@Bios
2020-06-28T09:20:43.000000Z
字数 38818
阅读 1697
前端高手进阶
前端 js
模块一:前端核心基础知识
第01讲:你真的熟悉HTML标签吗?
本课时主要讲解那些“看不见”的 HTML 标签。
提到 HTML 标签,前端工程师会非常熟悉,因为在开发页面时经常使用。但往往关注更多的是页面渲染效果及交互逻辑,也就是对用户可见可操作的部分,比如表单、菜单栏、列表、图文。
其实还有一些非常重要却容易被忽视的标签,这些标签大多数用在页面头部 head 标签内,虽然对用户不可见,但如果在某些场景下,比如交互实现、性能优化、搜索优化,合理利用它们就可以达到事半功倍的效果。
这一课时就和你来聊聊那些“看不见”的 HTML 标签及其使用场景。
交互实现
我经常会向我的团队成员提倡一个编码原则:Less code, less bug。
在实现一个功能的时候,我们编写的代码越多,不仅开发成本越高,而且代码的健壮性也越差。
它和 KISS(Keep it simple, stupid)原则及奥卡姆剃刀原则(如无必要,勿增实体)有相同的意思,都是提倡编码简约。
下面介绍几个标签,来看看如何帮助我们更简单地实现一些页面交互效果。
meta 标签:自动刷新/跳转
假设要实现一个类似 PPT 自动播放的效果,你很可能会想到使用 JavaScript 定时器控制页面跳转来实现。但其实有更加简洁的实现方法,比如通过 meta 标签来实现:
<meta http-equiv="Refresh" content="5; URL=page2.html">
上面的代码会在 5s 之后自动跳转到同域下的 page2.html 页面。我们要实现 PPT 自动播放的功能,只需要在每个页面的 meta 标签内设置好下一个页面的地址即可。
另一种场景,比如每隔一分钟就需要刷新页面的大屏幕监控,也可以通过 meta 标签来实现,只需去掉后面的 URL 即可:
<meta http-equiv="Refresh" content="60">
细心的你可能会好奇,既然这样做又方便又快捷,为什么这种用法比较少见呢?
一方面是因为不少前端工程师对 meta 标签用法缺乏深入了解,另一方面也是因为在使用它的时候,刷新和跳转操作是不可取消的,所以对刷新时间间隔或者需要手动取消的,还是推荐使用 JavaScript 定时器来实现。但是,如果你只是想实现页面的定时刷新或跳转(比如某些页面缺乏访问权限,在 x 秒后跳回首页这样的场景)建议你可以实践下 meta 标签的用法。
title 标签与 Hack 手段:消息提醒
作为前端工程师的你对 B/S 架构肯定不陌生,它有很多的优点,比如版本更新方便、跨平台、跨终端,但在处理某些场景,比如即时通信场景时,就会变得比较麻烦。
因为前后端通信深度依赖 HTTP 协议,而 HTTP 协议采用“请求-响应”模式,这就决定了服务端也只能被动地发送数据。一种低效的解决方案是客户端通过轮询机制获取最新消息(HTML5 下可使用 WebSocket 协议)。
消息提醒功能实现则比较困难,HTML5 标准发布之前,浏览器没有开放图标闪烁、弹出系统消息之类的接口,只能借助一些 Hack 的手段,比如修改 title 标签来达到类似的效果(HTML5 下可使用 Web Notifications API 弹出系统消息)。
下面这段代码中,通过定时修改 title 标签内容,模拟了类似消息提醒的闪烁效果:
let msgNum = 1 // 消息条数let cnt = 0 // 计数器const inerval = setInterval(() => {cnt = (cnt + 1) % 2if(msgNum===0) {// 通过DOM修改titledocument.title += `聊天页面`clearInterval(interval)return}const prefix = cnt % 2 ? `新消息(${msgNum})` : ''document.title = `${prefix}聊天页面`}, 1000)
实现效果如下图所示,可以看到标签名称上有提示文字在闪烁。

通过模拟消息闪烁,可以让用户在浏览其他页面的时候,及时得知服务端返回的消息。
定时修改 title 标签内容,除了用来实现闪烁效果之外,还可以制作其他动画效果,比如文字滚动,但需要注意浏览器会对 title 标签文本进行去空格操作。
动态修改 title 标签的用途不仅在于消息提醒,你还可以将一些关键信息显示到标签上(比如下载时的进度、当前操作步骤),从而提升用户体验。
性能优化
性能优化是前端开发中避不开的问题,性能问题无外乎两方面原因:渲染速度慢、请求时间长。性能优化虽然涉及很多复杂的原因和解决方案,但其实只要通过合理地使用标签,就可以在一定程度上提升渲染速度以及减少请求时间。
script 标签:调整加载顺序提升渲染速度
由于浏览器的底层运行机制,渲染引擎在解析 HTML 时,若遇到 script 标签引用文件,则会暂停解析过程,同时通知网络线程加载文件,文件加载后会切换至 JavaScript 引擎来执行对应代码,代码执行完成之后切换至渲染引擎继续渲染页面。
在这一过程中可以看到,页面渲染过程中包含了请求文件以及执行文件的时间,但页面的首次渲染可能并不依赖这些文件,这些请求和执行文件的动作反而延长了用户看到页面的时间,从而降低了用户体验。
为了减少这些时间损耗,可以借助 script 标签的 3 个属性来实现。
- async 属性。立即请求文件,但不阻塞渲染引擎,而是文件加载完毕后阻塞渲染引擎并立即执行文件内容。
- defer 属性。立即请求文件,但不阻塞渲染引擎,等到解析完 HTML 之后再执行文件内容。
- HTML5 标准 type 属性,对应值为“module”。让浏览器按照 ECMA Script 6 标准将文件当作模块进行解析,默认阻塞效果同 defer,也可以配合 async 在请求完成后立即执行。
具体效果可以参看下图:
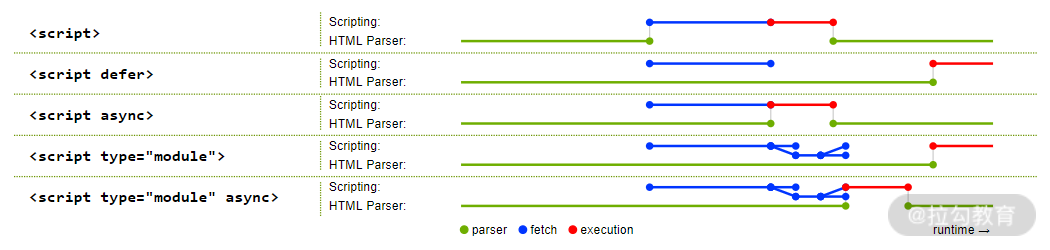
其中,绿色的线表示执行解析 HTML ,蓝色的线表示请求文件,红色的线表示执行文件。
从图中可以得知,采用 3 种属性都能减少请求文件引起的阻塞时间,只有 defer 属性以及 type="module" 情况下能保证渲染引擎的优先执行,从而减少执行文件内容消耗的时间,让用户更快地看见页面(即使这些页面内容可能并没有完全地显示)。
除此之外还应当注意,当渲染引擎解析 HTML 遇到 script 标签引入文件时,会立即进行一次渲染。所以这也就是为什么构建工具会把编译好的引用 JavaScript 代码的 script 标签放入到 body 标签底部,因为当渲染引擎执行到 body 底部时会先将已解析的内容渲染出来,然后再去请求相应的 JavaScript 文件。如果是内联脚本(即不通过 src 属性引用外部脚本文件直接在 HTML 编写 JavaScript 代码的形式),渲染引擎则不会渲染。
link 标签:通过预处理提升渲染速度
在我们对大型单页应用进行性能优化时,也许会用到按需懒加载的方式,来加载对应的模块,但如果能合理利用 link 标签的 rel 属性值来进行预加载,就能进一步提升渲染速度。
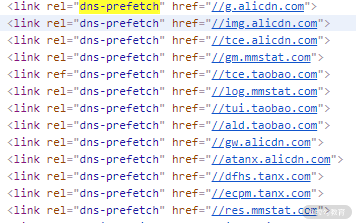
- dns-prefetch。当 link 标签的 rel 属性值为“dns-prefetch”时,浏览器会对某个域名预先进行 DNS 解析并缓存。这样,当浏览器在请求同域名资源的时候,能省去从域名查询 IP 的过程,从而减少时间损耗。下图是淘宝网设置的 DNS 预解析。
- preconnect。让浏览器在一个 HTTP 请求正式发给服务器前预先执行一些操作,这包括 DNS 解析、TLS 协商、TCP 握手,通过消除往返延迟来为用户节省时间。
- prefetch/preload。两个值都是让浏览器预先下载并缓存某个资源,但不同的是,prefetch 可能会在浏览器忙时被忽略,而 preload 则是一定会被预先下载。
- prerender。浏览器不仅会加载资源,还会解析执行页面,进行预渲染。
这几个属性值恰好反映了浏览器获取资源文件的过程,在这里我绘制了一个流程简图,方便你记忆。
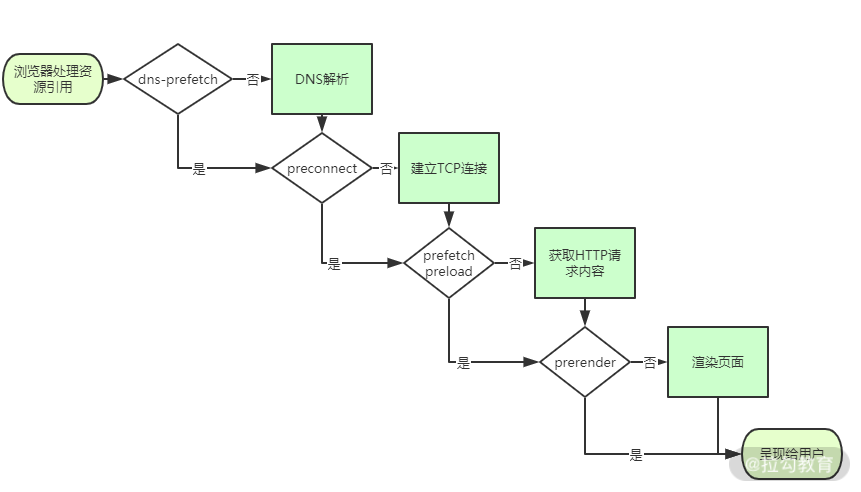
浏览器获取资源文件的流程
搜索优化
你所写的前端代码,除了要让浏览器更好执行,有时候也要考虑更方便其他程序(如搜索引擎)理解。合理地使用 meta 标签和 link 标签,恰好能让搜索引擎更好地理解和收录我们的页面。
meta 标签:提取关键信息
通过 meta 标签可以设置页面的描述信息,从而让搜索引擎更好地展示搜索结果。
例如,在百度中搜索“拉勾”,就会发现网站的描述信息,这些描述信息就是通过 meta 标签专门为搜索引擎设置的,目的是方便用户预览搜索到的结果。
为了让搜索引擎更好地识别页面,除了描述信息之外还可以使用关键字,这样即使页面其他地方没有包含搜索内容,也可以被搜索到(当然搜索引擎有自己的权重和算法,如果滥用关键字是会被降权的,比如 Google 引擎就会对堆砌大量相同关键词的网页进行惩罚,降低它被搜索到的权重)。
当我们搜索关键字“垂直互联网招聘”的时候搜索结果会显示拉勾网的信息,虽然显示的搜索内容上并没有看到“垂直互联网招聘”字样,这就是因为拉勾网页面中设置了这个关键字。
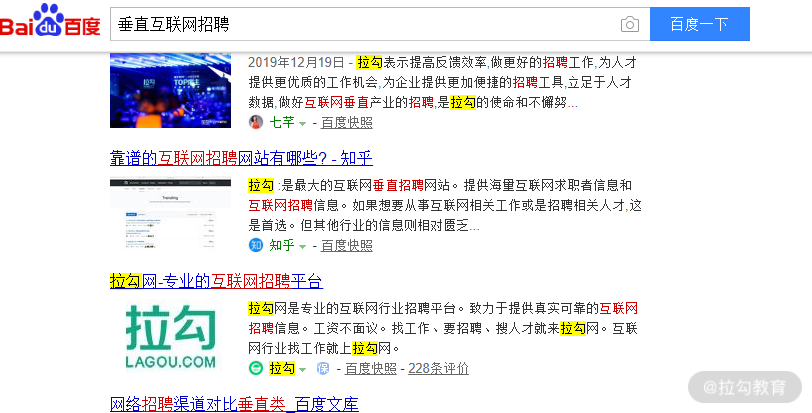
对应代码如下:
<meta content="拉勾,拉勾网,拉勾招聘,拉钩, 拉钩网 ,互联网招聘,拉勾互联网招聘, 移动互联网招聘, 垂直互联网招聘, 微信招聘, 微博招聘, 拉勾官网, 拉勾百科,跳槽, 高薪职位, 互联网圈子, IT招聘, 职场招聘, 猎头招聘,O2O招聘, LBS招聘, 社交招聘, 校园招聘, 校招,社会招聘,社招" name="keywords">
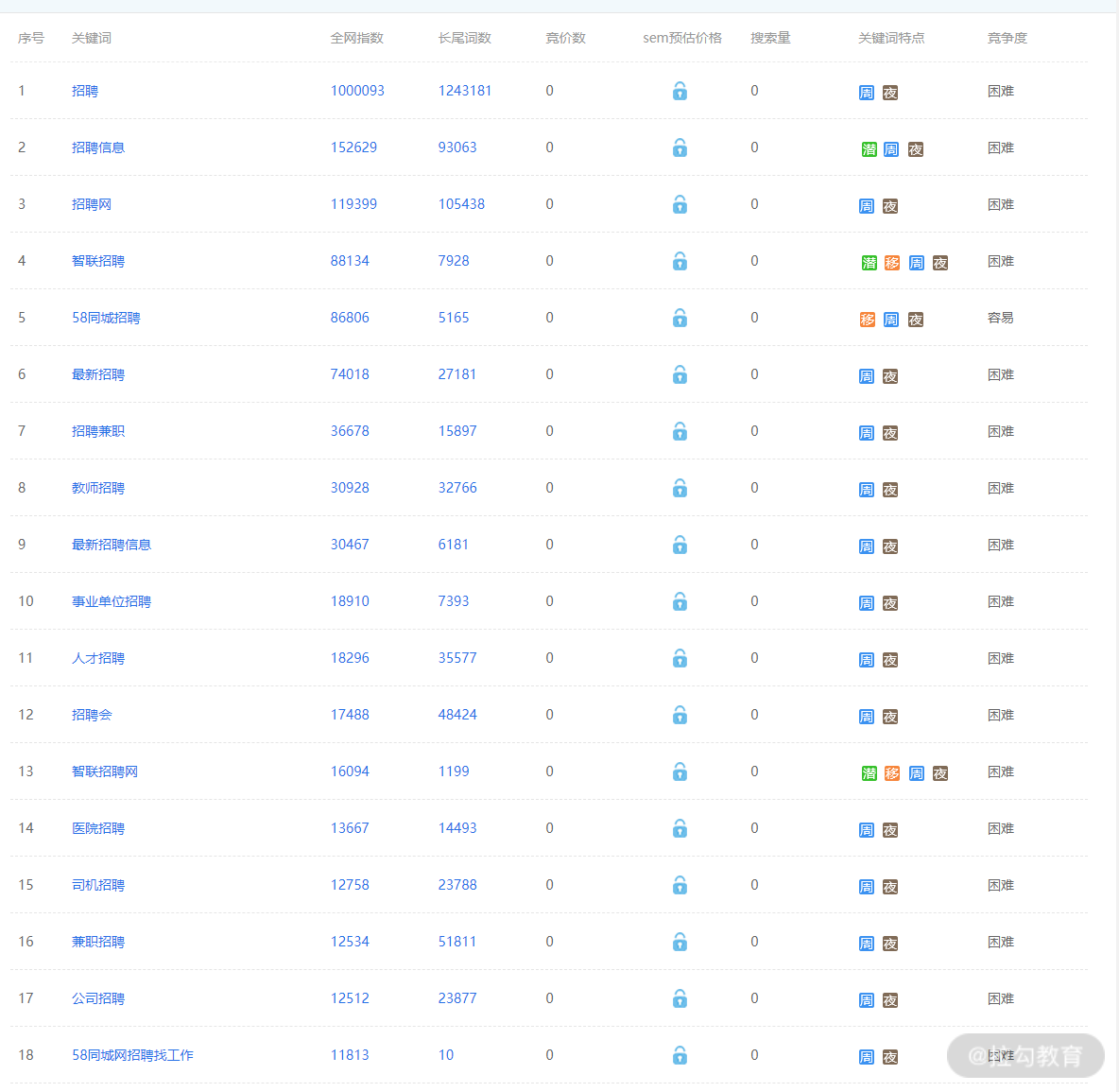
在实际工作中,推荐使用一些关键字工具来挑选,比如 Google Trends、站长工具。下图是我使用站长工具搜索“招聘”关键字得到的结果,可以看到得到了相当关键的一些信息,比如全网搜索指数、关键词特点。
link 标签:减少重复
有时候为了用户访问方便或者出于历史原因,对于同一个页面会有多个网址,又或者存在某些重定向页面,比如:
那么在这些页面中可以这样设置:
<link href="https://xx.com/a.html" rel="canonical">
这样可以让搜索引擎避免花费时间抓取重复网页。不过需要注意的是,它还有个限制条件,那就是指向的网站不允许跨域。
当然,要合并网址还有其他的方式,比如使用站点地图,或者在 HTTP 请求响应头部添加 rel="canonical"。这里,我就不展开介绍了,道理都是相通的,你平时可以多探索和实践。
延伸内容:OGP(开放图表协议)

