@happyforever
2018-08-01T01:06:49.000000Z
字数 17925
阅读 850
2018.7湖南培训
湖南培训
只写重点和课堂笔记
Day1
DFS
算法简要过程:对每一个可能的分支路径深入到不能再深入为止
一般用于图的遍历或枚举某个题目可能出现的各种情况
时间复杂度比较高
组成部分:
递归参数
结束条件(递归边界)
递归方式(例:f(i)=f(i-1)+f(i-2))
拓展延伸:回溯算法,记忆化搜索,最优性剪枝,可行性剪枝
每进入一个新的递归层都会产生新的临时变量消耗空间,显然深度较大的变量会先被销毁
这样的逻辑十分符合栈的定义,所以一般选择用栈来存储这些信息
windows系统下最多递归3w+层,linux下最多递归20w层
所以有时需要写手工栈
手工栈主要组成:
1、stack:手工栈。“手工栈”实际上就是这个数组,作为一个栈存储的是当前遍历到的所有点,模拟递归的过程。某一个点在栈内说明它并没有利用完成,某一个点已经出栈说明其所有的信息都已经利用过了。
2、cur:当前弧。与isap、dinic中的当前弧数组类似
3、use:有的递归过程在某一个点第一次遍历到的时候需要记录一些信息(比如dfs序等),这时需要用到标记数组判断当前点是否是第一次遍历到。
然后就可以用循环和手工栈代替递归了
-
经典模型:
全排列、求C(n,m)的各种情况、n皇后、迷宫
例题:
1.
定义:团是任意两点之间都有连边的点集
给定一个 n 个点,m 条边的无向图,求该图中最大团的点数。
解:
考虑设立F(i),表示只考虑标号$\ge i$的点所能构成的最大团的点数。
那么我们就可以从n到1依次枚举,假设枚举到i号点,我们可以强制选择i号点作为团中的点,然后从小到大依次枚举i号点所连向的编号大于i的点,选为团中的点,然后不断进行这样的操作,注意要保证当前选的点要和之前选的点都有连边才合法。
几个最优性剪枝
可以发现$F(i)\le F(i+1)+1$。因为每次只添加一个点,每次更新不可能把最大团的点数加2或更多。所以如果把F(i)更新为了F(i+1)+1,那么就可以直接退出(这已经是最好的情况了)。
如果当前深度是depth,最后一个枚举的点是u,设D(u)为编号大于u的且与u有连边的点的个数,那么如果$depth+D(u)\le F(i)$,那么显然这之后也肯定不可能会有更优的解(即使前面所有点和现在这个点连向的点能组成一个团,也不会比最优情况更优),直接退出。
假设当前深度是depth,最后一个枚举的点是u,如果$depth+F(u+1)\le F(i)$,那么这之后肯定不可能会有更优的解(跟上面原理相似),直接退出。
BFS
两种实现方式
1.基于队列的BFS
每次从存储状态取出队首,并枚举可能扩展出的状态,满足某种条件的话则加入队尾
举例:最短路、走迷宫、某状态到某状态的最短距离
有两种优化:判重、SLF优化
SLF优化:每次在队尾加入一个元素时,队尾和队首进行比较,如果队尾比队首更优(优劣根据题目来定),则将这个元素放到队首
优势:空间利用率高,常数小,可以很方便地记录一个状态的父状态
2.基于层次的BFS
每次枚举当前层次所有的后继状态,同意存储和更新,可以用于分层
举例:dinic或isap分层、黑白染色、求深度
一种优化:对于每个层次,可以在搜索之前对其状态进行预处理(排序、去重等)
优势:易于实现,可以很方便地得到每个状态的深度
- 折半搜索
一种显然的这种思想的利用是双向BFS
可以做那些“X步内搜到结果就输出步数,搜不到结果就输出……”的题目
前提是状态具有可逆性
不论是时间复杂度还是空间复杂度都会有极大的优化
例题:
有n个数字,问能否在这n个数字中选出某些数,使得这些数字的和等于k
n<=20?
n<=40?
解法:
考虑:加法是可逆的,其逆操作是减法
显然n<=20的时候可以枚举
n<=40的时候,把这n个数分成两组,分别记为X1,和X2
- 对于棋盘的状态
如果棋盘上的棋子有多种颜色,可以转换成与颜色数相关的进制数来存储(康托展开)
- 对于排列的状态
有些状态是数的排列,虽然可以直观地用n进制数进行存储,但是这样空间利用效率比较低,可以用康托展开来存储
比如8数码难题
康托展开:
$$X = a_1\times(n-1)!+a_2+a_2\times(n-2)!+\cdots+a_{n-1}+a_{n-1}\times 1!+a_0\times 0!*$$
二分答案
求什么什么的满足条件的最大(小)值。
如果x满足条件,那么所有$\le x$的值都满足条件;
如果x不满足条件,那么所有$\ge x$的值都不满足条件。
直接求答案比较不可做,但是检验一个答案是否满足条件又比较简单。
这样的话,就可以采用 “二分答案+检验” 的思路来解题。
算法大概流程:
先确定一个初始区间[l,r],保证答案在这个区间里面。
检验mid=(l+r)/2,如果满足条件,则令r=mid,否则l=mid。
重复以上过程,直到l==r-1退出,如果l满足条件,则答案是l,否则是l+1。
01分数规划
有一类题目是涉及到最优比率问题的。
比如说,给n个物品,要从中选k个物品出来,每一个东西有一个价值vi,一个权重xi,一个代价wi,那么我们选出来的东西的比率就是$\frac{\sum_{i为选中物品的编号}(x_iv_i)}{\sum_{i为选中物品的编号}(x_iw_i)}$。
然后题目一般会给选东西的方式加以限制,最后问你能选出的最大的比率。
面对这种问题,我们可以二分答案,假设答案是L,那么就把所有物品的价值重新定义为$v'_i=x_i(v_i-Lw_i)$,那么问题就变成是否能选出一些物品,并且满足 $\sum v'_i\gt 0$,这个一般来说都会比较好做
贪心
在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,他所做出的是在某种意义上的局部最优解。
贪心算法不是对所有问题都能得到整体最优解,关键是贪心策略的选择,选择的贪心策略必须具备无后效性,即某个状态以前的过程不会影响以后的状态,只与当前状态有关。
基本思路:
从问题的某一初始解出发;
while(能朝给定总目标前进一步)
利用可行的决策,求出可行解的一个解元素;
由所有解元素组合成问题的一个可行解;
只有当局部最优可以保证全局最优的时候,贪心才可能正确
例题:
有n支队伍参加比赛。。。
n<=10 直接枚举各种组合
n<=20 记录每个队伍被那支队伍打败过
正解:
根据鸽笼定理,胜利场次最多的队伍胜利场次一定大于或等于$\frac{n}{2}$
所以每次搜索可以将队伍数量减半,那么最后答案一定小于$\log_2n$
那么只需要搜索$\log_2n$次就行了
相当于加了一个最优性剪枝
时间复杂度就变成了$O(n^{\log_2n})$
Day2
动态规划
要素:
1.状态设立
动态规划过程中,需要存储的量为状态表示和最优化值
状态表示是对当前子问题的解的局面集合的一种充分描述
最优化值是对应状态集合下的最优化信息,最终可以通过它来直接或间接地得到答案
状态表示需要满足的性质:
①具有最优化子结构:问题的最优解能有效的从问题的子问题的最优解构造出来
②无后效性:后面产生的状态不会影响前面已有状态的决策
③简洁性:尽可能简化状态的表示,以获得更优的时间复杂度
2.状态转移
由于具有最优化子结构,所以求当前状态的最优值可以通过其他的状态的最优值加以变化从而求出
所以当一个状态的所有子结构都被计算过之后,就可以通过转移把这个状态的最优值求出
注意:状态的转移需要考虑到所有可能性!!!!
