@zero1036
2018-05-04T11:16:08.000000Z
字数 9468
阅读 2539
storm学习笔记
数据处理
一、概述
Storm:开源的、分布式、流式计算系统
Hadoop:批量计算生态系统
Hadoop特点:只能处理适合进行批量计算的需求。对于,非批量的计算就不能够满足要求了。
很多时候,其应用只能先收集一段时间数据,等数据收集到一定规模之后,我们才开始MapReduce处理。
批量计算与流式计算的区别

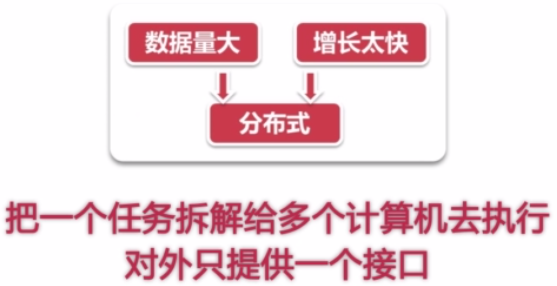
无论Storm或Hadoop生态,本质都是把一个任务拆解给多个计算机去执行,对外只提供一个接口
二、内部机制
运作模式
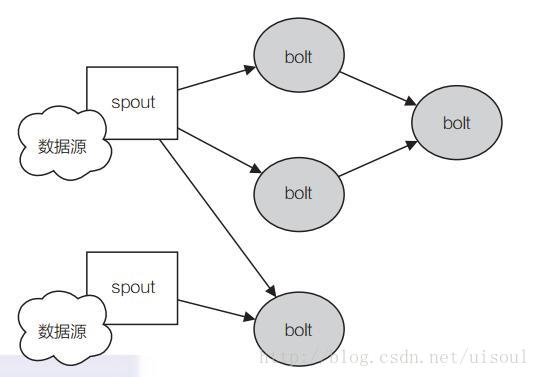
topology运作模式:spout 代表了一个 Storm topology的主要数据入口,充当采集器的角色,连接到数据源,将数据转化为一个个 tuple,并将 tuple 作为数据流进行发射。
bolt 可以理解为计算程序中的运算或者函数,将一个或者多个数据流作为输入,对数据实施运算后,选择性地输出一个或者多个数据流。 bolt 可以订阅多个由 spout 或者其他bolt发射的数据流,这样就可以建立复杂的数据流转换网络。
模块关系
整个集群维度:
- Nimbus
- Supervisor
单个拓扑维度:
- 组件(component包含spout与bolt)
- 进程(worker)
- 执行器(executor)
- task(任务)
其关系如下运行示例:
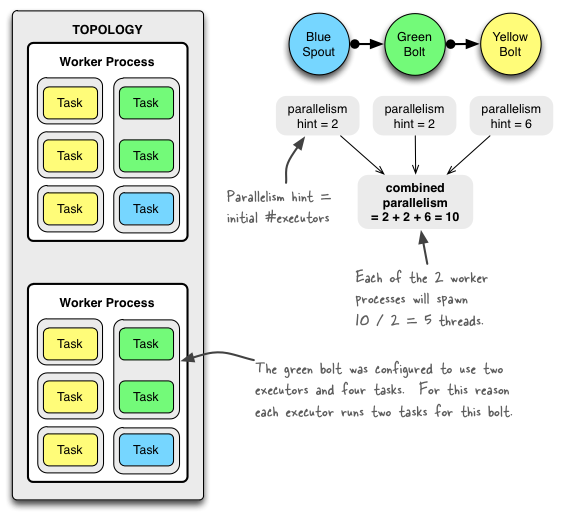
下图显示了简单的 topology(拓扑)是如何运行的. 该 topology 由 3 个 components(组件)构成: 一个名为 BlueSpout 的 spout 和两个名为 GreenBolt 和 YellowBolt 的 bolts. 该组件链接, 使得 BlueSpout 将其输出发送到 GreenBolt, 它们将自己的输出发送到 YellowBolt。
note:
1.拓扑(topology)在分布式集群中同时运行多个进程(woker)
2.单个进程运行多个执行器/线程(executor),每个执行器默认持有一个任务(task),可设置多个
3.单个任务对应单个组件的实例,因此实例中变量不共享、线程安全
code example:
Config conf = new Config();conf.setNumWorkers(2); // use two worker processestopologyBuilder.setSpout("blue-spout", new BlueSpout(), 2); // set parallelism hint to 2topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2).setNumTasks(4).shuffleGrouping("blue-spout");topologyBuilder.setBolt("yellow-bolt", new YellowBolt(), 6).shuffleGrouping("green-bolt");StormSubmitter.submitTopology("mytopology",conf,topologyBuilder.createTopology());
通过示例可知,topology中共有2个worker进程,12个task(2+2+6),10个executor
同一个component不同task之间,变量不共享:
public class TaskMain {private static final String TOPOLOGY_NAME = "test-task-topology";public static class TaskTestBolt extends BaseRichBolt {OutputCollector _collector;private Integer count;private StringBuilder builder;@Overridepublic void prepare(Map conf, TopologyContext context,OutputCollector collector) {_collector = collector;count = 0;builder = new StringBuilder();}@Overridepublic void execute(Tuple tuple) {count++;String word = tuple.getStringByField("word");builder.append(word).append("-");System.out.println("word:" + builder.toString() + " metric:" + count);_collector.ack(tuple);}@Overridepublic void declareOutputFields(OutputFieldsDeclarer declarer) {}}public static void main(String[] args) {TopologyBuilder builder = new TopologyBuilder();builder.setSpout("wordSpout", new TestWordSpout(), 1);builder.setBolt("taskBolt", new TaskTestBolt(), 1) //单个executor.setNumTasks(2) //2个task.shuffleGrouping("wordSpout");Config conf = new Config();conf.setDebug(true);LocalCluster