@rmokerone
2016-04-03T10:46:19.000000Z
字数 18283
阅读 598
Implementing our network to classify digits
ODOP
文章地址:
http://neuralnetworksanddeeplearning.com/chap1.html
实施我们的网络识别数字
来写一个程序去学习怎么使用随机梯度下降(stochastic gradient)和MNIST数据集去识别手写数字。我们使用一个仅仅74行程序的短小Python程序来做这件事。我们要做的第一件事是获取MNIST数据。如果你是git用户,你可以通过克隆本书的代码分支来获取的数据。
git clone https://github.com/mnielsen/neural-networks-and-deep-learning.git
如果你不使用git,你可以从这里下载数据.
顺便说下,当我在前面描述MNIST数据集时,我将它分成60000训练图像(training images)和10000测试图像(test images),这是MNIST的官方描述。实际上,我们分割数据有些不同。我们的测试图像是一样,但是将60000-MNIST训练数据分割为两个部分,一个50000图像,用来训练我们的神经网络,和一个10000图像的验证数据集(validation set)。在本章我们没有用到验证数据集,但在本书的后续部分,我们将发现在指示如何确定神经网络的假设(例如学习速率,等等,这些并不能由我们的算法直接选择的参数)时非常有用。尽管,验证数据并不是原始MNIST规格指定的一部分,但很多人都用这种方式,并且使用验证数据在训练神经网络中是非常流行的。从此往后当我提到“MNIST训练数据"是指我们的50000图像数据集,并不是原始的60000图像数据集。
除了MNIST数据集,我们为了做线性代数还需要一个Python库叫Numpy。如果你还没有安装Numpy,你可以从这里获取到。
在给出全部代码之前,让我先来解释下神经网路代码的核心特征(core feature)。重点是一个Network类,我们用来表示神经网络。下面的代码用来初始化Network对象:
class Network(object):def __init__(self, sizes):self.num_layers = len(sizes)self.sizes = sizesself.biases = [np.random.randn(y, 1) for y in sizes[1:]]self.weights = [np.random.randn(y, x)for x, y in zip(sizes[:-1], sizes[1:])]
在上述代码中,sizes列表包含了各个层中的神经元数目。例如,我们想创建一个第一层两个神经元,第二层三个神经元,最后一层一个神经元的Network对象。我们可以用如下代码:
net = Network([2, 3, 1])
Network对象中的偏置(biases)和权重(weights)均是使用Numpy库函数np.random.randn进行随机地初始化(期望为0标准差为1的随机高斯分布)。该随机初始化给我们的随机梯度下降(stochastic gradient descent)算法一个起始位置。在随后的章节我们将寻找更好对权重和偏置初始化的方法,但现在我们将用这种方法。记住,在Network初始化代码中我们假设第一层神经元是输入层(input layer),省略对该层神经元偏置的设置,即偏置仅仅在其他层神经元的输出计算中设置。
谨记,偏置和权重存储在Numpy的列表矩阵中。例如,Numpy矩阵net.weight[1]存储第二层和第三层神经元链接的权重(并不是第一层和第二层,因为Python列表类型的索引号从0开始)。显然net.weight[1]有点冗长,让我们使用矩阵来代替。例如一个矩阵表示第二层中第神经元和第三层中第神经元之间的链接权重。这和指示的次序看起来有些奇特,为什么不交换和的指示使看起来更舒适?这种用法的巨大优势是,它意味着第三层的神经元的激活向量可以表示为:
在这个公式中有相当多的事情,让我们一块一块来分解。是表示第二层神经元输入(activations)的向量。为了获取我们用矩阵乘上再加上偏置向量。我们将函数元素方式化(element wish)向量中的每项(这被称为矢量化函数)。和容易验证公式(22)和我们前面的公式(4)具有相同的结果(计算sigmoid神经网络的输出)。
练习
- 以组件的形式写出公式(22),并验证是否与公式(4)一样对sigmoid网络的输出具有相同的输出。
将这些记在脑海里,下面对Network输出的计算得程序编写就显得简单了。我们先来定义一个sigmoid函数:
def sigmoid(z):return 1.0/(1.0+np.exp(-z))
注意,当输入z是一个向量或者Numpy数组,Numpy自动应用sigmoid函数到每个元素上-这就是向量化的形式。
我们接着添加feedforward方式到Network类,实现输入一个a,返回相应的计算。该方法所做就是应用公式(22)到每层:
def feedforward(self, a):"""Return the output of the network if "a" is input."""for b, w in zip(self.biases, self.weights):a = sigmoid(np.dot(w, a)+b)return a
当然,我们想让Network类做的事情是学习。为此,我们给出SGD方式实现随机梯度下降。这里给出大妈。在其中有些地方有些难懂,但是接下来我会进行解释。
