@maorongrong
2016-12-21T07:58:18.000000Z
字数 7970
阅读 1098
docker集群调度器
docker
参考
写的比较清楚的:容器时代,集群调度谁家强?
swarm参考:深入浅出Swarm,Docker集群的管理工具
K8s参考:Kubernetes初探
marathon参考:使用Mesos和Marathon管理Docker集群
marathon搭建参考:Marathon主要功能介绍(-)
Swarm、Fleet、Kubernetes、Mesos - 编排工具对比分析
docker三剑客
Machine
在没有Machine时,安装docker需要根据不同的OS使用不同的安装方法,配置文件也在不同的位置,流程复杂而且不简单方便。Machine就是解决的是操作系统异构安装Docker困难的问题。
有了Machine,所有的系统都是一样的安装方式,一个命令直接安装Docker引擎,这样就有了docker环境。
Swarm
Machine帮我们快速构建docker环境,但是那是单机的。Swarm管理docker集群,支持用户创建docker engine主机资源池,并提供docker集群环境和调度策略等。
有了Swarm,能够对集群调度管理,就有了docker 容器运行的资源池环境。
Compose
有了集群环境,下面就是部署应用,有时候就需要多容器组装应用,这个时候我们需要docker run image1、docker run image2 …,进行大量重复操作和配置。
Compose就是简化部署应用流程,只需要把命令参数固化到docker-compose.yml中,维护所有应用程序容器的逻辑定义以及它们之间的连接关系。
docker swarm
一套Docker Swarm架构由一个Swarm manager(运行Swarm daemon)和若干Swarm节点组成。用户只需跟Swarm manager通信,然后Swarm manager根据discovery service的信息选择一个Swarm节点来运行容器
details can find in swarm官方文档
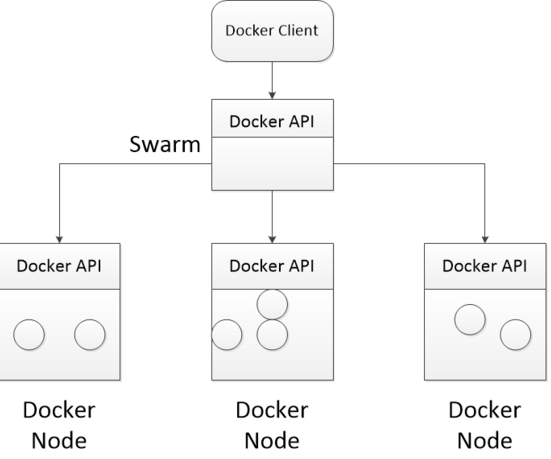
1.12版Docker Engine,最大的新特性是Docker Swarm已经被整合到了Docker Engine里面而不再是一个单独的工具了,这样就可以更容易的把多个Docker主机组合成一整个规模更大可靠性更高的逻辑单元.

具体的swarm架构:


通过所有Docker Node的状态以及具体信息,来筛选(filter)决策到底哪些Docker Node满足要求,并通过一定的策略(strategy)将请求转发至具体的一个Docker Node.
当Swarm Server被初始化并完成监听之后,用户即可以通过Docker Client向Swarm发送Docker集群的管理请求。
请求入口为Swarm Server,处理引擎为Scheduler,节点信息依靠Disocovery.
filter
Filters tell Docker Swarm scheduler which nodes to use when creating and running a container。
docker.com对于filter讲解
策略
策略有三个:
- spread: 默认策略,尽量均匀分布,找容器数少的结点调度(默认策略)
- binpack: 和spread相反,尽量把一个结点占满再用其他结点(当使用binpack策略时,必须指定资源的占用大小)
- random: 随机
修改Docker 1.12的代码把replica容灾的策略加到Swarm调度策略
新的Swarm调度算法和老Swarm差不多,不过不再提供策略选择,只提供了spread策略。
fleet
fleet 是通过systemd来控制集群的,控制的任务被称之为unit(单元),控制的命令是fleetctl。
Fleet是CoreOS的一个调度和集群管理组件。它从集群中etcd(CoreOS所使用的一个分布式key-value存储,用来创建分布式init系统)中读取每一个宿主机上的连接信息,然后提供systemd类似的服务管理。
fleet逻辑框架