cluster = new LocalCluster();cluster.submitTopology(TOPOLOGY_NAME, conf, builder.createTopology());Utils.sleep(10000);cluster.killTopology(TOPOLOGY_NAME);cluster.shutdown();}}//output resultword:nathan-jackson-jackson-nathan-jackson-bertels-jackson- metric:77857 [Thread-14-taskBolt-executor[2 3]] INFO o.a.s.d.executor - BOLT ack TASK: 3 TIME: TUPLE: source: wordSpout:4, stream: default, id: {}, [jackson]7857 [Thread-14-taskBolt-executor[2 3]] INFO o.a.s.d.executor - Execute done TUPLE source: wordSpout:4, stream: default, id: {}, [jackson] TASK: 3 DELTA:7955 [Thread-20-wordSpout-executor[4 4]] INFO o.a.s.d.task - Emitting: wordSpout default [golda]7955 [Thread-20-wordSpout-executor[4 4]] INFO o.a.s.d.executor - TRANSFERING tuple [dest: 2 tuple: source: wordSpout:4, stream: default, id: {}, [golda]]7957 [Thread-14-taskBolt-executor[2 3]] INFO o.a.s.d.executor - Processing received message FOR 2 TUPLE: source: wordSpout:4, stream: default, id: {}, [golda]word:jackson-golda- metric:2
并行度具体配置参考:http://storm.apachecn.org/releases/cn/1.1.0/Understanding-the-parallelism-of-a-Storm-topology.html
三、消息可靠性

在Storm中,消息处理可靠性从Spout开始的。storm为了保证数据能正确的被处理,对于spout产生的每一个tuple,storm都能够进行跟踪,这里面涉及到了ack/fail的处理, 如果一个tuple被处理成功,那么spout便会调用其ack方法,如果失败,则会调用fail方法。而topology中处理tuple的每一个bolt都会通过OutputCollector来告知storm,当前bolt处理是否成功。
我们知道spout必须能够追踪它发射的所有tuples或其子tuples,并且在这些tuples处理失败时能够重发。那么spout如何追踪tuple呢?storm是通过一个简单的anchor机制来实现的(在下面的bolt可靠性中会讲到)。
- bolt把元组作为输入,然后产生新的元组作为输出;
- 可靠性情况下,元组树的任意节点发生处理失败将会传导到其根节点的tuple上(即spout发出的tuple)
- 元组在中层bolt处理中被丢弃(没有传导到下一层bolt)同时又被ack的情况,该元组的根节点元组将会ack;
- 可靠性实现方式:spout发射消息传递messageId,bolt发射消息时传递接收元组(Question:Kestrel消息队列可以直接使用其消息自带的编号,rabbitMq是否可以?如果不可以,如何生成全局唯一有序消息Id?2版朱雀调度服务按事件类型分组,MongoDB生成唯一Id)
四、数据流组
随机数据流组(shuffleGrouping):随机流组是最常用的数据流组。它只有一个参数(数据源组件),并且数据源会向随机选择的 bolt 发送元组,每个bolt实例接收到的相同数量的tuple
按字段分组(fieldsGrouping):根据指定字段的值进行分组。比如说,一个数据流根据“word”字段进行分组,所有具有相同“word”字段值的tuple会路由到同一个bolt的task中。注意:当bolt设置的task数量少于word的种类时,相同种类的work同样会路由到同一个bolt的task中,问题是bolt的task数量需要在topology构建时确定,是否可以根据work的种类动态增加
全复制分组(allGrouping):将所有的 tuple 复制后分发给所有 bolt task。每个订阅数据流的 task 都会接收到 tuple 的拷贝。注意:拓扑里的所有bolt都失败了,spout的fail方法才会被调用;换言之,另外两个数据流组,仅一个bolt fail就会导致spout的fail
全局分组(globleGrouping):这种分组方式将所有的 tuples 路由到唯一一个 task上。Storm按照最小的 task ID 来选取接收数据的 task。注意:当使用全局分组方式时,设置bolt的task并发度是没有意义的,因为所有tuple都转发到同一个 task 上了。使用全局分组的时候需要注意,因为所有的tuple都转发到一个JVM 实例上,可能会引起 Storm 集群中某个 JVM或者服务器出现性能瓶颈或崩溃。
不分组(noneGrouping):在功能上和随机分组相同,是为将来预留的。
指向型分组(directGrouping):数据源会调用 emitDirect() 方法来判断一个 tuple 应该由哪个 Storm 组件来接收。只能在声明了是指向型的数据流上使用。
