@15311494814
2018-05-17T08:06:00.000000Z
字数 1452
阅读 870
avatar server层 和 数据层分析
avatar
一、server

1,server的账户登录
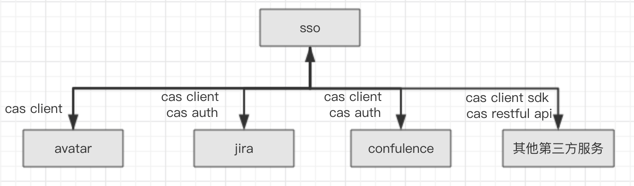
1,所有子系统都不会进行账户的登录登出,统一交给cas集中授权。
2,子系统在进行登录时,交由cas来引导用户进行操作,登录成功后将登录结果返回给子系统,登出时,会通知其他所有子系统进行用户的注销。
1,cas client : cas 客户端的过滤器和监听器,及cas client sdk。
2,cas auth : cas编写的登录验证器,用于替换jira和confulence自身的登录验证器
3,cas restful api : cas 提供了用于统一登录的api。
2,server的账户同步
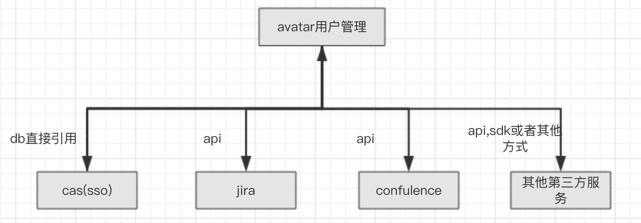
1,avatar的用户管理数据是核心用户数据,cas的数据库直接来自于这里,与avatar使用同一个db。
2,jira,confulence程序本身维护了一个db,因此通过api的方式进行账户同步,即:在avatar的用户管理的数据与jira,confulence中的用户数据保存同步更新。
3,其他第三方会考虑用api或者sdk,datax等方式来进行账户同步。
4,在该集群中,对于自建子项目,会摘除掉子项目中的用户管理模块,交由cas和avatar的用户管理模块统一维护,而对于第三方项目,如果支持cas,那么直接整合即可,如果没有,那么会通过api,sdk等方式来进行维护。
5,钉钉的数据虽然属于第三方,但是由于钉钉的数据与avatar高度耦合,属于avatar产生的数据。
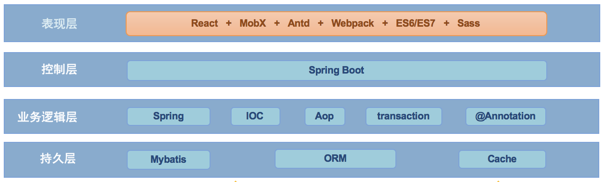
3,技术框架说明
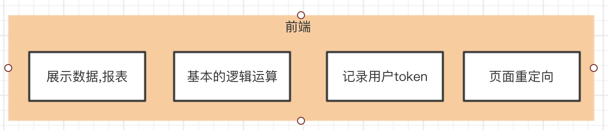
1,前端只做基础逻辑和纯展示,记录用户token,用户的在线状态由后台维护和验证。
2,后台使用spring boot ,集成了cas的客户端,会对每次指定请求进行拦截,验证用户状态。