3.初始和边界状态
根据所设立的状态和对应的状态转移来规定其中的初始状态的值和不合法的状态
举例:
斐波那契数列
floyd算法中数组初始化
*
填表法就是推出前面的状态时主动更新后面的
刷表法是要推后面状态的时候找前面的状态来更新这个
动态规划各种类型
序列型
模型:给定一个序列,找出一个子序列,使得满足某种最优性或特殊性质。
例题:给定一个长为 n 的序列 A,求这个序列的最长上升子序列的长度。
状态设立:f[i]表示所有以 i 结尾的最长上升子序列的长度
状态转移:f[i]=$\max\{f[j]|j<i,A[j]<A[i]\}+1$,
特别地,$\max\{\varnothing\}$定义为0
初始条件:$f[0]=0$
for(int i=1;i<=n;++i){int Max=0;for(int j=1;j<i;++j)if(A[j]<A[i]&&Max<f[j])Max=f[j];f[i]=Max+1;}
区间型
例题:有n堆石子排成一列,每堆石子有一个重量w[i],每次合并可以合并相邻的两堆石子,一次合并的代价为两堆石子的重量和w[i]+w[i+1]。问安排怎样的合并顺序,能够使得总合并代价达到最小。
状态设立:设f[i][j]表示将[i,j]区间内的石子合成一个所需要的最小代价
状态转移:f[i][j]=Sum[j]–Sum[i-1]+min{f[i][k]+f[k+1][j]|i<=k
边界条件:f[x][y]=0(x>y)
初始条件:f[i][i]=wi
for(int len=1;l<=n;++l)//枚举区间长度for(int r,l=1;l+len-1<=n;++l)//枚举区间左端点{r=i+len–1;f[l][r]=INF;for(int k=l;k<r;++k) // 枚举分界点f[l][r]=min(f[l][r],f[l][k]+f[k+1][r]+Sum[r]-Sum[l-1]);}
棋盘型
在一个二维载体上进行的动态规划
例题:给一个n*m的01棋盘,即棋盘上的每一个格子非0即1。现在从(1,1)出发,每次只能往右或者往下走一步,走一步的代价等于这一步涉及的两个格子的值异或。问从(1,1)走到(n,m)的最小代价。
状态设立:f[i][j]为从(1,1)走到(i,j)的最小代价
状态转移:f[i][j]=min(f[i][j-1]+(A[i][j]!=A[i][j-1]),f[i-1][j]+(A[i][j]!=A[i-1][j]))
边界条件:$f[x][y]=+\inf (x<1||x>n||y<1||y>m)$
初始条件:f1=0
// 边界条件for(int i=1;i<=n;++i)f[i][0]=INF;for(int j=1;j<=m;++j)f[0][j]=INF;// 状态转移for(int i=1;i<=n;++i)for(int j=1;j<=m;++j)if(i==1&&j==1)f[i][j]=0;// 初始条件else f[i][j]=min(f[i][j-1]+(A[i][j]!=A[i][j-1]),f[i-1][j]+(A[i][j]!=A[i-1][j]));answer = f[n][m];
树型
两种模型:
1.子树型
给一棵n个点的树,以1号点为根,求以每个点为根的子树大小。
状态设立:记f[u]表示u点的子树大小
状态转移:$f[u]=1+\sum_{fa[v]==u}f[v]$
初始条件:叶子节点的f值记为1。
2.链型
给一棵n个点的树,以1号点为根,求以每个点为根向下最深的链。
状态设立:记g[u]表示u点为根向下最深的链
状态转移:$g[u]=1+\max\{g[v]|fa[v]==y\}$
初始条件:叶子节点的g值记为1
void dfs(int now,int fa){size[now]=max[now]=1;for(int v,i=head[now];i;i=edge[i].nxt){v=edge[i].v;if(v==fa)continue;dfs(v);size[now]+=size[v];Max[now]=max(Max[now],Max[v]);}}
数位型
给定一个[L,R]的范围,求这个范围内满足某个条件的数的个数。
例题:给定L,R,k,求[L,R]中数码和为k的数的个数。
首先可以把[L,R]拆成[1,R]-[1,L-1],那么问题就变成考虑[1,n]范围的了。
状态设立:记f[i][j][0/1]表示从高到低考虑到第i位,数字和为j,当前数字是/否卡住上界的情况数
这里的0/1表示的是/否卡上界 在转移的时候起到作用:如果当前数字卡到上界,那么下一个数码不能比R对应的数码大,否则就超出[1,R] 范围了;如果当前数字没有卡到上界,那么下一个数码的取值则不受限制
状态转移有两种情况(记w[i]为R的第i位的数码):
f[i][j][0]->f[i-1][j+(0~9)][0],f[i][j]2->f[i-1][j+(0~w[i-1])][j==w[i-1]]
初始条件:f[sz+1][0]1=1
int L,R,k,sz,f[MAXW][MAXK][3],w[MAXW];...//求出R的位数sz以及w[i]f[sz+1][0][1]=1;for(int i=sz+1;i>1;--i)for(int j=0;j<=k;++j){for(int x=0;x<=w[i-1]&&x+j<=k;++x)f[i-1][x+j][0]+=f[i][j][0];for(int x=0;x<=9&&x+j<=k;++x)f[i-1][x+j][x==w[i-1]]+=f[i][j][4];}ans =f[1][k][0]+f[1][k][5];
状态压缩
把某种实际的状态抽象成一个数字,然后用实际状态之间的关系进行转移。
例题:给定n(n<=17)个正整数ai,问是否可以找到一组1~n的排列,使得相邻两个数之和均为质数
首先,可以用[0,2^n-1]这2^n个数字来表示n个数字的选择情况,所以可以记f[S][x]表示当前的排列用了S(S是一个[1,2^n-1]的数字)所对应的数字集合,并且排列的最后一个数字是x的阶段可行性(x$\in$S)
状态转移:$f[S][x]|=(f[S-{x}][y] \&\& IsPrime(ax+ay))(x\ne y;x,y\in S)$
初始条件:$f[{i}][i]=1$
