@snowying
2018-08-28T12:07:01.000000Z 字数 2735 阅读 2020
Joint 3D Proposal Generation and Object Detection from View Aggregation
目前kitti网站上排名第一的方法,结合了图像和lidar,作者是来自滑铁卢大学的Jason Ku, Melissa Mozifian等
摘要:
AVOD(Aggregate View Object Detection),运用了雷达点和RGB图像来生成特征,生成的特征被两个子网络分享:RPN网络和第二阶段的检测网络。
1.引言
3D目标检测难度高于2D原因在于:一是3D数据的分辨率不高,并且随着距离的增加,分辨率降低;二是3D目标检测需要估计bbox的方向。
3D目标检测也像2D一样依赖于RPN的效果。将RPN应用到3D是很有挑战的:2D图像是密集的和高分辨率的,一个目标在特征图上占几个像素,但是点云的前视图和俯视图(BEV)都是稀疏的和低分辨率的,还有目标很小的情况。论文中提出AVOD来解决这些问题。
特征提取器和RPN结合,从不同的输入模式来提取RPN结果,对小目标更有效。
2.相关工作(省略)
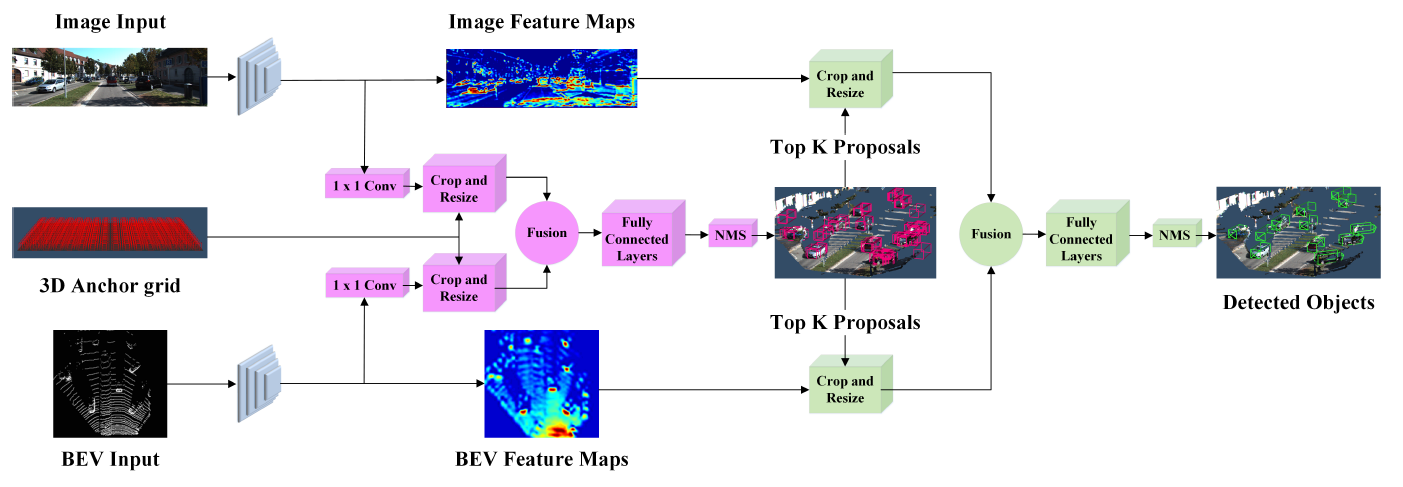
3.AVOD模型结构
图中蓝色 的代表特征提取过程,粉色 的代表RPN过程,绿色 的代表第二阶段的检测网络。
论文的方法是从雷达俯视图(BEV)和RGB图像来生成特征图。然后特征图用于RPN生成没有方向的region proposals,然后再传递给检测网络进行维度精简,方向估计和分类。
A. 从点云和图像上提取特征图
点云输入是6通道的BEV map,采取了MV3D的方法,BEV map是用0.1m分辨率的voxel grid来表示的。范围是[-40,40]×[0, 70],跟camera的范围一致。BEV map前5个通道是由grid里面的点的最大高度指编码得到,grid的选取是在Z轴[0, 2.5]范围内平均选取;第6个通道是voxel grid点密度信息,公式
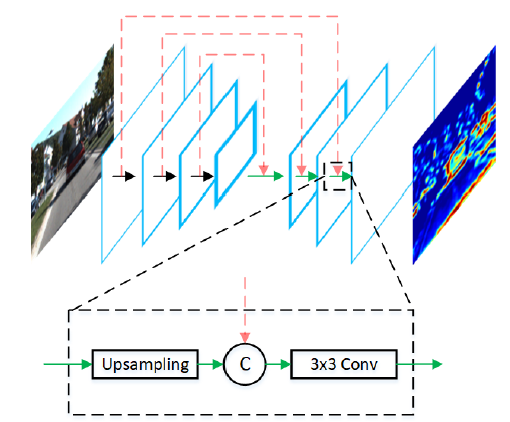
B. 特征提取
RGB和BEV视角特征提取网络结构相同,如上图所示,是一种full-resolution的方法,包括encoder和decoder两个步骤。encoder是在VGG-16基础上做一些改动,主要是将通道数减半,在conv-4层删减了网络。encoder网络输入(image或者BEV)大小是
