@zhangning16
2018-03-21T10:39:36.000000Z
字数 6762
阅读 663
基于express搭建一个node中间层服务
Node
背景
我们这边有一个后台erp的需求,运营人员在该系统里配置商品,线上展示,由于该项目的用户是内部人员,对服务稳定性的要求稍微低点,所以借此契机,于是进行了这次node中间层的尝试。
在该业务中,node主要做了两件事:
1. 模板文件由前端控制。
2. api的转发。
Node中间层可以给前端带来什么
合并请求:
试想一下这个场景,当我们渲染一块区域,需要从好几个接口中获得数据的时候,如果通过浏览器发送多个请求,会受到浏览器并发请求数量的限制,且浏览器建立http连接的成本比较高。我们就可以通过node中间层,实现前端调用一次我们的node服务接口,node再调用多个接口,最终对数据进行拼接,一次性返回给前端。而且这样后端人员,在接口开发的时候也可以提供数据粒度更加细腻的接口,而不至于与业务强耦合,让接口更加的通用,我们前端需要什么数据,自己去组装就行了!
模板渲染:
现在咱们这边大多业务是采用spa的方式去开发,给后端提供一个vm模板,里面引用咱们的静态资源,页面的渲染完全由js去控制,实现了前后端分离,前后端分工明确,可维护性更强。但是这样也存在弊端,用户看到的白屏时间偏长,先去加载js,js再去发起数据请求,这样无形中增加了用户的等待时间。有了node中间层后,就可以在node中间层里面直接拼接成html页面,返回给浏览器。这样可以明显提高页面的加载速度,而且网速越差,效果越明显。还能够有利于SEO。
不可忽视带来的挑战
Node给了前端更大的能力,可以深入到后端领域,甚至实现全栈开发。但是更大的能力,也带来着更多的挑战,引入node服务,我们需要关注更多的东西,包括但不仅限于线上服务的可用性,服务器的状态等,对前端的能力要求更高!
比如我们做前端开发的时候,可能根本不关注内存泄漏,但是node服务对内存泄漏比较敏感,必须及时释放不再用到的内存。否则,内存占用越来越高,轻则影响系统性能,重则导致进程崩溃。
加了node后的架构

智能助理页面加载整个流程
- 在浏览器输入http://smart-assistant.jd.com/guess-price.html,这时候,根据node服务路由的匹配规则,指向这个智能助理erp的首页。
- 在该首页中,会进行一次获取商品列表的ajax请求。请求http://smart-assistant.jd.com/api/getGoods.json这个地址,node服务接受到这个请求后,会转发这次请求到java服务,同时对浏览器请求携带的cookie透传。
- java服务收到这次请求后,会首先进行一个登录态的验证,如果没有登录,会返回状态码302,前端根据返回的302状态码,手动跳转至通用的erp登录页。
- 如果判断用户已经登录,java会进行第二步判断,判断该用户是否有权限访问该页面,如果没权限,返回状态码302,前端根据返回的302状态码,手动跳转至‘无权访问’页面。
- 如果该用户已经登录,且有权限访问该系统,则会返回用户所需的数据,node拿到数据后再传给浏览器,此时,一次完整的node中间层转发已经完毕。

Node中间层的开发流程
框架选型
我们在做业务的时候,不太可能用原生node,从头开始写项目,目前行业内最火的两个框架就是express和koa。
1. express封装了更多的功能。开发起来比较省心。自带 Router,模板引擎。
2. express历史更悠久,使用人数最多,资料最多,出现问题后能够快速在网上找到解决方案,第三方的中间件也很多。
3. express提供脚手架,一键生成项目框架,省去搭建项目的烦恼。
4. koa是面向未来的框架,抛弃了callback的异步写法,采用异步终极解决方案-async/await,写出来的代码更加优雅,可读性更强。
5. koa更像是一个中间件框架,只提供一个架子,而几乎所有的功能都需要由第三方中间件完成,用户的选择更加灵活,但是也增加了一定的学习成本。
项目工程搭建
首先全局安装express与express-generator。
$ npm install exprss -g$ npm install express-generator -g
创建一个express应用并启动
$ express myapp$ cd myapp$ npm install$ DEBUG=myapp npm start