好了,前面我们说了 HTML5 标准的一些标签和属性,下面再延伸说一说基于 meta 标签扩展属性值实现的第三方协议——OGP(Open Graph Protocal,开放图表协议 )。
OGP 是 Facebook 公司在 2010 年提出的,目的是通过增加文档信息来提升社交网页在被分享时的预览效果。你只需要在一些分享页面中添加一些 meta 标签及属性,支持 OGP 协议的社交网站就会在解析页面时生成丰富的预览信息,比如站点名称、网页作者、预览图片。具体预览效果会因各个网站而有所变化。
下面是微信文章支持 OGP 协议的代码,可以看到通过 meta 标签属性值声明了:网址、预览图片、描述信息、站点名称、网页类型和作者信息。

现在百度已经宣布支持,微信文章的不少页面上也添加了相关标签属性,有兴趣的话你可以查看官方网站:https://ogp.me/。
总结
本课时,我从交互实现、性能优化、搜索优化场景出发,分别讲解了 meta 标签、title 标签、link 标签,以及 script 标签在这些场景中的重要作用,希望这些内容你都能有效地应用到工作场景中,不再只是了解,而是能够熟练运用。
最后布置一道思考题:说一说你还知道哪些“看不见”的标签及用法?
第02讲:如何高效操作 DOM 元素?
什么是 DOM
DOM(Document Object Model,文档对象模型)是 JavaScript 操作 HTML 的接口(这里只讨论属于前端范畴的 HTML DOM),属于前端的入门知识,同样也是核心内容,因为大部分前端功能都需要借助 DOM 来实现,比如:
- 动态渲染列表、表格表单数据;
- 监听点击、提交事件;
- 懒加载一些脚本或样式文件;
- 实现动态展开树组件,表单组件级联等这类复杂的操作。
如果你查看过 DOM V3 标准,会发现包含多个内容,但归纳起来常用的主要由 3 个部分组成:
- DOM 节点
- DOM 事件
- 选择区域
选择区域的使用场景有限,一般用于富文本编辑类业务,我们不做深入讨论;DOM 事件有一定的关联性,将在下一课时中详细讨论;对于 DOM 节点,需与另外两个概念标签和元素进行区分:
- 标签是 HTML 的基本单位,比如 p、div、input;
- 节点是 DOM 树的基本单位,有多种类型,比如注释节点、文本节点;
- 元素是节点中的一种,与 HTML 标签相对应,比如 p 标签会对应 p 元素。
举例说明,在下面的代码中,“p” 是标签, 生成 DOM 树的时候会产生两个节点,一个是元素节点 p,另一个是字符串为“亚里士朱德”的文本节点。
<p>亚里士朱德</p>
会框架更要会 DOM
有的前端工程师因为平常使用 Vue、React 这些框架比较多,觉得直接操作 DOM 的情况比较少,认为熟悉框架就行,不需要详细了解 DOM。这个观点对于初级工程师而言确实如此,能用框架写页面就算合格。
但对于屏幕前想成为高级/资深前端工程师的你而言,只会使用某个框架或者能答出 DOM 相关面试题,这些肯定是不够的。恰恰相反,作为高级/资深前端工程师,不仅应该对 DOM 有深入的理解,还应该能够借此开发框架插件、修改框架甚至能写出自己的框架。
因此,这一课时我们就深入了解 DOM,谈谈如何高效地操作 DOM。
为什么说 DOM 操作耗时
要解释 DOM 操作带来的性能问题,我们不得不提一下浏览器的工作机制。
线程切换
如果你对浏览器结构有一定了解,就会知道浏览器包含渲染引擎(也称浏览器内核)和 JavaScript 引擎,它们都是单线程运行。单线程的优势是开发方便,避免多线程下的死锁、竞争等问题,劣势是失去了并发能力。
浏览器为了避免两个引擎同时修改页面而造成渲染结果不一致的情况,增加了另外一个机制,这两个引擎具有互斥性,也就是说在某个时刻只有一个引擎在运行,另一个引擎会被阻塞。操作系统在进行线程切换的时候需要保存上一个线程执行时的状态信息并读取下一个线程的状态信息,俗称上下文切换。而这个操作相对而言是比较耗时的。
每次 DOM 操作就会引发线程的上下文切换——从 JavaScript 引擎切换到渲染引擎执行对应操作,然后再切换回 JavaScript 引擎继续执行,这就带来了性能损耗。单次切换消耗的时间是非常少的,但是如果频繁的大量切换,那么就会产生性能问题。
比如下面的测试代码,循环读取一百万次 DOM 中的 body 元素的耗时是读取 JSON 对象耗时的 10 倍。
// 测试次数:一百万次const times = 1000000// 缓存body元素console.time('object')let body = document.body// 循环赋值对象作为对照参考for(let i=0;i<times;i++) {let tmp = body}console.timeEnd('object')// object: 1.77197265625msconsole.time('dom')// 循环读取body元素引发线程切换for(let i=0;i<times;i++) {let tmp = document.body}console.timeEnd('dom')// dom: 18.302001953125ms
虽然这个例子比较极端,循环次数有些夸张,但如果在循环中包含一些复杂的逻辑或者说涉及到多个元素时,就会造成不可忽视的性能损耗。
重新渲染
另一个更加耗时的因素是元素及样式变化引起的再次渲染,在渲染过程中最耗时的两个步骤为重排(Reflow)与重绘(Repaint)。
浏览器在渲染页面时会将 HTML 和 CSS 分别解析成 DOM 树和 CSSOM 树,然后合并进行排布,再绘制成我们可见的页面。如果在操作 DOM 时涉及到元素、样式的修改,就会引起渲染引擎重新计算样式生成 CSSOM 树,同时还有可能触发对元素的重新排布(简称“重排”)和重新绘制(简称“重绘”)。
可能会影响到其他元素排布的操作就会引起重排,继而引发重绘,比如:
- 修改元素边距、大小
- 添加、删除元素
- 改变窗口大小
与之相反的操作则只会引起重绘,比如:
- 设置背景图片
- 修改字体颜色
- 改变 visibility 属性值
如果想了解更多关于重绘和重排的样式属性,可以参看这个网址:https://csstriggers.com/。
下面是两段验证代码,我们通过 Chrome 提供的性能分析工具来对渲染耗时进行分析。
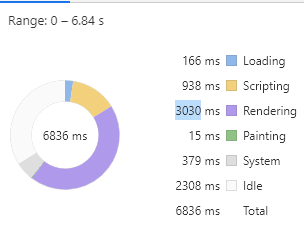
第一段代码,通过修改 div 元素的边距来触发重排,渲染耗时(粗略地认为渲染耗时为紫色 Rendering 事件和绿色 Painting 事件耗时之和)3045 毫秒。
const times = 100000let html = ''for(let i=0;i<times;i++) {html+= `<div>${i}</div>`}document.body.innerHTML += htmlconst divs = document.querySelectorAll('div')Array.prototype.forEach.call(divs, (div, i) => {div.style.margin = i % 2 ? '10px' : 0;})
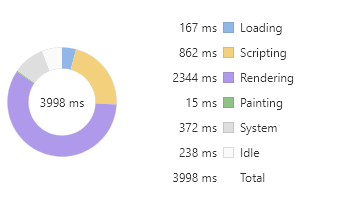
第二段代码,修改 div 元素字体颜色来触发重绘,得到渲染耗时 2359 ms。
const times = 100000let html = ''for(let i=0;i<times;i++) {html+= `<div>${i}</div>`}document.body.innerHTML += htmlconst divs = document.querySelectorAll('div')Array.prototype.forEach.call(divs, (div, i) => {div.style.color = i % 2 ? 'red' : 'green';})
从两段测试代码中可以看出,重排渲染耗时明显高于重绘,同时两者的 Painting 事件耗时接近,也应证了重排会导致重绘。
如何高效操作 DOM
明白了 DOM 操作耗时之处后,要提升性能就变得很简单了,反其道而行之,减少这些操作即可。
在循环外操作元素
比如下面两段测试代码对比了读取 1000 次 JSON 对象以及访问 1000 次 body 元素的耗时差异,相差一个数量级。
const times = 10000;console.time('switch')for (let i = 0; i < times; i++) {document.body === 1 ? console.log(1) : void 0;}console.timeEnd('switch') // 1.873046875msvar body = JSON.stringify(document.body)console.time('batch')for (let i = 0; i < times; i++) {body === 1 ? console.log(1) : void 0;}console.timeEnd('batch') // 0.846923828125ms
批量操作元素
比如说要创建 1 万个 div 元素,在循环中直接创建再添加到父元素上耗时会非常多。如果采用字符串拼接的形式,先将 1 万个 div 元素的 html 字符串拼接成一个完整字符串,然后赋值给 body 元素的 innerHTML 属性就可以明显减少耗时。
const times = 10000;console.time('createElement')for (let i = 0; i < times; i++) {const div = document.createElement('div')document.body.appendChild(div)}console.timeEnd('createElement')// 54.964111328125msconsole.time('innerHTML')let html=''for (let i = 0; i < times; i++) {html+='<div></div>'}document.body.innerHTML += html // 31.919921875msconsole.timeEnd('innerHTML')
虽然通过修改 innerHTML 来实现批量操作的方式效率很高,但它并不是万能的。比如要在此基础上实现事件监听就会略微麻烦,只能通过事件代理或者重新选取元素再进行单独绑定。批量操作除了用在创建元素外也可以用于修改元素属性样式,比如下面的例子。
创建 2 万个 div 元素,以单节点树结构进行排布,每个元素有一个对应的序号作为文本内容。现在通过 style 属性对第 1 个 div 元素进行 2 万次样式调整。下面是直接操作 style 属性的代码:
const times = 20000;let html = ''for (let i = 0; i < times; i++) {html = `<div>${i}${html}</div>`}document.body.innerHTML += htmlconst div = document.querySelector('div')for (let i = 0; i < times; i++) {div.style.fontSize = (i % 12) + 12 + 'px'div.style.color = i % 2 ? 'red' : 'green'div.style.margin = (i % 12) + 12 + 'px'}
