@MrCauda
2023-06-28T08:27:53.000000Z
字数 95641
阅读 310
Java面试内容
面试
1、Integer
Integer范围为-128-127,超出部分则会new一个新对象,因此无法使用==进行比较,需要使用a.compareTo(b),-1为a < b,0为a=b,1为a > b
自动拆装箱:
装箱:将基础数据类型用他们对应的包装类包装
拆箱:将包装类转换为对应的基础数据类型
自动拆装箱的问题:
包装对象之间不能简单的使用==进行比较,需要使用compare或者equals
如果包装对象为null,自动拆箱会产生npe问题
如果一个for循环中有大量拆装箱操作,会浪费很多资源
为什么需要自动拆装箱:
因为Java作为面向对象语言,会将数据数据也定义成对象,此时需要将基础类型装箱为包装对象。自动装箱也会方便向集合类中添加数据,不需要手动装箱。而对包装对象进行运算时,会进行自动拆箱,使用基础类型进行计算。
// valueOf()进行装箱Integer t = Integer.valueOf(123);// .intValue()进行拆箱int tt = t.intValue();
包装类型和基本类型比较大小会先将包装类进行拆箱成基本数据类型,然后再进行比较。
包装类型的运算会将包装类型自动拆箱成基本类型再运算。
Integer如果是直接以=号赋值,则-128~127之间相等,之外的范围不等。但如果是Integer(val)的形式赋值,则为一个全新的对象。
2、static、final、transient
static关键字:
static修饰的方法、变量是属于类本身的,不属于对象;
static方法只能访问static方法和数据,不能使用this或super;
子类不继承父类static变量和方法,因为属于类本身,但子类可以访问;
子类和父类同名static变量和方法相互独立,不存在重写关系
final关键字:
修饰类:表示类不可以被继承
修饰方法:表示方法不可以被子类重写
修饰变量:变量赋值后不可以被更改。如果是引用类型,则被引用的地址不能变,只能修改其属性。
修饰类变量(静态变量):必须要在静态代码块中初始化或者在定义时赋初值。
修饰成员变量:必须要赋初始值且只能初始化一次。
修饰局部变量:可以赋初值,也可以不赋初值。但包括赋初值只能赋值一次。
transient关键字:
当一个对象被序列化时,transient修饰的变量不会被序列化。
3、集合类
集合类存放于Java.util包中,主要有3种:set(集)、list(列表包含Queue)和map(映射)。
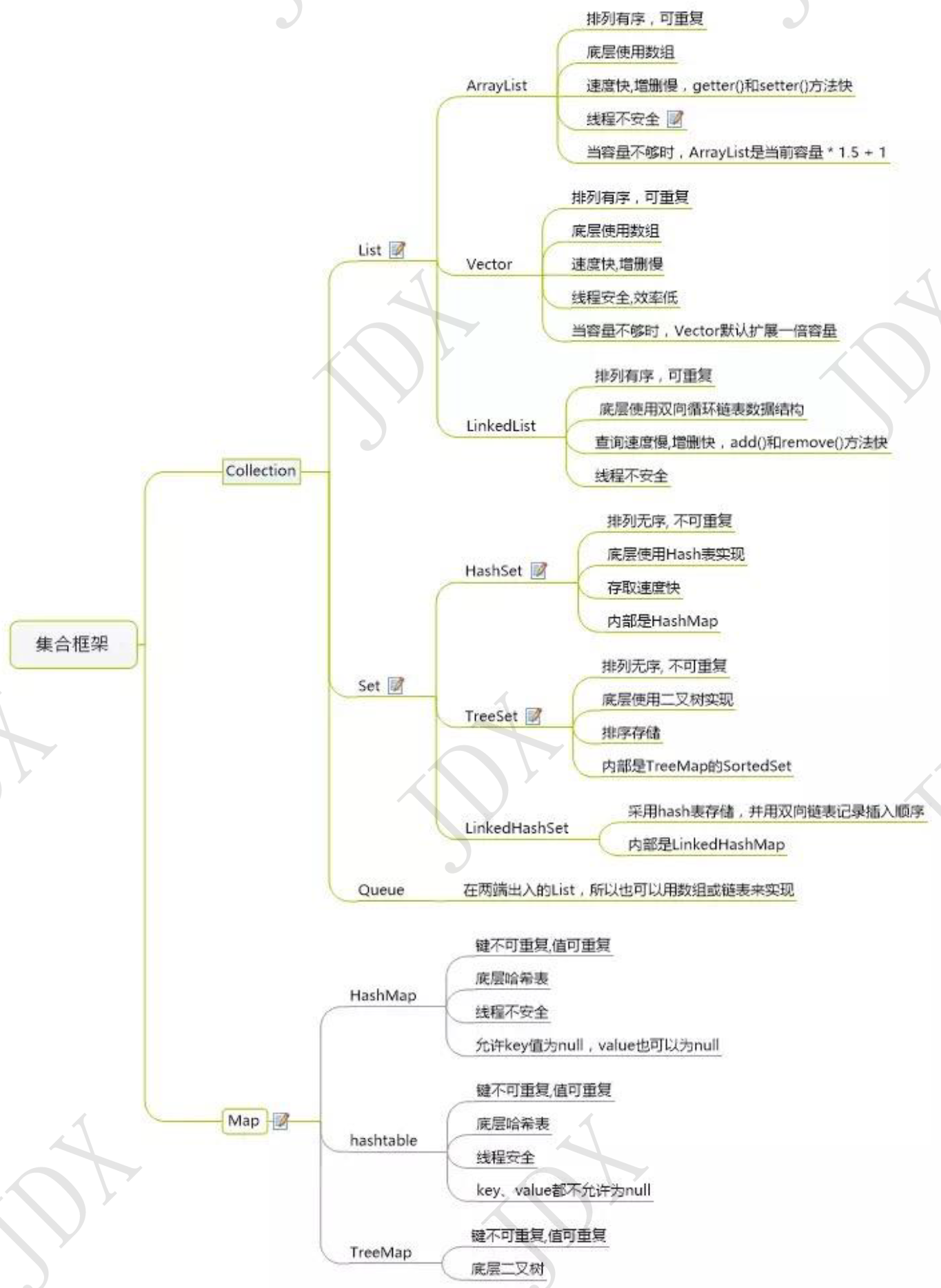
List和Set继承自Collection接口。
Set无序不允许元素重复。HashSet和TreeSet是两个主要的实现类。
List有序且允许元素重复,支持null对象。ArrayList、LinkedList和Vector是三个主要的实现类。
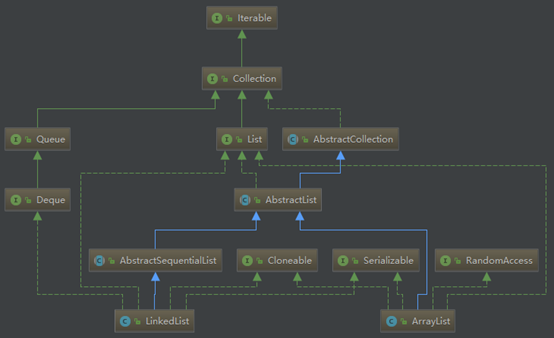
Map也属于集合系统,但和Collection接口没关系。Map是key对value的映射集合,其中key列就是一个集合。key不能重复,但是value可以重复。HashMap、TreeMap和Hashtable是三个主要的实现类。
SortedSet和SortedMap接口对元素按指定规则排序,SortedMap是对key列进行排序。
List
ArrayList
ArrayList实现了List接口,是非线程安全的;
ArrayList扩容首先判断新长度是否超过原长度,如果超过则将原长度扩至1.5倍,再次比较,如果满足要求,则将原内容复制到原长度1.5倍后的一个数组中。
线程不安全的原因是在对数组扩容和赋值时都可能会出现问题。
当线程A检查过数组长度确认可以添加后被挂起,而线程B同样执行完成刚好写满数组。线程A再次继续执行写入任务时,size++后会出现数组越界的情况。
另外在赋值和size++这里并非原子操作,可能出现线程A已经写入了数据但是尚未size++,线程B继续执行导致线程B覆盖了线程A的值。
ArrayList默认容量是10,如果初始化时一开始指定了容量,或者通过集合作为元素,则容量为指定的大小或参数集合的大小。每次扩容为原来的1.5倍,如果新增后超过这个容量,则容量为新增后所需的最小容量。如果增加0.5倍后的新容量超过限制的容量,则用所需的最小容量与限制的容量进行判断,超过则指定为Integer的最大值,否则指定为限制容量大小。然后通过数组的复制将原数据复制到一个更大(新的容量大小)的数组。
在ArrayList中,底层数组存/取元素效率非常的高(get/set),时间复杂度是O(1),而查找,插入和删除元素效率似乎不太高,时间复杂度为O(n)。(add时不考虑扩容的话,直接在底层数组最后添加一位,时间复杂度是O(1))
当ArrayLIst里有大量数据时,这时候去频繁插入/删除元素会触发底层数组频繁拷贝,效率不高,还会造成内存空间的浪费。
ArrayList和vector区别
ArrayList和Vector都实现了List接口,都是通过数组实现的。
Vector是线程安全的(在可能出现不安全情况的地方都使用了synchronized同步),而ArrayList是非线程安全的(多线程时,新增元素时可能数组越界)。
Vector缺省情况下自动增长原来一倍的数组长度,ArrayList增长原来的50%。
ArrayList和LinkedList区别及使用场景
区别
ArrayList底层是用数组实现的,第一次add操作将数组的长度初始化为10,可以认为ArrayList是一个可改变大小的数组。随着越来越多的元素被添加到ArrayList中,其规模是动态增加的,每次增长为原数组大小的1.5倍。
LinkedList底层是通过双向链表实现的,每个节点Node对象包括指向上一个Node对象和指向下一个Node对象,同时LinkedList还实现了Queue接口,所以他还提供了offer(), peek(), poll()等方法。
LinkedList和ArrayList相比,增删的速度较快。但是查询和修改值的速度较慢。
使用场景
LinkedList更适合从中间插入或者删除(链表的特性)。
ArrayList更适合检索和在末尾插入或删除(数组的特性)。
Set
Set注重独一无二的性质,该体系集合用于存储无序(存入和取出的顺序不一定相同)元素,值不能重复。
HashSet(Hash表)
存放的是哈希值,哈希值相同且值不同的元素会放在一起。底层实现是hashMap,通过判断hashCode相同的情况下是有存在相同元素来确保唯一性。
TreeSet(红黑树) (有序集合)
使用红黑树的原理对新增的对象按照指定的顺序排序(升序、降序),每增加一个对象都会进行排序,将对象插入的二叉树指定的位置。
treeset只能存储一个对象,即key。
TreeSet为基本操作(add、remove 和 contains)提供受保证的 log(n) 时间开销。
另外,TreeSet基于treeMap实现,是线程不安全的。 它的iterator 方法返回的迭代器是fail-fast的。
LinkHashSet(HashSet+LinkedHashMap)
底层使用LinkedHashMap(底层使用数组+双向链表实现)来保存所有元素。
数据唯一、存储取出顺序一致。
linkedHashSet和treeSet都支持顺序遍历,但treeSet还支持自然排序和自定义排序。
Map
TreeMap
TreeMap 是一个有序的key-value集合,它是通过红黑树实现的。
TreeMap 继承于AbstractMap,所以它是一个Map,即一个key-value集合。
TreeMap 实现了NavigableMap接口,意味着它支持一系列的导航方法。比如返回有序的key集合。
TreeMap 实现了Cloneable接口,意味着它能被克隆。
TreeMap 实现了java.io.Serializable接口,意味着它支持序列化(保证数据不会重复)。
TreeMap基于红黑树(Red-Black tree)实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
TreeMap的基本操作 containsKey、get、put 和 remove 的时间复杂度是 log(n) 。
TreeMap是线程不安全的。 它的iterator 方法返回的迭代器是fail-fastl(即需要保证在迭代过程中TreeMap没有结构变化)的。
HashTable实现原理
(1)是一个线程安全的散列表,存储内容是键值对映射,不支持和null键值对。底层也是数组+链表实现,大部分操作使用Syncronized保护。hashCode方法执行前没有判断是否为null,如果传入null值会导致报错,因此不支持null键值对。
(2)继承于Dictionary,实现了Map、Cloneable、java.io.Serializable接口
(3)线程安全,默认数组长度为11,负载因子为0.75,扩容方式是old*2+1;
HashMap实现原理
(1)基于Hash的map接口非同步实现, 无序且允许null的键值对。
(2)初始大小为16,默认负载因子0.75。当一个map填满了75%的bucket时候,将会创建原来HashMap大小的2倍的bucket数组,来重新调整map的大小,并将原来的对象放入新的bucket数组中
(3) put(K key, V value)
根据key的hashCode值重新计算出hash值(高位计算一次散列,防止低位不变高位变化造成冲突),既而得到这个元素在数组中的位置(下标)如果数组该位置上已经存放有其他元素了,那么在这个位置上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在链尾。如果数组该位置上没有元素,就直接将该元素放到此数组中的该位置上。
(4) get(Object key)
计算key的hashCode,找到数组中对应位置的某一元素,然后通过key的equals方法在对应位置的链表中找到需要的元素。
(5) 重新调整HashMap大小存在什么问题吗?(头插法造成环形链表)
重新调整hashMap大小,确实存在竞争,多线程环境,调整大小的过程中,存储在LinkedList中的元素的次序会反过来,因为移动到新的bucket位置的时候,HashMap并不会将元素放在LinkedList的尾部,而是放在头部,这是为了避免尾部遍历(tail traversing)。如果条件竞争发生了,那么就死循环了。
死锁出现原因是多个线程同时rehash并且同时操作到了同一个节点的链表,第一个线程完成了当前节点的rehash,链表倒转,但第二个节点指针未进行修改,产生循环。
public static int hashCode(byte[] value) {int h = 0;int length = value.length >> 1;for (int i = 0; i < length; i++) {h = 31 * h + getChar(value, i);}return h;}
hashmap为什么不是线程安全的
1.7中可能出现死循环(头插法)、数据丢失(头插法)、数据覆盖的问题。头插法多线程时可能会导致链表成环并且在环外的数据会丢失。
头插法链表成环:多线程操作在扩容时有多个线程同时操作。线程A先获取了链表的当前节点和下一个节点,时间片交给线程B并且完成转移,此时线程A的当前节点和下一个节点顺序与线程B操作后刚好相反。由此两者会互为下一个节点,导致成环。
1.8中会出现数据覆盖的问题。多线程插入hash值相同的数据时,如果在各自判断是否hash碰撞之后各自执行put操作,则会出现第二个线程覆盖了第一个线程写入的数据的情况。
HashMap中用对象做key:
需要重写hashCode方法和equals方法。hashCode是用来获取key对应的哈希码,但hashCode方法继承自Object类,默认获取的是对象的内存地址,若不改写hashCode则即使对象相同都不会有相同的哈希码,无法比较。equals方法用来比较相同哈希码上的对象是否相等,默认也是比较内存地址,完全相同的对象也会被认为不相等。
注:字符串因为String类中已经重写过hashCode方法,直接使用字符串内容生成哈希码,不存在这种问题;Integer类型也重写了hashCode方法,直接根据数值生成哈希码。
Object的方法:
hashcode:计算hash值
equals:判断是否相等,默认也是比较内存地址
notify:唤醒一个在此对象监视器下的线程
notifyAll:唤醒所有在此对象监视器下的线程
wait:使线程发生阻塞,直到其他线程通知唤醒
finalize:实例被垃圾回收器回收的时候触发的操作
clone:用于创建并返回当前对象的一份拷贝。没有实现cloneable接口的需要重写clone方法
toString:返回”类的名字 + @ + hashCode的十六进制字符串“,通常子类都会重写
getClass:获取当前类对象
HashMap和HashTable区别
1).HashTable的方法前面都有synchronized来同步,是线程安全的;HashMap未经同步,是非线程安全的。
2).HashTable不允许null值(key和value都不可以) ;HashMap允许null值(key和value都可以,一个null值的key和多个null值的value)。
3).HashTable有一个contains(Object value)功能和containsValue(Object value)功能一样。
4).HashTable使用Enumeration进行遍历;HashMap使用Iterator进行遍历。
5).HashTable中hash数组默认大小是11,增加的方式是old*2+1;HashMap中hash数组的默认大小是16,而且一定是2的指数,扩容*2。
6).哈希值的使用不同,HashTable直接使用对象的hashCode; HashMap重新计算hash值,而且用与代替求模。
7) hashTable初始化时直接使用该值创建底层数组。hashMap会使用比该值大的最近的2的幂次方作为容量。
JDK7 与 JDK8 中关于HashMap的对比
结构不同:
JDK7 HashMap结构为 数组+链表 的形式。