def SGD(self, training_data, epochs, mini_batch_size, eta,test_data=None):"""Train the neural network using mini-batch stochasticgradient descent. The "training_data" is a list of tuples"(x, y)" representing the training inputs and the desiredoutputs. The other non-optional parameters areself-explanatory. If "test_data" is provided then thenetwork will be evaluated against the test data after eachepoch, and partial progress printed out. This is useful fortracking progress, but slows things down substantially."""if test_data: n_test = len(test_data)n = len(training_data)for j in xrange(epochs):random.shuffle(training_data)mini_batches = [training_data[k:k+mini_batch_size]for k in xrange(0, n, mini_batch_size)]for mini_batch in mini_batches:self.update_mini_batch(mini_batch, eta)if test_data:print "Epoch {0}: {1} / {2}".format(j, self.evaluate(test_data), n_test)else:print "Epoch {0} complete".format(j)
training_data是元组的列表,表示训练输入和相应的期望输出。变量epochs和mini_batch_size表示你想要设置的训练的迭代次数和训练采样的大小。eta表示学习速率。如果提供了可选参数test_data,网络将会在每轮训练后进行评估(evaluate),并打印出部分进展。这对于跟踪程序很有用,但是实际上降低了速度。
该代码的工作如下。在每个迭代中,随机洗牌训练数据,并按期望的大小划分到mini-batches中。这是一种从训练数据中随机抽样的简单方式。然后对每个mini_batch进行单步梯度下降(a single step of gradient descent)。代码是self.update_mini_batch(mini_batch, etat),根据仅用mini_batch训练数据大得到单步梯度下降结果更新网络权重和偏差。下面是update_mini_batch方法的代码:
def update_mini_batch(self, mini_batch, eta):"""Update the network's weights and biases by applyinggradient descent using backpropagation to a single mini batch.The "mini_batch" is a list of tuples "(x, y)", and "eta"is the learning rate."""nabla_b = [np.zeros(b.shape) for b in self.biases]nabla_w = [np.zeros(w.shape) for w in self.weights]for x, y in mini_batch:delta_nabla_b, delta_nabla_w = self.backprop(x, y)nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]self.weights = [w-(eta/len(mini_batch))*nwfor w, nw in zip(self.weights, nabla_w)]self.biases = [b-(eta/len(mini_batch))*nbfor b, nb in zip(self.biases, nabla_b)]
大部分的工作是如下一行完成的:
delta_nabla_b, delta_nabla_w = self.backprop(x, y)
这牵涉到backpropagation算法,一种快速计算cost function梯度的方法。因此,update_mini_batch仅仅是计算mini_batch样本集中的每个训练样本的梯度,然后适当的更新self.weights和self.biases。
我现在并不准备展示slef.backprop的代码。在下一章我们将学习backpropagation算法是如何工作的,并包括self.backprop的代码。现在,我们先假设这一部分已将完成,能够返回训练样本x消耗的合适梯度。
让我们来看下全部的代码,包括一些上面省略的文档字符串。除了self.backprop整个程序是不言自明的,所有self.SDG和self.update_mini_batch做的繁重任务,我们已经讨论过了。self.backprop方式使用了一个额外叫sigmoid_prime的函数来帮助计算梯度,该函数计算函数的导数即self.cost_derivative,在这里我并不会解释。你可以从代码或者注释字符中得到函数的要点(或者细节)。我们将在下一章中详细讨论。注意,代码可能看起来有些冗长,但大部分代码是为了便于理解的文档字符。事实上,整个程序仅有74行非空白非注释代码。全部代码可以在GitHub上查看到。