int n,f[1<<MAXN][MAXN],a[MAXN];...//读入,a[]从0开始标号for(int s=1;s<(1<<n);++s)for(int x = 0; x < n; x ++)if((s>>x)&1){if(s==(1<<x))//s只有x一个元素f[s][x]=1;elsefor(int y=0;y<n;++y)if(x!=y&&((s>>y)&1))f[s][x]|=f[s^(1<<y)][y]&IsPrime(a[x]+a[y]);}int ans=0;for(int i=0;i<n;++i)ans|=f[(1<<n)-1][i];
时间复杂度:$O(2^n\times n^2)$
DAG上动态规划
本质上,每一个类型的动态规划都是某个特殊的DAG上的动态规划,每一个状态对应图中的一个点,每一个转移式也对应着一条边
例题:给定一个 DAG,求出每个点u的SG函数sg(u)=mex{sg(v)|u->v}
其中mex(S)定义为最小的没有在S中出现的非负整数
状态设立:记f[u]为点u的SG函数值。
状态转移:f[u]=mex{f[v]|u->v}
初始条件:f[x]=0(x无后继节点)
int n,f[MAXN],Tag[MAXN];void dfs(int now){for(int v,i=head[now];i;i=edge[i].nxt)if(f[v=edge[i].v]!=-1)dfs(v);//先把后继的SG函数值全部求出来再集中处理for(int v,i=head[now];i;i=edge[i].nxt)Tag[f[edge[i].v]]=x;for(f[x]=0;Tag[f[x]]==x;++f[x]);}void CalcSG(){memset(f,-1,sizeof f);for(int i=1;i<=n;++i)if(f[i]==-1)dfs(i);}
DP优化
矩阵优化
如果在状态转移中,f[i+1]可由f[k]*M得到,其中M是转移矩阵,也就是转移式的矩阵形式,并且M不随i的变化而变化,即f[t]=f[0]*M^t,那么就可以用快速幂的思想先把$M^t$求出来,然后再算$f[0]\times(M^t)$
以上思想可以拓展到其他满足结合律的矩阵运算中。
设f[i+1]是n*m的矩阵,M是m*m的矩阵,那么整个算法时间复杂度将从原来的$O(tnm^2)$变成$O(m^3\log t)$,在t比较大的时候效果拔群
struct Rec{int r,c,num[MAXN][MAXN];Rec operator*(const Rec& a){Rec res;res.r=r,res.c=a.c;for(int i= 0;i<res.r;++i)for(int j=0;j<res.c;++j){res.num[i][j]=0;for(int k=0;k<c;++k)res.num[i][j]+=num[i][k]*a.num[k][j];}return res;}};
举例:计算fibonacci数列的第n项,对p取模。
矩阵设计:F[i]=[fib[i],fib[i+1]],M=[[0,1][1,1]],可知F[i+1]=[fib[i+1],fib[i+2]];
练习题:有一个2*n的地板,每一块地板都可以选择贴地砖或者不贴,问有多少种给地板贴地砖的方法,使得整个地板中不存在全贴了地砖的2*2的小正方形
矩阵设计:F[i]=[00,01,10,11],M=[[1,1,1,1][1,1,1,1][1,1,1,1][1,1,1,0]]
其中0/1表示地板 没有/有 贴地砖
实际上00,01,10三种状态是等价的,故可以进行进一步的压缩:
F'[i]=[非11,11],M'=[[3, 1] [3, 0]]
最后的答案就是 F'[n][0]+F'n
前缀优化
在状态转移中,如果每个状态是从连续的一段前置状态转移得到,那么可以用前缀和之差的处理方式来降低转移的复杂度
例题:求长为n,逆序对个数为k的排列个数。
记f[i][j]为长为i,逆序对个数为j的排列个数,朴素的转移方法是枚举第i个数在前i个数中的排名,然后可以得出把i加进来之后逆序对所增加的个数
转移:$f[i][j]=\sum_{x=0}^{i-1}f[i-1][j-x]$
初始:f[0][0]=1
可以看到转移状态是连续的,所以可以记$Sum[i][j]=\sum_{x=0}^{k}f[i][x]$
那么转移式可以写成:f[i][j]=Sum[i-1][j]-(j>=i?Sum[i-1][j-i]:0);
时间复杂度从原来的$O(nk^2)$降到了$O(nk)$
int n,k,f[MAXN][MAXK],Sum[MAXK];scanf(“%d%d”,&n,&k);for(int i=0;i<=k;++i)Sum[i]=1;for(int i=1;i<=n;++i){for(int j=0;j<=k;++j)f[i][j]=Sum[j]-(j>=i?Sum[j-i]:0);for(int j=0;j<=k;++j)Sum[j]=f[i][j]+(j?Sum[j-1]:0);}ans=f[n][k];
简单数据结构
离散化、树状数组、单调队列等
* 离散化
std::unique 返回值是个指针,重复的元素会放到原数组后面
这个指针指向的是在进行去重之后第一个重复出现的元素的位置
斜率优化:
是单调队列优化的一个拓展
例题:给三个长为n的序列 A,B,P,其中A是递增的序列。
你可以在{1,2,...,n}中选出一个子集S,其中规定必须有$n\in S$,记nxt[i]为S中大于等于i的数中最小的一个,定义S的价值为$\sum_{x\in S}{B_x}+\sum_{i=1}^n(A[nxt[i]]-A[i])*P[i]$,求S的最小价值。
状态设立:记f[i]为考虑了前i个数,且$i\in S$的情况中,当前的最小价值
状态转移:$f[i]=\min_{j=0}^{i-1}\{f[j]+\sum_{k=j+1}^i(A[i]-A[k])*P[k]\}+B[i]$
初始条件:f[0]=0
这样子时间复杂度是$O(n^2)$的。
考虑优化转移:
对于$0\le j1\lt j2\lt i$,如果j2转移到i要比j1转移到i更优,则:
$$f[j2]+\sum_{k=j2+1}^i(A[i]-A[k])\times P[k]\lt f[j1]+\sum_{j=k1+1}^i(A[i]-A[k])\times P[k]$$
记
$$SumP[i]=\sum_{x=1}^ip[x],SumAp[i]=\sum_{x=1}^iA[x]\times P[x]$$
则有