JDK8 HashMap结构为 数组+链表+红黑树的形式,当桶内元素大于8时,便会树化。
hash值的计算方式不同
JDK7 table在创建hashmap时分配空间。先扩容后赋值。
JDK8 在put的时候分配,如果table为空,则为table分配空间。先赋值后扩容。
1.7超过阈值且发生碰撞时扩容
1.8超过阈值就扩容
发生冲突时:
插入链表操作,JDK7是头插法,每次扩容导致链表顺序反转,JDK8是尾插法,扩容前后链表顺序不变。
resize操作:
JDK7 需要重新进行index的计算。
JDK8 不需要,通过判断相应的位是0还是1,要么依旧是原index,要么是oldCap + 原index。
JDK7 与 JDK8 中关于ConcurrentHashMap的对比
结构不同:
JDK1.7 由Segment数组结构和HashEntry数组结构组成。Segment实际继承自可重入锁(ReentrantLock)
JDK1.8 直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用Synchronized和CAS来操作,整个看起来就像是优化过且线程安全的HashMap。只要不发生hash碰撞就不会出问题。
锁的粒度不同:
JDK1.7 版本锁的粒度是基于Segment的,包含多个HashEntry,有上限(默认16,初始化后无法更改)
JDK1.8 的实现降低锁的粒度,锁的粒度就是HashEntry(首节点)
锁的替代:
JDK1.8为什么使用内置锁synchronized来代替重入锁ReentrantLock
因为粒度降低了,在相对而言的低粒度加锁方式,synchronized并不比ReentrantLock差,在粗粒度加锁中ReentrantLock可能通过Condition来控制各个低粒度的边界,更加的灵活,而在低粒度中,Condition的优势就没有了,基于JVM的synchronized优化空间更大,使用内嵌的关键字比使用API更加自然
size操作:
JDK7 先进行两次无锁统计,相同直接返回,不同再进行加锁统计
JDK8 扩容和addCount()方法就已经有处理
ConcurrentReferenceHashMap与ConcurrentHashMap的区别是ConcurrentReferenceHashMap能指定所存放对象的引用级别,适用于并发下Map的数据缓存。
例:ConcurrentReferenceHashMap map = new ConcurrentReferenceHashMap(16, ConcurrentReferenceHashMap.ReferenceType.WEAK);
comparable和comparator接口的区别:
comparable是java.lang下,有一个compareTo(Object obj1)方法
comparator是java.util下,有一个compare(Object o1, Object o2)方法
通常定义比较器时都用的comparator
4、设计模式
总体来说设计模式分为三大类:
创建型模式,共五种:工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式。
结构型模式,共七种:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式。
行为型模式,共十一种:策略模式、模板方法模式、观察者模式、迭代器模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。
设计模式的六大原则:
1、开闭原则(Open Close Principle)
开闭原则就是说对扩展开放,对修改关闭。在程序需要进行拓展的时候,不能去修改原有的代码,实现一个热插拔的效果。所以一句话概括就是:为了使程序的扩展性好,易于维护和升级。想要达到这样的效果,我们需要使用接口和抽象类。
2、里氏代换原则(Liskov Substitution Principle)
里氏代换原则(Liskov Substitution Principle LSP)面向对象设计的基本原则之一。 里氏代换原则中说,任何基类可以出现的地方,子类一定可以出现。 LSP是继承复用的基石,只有当衍生类可以替换掉基类,软件单位的功能不受到影响时,基类才能真正被复用,而衍生类也能够在基类的基础上增加新的行为。里氏代换原则是对“开-闭”原则的补充。实现“开-闭”原则的关键步骤就是抽象化。而基类与子类的继承关系就是抽象化的具体实现,所以里氏代换原则是对实现抽象化的具体步骤的规范。
3、依赖倒转原则(Dependence Inversion Principle)
这个是开闭原则的基础,具体内容:只对接口编程,依赖于抽象而不依赖于具体。
4、接口隔离原则(Interface Segregation Principle)
这个原则的意思是:使用多个隔离的接口,比使用单个接口要好。还是一个降低类之间的耦合度的意思,从这儿我们看出,其实设计模式就是一个软件的设计思想,从大型软件架构出发,为了升级和维护方便。所以上文中多次出现:降低依赖,降低耦合。
5、迪米特法则(最少知道原则)(Demeter Principle)
为什么叫最少知道原则,就是说:一个实体应当尽量少的与其他实体之间发生相互作用,使得系统功能模块相对独立。
6、合成复用原则(Composite Reuse Principle)
原则是尽量使用合成/聚合的方式,而不是使用继承。
设计原则
找出应用中可能需要变化的地方,将他们独立出来,不要和不需要变化的代码混在一起。
针对接口编程,而不是针对实现编程。
多用组合,少用继承。
一个类应该只有一个引起变化的原因
策略模式
策略模式定义了算法族,分别封装起来,让它们之间可以互相替换,此模式让算法的变化独立于使用算法的客户。
即将会经常变化或有多种实现的方法抽象成为一个接口,根据实际的子类来确定使用哪一种具体的实现。
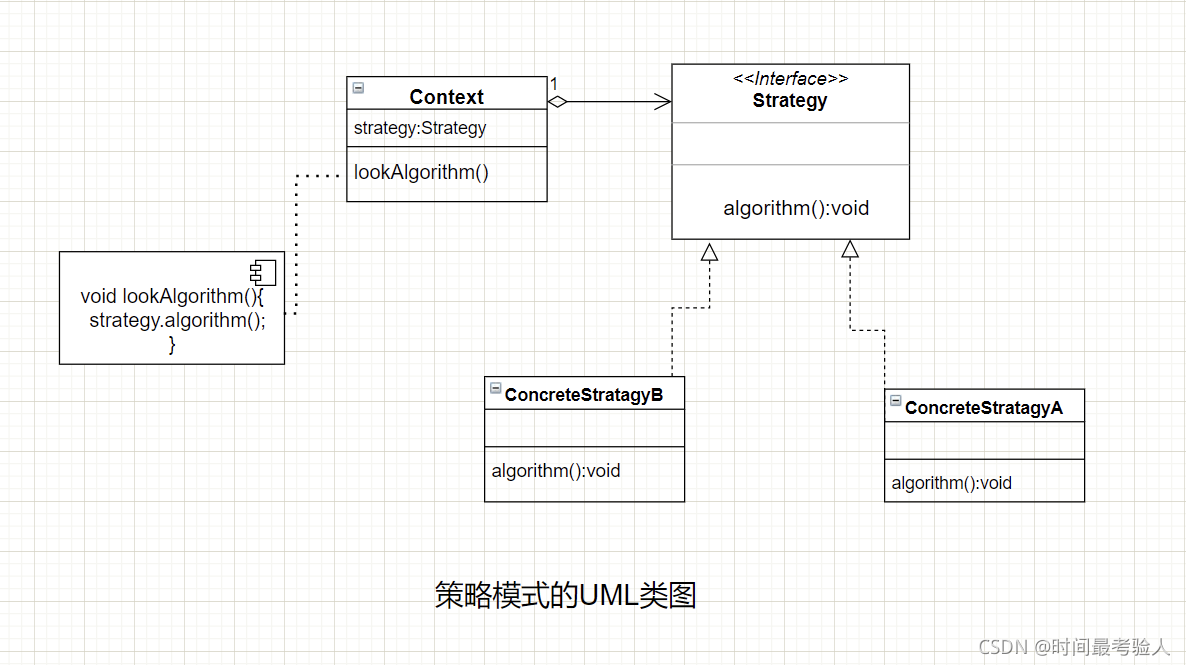
策略模式可以用来解决大量if-else的场景,将if-else部分的执行逻辑全部抽象成为一个接口,每种逻辑使用一个实现了该接口的类实现。然后在需要执行该接口处以恰当的方式调用对应逻辑的实现类的方法即可。
适配器模式
适配器模式把一个类的接口变换成客户端所期待的另一种接口,从而使原本因接口不匹配而无法在一起工作的两个类能够在一起工作。
客户类Client通过一个实现了Tatget的对象及一个Target接口调用功能类Adaptee的方法。
类适配器:
类的适配器模式把适配的类的API转换成为目标类的API。
1、适配器类(Adapter)实现Target接口;2、适配器类(Adapter)通过继承来实现对Adaptee类的重用。
客户调用Target接口的request方法,实际就是调用其父类Adaptee的specialRequest方法。
对象适配器:
适配器类实现target接口,但通过Adaptee类的实例实现重用
与类的适配器模式一样,对象的适配器模式把被适配的类的API转换成为目标类的API,与类的适配器模式不同的是,对象的适配器模式不是使用继承关系连接到Adaptee类,而是使用委派关系连接到Adaptee类。
理解:使不同的客户可以调用同一个接口
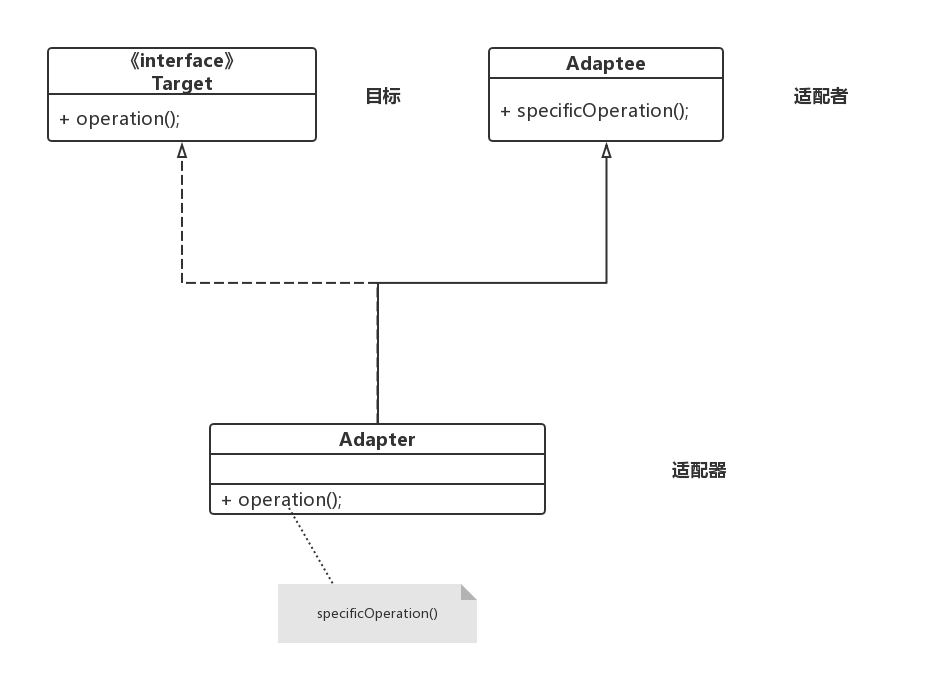
装饰器模式
装饰器模式以对客户透明的方式动态的给一个对象附加上更多的责任。换言之,客户端并不会觉得对象在装饰前和装饰后有什么不同。装饰器模式可以在不是用创造更多子类的情况下,将对象的功能加以拓展。
理解:将更多的功能挂接给原对象
迭代器模式
迭代器模式提供一种方法顺序访问一个聚合对象中的各个元素,而不暴露其内部的表示。
迭代器把访问元素交给迭代器处理,而不是聚合对象上,简化了聚合对象的接口和实现。

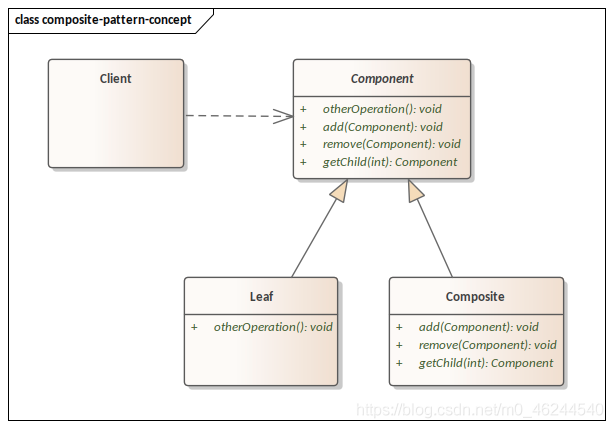
组合模式
组合模式(Composite Pattern)将对象组合成树形结构以表示“部分-整体”的层次结构。组合模式使得用户可以使用一致的方法操作单个对象和组合对象。
优点:
高层模块调用简单。组合模式中,用户不用关心到底是处理简单组件还是复合组件,可以按照统一的接口处理。不必判断组件类型,更不用为不同类型组件分开处理。
组合模式可以很容易的增加新的组件。若要增加一个简单组件或复合组件,只须找到它的父节点即可,非常容易扩展,符合“开放-关闭”原则。
缺点:
无法限制组合组件中的子组件类型。在需要检测组件类型时,不能依靠编译期的类型约束来实现,必须在运行期间动态检测。
理解:客户可以通过同一个方法对单个对象或者组合对象进行操作
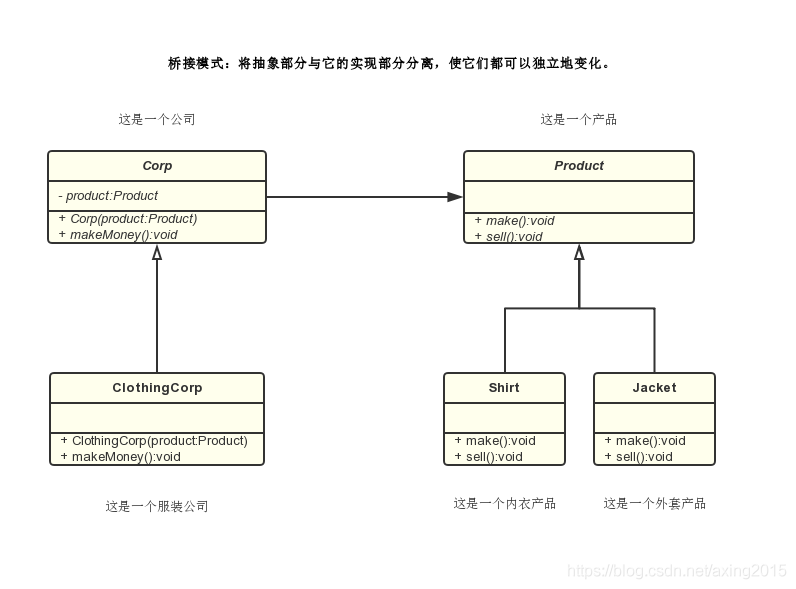
桥接模式
桥接模式(Bridge Pattern)桥接模式将定义与其实现分离,它是一种结构模式。此模式涉及充当桥接的接口。桥使得具体类与接口实现者类无关,这两种类型的类可以改变而不影响对方。
桥接模式不只改变实现,也改变抽象。
适用性:
1)你不希望在抽象和它的实现部分之间有一个固定的绑定关系。例如这种情况可能是因为,在程序运行时刻实现部分应可以被选择或者切换。
2)类的抽象以及它的实现都应该可以通过生成子类的方法加以扩充。这时Bridge模式使你可以对不同的抽象接口和实现部分进行组合,并分别对它们进行扩充。
3)对一个抽象的实现部分的修改应对客户不产生影响,即客户的代码不必重新编译。
4)你想在多个对象间共享实现(可能使用引用计数),但同时要求客户并不知道这一点。
优点:
将实现解耦,让它和界面之间不再永久绑定。
抽象和实现可以独立扩展,不会影响到对方。
具体抽象类的改变,不会影响到客户。
缺点:
增加了复杂度。
理解:
使用不同实现类实现功能不同的相同接口,并使用抽象类抽象出公共动作,而在调用方法时根据需要选择具体执行的功能。
责任链模式
责任链模式(Chain of Responsibility)是一种对象的行为模式。在责任链模式里,很多对象由每一个对象对其下家的引用而连接起来形成一条链。请求在这个链上传递,直到链上的某一个对象决定处理此请求。发出这个请求的客户端并不知道链上的哪一个对象最终处理这个请求,这使得系统可以在不影响客户端的情况下动态地重新组织和分配责任。
纯与不纯的责任链模式:
一个纯的责任链模式要求一个具体的处理者对象只能在两个行为中选择一个:一是承担责任,二是把责任推给下家。不允许出现某一个具体处理者对象在承担了一部分责任后又把责任向下传的情况。在一个纯的责任链模式里面,一个请求必须被某一个处理者对象所接收;在一个不纯的责任链模式里面,一个请求可以最终不被任何接收端对象所接收。
责任链模式的优缺点:
优点:降低了请求的发送者和接收者之间的耦合;把多个条件判定分散到各个处理类中,使得代码更加清晰,责任更加明确。通过改变链内的成员或调动他们的次序,允许动态新增或删除责任。
缺点:在找到正确的处理对象之前,所有的条件判定都要执行一遍,当责任链过长时,可能会引起性能的问题;可能导致某个请求不被处理。可能不容易观察运行时特征,碍于排查问题。

单例模式
指一个类只有一个实例,且该类能自行创建这个实例的一种模式。
实现单例模式:私有构造器+静态方法+静态变量
三个特点:
单例类只有一个实例对象;
该单例对象必须由单例类自行创建;
单例类对外提供一个访问该单例的全局访问点。
优点:
单例模式可以保证内存里只有一个实例,减少了内存的开销。
可以避免对资源的多重占用。
单例模式设置全局访问点,可以优化和共享资源的访问。
缺点:
单例模式一般没有接口,扩展困难。如果要扩展,则除了修改原来的代码,没有第二种途径,违背开闭原则。
在并发测试中,单例模式不利于代码调试。在调试过程中,如果单例中的代码没有执行完,也不能模拟生成一个新的对象。
单例模式的功能代码通常写在一个类中,如果功能设计不合理,则很容易违背单一职责原则。
多个类加载器的场景下,可能导致单例模式失效而产生多个实例。
应用场景:
需要频繁创建的一些类,使用单例可以降低系统的内存压力,减少 GC。
某类只要求生成一个对象的时候,如一个班中的班长、每个人的身份证号等。
某些类创建实例时占用资源较多,或实例化耗时较长,且经常使用。
某类需要频繁实例化,而创建的对象又频繁被销毁的时候,如多线程的线程池、网络连接池等。
频繁访问数据库或文件的对象。
对于一些控制硬件级别的操作,或者从系统上来讲应当是单一控制逻辑的操作,如果有多个实例,则系统会完全乱套。
当对象需要被共享的场合。由于单例模式只允许创建一个对象,共享该对象可以节省内存,并加快对象访问速度。如Web中的配置对象、数据库的连接池等。
多例:
可以有多个实例,构造方法私有;每个请求会生成一个新的对象来处理;避免并发问题。
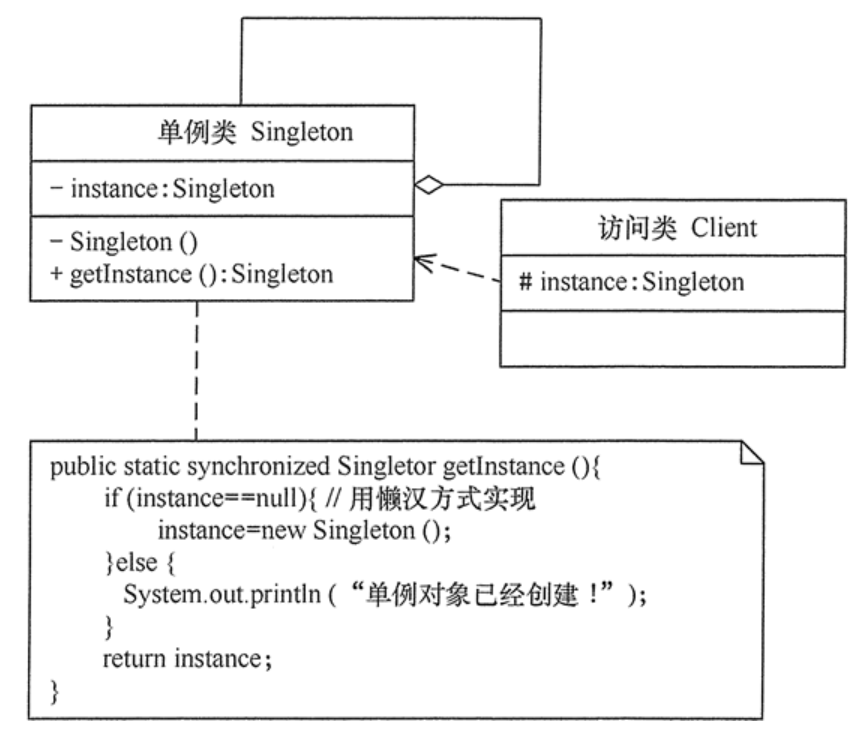
单例模式的实现方式:
懒汉:
在获取实例的时候才初始化,使用synchronized关键字加锁,保证线程安全性。优点是第一次调用时才初始化,避免内存浪费;缺点是对实例方法加锁,降低了并发效率。
饿汉:
在静态代码中直接初始化实例,使得实例在类加载阶段就完成实例化,即在初始化单例类时进入JVM,避免多线程问题。优点是不需要加锁,性能更高;缺点是类加载阶段就实例化,浪费内存。
双重锁:
使用volatile关键字保证单例对象的线程可见性,同时使用双重校验(获取实例时先判断是否存在实例,如果存在直接获取,如果不存在则使用加锁的方法进行初始化),避免了对整个方法加锁导致的性能问题。
静态内部类:
利用静态内部类在使用时才进行初始化的特性,实现了懒加载也避免了多线程问题。
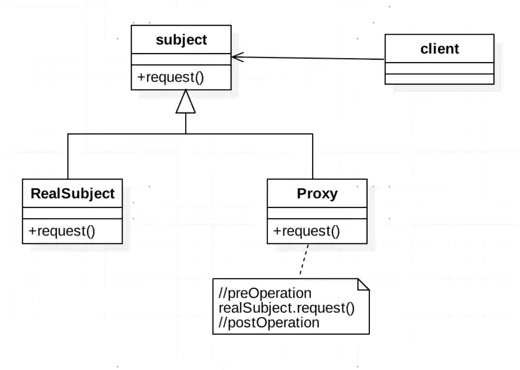
代理模式:
代理模式要做的事情是:控制和管理访问
给某一个对象提供一个代理,并由代理对象控制对原对象的引用。真实对象和代理对象实现相同的接口,在代理对象中含有真实对象的引用,因此可以直接使用代理对象操作真实对象,相当于对真实对象的封装。
结构上与装饰器模式类似,但目的不同。
RMI:远程接口调用。在服务端为服务创建interface(继承Remote)及其实现(继承UnicastRemoteObject,并编写空构造器抛出RemoteException);并将服务注册。在客户端,需要寻找对应的服务。
虚拟代理:作为创建开销大的对象代表。直到真正需要一个对象时才创建它,在这之前由虚拟对象扮演对象的替身。对象创建后,代理就会将请求直接委托给对象。
静态代理:在使用时,代理对象和被代理对象都要实现相同的接口。程序运行前代理类就已经编译完成。