"""network.py~~~~~~~~~~A module to implement the stochastic gradient descent learningalgorithm for a feedforward neural network. Gradients are calculatedusing backpropagation. Note that I have focused on making the codesimple, easily readable, and easily modifiable. It is not optimized,and omits many desirable features."""#### Libraries# Standard libraryimport random# Third-party librariesimport numpy as npclass Network(object):def __init__(self, sizes):"""The list ``sizes`` contains the number of neurons in therespective layers of the network. For example, if the listwas [2, 3, 1] then it would be a three-layer network, with thefirst layer containing 2 neurons, the second layer 3 neurons,and the third layer 1 neuron. The biases and weights for thenetwork are initialized randomly, using a Gaussiandistribution with mean 0, and variance 1. Note that the firstlayer is assumed to be an input layer, and by convention wewon't set any biases for those neurons, since biases are onlyever used in computing the outputs from later layers."""self.num_layers = len(sizes)self.sizes = sizesself.biases = [np.random.randn(y, 1) for y in sizes[1:]]self.weights = [np.random.randn(y, x)for x, y in zip(sizes[:-1], sizes[1:])]def feedforward(self, a):"""Return the output of the network if ``a`` is input."""for b, w in zip(self.biases, self.weights):a = sigmoid(np.dot(w, a)+b)return adef SGD(self, training_data, epochs, mini_batch_size, eta,test_data=None):"""Train the neural network using mini-batch stochasticgradient descent. The ``training_data`` is a list of tuples``(x, y)`` representing the training inputs and the desiredoutputs. The other non-optional parameters areself-explanatory. If ``test_data`` is provided then thenetwork will be evaluated against the test data after eachepoch, and partial progress printed out. This is useful fortracking progress, but slows things down substantially."""if test_data: n_test = len(test_data)n = len(training_data)for j in xrange(epochs):random.shuffle(training_data)mini_batches = [training_data[k:k+mini_batch_size]for k in xrange(0, n, mini_batch_size)]for mini_batch in mini_batches:self.update_mini_batch(mini_batch, eta)if test_data:print "Epoch {0}: {1} / {2}".format(j, self.evaluate(test_data), n_test)else:print "Epoch {0} complete".format(j)def update_mini_batch(self, mini_batch, eta):"""Update the network's weights and biases by applyinggradient descent using backpropagation to a single mini batch.The ``mini_batch`` is a list of tuples ``(x, y)``, and ``eta``is the learning rate."""nabla_b = [np.zeros(b.shape) for b in self.biases]nabla_w = [np.zeros(w.shape) for w in self.weights]for x, y in mini_batch:delta_nabla_b, delta_nabla_w = self.backprop(x, y)nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]self.weights = [w-(eta/len(mini_batch))*nwfor w, nw in zip(self.weights, nabla_w)]self.biases = [b-(eta/len(mini_batch))*nbfor b, nb in zip(self.biases, nabla_b)]def backprop(self, x, y):"""Return a tuple ``(nabla_b, nabla_w)`` representing thegradient for the cost function C_x. ``nabla_b`` and``nabla_w`` are layer-by-layer lists of numpy arrays, similarto ``self.biases`` and ``self.weights``."""nabla_b = [np.zeros(b.shape) for b in self.biases]nabla_w = [np.zeros(w.shape) for w in self.weights]# feedforwardactivation = xactivations = [x] # list to store all the activations, layer by layerzs = [] # list to store all the z vectors, layer by layerfor b, w in zip(self.biases, self.weights):z = np.dot(w, activation)+bzs.append(z)activation = sigmoid(z)activations.append(activation)# backward passdelta = self.cost_derivative(activations[-1], y) * \sigmoid_prime(zs[-1])nabla_b[-1] = deltanabla_w[-1] = np.dot(delta, activations[-2].transpose())# Note that the variable l in the loop below is used a little# differently to the notation in Chapter 2 of the book. Here,# l = 1 means the last layer of neurons, l = 2 is the# second-last layer, and so on. It's a renumbering of the# scheme in the book, used here to take advantage of the fact# that Python can use negative indices in lists.for l in xrange(2, self.num_layers):z = zs[-l]sp = sigmoid_prime(z)delta = np.dot(self.weights[-l+1].transpose(), delta) * spnabla_b[-l] = deltanabla_w[-l] = np.dot(delta, activations[-l-1].transpose())return (nabla_b, nabla_w)def evaluate(self, test_data):"""Return the number of test inputs for which the neuralnetwork outputs the correct result. Note that the neuralnetwork's output is assumed to be the index of whicheverneuron in the final layer has the highest activation."""test_results = [(np.argmax(self.feedforward(x)), y)for (x, y) in test_data]return sum(int(x == y) for (x, y) in test_results)def cost_derivative(self, output_activations, y):"""Return the vector of partial derivatives \partial C_x /\partial a for the output activations."""return (output_activations-y)#### Miscellaneous functionsdef sigmoid(z):"""The sigmoid function."""return 1.0/(1.0+np.exp(-z))def sigmoid_prime(z):"""Derivative of the sigmoid function."""return sigmoid(z)*(1-sigmoid(z))
程序识别手写数字的效果如何?让我们先来导入MNIST数据。我将使用一个小帮助程序mnist_load.py像下面这样来做这件事情。我们在Python shell中执行如下的命令:
>>> import mnist_loader>>> training_data, validation_data, test_data = \... mnist_loader.load_data_wrapper()
当然这些也可以在一个独立的Python程序中完成,但你照着操作还是在Python shell中更为方便。
在导入MINIST数据后,我们将创建一个带30个隐藏神经元的Network。如下代码导入Python程序,并命名为network。