$$f[j2]+A[i]\times(SumP[i]-SumP[j2])-SumAp[i]+SumAp[j2]\lt f[j1]+A[i]\times(SumP[i]-SumP[j1])-SumAp[i]+SumAp[j1]$$
作差可得:
$$(f[j2]+SumAp[j2])-(f[j1]+SumAp[j1])-A[i]\times(SumP[j2]-SumP[j1])\lt 0$$
$$A[i]\gt \frac{(f[j2]+SumAp[j2])-(f[j1]+SumAp[j1])}{SumP[j2]-SumP[j1]}(SumP[j2]-SumP[j1]\gt 0,不等号方向不变)$$
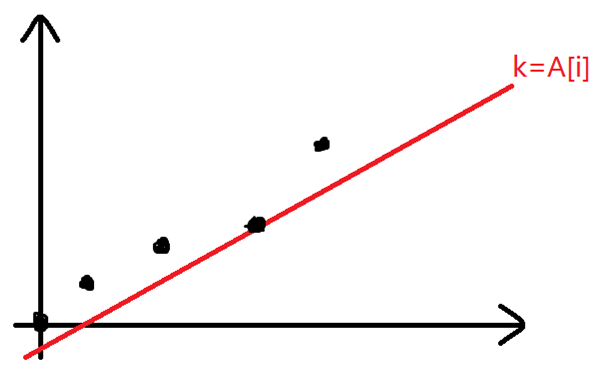
我们可以把每个i对应为一个平面坐标系上的点(SumP[i],f[i]+SumAp[i]),其中可以得知SumP[i],f[i]+SumAp[i],即点的坐标都是随着i的增大而增大的
那么对于f[i]的转移,就相当于要在0~i-1中选出一个点,使得经过这个点的斜率为A[i]的直线的纵截距最小(一条直线y=kx+b的纵截距为b)。
那么我们可以维护一个下凸壳,因为A[i]是递增的,即每次转移的斜率是递增的,所以最优的决策点在凸包内是单调的。
所以可以用队列来维护凸壳,每次把不优的队首弹出,加入队尾的时候按照维护凸包的方式来操作即可。
转移就从当前队首,即凸包上的最优决策点转移即可。
复杂度优化为:O(n)。
LL fz(int j1,int j2)//y坐标点{return f[j1]-f[j2]+sumAp[j1]-sumAp[j2];}LL fm(int j1,int j2)//x坐标点{return sumP[j1]-sumP[j2];}void work(){int head=0,tail=0;for(int i=1;i<=n;++i){while(head<tail&&fz(q[head+1],q[head])<=A[i]*fm(q[head+1],q[head]))//弹出不优的队首++head;//转移int j=q[head];f[i]=f[j]+B[i]+A[i]*(sumP[i]-sumP[j])-sumAp[i]+sumAp[j];while(head<tail&&fz(q[tail],q[tail-1])*fm(i,q[tail])>=fm(q[tail],q[tail-1])*fz(i,q[tail]))//把当前点i加入队尾,并维护凸壳--tail;q[++tail]=i;}}
凸壳
上凸壳是向上凸的凸包
下凸壳是向下凸的凸包
斜率:纵坐标之差除以横坐标之差
求上凸壳的代码
int st[N],tp;void convex_hull(Point *pnts)//存x坐标的数组{std::sort(pnts+1,pnts+n+1,cmp);for(int i=1;i<=n;++i){while(tp>1&&panduanxielv(st[tp-1],st[tp],pnts[i])--tp;st[++tp]=pnts[i];}
Day4
质数性质:
质数有无穷多个
$\pi(x)=\frac{x}{\ln x}$
每个数可以被唯一分解成一些质数的乘积
费马小定理:
如果p是质数并且$a%p\ne 0$,那么$a^{p-1}\equiv 1(\mod p)$
证明:
$1\times a,2\times a,\cdots ,(p-1)\times a$在$\mod p$之后是$[1,p-1]$的一个排列
$1\times 2\times\cdots\times p-1\equiv1a\times2a\times\cdots\times (p-1)a(\mod p)$
$1\equiv a^{p-1}(\mod p)$
狄利克雷卷积
定义函数f(n)和g(n)的狄利克雷卷积
$$(f\times g)(n)=\sum_{d|n}f(d)g(\frac n d)$$
性质:
交换律:f*g=g*f
结合律:f*g*h=(f*g)h=f(g*h)
分配律:f*(g+h)=f*g+f*h
两个积性函数的狄利克雷卷积仍然是积性函数.
例题:
给出数组f(n),k求:
$g(i)=\sum_{i_1|i}\sum_{i_2|i_1}\cdots\sum_{i_k|i_{k-1}}f(i_k)$
其中$n\le10^5,k\le10^9$
解:
可以发现$g=f*Id^k(1)$
由于狄利克雷卷积具有交换律,所以先快速幂求出$Id^k(1)$,然后与f进行卷积即可
复杂度$O(n\log n\log k)$
另一种解法:
考虑f(d)对g(a*d)的贡献显然只与a有关,记为h(a)
那么h为积性函数,$h(p^m)=\binom{m+k-1}{k-1}$
先算出所有$h(p^m)$,再筛出其他的h值,最后计算贡献
复杂度$O(n\log n)$
欧拉函数
积性函数
$\varphi(n)$为小于n且与n互质的正整数个数.
$\varphi(p^k)=(p-1)p^{k-1}$
性质:
如果a,b互质,那么$a^x\equiv a^{x\bmod\varphi(m)}(\mod m)$
$\sum_{d|n}\varphi(d)=n$
$\sum_{d<n,gcd(d,n)=1}d=\frac{\varphi(n)\times n}{2}$
莫比乌斯函数
$\mu(n)=\begin{cases}\ (-1^k),&n=p1\times p2\times p3\cdots\\ 0 &otherwidth\\ \end{cases}$
性质:
$\sum_{d|n}\mu(d)=[n=1]$
$\sum_{d|n}\mu(d)\times\frac{n}{d}=\varphi(n)$
$F(n)=\sum_{d|n}f(d)\Rightarrow f(n)=\sum_{d|n}\mu(d)\times F(d)$
$F(n)=\sum_{n|d}f(d)\Rightarrow f(n)=\sum_{n|d}\mu(d)\times F(n)$
概率和组合游戏
条件概率
记$P(A|B)$为在事件B发生的条件下, 事件A发生的概率.
Bayes公式:
$$P(A|B)=\frac{P(A)\times P(B|A)}{P(B)}$$
全概率公式:
$$P(A)=\sum P(A|B_i)\times P(B_i)$$
期望
随机变量是在概率空间的基本变量上定义的函数.
