@Humbert
2018-02-19T06:01:58.000000Z
字数 1771
阅读 1216
文科僧的数据结构入门指南(一):地址, 数组与链表
Pre
- 我们使用的计算机由运算器、控制器、存储器、输入设备和输出设备组成.其中运算器和控制器现在被集成到了CPU中,他们负责执行程序;输入设备与输出设备负责与我们交互;而存储器一方面负责储存数据(电影,文档等,一般被放在硬盘中),另一方面则负责在程序运行时为他们提供空间(一般在RAM即内存中,现在主流的电脑一般为4G或8G). 数据结构是计算机中存储、组织数据的方式,他们被写在程序中,因此在程序运行时才会发挥他们的作用.
1GB = 1024MB
1MB = 1024KB
1KB = 1024Byte
1Byte = 8bit
bit为信息的最小单位,其值为0或1,但是因为一个bit能表示的东西太有限了,意义不大,因此把8个bit称为一个Byte.Char类型为字符形,用来存放字符,一般占用1Byte
Int类型为整形,用来存放数字,一般占用4Byte
地址
地址指内存地址,因为内存有那么多,必须需要用标识来指示它们,地址即为内存的标识.因为他为标识,因此地址也被成为指针.
每一个Byte都有它自己的地址.地址为从0至内存大小的数字,比如你的内存有2KB, 则该块内存的地址就是从0-2047(计算机从0开始计数,因此0到2047即有了2048个数字)的数字.
数组
一个程序要完成一定的功能,变量是不可避免的.
变量可以指在电脑内存里存在值的被命名的存储空间。变量通常是可被修改的,即可以用来表示可变的状态。这是许多语言的基本概念之一。当某个已宣告变量开始使用,编译器通常会设定一个空间来储存所给出的值。稍后该变量不再使用时,那些空间可以回收。--变量在维基百科上的定义
但是一个变量只能用来存放一个元素,如果你需要存放一组相互之间有关联的数据(如所有Stark家族孩子的年龄),你就需要数组.
在计算机科学中,数组是由相同类型的元素(element)的集合所组成的数据结构,分配一块连续的内存来存储。利用元素的索引(index)可以计算出该元素对应的存储地址。
如图表示一个数组
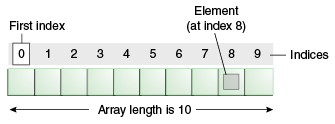
可以注意到数组由两个部分组成,一个是下标即index,另一个即为填充在其中的元素.
因为其在内存中为连续的,因此可以通过其下标来直接获得其中填充的元素.
比如你去九号楼下面取快递,因为它给货柜都编号了,所以你根据编号可以很容易找到你的快递在哪,而不需要从第一个货柜开始一个个地找.
int a[5]; //声明一个大小为5,类型为int的数组,此时计算机会在内存中分配一块连续的20Byte的空间,因为每个int占用4Byte, 5个元素占用20Byte.但是并不会决定每个元素的值.a[0] = 10; //让第一个元素值为10.a[1] = a[0]; //让第二个元素的值等于第一个元素的值
链表
数组很好用,但是它有他的不方便之处,比如你要去掉(erase)第二个元素,你需要将第二个元素之后的所有元素全都一个个向前动一下.
int a[5] = {0, 2, 1,2,3}; //声明一个数组a, 赋值其5个数据分别为0,2,1,2,3a[1] = a[2]; //注意a[1]为第二个元素,而不是第一个a[2] = a[3];a[3] = a[4];//之后的结果为 {0, 1, 2, 3, 3} 即抹除了第二个元素.
这样当然是很不方便的,所以,当你需要经常大规模的抹除或者添加元素时(添加时你需要把其后的元素一个个往后挪一个),你就需要链表来节省电脑运算的花销了.
一个链表由许多节点(Node)组成,一个Node最少要包括存放的数据部分(data)以及指向下一个节点的指针(next, 即下一个节点的地址,我们用它来标识数据存放的位置)
图为一个单向链表.

此时,如下图,我们要消除99那个节点,只需要将12的指针指向37的位置即可.

在代码上表示如下
Head->next = Head -> next -> next //Head表示头节点即12那个节点,令Head的next即指针部分指向next的next即可将99那个节点从链表中抹除掉.//之后的效果为12->37->End
理解了链表,就可以很容易地理解双向链表与循环链表了.
双向链表

即为一个节点既有下一个节点的地址,又有上一个节点的地址
循环链表

即为节点不会指向End(在计算机中地址为0的地方表示为结束,若next指向那里即为链表结束了),而是指向最开始的那个节点.