>>> import network>>> net = network.Network([784, 30, 10])
最后,我们将使用随机梯度下降从MNIST的training_dat中学习,使用30次迭代(epochs),mini-batch大小为10, 学习速率,
>>> net.SGD(training_data, 30, 10, 3.0, test_data=test_data)
如果你边读文章边运行代码,这将消耗一定的时间去运行,对标准机器(2015年)这可能花费几分钟。我建议你边运行代码,边往下读,并定期检查下代码的输出。如果你比较心急,可以通过减少迭代次数,降低隐含层神经元数目, 或者仅用一部分训练数据进行训练。注意,商业代码会更多和更高效,python代码仅仅是帮助你理解神经网络如何工作的,并不是一种高效的代码!当然,我们已经训练后网络可以运行非常的快速,也可以在任何计算平台上运行。例如,一旦你的神经网络,学习到一个好的权重和偏置设置,可以很容易的移植到web浏览器的Javascript代码中,或者手机的本地app中。下面的片段展示了每次迭代训练后神经网络识别的正确率。如你所见,仅仅进行一次迭代后,10000个中正确个数为9129个,并且这个数字在随后继续增加。
Epoch 0: 9129 / 10000Epoch 1: 9295 / 10000Epoch 2: 9348 / 10000...Epoch 27: 9528 / 10000Epoch 28: 9542 / 10000Epoch 29: 9534 / 10000
亦即,该训练网络最高识别率大约为95%(在28次迭代时)!第一次能做到这样令人激动。我应该提示下你,如果你运行该代码,你的结果可能和我不太一样,因为我们初始化的神经网络具有不同的随机权重和偏差。为了产生本章的结果,我取了三次运行中最好的一次(best-of-three runs)。
让我们将隐含神经元的个数改为100再次运行上述的示例。与上一个示例一样,如果你边运行边阅读,你应该注意到这会花费很长时间去执行(在我的电脑,每次训练迭代花费数十秒时间),所以你最好边阅读边运行代码。
>>> net = network.Network([784, 100, 10])>>> net.SGD(training_data, 30, 10, 3.0, test_data=test_data)
果然,这将结果提升到96.59%。至少在这种情况下,使用更多的隐含神经元将帮助我们获取到更好的结果。
当然,为获取到这样的精度,我已经对训练迭代次数,mini-batch大小,学习速率。如上面我已经提到的那样,这些被称为我们神经网络的假设参数(hyper-parameters),以便于与我们学习算法的其他学到的参数区分(例如权重和偏差)。如果我们不加选择的使用我们的假设参数(hyper-parameters),我们就会获得比较差的结果。假设,如下,我们选择学习速率
>>> net = network.Network([784, 100, 10])>>> net.SGD(training_data, 30, 10, 0.001, test_data=test_data)
结果就会差强人意,
Epoch 0: 1139 / 10000Epoch 1: 1136 / 10000Epoch 2: 1135 / 10000...Epoch 27: 2101 / 10000Epoch 28: 2123 / 10000Epoch 29: 2142 / 10000
然而,你能够看到网络的表现正随着时间逐渐变好。这建议我们提高学习速率,让我们将。如果我们这样做了,我们就会获得更好的结果,这就建议我们再次提高学习速率。(如果做一个改变能够提高结果,那就继续改变!!!)如果我们多次这样做后,我们的学习速率可能会是(或者会到3.0),这与我们早先的示例非常接近。所以,即使我们在初始化阶段设置了一个很差的假设参数(hyper-parameters),我们在后来也能够获取到足够的信息帮助我们提高对假设参数的选择。
一般而言,调试一个神经网络具有挑战。并且这句话在你的假设参数产生的结果并不比随机噪声强的时候特别正确。假设,我们尝试将早先成功的30隐含神经元的网络,的学习速率改为:
>>> net = network.Network([784, 30, 10])>>> net.SGD(training_data, 30, 10, 100.0, test_data=test_data)
在这一点上我们实际已经走的太远,即学习速率设置的太高:
Epoch 0: 1009 / 10000Epoch 1: 1009 / 10000Epoch 2: 1009 / 10000Epoch 3: 1009 / 10000...Epoch 27: 982 / 10000Epoch 28: 982 / 10000Epoch 29: 982 / 10000
现在假设我们是第一次遇见这个问题。当然,我们已经从上面的示例中知道正确的做法是减小学习速率。但是,如果你是第一次遇到这个问题,那么你并没有足够的输出帮助你知道怎么去做。我们可能不仅担心学习速率,还会担心神经网络的其他方面。我们可能会想,是不是我们初始化神经网络的方式,让神经网络难以学习?或者,是不是我们的训练数据不够,不能让神经网络进行有效的学习?或者我们进行迭代的次数不够?或者,使用这种神经网络架构去学习识别手写数字是不可能的?或者学习速率太低?或者,可能学习速率太高?当我们第一次遇到这样的问题,我们什么都无法确定。
这个课程会告诉你调试神经网络并不是不重要的,并且对于通常的编程,它是一门艺术。你应该学习调试的艺术以便于从神经网络获取更好的结果。更通常的,我们应该选择好假设参数和好架构的试探法。我们将会在整本书中贯穿这些讨论,包括,我是怎么样选择如上的假设参数的。
Exercise
- 尝试创建两层神经网络-一层输入和一层输出,没有隐含层-分别具有784和10神经元。使用随机梯度下降训练网络。你能够获取到的识别精度是多少?
