@jk88876594
2017-08-20T02:52:52.000000Z
字数 2989
阅读 3719
DataFrame——数据汇总
阿雷边学边教python数据分析第3期——pandas与numpy
一.分组计算
1.什么是分组计算?
以宠物小精灵数据集为例
#示例数据df = pd.read_csv("pokemon_data.csv",encoding="gbk")
小精灵会有多个分类,例如有火系的(Fire),或者是草系的(Grass)等等,那么分组计算就是指:将不同类别的小精灵归入到不同的组,例如火系的归一组,草系的归一组,这样我们就得到了很多个组,然后对这些组可以去实现不同的计算,例如求每一个组攻击力的平均值,这样我们就得到了每一个组它们自身组内的攻击力均值了。
2.如何分组计算?
分组计算用到的一个重要函数就是groupby
groupby分组计算流程:split——apply——combine
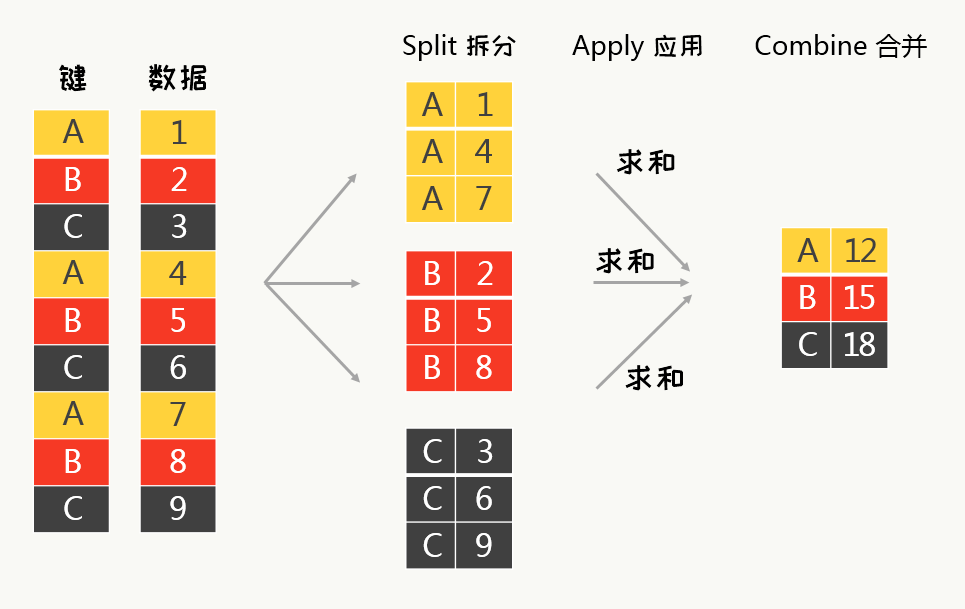
(1)split(拆分)
根据键对数据进行分组,常见的键类型有两种
- 根据列来分组
- 根据索引来分组
(2)apply(应用)
对每个组应用函数,类型有三种
- aggregation:聚合,对每个组计算统计值
- transformation:转换,对每个组进行特殊计算,例如在组内标准化数据
- filtration:过滤,对组进行条件过滤,根据条件判断得到的布尔值,丢弃掉一些组
(3)combine(合并)
将计算好的组整合到一个数据结构中
实例演练:
Q1:想知道类型1的这18个种类各自的平均攻击力是多少(单列分组计算)
#根据类型1这列来分组,并将结果存储在grouped1中grouped1 = df.groupby("类型1")#求类型1的18个种类各自的平均攻击力grouped1[["攻击力"]].mean()
小结一下:
grouped1 = df.groupby("类型1")
这一步就是分组计算流程里的第一步:split(通过类型1这列对数据进行了分组)grouped1[["攻击力"]].mean()
这一步就是分组计算流程的第二和第三步:apply(对每个组应用函数mean)—combine(将结果整合到了一个新的DataFrame里)
Q2:想知道类型1和类型2的组合类型里,每个组合各自的攻击力均值(多列分组计算)
grouped2 = df.groupby(["类型1","类型2"])grouped2[["攻击力"]].mean()
Q3:想知道类型1和类型2的组合类型里,每个组合各自的攻击力均值、中位数、总和(对组应用多个函数)
grouped2[["攻击力"]].agg([np.mean,np.median,np.sum])
Q4:想知道类型1和类型2的组合类型里,每个组合各自的攻击力的均值和中位数,生命值的总和(对不同列应用不同的函数)
grouped2.agg({"攻击力":[np.mean,np.median],"生命值":np.sum})
Q5:对组内数据进行标准化处理(转换)
zscore = lambda x : (x-x.mean())/x.std()grouped1.transform(zscore)
Q6:对组进行条件过滤(过滤)
需求:针对grouped2的这个分组,希望得到平均攻击力为100以上的组,其余的组过滤掉
attack_filter = lambda x : x["攻击力"].mean() > 100grouped2.filter(attack_filter)
Q7:将类型1和2作为索引列,按照索引来实现分组计算(根据索引来分组计算)