动态代理:代理类在程序运行时创建的代理方式。与静态代理方式在程序编译时创建好代理不同,动态代理是在运行时创建,方便对代理类中的所有方法进行统一控制。在需要使用被代理对象时,创建代理类,并在代理类中的方法被执行前后,基于AOP原理使用InvocationHandler进行控制。
工厂模式:
所有工厂都是用来封装对象的创建。
简单工厂不算工厂模式,也称作静态工厂模式。简单工厂中进行了具体子类的实现,简单工厂的调用者只需要持有简单工厂对象即可。
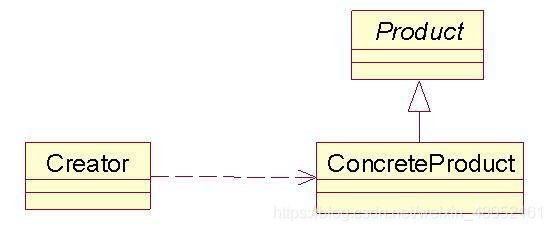
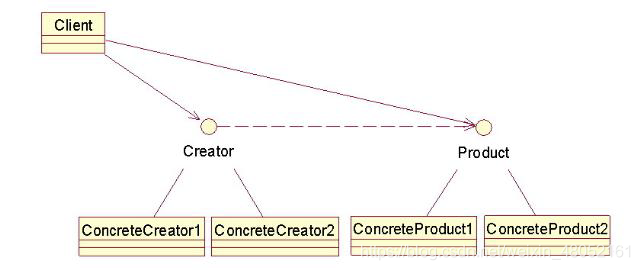
工厂方法模式定义了一个创建对象的接口,但由子类决定要实例化的类是哪一个。工厂方法让类把实例化推迟到子类。工厂方法模式使用继承,把对象的创建委托给子类,子类实现工厂方法来创建对象。
工厂方法模式封装了对象的实现,降低了客户与产品对象的耦合。
抽象工厂模式提供一个接口,用于创建相关或依赖对象的家族,而不需要明确指定具体类。抽象工厂模式使用对象组合,对象的创建被实现在工厂接口所暴露出来的方法中。
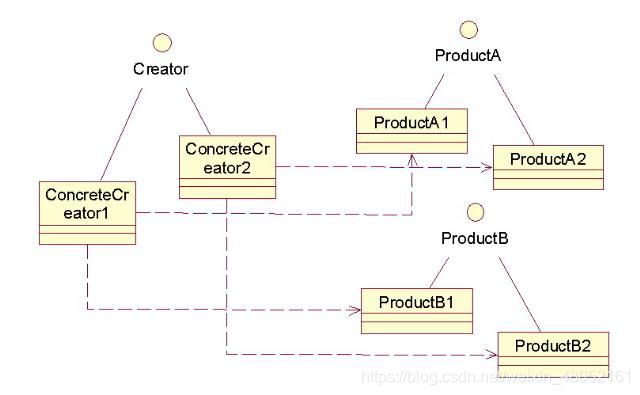
抽象工厂模式隔离了具体类的生成,使客户不需要知道什么被创建。
5、数据库的ACID特性
ACID,指数据库事务正确执行的四个基本要素的缩写。包含:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)
原子性:整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
一致性:一致性是指事务使得系统从一个一致的状态转换到另一个一致状态。事务的一致性决定了一个系统设计和实现的复杂度,也导致了事务的不同隔离级别。
隔离性:隔离状态执行事务,使它们好像是系统在给定时间内执行的唯一操作。如果有两个事务,运行在相同的时间内,执行相同的功能,事务的隔离性将确保每一事务在系统中认为只有该事务在使用系统。这种属性有时称为串行化,为了防止事务操作间的混淆,必须串行化或序列化请求,使得在同一时间仅有一个请求用于同一数据。
永久性:在事务完成以后,该事务对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。
mysql通过undolog保证原子性。记录已经执行了的sql语句,回滚时对这些语句进行回滚。
mysql通过redolog保证持久性。事务提交时,需要先写入redolog进行持久化。
mysql通过MVCC和锁保证隔离性。
一致性是基于原子性、隔离性、持久性才能保证的特性。
数据库事务隔离级别:
Read Uncommitted 读未提交:可以查询到未提交的数据。select未加锁
Read Committed 读已提交:只能查询到已提交的数据
Repeatable Read 重复读(mysql默认事务):在同一个事务执行期间,两次查询的结果一定相同
Serializable 可串行化:事务顺序执行。
脏读、不可重复读、幻读:
脏读: 没有提交的事务被其他事务读取到了,这叫做脏读 。可出现在RU级别。
不可重复读:一个事务范围内多次相同查询返回的数据值发生了变化,即当前事务范围内读取了另一个事务提交之后的修改。不可重复读是因为其他事务进行了 UPDATE、delete 操作。可出现在RC级别。某些情况下也不影响数据正确性,可能多次读取时以最后一次查询为主。锁行可以解决。
幻读:幻读是指一个事务两次查询的结果数量不一致,因为其他事务进行了 INSERT 操作。可出现在RR级别。解决幻读的方式是在查询时锁住条件区间内的行。
6、垃圾回收(GC)
垃圾回收的时机:
GC的触发包括两种情况
- 程序调用System.gc()的时候
- 系统自身决定是否需要GC
系统进行GC的依据:
1.eden区满会触发 Minor GC。
2.FULL GC的触发条件:
(1)调用System.gc()时,系统建议执行Full GC,但是不必然执行。
(2)老年代内存不足的时候。
(3)方法区内存不足的时候。
确定垃圾的方法:
(1)引用计数法:若一个对象没有任何与之相关联的引用,则为可回收对象。对象只要被引用,则计数+1,引用结束则计数-1。但可能由于循环引用导致无法回收。
(2)可达性分析:通过GCroots(虚拟机栈引用的对象-即正在活动的对象、本地方法栈引用的对象、方法区中类静态属性引用的对象、方法区中常量引用的对象、synchronized持有的对象、系统类的引用对象)作为起点搜索,若对象至少两次没有可达路径,则为可回收对象。
safePoint:在GC触发时,线程执行到检查点检查是否需要中断全部线程。
safePoint一般出现在循环末尾、方法临返回前\调用方法的call指令后、可能抛出异常的位置。
为GC生成的符号信息是OopMap,指出栈上和寄存器哪里有GC管理的指针。
GC算法:
标记-清除算法:最基础的垃圾回收算法,分为标记和清除两个阶段。最大问题是内存碎片化,后续可能发生大对象找不到可用空间的情况。
复制算法:为了解决标记清除算法的内存碎片化问题,将内存平分为两块,每次只用一块,在这一块内存满的时候将存活的对象复制到另一块上,并清除前一块内存。内存效率高,不易产生碎片,但可用内存减为一半,且存活对象多的时候效率会大大降低。
标记-整理算法:标记需要回收的对象后,将存活对象向内存的一端移动,可以避免内存利用率低或产生内存碎片的问题。
分代收集算法:根据年轻代和老年代的垃圾回收频率等特性,可以选择不同的垃圾回收算法。
- 新生代使用的是复制算法,Eden区和survivalFrom、survivalTo区按8:1:1划分。
- 而老年代使用的是标记-整理算法,因为每次回收的对象很少。
分区收集算法:
- 将整个堆空间划分为多个连续的小区间,每个区间单独使用,独立回收,这样可以控制一次回收多个小区间,每次合理的回收若干个小区间而不是整个堆。
进入老年代的条件:
1、在SurvivalTo区没有足够的空间存储某个对象时,会直接进入老年代;
2、大对象直接进入老年代(超过了JVM中-XX:PretenureSizeThreshold参数的设置)
3、幸存者区中有相同年龄的对象所占空间超过一半,则超过该年龄的对象会直接进入老年代
4、其他正常情况下,活过15次GC的对象会进入老年代。
垃圾回收器:
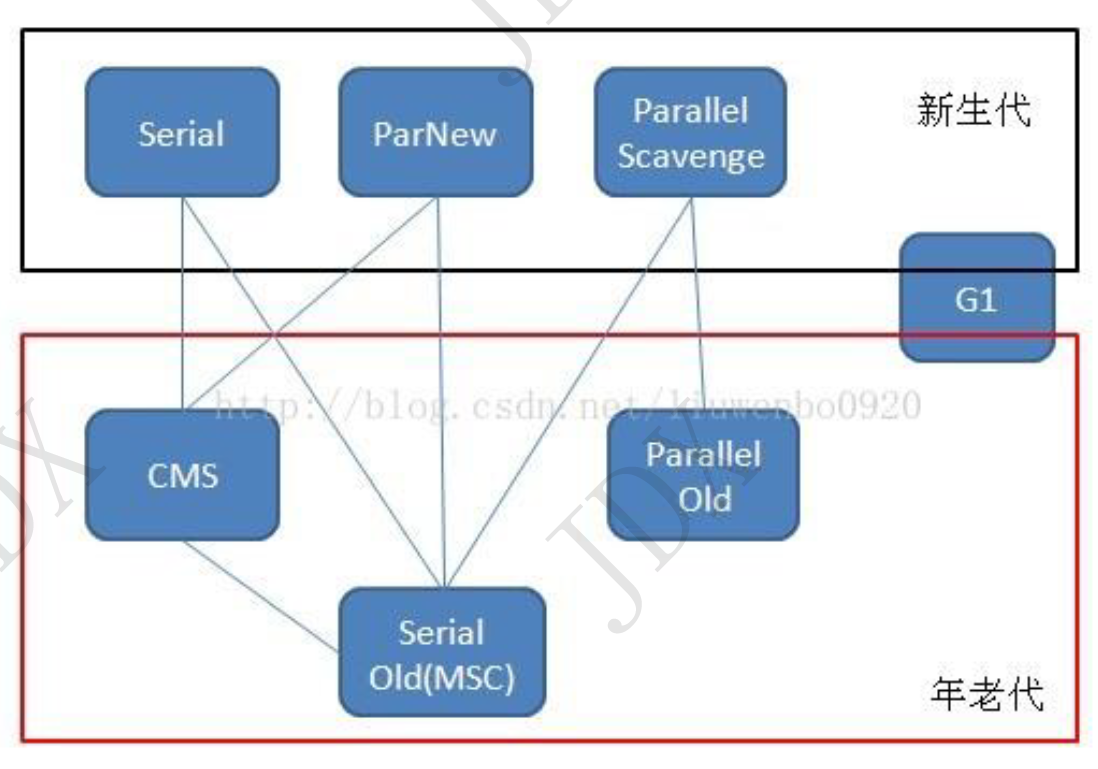
- Serial垃圾收集器(单线程+复制算法)
- ParNew垃圾收集器(和Serial一致,多线程+复制算法)
- ParallelScavenge垃圾收集器(多线程+复制算法+高效,根据吞吐量(代码执行时间/代码执行时间+GC时间)来控制GC时间,避免不满足要求的停顿时间)
- SerialOld垃圾收集器(单线程+标记整理算法)
- ParallelOld垃圾收集器(ParallelScavenge的老年代版:多线程+标记整理算法)
- CMS(Concurrent mark sweep)垃圾收集器(多线程+标记清除算法)可以获取最短的垃圾回收停顿时间:初始标记(标记GCRoots能直接关联的对象,STW)->并发标记(跟踪GCRoots)->重新标记(修正并发标记期间变化的对象,STW)->并发清除(清除对象)。CMS使用标记清除算法,由于是在老年代操作,并不会有大量高频的GC,只是为了获取高速GC;如果内存碎片多到无法整理,会退回使用SerialOld算法进行GC
- G1(Garbage first)垃圾收集器(多线程+标记整理算法+分区垃圾收集,优先收集垃圾最多的区域),新生代老年代都可以使用。可以预测的STW时间。初始标记(STW,单线程但速度很快)->并发标记->最终标记(STW,多线程修正对象标记)->筛选回收(STW,多线程,对每个分区的回收成本进行排序,按照用户自定义的回收时间优先收集垃圾最多的区域)。适用场景:超过一半以上的堆被存活对象占用;8G以上堆内存;垃圾回收时间超过1s。
7、JVM
JVM虚拟机是在安装在操作系统之上的。

内存模型
公有:方法区(存放类对象信息、静态变量、常量)、堆(存放对象和数组);私有:程序计数器(当前方法执行的字节码行号指示器)、虚拟机栈(存放方法运行信息)、本地方法栈(和虚拟机栈类似,针对native方法)。
方法区
方法区是规范,永久代、元空间是方法区的具体实现。
永久代和元空间是否同时存在?否
永久代在JdK1.8之前存在于堆区,可能产生OOM,触发GC
元空间是JDK1.8之后存在于本地内存(直接内存、操作系统内存、native memory)中,元空间大小由系统的实际可用空间决定(默认最小20.75M、最大256T),由操作系统回收,减轻GC系统负担,不再有OOM错误,但仍需要注意内存泄漏的问题。
方法区存放静态变量、类信息、常量、运行时常量池。
常量池:class文件常量池、运行时常量池、全局常量池
JDK1.8后,元空间取代了永久代。64位机器最大内存为,即256T。字符串从永久带移到堆区。在之前的版本中,字符串常量池存在于永久代中,在大量使用字符串的情况下,非常容易出现OOM的异常。此外,JVM加载的class的总数,方法的大小等都很难确定,因此对永久代大小的指定难以确定。太小的永久代容易导致永久代内存溢出,太大的永久代则容易导致虚拟机内存紧张。
元空间调优:1、最小最大设置为一样,防止内存抖动(内存频繁地分配和回收);2、设置为物理内存的1/32;3、预留20%-30%的空闲空间
程序计数器(线程私有)
是字节码行号指示器,字节码解释器通过改变该计数器确定接下来执行哪个指令。
栈
先进后出,后进先出。相比而言,队列是先进先出。
栈主管程序的运行,生命周期和线程同步。线程结束,栈内存释放。不存在垃圾回收问题。
存放八大基本类型+对象引用+实例方法。
程序正在执行的方法,一定在栈顶。
如果栈满了就会抛出栈溢出错误。
虚拟机栈:存储线程运行信息(包括局部变量表,操作数栈、动态连接、返回地址)
动态连接:存放的是这个方法在方法区的内存地址(连接了虚拟机栈和方法区)
返回地址(恢复现场):使方法能够继续执行而不是重新执行
局部变量表:一组变量值存储空间,用于存放方法参数和方法内部定义的局部变量。每个非静态方法,局部变量表index[0]位置永远存放this
操作数栈:虚拟机把操作数栈作为它的工作区,大多数指令都要从这里弹出数据,执行运算,然后把结果压回操作数栈
当一个方法刚刚开始执行时,其操作数栈是空的,随着方法执行和字节码指令的执行,会从局部变量表或对象实例的字段中复制常量或变量写入到操作数栈,再随着计算的进行将栈中元素出栈到局部变量表或者返回给方法调用者,也就是出栈/入栈操作。一个完整的方法执行期间往往包含多个这样出栈/入栈的过程。
一个方法执行完JVM需要做的事情:1、恢复局部表指针;2、恢复操作栈指针;3、恢复程序计数器;4、如果方法有返回地址,需要返回;5、清理栈帧
堆
一个JVM只有一个堆,大小可以调节。放置类、方法、常量、变量,保存引用类型的真实对象。
所有线程共享,主要存放对象实例和数组。新生代:老年代 = 1:2。默认大小最小物理内存的1/64,最大1/4。(JVM默认分配内存是物理内存的1/4, 初始化大小为1/64)
klass pointer是对象指向所属类的class对象内存地址的指针,连接了堆和方法区。
而静态变量作为类对象的一个属性从方法区指向堆。
新生代:是类诞生、成长、消亡的区域
伊甸区:对象产生的区域 8
幸存区(0, 1) 1:1
老年代:活过多次minor GC的对象会进入老年代
永久代:常驻内存中,存放JDK自带class对象,interface元数据,存储JAVA运行时环境,不存在垃圾回收,关闭JVM时释放。
1.6:存在永久代,常量池在方法区中
1.7:存在永久代,常量池在堆中
1.8:变为元空间,使用本地内存
对象的内存布局:
对象头区域:
mark word,8字节,存储锁信息,也可以用来配合GC、存放该对象的hashCode;
类型指针(klass pointer):对象指向class对象的指针,开启指针压缩4字节,未开启8字节;
数组长度:数组对象的长度,4字节。对象头区域也存在对齐填充区域。
实例数据区域:数据实例对象的属性。
对齐填充区域:数据需要能够被8字节整除,该区域则是被补充的空间。
计算对象大小:
空对象:没有实例数据的对象。
指针压缩:存储时抹除后三位0;使用时后三位补0。
JVM内存调优的目的:
防止出现OOM、解决OOM、减少full GC的频率
合理分配内存大小,避免eden区对象频繁进入老年代;
避免动态年龄判定:增大内存,使young GC存活对象大小不超过幸存区的50%;改变新生代内存分配,提高幸存区大小
上线前进行预估,配置内存;线上找到压力点,推算并发量,计算单次业务内存使用(或使用工具监测),计算单次业务耗时,从而推算无法回收的内存大小,调整内存。
OOM:1.尝试扩大堆内存
2.分析内存,定位问题
// -Xms1024m -Xmx1024m -XX:+PrintGCDetails 指定JVM内存大小,输出GC日志
引用
强引用:类似 Object object = new Object()。只要强引用还存在,永远不会被GC回收。
软引用:用来描述一些还有用但是并非必须的对象。在要发生内存溢出之前,系统会把这些对象列进回收范围中进行回收,若仍内存不足,则抛出内存溢出异常。
弱引用:比软引用更弱的非必须对象。对象只能生存到下一次GC发生之前,不论内存是否足够。
虚引用:完全不会影响生存时间,也无法通过虚引用获取对象实例。仅在被回收时收到一个系统通知。用于跟踪对象被垃圾回收。
JVM常用命令
查看存活对象:
可以使用Jmap进行查看。使用jmap -heap [pid]就能输出相应进程的新生代和老年代的情况。
输出的主要信息:
* 堆的最小容量,最大容量
* eden区与survivor区的比值
* eden区的容量,使用的大小,未使用的区域的大小,使用的区域的比例
* 两个survivor区的容量,使用的大小,未使用的区域的大小,使用的区域的比例
* 老年代的容量,使用的大小,未使用的区域的大小,使用的区域的比例
查看对象信息可以使用jmap -histo(:live) pid 其中添加:live参数时用以仅查看存活对象
查看堆状态:
jstat -gcutil 451929 1000 10 // 监控进程451929的堆内存,每秒一次,共十次