fieldsGrouping task数量少于分组值种类的code example:
public class OneTaskForFieldsGroupingMain {private static final String TOPOLOGY_NAME = "test-grouping-topology";public static class TaskTestBolt extends BaseRichBolt {OutputCollector _collector;private StringBuilder builder;@Overridepublic void prepare(Map conf, TopologyContext context,OutputCollector collector) {_collector = collector;builder = new StringBuilder();}@Overridepublic void execute(Tuple tuple) {String word = tuple.getStringByField("word");builder.append(word).append("-");System.out.println("word:" + builder.toString());_collector.ack(tuple);}@Overridepublic void declareOutputFields(OutputFieldsDeclarer declarer) {}}public static void main(String[] args) {TopologyBuilder builder = new TopologyBuilder();builder.setSpout("wordSpout", new TestWordSpout(), 1);builder.setBolt("myBolt", new TaskTestBolt(), 1).setNumTasks(2) //2 task.fieldsGrouping("wordSpout", new Fields("word"));Config conf = new Config();conf.setDebug(true);LocalCluster cluster = new LocalCluster();cluster.submitTopology(TOPOLOGY_NAME, conf, builder.createTopology());Utils.sleep(10000);cluster.killTopology(TOPOLOGY_NAME);cluster.shutdown();}}//output resultword:golda-jackson-bertels-jackson-golda-bertels-bertels-bertels-jackson-golda-jackson-jackson-jackson-jackson-jackson-jackson-jackson-jackson-jackson-bertels-bertels-word:mike-mike-nathan-mike-mike-mike-mike-nathan-nathan-nathan-mike-
五、组件spout and bolt
spout对接消息队列
spout对接可用数据源:
- 消息队列:Kalfa、ActiveMQ、RabbitMQ、Kestrel
- 数据库
- 其他
对接rabbitmq消息队列作为数据源
1.利用RabbitMQSpout接收消息
public class Main{public static void main(String[] args) {TopologyBuilder builder = new TopologyBuilder();Scheme scheme = new RabbitMQMessageScheme(new MqScheme(), "envelope", "properties");IRichSpout spout = new RabbitMQSpout(scheme);ConnectionConfig connectionConfig = new ConnectionConfig("localhost", 5672, "guest", "guest", ConnectionFactory.DEFAULT_VHOST, 10); // host, port, username, password, virtualHost, heartBeatConsumerConfig spoutConfig = new ConsumerConfigBuilder().connection(connectionConfig).queue("testExchange-q1").prefetch(200).requeueOnFail().build();builder.setSpout("my-spout", spout).addConfigurations(spoutConfig.asMap()).setMaxSpoutPending(200);...}}
自定义Scheme:MqScheme.class