每个机器运行一个引擎和一个代理,任何时候在集群中只激活一个引擎,但是所有代理会一直运行,Systemd单元文件被提交给引擎,然后在least-loaded机器上调度任务,单元文件会简单运行一个容器,代理会启动单元和报告状态,Etcd用来激活机器间的通讯以及存储集群和单元的状态。
单元的调度可以是全局的:一个实例将在所有机器上运行,或者作为一个单独的单元运行在一台机器上。全局调度对于如日志和监控容器任务非常实用。
fleet工作方式
unit文件定义了你要在集群中跑的服务。可以想成它就是fleet管理应用的方式
通过fleet运行一个服务,需要几个必要的步骤:
1. 上传单元配置文件
2. fleet读取单元配置文件
3. fleet安排load单元配置文件去机器上run,涉及到scheduling: fleet不是一个具有资源意识的调度器,调度时fleet并不将诸如CPU和内存等可用的系统资源纳入考虑范围,fleet会判断哪个节点目前运行的单元文件最少,然后将下一个单元文件调向该节点.
4. start在目标主机上启动该单元服务。
marathon
是Mesosphere的一个调度和服务管理组件。它配合mesos来控制长时间运行的服务,并为进程和容器管理提供Web界面。
mesos
Apache mesos是一个抽象和管理集群中所有宿主资源的工具:能够在同样的集群机器上运行多种分布式系统类型,更加动态有效率低共享资源。提供失败侦测,任务发布,任务跟踪,任务监控,低层次资源管理和细粒度的资源共享,可以扩展伸缩到数千个节点。提供双层调度,即调度容器集群,也可以调度application自己调度器.eg. Hadoop。
- Mesos架构

mesos 被称为是分布式系统的内核.
执行器是一个docker容器:

- Mesos主从服务器调度资源的顺序图如下

首先由Mesos主服务器查询可用资源给调度器,第二步调度器向主服务器发出加载任务,主服务器再传达给从服务器,从服务器向执行器命令加载任务执行,执行器执行任务以后,将状态反馈上报给从服务器,最终告知调度器 。
- mesos两级调度架构

Mesos实现了两级调度架构,它可以管理多种类型的应用程序。第一级调度是Master的守护进程,管理Mesos集群中所有节点上运行的Slave守护进程。集群由物理服务器或虚拟服务器组成,用于运行应用程序的任务,比如Hadoop和MPI作业。第二级调度由被称作Framework的“组件”组成。Framework包括调度器(Scheduler)和执行器(Executor)进程,其中每个节点上都会运行执行器。Mesos能和不同类型的Framework通信,每种Framework由相应的应用集群管理。上图中只展示了Hadoop和MPI两种类型,其它类型的应用程序也有相应的Framework。
Mesos Master协调全部的Slave,并确定每个节点的可用资源,
聚合计算跨节点的所有可用资源的报告,然后向注册到Master的Framework(作为Master的客户端)发出资源邀约。Framework可以根据应用程序的需求,选择接受或拒绝来自master的资源邀约。一旦接受邀约,Master即协调Framework和Slave,调度参与节点上任务,并在容器中执行,以使多种类型的任务,比如Hadoop和Cassandra,可以在同一个节点上同时运行
Marathon
它是一个mesos框架,能够支持运行长服务,比如web应用等。是集群的分布式Init.d,能够原样运行任何Linux二进制发布版本,如Tomcat Play等等,可以集群的多进程管理。也是一种私有的Pass,实现服务的发现,为部署提供提供REST API服务,有授权和SSL、配置约束,通过HAProxy实现服务发现和负载平衡。
Kubernetes
k8s逻辑图