监控内存溢出问题:启动时添加 -XX:+HeapDumpOnOutOfMemoryError,可以在出现内存溢出时输出dump文件,可以使用JProfie等工具分析。
GC健康问题:查找到Java进程,在通过jmap查看堆的情况,根据堆中各个区域使用情况判断问题。进一步可以使用GCUtil分析GC状况,进一步定位问题。
定位CPU使用率高
首先使用top命令查看cpu使用率高的进程
然后使用top -Hp Pid命令查看对应进程中的cpu线程使用率
最后使用printf "%x\n" [线程id] (转换线程id为十六进制)
jstack PID | grep -A 10 [十六进制线程id]命令最终可以定位到对应代码
CPU使用率高的可能情况:
1.程序计算比较密集
2.程序死循环
3.程序逻请求堵塞
4.系统频繁YoungGC
native关键字
凡是带native关键字的方法,说明java的作用范围无法达到,会调用底层C语言的方法库。会进入本地方法栈,调用本地方法接口(JNI),扩展JAVA的使用,融合不同的变成语言为JAVA所用(JAVA初期需要在C++和C语言的大环境下开创)。在内存区域中专门开辟了一块标记区域,即本地方法栈,登记native方法,在最终执行时通过JNI调用本地方法。
类加载机制
class文件:就是类编译成的class文件
class content:内存中放置类文件的区域
class对象:将class content解析成class对象(class的元数据),放到方法区中
对象:实际使用的对象,存放在堆区
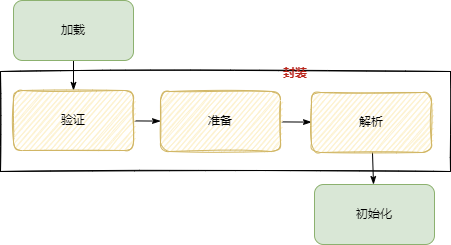
JVM类加载机制分为五个部分:加载,验证,准备,解析,初始化。
- 加载:这个阶段会在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的入口。(在方法区而不在堆中)
- 连接:
- 验证:确保Class文件的字节流中包含的信息是否符合当前虚拟机的要求。
- 准备:在方法区中分配静态变量静态常量所使用的内存空间。静态变量只会赋默认值,静态常量才会直接赋值。
- 解析:虚拟机将常量池中的符号引用替换为直接引用的过程。(符号引用:引用的目标并不一定要已经加载到内存中;直接引用:是指向目标的指针,相对偏移量或是一个能间接定位到目标的句柄,引用的目标一定在内存中存在。)
- 初始化:除了在加载阶段可以自定义类加载器以外,其它操作都由JVM主导。初始化阶段是执行类构造器方法的过程,方法是由编译器收集的类的静态变量赋值操作和静态语句块合成而成,父类方法执行完成后才会执行子类方法,如果类中没有静态变量及静态语句块,则不会生成方法。
类加载器:
- 虚拟机自带加载器:
- 启动类加载器:负责加载 JAVA_HOME\lib 目录中的,或通过-Xbootclasspath参数指定路径中的,且被虚拟机认可(按文件名识别,如rt.jar)的类。
- 扩展类加载器:负责加载 JAVA_HOME\lib\ext 目录中的,或通过java.ext.dirs系统变量指定路径中的类库。
- 应用程序类加载器:负责加载用户路径(classpath)上的类库。
双亲委派机制描述
某个特定的类加载器在接到加载类的请求时,首先将加载任务委托给父类加载器,依次递归,如果父类加载器可以完成类加载任务,就成功返回;只有父类加载器无法完成此加载任务时,才自己去加载。
类加载器过程
类加载器收到类加载请求 -> 将这个请求向上委托给父加载器,一直向上,直至启动类加载器 -> 加载器如果可以加载,则直接进行加载,如果不能,则通知子加载器加载,逐级向下
如果都没有可以使用的加载器,则会报错,class not found
委托机制的意义:防止内存中出现多份同样的字节码
比如两个类A和类B都要加载System类,如果不用委托而是自己加载自己的,那么类A就会加载一份System字节码,然后类B又会加载一份System字节码,这样内存中就出现了两份System字节码。
如果使用委托机制,会递归的向父类查找,也就是首选用Bootstrap尝试加载,如果找不到再向下。这里的System就能在Bootstrap中找到然后加载,如果此时类B也要加载System,也从Bootstrap开始,此时Bootstrap发现已经加载过了System那么直接返回内存中的System即可而不需要重新加载,这样内存中就只有一份System的字节码了。
双亲委派可以保证不会加载用户自定义的和Java环境中的同包同名类,提高了安全性。
为什么要破坏双亲委派:
因为某些情况下需要父类加载器委托子类加载器去加载class文件。受到加载范围的限制,父加载器无法加载到需要的文件。如MysqlConnector,jdk中仅有定义,具体方法实现在各数据库提供方中,因此需要破坏双亲委派使用指定类加载器。可以直接改写ClassLoader中的loadClass方法,在父加载器及顶层加载器无法加载时使用自定义的类加载器处理。
8、渐进式rehash(hashmap的扩容)
在redis的具体实现中,使用了一种叫做渐进式哈希(rehashing)的机制来提高字典的缩放效率,避免 rehash 对服务器性能造成影响,渐进式 rehash 的好处在于它采取分而治之的方式, 将 rehash 键值对所需的计算工作均摊到对字典的每个添加、删除、查找和更新操作上, 从而避免了集中式 rehash 而带来的庞大计算量。
rehash的核心思想是将扩容的过程变成一个可以持续进行并不会中断hashmap功能的操作,即将其分散到各个普通的操作中。
在redis中,扩展或收缩哈希表需要将 ht[0] 里面的所有键值对 rehash 到 ht1 里面, 但是, 这个 rehash 动作并不是一次性、集中式地完成的, 而是分多次、渐进式地完成的。以下是哈希表渐进式 rehash 的详细步骤:
(1)为 ht1 分配空间, 让字典同时持有 ht[0] 和 ht1 两个哈希表。
(2)在字典中维持一个索引计数器变量 rehashidx , 并将它的值设置为 0 , 表示 rehash 工作正式开始。
(3)在 rehash 进行期间, 查找、更新、删除操作会同时在两个字典中进行操作,但是新增只会在ht1中操作。每次操作会顺带将 ht[0] 哈希表在 rehashidx 索引上的所有键值对 rehash 到 ht1 , 当 rehash 工作完成之后, 程序将 rehashidx 属性的值增一。
(4)随着字典操作的不断执行, 最终在某个时间点上, ht[0] 的所有键值对都会被 rehash 至 ht1 , 这时程序将 rehashidx 属性的值设为 -1 , 表示 rehash 操作已完成。
渐进式 rehash 的好处在于它采取分而治之的方式, 将 rehash 键值对所需的计算工作均滩到对字典的每个添加、删除、查找和更新操作上, 从而避免了集中式 rehash 而带来的庞大计算量。
9、网络知识
9.1 OSI(Open System Interconnect),即开放式系统互联,是ISO(国际标准化组织)组织在1985年研究的网络互连模型。其一共有7层:
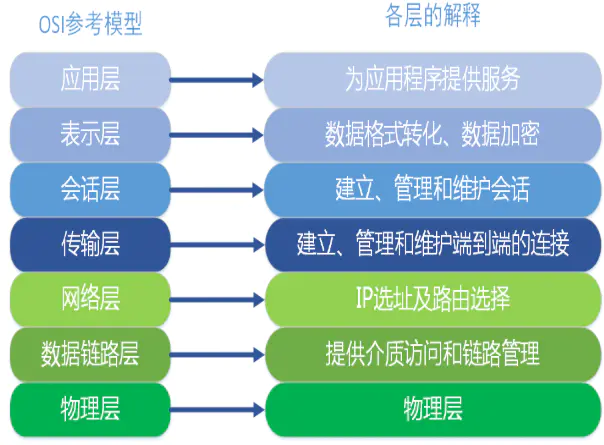
- 应用层(数据):确定进程之间通信的性质以满足用户需要以及提供网络与用户应用
- 表示层(数据):主要解决用户信息的语法表示问题,如加密解密
- 会话层(数据):提供包括访问验证和会话管理在内的建立和维护应用之间通信的机制,如服务器验证用户登录便是由会话层完成的
- 传输层(段):实现网络不同主机上用户进程之间的数据通信,可靠与不可靠的传输,传输层的错误检测,流量控制等
- 网络层(包):提供逻辑地址(IP)、选路,数据从源端到目的端的传输
- 数据链路层(帧):将上层数据封装成帧,用MAC地址访问媒介,错误检测与修正
- 物理层(比特流):设备之间比特流的传输,物理接口,电气特性等
9.2 TCP/IP分层模型(TCP/IP Layening Model)被称作因特网分层模型(Internet Layering Model)、因特网参考模型(Internet Reference Model)。
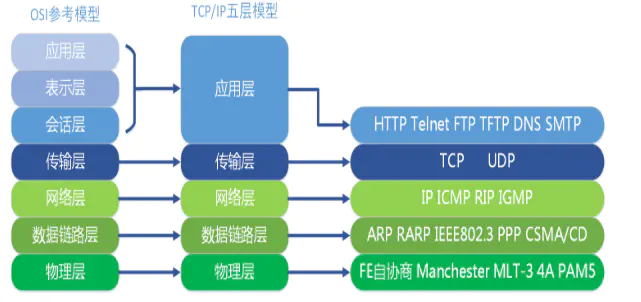
- 应用层(TELNET、FTP、SMTP)
- 传输层(TCP、UDP)
- 网际层(IP、ICMP)
- 网络接口层(PPP)
9.3 http和https
http是一种用于分布式、协作式和超媒体信息系统的应用层协议。简单来说就是一种发布和接收HTML页面的方法,被用于在web浏览器和网站服务器之间传递信息。默认工作TCP的80端口。以明文发送内容,不提供内容加密,不适合传输敏感信息。
而https是一种透过计算机网络进行安全通信的传输协议,基于http但是使用ssl/tls进行数据加密,主要为了提供对网站服务器的身份认证、保护数据的隐私与完整性。默认工作TCP的443端口。
https工作流程:
1、TCP三次握手
2、客户端验证服务器数字证书
3、DH算法协商对称加密算法的秘钥、hash算法的秘钥
4、ssl安全加密隧道协商完成
5、加密方式传输,对称算法保证隐秘性、hash算法保证数据完整性
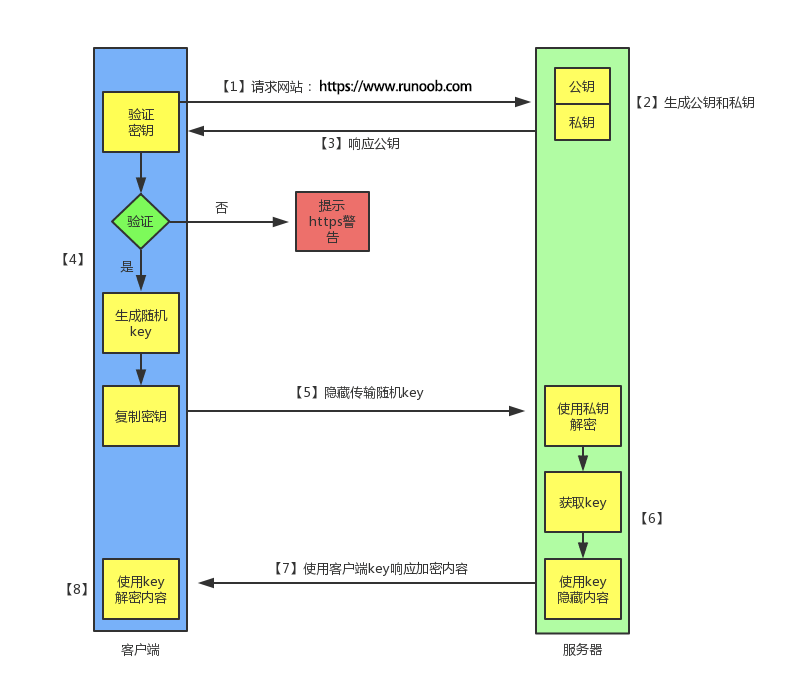
非对称加密算法:
发送方使用接收方的公钥进行加密,加密完成后接收方使用私钥进行解密。
密文=明文^E mod N
明文=密文^D mod N
E是公钥,D是私钥
9.4 TCP三次握手和四次挥手
握手是建立连接。
第一次握手:客户端向服务端发送syn包,客户端进入SYN_SEND状态
第二次握手:服务端接收了客户端syn包并确认,向客户端发送一个syn+ack包,服务端进入SYN_RECV状态
第三次握手:客户端接收了服务端发送的syn+ack包,并向服务端发送ack包确认,此时发送完毕,双方进入ESTABLISHED状态,完成握手。

挥手是关闭连接。
第一次挥手:客户端打算关闭连接,会发送FIN报文给服务端,客户端进入FIN_WAIT1状态。
第二次挥手:服务端收到报文后,向客户端发送ACK应答报文,服务端进入CLOSED_WAIT状态。
第三次挥手:客户端接收到ack报文后,进入FIN_WAIT_2状态,等待服务端处理完数据后也会向客户端发送FIN报文,之后服务端进入LAST_ACK状态。
第四次挥手:客户端收到服务端的FIN报文后,回一个ACK应答报文,之后进入TIME_WAIT状态。服务器收到ACK报文后,进入CLOSED状态。客户端在经过2MSL(指两个报文的传递时间,如果客户端发送ACK报文后,服务端没收到,服务端会再次发送FIN报文,这里需要2MSL的时间,保证没有在传输中的数据,也防止服务端没有收到客户端的ACK报文,避免仅有客户端关闭的情况)时间后,自动进入CLOSED状态。

9.5 session和cookie以及token和storage
cookie是保存在浏览器中的小型文本数据文件。对浏览器发送的请求,服务端会设置cookie返回给浏览器,下次浏览器请求就会附上这个cookie。cookie是有有效期的,到期后浏览器会删除。cookie是对应域名的,访问对应域名会把cookie放在请求头中。cookie可以直接在浏览器中查看,因此敏感数据不适合放在cookie中。
session是保存在服务器上的一个类map文件,key是sessionId,value是对应的数据。一个session的开始是浏览器发起请求,然后服务端收到请求并生成对应的sessionId存储、返回给浏览器存储到cookie中,下次浏览器带着这个sessionId就可以请求到存储在服务器中的对应session的数据。
storage包括localStorage和sessionStorage:都是保存在浏览器中的数据。local是永久储存;session只针对当前session,关闭页面或浏览器后被清除。
token是由后端生成返回给前端的,前端拿到token之后可以使用token认证。
9.6 TCP和UDP
1、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接
2、TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付
3、TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的
4、UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)
5、每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
6、TCP首部开销20字节;UDP的首部开销小,只有8个字节
TCP拥塞控制
是为了防止过多的数据出现在网络中导致路由器或者链路出现过载。
发送方维护一个拥塞窗口,先进性慢开始算法,逐步增加窗口大小,直到达到慢开始门限,然后使用拥塞避免算法。直到出现超时,重新将窗口调整为一个字节,将慢开始门限调整为超时点的一般,达到门限后继续使用拥塞避免算法。
10、Java面向对象特点
封装:封装是面向对象的特征之一,是对象和类概念的主要特性。就是把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。
继承:面向对象编程 (OOP) 语言的一个主要功能就是“继承”。继承是指:它可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展。继承的过程,就是从一般到特殊的过程。
要实现继承,可以通过“继承”(Inheritance)和“组合”(Composition)来实现。
一般情况下,一个子类只能有一个基类,要实现多重继承,可以通过多级继承来实现。
通过类继承和接口实现实现继承。
在考虑使用继承时,有一点需要注意,那就是两个类之间的关系应该是“属于”关系。例如,Employee 是一个人,Manager也是一个人,因此这两个类都可以继承 Person 类。但是 Leg 类却不能继承 Person 类,因为腿并不是一个人。
抽象类仅定义将由子类创建的一般属性和方法,创建抽象类时,请使用关键字 Interface 而不是 Class。
OO开发范式大致为:划分对象→抽象类→将类组织成为层次化结构(继承和合成) →用类与实例进行设计和实现几个阶段。
多态:多态性(polymorphisn)是允许你将父对象设置成为和一个或更多的他的子对象相等的技术,赋值之后,父对象就可以根据当前赋值给它的子对象的特性以不同的方式运作。简单的说,就是一句话:允许将子类类型的指针赋值给父类类型的指针。