public class MqScheme implements Scheme {@Overridepublic List<Object> deserialize(ByteBuffer byteBuffer) {List result = Lists.newArrayListWithCapacity(1);result.add(byteBufferToString(byteBuffer));return result;}@Overridepublic Fields getOutputFields() {return new Fields("testMqMessage");}public static String byteBufferToString(ByteBuffer buffer) {CharBuffer charBuffer = null;try {Charset charset = Charset.forName("UTF-8");CharsetDecoder decoder = charset.newDecoder();charBuffer = decoder.decode(buffer);buffer.flip();return charBuffer.toString();} catch (Exception ex) {ex.printStackTrace();return null;}}}
2.利用RabbitMQBolt发送消息
topology main固定bolt输出字段方法:
TupleToMessage msg = new TupleToMessageNonDynamic() {@Overrideprotected byte[] extractBody(Tuple input) {return input.getStringByField("sendMsg").getBytes();}};ProducerConfig sinkConfig = new ProducerConfigBuilder().connection(connectionConfig).contentEncoding("UTF-8").contentType("application/json").exchange("testExchangeOutput").routingKey("").build();builder.setBolt("send-msg-bolt", new RabbitMQBolt(msg)).addConfigurations(sinkConfig.asMap()).shuffleGrouping("my-bolt");
spout多个executor(线程)
spout多个executor(即多线程)处理时,会产生多份数据流输入,例如:
MainClass:
//设置两个Executeor(线程),默认一个builder.setSpout(SENTENCE_SPOUT_ID, spout, 2);
SpoutClass:
private Integer index = 0;private String[] sentences = {"a","b","c"};public void nextTuple() {if (index >= sentences.length) {index = 0;Utils.sleep(1000);return;} else {this.collector.emit(new Values(sentences[index]), index);index++;}Utils.sleep(1);}
boltClass:
public void execute(Tuple input) {String sentence = input.getStringByField("sentence");System.out.println("bolt is workding:" + sentence);}
console:
//spout单线程下(默认单线程):bolt is workding:abolt is workding:bbolt is workding:c//spout设置2个线程情况下bolt is workding:abolt is workding:bbolt is workding:cbolt is workding:abolt is workding:bbolt is workding:c
transient
注意:metric都定义为了transient。因为这些Metric实现都没有实现Serializable,而在storm的spout/bolt中,所有非transient的变量都必须Serializable
Bolt 生命周期
Bolt 是这样一种组件,它把元组作为输入,然后产生新的元组作为输出。实现一个 bolt 时,通常需要实现 IRichBolt 接口。Bolts 对象由客户端机器创建,序列化后提交给集群中的主机。然后集群启动进程反序列化 bolt,调用 prepare****,最后开始处理元组。
Bolt 结构
Bolts拥有如下方法:
declareOutputFields(OutputFieldsDeclarer declarer)为bolt声明输出模式prepare(java.util.Map stormConf, TopologyContext context, OutputCollector collector)仅在bolt开始处理元组之前调用execute(Tuple input)处理输入的单个元组cleanup()在bolt即将关闭时调用
六、计量器
待
七、Storm UI
传送门:Storm UI详解
问题
- spout、bolt对象内,如何避免初始化对象?如何引入访问数据库对象?redis?mongodb?答:http://www.aboutyun.com/forum.php?mod=viewthread&tid=17854
- 如何平行不同的bolt?如何汇总不同的bolt?答:创建拓扑时,同时建立平行不同的bolt,但不同的bolt所创建的tuple,可以引导到同一个bolt处理,但该bolt会创建两份实例,内部对象不共享。
- spout如何对接rabbitmq?答:使用storm-rabbitmq
- storm分布式读取及更新业务配置?答:使用storm config,通过addConfiguration()api添加
- storm streaming传递强类型对象?答:参考例子com.tg.stormgo121.serializable
- 调试与日志:logback如何配置?log日志在集群及本地模式下分别的存放目录?答:p122