然后在浏览器中打开 http://localhost:3000/
网址就可以看到这个应用了。
脚手架生成的项目目录的结构如下
.├── app.js // 项目入口文件├── bin // 存放服务器相关的脚本│ └── www├── package.json├── public // 存放静态资源│ ├── images│ ├── javascripts│ └── stylesheets│ └── style.css├── routes // 路由控制部分│ ├── index.js│ └── users.js└── views // 页面模板文件├── error.jade├── index.jade└── layout.jade
express脚手架生成的项目默认是jade模板引擎, 虽然jade模板可以极大的简化模板代码,但是可读性差,学习成本高。 而ejs可读性更强,学习成本几乎为零,并且完美兼容html,你也可以直接书写html,本次由于几乎不需要写模板语法,于是将jade模板引擎替换为ejs。
npm install ejs --save
修改app.js文件里的模板配置代码:
// 设置存放模板文件的路径// 设置模板引擎为ejsapp.set('views', path.join(__dirname, 'views'));app.set('view engine', 'ejs');
模板渲染
有了node这一层后,我们就不用再把模板文件放到java服务里面去了,直接由node服务提供,这样我们就掌握了模板文件的主动权,我们也就可以做一些服务端渲染的工作。而且如果不把模板文件放到node服务里的话,我们后续的接口请求就会存在跨域问题。
如果按照我们开发单页应用的习惯,其实不需要什么模板,我们只需要一个html,里面引用我们的js和css就够了。
比如这样,跟我们之前的开发方式完全一样,js去控制dom的生成,还是纯粹的浏览器渲染。
模板部分:
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><meta http-equiv="X-UA-Compatible" content="ie=edge"><title>ceshi</title></head><body><script>fetch('https://www.easy-mock.com/mock/5a34c925a68e2224f9e94d94/example/demoList').then((res) => {res.json().then((data) => {var list = data.data.list;list.forEach((item, index) => {document.body.innerHTML += `<div>${index}-${item.name}</div>`;})})})</script></body></html>
路由部分:
router.get('/ceshi.html', function(req, res, next) {res.render('ceshi.ejs');});
打开http://localhost:3000/ceshi.html,渲染出来的页面, 很明显是浏览器是通过两次http把这个页面渲染出来的,一次请求html,一次请求页面所需的json数据:

有了node,我们也可以尝试服务端渲染,html直接在服务端拼接完成,这时候模板引擎就派上了用场,同样是刚才的那个页面:
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><meta http-equiv="X-UA-Compatible" content="ie=edge"><title>ceshi</title></head><body>最近上映的电影<ul><% data.list.forEach(function(movie, index){ %><li> <%- index + 1 %> - <%- movie.name %> </li><% }); %></ul></body></html>
路由部分:
router.get('/ceshi2.html', function(req, res, next) {request({url: 'https://www.easy-mock.com/mock/5a34c925a68e2224f9e94d94/example/demoList',method: 'GET'}, (error, response, body) => {res.render('ceshi2.ejs', JSON.parse(response.body));});});
