks up the thread from the Runnable thread’s pool, the thread starts running and the thread is said to be in Running state.
4) Waiting/Blocked/Sleeping – In these states the thread is said to be alive but not runnable. The thread switches to this state because of reasons like wait method called or sleep method has been called on the running thread or thread might be waiting for some i/o resource so blocked. 5) Dead – When the thread finishes its execution i.e. the run() method execution completes, it is said to be in dead state. A dead state can not be started again. If a start() method is invoked on a dead thread a runtime exception will occur.
Java Thread: Status Diagram
Concurrency vs. Parllelism
Concurrency doesn't necessarily mean the programs are running at the same, but parllelism have this meaning. Concurrency problems occurr when multiple twos are requring the same resource, instance, etc, in overlapping time periods.
Deadlock
Deadlock happens when each thread is asking for the other thread to release a lock.
Deadlock conditions:
(1) Mutual Exclusion
(2) Hold and wait
(3) No preemption
(4) Circular wait
Mutex:
Is a key to a toilet. One person can have the key - occupy the toilet - at the time. When finished, the person gives (frees) the key to the next person in the queue.
Officially: "Mutexes are typically used to serialise access to a section of re-entrant code that cannot be executed concurrently by more than one thread. A mutex object only allows one thread into a controlled section, forcing other threads which attempt to gain access to that section to wait until the first thread has exited from that section."
Semaphore:
Is the number of free identical toilet keys. Example, say we have four toilets with identical locks and keys. The semaphore count - the count of keys - is set to 4 at beginning (all four toilets are free), then the count value is decremented as people are coming in. If all toilets are full, ie. there are no free keys left, the semaphore count is 0. Now, when eq. one person leaves the toilet, semaphore is increased to 1 (one free key), and given to the next person in the queue.
Officially: "A semaphore restricts the number of simultaneous users of a shared resource up to a maximum number. Threads can request access to the resource (decrementing the semaphore), and can signal that they have finished using the resource (incrementing the semaphore)."
Misconception:
There is an ambiguity between binary semaphore and mutex. We might have come across that a mutex is binary semaphore. But they are not! The purpose of mutex and semaphore are different. May be, due to similarity in their implementation a mutex would be referred as binary semaphore.
Strictly speaking, a mutex is locking mechanism used to synchronize access to a resource. Only one task (can be a thread or process based on OS abstraction) can acquire the mutex. It means there will be ownership associated with mutex, and only the owner can release the lock (mutex).
Semaphore is signaling mechanism (“I am done, you can carry on” kind of signal). For example, if you are listening songs (assume it as one task) on your mobile and at the same time your friend called you, an interrupt will be triggered upon which an interrupt service routine (ISR) will signal the call processing task to wakeup.
Classical Problems
Dinning Philosopher problem (ctci 16.3)
Producer and Consumers
Producer:
loop : <xxx>;send(c);goto loop;
Consumer:
loop : c = rcv();<yyy>goto loop;
- Can't consume data before it's produced
sendi≤rcvi - Producer can't overwirte data before it's consumed
rcvi≤sendi+1
//shared memorychar buffer[BUFFER_SIZE]; //shared buffersemaphore chars= 0, space = BUFFER_SIZE;semaphore mutex = 1; //mutual exclusion
//waitvoid wait() {while(n<=0); //Stalln = n - 1;}//signalvoid signal() {n = n + 1;}
//Producer Processvoid Produce(char c) {wait(space); // wait for empty spacewait(mutex); // mutual exclusion from other process to enter the CSbuffer[in] = c;in = (in + 1) % BUFFER_SIZE;signal(mutex); // allow other to enter the CSsignal(chars); // add 1 char to the buffer}
//Consumer Processchar Consumer() {wait(chars); // check if there's enough char to consumewait(mutex);char c = buffer[out];out = (out + 1) % BUFFER_SIZE;signal(mutex);signal(space); // empty one spacereturn c;}```Thread in Java--<div class="md-section-divider"></div>```javaclass ThreadDemo extends Thread {public void run() {/******/}public static void main(String[] args) {Thread t = new ThreadDemo();t.start();}
2.
class ThreadDemo implements Runnable {public void run() {/******/}public static void main(String[] args) {ThreadDemo d = new ThreadDemo();Thread t = new Thread(d);t.start();}
Differerence between
run()andstart(),an overriding example?