实现多态,有二种方式,覆盖,重载。
覆盖,是指子类重新定义父类的虚函数的做法。
重载,是指允许存在多个同名函数,而这些函数的参数表不同(或许参数个数不同,或许参数类型不同,或许两者都不同)。
其实,重载的概念并不属于“面向对象编程”,重载的实现是:编译器根据函数不同的参数表,对同名函数的名称做修饰,然后这些同名函数就成了不同的函数(至少对于编译器来说是这样的)。如,有两个同名函数:function func(p:integer):integer;和function func(p:string):integer;。那么编译器做过修饰后的函数名称可能是这样的:int_func、str_func。对于这两个函数的调用,在编译器间就已经确定了,是静态的(记住:是静态)。也就是说,它们的地址在编译期就绑定了(早绑定),因此,重载和多态无关!真正和多态相关的是“覆盖”。当子类重新定义了父类的虚函数后,父类指针根据赋给它的不同的子类指针,动态(记住:是动态!)的调用属于子类的该函数,这样的函数调用在编译期间是无法确定的(调用的子类的虚函数的地址无法给出)。因此,这样的函数地址是在运行期绑定的(晚邦定)。结论就是:重载是静态多态。
11、线程与进程
线程具有许多传统进程所具有的特征,故又称为轻型进程(Light—Weight-Process)或进程元;而把传统的进程称为重型进程(Heavy-Weight-Process),它相当于只有一个线程的任务。在引入了线程的操作系统中,通常一个进程都有若干个线程,至少包含一个线程。
根本区别:进程是操作系统资源分配的基本单位,而线程是处理器任务调度和执行的基本单位
资源开销:每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小。
包含关系:如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线(线程)共同完成的;线程是进程的一部分,所以线程也被称为轻权进程或者轻量级进程。
内存分配:同一进程的线程共享本进程的地址空间和资源,而进程之间的地址空间和资源是相互独立的
影响关系:一个进程崩溃后,在保护模式下不会对其他进程产生影响,但是一个线程崩溃整个进程都死掉。所以多进程要比多线程健壮。
执行过程:每个独立的进程有程序运行的入口、顺序执行序列和程序出口。但是线程不能独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制,两者均可并发执行
线程数并不是越多越好:
对于计算密集型任务,线程数最好控制在cpu核心数,避免频繁线程切换上下文切换。
对于IO密集型任务,线程数控制在能够同时进行IO任务的数量最好。
TOMCAT
tomcat connector常用参数:
acceptCount:accept队列长度,当accept队列中的连接个数到达acceptCount时,队列已满,进来的请求被拒绝。
maxConnections:tomcat在任意时刻接收和处理的最大连接数。当Tomcat接收的连接数达到maxConnections时,Acceptor线程不会读取accept队列中的连接;这时accept队列中的线程会一直阻塞着,直到Tomcat接收的连接数小于maxConnections。如果设置为-1,则连接数不受限制。
maxThreads:请求处理的最大线程数。通常设置比CPU数大得多的值。
connectionTimeout:连接超时时间,根据请求处理时间设置。
12、抽象类和接口
区别:
抽象类中可以没有抽象方法;接口中的方法必须是抽象方法。
抽象类中可以有普通的成员变量;接口中只有常量,没有变量
抽象类只能单继承,接口可以继承多个父接口。
选择:
如果要创建不带任何方法定义和成员变量的基类,那么就应该选择接口而不是抽象类。
如果知道某个类应该是基类,那么第一个选择的应该是让它成为一个接口,只有在必须要有方法定义和成员变量的时候,才应该选择抽象类。因为抽象类中允许存在一个或多个被具体实现的方法,只要方法没有被全部实现,该类就仍是抽象类。
接口只能是public的。
13、java是值传递还是引用传递
Java其实是值传递,不论是基本类型还是引用类型,传递的都只是变量的值的拷贝。若参数是个对象,则传递的是这个对象的引用的拷贝,是指向真正的对象的,因此在此时修改会真正修改到对象的属性。
14、mysql索引
覆盖索引
聚集索引(主键索引)和辅助索引(二级索引):
聚集索引(主键索引): 聚集索引就是按照每张表的主键构造一颗B+树,同时叶子节点中存放的即为整张表的数据。 聚集索引的叶子节点称为数据页,聚集索引的这个特性决定了索引组织表中的数据也是索引的一部分。 辅助索引(二级索引): 非主键索引,叶子节点=键值+书签。Innodb存储引擎的书签就是相应行数据的主键索引值。
覆盖索引,有下面三种理解:
解释一: 就是select的数据列只用从索引中就能够取得,不必从数据表中读取,换句话说查询列要被所使用的索引覆盖。
解释二: 索引是高效找到行的一个方法,当能通过检索索引就可以读取想要的数据,那就不需要再到数据表中读取行了。如果一个索引包含了(或覆盖了)满足查询语句中字段与条件的数据就叫做覆盖索引。
解释三:是非聚集组合索引的一种形式,它包括在查询里的Select、Join和Where子句用到的所有列(即建立索引的字段正好是覆盖查询语句[select子句]与查询条件[Where子句]中所涉及的字段,也即,索引包含了查询正在查找的所有数据)。
不是所有类型的索引都可以成为覆盖索引。覆盖索引必须要存储索引的列,而哈希索引、空间索引和全文索引等都不存储索引列的值,所以MySQL只能使用B-Tree索引做覆盖索引
当发起一个被索引覆盖的查询(也叫作索引覆盖查询)时,在EXPLAIN的Extra列可以看到“Using index”的信息
索引下推
不使用索引下推优化的查询是通过第一个索引查询出所有数据后,再在查询到的行数据中根据其他条件筛选出满足条件的数据。
而使用了索引下推优化的查询,会在第一个索引查询出数据后,根据该数据的其他索引判断数据是否符合要求(推测是使用索引对应的主键id,再根据id找到对应的其他索引数据),满足要求才会读取整行数据,减少IO次数。
适用于需要整表扫描的情况,且只能作用于二级索引。
changeBuffer
在Mysql中对数据的写操作使用了change buffer优化,减少磁盘的写次数。
对普通索引(唯一索引写入时需要判断是否违反唯一性,需要读取数据才能判断)进行写操作的情况下,先将记录变更到change buffer中,之后再对数据读取时,可以直接用change buffer中获取。
触发merge的情况有:
访问该数据页、定期merge、数据库缓冲池不够用、数据库正常关闭、redo log写满时。
b-Tree
是一种多路搜索树(并不是二叉的):
1.定义任意非叶子结点最多只有M个儿子;且M>2;
2.根结点的儿子数为[2, M];
3.除根结点以外的非叶子结点的儿子数为[M/2, M];
4.每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
5.非叶子结点的关键字个数=指向儿子的指针个数-1;
6.非叶子结点的关键字:K1, K2, …, K[M-1];且K[i] < K[i+1];
7.非叶子结点的指针:P1, P2, …,P[M];其中P1指向关键字小于K1的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
8.所有叶子结点位于同一层;
9.每个k对应一个data。
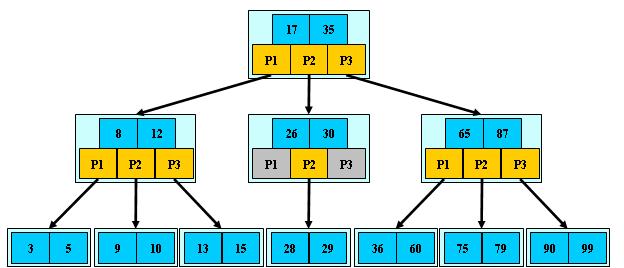
B-树的特性:
1.关键字集合分布在整颗树中;
2.任何一个关键字出现且只出现在一个结点中;
3.搜索有可能在非叶子结点结束;
4.其搜索性能等价于在关键字全集内做一次二分查找;
5.自动层次控制;
B+Tree
B-Tree有许多变种,其中最常见的是B+Tree,例如MySQL就普遍使用B+Tree实现其索引结构。
与B-Tree相比,B+Tree有以下不同点:
1.非叶子结点的子树指针与关键字个数相同;
2.非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间);
3.为所有叶子结点增加一个链指针;
4.所有关键字都在叶子结点出现;
5.内节点不存储data,只存储key
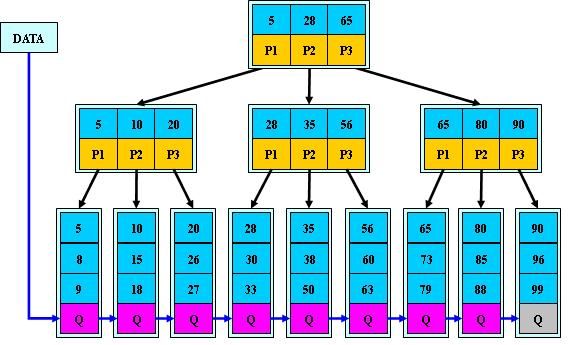
B+的搜索与B-树也基本相同,区别是B+树只有达到叶子结点才命中(B-树可以在非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
B+的特性:
1.所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
2.不可能在非叶子结点命中;
3.非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
4.更适合文件索引系统;
B+tree的优点:
B+-tree的磁盘读写代价更低
b+Tree的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
B+-tree的查询效率更加稳定
由于内部结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
数据库索引不使用二叉树的原因:
同等数据情况下,二叉树需要进行的io操作和内存查找次数多于b树,而且数据量越大差距越明显。
数据库引擎
MyISAM索引实现:
MyISAM索引使用b+Tree实现,叶节点的data域存放的是数据记录的地址。
在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复
InnoDB索引实现:
InnoDB索引也使用b+Tree实现,但表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。InnoDB的辅助索引data域存储相应记录主键的值而不是地址。即InnoDB的所有辅助索引都引用主键作为data域
知道InnoDB的索引实现后,就很容易明白为什么不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。再例如,用非单调的字段作为主键在InnoDB中不是个好主意,因为InnoDB数据文件本身是一颗B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。
为什么不用哈希索引
哈希索引虽然在查找修改删除时时间复杂度是O(1),但以下情况下不够稳定:
1、范围查询:哈希索引使用的是hash后的hashcode,范围内的数据hashcode并没有对应的关系。
2、哈希索引需要再查询到hashcode之后再通过code查询到指定的记录才行,不能避免表扫描。
3、大量hashcode相等的情况时,时间复杂度退化。
4、哈希索引使用多个字段值合并计算hashcode,无法使用索引的最左匹配查询。
explain
explain结果的字段含义:
- id,代表select语句执行的id,id越大执行越早
- selectType,代表查询的类型。SIMPLE查询语句只有一个select没有子查询;PRIMARY复杂查询最外层的查询;SUBQUERY外层查询from千的子查询;DERIVED外层查询from后的子查询,派生查询;UNION在union查询中union后面的select都是UNION
- table,表示访问的表
- type,表示关联类型或访问类型。依次从最优到最差分别为:system > const > eq_ref > ref > range > index > ALL,一般来说最好能达到range以上到ref级别。NULL,表示在优化阶段能够分解查询语句,不需要再访问表或索引;const、system,表示查询的结果能被优化并转化为一个常量,system表示表里只有一条数据匹配;eq_ref,使用唯一索引或主键索引做连接,最多只会返回一条符合条件的记录;ref,使用普通索引或唯一性索引的部分前缀,可能会有多个符合条件的行;range,范围扫描;index,扫描全索引即可拿到结果,一般是二级索引,速度较慢;ALL,全表扫描。
- possibleKey:表示可能用到哪些索引,是否使用需要看key列
- key:显示实际采用哪个索引
- keyLen:显示在索引里使用的字节数,通过这个值可以算出具体使用了索引中的哪些列
- ref:显示在索引中,表查找值所用到的列或常量
- extra:额外信息。如UsingIndex表示使用覆盖索引;UsingWhere使用where语句并且违背索引覆盖;UsingIndexCondition查询的列不完全被索引覆盖;UsingTemporary需要创建临时表查询;UsingFileSort使用外部排序而非索引排序;SelectTablesOptimizedAway使用了聚合函数访问存在索引的某个字段
15.MySQL的锁:
1. 行锁:行锁一定是作用在索引上的。eg:select * from tableA where id = 11 for update; 若id是索引字段即自动加行锁。而select会自动给表加读锁,insert、update、delete则会自动给表加写锁。
2. 间隙锁:间隙锁本质上是用于阻止其他事务在该间隙内插入新记录,而自身事务是允许在该间隙内插入数据的。也就是说间隙锁的应用场景包括并发读取、并发更新、并发删除和并发插入。只有在事务隔离级别 RR 中才会产生。
唯一索引只有锁住多条记录或者一条不存在的记录的时候,才会产生间隙锁,不包括记录本身,指定给某条存在的记录加锁的时候,只会加记录锁,不会产生间隙锁。普通索引不管是锁住单条,还是多条记录,都会产生间隙锁。间隙锁会封锁该条记录相邻两个键之间的空白区域,防止其它事务在这个区域内插入、修改、删除数据,这是为了防止出现幻读现象。普通索引的间隙,优先以普通索引排序,然后再根据主键索引排序。事务级别是RC(读已提交)级别的话,间隙锁将会失效。
3. 临键锁:是行锁与间隙锁的组合,它的封锁范围,既包含索引记录,又包含索引区间。主要目的也是为了避免幻读。如果把事务的隔离级别降级为RC,临键锁则也会失效。