具体实现是沿着红色箭头的方向,把encoder的结果传递给相应的decoder层,中间的特征图F先经过上采样,跟红色箭头起始的encoder层特征进行连接(如图中黑框中所示),再接一个3×3的卷积层进行特征融合,重复三次这样的计算,decoder的最后一层就得到了一个全分辨率的特征图,类似FCN。
C. 多模型融合的RPN
如上图所示,3D的RPN结构与2D的相似,其中的anchor boxes由中心点的坐标( ) ( ) ( )
从多视角的crop和resize操作提取特征crop 的做法是:给一个3维的anchor时,将anchor投影到BEV和图像的特征图上,然后相关的区域就会被用来提取多视角(BEV和image)feature crop,然后双线性调整到3×3大小来获取相同长度的特征向量。
通过1×1卷积层降维 :如果保存100k个anchors的feature crop,就会占用很大的GPU内存,并且增加计算需求,因此就采用了1×1的卷积核,作用于输出的特征图,公式是
其中
3D Proposal 生成 :两种视角的feature crops长度相同,然后通过取均值的方式融合,两个任务分支256维的全连接层用融合的feature crops回归得到建议框和目标/背景分数值,通过计算( , )
对于汽车检测来说,IoU小于0.3被认为是背景,大于0.5就认为是目标的anchor,对于行人和骑自行车的人,阈值减少到0.45。为了减少多余的建议框,采用2D的非极大值抑制(non-maximum suppression,NMS)来保证在训练时BEV上IoU阈值是0.8时,有1024个建议框。在预测时,汽车目标有300个建议框,行人和骑自行车的人有1024个建议框。
D. 第二阶段的检测网络
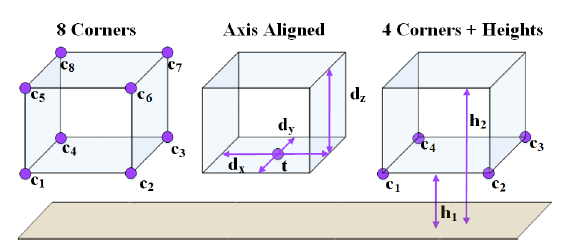
3D Bounding Box编码 :用四个corners和两个高度值来编码bounding box,如C中图所示,两个高度值表示最高和最低的corner的距地面的高度,将参数降低到了10维。
明确的方向向量回归 :通过计算(
实现最终的检测 :采用和RPN相似的方法,输入是特征crops,是通过将建议框投影到两个输入视角得到的。由于建议框的数量大大的小于anchors的数量,使用最原始的特征图(深度是D'=35)来生成特征crops。两个视角的crops resize到7×7然后通过像素平均计算进行融合,然后接3个大小是2048的全连接层,得到输出的box regression,方向估计和分类。