@survivorZzz
2019-05-07T09:03:11.000000Z
字数 2978
阅读 779
Java 8 实战读书笔记
java8 stream
- 可以在函数式接口上使用lamdba表达式.
- 只有一个抽象方法的接口就是函数式接口.
- 接口可以定义无数个默认方法, 但是只要接口中只有一个抽象方法, 则接口就是函数式接口.
- lamdba表达式就是对应函数式接口的实例, 例如可以将lamdba表达式赋值给函数式接口:
Runnable r1 = () -> System.out.println("Hello World 1") 一个函数式接口的等价lamdba表达式需要这个lamdba的签名和对应函数式接口的抽象方法的签名一致, 例如:
() -> void就和接口Runnable的void run()方法的签名一致.


- 任何函数式接口都不允许抛出可检查型异常(checked exception),至于原因:see this,如果需要lamdba表达式抛出异常, 可以:
- 定义一个自定义的函数式接口, 并在抽象方法上声明异常类型.
- 或者把lamdba表达式包在try-cache块中.
- 当lamdba仅有一个类型需要推断的参数时, 参数括号可省略,例如:
Predicate<Apple> p = a -> a.getWeight > 0;
- lamdba表达式只可以"捕获"lamdba外被finnal修饰的或事实上是final也即只被赋值过一次的局部变量.
- 函数式接口Predicate的三个默认方法:
nagete,and,or分别对应着"非","且","或",用于连接多个断言. 注意and, or的优先级是按从左到右的顺序. 例如p6是先p4和p5先or, 再和p1与.
//断言一个苹果重量大于80Predicate<Apple> p1 = p -> p.getWeight > 80;//断言一个苹果重量不大于80Predicate<Apple> p2 = p1.negate;//断言一个苹果重量既大于80, 且颜色是红色Predicate<Apple> p3 = p1.and(p -> p.getColor.equals("红色"));Predicate<Apple> p4 = a -> a.getColor.equals("蓝色");Predicate<Apple> p5 = a -> a.getColor.equals("红色");//断言一个苹果重量大于80且红色蓝色都行Predicate<Apple> p6 = p4.or(p5).and(p1);
函数式接口Function, 有两个方法
andThen和compose. 两个方法的作用均是将两个函数式接口(或者说lamdba)进行复合, 区别如下:Function f1 = (int a) -> a + 1;Function f2 = (int a) -> a * 2;
则
f1.andThen(f2)相当于数学里面的y = f2(f1(x)),f1.compose(f2)相当于数学里面的y = f1(f2(x)).一个流只可以被消费一次, 所谓的消费指的是"终极"操作.
- 外部迭代: 使用迭代器显示迭代或使用
for-each隐式迭代. - 内部迭代:stream内部做的迭代.
- 可以连接起来的流式操作称为中间操作, 关闭流的操作叫终端操作. 例如Stream的
map(),filter(),limit()等就是中间操作, 他们可以连起来使用. 像collect()就是终端操作, 它收集结果, 并关闭流. - 如果一个流式操作返回一个Stream, 则是一个中间操作, 否则, 是一个终端操作. 比如
map()返回一个Stream是中间操作,count()返回一个long则是终端操作. 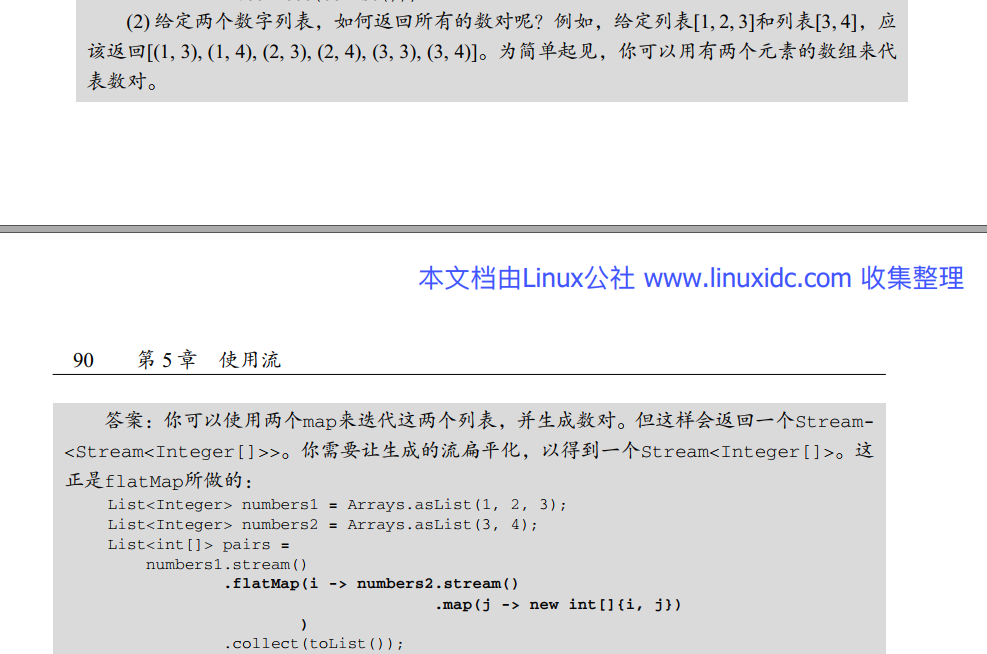