- Pod
pod包含containers,逻辑上表示某种应用的一个实例。比如一个web站点应用由前端、后端及数据库构建而成,这三个组件将运行在各自的容器中,那么我们可以创建包含三个container的pod。
Pod是Kubernetes的基本操作单元,把相关的一个或多个容器构成一个Pod,通常Pod里的容器运行相同的应用。Pod包含的容器运行在同一个Minion(Host)上,看作一个统一管理单元,共享相同的volumes和network namespace/IP和Port空间
- service
service是pod的路由代理抽象,用于解决pod之间的服务发现问题。因为pod的运行状态可动态变化(比如切换机器了、缩容过程中被终止了等),所以访问端不能以写死IP的方式去访问该pod提供的服务。service的引入旨在保证pod的动态变化对访问端透明,访问端只需要知道service的地址,由service来提供代理。
Services也是Kubernetes的基本操作单元,是真实应用服务的抽象,每一个服务后面都有很多对应的容器来支持,通过Proxy的port和服务selector决定服务请求传递给后端提供服务的容器,对外表现为一个单一访问接口,外部不需要了解后端如何运行,这给扩展或维护后端带来很大的好处。
- replication Controller
是pod的复制抽象,用于解决pod的扩容缩容问题。通常,分布式应用为了性能或高可用性的考虑,需要复制多份资源,并且根据负载情况动态伸缩。通过replicationController,我们可以指定一个应用需要几份复制,Kubernetes将为每份复制创建一个pod,并且保证实际运行pod数量总是与该复制数量相等(例如,当前某个pod宕机时,自动创建新的pod来替换)。
Replication Controller确保任何时候Kubernetes集群中有指定数量的pod副本(replicas)在运行, 如果少于指定数量的pod副本(replicas),Replication Controller会启动新的Container,反之会杀死多余的以保证数量不变。Replication Controller使用预先定义的pod模板创建pods,一旦创建成功,pod 模板和创建的pods没有任何关联,可以修改pod 模板而不会对已创建pods有任何影响,也可以直接更新通过Replication Controller创建的pods。对于利用pod 模板创建的pods,Replication Controller根据label selector来关联,通过修改pods的label可以删除对应的pods
- label
就是为pod加上可用于搜索或关联的一组key/value标签,而service和replicationController正是通过label来与pod关联的。如下图所示,有三个pod都有label为"app=backend",创建service和replicationController时可以指定同样的label:"app=backend",再通过label selector机制,就将它们与这三个pod关联起来了。例如,当有其他frontend pod访问该service时,自动会转发到其中的一个backend pod。
Pod、Service、 Replication Controller可以有多个label,但是每个label的key只能对应一个value。

k8s集群架构图

master运行三个组件:

apiserver:作为kubernetes系统的入口,封装了核心对象的增删改查操作,以RESTFul接口方式提供给外部客户和内部组件调用。它维护的REST对象将持久化到etcd(一个分布式强一致性的key/value存储)。
scheduler:负责集群的资源调度,为新建的pod分配机器。这部分工作分出来变成一个组件,意味着可以很方便地替换成其他的调度器。
Scheduler收集和分析当前Kubernetes集群中所有Minion节点的资源(内存、CPU)负载情况,然后依此分发新建的Pod到Kubernetes集群中可用的节点。由于一旦Minion节点的资源被分配给Pod,那这些资源就不能再分配给其他Pod, 除非这些Pod被删除或者退出, 因此,Kubernetes需要分析集群中所有Minion的资源使用情况,保证分发的工作负载不会超出当前该Minion节点的可用资源范围。具体来说,Scheduler做以下工作:
1) 实时监测Kubernetes集群中未分发的Pod。
2) 实时监测Kubernetes集群中所有运行的Pod,Scheduler需要根据这些Pod的资源状况安全地将未分发的Pod分发到指定的Minion节点上。
3) Scheduler也监测Minion节点信息,由于会频繁查找Minion节点,Scheduler会缓存一份最新的信息在本地。
4) 最后,Scheduler在分发Pod到指定的Minion节点后,会把Pod相关的信息Binding写回API Server。
controller-manager:负责执行各种控制器,目前有两类:
endpoint-controller:定期关联service和pod(关联信息由endpoint对象维护),保证service到pod的映射总是最新的。replication-controller:定期关联replicationController和pod,保证replicationController定义的复制数量与实际运行pod的数量总是一致的。Replication Controller主要有如下用法:
1) Rescheduling
Replication Controller会确保Kubernetes集群中指定的pod副本(replicas)在运行, 即使在节点出错时。
2) Scaling
通过修改Replication Controller的副本(replicas)数量来水平扩展或者缩小运行的pods。
3) Rolling updates
Replication Controller的设计原则使得可以一个一个地替换pods来rolling updates服务。
4) Multiple release tracks
如果需要在系统中运行multiple release的服务,Replication Controller使用labels来区分multiple release tracks。
slave(称作minion)运行两个组件:

- kubelet:负责管控docker容器,如启动/停止、监控运行状态等。它会定期从etcd获取分配到本机的pod,并根据pod信息启动或停止相应的容器。同时,它也会接收apiserver的HTTP请求,汇报pod的运行状态。
Master API Server和Minion之间的桥梁,接收Master API Server分配给它的commands和work,与持久性键值存储etcd、file、server和http进行交互,读取配置信息。Kubelet的主要工作是管理Pod和容器的生命周期,其包括Docker Client、Root Directory、Pod Workers、Etcd Client、Cadvisor Client以及Health Checker组件.
- proxy:负责为pod提供代理。它会定期从etcd获取所有的service,并根据service信息创建代理。当某个客户pod要访问其他pod时,访问请求会经过本机proxy做转发。
Proxy是为了解决外部网络能够访问跨机器集群中容器提供的应用服务而设计的,从上图3-3可知Proxy服务也运行在每个Minion上。Proxy提供TCP/UDP sockets的proxy,每创建一种Service,Proxy主要从etcd获取Services和Endpoints的配置信息,或者也可以从file获取,然后根据配置信息在Minion上启动一个Proxy的进程并监听相应的服务端口,当外部请求发生时,Proxy会根据Load Balancer将请求分发到后端正确的容器处理。
k8s调度策略
新增pod
- predicates
解决,能否将Pod调度到特定的Node上运行。
Predicates阶段包括五个调度策略:PodFitsPorts、PodFitsResources、NoDiskConflict、 MatchNodeSelector和HostName。
- Priorities
回答,哪个更适合的问题。
Priorities阶段包括三个调度策略:
1. LeastRequestedPriority(最少请求资源优先调度策略)(最主要)
尽量将需要新创建的Pod调度到计算资源占用比较小的Node上,这里的“计算资源”指 CPU 资源和Memory资源
2. ServiceSpreadingPriority(最小相同服务优先调度策略)
使同一个Node上属于相同服务的Pod数量尽量少,这样调度的 Pod能够尽可能地实现服务的高可用性和流量负载均衡
3. EqualPriority(平等优先调度策略)
算原则是平等对待Predicates阶段筛选出来的每一个可用 Node。
Kubernetes的调度器实现了插件化,用户可以开发自己的调度策略并以插件的形式集成到Kubernetes中,以便调度不同类型的任务。
docker容器怎么迁移的
来自:使用 Docker 部署和迁移多节点的 ElasticSearch-Logstash-Kibana 集群 的一段话:
老的:
"version": 1"nodes":"172.16.255.250": ["elasticsearch"]"172.16.255.251": ["logstash"]"172.16.255.252": ["kibana"]
新的:
"version": 1"nodes":"172.16.255.250": []"172.16.255.251": ["logstash"]"172.16.255.252": ["kibana"]"172.16.255.253": ["elasticsearch"]
这里说明了当你重新运行 flocker-deploy 从节点1去迁移 ElasticSearch 到节点2的时候发生了什么:
Flocker 检查是否你已经改变了你的配置
因为它看起来你好像已经从 172.16.255.250 移动 ElasticSearch 到 172.16.255.253 了,它初始化一个迁移
**迁移通过推送整个节点1的数据卷内容到节点2开始。在这个期间,节点1依然接受连接,因此你的用户或其他依赖于那些数据的进程不会感受任何连接问题
一旦所有的数据被拷贝完,运行在节点1的应用被关闭
数据被复制过来之后的任何对数据卷的改变这时将被复制,依赖于你的数据库多繁忙,这可能只是几百kb 的变化
一旦这些最后的少许改变被复制过来,Flocker 不干涉节点2的卷**
ElasticSearch 在节点2启动
我们称这个方式为 two-phase 推送,因为数据在两个阶段迁移。在第一阶段,也是时间最长的阶段,当数据卷被拷贝过来,数据库继续提供连接服务。它仅仅在第二阶段,应用程序会经历停机。我们正在积极地朝着一个世界,当应用运行在一个容器中,它们的数据可以在两台机器之间无缝迁移,甚至整个数据中心在一个基于虚机的世界灵活的移动。
