@2368860385
2021-12-23T05:42:55.000000Z
字数 5921
阅读 226
数据科学导论 笔记
SDU
update: 2021.12
四年真题考过的点:
ETL
各种距离计算(适用)
朴素贝叶斯(ML)
KNN(k个最近邻居判断类别)
K-means(聚类,将相同的元素聚到一起的分类算法)
page rank
pernal rank
gsp vcg
hdfs数据冗余原因
mapreduce map shuffle的过程具体内容
map reduce计算题(计算最大值,每个map求一个最大值传给reduce,reduce再计算)
脏数据(表现语法语义覆盖类)
words of bag(词袋,不计较顺序,每个词对应高维变量的一个位置,统计次数,处理方便容易比较相似性,存在一词多义现象,直接忽略顺序不合理)
关系型数据库再web时代不适用
非关系型数据库(表示,给一个数据然后分解key-value)
entity resolution
大数据的生命周期(采集,表示存储,清洗,集成,分析,展现,决策)
探索性数据分析
大数据相关概念:
1、技术支撑:
1、存储设备容量不断增加
2、CPU处理能力大幅度提升
3、网络带宽不断增加
2、发展阶段:
1、上世纪90年代到本世纪初:数据挖掘理论和数据库技术成熟,数据仓库、专家系统、知识管理系统。
2、本世纪前十年:web2.0的发展迅速,大数据解决方案成熟(并行计算与分布式系统核心技术)。MapReduce Hadoop
3、2010年后:渗透各行各业
3、大数据的概念:
大量化,快速化,多样化,价值化。
4、数据处理的流程:
采集,表示与存储,清洗,集成,分析,展现,决策。
5、数据科学的基本原则:
分析数据,获得知识,从而解决具体的业务问题,是数据科学的核心任务。
对数据分析的结果进行评估,需要具体考虑程序的上下文,结合所处环境进行考虑
6、数据整理
目的:确保数据的质量和数据是有用的。
ETL:用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。
E xtract:从源中提取数据
T ransform: 在源、汇或暂存区转换数据
L oad:将数据加载到汇中
三个阶段:
数据表征
数据清洗
数据集成(ETL中从多个异构的数据源ETL到数据仓库中,这些数据存在异构性以及不一致性,就需要对数据进行集成,数据集成是从多个数据源建立统一的数据库的技术)
任务(需要达到什么要求):在有限的时间内实现传输数组
数据转移
数据序列化和反序列化
7、 数据清洗:
脏数据:不完整,含噪声,不一致的数据。
ETL操作是,如果数据源的数据质量比较差,那么就需要进行数据清洗,解决数据质量问题
清洗的目的是剔除数据中的异常,(语法异常,语义异常,覆盖类异常)
语法异常:(结构、格式,不规则)
语义类异常(取值(违反原则)、计算、重复,无效)
覆盖类异常:(某些东西缺失)
过程:
数据审计,定义数据清洗流,执行数据清洗流,后续处理与控制
具体方法:
数据解析,数据转换,实施完整性约束条件,重复数据清除,一些统计方法。
8、数据集成
把多个数据源的数据进行整合,消除数据源的异构性和差异性。
如数据管理系统的异构性,通信协议的异构性,数据模式的异构性,数据类型的异构性
9、关系型数据库
关系型数据库是依据关系模型来创建的数据库。
所谓关系模型就是“一对一、一对多、多对多”等关系模型,关系模型就是指二维表格模型,因而一个关系型数据库就是由二维表及其之间的联系组成的一个数据组织。
关系型数据可以很好地存储一些关系模型的数据,比如一个老师对应多个学生的数据(“多对多”),一本书对应多个作者(“一对多”),一本书对应一个出版日期(“一对一”)关系模型是我们生活中能经常遇见的模型,存储这类数据一般用关系型数据库关系模型包括数据结构(数据存储的问题,二维表)、操作指令集合(SQL语句)、完整性约束(表内数据约束、表与表之间的约束)。
缺点:占用大量空间,安全状态改变很慢,数据保存磁盘、访问慢,改变关系需要重新添加新的开销,稀疏数据是浪费的、稀疏数据是常见的。不支持分布式
10、非关系型数据库
