@liuximing
2018-04-10T18:18:25.000000Z
字数 1034
阅读 71
字符编码的那些事儿
Web
ASCII
ASCII是美国制定的一套字符编码,对英语字符与二进制位之间的关系做了统一规定。ASCII码一共规定了128个字符的编码(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的一位统一规定为0。
Unicode 和 UTF-8
Unicode希望将世界上所有的字符统一表示,最初也是最常用的UCS-2标准使用2个字节表示一个字符。(之后为了表示更多的字符,还提出了使用4个字节表示一个字符的UCS-4标准。)
举个🌰:汉字“刘”的Unicode编码是十六进制的5218。
更多中日韩汉字Unicode编码表
Unicode本质上只是一张码表,它只规定了字符和编码的对应关系,并没有规定编码的存储方式。而UTF-8做了这件事,也就是说UTF-8是Unicode的一种实现,并且是使用最广泛的一种。(如果直接按照Unicode的码位存储,就是UTF-16。)
UTF-8存储规则:
1)对于单字节字符,字节第一位都为0,规则同ASCII码;
2)对于n(n>1)字节的字符,第一个字节的前n位都为1,第n+1位为0,后面字节的前两位都为10。
| Unicode(十六进制) | UTF-8(二进制) |
|---|---|
| 0000 - 007F | 0xxxxxxx |
| 0080 - 07FF | 110xxxxx 10xxxxxx |
| 0800 - FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
举个🌰:汉字“刘”的Unicode编码是十六进制的5218(二进制的01010010 00011000),而它的UTF-8编码是二进制的11100101 10001000 10011000。
PHP中的编码
Python中的编码
Python的文件编码
Python 2.x默认使用ASCII进行文件编码,Python 3.x默认使用UTF-8进行文件编码。
Python 2.x要在代码中使用中文注释,就必须指定文件编码为UTF-8。
#/usr/bin/python# -*- coding: UTF-8 -*-
Python的系统编码
Python 2.x默认的系统编码也是ASCII:
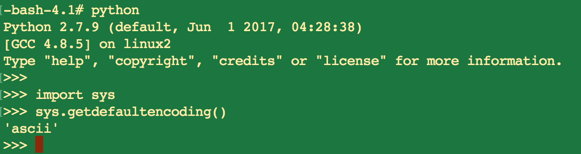
Python 3.x默认的系统编码也是UTF-8:
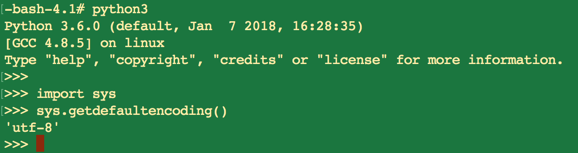
Python 2.x更改系统的默认编码:
import sysreload(sys)sys.setdefaultencoding('UTF-8')