记E(X)为随机变量X的期望值
$$E(X)=\sum_{\omega\in\varOmega}P(\omega)X(\omega)$$
期望具有线性性:$$E(aX+Y)=aE(X)+E(Y)$$
必胜必败状态
前提条件:
- 双人游戏
- 双方轮流操作
- 双方都采取最优策略
- 信息公开
必胜状态指从当前状态开始操作,无论后手采取什么方式,先手都能存在必胜策略.
必败状态则相反.
必胜状态存在一个后继状态为必败状态.
必败状态的所有后继状态都是必胜状态.
这种方法很直观, 但是只能在状态数可接受的情况下使用, 有些时候也可
以用来分析
SG函数
设一个游戏的X的SG值为SG(X)=mex{SG(Y)|X通过一步操作可以转移到Y},一个游戏先手必败当且仅当它的SG值为0.
mex{S}为最小的没有出现在S中的自然数.
Theorem(SG定理)
由一些互不干扰的子游戏组成的游戏,它的SG值为所有子游戏SG值的异或和.
证明:
根据SG函数的定义,SG值为k的游戏可以转移到SG值为0到k−1的游戏(也可能转移到SG值大于k的游戏, 但是这样没有意义).
那么可以把一个子游戏看成一堆石子, 这样就和Nim游戏一样了
Day6
计数
容斥原理
$$|S_1\cup S_2\cup\cdots\cup S_n|=\sum|S_i|-\sum_{i\lt j}|S_i\cap S_j|+\sum_{i\lt j\lt k}|S_i+S_j+S_k|+\cdots+(-1)^n|S_1\cap S_2\cap\cdots\cap S_n|$$
子集DP
给出数列长度为$2^N$的数列f[x],求出$g[x]=\sum_{y\in x}f[y]$
要求复杂度$O(N\times 2^N)$
设h[i][S]为只有二进制第0到第i位与S不同的所有S子集的和.
初值h[−1][S]=f[S],答案g[S]=h[N][S]
$h[i][S]=h[i-1][S](S\&2^i=0)$
$$
Stiring数
第一类斯特林数
定义:$s(n,k)$表示把n个不同的元素划分成k个圆排列的方案数
递推公式:
$s(n,0)=0,s(1,1)=1$
$s(n,k)=s(n-1,k-1)+(n-1)s(n-1,k)$
解释说明:
考虑前n−1个物品已经分好了,第n个物品要么单独成为一个环,要么插在前n−1个物品中某个物品的后面
第二类斯特灵数
定义:$S(n,k)$为把n个不同的元素划分成k个集合的方案数
递推公式:
$S(n,n)=S(n,1)=1$
$S(n,k)=S(n−1,k−1)+k\times S(n−1,k)$
解释说明
考虑前n−1个数已经分好了,第n个数要么单独作为一个集合,要么和加入k个集合中的某一个
DP套DP
对于一个可以用DP解决问题,求有多少种输入使得这个问题的答案为A
在原DP的基础上暴力加上一维来记录每个状态的DP值,并统计这种情况下的方案数
Day7 数据结构
堆
例题:
给一个长度为n的序列,q次操作:
1.加入某个数 1 x
2.删除某个数 2 x
3.询问最值 3
解法:
如果加入、删除的是某个值,并且每次删除仅仅删除一个元素而不是所有等于x的元素都删除
开两个大(小)根堆q1,q2。
每次插入就把x往q1里面放,删除操作就把x往q2里面放
询问时查询q1,如果q1堆顶元素同时也是q2的堆顶元素,那么两个堆同时往外弹,直到两个堆顶元素不同
如果每次删除删掉所有等于x的值
询问时查询q1,如果q1堆顶元素同时也是q2的堆顶元素,那么q1往外弹,直到两个堆顶元素不同,q2比较堆顶元素和下一个元素是否相同(防止多次读入删除某个元素),不同则弹出堆顶元素
其他同上
- 可并堆
有斜堆和左偏树两种(当时只简单提到了左偏树,就只写左偏树了)
左偏树:
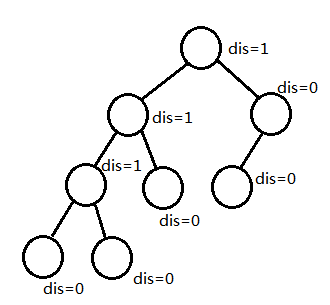
定义dis[p]为从p节点出发可以向右走的最大步数,若当前点的左儿子的dis值都比右儿子的dis值大,只要满足这个性质就是左偏树。
合并操作:
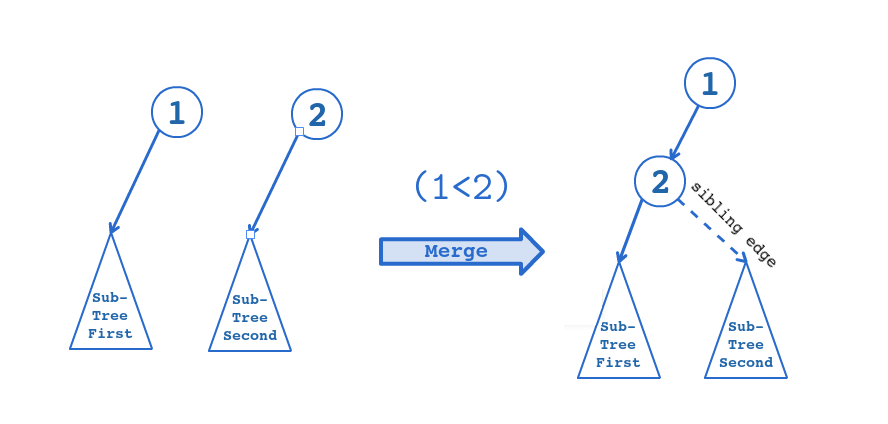
为了能保证时间复杂度,每一次合并都应该把新的节点放在当前的节点的右儿子上,这是一个递归的过程,每一次把当前的两个节点进行比较,留下权值大的点,然后递归下去把另一个点和留下的点的右儿子进行比较,如此下去,进行合并。当然每一次回溯之前,我们都需要判断当前节点的左右两个儿子的dis值,如果右儿子的dis值大于左儿子的dis值,则交换左右儿子。