早先,我跳过了如何载入MNIST数据集的详细过程。这是非常易懂的。为了完整,这里是代码。用来存储MNIST数据的结构在注释中有描述-这是非常易懂的东西,Numpy ndarray对象的元组(tuple)和列表(lists)(如果你对ndarrays不太熟悉,将这些视为向量(vectors)):
"""mnist_loader~~~~~~~~~~~~A library to load the MNIST image data. For details of the datastructures that are returned, see the doc strings for ``load_data``and ``load_data_wrapper``. In practice, ``load_data_wrapper`` is thefunction usually called by our neural network code."""#### Libraries# Standard libraryimport cPickleimport gzip# Third-party librariesimport numpy as npdef load_data():"""Return the MNIST data as a tuple containing the training data,the validation data, and the test data.The ``training_data`` is returned as a tuple with two entries.The first entry contains the actual training images. This is anumpy ndarray with 50,000 entries. Each entry is, in turn, anumpy ndarray with 784 values, representing the 28 * 28 = 784pixels in a single MNIST image.The second entry in the ``training_data`` tuple is a numpy ndarraycontaining 50,000 entries. Those entries are just the digitvalues (0...9) for the corresponding images contained in the firstentry of the tuple.The ``validation_data`` and ``test_data`` are similar, excepteach contains only 10,000 images.This is a nice data format, but for use in neural networks it'shelpful to modify the format of the ``training_data`` a little.That's done in the wrapper function ``load_data_wrapper()``, seebelow."""f = gzip.open('../data/mnist.pkl.gz', 'rb')training_data, validation_data, test_data = cPickle.load(f)f.close()return (training_data, validation_data, test_data)def load_data_wrapper():"""Return a tuple containing ``(training_data, validation_data,test_data)``. Based on ``load_data``, but the format is moreconvenient for use in our implementation of neural networks.In particular, ``training_data`` is a list containing 50,0002-tuples ``(x, y)``. ``x`` is a 784-dimensional numpy.ndarraycontaining the input image. ``y`` is a 10-dimensionalnumpy.ndarray representing the unit vector corresponding to thecorrect digit for ``x``.``validation_data`` and ``test_data`` are lists containing 10,0002-tuples ``(x, y)``. In each case, ``x`` is a 784-dimensionalnumpy.ndarry containing the input image, and ``y`` is thecorresponding classification, i.e., the digit values (integers)corresponding to ``x``.Obviously, this means we're using slightly different formats forthe training data and the validation / test data. These formatsturn out to be the most convenient for use in our neural networkcode."""tr_d, va_d, te_d = load_data()training_inputs = [np.reshape(x, (784, 1)) for x in tr_d[0]]training_results = [vectorized_result(y) for y in tr_d[1]]training_data = zip(training_inputs, training_results)validation_inputs = [np.reshape(x, (784, 1)) for x in va_d[0]]validation_data = zip(validation_inputs, va_d[1])test_inputs = [np.reshape(x, (784, 1)) for x in te_d[0]]test_data = zip(test_inputs, te_d[1])return (training_data, validation_data, test_data)def vectorized_result(j):"""Return a 10-dimensional unit vector with a 1.0 in the jthposition and zeroes elsewhere. This is used to convert a digit(0...9) into a corresponding desired output from the neuralnetwork."""e = np.zeros((10, 1))e[j] = 1.0return e
我在上面说过,我们的程序获得了一个很好的结果。这是什么意思?和什么比是好的?这里有一些简单的基准(非神经网络)信息进行对比,以便于明白为什么说表现较好。当然,所有基准中最简单的是随机猜测数字。正确率大概是10%,我们的结果比这好太多。
什么是更好的基准?让我们来尝试一个非常建档的想法:我们将看一幅图片有多暗。例如,一个为2的图片一般会比为1的图片更暗,仅仅因为有更多的黑色像素,如下图所示:

这种方法使用训练数据来计算每个数字的平均暗度。当测试一个新的图像,我们将计算图像多暗,然后猜测其上面的数字就是平均值与其最接近的那个。这是一个简单的步骤,并且容易进行编程,所以在这里我就不写出代码了-如果你对此感兴趣,示例代码在这里。但这相对于随机猜测来说是一个巨大的进步,10000幅测试图片中有2225幅正确。即,准确率为22.25%。
发现其它准确率在20%到50%的方法并不困难。如果你继续努力,你最高能达到50%。但是,使用确定的机器学习算法能获取到更高的精度。让我们来尝试使用更一种最好的算法,支持向量机(support vector machine 或 SVM)。如果你对这些不太熟悉,不要捉急,我们并不需要明白SVMs工作的具体细节。反而,我们将会使用一个叫做scikit-learn的Python库,它给我们提供了一个很快的c语言SVMs库(LIBSVM)的Python借口。
如果你以默认设置运行scikit-learn的svm分类器,在10000个测试图像中,你能获得9435个正确(代码在这里)。这相对于我们幼稚的通过比暗来分辨图像是一个巨大的提升,仅仅有一点瑕疵。在后面的章节,我将介绍能提高我们神经网络的新技术,让神经网络的表现远超SVM。
这并不是故事的结尾,然而,9435/10000的结果仅是scikit-learn's中SVMs的默认设置。SVMs拥有很多的可调参数,并且可能会获得超出当前表现的参数。我并不会明确的解释这项搜索,如果你想了解更多,你可以参阅这边Andreas Mueller的博客。Mueller展示了对SVMs参数做一些优化工作,能够获得高达98.5%的准确率。换句话说,一个表现好的SVM可以在70次识别中仅错误一次。多棒,神经网络能做的更好吗?