class A implements Runnable {public void run() {System.out.println(Thread.currentThread().getName());}}class B implements Runnable {public void run() {new A().run();new Thread(new A(), "name_thread2").run();new Thread(new A(), "name_thread3").start();}}public class Main {public static void main(String[] args) {new Thread(new B(), "name_thread1").start();}}
output:
===========
name_thread1
name_thread1
name_thread3
===========
The difference between new Thread(new A(),"name_thread2").run(); and new Thread(new A(),"name_thread3").start(); is that the
start() method creates a new Thread and executes the run method in that thread. If you invoke the run() method directly, the code in run method will execute in the current thread. This explains why the code prints two lines with the same thread name.
synchronized is used to prevent concurrency. synchronized keyword can be applied to static/non-static methods or a block of code. Only one thread at a time can access synchronized methods and if there are multiple threads trying to access the same method then other threads have to wait for the execution of method by one thread. Synchronized keyword provides a lock on the object and thus prevents race condition. E.g.
public void synchronized method(){}public void synchronized staticmethod(){}public void myMethod(){synchronized (this){ // synchronized keyword on block of code}}
public class LockDemo implements Runnable {private int counter = 0;public void run() {int loopTimes = 10000;while (loopTimes > 0) {synchronized(this) {counter ++;}loopTimes --;}}public static void main(String[] args) throws InterruptedException {LockDemo demo = new LockDemo();Thread[] threads = new Thread[]{new Thread(demo), new Thread(demo),new Thread(demo), new Thread(demo),new Thread(demo)};for (Thread t : threads) {t.start();}for (Thread t : threads) {t.join();}System.out.println("demo's counter is " + demo.counter);}}
Examples in Lock
public class LockDemo implements Runnable {private int counter = 0;private final Lock lock = new ReentrantLock();public void run() {int loopTimes = 10000;while (loopTimes > 0) {try{lock.lock();counter ++;} catch (Exception e) {e.printStackTrace();} finally {lock.unlock();}loopTimes --;}}public static void main(String[] args) throws InterruptedException {LockDemo demo = new LockDemo();Thread[] threads = new Thread[]{new Thread(demo), new Thread(demo),new Thread(demo), new Thread(demo),new Thread(demo)};for (Thread t : threads) {t.start();}for (Thread t : threads) {t.join();}System.out.println("demo's counter is " + demo.counter);}}
The difference between
Lockandsynchronizedkeywords in Java
Lock implementations provide more extensive locking operations than can be obtained using synchronized methods and statements. They allow more flexible structuring, may have quite different properties, and may support multiple associated Condition objects.
...
The use of synchronized methods or statements provides access to the implicit monitor lock associated with every object, but forces all lock acquisition and release to occur in a block-structured way: when multiple locks are acquired they must be released in the opposite order, and all locks must be released in the same lexical scope in which they were acquired.
While the scoping mechanism for synchronized methods and statements makes it much easier to program with monitor locks, and helps avoid many common programming errors involving locks, there are occasions where you need to work with locks in a more flexible way. For example, **some algorithms* for traversing concurrently accessed data structures require the use of "hand-over-hand" or "chain locking": you acquire the lock of node A, then node B, then release A and acquire C, then release B and acquire D and so on. Implementations of the Lock interface enable the use of such techniques by allowing a lock to be acquired and released in different scopes, and allowing multiple locks to be acquired and released in any order.
With this increased flexibility comes additional responsibility. The absence of block-structured locking removes the automatic release of locks that occurs with synchronized methods and statements. In most cases, the following idiom should be used:
...
When locking and unlocking occur in different scopes, care must be taken to ensure that all code that is executed while the lock is held is protected by try-finally or try-catch to ensure that the lock is released when necessary.
Lock implementations provide additional functionality over the use of synchronized methods and statements by providing a non-blocking attempt to acquire a lock (tryLock()), an attempt to acquire the lock that can be interrupted (lockInterruptibly(), and an attempt to acquire the lock that can timeout (tryLock(long, TimeUnit)).
| Property | HashMap | HashTable | ConcurrentHashMap |
|---|---|---|---|
| Null values/keys | allowed | not allowed | |
| Is thread-safe | no | yes | |
| Lock Mechansim | not applicable | locks the portion of map | |
| Iterator | fail-fast | fail-safe |