#将类型1、类型2设置为索引列df_pokemon = df.set_index(["类型1","类型2"])#根据索引分组grouped3 = df_pokemon.groupby(level=[0,1])#分组计算各列均值grouped3.mean()
3.组的一些特征
group.size()可以查看每个索引组的个数
grouped2.size()
group.groups 可以查看每个索引组的在源数据中的索引位置
grouped2.groups
group.get_group((索引组)) 得到包含索引组的所有数据
#得到索引组为Fire和Flying的所有数据grouped2.get_group(('Fire', 'Flying'))
4.组的迭代
for name,group in grouped2:print(name)print(group.shape)
二.数据透视表
1.数据透视表pivot_table
#示例数据df_p = df.iloc[:10,0:6]
#做一些修改df_p.loc[0:2,"姓名"] = "A"df_p.loc[3:5,"姓名"] = "B"df_p.loc[6:9,"姓名"] = "C"df_p["类型2"] = df_p["类型2"].fillna("Flying")df_p.rename(columns={"姓名":"组"},inplace=True)df_p
#将组放在行上,类型1放在列上,计算字段为攻击力,如果没有指定,默认计算其均值df_p.pivot_table(index="组",columns="类型1",values="攻击力")
#将组放在行上,类型1放在列上,计算攻击力的均值和计数df_p.pivot_table(index="组",columns="类型1",values="攻击力",aggfunc=[np.mean,len])
#将组和类型1放在行上,类型2放在列上,计算攻击力的均值和计数df_p.pivot_table(index=["组","类型1"],columns="类型2",values="攻击力",aggfunc=[np.mean,len])
#将组和类型1放在行上,类型2放在列上,计算生命值和攻击力的均值和计数df_p.pivot_table(index=["组","类型1"],columns="类型2",values=["生命值","攻击力"],aggfunc=[np.mean,len])
#将组和类型1放在行上,类型2放在列上,计算生命值和攻击力的均值和计数,并且将缺失值填充为0df_p1 = df_p.pivot_table(index=["组","类型1"],columns="类型2",values=["生命值","攻击力"],aggfunc=[np.mean,len],fill_value=0)
#将组和类型1放在行上,类型2放在列上,计算生命值和攻击力的均值和计数,将缺失值填充为0,并且增加总计行列df_p.pivot_table(index=["组","类型1"],columns="类型2",values=["生命值","攻击力"],aggfunc=[np.mean,len],fill_value=0,margins=True)
2.重塑层次化索引
stack():将数据最内层的列旋转到行上
unstack():将数据最内层的行旋转到列上
#将数据最内层的列旋转到行上,也即是将类型2转移到行上df_p1.stack()
#将数据最内层的行旋转到列上,也即是将类型1转移到列上df_p1.unstack()
三.交叉表
crosstab
用于计算分组频率用的特殊透视表
#示例数据df_p
#计算组和类型1的交叉频率pd.crosstab(index=df_p["组"],columns=df_p["类型1"])