NoSQL的存储结构导致它根本不需要1 2 3 范式化。一个实体的各属性直接存放在一个键值下。列族用于分类属性。举例:学号===键值 列族1:基础信息(姓名 性别 电话 地址。。。) 列族2:档案信息(身份 学习成绩 。。。) 列族3:专业信息(专业 各科成绩。。。)所以通过一个键值,能直接索引到一个实体的所有信息,不像关系数据库那样需要各种联接查询(联接查询是巨耗费性能的操作) nosql为什么这样设计呢,这主要nosql是在大数据环境下使用。同一个表的数据按键值分段存入不同节点。如果2表的数据肯定更不能集中到一个节点上。那么你要2个表联接查询。。。。想象下那个性能吧(节点间交换数据是通过网络传输的哦)。
但只能应对简单的数据查询,不能应对复杂的数据查询。
例子:https://blog.csdn.net/huojiao2006/article/details/71123914
探索性数据分析
对已有的数据,在尽量少的假定情况下,逐步了解数据的特点,
探索性数据分析对数据进行概括性分析,发现变量之间的相关性,属于归纳法或者演绎法。刚开始对数据一无所知,经过探索性数据分析了解特点,建立模型,利用数据进行模型训练,然后评价该模型。
基本方法:包括两种汇总统计量和制图、制表。
汇总量的计算:均值、中位数、众数、切尾均值,典型值、最大值、最小值、上下四分位数、数据范围。
制图和制表:变量分布情况、变化趋势,变量之间的关系。
机器学习
KNN(k个最邻近的邻居)
欧几里得距离:
曼哈顿距离:
余弦距离:
汉明距离: 即不同元素的个数
杰卡德距离:
相似性:交集/并集
杰卡德距离描述的差异性,所以是1-交集/并集
切比雪夫距离:
算法思路:
选取一个k,然后选取找到k个最近的点,看这些点有什么特点,这个点可能也就有这些特点。
比如向知道这个人的学历,随机选择他最邻近的k个人,看是什么学历,他就可能什么学历。
k的取值,k从小到大的过程错误率首先会降低,因为数据多了,其次再增多错误率又会上升。
K means/聚类
牧师—村民模型:
有四个牧师去郊区布道,一开始牧师们随意选了几个布道点,并且把这几个布道点的情况公告给了郊区所有的村民,于是每个村民到离自己家最近的布道点去听课。
听课之后,大家觉得距离太远了,于是每个牧师统计了一下自己的课上所有的村民的地址,搬到了所有地址的中心地带,并且在海报上更新了自己的布道点的位置。
牧师每一次移动不可能离所有人都更近,有的人发现A牧师移动以后自己还不如去B牧师处听课更近,于是每个村民又去了离自己最近的布道点……
就这样,牧师每个礼拜更新自己的位置,村民根据自己的情况选择布道点,最终稳定了下来。
步骤
1、选择初始化的 k 个样本作为初始聚类中心 a1,a2,...ak;
2、针对数据集中每个样本 xi 计算它到 k 个聚类中心的距离并将其分到距离最小的聚类中心所对应的类中;
3、针对每个类别 aj,重新计算它的聚类中心 (即属于该类的所有样本的质心);
4、重复上面 2 3 两步操作,直到达到某个中止条件(迭代次数、最小误差变化等)。
2.1 优点
容易理解,聚类效果不错,虽然是局部最优, 但往往局部最优就够了;
处理大数据集的时候,该算法可以保证较好的伸缩性;
当簇近似高斯分布的时候,效果非常不错;
算法复杂度低。
2.2 缺点
K 值需要人为设定,不同 K 值得到的结果不一样;
对初始的簇中心敏感,不同选取方式会得到不同结果;
对异常值敏感;
样本只能归为一类,不适合多分类任务;
不适合太离散的分类、样本类别不平衡的分类、非凸形状的分类。
最佳聚类数3
朴素贝叶斯
优点:简单快速,稀疏数据良好
缺点:易受错误偏见影响,不那么准确,不能模型化
对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。通俗来说,就好比这么个道理,你在街上看到一个黑人,我问你你猜这哥们哪里来的,你十有八九猜非洲。为什么呢?因为黑人中非洲人的比率最高,当然人家也可能是美洲人或亚洲人,但在没有其它可用信息下,我们会选择条件概率最大的类别,这就是朴素贝叶斯的思想基础。
根据某社区网站的抽样统计,该站10000个账号中有89%为真实账号(设为C0),11%为虚假账号(设为C1)。
C0 = 0.89
C1 = 0.11
接下来,就要用统计资料判断一个账号的真实性。假定某一个账号有以下三个特征:
F1: 日志数量/注册天数
F2: 好友数量/注册天数
F3: 是否使用真实头像(真实头像为1,非真实头像为0)
F1 = 0.1
F2 = 0.2
F3 = 0
请问该账号是真实账号还是虚假账号?