- Stream的
anyMatch(),noneMatch(),allMatch()对应||,!,&&, 他们均是"短路"的. limit()也是"短路"的, 它只会取出前三个, 后面的就不操作了, 这样可以将一个无限流转成有线流.- java8 io
Files.lines()将返回一个文件的每一行的流Stream<String>. 生成前十个斐波那契数列:
Stream.iterate(new int[]{0,1}, a -> new int[]{a[1], a[0] + a[1]}).limit(10).map(a -> a[0]).forEach(System.out::println);
运用的是
public static<T> Stream<T> iterate(final T seed, final UnaryOperator<T> f)方法, 该方法第一个参数是第一个数, 第二参数是一个一元操作函数.需要对无限流进行
limit()否则终端操作将无限或不能进行, 例如forEach()会无限进行, 排序和归约则无法进行.Stream.limit()和Stream.skip()区别:点我.汇总统计的使用例子:
IntSummaryStatistics result = IntStream.rangeClosed(1, 100).boxed().collect(Collectors.summarizingInt(a -> a));System.out.println(result.toString());System.out.println(result.getAverage());System.out.println(result.getCount());System.out.println(result.getSum());
和
IntSummaryStatistics类似的还有DoubleSummaryStatistics和LongSummaryStatistics.Collectors.joining()方法内部使用的是线程不安全的StringBuilder来构建字符串.Stream.reduce()和Stream.collect()比较, 看这里.
下图是书的截图, 帮助理解:





Collectors.groupingBy()和Collectors.partitioningBy()的区别:

并行流是使用fork/join框架实现多线程的,使用的是
java.util.concurrent.ForkJoinPool作为线程池, 线程池的默认值是处理器的个数, 可以通过如下方法设置大小System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism","12");这是一个系统属性, 且是全局的, 目前没办法为某一个特定的并行流独立的设置该值. 建议使用默认值, 除非有充分的理由.

- 默认方法不是抽象方法, 函数式接口只有一个抽象方法.

- 一个类实现了多个接口, 而这多个接口中有函数签名的相同默认方法
String hello(), 那这个类在使用这个hello()方法时, 实际使用的是哪一个接口的默认方法呢? 有以下三个原则来解决这种冲突:

- 一个类C实现了两个接口B和C, B和C都有一个默认方法
m()并且方法签名也都相同, 当C的一个对象调用方法m()时, 编译器就会抛出异常Error: class C inherits unrelated defaults for m() from types B and A.这时候编译器没办法判断C的对象究竟调用的是哪一个父接口的默认方法. 解决办法是手动显式的告诉编译器你想使用B接口的m()方法:B.super.m(). - When to use parallel streams
- Optional的使用可以参考