打开http://localhost:3000/ceshi2.html,可以看到,通过服务端渲染,浏览器只与服务端建立起一次http通讯,页面里的数据也是直接在服务端拼接好后,返给前端的。

api转发
下面是一个简单的post请求转发的代码:
router.post('/getGoods.json', function (req, res) {// 用来传递浏览器发起请求携带的cookielet header = {cookie: req.headers.cookie}request({url: 'http://zny-erp.jd.com/asstGuessPrice/list.json',method: 'POST',headers: header,qs: req.body}, (error, response, body) => {if(error) {console.log(error);return;}res.json(JSON.parse(response.body));});});
但是如果仅仅是接口的透传,很多时候是没多大意义的,有时候后端提供的接口不一定能够满足我们的业务需求,比如前端需要的数据需要从多个接口中获取,那么就可以可以在node层做接口合并处理的事,前端浏览器只需要建立起一次http请求,后端收到http请求后,再发起多个请求,等到所有的请求都收到响应后,再将数据合并处理,返回给前端浏览器:
// 生成一个promise对象,这个对象会发起一个网络请求let createXHR = (url) => {return new Promise(function(resolve, reject) {request({url,type: 'GET'}, (err, response, body) => {resolve(body);});});}router.get('/getGoods.json', function(req, res, next) {// 用一个数组存放需要请求的接口地址,有几个地址,就代表几次网络请求var xhrArr = ['https://www.easy-mock.com/mock/5a34c925a68e2224f9e94d94/example/ceshi1','https://www.easy-mock.com/mock/5a34c925a68e2224f9e94d94/example/ceshi2','https://www.easy-mock.com/mock/5a34c925a68e2224f9e94d94/example/ceshi3']// 生成一个Promise对象的数组const promises = xhrArr.map(function (url) {return createXHR(url);});// Promise.all是等所有的promise对象都fulfilled后会触发Promise.all(promises).then((value) => {let result = {};value.map((item)=> {let parsedData;try {parsedData = JSON.parse(item);}catch (e) {res.send('数据获取异常');}Object.assign(result, parsedData.data)});res.json({"data": result});}).catch(function(reason){console.log(reason);return;});});
上述的三个小接口的返回的数据格式大概如下:
{"data": {"key1": "value1"}}
{"data": {"key2": "value2"}}
{"data": {"key3": "value3"}}
打开http://localhost:3000/api/getGoods.json,我们可以看到,经过node这层包装后的数据,就是三个接口响应数据的组合。
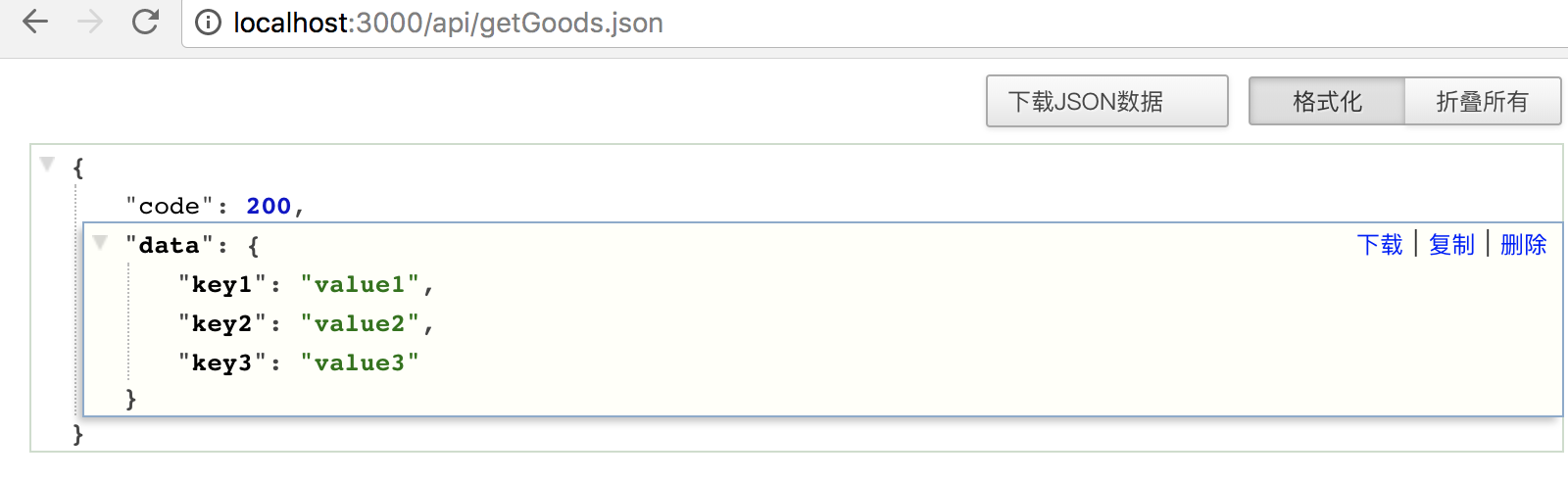
这个时候,我们其实就实现了接口合并, 组合响应数据的整个过程。
上线之后我们还要做什么?