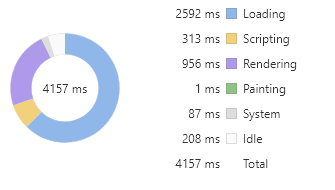
如果将需要修改的样式属性放入 JavaScript 数组,然后对这些修改进行 reduce 操作,得到最终需要的样式之后再设置元素属性,那么性能会提升很多。代码如下:
const times = 20000;let html = ''for (let i = 0; i < times; i++) {html = `<div>${i}${html}</div>`}document.body.innerHTML += htmllet queue = [] // 创建缓存样式的数组let microTask // 执行修改样式的微任务const st = () => {const div = document.querySelector('div')// 合并样式const style = queue.reduce((acc, cur) => ({...acc, ...cur}), {})for(let prop in style) {div.style[prop] = style[prop]}queue = []microTask = null}const setStyle = (style) => {queue.push(style)// 创建微任务if(!microTask) microTask = Promise.resolve().then(st)}for (let i = 0; i < times; i++) {const style = {fontSize: (i % 12) + 12 + 'px',color: i % 2 ? 'red' : 'green',margin: (i % 12) + 12 + 'px'}setStyle(style)}
从下面的耗时占比图可以看到,紫色 Rendering 事件耗时有所减少。
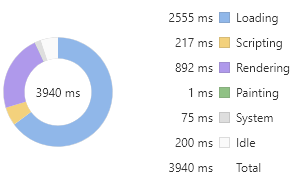
virtualDOM 之所以号称高性能,其实现原理就与此类似。
缓存元素集合
比如将通过选择器函数获取到的 DOM 元素赋值给变量,之后通过变量操作而不是再次使用选择器函数来获取。
下面举例说明,假设我们现在要将上面代码所创建的 1 万个 div 元素的文本内容进行修改。每次重复使用获取选择器函数来获取元素,代码以及时间消耗如下所示。
for (let i = 0; i < document.querySelectorAll('div').length; i++) {document.querySelectorAll(`div`)[i].innerText = i}
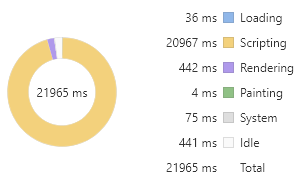
如果能够将元素集合赋值给 JavaScript 变量,每次通过变量去修改元素,那么性能将会得到不小的提升。
const divs = document.querySelectorAll('div')for (let i = 0; i < divs.length; i++) {divs[i].innerText = i}
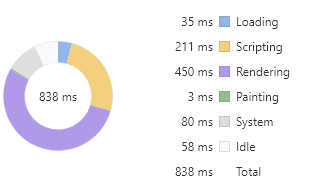
对比两者耗时占比图可以看到,两者的渲染时间较为接近。但缓存元素的方式在黄色的 Scripting 耗时上具有明显优势。
总结
本课时从深入理解 DOM 的必要性说起,然后分析了 DOM 操作耗时的原因,最后再针对这些原因提出了可行的解决方法。
除了这些方法之外,还有一些原则也可能帮助我们提升渲染性能,比如:
- 尽量不要使用复杂的匹配规则和复杂的样式,从而减少渲染引擎计算样式规则生成 CSSOM 树的时间;
- 尽量减少重排和重绘影响的区域;
- 使用 CSS3 特性来实现动画效果。
希望你首先能理解原因,然后记住这些方法和原则,编写出高性能代码。
最后布置一道思考题:说一说你还知道哪些提升渲染速度的方法和原则?
第03讲:3 个使用场景助你用好 DOM 事件
这一课时我们将一起探究 DOM 事件。
DOM 事件数量非常多,即使分类也有十多种,比如键盘事件、鼠标事件、表单事件等,而且不同事件对象属性也有差异,这带来了一定的学习难度。
但页面要与用户交互,接收用户输入,就离不开监听元素事件,所以,DOM 事件是前端工程师必须掌握的重要内容,同时也是 DOM 的重要组成部分。
下面我们就从防抖、节流、代理 3 个场景出发,详细了解 DOM 事件。
防抖
试想这样的一个场景,有一个搜索输入框,为了提升用户体验,希望在用户输入后可以立即展现搜索结果,而不是每次输入完后还要点击搜索按钮。最基本的实现方式应该很容易想到,那就是绑定 input 元素的键盘事件,然后在监听函数中发送 AJAX 请求。伪代码如下:
const ipt = document.querySelector('input')ipt.addEventListener('input', e => {search(e.target.value).then(resp => {// ...}, e => {// ...})})
但其实这样的写法很容易造成性能问题。比如当用户在搜索“lagou”这个词的时候,每一次输入都会触发搜索:
- 搜索“l”
- 搜索“la”
- 搜索“lag”
- 搜索“lago”
- 搜索“lagou”
而实际上,只有最后一次搜索结果是用户想要的,前面进行了 4 次无效查询,浪费了网络带宽和服务器资源。
所以对于这类连续触发的事件,需要添加一个“防抖”功能,为函数的执行设置一个合理的时间间隔,避免事件在时间间隔内频繁触发,同时又保证用户输入后能即时看到搜索结果。
要实现这样一个功能我们很容易想到使用 setTimeout() 函数来让函数延迟执行。就像下面的伪代码,当每次调用函数时,先判断 timeout 实例是否存在,如果存在则销毁,然后创建一个新的定时器。
// 代码1const ipt = document.querySelector('input')let timeout = nullipt.addEventListener('input', e => {if(timeout) {clearTimeout(timeout)timeout = null}timeout = setTimeout(() => {search(e.target.value).then(resp => {// ...}, e => {// ...})}, 500)})
问题确实是解决了,但这并不是最优答案,或者说我们需对这个防抖操作进行一些“优化”。
试想一下,如果另一个搜索框也需要添加防抖,是不是也要把 timeout 相关的代码再编写一次?而其实这个操作是完全可以抽取成公共函数的。
在抽取成公共函数的同时,还需要考虑更复杂的情况:
参数和返回值如何传递?
防抖化之后的函数是否可以立即执行?
防抖化的函数是否可以手动取消?
具体代码如下所示,首先将原函数作为参数传入 debounce() 函数中,同时指定延迟等待时间,返回一个新的函数,这个函数包含 cancel 属性,用来取消原函数执行。flush 属性用来立即调用原函数,同时将原函数的执行结果以 Promise 的形式返回。
// 代码2const debounce = (func, wait = 0) => {let timeout = nulllet argsfunction debounced(...arg) {args = argif(timeout) {clearTimeout(timeout)timeout = null}// 以Promise的形式返回函数执行结果return new Promise((res, rej) => {timeout = setTimeout(async () => {try {const result = await func.apply(this, args)res(result)} catch(e) {rej(e)}}, wait)})}// 允许取消function cancel() {clearTimeout(timeout)timeout = null}// 允许立即执行function flush() {cancel()return func.apply(this, args)}debounced.cancel = canceldebounced.flush = flushreturn debounced}
我们在写代码解决当前问题的时候,最初只能写出像代码 1 那样满足需求的代码。但要成为高级工程师,就一定要将问题再深想一层,比如代码如何抽象成公共函数,才能得到较为完善的代码 2,从而自身得到成长。
关于防抖函数还有功能更丰富的版本,比如 lodash 的 debounce() 函数,有兴趣的话可以到 GitHub 上查阅资料。
节流
现在来考虑另外一个场景,一个左右两列布局的查看文章页面,左侧为文章大纲结构,右侧为文章内容。现在需要添加一个功能,就是当用户滚动阅读右侧文章内容时,左侧大纲相对应部分高亮显示,提示用户当前阅读位置。
这个功能的实现思路比较简单,滚动前先记录大纲中各个章节的垂直距离,然后监听 scroll 事件的滚动距离,根据距离的比较来判断需要高亮的章节。伪代码如下:
// 监听scroll事件wrap.addEventListener('scroll', e => {let highlightId = ''// 遍历大纲章节位置,与滚动距离比较,得到当前高亮章节idfor (let id in offsetMap) {if (e.target.scrollTop <= offsetMap[id].offsetTop) {highlightId = idbreak}}const lastDom = document.querySelector('.highlight')const currentElem = document.querySelector(`a[href="#${highlightId}"]`)// 修改高亮样式if (lastDom && lastDom.id !== highlightId) {lastDom.classList.remove('highlight')currentElem.classList.add('highlight')} else {currentElem.classList.add('highlight')}})
功能是实现了,但这并不是最优方法,因为滚动事件的触发频率是很高的,持续调用判断函数很可能会影响渲染性能。实际上也不需要过于频繁地调用,因为当鼠标滚动 1 像素的时候,很有可能当前章节的阅读并没有发生变化。所以我们可以设置在指定一段时间内只调用一次函数,从而降低函数调用频率,这种方式我们称之为“节流”。
实现节流函数的过程和防抖函数有些类似,只是对于节流函数而言,有两种执行方式,在调用函数时执行最先一次调用还是最近一次调用,所以需要设置时间戳加以判断。我们可以基于 debounce() 函数加以修改,代码如下所示:
const throttle = (func, wait = 0, execFirstCall) => {let timeout = nulllet argslet firstCallTimestampfunction throttled(...arg) {if (!firstCallTimestamp) firstCallTimestamp = new Date().getTime()if (!execFirstCall || !args) {console.log('set args:', arg)args = arg}if (timeout) {clearTimeout(timeout)timeout = null}// 以Promise的形式返回函数执行结果return new Promise(async(res, rej) => {if (new Date().getTime() - firstCallTimestamp >= wait) {try {const result = await func.apply(this, args)res(result)} catch (e) {rej(e)} finally {cancel()}} else {timeout = setTimeout(async () => {try {const result = await func.apply(this, args)res(result)} catch (e) {rej(e)} finally {cancel()}}, firstCallTimestamp + wait - new Date().getTime())}})}// 允许取消function cancel() {clearTimeout(timeout)args = nulltimeout = nullfirstCallTimestamp = null}// 允许立即执行function flush() {cancel()return func.apply(this, args)}throttled.cancel = cancelthrottled.flush = flushreturn throttled}
节流与防抖都是通过延迟执行,减少调用次数,来优化频繁调用函数时的性能。不同的是,对于一段时间内的频繁调用,防抖是延迟执行后一次调用,节流是延迟定时多次调用。
代理
<ul class="list"><li class="item" id="item1">项目1<span class="edit">编辑</span><span class="delete">删除</span></li><li class="item" id="item2">项目2<span class="edit">编辑</span><span class="delete" >删除</span></li><li class="item" id="item3">项目3<span class="edit">编辑</span><span class="delete">删除</span></li>...</ul>
要实现这个功能并不难,只需要对列表中每一项,分别监听 3 个元素的 click 事件即可。
但如果数据量一旦增大,事件绑定占用的内存以及执行时间将会成线性增加,而其实这些事件监听函数逻辑一致,只是参数不同而已。此时我们可以以事件代理或事件委托来进行优化。不过在此之前,我们必须先复习一下 DOM 事件的触发流程。
事件触发流程如图 1 所示,主要分为 3 个阶段:
- 捕获,事件对象 Window 传播到目标的父对象,图 1 的红色过程;
- 目标,事件对象到达事件对象的事件目标,图 1 的蓝色过程;
- 冒泡,事件对象从目标的父节点开始传播到 Window,图 1 的绿色过程。
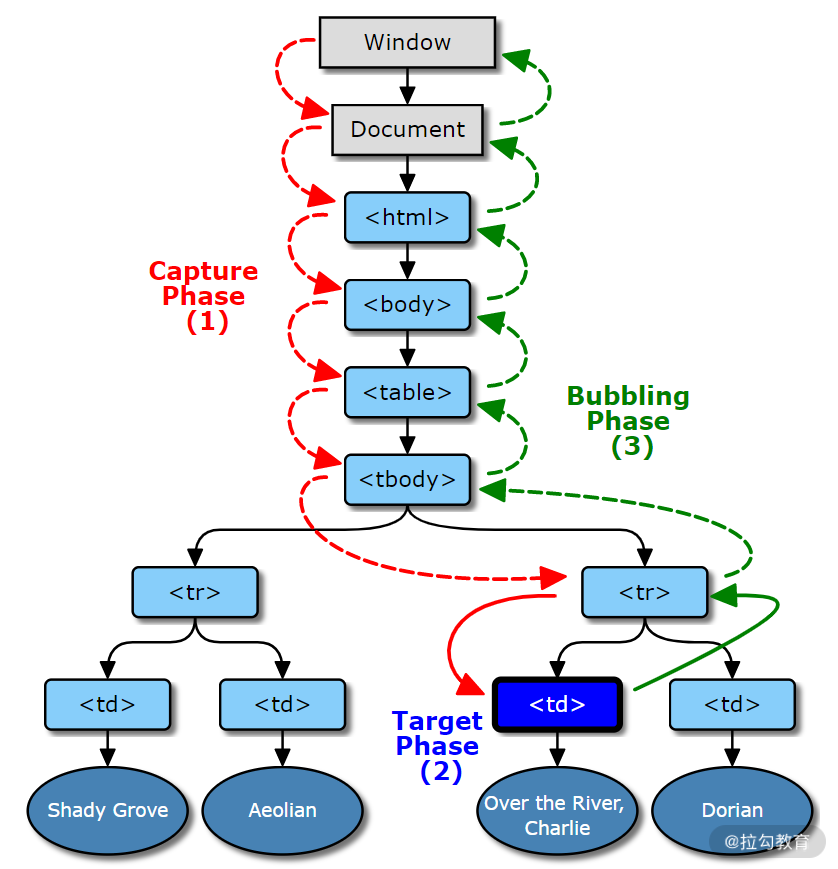
例如,在下面的代码中,虽然我们第二次进行事件监听时设置为捕获阶段,但点击事件时仍会按照监听顺序进行执行。
<body><button>click</button></body><script>document.querySelector('button').addEventListener('click', function () {console.log('bubble')})document.querySelector('button').addEventListener('click', function () {console.log('capture')}, true)// 执行结果// buble// capture</script>
我们再回到事件代理,事件代理的实现原理就是利用上述 DOM 事件的触发流程来对一类事件进行统一处理。比如对于上面的列表,我们在 ul 元素上绑定事件统一处理,通过得到的事件对象来获取参数,调用对应的函数。
const ul = document.querySelector('.list')ul.addEventListener('click', e => {const t = e.target || e.srcElementif (t.classList.contains('item')) {getInfo(t.id)} else {id = t.parentElement.idif (t.classList.contains('edit')) {edit(id)} else if (t.classList.contains('delete')) {del(id)}}})
虽然这里我们选择了默认在冒泡阶段监听事件,但和捕获阶段监听并没有区别。对于其他情况还需要具体情况具体细分析,比如有些列表项目需要在目标阶段进行一些预处理操作,那么可以选择冒泡阶段进行事件代理。
补充:关于 DOM 事件标准
你知道下面 3 种事件监听方式的区别吗?
// 方式1<input type="text" onclick="click()"/>// 方式2document.querySelector('input').onClick = function(e) {// ...}// 方式3document.querySelector('input').addEventListener('click', function(e) {//...})
方式 1 和方式 2 同属于 DOM0 标准,通过这种方式进行事件监会覆盖之前的事件监听函数。
方式 3 属于 DOM2 标准,推荐使用这种方式。同一元素上的事件监听函数互不影响,而且可以独立取消,调用顺序和监听顺序一致。
第04讲:掌握 CSS 精髓:布局
CSS 虽然初衷是用来美化 HTML 文档的,但实际上随着 float、position 等属性的出现,它已经可以起到调整文档渲染结构的作用了,而随着弹性盒子以及网格布局的推出,CSS 将承担越来越重要的布局功能。渐渐地我们发现 HTML 标签决定了页面的逻辑结构,而 CSS 决定了页面的视觉结构。
这一课时我们先来分析常见的布局效果有哪些,然后再通过代码来实现这些效果,从而帮助你彻底掌握 CSS 布局。
我们通常提到的布局,有两个共同点:
- 大多数用于 PC 端,因为 PC 端屏幕像素宽度够大,可布局的空间也大;
- 布局是有限空间内的元素排列方式,因为页面设计横向不滚动,纵向无限延伸,所以大多数时候讨论的布局都是对水平方向进行分割。
实际上我们在讨论布局的时候,会把网页上特定的区域进行分列操作。按照分列数目,可以大致分为 3 类,即单列布局、2 列布局、3 列布局。
单列布局
单列布局是最常用的一种布局,它的实现效果就是将一个元素作为布局容器,通常设置一个较小的(最大)宽度来保证不同像素宽度屏幕下显示一致。
示例网站
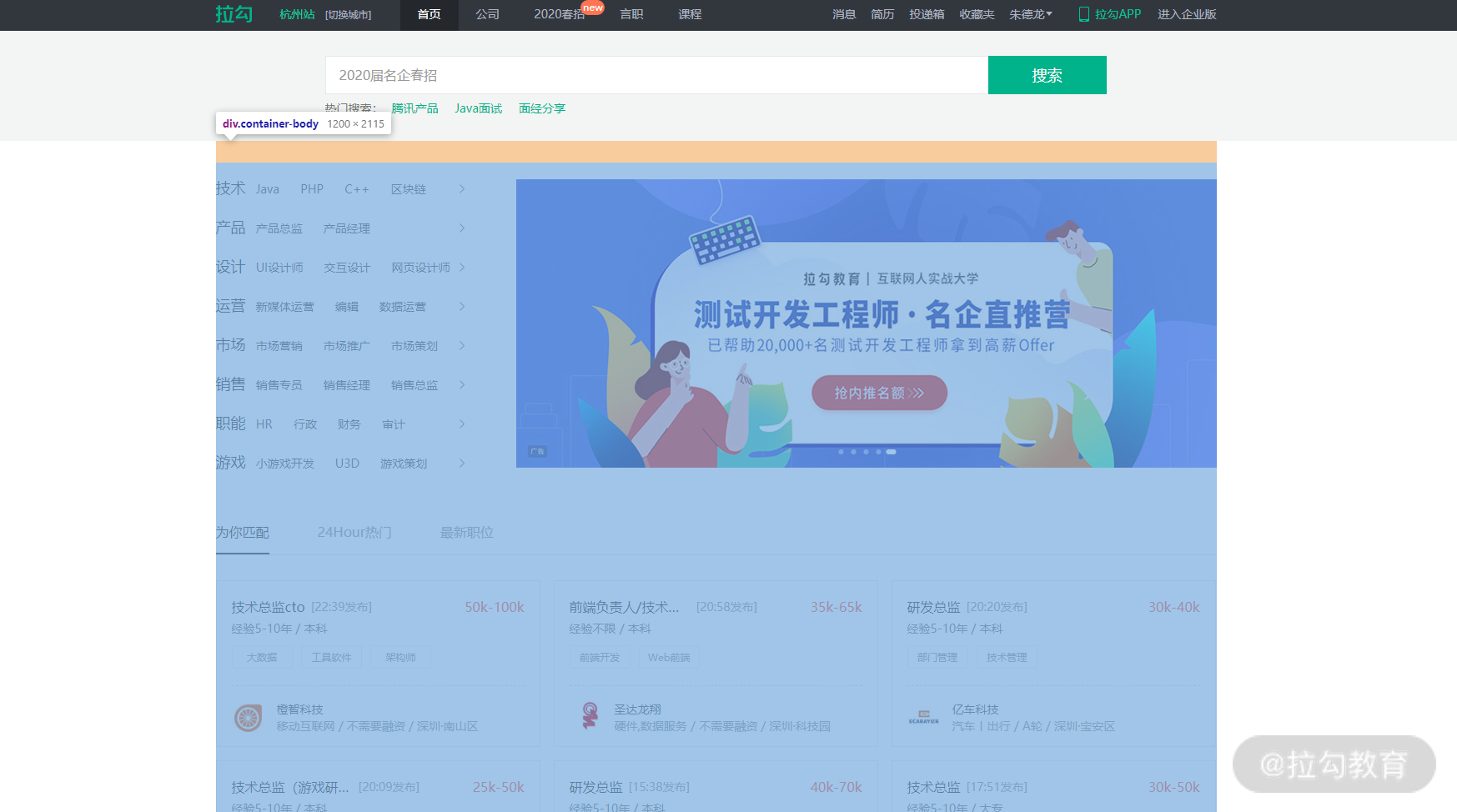
拉勾,蓝色区域为布局容器,水平居中对齐,宽度 1260px:
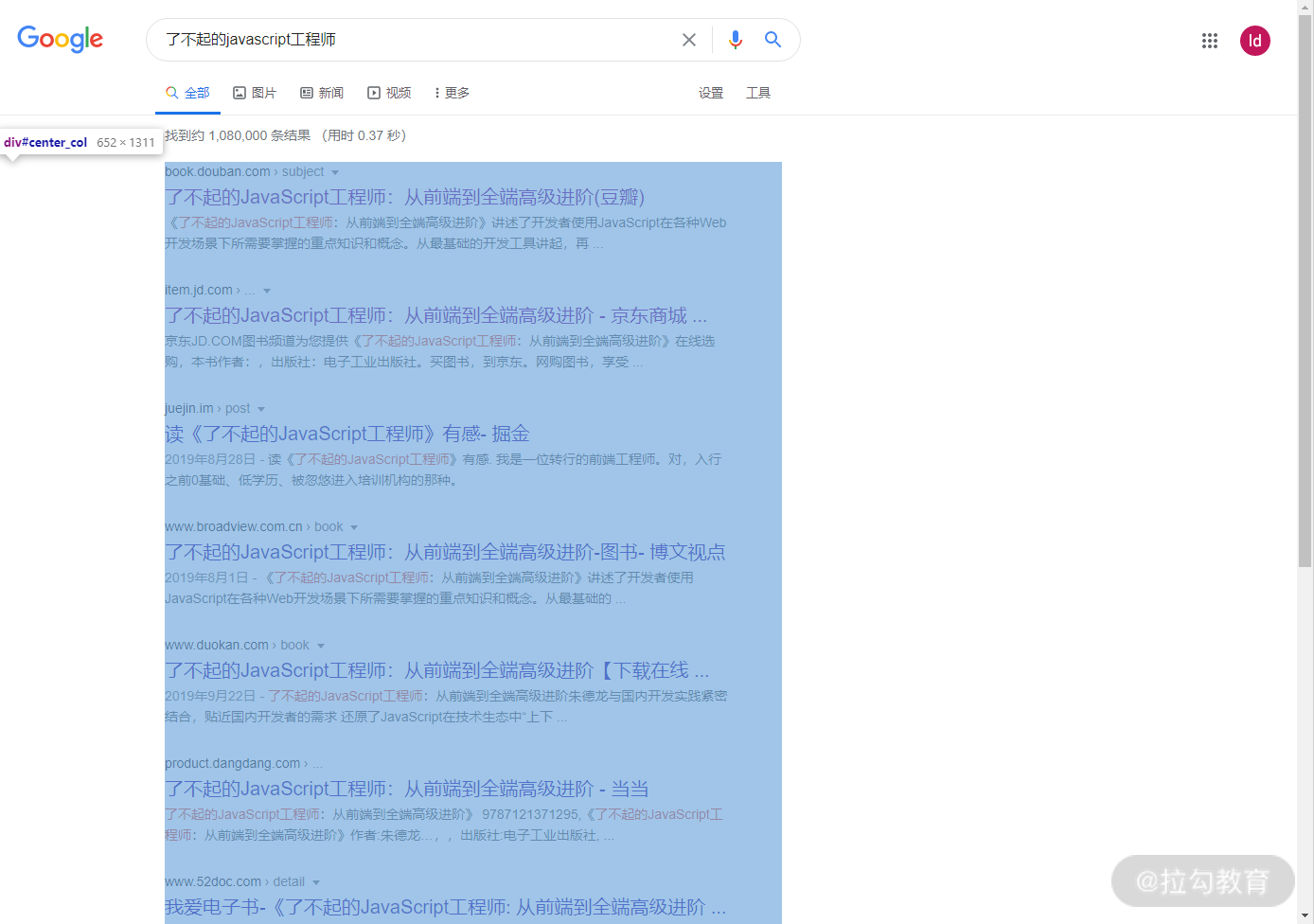
谷歌搜索,蓝色区域为布局容器,水平左对齐,宽度 652px:
一些网站会将单列布局与其他布局方式混合使用,比如拉勾网首页的海报和左侧标签就使用了 2 列布局,这样既能向下兼容窄屏幕,又能按照主次关系显示页面内容。
这种布局的优势在于基本上可以适配超过布局容器宽度的各种显示屏幕,比如上面的示例网站布局容器宽度为 700px,也就是说超过 700px 宽度的显示屏幕上浏览网站看到的效果是一致的。
但它最大的缺点也是源于此,过度的冗余设计必然会带来浪费。例如,在上面的例子中,其实我的屏幕宽度是足够的,可以显示更多的内容,但是页面两侧却出现了大量空白区域,如果在 4k 甚至更宽的屏幕下,空白区域大小会超过页面内容区域大小!
2 列布局
2 列布局使用频率也非常的高,实现效果就是将页面分割成左右宽度不等的两列,宽度较小的列设置为固定宽度,剩余宽度由另一列撑满。为了描述方便,我们暂且称宽度较小的列父元素为次要布局容器,宽度较大的列父元素为主要布局容器。
示例网站
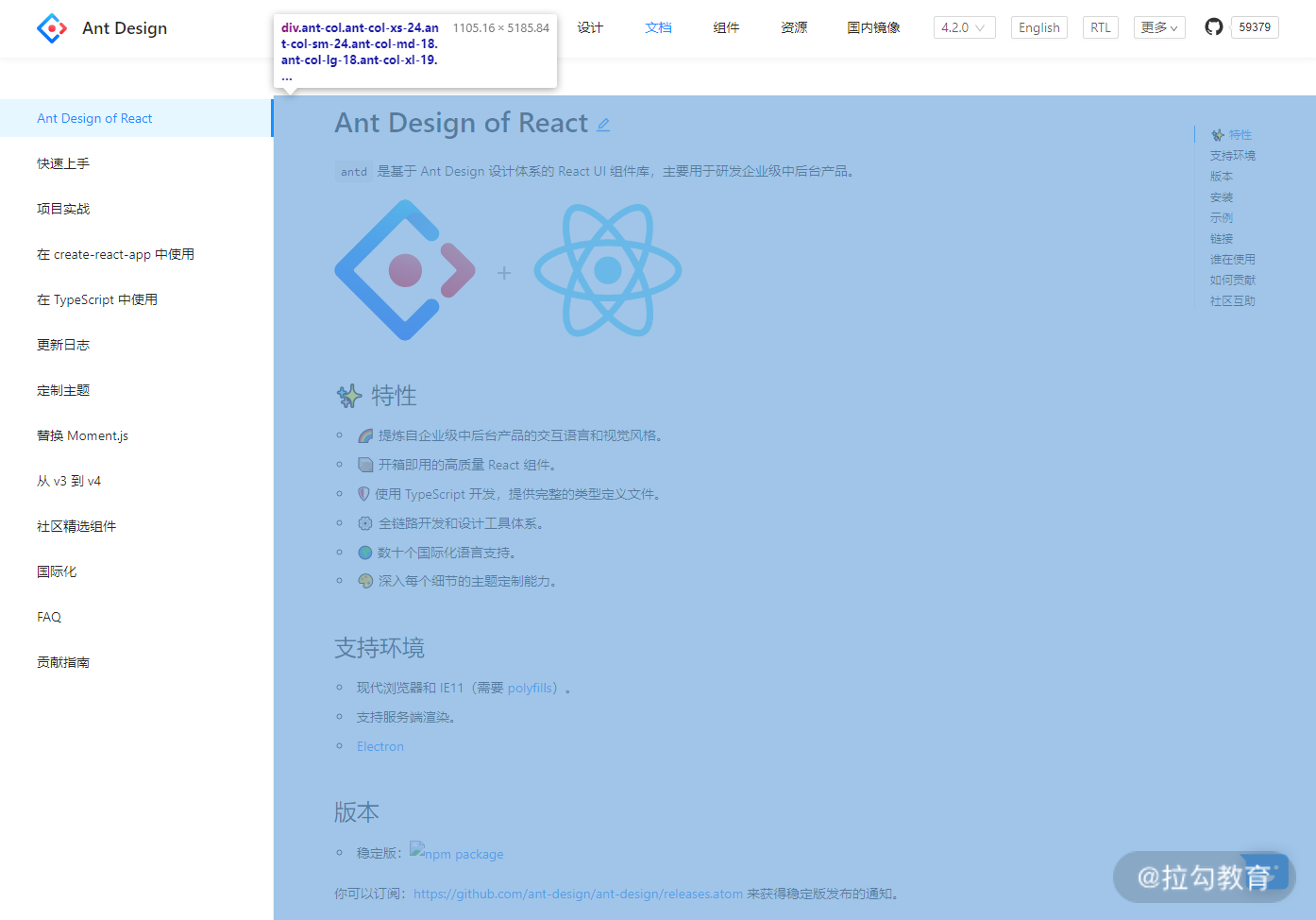
Ant Design 文档,蓝色区域为主要内容布局容器,侧边栏为次要内容布局容器。
这种布局适用于内容上具有明显主次关系的网页,比如 API 文档页面中左侧显示内容导航,右侧显示文档描述;又比如后台管理系统中左侧显示菜单栏,右侧显示配置页面。相对于单列布局,在屏幕宽度适配方面处理得更好。当屏幕宽度不够时,主要内容布局容器优先显示,次要内容布局容器改为垂直方向显示或隐藏,但有时候也会和单列布局搭配使用,作为单列布局中的子布局使用。
3 列布局
3 列布局按照左中右的顺序进行排列,通常中间列最宽,左右两列次之。
示例网站
登录 GitHub 后,蓝色区域为宽度最大的中间列。
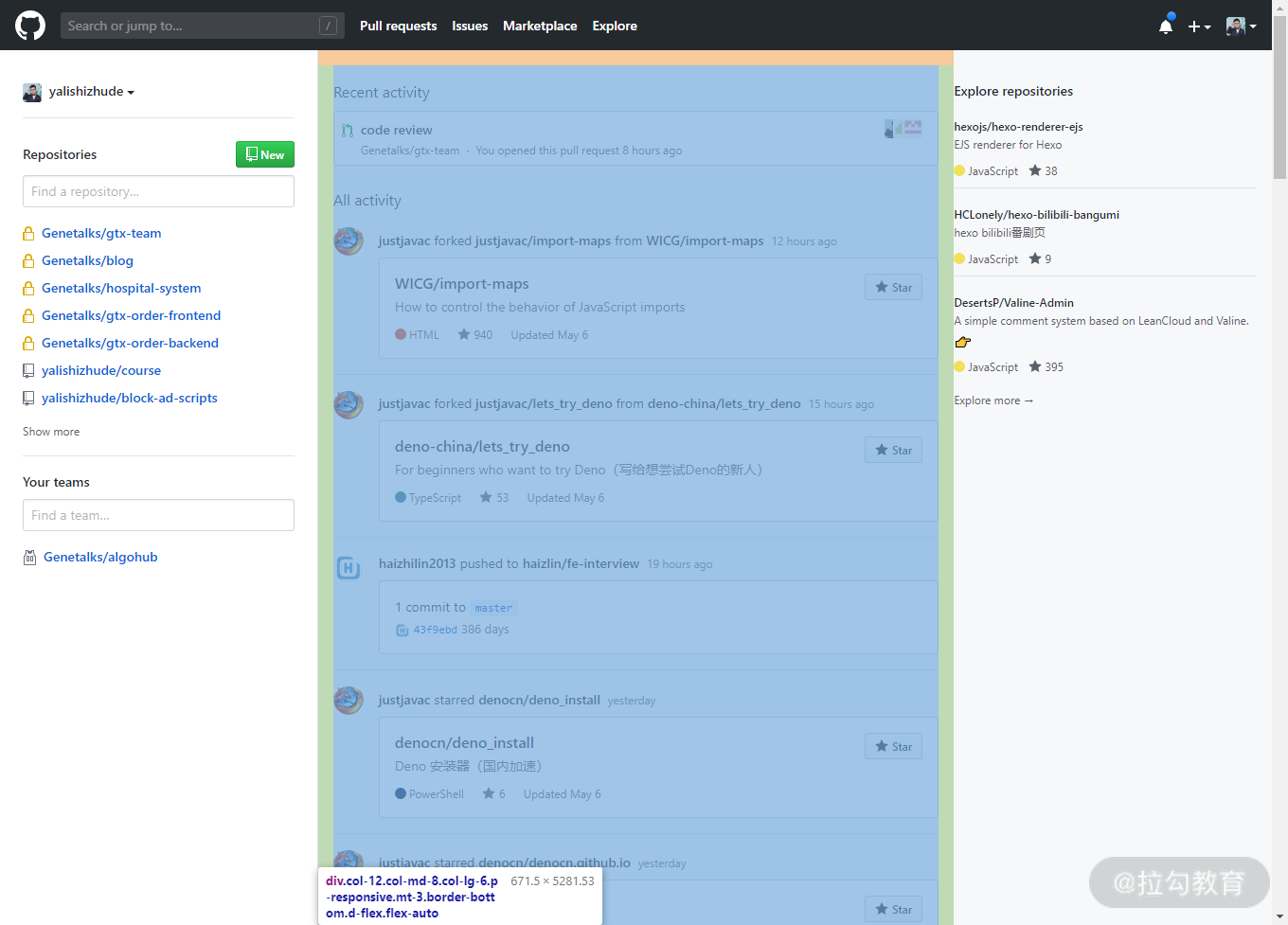
CSDN 首页,这是 3 列布局的第二种实现方式,蓝色部分就是 2 列布局的主要布局容器,而它的子元素又使用了 2 列布局。
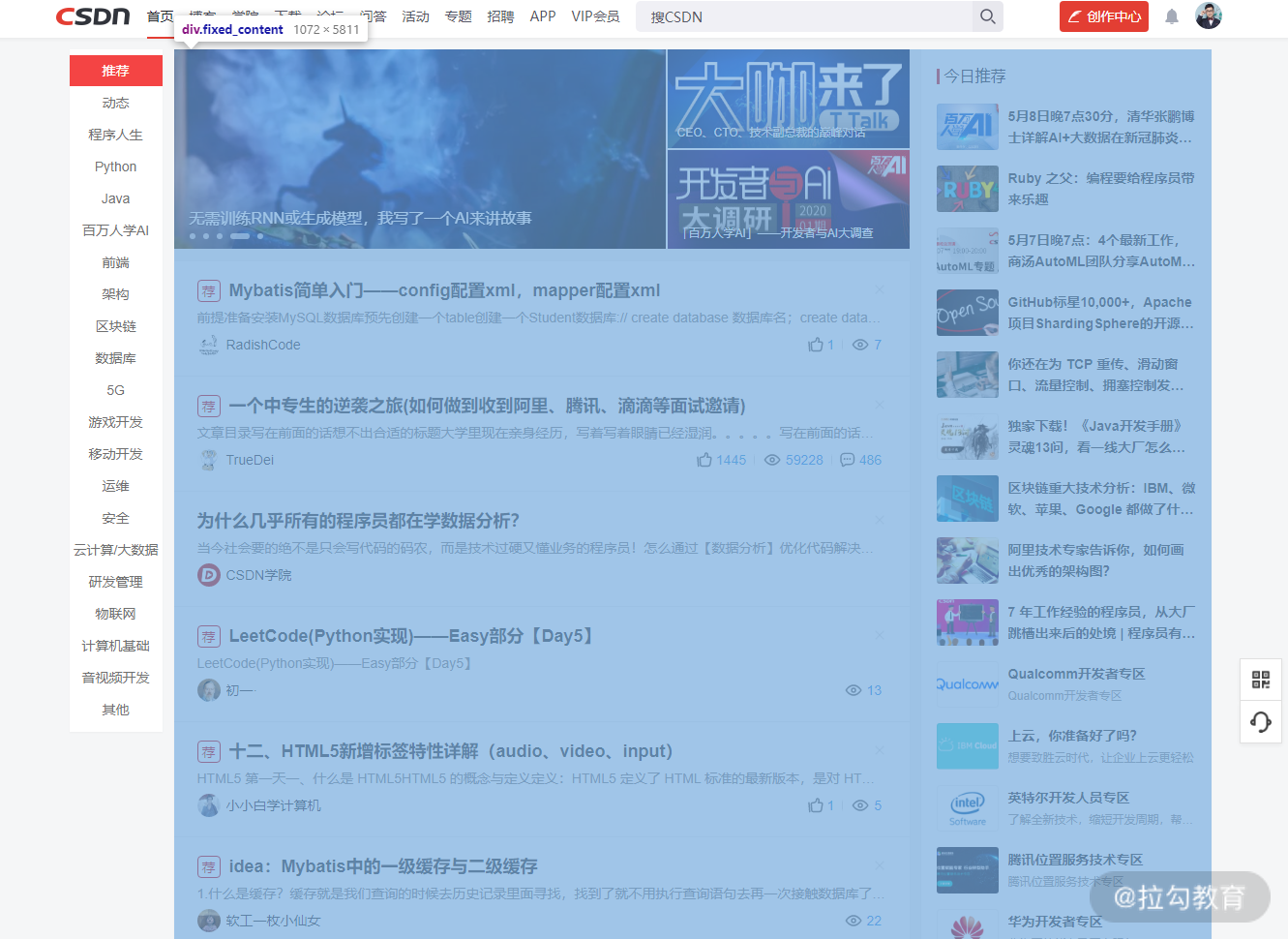
3 列布局和 2 列布局类似,也有明确的主次关系,只是关系层次增加了一层。下面我们来看看如何实现这些布局。
布局实现
单列布局没有太多技术难点,通过将设置布局容器(最大)宽度以及左右边距为 auto 即可实现,我们重点讨论 2 列和 3 列布局。关于这两种布局,在网上可以找到很多实现方式,我们是不是只要把这些方式收集起来然后都记住就行了呢?
当然不是!
我们要做的是通过归纳法,找到这些方式的共同实现步骤,只要把这些步骤记住了,就能做到举一反三。
你可以试着自己先整理一下,或者直接看我整理好的结果。
要实现 2 列布局或 3 列布局,可以按照下面的步骤来操作:
(1)为了保证主要布局容器优先级,应将主要布局容器写在次要布局容器之前。
(2)将布局容器进行水平排列;
(3)设置宽度,即次要容器宽度固定,主要容器撑满;
(4)消除布局方式的副作用,如浮动造成的高度塌陷;
(5)为了在窄屏下也能正常显示,可以通过媒体查询进行优化。
根据以上操作步骤,先来看一个使用 flex 布局实现 2 列布局的例子。
第 1 步,写好 HTML 结构。这里为了查看方便,我们为布局容器设置背景颜色和高度。
<style>/* 为了方便查看,给布局容器设置高度和颜色 */main,aside {height: 100px;}main {background-color: #f09e5a;}aside {background-color: #c295cf;}</style><div><main>主要布局容器</main><aside>次要布局容器</aside></div>