4. 共享锁/排它锁:共享锁/排他锁都只是行锁。共享锁可以并发读,排它锁其他线程不可以读写。读锁就是共享锁、写锁是排它锁。
5. 意向共享锁/意向排它锁:意向共享锁/意向排他锁属于表锁,且取得意向共享锁/意向排他锁是取得共享锁/排他锁的前置条件。由于InnoDB存储引擎支持的是行级别的锁,因此意向锁其实不会阻塞除全表扫以外的任何请求。且意向排它锁是可以互相兼容的。
6. 插入意向锁:一种特殊的间隙锁,只用于并发插入操作。多事务不能同时获取相同的插入意向锁。
7. 自增锁:是一种特殊的表级锁,主要用于事务中插入自增字段,也就是我们最常用的自增主键id。表里有一个auto_increment字段的时候,innoDB会在内存里保存一个计数器用来记录auto_increment的值,当插入一个新行数据时,就会用一个表锁来锁住这个计数器,直到插入结束。如果大量的并发插入,表锁会引起SQL堵塞。InnoDB为了解决自增主键锁表的问题,引入了参数innodb_autoinc_lock_mode,该实现方式是通过轻量级互斥量的增长机制完成的。它是专门用来在使用auto_increment的情况下调整锁策略。0:通过表锁的方式进行,所有类型的insert都用AUTO-inc locking;1:默认值,产生一个轻量锁,对于simple insert 自增长值的产生使用互斥量对内存中的计数器进行累加操作,对于bulk insert 则还是使用表锁的方式进行;2:对所有的insert-like 自增长值的产生使用互斥量机制完成,并发性能最高,并发插入可能导致自增值不连续,可能会导致Statement 的 Replication 出现不一致,使用该模式,需要用 Row Replication的模式。
16、Mybatis
MyBatis 是一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免了几乎所有的 JDBC代码和手动设置参数以及获取结果集。MyBatis 可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 POJOs(Plain Old Java Objects,普通的 Java对象)映射成数据库中的记录。
优势:
DAO层代码可以通过现有插件直接生成,大大提高编码效率和准确性。
mybatis已有的连接池管理,缓存管理等所带来的代码性能优势和可靠性。
一致的编码风格大大减少代码的沟通成本;
mybatis提供了一级和二级缓存(需要配置打开),强大的动态sql,自动化的session管理,都比手工维护来的方便和安全。
不用重复写resultset到domain的转化了。
相似的sql不需要重复写。
实现原理:
1)读取 MyBatis 配置文件:mybatis-config.xml 为 MyBatis 的全局配置文件,配置了 MyBatis 的运行环境等信息,例如数据库连接信息。
2)加载映射文件。映射文件即 SQL 映射文件,该文件中配置了操作数据库的 SQL 语句,需要在 MyBatis配置文件 mybatis-config.xml中加载。mybatis-config.xml文件可以加载多个映射文件,每个映射文件对应数据库中的一张表。用Mapper标签注册。
3)构造会话工厂:通过 MyBatis 的环境等配置信息构建会话工厂 SqlSessionFactory。
4)创建会话对象:由会话工厂创建 SqlSession 对象,该对象中包含了执行 SQL 语句的所有方法。
5)Executor 执行器:MyBatis 底层定义了一个 Executor 接口来操作数据库,它将根据 SqlSession 传递的参数动态地生成需要执行的 SQL 语句,同时负责查询缓存的维护。
6)MappedStatement 对象:在 Executor 接口的执行方法中有一个 MappedStatement 类型的参数,该参数是对映射信息的封装,用于存储要映射的 SQL 语句的 id、参数等信息。
7)输入参数映射:输入参数类型可以是 Map、List 等集合类型,也可以是基本数据类型和 POJO 类型。输入参数映射过程类似于 JDBC 对 preparedStatement 对象设置参数的过程。
8)输出结果映射:输出结果类型可以是 Map、 List 等集合类型,也可以是基本数据类型和 POJO 类型。输出结果映射过程类似于 JDBC 对结果集的解析过程。
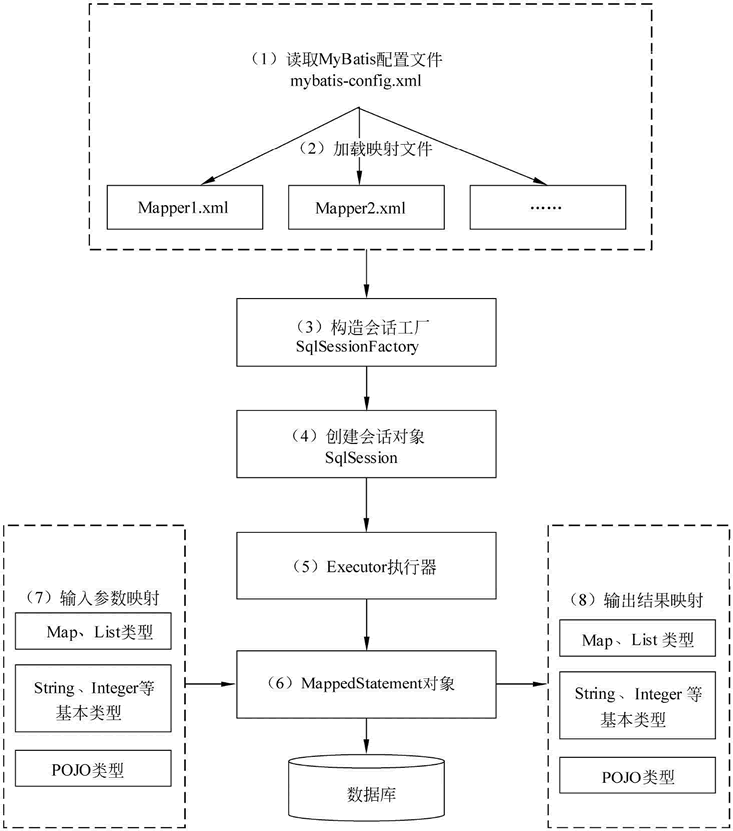
# 和 $ 的区别:
动态 sql 是 mybatis 的主要特性之一,在mybatis中我们可以把参数传到xml文件,由mybatis对sql及其语法进行解析,mybatis支持使用 ${} 和 #{} 。
#方式传入的参数会自动以String形式填入,而$方式传入的参数仅仅是简单的拼接,因此#可以避免sql注入而$不行
缓存:
mybatis自带缓存,一级缓存(sqlSession级别)、二级缓存(nameSpace级别)。
- 一级缓存:默认开启,底层基于hashMap实现的本地内存缓存,作用域是session,当session刷新或关闭时清除缓存,不同session之间互不影响。注:建议一个session周期不能过长,相同操作尽量使用同一个session,避免出现数据不一致的问题。
- 二级缓存:默认不开启,作用域是mapper。注:若多个nameSpace操作同一个表,则会产生数据问题,建议对同一个表的操作写在同一个namespace中;联表查询等操作都写在同一个nameSpace中。
mybatis自带缓存会存在脏数据问题。一级缓存因为是session维度,多session同时操作时会有脏数据产生;同样二级缓存是namespace维度,不同namespace查询同个表时也会产生脏数据。
建议关闭一二级缓存,同一使用第三方缓存,如redis。
使用redis保证缓存的数据一致性,而不是依赖于mybatis自身的一致性。
17、Spring boot 拦截器和过滤器
这两者在功能方面很类似,但是在具体技术实现方面,差距还是比较大的。先理解一下AOP的概念,AOP不是一种具体的技术,而是一种编程思想。在面向对象编程的过程中,很容易通过继承、多态来解决纵向扩展。 但是对于横向的功能,比如,在所有的service方法中开启事务,或者统一记录日志等功能,面向对象的是无法解决的。所以AOP——面向切面编程其实是面向对象编程思想的一个补充。过滤器和拦截器都属于面向切面编程的具体实现。而两者的主要区别包括以下几个方面:
1、Filter是依赖于Servlet容器,属于Servlet规范的一部分,而拦截器则是独立存在的,可以在任何情况下使用。
2、过滤器的实现基于回调函数。而拦截器(代理模式)的实现基于反射,代理分静态代理和动态代理,动态代理是拦截器的简单实现。
3、Filter的生命周期由Servlet容器管理,而拦截器则可以通过IoC容器来管理,因此可以通过注入等方式来获取其他Bean的实例,因此使用会更方便。而过滤器就不行,因为拦截器是spring提供并管理的,spring的功能可以被拦截器使用,在拦截器里注入一个service,可以调用业务逻辑。而过滤器是JavaEE标准,只需依赖servlet api ,不需要依赖spring。
4、过滤器和拦截器触发时机不一样,过滤器是在请求进入容器后,但请求进入servlet之前进行预处理的。请求结束返回也是,是在servlet处理完后,返回给前端之前
spring boot 使用过滤器
两种方式:
1、使用spring boot提供的FilterRegistrationBean注册Filter
2、使用原生servlet注解定义Filter
两种方式的本质都是一样的,都是去FilterRegistrationBean注册自定义Filter
spring boot使用拦截器
方式和aop简单实现相同,创建对前端请求的拦截器相关时序的相关操作,注册拦截器,即可
反射机制
在运行状态时,可以动态的直到一个类中的所有属性和方法,对于任意一个对象都能动态的调用它的属性和方法。
通过java.lang.Class类,封装了一个类或接口的运行信息,通过Class的方法可以获取这些信息。
反射机制可以在运行时判断任意一个对象所属的类,在运行时构建任意一个类的对象,在运行时判断任意一个类所具有的成员变量和方法,在运行时调用任意一个对象的方法,实现动态代理。
19、AOP
AOP(Aspect-OrientedProgramming,面向方面编程),可以说是OOP(Object-Oriented Programing,面向对象编程)的补充和完善。OOP引入封装、继承和多态性等概念来建立一种对象层次结构,用以模拟公共行为的一个集合。当我们需要为分散的对象引入公共行为的时候,OOP则显得无能为力。OOP允许定义从上到下的关系,但并不适合定义从左到右的关系。例如日志功能。日志代码往往水平地散布在所有对象层次中,而与它所散布到的对象的核心功能毫无关系。对于其他类型的代码,如安全性、异常处理和透明的持续性也是如此。这种散布在各处的无关的代码被称为横切(cross-cutting)代码,在OOP设计中,它导致了大量代码的重复,而不利于各个模块的重用。
而AOP技术则恰恰相反,利用一种称为“横切”的技术,剖解开封装的对象内部,并将那些影响了多个类的公共行为封装到一个可重用模块,并将其名为“Aspect”。即将那些与业务无关,却为业务模块所共同调用的逻辑或责任封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可操作性和可维护性。AOP代表的是一个横向的关系,如果说“对象”是一个空心的圆柱体,其中封装的是对象的属性和行为;那么面向方面编程的方法,就仿佛一把利刃,将这些空心圆柱体剖开,以获得其内部的消息。而剖开的切面,也就是所谓的“Aspect”了。然后它又以巧夺天功的妙手将这些剖开的切面复原,不留痕迹。
使用“横切”技术,AOP把软件系统分为两个部分:核心关注点和横切关注点。业务处理的主要流程是核心关注点,与之关系不大的部分是横切关注点。横切关注点的一个特点是,他们经常发生在核心关注点的多处,而各处都基本相似。比如权限认证、日志、事务处理。Aop 的作用在于分离系统中的各种关注点,将核心关注点和横切关注点分离开来。AOP的核心思想就是“将应用程序中的商业逻辑同对其提供支持的通用服务进行分离。”
实现AOP的技术,主要分为两大类:一是采用动态代理技术,利用截取消息的方式,对该消息进行装饰,以取代原有对象行为的执行;二是采用静态织入的方式,引入特定的语法创建“方面”,从而使得编译器可以在编译期间织入有关“方面”的代码。
通过beanFactory将bean对象包装成beanProxy对象,使用代理的特性(在被代理对象的每个方法执行前后可以进行额外操作)对原对象的功能进行增强。
使用场景:
Authentication 权限
Caching 缓存
Context passing 内容传递
Error handling 错误处理
Lazy loading 懒加载
Debugging 调试
logging, tracing, profiling and monitoring 记录跟踪 优化 校准
Performance optimization 性能优化
Persistence 持久化
Resource pooling 资源池
Synchronization 同步
Transactions 事务
Spring中对动态代理方式的选择:
如果是接口类,则默认使用JDK动态代理;而如果是普通类,则默认使用CgLib动态代理。
CgLib使用类继承实现动态代理,而JDK代理是基于实现接口。
“为什么Java动态代理一定是使用接口?”:因为默认生成的代理类(代理对象)已经继承了Proxy类,java单继承,如果需要进一步拓展功能,则需要使用实现接口的方式。
在Proxy.newProxyInstance中生成了代理类$Proxy0,这个代理类继承了Proxy类,因此不能再继承其他类,只能实现接口。
调用代理类对象方法的流程为:代理对象转换成了被代理类的接口类型,调用接口方法->接口方法调用handler中的invoke方法->invoke方法又通过反射调用了被代理类的指定方法。
代理类是通过被代理类的类加载器和接口生成的动态代理类,缓存在内存中。
即代理对象持有被代理对象的handler,被代理对象的handler通过invoke将外部调用转化为被代理对象的调用。
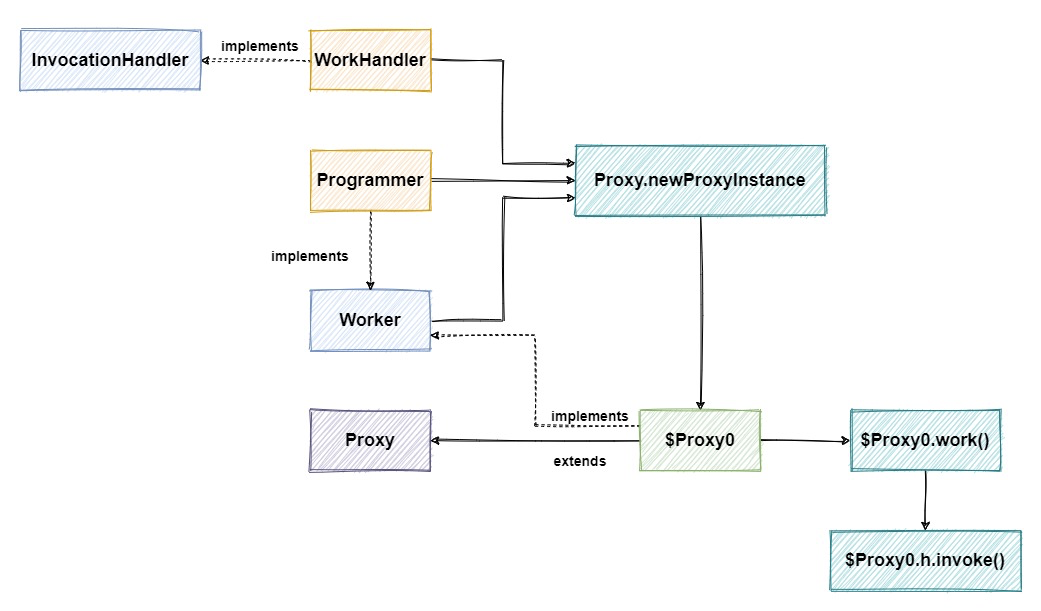
JDK动态代理和CgLib的区别:
JDK动态代理是实现接口,使用反射,在生成代理对象时,需要共同实现的接口的加载器、接口对象以及InvocationHandler(持有原始对象),在handler中每次调用invoke方法时都会使用一次反射。(接口没有private方法,不存在CgLib中private方法为空的情况)
CgLib是类继承,子类重写要代理类的所有不是final的方法,在底层使用字节码技术实现。方法不能是private,因为是类继承,子类继承后不能访问父类的private方法。
在效率上,JDK生成代理对象快,Cglib执行方法快。而在JDK7和8中,动态代理性能均优于Cglib。
20、接口幂等性设计
接口的幂等性实际上就是接口可重复调用,在调用方多次调用的情况下,接口最终得到的结果是一致的
全局唯一性ID
如果使用全局唯一ID,就是根据业务的操作和内容生成一个全局ID,在执行操作前先根据这个全局唯一ID是否存在,来判断这个操作是否已经执行。如果不存在则把全局ID,存储到存储系统中,比如数据库、redis等。如果存在则表示该方法已经执行。
去重表
这种方法适用于在业务中有唯一标的插入场景中,比如在支付场景中,如果一个订单只会支付一次,所以订单ID可以作为唯一标识。这时,我们就可以建一张去重表,并且把唯一标识作为唯一索引,在我们实现时,把创建支付单据写入去重表,放在一个事务中,如果重复创建,数据库会抛出唯一约束异常,操作就会回滚。
插入或更新
这种方法插入并且有唯一索引的情况,比如我们要关联商品品类,其中商品的ID和品类的ID可以构成唯一索引,并且在数据表中也增加了唯一索引。这时就可以使用InsertOrUpdate操作。
多版本控制
这种方法适合在更新的场景中,比如我们要更新商品的名字,这时我们就可以在更新的接口中增加一个版本号,来做幂等。在数据库中用版本号做乐观锁,只有版本号匹配的请求才可以进行数据操作。
状态控制机制