以往,我们写前端项目的时候,上线完成后,这个项目可能也就结束了。但是写node服务,我们在上线后还需要关注线上服务的状态,我们需要有进程守护,日志服务,监控和报警。
进程守护
由于node是单线程的语言,如果异常没有被捕获,那么整个服务就会崩掉,所以我们需要一个工具,能够在服务挂掉后,迅速重启服务。本次采用的进程守护工具是pm2。pm2是一个进程管理器,可以利用它来简化很多node应用管理的繁琐任务,如性能监控、自动重启、负载均衡等,使用起来也很简单,比如这样:
pm2 start app.js
日志服务
日志服务对于服务端开发很重要,因为它记录着程序运行时的各种信息,尤其是线上出现问题后,借助日志系统里的数据,能够快速的定位到问题所在。我们内部有logbook这个系统,接入起来也很简单,具体接入步骤可以看咱们git库里的博客。注意:logbook里面的日志是需要我们在代码里输入了,我们在开发的过程中就应该对一些比较关键的信息预留console.log输出。
logbook日志内容大概就是下面这样:

监控服务
- 监控系统对于服务端开发非常重要,开发人员不可能上线后24小时关注服务的状态,我们需要一个系统帮助我们做这些事,比如:
- 我们需要监控接口是否可用,比如dns解析出现了问题,我们可以通过接口监控,及时暴露接口的异常,不至于用户投诉后,才发现问题。
- 我们需要监控接口响应时间是否过长,通过设定接口响应时长的阈值,比如接口连续的3次请求响应时间都超过2秒钟,监控系统就可以报警,我们就能可以得知这个接口虽然能够使用,但是响应耗时过长,能够帮助我们做优化工作。