int merge(int x,int y){if(!x)return y;if(!y)return x;if(num[x]>num[y])std::swap(x,y);son[x][10]=merge(son[x][11],y);if(dis[son[x][12]]>dis[son[x][0]])swap(son[x][13],son[x][0]);dis[x]=dis[son[x][14]]+1;return x;}//son[p][0]表示p号节点的左儿子//son[p][15]表示p号节点的右儿子//num[p]表示p号节点的权值
删除节点的话直接将这个节点的左右儿子合并即可
(类比fhq treap)
并查集
按秩合并:合并时把深度小的并到深度大的上面
路径压缩:如果只是用并查集来查询代表点,那么其实可以不用维护树形态的路径,直接把所有点都指向根即可。
树状数组
lowbit(x)表示的是x的二进制表示中最右边的1的位置
树状数组中第i个数表示的是从x开始向前lowbit(x)个数的$\times\times\times$
有时候在数组边界过大时,可以用hash表进行维护
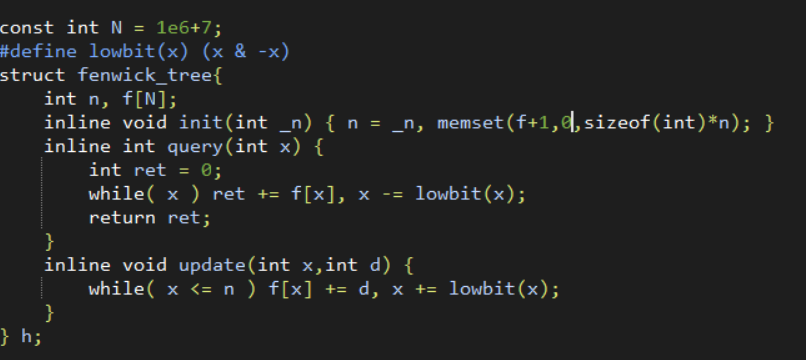
query(x) 处理的是询问数组到x处的前缀和。
update(x,d)处理的是,原数组x处的值加上d之后,树状数组对应的维护。
n是原数组的边界
平衡树
老师只讲了fhq treap,而且还不如xxy学姐讲得好。。。
直接贴上学姐博客吧
线段树
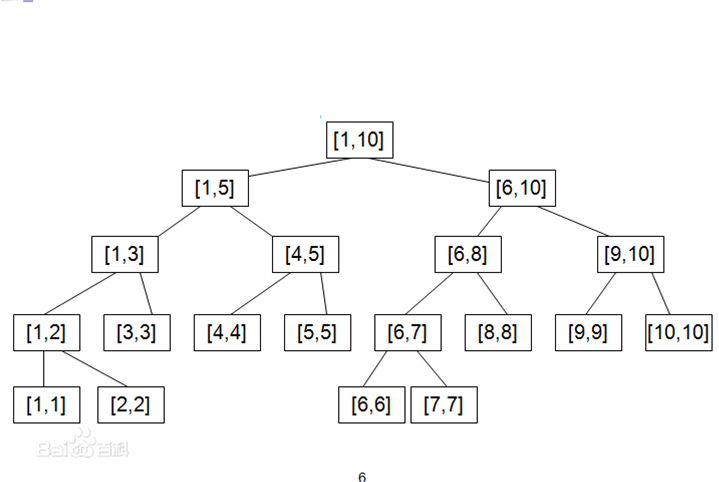
通过把一个区间沿中点不断划分成两个大小差不多的区间,形成了线段树的结构
其节点数大致是数组长度的两倍。
Day9 字符串
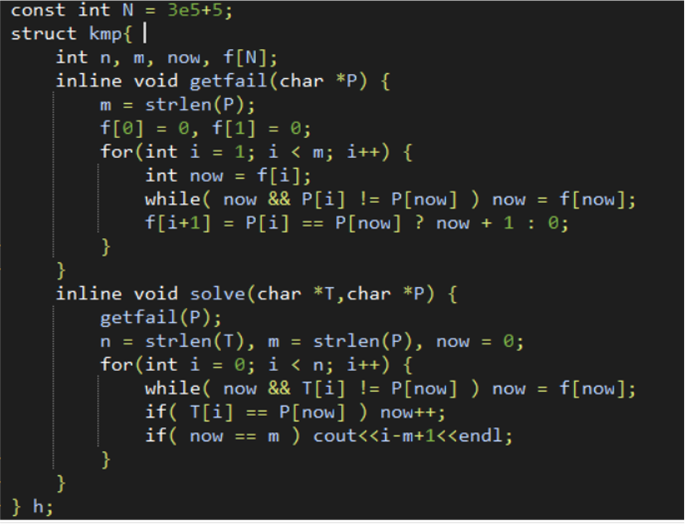
KMP
匹配串为s1,模板串为s2
通过对模板串进行预处理,在匹配过程中,充分利用上一次匹配的信息,将复杂度降至$O(N+M)(匹配串长度为N,模式串长度为M)$
nxt数组表示的是满足$s2[i-j\cdots i-1]=s2[0\cdots j-1]$的最大的j
Hash
考虑利用一个加密函数对字符串进行加密后得到一个数字
这个加密函数应该具有的性质:
①对于同一个字符串,每次加密得到的结果相同
②对于不同的字符串,加密得到的结果尽可能不同
通常情况下长度为N的字符串S进行加密的方式是设两个值K,P,然后令
$$f(S)=\sum_{i=1}^N S[i]\times K^{N-i}\mod P$$
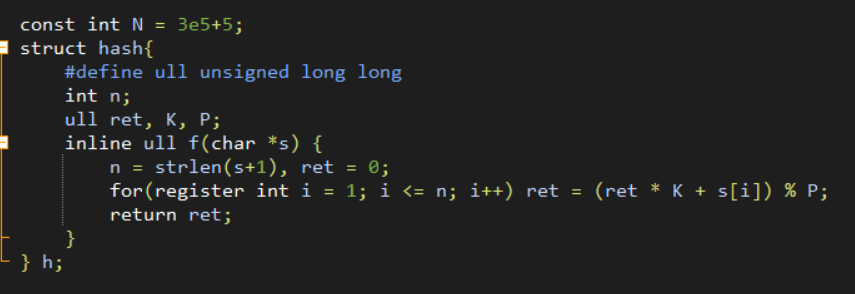
在实际应用中,我们通常是采用unsigned long long 自然溢出的方式来保存hash函数值(不用取模,速度较快),但是存在卡掉的方式
求回文串的长度
朴素算法:
枚举回文串的起点位置和长度,用hash判断是否相等
时间复杂度$O(n^2)$
简单的优化:
枚举回文串中心的位置,然后二分最大的长度,用hash判断是否合法
时间复杂度$O(n\log n)$
思想和KMP类似,也是充分利用之前获得的信息的利用价值,利用其回文串对称的特点进行优化
考虑维护之前处理到的回文串中往右延伸到的最远的位置mx和其对称中心pos,根据对称利用前面的信息更新后面的
时间复杂度O(n)
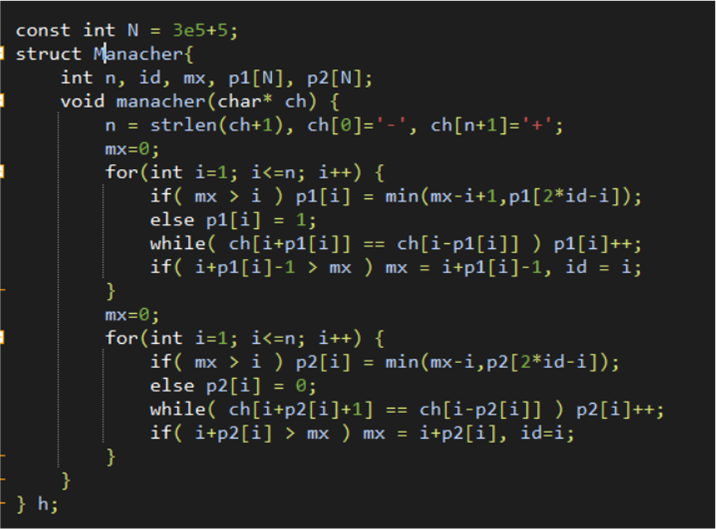
Trie树
一种树形数据结构,常用来维护字符串或者数字的二进制位的信息。
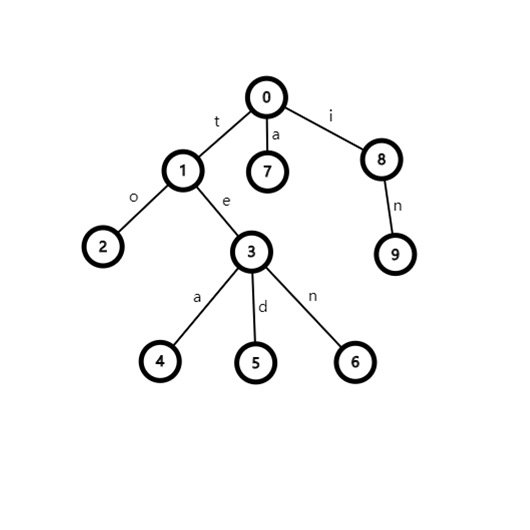
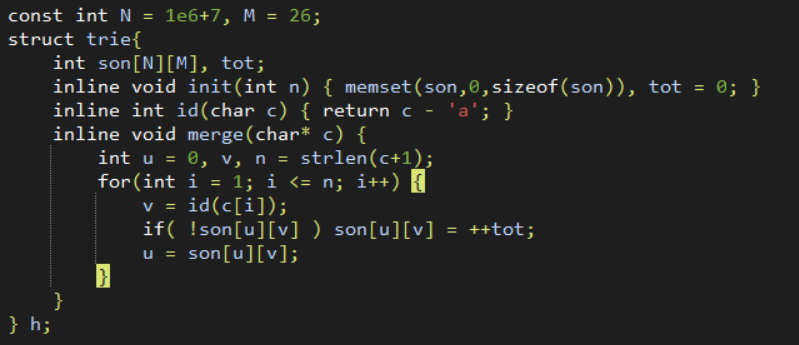
一般以0作为根节点的编号,因为trie是有根树,如果某条出边所到的节点是0,那么这个节点肯定不存在。
通常情况下会对每个节点开字符集大小的数组维护出边。
但是当空间不够的时候,可以考虑用hash(map)或者set进行维护压缩空间。
Day10
常识数据范围:$10^5$
二分
一个问题如果能够二分,那么这个问题一定具有某种意义上的单调性
如果不具有单调性,那么可以转化问题使之具有单调性
二分查找
给定一个有序表,求一个数字x是否在其中出现过;若出现过,求出x在有序表中最早出现的位置
斜率二分
通常用来解决一类“从n个中选k个”的问题
例题:
给定一个N个点M条边的图,其中每条边都有边权,并且要么是黑色要么是白色。求一个恰好包含K条白边的生成树,使得其权值之和最小
CDQ分治
一般用来解决三维偏序问题
例:给出n个点(x,y,z),请找出最长上升子序列,即对于选择序列中的i
输出最长上升子序列的长度
Solution:
假设按第一维的坐标排好序了,就需要在x排好序的点对(y,z)中找二维偏序.
因为之前已经排过序(x)了,所以直接再排序是有问题的(在这里可以写树套树维护但那玩意儿码量惊人。。。).
已经对x这一维排好序了,那么我们将[l,r]的点对分成两个区间[l,mid]和[mid+1,r]
然后依次递归调用,先处理[l,mid]的信息,然后处理[l,mid]对[mid+1,r]的影响,最后处理[mid+1,r]的信息
(为什么要这样?因为这道题是求三维lis,左边的区间会对右边的产生影响.)
继续刚才的分治:如果我们得到了两个区间的信息,就可以对第3维维护信息了。
时间二分
例题:
有N个物品每个物品有一个权值$W_i$和一个体积$V_i$,然后给出M次操作,每次操作会删除或添加一个物品,操作完成后会询问从中选出体积之和不超过P的若干物品,能获得的权值之和最大是多少
Solution
将时间建线段树,把每个物品的每个出现时间,打标记放到线段树的节点上。
遍历一遍线段树,只需要支持添加物品/还原背包即可。
同理还可以用这个思想动态维护联通块个数等
差分
定义一个序列$A$的差分序列$B_i=A_i-A_{i-1}$
通常用于简化时间复杂度
Day11图论专题
最短路
包括最短路,最短路树,最短路DAG,最短路性质,K短路
算法:Dijkstra,SPFA,bellman-ford(没什么卵用的算法),Floyd
应当说最短路问题在OI学中起到了从入门到劝退的作用
对于一道最短路题目,有三种增加难度的方法:
①出题人老老实实藏题型
(藏图的元素或藏图的有用的边)
②出题人抖机灵找性质型
③出题人很毒瘤套数据结构
例题:
给定一个N个点M条边的无向图,定义一条路径$e_1,e_2,\cdots,e_i$的权值为$e_1+\max(e_1,e_2)+\max(e2,e3)+\cdots+\max{e_{i-1},e_i}+e_i$
求从S到T的权值最小的路径权值是多少
解:
不难发现状态数是$O(M)$的(也可以看做是把边当成了点)
只需要在边和边之间快速连边即可
例题2
平面直角坐标系上有N个点,第i个点的坐标为$(X_i,Y_i)$定义两个点之间的距离为横纵坐标差的较小值
求1号点到N号点的最短路
解:
可以发现,很多边都是没有用的
横纵坐标分别排序后,相邻的点之间连边,直接最短路即可
Tarjan
提供了一种能够在有向图和无向图中找到所有联通分量的方法
- 什么时候需要求强联通分量
对于有向图来说,如果找到了一种在DAG上的做法,并且在有环的图上很难做,可以缩一下,这样剩下的就是DAG了,也许就可以用上刚刚那个做法
对于无向图来说,一般题目都会给暗示,或者自己推出的性质会用到这一点
一般来讲分析出这道题目是否需要缩点才是题目难点所在,算法本身反而不是什么问题
例题:
求有多少N个点的强联通图,$N\le 1000$
Solution
容斥+递推
对于一个有向图来说,如果不是强连通的,在缩完强连通分量之后,一定是一个DAG的形式
对于一棵树来说,如果不是边双联通的,在缩完边双联通分量之后,一定是一棵树的形式
2-SAT
生成树
Prim和Kruskal其实是等价的(蛤)
(除了这两个之外还有一些玄学的最小生成树算法,参见goodbye yiwei的题解)
例题:
给出一个N个点M条边的无向图,每一个点有一个颜色,边有一个边权。给出Q个操作,每次操作会改变一个点的颜色,或者询问边权最大的端点颜色不同的边的边权是多少
范围$3e5$
Solution
考虑特殊情况:给出的是一棵树,那么答案显然,只需要维护个大根堆就行了
实际给出的是图,答案只会出现在最大生成树上
维护最大生成树
二分图
一般棋盘问题都可以黑白染色转化成二分图
注意黑白染色的时候不要染错
- 二分图博弈
例题:bzoj1443游戏
一类博弈问题,基于以下条件:
1.博弈者人数为两人,双方轮流进行决策。
2.博弈状态(对应点)可分为两类(状态空间可分为两个集合),对应二分图两边(X集和Y集)。任意合法的决策(对应边)使状态从一类跳转到另一类。(正是由于这个性质使得问题可以用二分图描述)
3.不可以转移至已访问的状态。(不可重复访问点)
4.无法转移者判负。