方法是使用朴素贝叶斯分类器,计算下面这个计算式的值。
P(F1|C)P(F2|C)P(F3|C)P(C)
虽然上面这些值可以从统计资料得到,但是这里有一个问题:F1和F2是连续变量,不适宜按照某个特定值计算概率。
一个技巧是将连续值变为离散值,计算区间的概率。比如将F1分解成[0, 0.05]、(0.05, 0.2)、[0.2, +∞]三个区间,然后计算每个区间的概率。在我们这个例子中,F1等于0.1,落在第二个区间,所以计算的时候,就使用第二个区间的发生概率。
根据统计资料,可得:
P(F1|C0) = 0.5, P(F1|C1) = 0.1
P(F2|C0) = 0.7, P(F2|C1) = 0.2
P(F3|C0) = 0.2, P(F3|C1) = 0.9
因此,
P(F1|C0) P(F2|C0) P(F3|C0) P(C0)
= 0.5 x 0.7 x 0.2 x 0.89
= 0.0623
P(F1|C1) P(F2|C1) P(F3|C1) P(C1)
= 0.1 x 0.2 x 0.9 x 0.11
= 0.00198
可以看到,虽然这个用户没有使用真实头像,但是他是真实账号的概率,比虚假账号高出30多倍,因此判断这个账号为真。
自然语言处理
bag of words 词袋模型
统计每个单词出现的次数
Bag-of-words词袋模型最初被用在信息检索领域,对于一篇文档来说,假定不考虑文档内的词的顺序关系和语法,只考虑该文档是否出现过这个单词。假设有5类主题,我们的任务是来了一篇文档,判断它属于哪个主题。在训练集中,我们有若干篇文档,它们的主题类型是已知的。我们从中选出一些文档,每篇文档内有一些词,我们利用这些词来构建词袋。我们的词袋可以是这种形式:{‘watch’,'sports','phone','like','roman',……},然后每篇文档都可以转化为以各个单词作为横坐标,以单词出现的次数为纵坐标的直方图,如下图所示,之后再进行归一化,将每个词出现的频数作为文档的特征。
n - gram
https://www.zhihu.com/question/357850262
假设有一个字符串s,那么该字符串的N-Grams就表示按长度 N 切分原词得到的词段,也就是s中所有长度为 N 的子字符串。设想如果有两个字符串,然后分别求它们的N-Grams,那么就可以从它们的共有子串的数量这个角度去定义两个字符串间的N-Gram距离。举个例子(N=2): China:
Ch,hi,in,naChinese:Ch,hi,in,ne,es,se
发现有三个词段相同,所以两个字符串的N-Grams距离为3。
China有3/4的可能性与Chinese表达相同的意思,但事实并非如此。
问题就在于,原来的算法忽视了每个字符串本身的长度,无法精准地表示两个字符串的相似度。引出新的N-Grams计算方法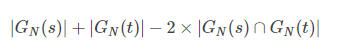
第一个字符串的长度,这里为4;
第二个字符串的长度,这里为6;
N-Grams = 4+6 - 2 * 3 = 4
由新的计算方法可知,当两个词完全相同时,N-Grams为0(最优结果)。字符串之间的距离(N-Grams)越小,它们就越接近。Python实例:
https://blog.csdn.net/songbinxu/article/details/80209197
TF IDF
词频 TF = 该词在文档中的次数/总词数
逆文档频率 IDF =
TF - IDF = TF * IDF
图推荐算法
https://blog.csdn.net/weixin_41481113/article/details/83449884
pagerank
personnal rank
Hadoop - HDFS 分布式文件系统
把文件存储到多个计算机节点上,成千上万的计算机通过光纤构成计算机集群。
块
一个文件被分成很多块,以块为存储单位。
好处:
1、支持大规模文件存储,可以将大文件分成若干份,保存到不同节点上;
2、简化程序设计,文件块大小固定,很容易计算出一个节点可以存储多块。
3、适合文件备份,每个文件块都被存储到多个节点上,提高系统容错性。
名称节点和数据节点
HDFS只有一个名称节点,负责管理分布式文件系统的命名空间。含有两个数据结构fslmage(维护文件系统书树以及树中的文件,操作日志文件)和editlog(记录了所有针对文件的创建、删除、重命名操作)
数据节点:负责数据的存储、读取等。
只有一个名称节点的局限性:
1、命名空间受到限制:名称节点保存到内存中,能容纳的对象(文件、块)的个数受到限制。
2、性能:整个分布式文件系统的吞吐量受限于 名称节点的吞吐量
3、隔离问题:只有一个名称节点,一个命名空间,无法对应用程序隔离。
4、集群的可用性,一旦名称节点发生故障,整个集群都会不可用。
冗余数据保存
一个数据块被存储到多个数据节点上。
1、加快数据传输速度
2、容易检查数据错误
3、保证数据的可靠性