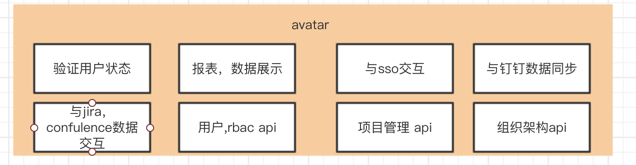
avatar server除了与cas,jira等第三方系统交互外,还管理了用户,rbac,组织架构和项目管理,其中与钉钉进行高度同步,共同维护用户信息。3,用户的登录是由前端重定向到后台,再由后台与cas交互实现的。
4,持久层使用mybatis作为工具,优化的generator作为dao生成器,redis作为缓存,mysql来存储关系型数据。

二、数据仓库
1,数据仓库结构
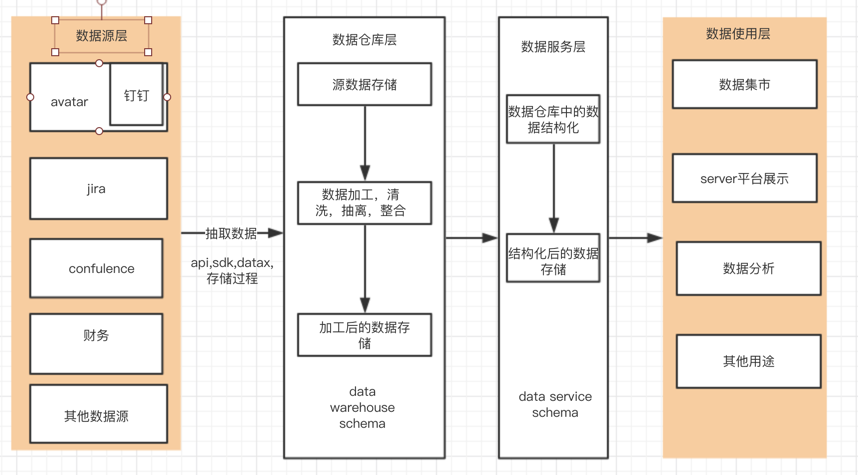
2,数据源层
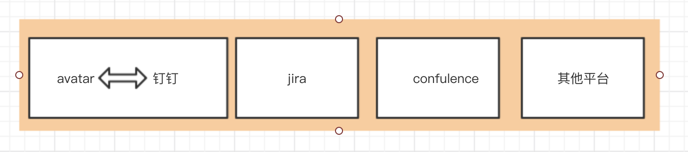
1, jira,confulence,用友,avatar项目等等自身都属于数据源,产生的数据作为原始数据推送到数据仓库进行整合。
2,其中钉钉数据比较特殊,不属于数据源,属于avtar数据。钉钉与avatar的用户管理和组织结构高度耦合,属于同步关系。
3,通过api调用,sdk调用,存储过程,等等方式将产生的数据同步到数据仓库中。
3,数据仓库层
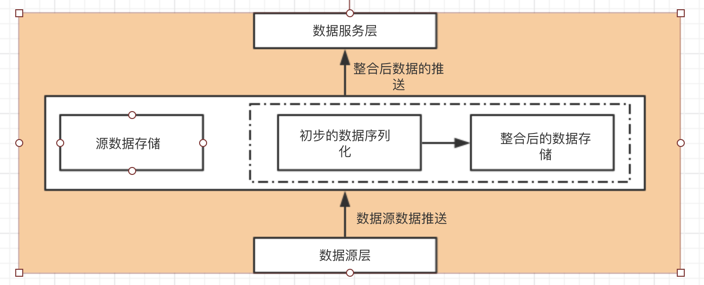
1,数据源推送了数据之后,会存储到数据仓库的data warehouse schema 中。
2,如有需要,会对数据进行序列化和整合,整合后的数据再次存储到schema中。
3,对数据服务层提供的数据为存储的数据源数据和序列化整合后的数据。
4,对于序列化和整合数据,可以单独跑一个服务,来做数据整合。
4,数据服务层
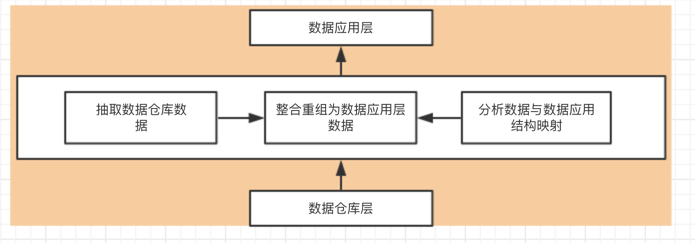
1,抽取数据仓库层中提供数据,并根据服务层存储的数据仓库层与数据应用层数据的对应关系,对数据进行拆分重组,生成结构化的数据,并存储在data service schema中。
2,数据服务层的工作是将数据仓库的数据根据映射关系重组为数据应用层需要的数据。
5,数据应用层
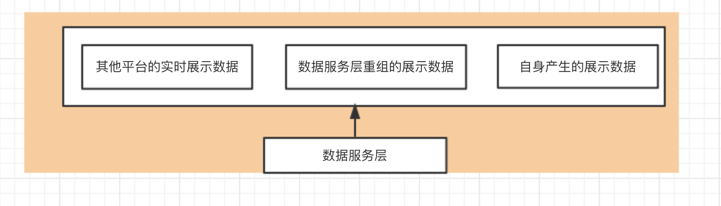
数据应用层数据由三部分组成:
1,其他平台需要展示的实时数据,该数据会实时展示到应用平台,并依旧进入数据仓库.
2,由数据服务层依据映射关系整合重组的展示数据。
3,自身平台产生的数据。