这种方法适合在有状态流转的情况下,比如就会订单的创建和付款,订单的付款肯定是在之前,这时我们可以通过在设计状态字段时,使用int类型,并且通过值类型的大小来做幂等,比如订单的创建为0,付款成功为100。付款失败为99
22、hashmap的四种遍历方式
public static void main(String[] args) {Map<String, String> map = new HashMap<String, String>();map.put("1", "value1");map.put("2", "value2");map.put("3", "value3");//第一种:普遍使用,二次取值System.out.println("通过Map.keySet遍历key和value:");for (String key : map.keySet()) {System.out.println("key= "+ key + " and value= " + map.get(key));}//第二种System.out.println("通过Map.entrySet使用iterator遍历key和value:");Iterator<Map.Entry<String, String>> it = map.entrySet().iterator();while (it.hasNext()) {Map.Entry<String, String> entry = it.next();System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());}//第三种:推荐,尤其是容量大时System.out.println("通过Map.entrySet遍历key和value");for (Map.Entry<String, String> entry : map.entrySet()) {System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());}//第四种System.out.println("通过Map.values()遍历所有的value,但不能遍历key");for (String v : map.values()) {System.out.println("value= " + v);}}
23、多线程相关
任何一个线程的开启,就是调用Thread实例的start()方法,然后JVM新起一个线程执行Thread实例的run()方法。而run()方法使用的target是一个Runnable对象。
由此可以有两种创建线程的方式。
// Thread.start()public synchronized void start() {if (threadStatus != 0)throw new IllegalThreadStateException();group.add(this);boolean started = false;try {start0();started = true;} finally {try {if (!started) {group.threadStartFailed(this);}} catch (Throwable ignore) {}}}// native方法,开启一个线程,并执行run()方法private native void start0();
private Runnable target;private Thread(ThreadGroup g, Runnable target, String name,long stackSize, AccessControlContext acc,boolean inheritThreadLocals) {...this.target = target;...}@Overridepublic void run() {if (target != null) {target.run();}}
实现多线程的方法:
- 继承Thread类,重写run():通过start()方法(一个native方法,启动一个新线程并执行run()方法)
public class ThreadDemo extends Thread{@Overridepublic void run() {for(int i = 0;i<10;i++){System.out.println(Thread.currentThread().getName()+"--------------"+i);}}public static void main(String[] args) {ThreadDemo threadDemo = new ThreadDemo();threadDemo.start(); //此处注意for(int i =0;i<5;i++){System.out.println(Thread.currentThread().getName()+"==========="+i);}}}
- 实现Runnable接口,重写run():在无法继承类的情况下实现接口。需要实例化一个Thread并传入自己线程类的实例target,此时Thread的run()方法会调用target的run()。
public class ThreadTest {public static void main(String[] args) {new Thread(new T1()).start();}}class T1 implements Runnable{@Overridepublic void run() {for(int i = 0; i < 100; i++)System.out.println("T1.....running......");}}
- ExecutorService、Callable、Future有返回值线程,重写call():Callable接口实际上是属于Executor框架中的功能类。在线程池中将结果submit到future中,最后通过future获取返回值。
- 实现Callable(V),实现call()方法。这是一个带返回值的方法,类似Thread的run()。
package mycallable;import java.util.concurrent.Callable;public class MyCallable implements Callable<String> {private int age;public MyCallable(int age) {super();this.age = age;}public String call() throws Exception {Thread.sleep(8000);return "返回值 年龄是:" + age;}}
package test.run;import java.util.concurrent.ExecutionException;import java.util.concurrent.Future;import java.util.concurrent.LinkedBlockingDeque;import java.util.concurrent.ThreadPoolExecutor;import java.util.concurrent.TimeUnit;import mycallable.MyCallable;public class Run {public static void main(String[] args) throws InterruptedException {try {MyCallable callable = new MyCallable(100);ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 3, 5L, TimeUnit.SECONDS, new LinkedBlockingDeque());Future<String> future = executor.submit(callable);System.out.println("main A " + System.currentTimeMillis());System.out.println(future.get());System.out.println("main B " + System.currentTimeMillis());} catch (ExecutionException e) {e.printStackTrace();}}}
- 线程池:可以避免线程和数据库连接等资源的浪费。(顶级接口Executor,真正的线程池接口为ExecutorService。)
线程池:
线程池只允许实现Runnable的线程,不允许thread
- newCachedThreadpool,创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。超过60秒未被使用的线程会被回收,适用于执行很多短期异步的小程序或者负载较轻的服务器。
- newFixedThreadpool,创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。适合执行长期的任务。
- newScheduledThreadpool,创建一个定长线程池,支持定时及周期性任务执行。适用于周期性执行任务的场景。
- newSingleThreadExecutor,创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。适用于一个任务一个任务执行的场景。
线程池参数:核心线程数、最大线程数、闲置线程存活时间、时间单位、线程队列(ArrayBlockingQueue,基于数组的有界阻塞队列;LinkedBlockingQuene,基于链表的无界阻塞队列;SynchronousQuene,一个不缓存的阻塞队列,进入的任务必须被处理才能接受新任务;PriorityBlockingQueue优先阻塞队列)、线程工厂、拒绝策略(AbortPolicy,丢弃任务并抛出异常;DiscardPolicy,丢弃后续任务,不抛出异常;DiscardOldestPolicy,丢弃旧任务,不抛出异常;CallerRunsPolicy,若被拒绝,则由调用线程直接完成)
线程池原理:
在达到核心线程数之前,新来的任务会直接创建线程并运行。达到核心线程数后,新来的任务会进入等待队列等待。如果任务继续增加,等待队列已满,则开始创建临时线程线程执行任务。若任务继续增加,队列已满且工作线程数达到最大线程数,则触发拒绝策略。
线程复用:线程池相当于继承重写 Thread 类,在其 start 方法中添加不断循环调用传递过来的 Runnable 对象。循环方法中不断获取 Runnable 是用 Queue 实现的,在获取下一个 Runnable 之前可以是阻塞的。即线程池的核心线程创建后通常是不会被回收的。
线程池组成:线程管理器(创建并管理线程池)、工作线程(线程池中的线程)、任务接口(每个线程必须实现,用于工作线程调度)、任务队列。
线程池状态
RUNNING:运行状态,接受新任务,处理队列中的任务。初始化后的线程池也是RUNNING,线程池中线程数为0。
SHUTDOWN:不接受新任务,但会处理队列中的任务。由shutdown()方法发起,状态由RUNNING变为SHUTDOWN。
STOP:不接受新任务,不处理队列中任务,中断正在执行的任务。由shutdownnow()方法发起,线程池由RUNNING或SHUTDOWN变为STOP。
TIDYING:
所有任务都销毁,workCount为0,并且转换状态为TIDYING时,会执行钩子方法terminated(),用户可以通过重载terminated()方法修改处理。
SHUTDOWN状态时,阻塞队列为空且任务都执行完成时,会变为TIDYING。
STOP状态时,线程中执行的任务为空时,会变为TIDYING。
TERMINATED:线程池在TIDYING状态执行完terminated()方法后会变为TERMINATED。
线程生命周期:
- 新建(new):创建实例后由jvm分配内存及初始化变量
- 就绪(runnable):运行start()方法后,创建了方法调用栈和程序计数器,等待运行
- 运行(running):就绪状态线程获取CPU,开始执行run()方法内容
- 阻塞(blocked):指线程因某种原因放弃了CPU,暂停运行。三种情况:等待阻塞,运行中线程调用o.wait()方法,该线程进入等待队列;同步阻塞,运行线程获取同步锁失败,该线程进入锁池;其他阻塞,运行的线程执行sleep或者join方法或IO超时,当sleep或join结束、IO执行完成后,线程可转为运行状态
- 死亡(dead):正常结束,run()或call()执行完成;异常结束,抛出未捕获的异常或错误;调用stop()结束线程,但容易产生死锁。
线程池回收空闲线程
工作线程启动后,会进入runWorker(Worker w)方法。其中有一个while循环,循环判断任务(通过getTask()获取)是否为空,若不为空则执行任务,若为空,则发生异常退出循环,移除工作线程。
有两种场景:
- 未调用shutdown(),RUNNING状态下全部执行完成
线程数量大于核心线程数,线程超时阻塞,唤醒后CAS减少工作线程数,成功则返回null,线程被回收。工作线程数小于等于核心线程数时会一直阻塞。 - 调用shutdown(),全部任务执行完成
所有线程都阻塞的情况时,中断唤醒进入循环,所有线程都返回null,回收线程;
任务还没有完全执行完时,会调用tryTerminate()方法,向任意空闲线程发出中断信号,被阻塞的线程最终都会被唤醒回收。
线程终止的方法:
- 正常结束运行
- 使用退出标志退出(但需要加锁,如volatile,保证同时只有一个线程修改)
- interrupt:线程处于阻塞状态,调用interrupt(),捕获抛出的InterruptException后,break跳出循环;线程处于非阻塞状态,使用isInterrupted标志和interrupt()退出循环。
- stop方法终止线程:thread.stop()可以强行停止线程,但是可能会导致该线程持有的锁不可控,进而导致数据不一致等问题。
sleep和wait:sleep是Thread的方法,wait是Object的方法;sleep不会释放锁,wait会释放锁。
start和run:start标志着线程就绪,run标志着线程运行。