- 我们需要知道系统的状态,比如CPU使用率、内存使用情况之类的问题,及时进行服务器扩容。
- 我们需要能够看到接口的调用记录,通过调用记录,我们能够看到各个接口的响应时长,借助响应时长的整体数据,我们就能得知哪些接口需要优化。通过接口的调用次数之类的数据,用来判断用户的访问时间段的分布以及访问高峰期,为业务的优化提供数据支持;甚至借助调用次数的分布,分析异常流量,推断接口在某一时间是不是被恶意调用。
- 在京东内部,我们已经有了比较完善内部的监控系统,比如我这次接入的ump监控系统,相似的还有thor(雷神监控系统)等。对于node 应用而言,我们需要按照要求的格式打印的日志,然后再ump系统里面配置报警,就可以轻松的搞定监控和报警。
- 目前接入的监控:
[1]. 接口存活监控:通过每五分钟一次的轮询,判断接口的存活状态,可以帮助我们在第一时间内处理接口的异常。

[2]. 系统状态监控:内存、CPU等的监控,并设置报警阈值,当系统状态异常时能够及时发现。

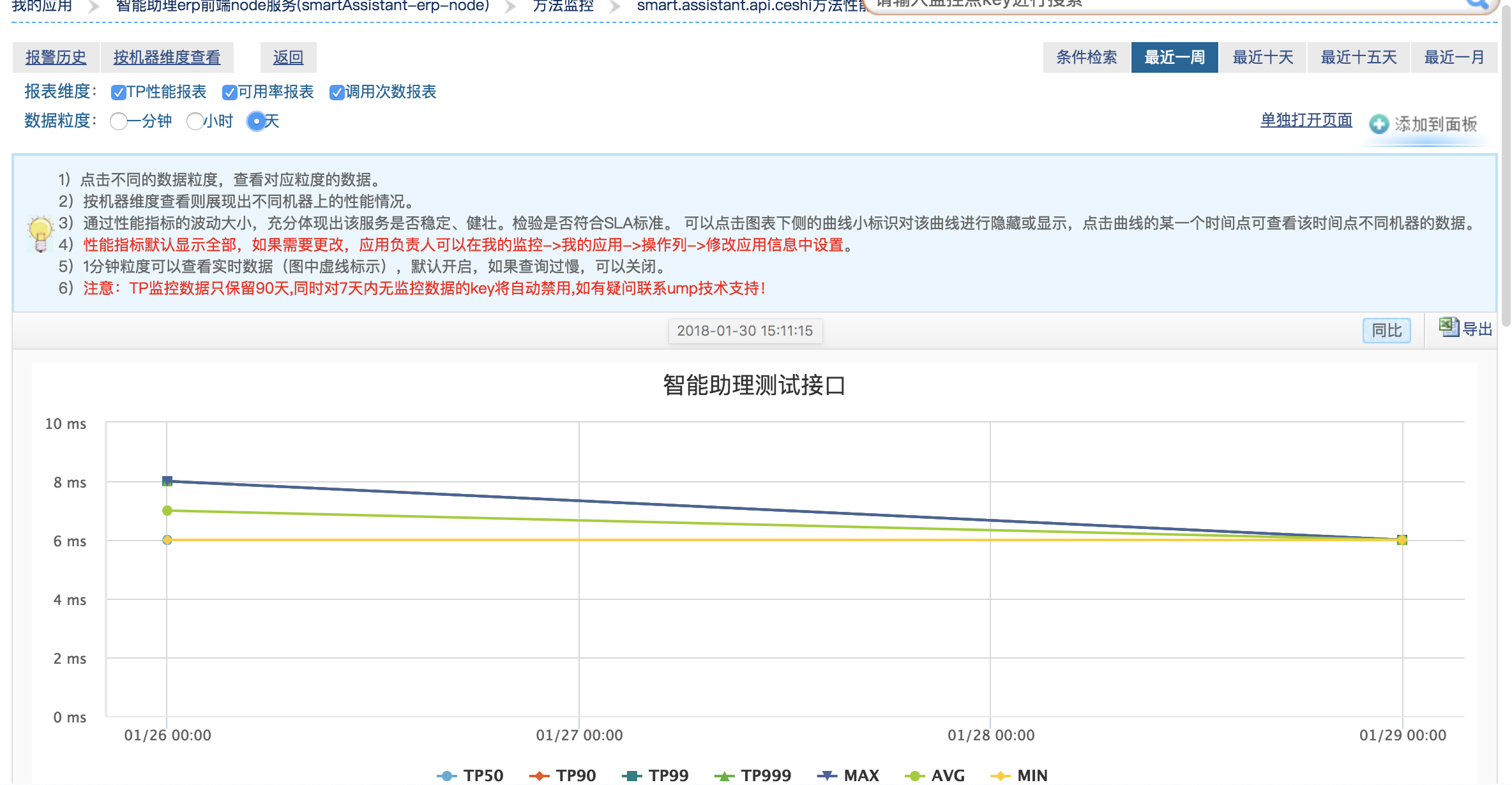
[3]. 应用状态监控:所有的远程调用记录,响应时间以及成功率,时刻了解各个接口的服务状态。比如这样:
可供参考的资料
[1].如何部署 Nodejs 应用
[2].Node服务接入ump监控系统教程
[3].上线必备三大系统:j-one,ump,logbook官方视频教程