事实上,它能够做到。目前,好的神经网络远超过其他解决MNIST问题的方法,包括SVMs。2013年的记录是9979/10000。这是 Li Wan, Matthew Zeiler, Sixin Zhang, Yann LeCun, and Rob Fergus(中国人是一作)做出来的。我们本书后续章节中看到他们使用的大多数技术。这个水平的表现和人类的识别率接近,甚至更好,因为有些MNIST图像即使人类识别也很困难。例如:
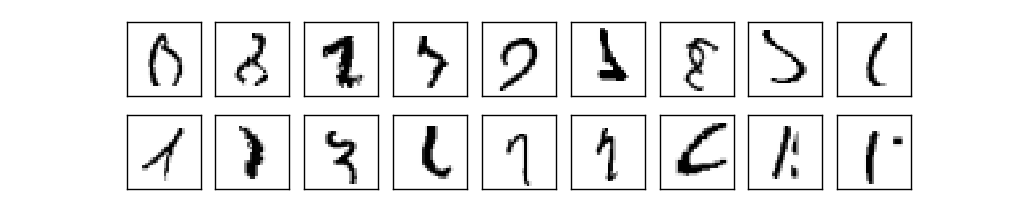
我相信你也同样认为这些难以识别!即使有这样的图像在MNIST数据集中,神经网络仍然能达到惊人的10000测试图像21错误。通常来讲,当我们编写程序时,我们相信像解决识别手写数字这么复杂的问题一定需要繁复的算法。但是,即使如Wan等人在文章中提及的神经网络也是非常简单的,相当于本章我们提及算法的变异。所有的复杂都能够从训练数据中自动学习。在一些层面上,我们结果和一些更复杂的文章是殊途同归的(moral这里翻译为道)。
sophisticated algorithm <= simple learning algorithm + good training data.
通向深度学习
尽管我们的神经网络给出了令人印象深刻的表现,但是这个表现总有些神秘。权重和偏差是网络自动发现的。这也意味着,我们并不能立即解释网络是如何做到这样的。我们能够以某种方式明白我们的神经网络识别手写数字的原理吗?并且,得到这样的原理,我们能做的更好吗?
让这个问题更鲜明些,假设几十年之后,神经网络衍生出了人工智能(AI)。我们能够明白智能网络是如何工作的吗?或许这个带着我们不明白的权重和偏差的网络将会是难以明白的,因为它们能够自动地学习。在早年,AI研究者希望对AI的努力建造,能够帮助我们理解智能的原理,或者人类大脑的功能。但是,最后的结果可能是我们既不能明白大脑也不能明白人工智能是如何工作的。
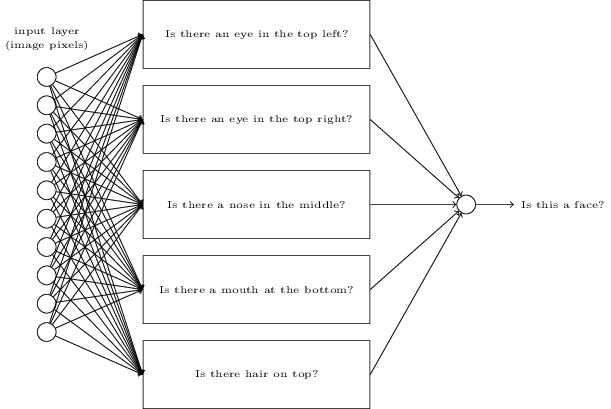
为了解决这个问题,让我们回想下我在起始章给出的人工神经元解释,作为一个重要的证据。假设,我们想确定一副图片中是否有人脸:



我们可以尝试以我们识别手写数字的方式破解这个问题-使用图片中的像素作为神经网络的输入,网络的输出是一个单个神经元指示"这是一个人脸"或者"这不是一个人脸"。
假设我们这样做,但是我们没有使用学习算法。相反,我们正在尝试去手动设计一个网络,选择适当的权重和偏差。我们可能会如何做?这个时候完全忘记神经网络,我们可以用启发思维将这个问题转换为子问题:这张图片左上方有一只眼睛吗?右上方有一只眼睛吗?在中间有一个鼻子吗?在底部中间有一个嘴巴吗?最上方有头发吗?等等。
如果这若干个问题的答案是"yes",或者近视是"可能是"。我们将推断出这幅图像貌似是一张人脸。如果这些问题的答案大多数是"no",那么这张图片可能不是人脸。