这类问题相当于从二分图指定起点开始轮流移动,不可重复访问点,无法移动判负 。
现在问题变为从二分图指定起点开始轮流移动,不可重复访问点,无法移动判负。
不妨设起点在二分图的X集中,那么先手只能从X集移动到Y集,后手只能从Y集移动到X集。一次游戏过程对应一条路径。若最后停留在X集且无法移动则先手负,停留在Y集则后手负。
考虑该二分图的某个最大匹配。(注意可能存在多个匹配相同的最大匹配)
若起点$s\in X$不属于该最大匹配。则先手所转移到的点$y\in Y$一定属于最大匹配(否则s-y是一个匹配,与最大匹配矛盾)。后手沿着最大匹配的边走即可,终点t(指无法从t再走一步)一定不可能在Y集中(否则,若t在Y集中,$s-\cdots -t$为一增广路,与最大匹配矛盾)。因此先手必败,后手必胜。
若起点$s\in X$属于该最大匹配。则将s从图中删除,再求图的最大匹配。若最大匹配数不变,则s还是不属于某最大匹配,先手必败。否则该图的任意最大匹配都包含s,则先手沿着最大匹配的边走即可,根据上面的分析,先手必胜。
也就是说题目中按棋盘黑白染色构建二分图后,必胜点就是二分图中的所有的最大匹配非必要点。不能直接枚举。会超时。
首先,不构成最大匹配的点一定是非必要点。
其次,对不构成最大匹配的点出发走交错轨可以求出其他的非必要点。
网络流
常用最大流算法Dinic
费用流中常用算法Spfa,但是有Dijkstra版费用流
由于Dijkstra不能求解有负环的问题,所以某些人认为它不能用来求解费用流问题
* 合理性证明:
能够使用dijkstra算法的前提基于以下几个前提
1.在最小费用最大流中,任何结点对(u,v),始终只存在一个方向的流f,该方向要不是从u到v,要不是v到u。
2.在使用第一条方式求解最小费最大流算法时候,每次选择最小费用增广路径一定是当前残留图的最小增广路径。
3. 由于网络拓扑的费用和容量都是正值,而其反向边的存在是存在一定限制的,所以在网络中永远不可能有负环的存在。
解释:
对于第一点:如果一个结点对之间存在两个方向的流(对于无向图或有一对有向边的有向图),那么其一定不是最小费用最大流网络,因为在该结点对上的两个方向流是可以互相抵消的,肯定会存在一个两个方向互相抵消的更小费用的最大流网络。
对于第二点,在使用第一种方式的时候,每次选择的路径都必须是最小费用增广矩阵,这样才能保证我们最后得到的最小费用最大流网络
对于第三点,因为网络拓扑给的容量和费用都是正值,而只有当一条边有流量通过之后,才存在其反向边的概念,而其反向边的最用就是为了回流,其容量限制就是正向边的通过的流量,所以网络拓扑中不可能存在负环。
而dijkstra算法不能应用负权值网络是因为其使用的是贪心策略,所以导致对于有负权值的边有可能不会遍历。但是注意到所说到的前提2、3。负权值反向边出现的条件是在正向边有流量通过,且我们每次选择最小费用的增广路径。而正因为两个限制弥补了dijkstra算法贪心策略的不足。大家自己画画图就可以理解了,所以这里我就不画图说明。
因此,正因为以上两条限制,所以完全可以使用dijkstra替换spfa来寻找最小费用最大流网络。
证毕
上下界网络流
分为三种:
无源汇有上下界可行流(循环流)
有源汇有上下界可行流
有源汇有上下界最大流
中心思想是根据流量守恒进行拆边
博客
最小割最大流定理
指在一个网络流中,能够从源点到达汇点的最大流量等于如果从网络中移除就能够导致网络流中断的边的集合的最小容量和。即在任何网络中,最大流的值等于最小割的容量
常见高级网络流建模思想
1.二元费用问题
例题:文理分科
在N个小朋友之间,有M对同桌之间有小小的感情。在文理分科的时候,每个人选文科和理科各有一个喜悦值$A_i,B_i$,如果一对同桌同时选了文科,有一个额外的喜悦值$C_j$,同时选了理科有一个额外的喜悦值$D_j$,两个人选的科目不一样有一个负喜悦值$E_j$,求一种文理分科的方式使得总喜悦值最大
2.线性规划转费用流
例题:NOI2008志愿者招募
3.棋盘黑白染色
其实是把网格图转成二分图
例题:
给定一个网格图,有些格子上有障碍,需要用若干条回路不重不漏地覆盖所有没有障碍的格子,且使得拐点个数尽量多。
求拐点最多多少个
Solution
黑白染色转二分图,先考虑每个格子需要不重不漏地覆盖,其实就是所有黑色格子出度=白色格子入度=2,对应到二分图上就是每个点流量为2
再考虑拐点数尽量多,其实就是尽量避免一个点的连边方向相同。按照方向进行拆点即可
4.“切糕”型最小割
例题:HNOI2013 切糕
2142