第 2 步,将布局容器水平排列:
<style>.wrap {display: flex;flex-direction: row-reverse;}.main {flex: 1;}.aside {flex: 1;}</style><div class="wrap"><main class="main">主要布局容器</main><aside class="aside">次要布局容器</aside></div>

第 3 步,调整布局容器宽度:
<style>.wrap {display: flex;flex-direction: row-reverse;}.main {flex: 1;}.aside {width: 200px;}</style><div class="wrap"><main class="main">主要布局容器</main><aside class="aside">次要布局容器</aside></div>

第 4 步,消除副作用,比如浮动造成的高度塌陷。由于使用 flex 布局没有副作用,所以不需要修改,代码和效果图同第 3 步。

第 5 步,增加媒体查询。
<style>.wrap {display: flex;flex-direction: row-reverse;flex-wrap: wrap;}.main {flex: 1;}.aside {width: 200px;}@media only screen and (max-width: 1000px) {.wrap {flex-direction: row;}.main {flex: 100%;}}</style><div class="wrap"><main class="main">主要布局容器</main><aside class="aside">次要布局容器</aside></div>

下面再来个复杂些的 3 列布局的例子。
第 1 步,写好 HTML 结构,为了辨认方便,我们给布局容器设置背景色和高度:
<style>/* 为了方便查看,给布局容器设置高度和颜色 */.main, .left, .right {height: 100px;}.main {background-color: red;}.left {background-color: green;}.right {background-color: blue;}</style><div class="wrap"><main class="main">main</main><aside class="left">left</aside><aside class="right">right</aside></div>

第 2 步,让布局容器水平排列:
<style>.main, .left, .right {float: left;}</style><div class="wrap"><main class="main">main</main><aside class="left">left</aside><aside class="right">right</aside></div>

第 3 步,调整宽度,将主要布局容器 main 撑满,次要布局容器 left 固定 300px,次要布局容器 right 固定 200px。
这里如果直接设置的话,布局容器 left 和 right 都会换行,所以我们需要通过设置父元素 wrap 内边距来压缩主要布局 main 给次要布局容器留出空间。同时通过设置次要布局容器边距以及采用相对定位调整次要布局容器至两侧。
<style>.main, .left, .right {float: left;}.wrap {padding: 0 200px 0 300px;}.main {width: 100%;}.left {width: 300px;position: relative;left: -300px;margin-left: -100%;}.right {position: relative;width: 200px;margin-left: -200px;right: -200px;}</style><div class="wrap"><main class="main">main</main><aside class="left">left</aside><aside class="right">right</aside></div>

第 4 步,消除副作用。我们知道使用浮动会造成高度塌陷,如果在父元素后面添加新的元素就会产生这个问题。所以可以通过伪类来清除浮动,同时减小页面宽度,还会发现次要布局容器 left 和 right 都换行了,但这个副作用我们可以在第 5 步时进行消除。
<style>.main, .left, .right {float: left;}.wrap {padding: 0 200px 0 300px;}.wrap::after {content: '';display: block;clear: both;}.main {width: 100%;}.left {width: 300px;position: relative;left: -300px;margin-left: -100%;}.right {position: relative;width: 200px;margin-left: -200px;right: -200px;}</style><div class="wrap"><main class="main">main</main><aside class="left">left</aside><aside class="right">right</aside></div>

第 5 步,利用媒体查询调整页面宽度较小情况下的显示优先级。这里我们仍然希望优先显示主要布局容器 main,其次是次要布局容器 left,最后是布局容器 right。
<style>.main, .left, .right {float: left;}.wrap {padding: 0 200px 0 300px;}.wrap::after {content: '';display: block;clear: both;}.main {width: 100%;}.left {width: 300px;position: relative;left: -300px;margin-left: -100%;}.right {position: relative;width: 200px;margin-left: -200px;right: -200px;}@media only screen and (max-width: 1000px) {.wrap {padding: 0;}.left {left: 0;margin-left: 0;}.right {margin-left: 0;right: 0;}}</style><div class="wrap"><main class="main">main</main><aside class="left">left</aside><aside class="right">right</aside></div>

这种 3 列布局的实现,就是流传已久的“圣杯布局”,但标准的圣杯布局没有添加媒体查询。
延伸1:垂直方向的布局
垂直方向有一种布局虽然使用频率不如水平方向布局高,但在面试中很容易被问到,所以这里特意再补充讲解一下。
这种布局将页面分成上、中、下三个部分,上、下部分都为固定高度,中间部分高度不定。当页面高度小于浏览器高度时,下部分应固定在屏幕底部;当页面高度超出浏览器高度时,下部分应该随中间部分被撑开,显示在页面最底部。
这种布局也称之为”sticky footer“,意思是下部分粘黏在屏幕底部。要实现这个功能,最简单的就是使用 flex 或 grid 进行布局。下面是使用 flex 的主要代码:
<style>.container {display: flex;height: 100%;flex-direction: column;}header, footer {min-height: 100px;}main {flex: 1;}</style><div class="container"><header></header><main><div>...</div></main><footer></footer></div>
代码实现思路比较简单,将布局容器的父元素 display 属性设置成 flex,伸缩方向改为垂直方向,高度撑满页面,再将中间布局容器的 flex 属性设置为 1,让其自适应即可。
如果要考虑兼容性的话,其实现起来要复杂些,下面是主要代码:
<style>.container {box-sizing: border-box;min-height: 100vh;padding-bottom: 100px;}header, footer {height: 100px;}footer {margin-top: -100px;}</style><div class="container"><header></header><main></main></div><footer></footer>
将上部分布局容器与中间布局容器放入一个共同的父元素中,并让父元素高度撑满,然后设置内下边距给下部分布局容器预留空间,下部分布局容器设置上外边距“嵌入”父元素中。从而实现了随着中间布局容器高度而被撑开的效果。
延伸2:框架中栅格布局的列数
很多 UI 框架都提供了栅格系统来帮助页面实现等分或等比布局,比如 Bootstrap 提供了 12 列栅格,elment ui 和 ant design 提供了 24 列栅格。
那么你思考过栅格系统设定这些列数背后的原因吗?
首先从 12 列说起,12 这个数字,从数学上来说它具有很多约数 1、2、3、4、6、12,也就是说可以轻松实现 1 等分、2 等分、3 等分、4 等分、6 等分、12 等分,比例方面可以实现 1:11、1:5、1:3、1:2、1:1、1:10:1、1:4:1 等。如果换成 10 或 8,则可实现的等分比例就会少很多,而更大的 16 似乎是个不错的选择,但对于常用的 3 等分就难以实现。
至于使用 24 列不使用 12 列,可能是考虑宽屏幕(PC 端屏幕宽度不断增加)下对 12 列难以满足等分比例需求,比如 8 等分。同时又能够保证兼容 12 列情况下的等分比例(方便项目迁移和替换)。
第05讲:如何管理你的 CSS 代码?
上一课时我们从技术细节的角度分析了 CSS 布局的相关内容。这一课时我们提升一下思考维度,从组织管理的角度探讨如何管理好项目中的 CSS 代码。
接下来我们先解决 CSS 原生语法未能很好实现的模块化和作用域的问题,然后再对代码结构进行优化,提升代码的复用率。
如何组织样式文件
尽管 CSS 提供了 import 命令支持文件引用,但由于其存在一些问题(比如影响浏览器并行下载、加载顺序错乱等)导致使用率极低。更常见的做法是通过预处理器或编译工具插件来引入样式文件,因此本课时的讨论将不局限于以 .css 为后缀的样式文件。
管理样式文件的目的就是为了让开发人员更方便地维护代码。
具体来说就是将样式文件进行分类,把相关的文件放在一起。让工程师在修改样式的时候更容易找到对应的样式文件,在创建样式文件的时候更容易找到对应的目录。
下面我们来看看热门的开源项目都是怎么来管理样式文件的。
开源项目中的样式文件
我们先来看看著名的 UI 相关的开源项目是怎么管理样式文件的。
以 Bootstrap 4.4 为例,下图是项目样式代码结构,可以看出项目使用的是 Sass 预处理器。