当然,这仅仅是一个粗糙的启发,并且具有很多的不足。可能这个人是一个秃头,那么他将没有头发。可能我们仅能偶看到脸的一部分,或者脸在一个角度,以至于一些面部特征被隐藏起来了。然而,这个启发说的是如果我们能够用神经网络解决这些子问题,那么我们就有可能通过合并这些网络建立人脸识别的神经网络。这里是一个可能的架构,方框表示子网络。注意,这并不是一个现实的主义去解决人脸识别问题。然而,这帮助我们建立网络函数如何工作的直觉。这里是架构:
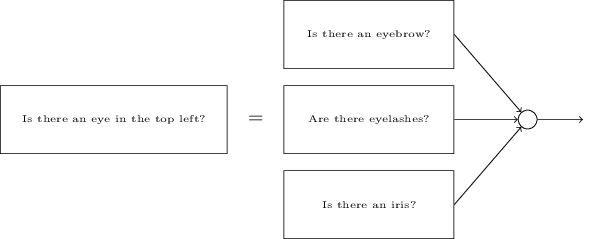
将子网络再进行分解看起来也是合理的。假设,我们在考虑这样的问题:"左上方是否有一只眼睛?"这可以分解为如下的问题:"是否有眼眉毛?";"是否有眼睫毛?";"是否有虹膜?";等等。当然,这些问题应该包括位置信息,例如-"眉毛是否在左上角,是否在睫毛的上方?",诸如此类-但是让我们简单的考虑它。这个回答"左上方是否有眼睛?"的问题可以如下分解:
这些问题可以继续分解,一步一步通过多层网络。最终,我们将获得单个像素就能够回答的简单得子网络。这些问题可能是,例如,在这幅图片的图书位置上存不存在非常简单的形状。该问题能够被链接到图片原始像素的单个神经元回答。
网络的最终原因是将一个非常复杂的问题(这张图片上有没有人脸)分解成非常简单的问题(单个像素级别就能够回答)。它做这项工作通过一系列的层,前面的层回答关于输入图像非常简单和特殊的问题,后面的层构建一个更复杂和更抽象的集合。带有两层或两层以上隐含层的网络称为深度神经网络(deep neural networks)。
当然,我并没有说分解成子问题的递归是怎么做的。可以确定的是,通过手动设计网络权重和偏置并不明智。相反,我们喜欢使用学习算法,这样网络能够自动学习权重和偏置-并且从训练数据中整合概念。1980年代和1990年代的研究者尝试使用随机梯度下降和反向传播(backpropagation)来训练深度网络。不幸的是,除了少数几个特别的架构,他们并没有太多的幸运。这种网络能够学习,但是非常慢,并且通常慢的无法使用。
自从2006年后,一系列的技术被开发出来,使得学习进入深度神经网络。深度学习技术基于随机梯度下降和反向传播,但是也引进了新的思想。这些技术开启了更深(更大)的网络训练-现在人们开始通常训练5层到10层的隐含网络。并且,它们在很多问题上输出的表现结果远好于浅神经网络(如,只有单隐含层的神经网络)。原因当然是,深度网络有能力构建复杂的概念集(hierarchy of concepts)。这有点像传统编程语言使用模块化的设计和抽象的思想去创造复杂的电脑软件。深度网络与浅层网络相比优先类似于有向下拆分函数功能的编程语言与没有该功能的编程语言相比。抽象在神经网络和传统编程中具有不同的形式,但是同样的重要。
moker@2016.4.3@2:24@WH
