@skyway
2015-10-18T08:39:50.000000Z
字数 1149
阅读 1119
散列hash及冲突解决
数据结构
title: 散列hash及冲突解决
date: 2015-09-09 15:51:07
categories: 编程
tags: [数据结构, hash]
数组:寻址容易,插入和删除困难
链表:寻址困难,插入和删除容易
散列方式
除法散列法
index = value % 16平方散列法
index = (value*value) >> 28斐波拉契散列法
(1)对于16位整数而言,这个乘数是40503
(2)对于32位整数而言,这个乘数是2654435769
(3)对于64位整数而言,这个乘数是11400714819323198485
index = (value*2654435769)>>28
hash冲突解决
拉链法
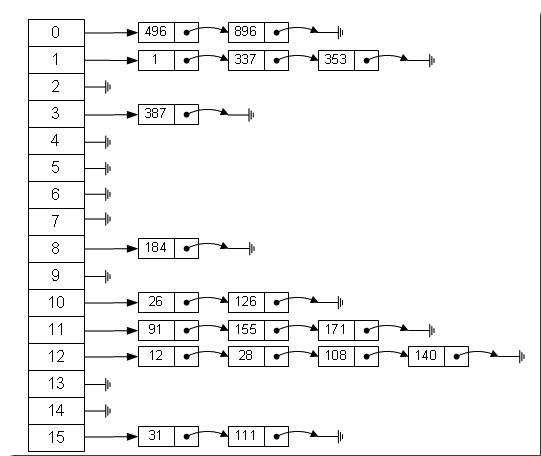
开放地址法
公式:Hi=(H(key)+di) MOD m i=1,2,...,k(k<=m-1)
线性探测法 Linear Probing
di = 1,冲突即往后移动一个位置。
探查过程终止于三种情况:
(1)若当前探查的单元为空,则表示查找失败(若是插入则将key写入其中);
(2)若当前探查的单元中含有key,则查找成功,但对于插入意味着失败;
(3)若探查到T[d-1]时仍未发现空单元也未找到key,则无论是查找还是插入均意味着失败(此时表满)。
聚集或堆积现象
用线性探查法解决冲突时,当表中i,i+1,…,i+k的位置上已有结点时,一个散列地址为i,i+1,…,i+k+1的结点都将插入在位置i+k+1上。把这种散列地址不同的结点争夺同一个后继散列地址的现象称为聚集或堆积(Clustering)。这将造成不是同义词的结点也处在同一个探查序列之中,从而增加了探查序列的长度,即增加了查找时间。若散列函数不好或装填因子过大,都会使堆积现象加剧。
如果插入数据相似,会产生数据聚合,导致查找和插入效率下降
二次探测法Quadratic Probing
hi=(h(key)+i*i)%m 0≤i≤m-1 //即di=i2
不易探查到整个散列空间,很多数据被映射到同一位置时,数据查找变得相当困难。
随机探测法
di = 随机数
双重散列法Double Hashing
hi=(h(key)+i*h1(key))%m 0≤i≤m-1 //即di=i*h1(key)
即探查序列为:d=h(key),(d+h1(key))%m,(d+2h1(key))%m,…,等。
【注意】定义h1(key)的方法较多,但无论采用什么方法定义,都必须使h1(key)的值和m**互素**,才能使发生冲突的同义词地址均匀地分布在整个表中,否则可能造成同义词地址的循环计算。
* 若m为素数,则h1(key)取1到m-1之间的任何数均与m互素,因此,我们可以简单地将它定义为:h1(key)=key%(m-2)+1
* 若m是2的方幂,则h1(key)可取1到m-1之间的任何奇数。