该目录包括了 5 个目录、组件样式文件和一些全局样式。再来分析下目录及内容:
- forms/,表单组件相关样式;
- helpers/,公共样式,包括定位、清除等;
- mixins/,可以理解为生成最终样式的函数;
- utilities/,媒体查询相关样式;
- vendor/,依赖的外部第三方样式。
根目录存放了组件样式文件和目录,其他样式文件放在不同的目录中。目录中的文件分类清晰,但目录结构相对于大多数实际项目而言过于简单(只有样式文件)。
我们再来看一个更符合大多数情况的开源项目 ant-design 4.2,该项目采用 Less 预处理器,主要源码放在 /components 目录下:
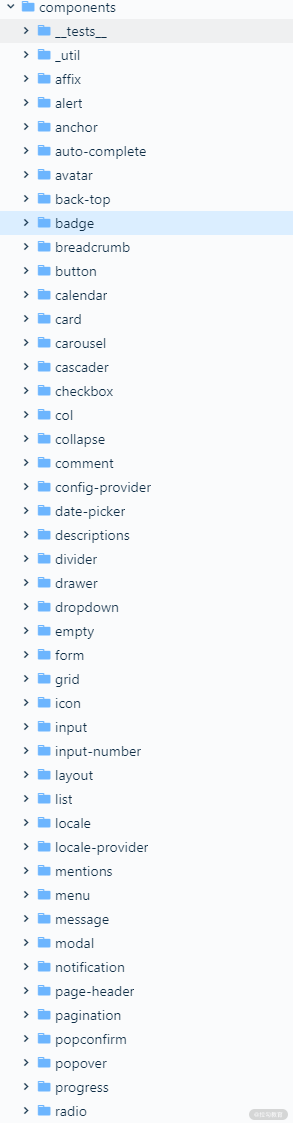
从目录名称上不难猜测,各个组件代码通过文件夹区分,点击其中的 alert 文件夹查看也确实如此,组件相关的代码、测试代码、demo 示例、样式文件、描述文档都在里面。
至于全局样式和公共样式则在 /components/style 目录下:
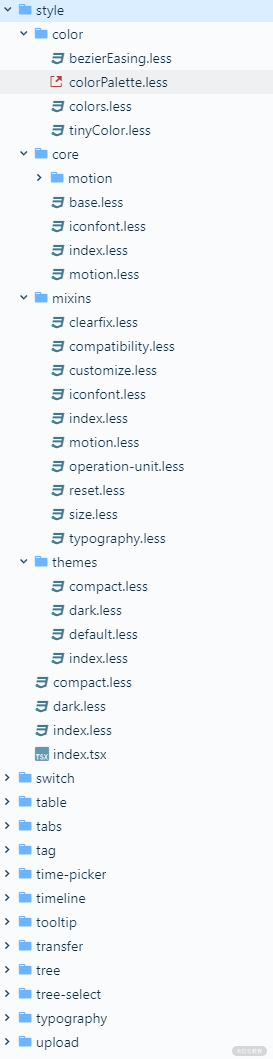
其中包括 4 个目录:
- color/,颜色相关的变量与函数;
- core/,全局样式,根标签样式、字体样式等;
- mixins/,样式生成函数;
- themes/,主题相关的样式变量。
将组件代码及相关样式放在一起,开发的时候修改会很方便。 但在组件目录 /comnponents 下设置 style 目录存放全局和公共样式,在逻辑上就有些说不通了,这些“样式”文件并不是一个单独的“组件”。再看 style 目录内部结构,相对于设置单独的 color 目录来管理样式中的颜色,更推荐像 Bootstrap 一样设立专门的目录或文件来管理变量。
最后来看看依赖 Vue.js 实现的热门 UI 库 element 2.13.1 的目录结构。项目根路径下的 packages 目录按组件划分目录来存放其源码,但和 ant-design 不同的是,组件样式文件并没有和组件代码放在一起。下图是 /packages 目录下的部分内容。
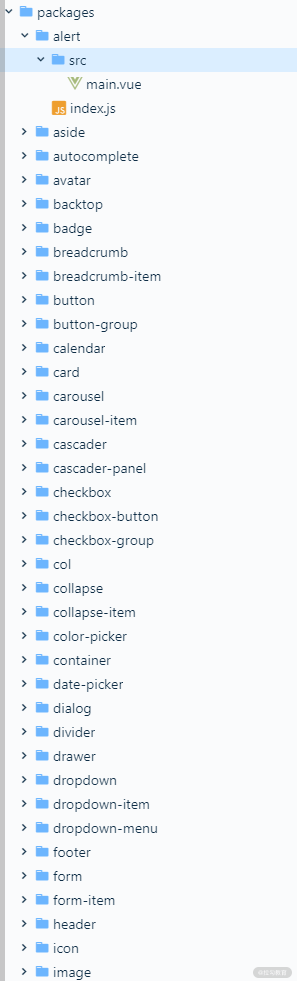
element 将样式文件统一放入了 /packages/theme-chalk 目录下,目录部分内容如下图所示:
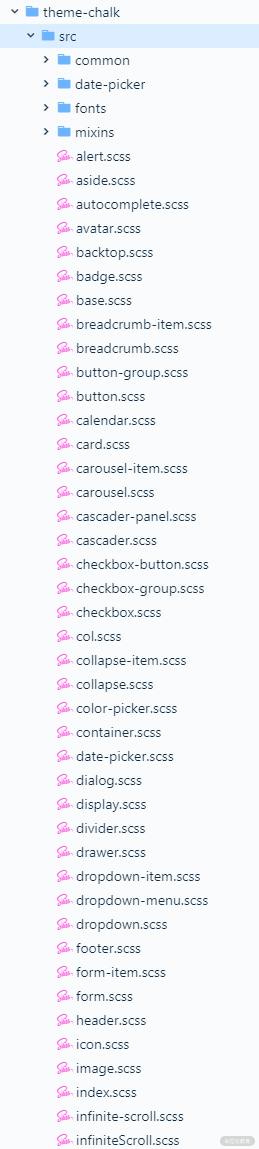
其中包含 4 个目录:
- common/,一些全局样式和公共变量;
- date-picker/,日期组件相关样式;
- fonts/,字体文件;
- mixins/,样式生成函数及相关变量。
和 antd 有同样的问题,把样式当成“组件”看待,组件同级目录设立了 theme-chalk 目录存放样式文件。theme-chalk 目录下的全局样式 reset.scss 与组件样式同级,这也有些欠妥。这种为了将样式打包成模块,在独立项目中直接嵌入另一个独立项目(可以简单理解为一个项目不要有多个 package.json 文件)并不推荐,更符合 Git 使用规范的做法,即是以子模块的方式引用进项目。 而且将组件样式和源码分离这种方式开发的时候也不方便,经常需要跨多层目录查找和修改样式。
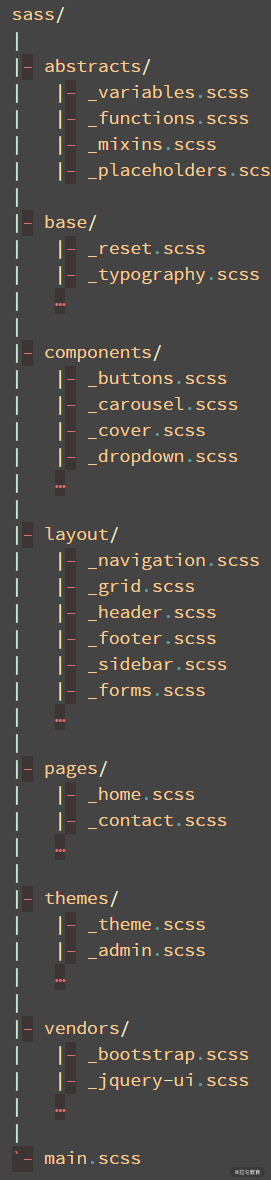
样式文件管理模式
除了开源项目之外,Sass Guidelines 曾经提出过一个用来划分样式文件目录结构的 7-1 模式也很有参考意义。这种模式建议将目录结构划分为 7 个目录和 1 个文件,这 1 个文件是样式的入口文件,它会将项目所用到的所有样式都引入进来,一般命名为 main.scss。
剩下的 7 个目录及作用如下:
- base/,模板代码,比如默认标签样式重置;
- components/,组件相关样式;
- layout/,布局相关,包括头部、尾部、导航栏、侧边栏等;
- pages/,页面相关样式;
- themes/,主题样式,即使有的项目没有多个主题,也可以进行预留;
- abstracts/,其他样式文件生成的依赖函数及 mixin,不能直接生成 css 样式;
- vendors/,第三方样式文件。
点击这里获取示例项目地址,截图如下图所示:
由于这个划分模式是专门针对使用 Sass 项目提出的,从样式文件名称看出还留有 jQuery 时代的影子,为了更加符合单页应用的项目结构,我们可以稍作优化。
- main.scss 文件存在意义不大,页面样式、组件样式、布局样式都可以在页面和组件中引用,全局样式也可以在根组件中引用。而且每次添加、修改样式文件都需要在 main.scss 文件中同步,这种过度中心化的配置方式也不方便。
- layout 目录也可以去除,因为像 footer、header 这些布局相关的样式,放入对应的组件中来引用会更好,至于不能被组件化的“_grid”样式存在性也不大。因为对于页面布局,既可以通过下面介绍的方法来拆分成全局样式,也可以依赖第三方 UI 库来实现。所以说这个目录可以去除。
- themes/ 目录也可以去除,毕竟大部分前端项目是不需要设置主题的,即使有主题也可以新建一个样式文件来管理样式变量。
- vendors/ 目录可以根据需求添加。因为将外部样式复制到项目中的情况比较少,更多的是通过 npm 来安装引入 UI 库或者通过 webpack 插件来写入对应的 cdn 地址。
所以优化后的目录结构如下所示:
src/||– abstracts/| |– _variables.scss| |– _functions.scss| |– _mixins.scss| |– _placeholders.scss||– base/| |– _reset.scss| |– _typography.scss| …||– components/| |– _buttons.scss| |– _carousel.scss| |– _cover.scss| |– _dropdown.scss| |- header/| |- header.tsx| |- header.sass| |- footer/| |- footer.tsx| |- footer.sass| …||– pages/| |– _home.scss| |– _contact.scss| …|
这只是推荐的一种目录结构,具体使用可以根据实际情况进行调整。比如我在项目的 src 目录下创建了模块目录,按照模块来拆分路由以及页面、组件,所以每个模块目录下都会有 pages/ 目录和 components/ 目录。
如何避免样式冲突
由于 CSS 的规则是全局的,任何一个样式规则,都对整个页面有效,所以如果不对选择器的命名加以管控会很容易产生冲突。
手动命名
最简单有效的命名管理方式就是制定一些命名规则,比如 OOCSS、BEM、AMCSS,其中推荐比较常用的 BEM。
这里简单补充一下 BEM 相关知识,熟悉 BEM 的可以直接跳过。
BEM 是 Block、Element、Modifier 三个单词的缩写,Block 代表独立的功能组件,Element 代表功能组件的一个组成部分,Modifier 对应状态信息。
下图是官方给出的示例代码:

从命名可以看到 Element 和 Modifier 是可选的,各个单词通过双横线(也可以用双下划线)连接(双横线虽然能和单词的连字符进行区分,但确实有些冗余,可以考虑直接用下划线代替)。BEM 的命名方式具有语义,很容易理解,非常适用于组件样式类。
工具命名
通过命名规范来避免冲突的方式固然是好的,但这种规范约束也不能绝对保证样式名的唯一性,而且也没有有效的校验工具来保证命名正确无冲突。所以,聪明的开发者想到了通过插件将原命名转化成不重复的随机命名,从根本上避免命名冲突。比较著名的解决方案就是 CSS Modules。
下面是一段 css 样式代码:
/* style.css */.className {color: green;}
借助 css Modules 插件,可以将 css 以 JSON 对象的形式引用和使用。
import styles from "./style.css";// import { className } from "./style.css";element.innerHTML = '<div class="' + styles.className + '">';
编译之后的代码,样式类名被转化成了随机名称:
<div class="_3zyde4l1yATCOkgn-DBWEL"></div><style>._3zyde4l1yATCOkgn-DBWEL {color: green;}</style>
但这种命名方式带来了一个问题,那就是如果想在引用组件的同时,覆盖它的样式会变得困难,因为编译后的样式名是随机。例如,在上面的示例代码中,如果想在另一个组件中覆盖 className 样式就很困难,而在手动命名情况下则可以直接重新定义 className 样式进行覆盖。
如何高效复用样式
如果你有一些项目开发经历,一定发现了某些样式会经常被重复使用,比如:
- display:inline-block
- clear:both
- position:relative
- ......
这违背了 DRY(Don't Repeat Yourself)原则,完全可以通过设置为全局公共样式来减少重复定义。
哪些样式规则可以设置为全局公共样式呢?
- 首先是具有枚举值的属性,除了上面提到的,还包括 cursor:pointer、float:left 等。
- 其次是那些特定数值的样式属性值,比如 margin: 0、left: 0、height: 100%。
- 最后是设计规范所使用的属性,比如设计稿中规定的几种颜色。
样式按照小粒度拆分之后命名规范也很重要,合理的命名规范可以避免公共样式重复定义,开发时方便快速引用。
前面提到的语义化命名方式 BEM 显然不太适合。首先全局样式是基于样式属性和值的,是无语义的;其次对于这种复用率很高的样式应该尽量保证命名简短方便记忆,所以推荐使用更简短、更方便记忆的命名规则。比如我们团队所使用的就是“属性名首字母 + 横线 + 属性值首字母”的方式进行命名。
举个例子,比如对于 display:inline-block 的样式属性值,它的属性为“display”缩写为“d”,值为“inline-block”,缩写为“ib”,通过短横线连接起来就可以命名成“d-ib”;同样,如果工程师想设置一个 float:left 的样式,也很容易想到使用“f-l”的样式名。
那会不会出现重复定义呢?这个问题很好解决,按照字母序升序定义样式类就可以了。
延伸:值得关注的 CSS in JavaScript
我们都知道 Web 标准提倡结构、样式、行为分离(分别对应 HTML、CSS、JavaScript 三种语言),但 React.js 的一出现就开始颠覆了这个原则。
先是通过 JSX 将 HTML 代码嵌入进 JavaScript 组件,然后又通过 CSS in JavaScript 的方式将 CSS 代码也嵌入进 JavaScript 组件。这种“all in JavaScript”的方式确实有悖 Web 标准。但这种编写方式和日益盛行的组件化概念非常契合,具有“高内聚”的特性,所以未来标准有所改变也未尝不可能。这也正是我们需要关注 CSS in JavaScript 技术的原因。
相对于使用预处理语言编写样式,CSS in JavaScript 具有两个不那么明显的优势:
- 可以通过随机命名解决作用域问题,但命名规则和 CSS Modules 都可以解决这个问题;
- 样式可以使用 JavaScript 语言特性,比如函数、循环,实现元素不同的样式效果可以通过新建不同样式类,修改元素样式类来实现。
我们以 styled-compoents 为例进行说明,下面是示例代码,第一段是源代码:
// 源代码const Button = styled.button`background: transparent;border-radius: 3px;border: 2px solid palevioletred;color: palevioletred;margin: 0.5em 1em;padding: 0.25em 1em;${props => props.primary && css`background: palevioletred;color: white;`}`;const Container = styled.div`text-align: center;`render(<Container><Button>Normal Button</Button><Button primary>Primary Button</Button></Container>);
第二段是编译后生成的:
<!--HTML 代码--><div class="sc-fzXfNJ ciXJHl"><button class="sc-fzXfNl hvaMnE">Normal Button</button><button class="sc-fzXfNl kiyAbM">Primary Button</button></div>/*CSS 代码*/.ciXJHl {text-align: center;}.hvaMnE {color: palevioletred;background: transparent;border-radius: 3px;border-width: 2px;border-style: solid;border-color: palevioletred;border-image: initial;margin: 0.5em 1em;padding: 0.25em 1em;}.kiyAbM {color: white;border-radius: 3px;border-width: 2px;border-style: solid;border-color: palevioletred;border-image: initial;margin: 0.5em 1em;padding: 0.25em 1em;background: palevioletred;}
对比以上两段代码很容易发现,在编译后的样式代码中有很多重复的样式规则。这并不友好,不仅增加了编写样式的复杂度和代码量,连编译后也增加了冗余代码。
styled-components 只是 CSS in JavaScript 的一种解决方案,其他解决方案还有很多,有兴趣的同学可以点击这里查阅 GitHub 上的资料学习,上面收录了现有的 CSS in JavaScript 解决方案。
总结
对于样式文件的管理,推荐使用 7-1 模式简化后的目录结构,包括 pages/、components/、abastracts/、base/ 4 个目录。对于样式命名,可以采用 BEM 来命名组件、面向属性的方式来命名公共样式。
最后留一道思考题:说说你在项目中是如何管理样式代码的?
加餐1:手写 CSS 预处理
功能需求
这一课时我们来写一个 CSS 预处理器,它的功能可以理解为精简版的 stylus,主要实现的功能有:
- 用空格和换行符替代花括号、冒号和分号;
- 支持选择器的嵌套组合;
- 支持以“$”符号开头的变量定义和使用。
如果你对这种风格不是很熟悉也没关系,通过下面这个例子你就能很快明白。
目标 CSS 代码,为 5 条样式规则。第 1 条和第 5 条样式规则是最简单的,使用 1 个选择器,定义了 1 条样式属性;第 2 条规则多用了一个标签选择器,样式属性值为多个字符串组成;第 3 条规则使用了类选择器;第 4 条规则增加了属性选择器,并且样式属性增加为 2 条。
div {color:darkkhaki;}div p {border:1px solid lightgreen;}div .a-b {background-color:lightyellow;}div .a-b [data] {padding:15px;font-size:12px;}.d-ib {display:inline-block;}
再来看看“源代码”,首先声明了两个变量,然后通过换行缩进定义了上述样式规则中的选择器和样式:
$ib inline-block$borderColor lightgreendivpborder 1px solid $borderColorcolor darkkhaki.a-bbackground-color lightyellow[data]padding 15pxfont-size 12px.d-ibdisplay $ib
像上面这种强制缩进换行的风格应用非常广泛,比如编程语言 Python、HTML 模板 pug、预处理器 Sass(以“.sass”为后缀的文件)。
这种风格可能有些工程师并不适应,因为缩进空格数不一致就会导致程序解析失败或执行出错。但它也有一些优点,比如格式整齐,省去了花括号等冗余字符,减少了代码量。推荐大家在项目中使用。
编译器
对预处理器这种能将一种语言(法)转换成另一种语言(法)的程序一般称之为“编译器”。我们平常所知的高级语言都离不开编译器,比如 C++、Java、JavaScript。
不同语言的编译器的工作流程有些差异,但大体上可以分成三个步骤:解析(Parsing)、转换(Transformation)及代码生成(Code Generation)。
解析
解析步骤一般分为两个阶段:词法分析和语法分析。
词法分析就是将接收到的源代码转换成令牌(Token),完成这个过程的函数或工具被称之为词法分析器(Tokenizer 或 Lexer)。
令牌由一些代码语句的碎片生成,它们可以是数字、标签、标点符号、运算符,或者其他任何东西。
将代码令牌化之后会进入语法分析,这个过程会将之前生成的令牌转换成一种带有令牌关系描述的抽象表示,这种抽象的表示称之为抽象语法树(Abstract Syntax Tree,AST)。完成这个过程的函数或工具被称为语法分析器(Parser)。
抽象语法树通常是一个深度嵌套的对象,这种数据结构不仅更贴合代码逻辑,在后面的操作效率方面相对于令牌数组也更有优势。
可以回想一下,我们在第 06 讲中提到的解析 HTML 流程也包括了这两个步骤。
转换
解析完成之后的下一步就是转换,即把 AST 拿过来然后做一些修改,完成这个过程的函数或工具被称之为转换器(Transformer)。
在这个过程中,AST 中的节点可以被修改和删除,也可以新增节点。根本目的就是为了代码生成的时候更加方便。
代码生成
编译器的最后一步就是根据转换后的 AST 来生成目标代码,这个阶段做的事情有时候会和转换重叠,但是代码生成最主要的部分还是根据转换后的 AST 来输出代码。完成这个过程的函数或工具被称之为生成器(Generator)。
代码生成有几种不同的工作方式,有些编译器将会重用之前生成的令牌,有些会创建独立代码
表示,以便于线性地输出代码。但是接下来我们还是着重于使用之前生成好的 AST。
代码生成器必须知道如何“打印”转换后的 AST 中所有类型的节点,然后递归地调用自身,直到所有代码都被打印到一个很长的字符串中。
代码实现
学习了编译器相关知识之后,我们再来按照上述步骤编写代码。
词法分析
在进行词法分析之前,首先要考虑字符串可以被拆分成多少种类型的令牌,然后再确定令牌的判断条件及解析方式。
通过分析源代码,可以将字符串分为变量、变量值、选择器、属性、属性值 5 种类型。但其中属性值和变量可以合并成一类进行处理,为了方便后面语法分析,变量可以拆分成变量定义和变量引用。
由于缩进会对语法分析产生影响(样式规则缩进空格数决定了属于哪个选择器),所以也要加入令牌对象。
因此一个令牌对象结构如下,type 属性表示令牌类型,value 属性存储令牌字符内容,indent 属性记录缩进空格数:
{type: "variableDef" | "variableRef" | "selector" | "property" | "value", //枚举值,分别对应变量定义、变量引用、选择器、属性、值value: string, // token字符值,即被分解的字符串indent: number // 缩进空格数,需要根据它判断从属关系}
然后确定各种类型令牌的判断条件:
- variableDef,以“”符号开头,该行前面有非空字符串;
- selector,独占一行,该行无其他非空字符串;
- property,以字母开头,该行前面无其他非空字符串;
- value,非该行第一个字符串,且该行第一个字符串为 property 或 variableDef 类型。
最后再来确定令牌解析方式。
一般进行词法解析的时候,可以逐个字符进行解析判断,但考虑到源代码语法的特殊性——换行符和空格缩进会影响语法解析,所以可以考虑逐行逐个单词进行解析。
词法分析代码如下所示:
function tokenize(text) {return text.trim().split(/\n|\r\n/).reduce((tokens, line, idx) => {const spaces = line.match(/^\s+/) || ['']const indent = spaces[0].lengthconst input = line.trim()const words = input.split(/\s/)let value = words.shift()if (words.length === 0) {tokens.push({type: 'selector',value,indent})} else {let type = ''if (/^\$/.test(value)) {type = 'variableDef'} else if (/^[a-zA-Z-]+$/.test(value)) {type = 'property'} else {throw new Error(`Tokenize error:Line ${idx} "${value}" is not a vairable or property!`)}tokens.push({type,value,indent})while (value = words.shift()) {tokens.push({type: /^\$/.test(value) ? 'variableRef' : 'value',value,indent: 0})}}return tokens;}, [])}
语法分析
现在我们来分析如何将上一步生成的令牌数组转化成抽象语法树,树结构相对于数组而言,最大的特点是具有层级关系,哪些令牌具有层级关系呢?
从缩进中不难看出,选择器与选择器、选择器与属性都存在层级关系,那么我们可以分别通过 children 属性和 rules 属性来描述这两类层级关系。
要判断层级关系需要借助缩进空格数,所以节点需要增加一个属性 indent。
考虑到构建树时可能会产生回溯,那么可以设置一个数组来记录当前构建路径。当遇到非父子关系的节点时,沿着当前路径往上找到其父节点。
最后为了简化树结构,这一步也可以将变量值进行替换,从而减少变量节点。
所以抽象语法树可以写成如下结构。首先定义一个根节点,在其 children 属性中添加选择器节点,选择器节点相对令牌而言增加了 2 个属性:
- rules,存储当前选择器的样式属性和值组成的对象,其中值以字符串数组的形式存储;
- children,子选择器节点。
{type: 'root',children: [{type: 'selector',value: stringrules: [{property: string,value: string[],}],indent: number,children: []}]}
由于考虑到一个属性的值可能会由多个令牌组成,比如 border 属性的值由“1px” “solid” “$borderColor” 3 个令牌组成,所以将 value 属性设置为字符串数组。
语法分析代码如下所示。首先定义一个根节点,然后按照先进先出的方式遍历令牌数组,遇到变量定义时,将变量名和对应的值存入到缓存对象中;当遇到属性时,插入到当前选择器节点的 rules 属性中,遇到值和变量引用时都将插入到当前选择器节点 rules 属性数组最后一个对象的 value 数组中,但是变量引用在插入之前需要借助缓存对象的变量值进行替换。当遇到选择器节点时,则需要往对应的父选择器节点 children 属性中插入,并将指针指向被插入的节点,同时记得将被插入的节点添加到用于存储遍历路径的数组中:
function parse(tokens) {var ast = {type: 'root',children: [],indent: -1};let path = [ast]let preNode = astlet nodelet vDict = {}while (node = tokens.shift()) {if (node.type === 'variableDef') {if (tokens[0] && tokens[0].type === 'value') {const vNode = tokens.shift()vDict[node.value] = vNode.value} else {preNode.rules[preNode.rules.length - 1].value = vDict[node.value]}continue;}if (node.type === 'property') {if (node.indent > preNode.indent) {preNode.rules.push({property: node.value,value: []})} else {let parent = path.pop()while (node.indent <= parent.indent) {parent = path.pop()}parent.rules.push({property: node.value,value: []})preNode = parentpath.push(parent)}continue;}if (node.type === 'value') {try {preNode.rules[preNode.rules.length - 1].value.push(node.value);} catch (e) {console.error(preNode)}continue;}if (node.type === 'variableRef') {preNode.rules[preNode.rules.length - 1].value.push(vDict[node.value]);continue;}if (node.type === 'selector') {const item = {type: 'selector',value: node.value,indent: node.indent,rules: [],children: []}if (node.indent > preNode.indent) {path[path.length - 1].indent === node.indent && path.pop()path.push(item)preNode.children.push(item);preNode = item;} else {let parent = path.pop()while (node.indent <= parent.indent) {parent = path.pop()}parent.children.push(item)path.push(item)}}}return ast;}
转换
在转换之前我们先来看看要生成的目标代码结构,其更像是一个由一条条样式规则组成的数组,所以我们考虑将抽象语法树转换成“抽象语法数组”。
在遍历树节点时,需要记录当前遍历路径,以方便选择器的拼接;同时可以考虑将“值”类型的节点拼接在一起。最后形成下面的数组结构,数组中每个元素对象包括两个属性,selector 属性值为当前规则的选择器,rules 属性为数组,数组中每个元素对象包含 property 和 value 属性:
{selector: string,rules: {property: string,value: string}[]}[]
具体代码实现如下,递归遍历抽象语法树,遍历的时候完成选择器拼接以及属性值的拼接,最终返回一个与 CSS 样式规则相对应的数组:
function transform(ast) {let newAst = [];function traverse(node, result, prefix) {let selector = ''if (node.type === 'selector') {selector = [...prefix, node.value];result.push({selector: selector.join(' '),rules: node.rules.reduce((acc, rule) => {acc.push({property: rule.property,value: rule.value.join(' ')})return acc;}, [])})}for (let i = 0; i < node.children.length; i++) {traverse(node.children[i], result, selector)}}traverse(ast, newAst, [])return newAst;}
实现方式比较简单,通过函数递归遍历树,然后重新拼接选择器和属性的值,最终返回数组结构。
代码生成
有了新的“抽象语法数组”,生成目标代码就只需要通过 map 操作对数组进行遍历,然后将选择器、属性、值拼接成字符串返回即可。
具体代码如下:
function generate(nodes) {return nodes.map(n => {let rules = n.rules.reduce((acc, item) => acc += `${item.property}:${item.value};`, '')return `${n.selector} {${rules}}`}).join('\n')}
总结
这一课时动手实践了一个简单的 CSS 预处理器,希望你能更好地掌握 CSS 工具预处理器的基本原理,同时也希望通过这个实现过程带你跨入编译器的大门。编译器属于大家日用而不知的重要工具,像 webpack、Babel这些著名工具以及 JavaScript 引擎都用到了它。
最后布置一道思考题:你能否为预处理器添加一些其他功能呢(比如局部变量)?
第06讲:浏览器如何渲染页面?
这一课时我将结合代码实例为你讲解浏览器渲染页面时的流程和步骤。
先来看一个例子,假如我们在浏览器中输入了一个网址,得到了下面的 html 文件,渲染引擎是怎样通过解析代码生成页面的呢?
<html><head></head><body>lagou</body></html>
从 HTML 到 DOM
1. 字节流解码
对于上面的代码,我们看到的是它的字符形式。而浏览器通过 HTTP 协议接收到的文档内容是字节数据,下图是抓包工具截获的报文截图,报文内容为左侧高亮显示的区域(为了查看方便,该工具将字节数据以十六进制方式显示)。当浏览器得到字节数据后,通过“编码嗅探算法”来确定字符编码,然后根据字符编码将字节流数据进行解码,生成截图右侧的字符数据,也就是我们编写的代码。
这个把字节数据解码成字符数据的过程称之为“字节流解码”。
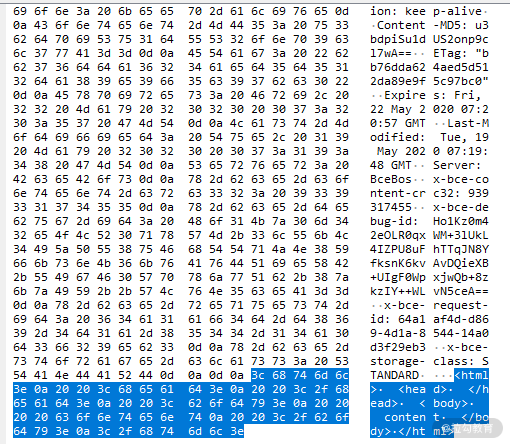
我们通过浏览器调试工具查看网络请求时,也是经过了上述操作过程,才能直观地看到字符串。
2. 输入流预处理
通过上一步解码得到的字符流数据在进入解析环节之前还需要进行一些预处理操作。比如将换行符转换成统一的格式,最终生成规范化的字符流数据,这个把字符数据进行统一格式化的过程称之为“输入流预处理”。
3. 令牌化
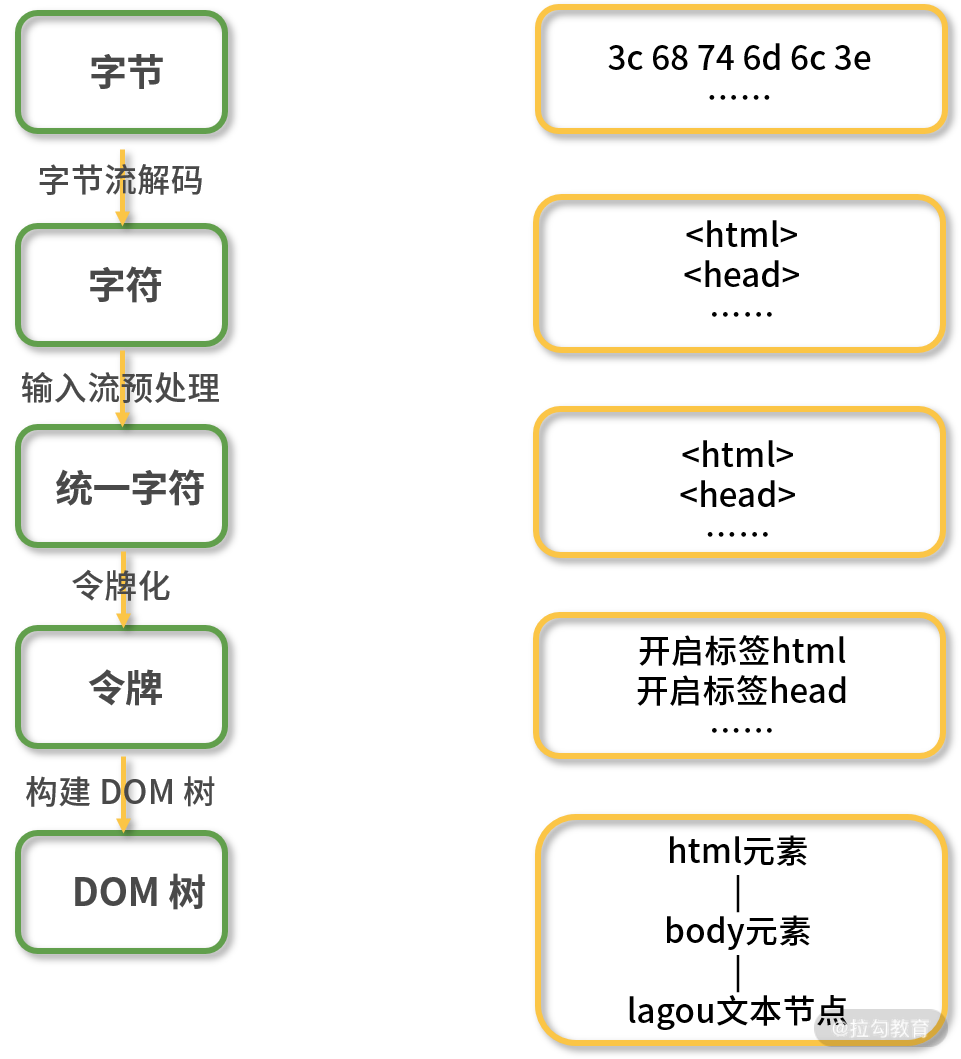
经过前两步的数据解码和预处理,下面就要进入重要的解析步骤了。
解析包含两步,第一步是将字符数据转化成令牌(Token),第二步是解析 HTML 生成 DOM 树。先来说说令牌化,其过程是使用了一种类似状态机的算法,即每次接收一个或多个输入流中的字符;然后根据当前状态和这些字符来更新下一个状态,也就是说在不同的状态下接收同样的字符数据可能会产生不同的结果,比如当接收到“body”字符串时,在标签打开状态会解析成标签,在标签关闭状态则会解析成文本节点。
这个算法的解析规则较多,在此就不一一列举了,有兴趣的同学可以通过下面这个简单的例子来理解其原理。
上述 html 代码的标记过程如下:
- 初始化为“数据状态”(Data State);
- 匹配到字符 <,状态切换到 “标签打开状态”(Tag Open State);
- 匹配到字符 !,状态切换至 “标签声明打开状态”(Markup Declaration Open State),后续 7 个字符可以组成字符串 DOCTYPE,跳转到 “DOCTYPE 状态”(DOCTYPE State);
- 匹配到字符为空格,当前状态切换至 “DOCTYPE 名称之前状态”(Before DOCTYPE Name State);
- 匹配到字符串 html,创建一个新的 DOCTYPE 标记,标记的名字为 “html” ,然后当前状态切换至 “DOCTYPE 名字状态”(DOCTYPE Name State);
- 匹配到字符 >,跳转到 “数据状态” 并且释放当前的 DOCTYPE 标记;
- 匹配到字符 <,切换到 “标签打开状态”;
- 匹配到字符 h,创建一个新的起始标签标记,设置标记的标签名为空,当前状态切换至 “标签名称状态”(Tag Name State);
- 从字符 h 开始解析,将解析的字符一个一个添加到创建的起始标签标记的标签名中,直到匹配到字符 >,此时当前状态切换至 “数据状态” 并释放当前标记,当前标记的标签名为 “html” 。
- 解析后续的 的方式与 一致,创建并释放对应的起始标签标记,解析完毕后,当前状态处于 “数据状态” ;
- 匹配到字符串 “标记” ,针对每一个字符,创建并释放一个对应的字符标记,解析完毕后,当前状态仍然处于 “数据状态” ;
- 匹配到字符 <,进入 “标签打开状态” ;
- 匹配到字符 /,进入 “结束标签打开状态”(End Tag Open State);
- 匹配到字符 b,创建一个新的结束标签标记,设置标记的标签名为空,当前状态切换至“标签名称状态”(Tag Name State);
- 重新从字符 b 开始解析,将解析的字符一个一个添加到创建的结束标签标记的标签名中,直到匹配到字符 >,此时当前状态切换至 “数据状态” 并释放当前标记,当前标记的标签名为 “body”;
- 解析 的方式与 一样;
- 所有的 html 标签和文本解析完成后,状态切换至 “数据状态” ,一旦匹配到文件结束标志符(EOF),则释放 EOF 标记。
最终生成类似下面的令牌结构:
开始标签:html开始标签:head结束标签:head开始标签:body字符串:lagou结束标签:body结束标签:html
补充 1:遇到 script 标签时的处理
如果在 HTML 解析过程中遇到 script 标签,则会发生一些变化。
如果遇到的是内联代码,也就是在 script 标签中直接写代码,那么解析过程会暂停,执行权限会转给 JavaScript 脚本引擎,待 JavaScript 脚本执行完成之后再交由渲染引擎继续解析。有一种情况例外,那就是脚本内容中调用了改变 DOM 结构的 document.write() 函数,此时渲染引擎会回到第二步,将这些代码加入字符流,重新进行解析。
如果遇到的是外链脚本,那么渲染引擎会按照我们在第 01 课时中所述的,根据标签属性来执行对应的操作。
4. 构建 DOM 树
解析 HTML 的第二步是树构建。
浏览器在创建解析器的同时会创建一个 Document 对象。在树构建阶段,Document 会作为根节点被不断地修改和扩充。标记步骤产生的令牌会被送到树构建器进行处理。HTML 5 标准中定义了每类令牌对应的 DOM 元素,当树构建器接收到某个令牌时就会创建该令牌对应的 DOM 元素并将该元素插入到 DOM 树中。
为了纠正元素标签嵌套错位的问题和处理未关闭的元素标签,树构建器创建的新 DOM 元素还会被插入到一个开放元素栈中。
树构建算法也可以采用状态机的方式来描述,具体我们以步骤 1 的 HTML 代码为例进行举例说明。
- 进入初始状态 “initial” 模式;
- 树构建器接收到 DOCTYPE 令牌后,树构建器会创建一个 DocumentType 节点附加到 Document 节点上,DocumentType 节点的 name 属性为 DOCTYPE 令牌的名称,切换到 “before html” 模式;
- 接收到令牌 html 后,树构建器创建一个 html 元素并将该元素作为 Document 的子节点插入到 DOM 树中和开放元素栈中,切换为 “before head” 模式;
- 虽然没有接收到 head 令牌,但仍然会隐式地创建 head 元素并加到 DOM 树和开放元素栈中,切换到“in head”模式;
- 将开放元素栈中的 head 元素弹出,进入 “after head”模式;
- 接收到 body 令牌后,会创建一个 body 元素插入到 DOM 树中同时压入开放元素栈中,当前状态切换为 “in body” 模式;
- 接收到字符令牌,创建 Text 节点,节点值为字符内容“标记”,将 Text 节点作为 body 元素节点插入到 DOM 树中;
- 接收到结束令牌 body,将开放元素栈中的 body 元素弹出,切换至 “after body” 模式;
- 接收到结束令牌 html,将开放元素栈中的 html 元素弹出,切换至 “after after body” 模式;
- 接收到 EOF 令牌,树构建器停止构建,html 文档解析过程完成。
最终生成下面的 DOM 树结构:
Document/ \DocumentType HTMLHtmlElement/ \HTMLHeadElement HTMLBodyElement|TextNode
补充 2:从 CSS 到 CSSOM
渲染引擎除了解析 HTML 之外,也需要解析 CSS。
CSS 解析的过程与 HTML 解析过程步骤一致,最终也会生成树状结构。
与 DOM 树不同的是,CSSOM 树的节点具有继承特性,也就是会先继承父节点样式作为当前样式,然后再进行补充或覆盖。下面举例说明。
body { font-size: 12px }p { font-weight: light }span { color: blue }p span { display: none }img { float: left }
对于上面的代码,会解析生成类似下面结构的 DOM 树:
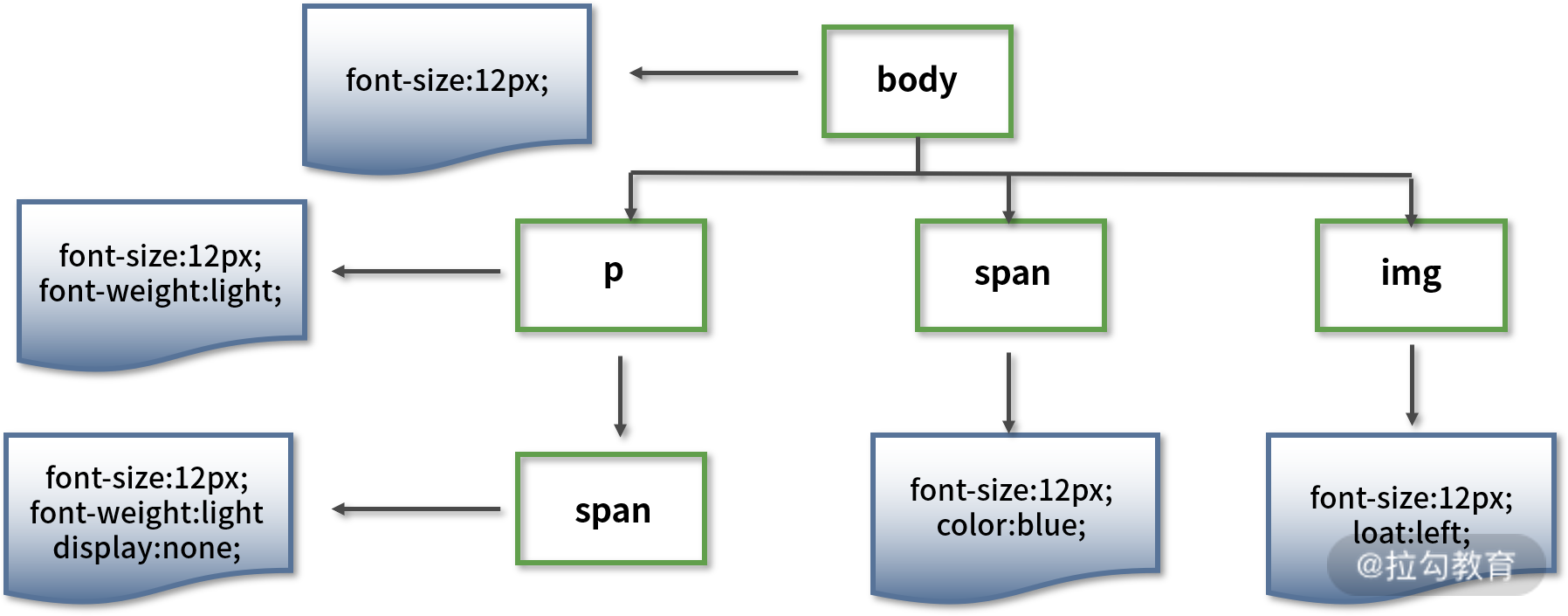
需要注意的是,上图中的 CSSOM 树并不完整,完整的 CSSOM 树还应当包括浏览器提供的默认样式(也称为“User Agent 样式”)。
从 DOM 到渲染
有了 DOM 树和 CSSOM 树之后,渲染引擎就可以开始生成页面了。
5. 构建渲染树
DOM 树包含的结构内容与 CSSOM 树包含的样式规则都是独立的,为了更方便渲染,先需要将它们合并成一棵渲染树。
这个过程会从 DOM 树的根节点开始遍历,然后在 CSSOM 树上找到每个节点对应的样式。
遍历过程中会自动忽略那些不需要渲染的节点(比如脚本标记、元标记等)以及不可见的节点(比如设置了“display:none”样式)。同时也会将一些需要显示的伪类元素加到渲染树中。
对于上面的 HTML 和 CSS 代码,最终生成的渲染树就只有一个 body 节点,样式为 font-size:12px。
6. 布局
生成了渲染树之后,就可以进入布局阶段了,布局就是计算元素的大小及位置。
计算元素布局是一个比较复杂的操作,因为需要考虑的因素有很多,包括字体大小、换行位置等,这些因素会影响段落的大小和形状,进而影响下一个段落的位置。
布局完成后会输出对应的“盒模型”,它会精确地捕获每个元素的确切位置和大小,将所有相对值都转换为屏幕上的绝对像素。
7. 绘制
绘制就是将渲染树中的每个节点转换成屏幕上的实际像素的过程。得到布局树这份“施工图”之后,渲染引擎并不能立即绘制,因为还不知道绘制顺序,如果没有弄清楚绘制顺序,那么很可能会导致页面被错误地渲染。
例如,对于使用 z-index 属性的元素(如遮罩层)如果未按照正确的顺序绘制,则将导致渲染结果和预期不符(失去遮罩作用)。
所以绘制过程中的第一步就是遍历布局树,生成绘制记录,然后渲染引擎会根据绘制记录去绘制相应的内容。
对于无动画效果的情况,只需要考虑空间维度,生成不同的图层,然后再把这些图层进行合成,最终成为我们看到的页面。当然这个绘制过程并不是静态不变的,会随着页面滚动不断合成新的图形。
总结
这一课时主要讲解了浏览器渲染引擎生成页面的 7 个步骤,前面 4 个步骤为 DOM 树的生成过程,后面 3 个步骤是利用 DOM 树和 CSSOM 树来渲染页面的过程。我们想要理解和记忆这些过程其实很简单,那就是以数据变化为线索,具体来说数据的变化过程为:
字节 → 字符 → 令牌 → 树 → 页面
最后布置一道思考题:在构建渲染树的时候,渲染引擎需要遍历 DOM 树节点并从 CSSOM 树中找到匹配的样式规则,在匹配过程中是通过自上而下还是自下而上的方式呢?为什么?