守护线程:守护线程为用户线程提供公共服务,需要在start前设置为守护线程,在守护线程中启动的线程也是守护线程,在jvm中若没有用户线程时会守护线程才会退出。
锁:
- 乐观锁(Optimistic Locking):对加锁持有一种乐观的态度,即先进行业务操作,不到最后一步不进行加锁,"乐观"的认为加锁一定会成功的,在最后一步更新数据的时候再进行加锁(比较版本号)。java中使用CAS实现乐观锁,比较当前值和传入值是否相同,一致更新,否则失败,然后重试。
- 悲观锁(Pessimistic Lock):对数据加锁持有一种悲观的态度。在整个数据处理过程中,将数据处于锁定状态。悲观锁的实现,往往依靠数据库提供的锁机制(也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据)。如Synchronized、RetrantLock。
- 自旋锁:若持有锁的线程在较短的时间内可以释放锁,则等待线程可以不必在内核态和用户态之间进行切换而进入阻塞状态,可以进入自旋稍等线程释放锁;若在最大自旋等待时间内还未释放锁,则竞争线程停止自旋进入阻塞。适合竞争不激烈且线程占用对象时间短的情况。
- Synchronized同步锁:可以把任意一个非NULL的对象当作锁。属于独占式的悲观锁,同时属于可重入锁。
Synchronized作用范围:非静态方法使用 synchronized 修饰的写法,修饰实例方法时,锁定的是当前线程对象;代码块使用 synchronized 修饰的写法,使用代码块,如果传入的参数是 this,那么锁定的也是当前的对象;同一个类的两个同步方法,在一个线程访问任一方法后,其他线程需要等待才能访问其他同步方法,但可以直接访问其他非同步方法;静态同步方法和同步方法不互相影响。
Synchronized核心组件:
Wait Set: 放置调用 Object#wait() 方法后被阻塞的线程
Contention List: 竞争队列,所有请求锁的线程先放置在这个竞争队列中
Entry List: 竞争队列中有资格成为候选资源的线程被移动到 Entry List 中
OnDeck: 无论什么时候, 最多只有一个线程正在竞争锁资源,该线程就叫 OnDeck
Owner: 当前已经获取到锁资源的线程叫做 Owner
!Owner: 当前释放锁的线程Synchronized实现:
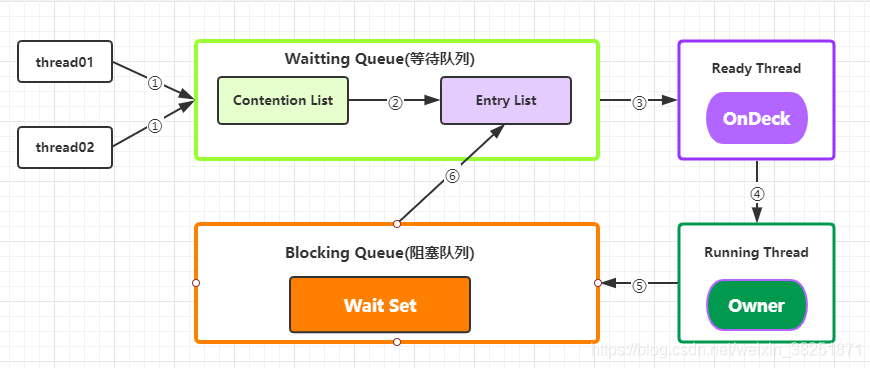
1. JVM每次从ContentionList队列的尾部取出一个数据用于锁竞争候选者(OnDeck),但是并发情况下,ContentionList会被大量的并发线程进行CAS访问,为了降低对尾部元素的竞争,JVM会将一部分线程移动到EntryList中作为候选竞争线程。
2. Owner线程会在unlock时,将ContentionList中的部分线程迁移到EntryList中,并指定EntryList中的某个线程为OnDeck线程(一般是最先进去的那个线程)。
3.Owner线程并不直接把锁传递给OnDeck线程,而是把锁竞争的权利交给OnDeck,OnDeck需要重新竞争锁。这样虽然牺牲了一些公平性,但是能极大的提升系统的吞吐量,在JVM中,也把这种选择行为称之为“竞争切换”。
4. OnDeck线程获取到锁资源后会变为Owner线程,而没有得到锁资源的仍然停留在EntryList中。如果Owner线程被wait方法阻塞,则转移到WaitSet队列中,直到某个时刻通过notify或者notifyAll唤醒,会重新进去EntryList中。
5. 处于ContentionList、EntryList、WaitSet中的线程都处于阻塞状态,该阻塞是由操作系统来完成的(Linux内核下采用pthread_mutex_lock内核函数实现的)。
6. Synchronized是非公平锁。 Synchronized在线程进入ContentionList时,线程会先尝试自旋获取锁,如果获取不到就进入ContentionList,这明显对于已经进入队列的线程是不公平的,还有一个不公平的事情就是自旋获取锁的线程还可能直接抢占OnDeck线程的锁资源。
7. 每个对象都有个monitor对象,加锁就是在竞争monitor对象,代码块加锁是在前后分别加上monitorenter和monitorexit指令来实现的,方法加锁是通过一个标记位来判断的。monitor对象中还有一个计数器,用来实现重入。
8. synchronized是一个重量级操作,需要调用操作系统相关接口,性能是低效的,有可能给线程加锁消耗的时间比有用操作消耗的时间更多。
9. Java1.6,synchronized进行了很多的优化,有适应自旋、锁消除、锁粗化、轻量级锁及偏向锁等,效率有了本质上的提高。在之后推出的Java1.7与1.8中,均对该关键字的实现机理做了优化。引入了偏向锁和轻量级锁。都是在对象头中有标记位,不需要经过操作系统加锁。
10. 锁可以从偏向锁升级到轻量级锁,再升级到重量级锁。这种升级过程叫做锁膨胀;
11. JDK 1.6中默认是开启偏向锁和轻量级锁,可以通过-XX:-UseBiasedLocking来禁用偏向锁。
12. 底层依赖操作系统的MutexLock。相当于MutexLock控制了资源,线程需要向MutexLoack请求资源,而其指针指向的是当前占有资源的线程。
ReentrantLock:
是一个可重入的互斥锁,又被称为“独占锁”,继承接口Lock并实现了接口中定义的方法,除了能完成synchronized所能完成的所有工作外,还提供了诸如可响应中断锁、可轮询锁请求、定时锁等避免多线程死锁的方法。
reentrantlock的公平锁和非公平锁都是基于AQS实现的。加锁时使用CAS设置锁的state,如果是0,则表示可以加锁,将当前线程设置为锁的owner;如果加锁失败,则执行AQS中的acquire进行锁的抢占,先执行自定义的抢占逻辑:首先使用CAS再次尝试加锁,如果失败,则判断当前owner是否为当前线程,如果是则进行锁重入,如果不是则失败,进入队列排队。
Lock主要方法:
1. void lock(): 执行此方法时, 如果锁处于空闲状态, 当前线程将获取到锁. 相反, 如果锁已经被其他线程持有, 将禁用当前线程, 直到当前线程获取到锁.
2. boolean tryLock():如果锁可用, 则获取锁, 并立即返回true, 否则返回false. 该方法和lock()的区别在于, tryLock()只是"试图"获取锁, 如果锁不可用, 不会导致当前线程被禁用, 当前线程仍然继续往下执行代码. 而lock()方法则是一定要获取到锁, 如果锁不可用, 就一直等待, 在未获得锁之前,当前线程并不继续向下执行.
3. void unlock():执行此方法时, 当前线程将释放持有的锁. 锁只能由持有者释放, 如果线程并不持有锁, 却执行该方法, 可能导致异常的发生.
4. Condition newCondition():条件对象,获取等待通知组件。该组件和当前的锁绑定,当前线程只有获取了锁,才能调用该组件的await()方法,而调用后,当前线程将缩放锁。
5. getHoldCount() :查询当前线程保持此锁的次数,也就是此线程执行lock方法的次数。
6. getQueueLength():返回正等待获取此锁的线程估计数,比如启动10个线程,1个线程获得锁,此时返回的是9
7. getWaitQueueLength:(Condition condition)返回等待与此锁相关的给定条件的线程估计数。比如10个线程,用同一个condition对象,并且此时这10个线程都执行了condition对象的await方法,那么此时执行此方法返回10
8. hasWaiters(Condition condition):查询是否有线程等待与此锁有关的给定条件(condition),对于指定contidion对象,有多少线程执行了condition.await方法
9. hasQueuedThread(Thread thread):查询给定线程是否等待获取此锁
10. hasQueuedThreads():是否有线程等待此锁
11. isFair():该锁是否公平锁
12. isHeldByCurrentThread(): 当前线程是否保持锁锁定,线程的执行lock方法的前后分别是false和true
13. isLock():此锁是否有任意线程占用
14. lockInterruptibly():如果当前线程未被中断,获取锁
15. tryLock(long timeout TimeUnit unit):如果锁在给定等待时间内没有被另一个线程保持,则获取该锁。
公平锁、非公平锁:
公平锁指的是锁的分配机制是公平的,加锁前检查是否有排队等待的线程,优先分配排队等待的线程。ReentrantLock在构造函数中提供了是否公平锁的初始化方式来定义公平锁,默认为非公平锁。非公平锁在加锁时不考虑排队等待问题,直接尝试获取锁,获取不到自动到队尾等待。非公平锁性能比公平锁高5~10倍,因为公平锁需要在多核的情况下维护一个队列,队列中等待的线程需要进行cpu状态的切换进行资源抢占,而非公平锁的线程如果直接抢占成功就避免了切换产生的开销。除非程序有特殊需要,否则最常用非公平锁的分配机制。
ReentrantLock 与synchronized:
1. ReentrantLock通过方法lock()与unlock()来进行加锁与解锁操作,与synchronized会被JVM自动解锁机制不同,ReentrantLock加锁后需要手动进行解锁。为了避免程序出现异常而无法正常解锁的情况,使用ReentrantLock必须在finally控制块中进行解锁操作。
2. ReentrantLock相比synchronized的优势是可中断、公平锁、多个锁。这种情况下需要使用ReentrantLock。
AtomicInteger:
AtomicInteger,一个提供原子操作的Integer的类,常见的还有AtomicBoolean、AtomicLong、AtomicReference等,他们的实现原理相同,区别在与运算对象类型的不同。还可以通过AtomicReference将一个对象的所有操作转化成原子操作。在多线程程序中,诸如++i或i++等运算不具有原子性,是不安全的线程操作之一。通常我们会使用synchronized将该操作变成一个原子操作,但JVM为此类操作特意提供了一些同步类,使得使用更方便,且使程序运行效率变得更高。通常AtomicInteger的性能是ReentantLock的好几倍。
读写锁:
为了提高性能,Java提供了读写锁,在读的地方使用读锁,在写的地方使用写锁,灵活控制。如果没有写锁的情况下,读是无阻塞的,在一定程度上提高了程序的执行效率。读写锁分为读锁和写锁,多个读锁不互斥,读锁与写锁互斥,这是由jvm自己控制的。
可重入锁:
也叫做递归锁,指的是同一线程外层函数获得锁之后,内层递归函数仍然有获取该锁的代码,但不受影响。在JAVA环境下 ReentrantLock 和synchronized都是可重入锁。获取到ReentrantLock锁的线程可以再次获取该锁,获取了n次锁,在也需要释放n次才可以被其他线程获取。
共享锁和独占锁:
独占锁只允许一个线程持有锁,ReentrantLock就是以独占方式实现的互斥锁。独占锁是一种悲观保守的加锁策略,避免读/读冲突。
共享锁则允许多个线程同时获取锁,并发访问共享资源,如:ReadWriteLock。共享锁则是一种乐观锁,它放宽了加锁策略,允许多个执行读操作的线程同时访问共享资源。
锁的升级:
无锁状态->偏向锁->轻量级锁->重量级锁
随着锁的竞争,锁可以从偏向锁升级到轻量级锁,再升级到重量级锁(但是锁的升级是单向的,也就是说只能从低到高升级,不会出现锁的降级)。
通常是不会进行锁的降级的,因为频繁对锁升降级会有性能上 的影响。重量级锁降级发生在stw阶段,降级对象为仅仅能被VMThread访问而没有其他JavaThread访问的对象。
正在使用中的锁不能降级。所有的重量级锁释放后会回归无锁状态,但下一次获取锁的时候,就会直接获取轻量级锁(相当于禁用了偏向锁,说明当前环境是多线程的)
偏向锁:
大多数情况下锁不仅不存在多线程竞争,而且总是由同一线程多次获得。偏向锁的目的是在某个线程获得锁之后,消除这个线程锁重入(CAS)的开销,看起来让这个线程得到了偏护。引入偏向锁是为了在无多线程竞争的情况下尽量减少不必要的轻量级锁执行路径,因为轻量级锁的获取及释放依赖多次CAS原子指令,而偏向锁只需要在置换ThreadID的时候依赖一次CAS原子指令(由于一旦出现多线程竞争的情况就必须撤销偏向锁,所以偏向锁的撤销操作的性能损耗必须小于节省下来的CAS原子指令的性能消耗)。偏向锁是在只有一个线程执行同步块时进一步提高性能。
轻量级锁:
在没有多线程竞争的前提下,通过CAS减少重量级锁使用操作系统互斥量产生的性能消耗。如果自旋能够获取到锁,则就是轻量级锁;如果自旋需要等待,自旋超过10次后,产生阻塞队列即升级为重量级锁。
“轻量级”是相对于使用操作系统互斥量来实现的传统锁而言的,减少传统的重量级锁使用操作系统互斥量产生的性能消耗。轻量级锁并不是用来代替重量级锁的,它的本意是在没有多线程竞争的前提下,减少传统的重量级锁使用产生的性能消耗。在解释轻量级锁的执行过程之前,轻量级锁所适应的场景是线程交替执行同步块的情况,为了在线程交替执行同步块时提高性能,如果存在同一时间访问同一锁的情况,就会导致轻量级锁膨胀为重量级锁。
轻量级锁是借助JVM虚拟机栈栈帧实现的。
重量级锁:
Synchronized是通过对象内部的一个叫做监视器锁(monitor)来实现的。但是监视器锁本质又是依赖于底层的操作系统的Mutex Lock来实现的。而操作系统实现线程之间的切换需要从用户态转换到核心态,这个成本非常高,状态之间的转换需要相对较长的时间,这就是为什么Synchronized效率低的原因。这种依赖于操作系统Mutex Lock所实现的锁我们称之为“重量级锁”。JDK中对Synchronized做的种种优化,其核心都是为了减少这种重量级锁的使用。JDK1.6以后,为了减少获得锁和释放锁所带来的性能消耗,提高性能,引入了“轻量级锁”和“偏向锁”。
锁优化:
- 减少锁持有时间:只在有线程安全要求的部分加锁
- 减小锁粒度:将大对象(这个对象可能会被很多线程访问),拆成小对象,增加并行度,降低锁竞争。降低了锁的竞争,偏向锁,轻量级锁成功率才会提高。
- 锁分离:例如读写锁,按功能分离锁,保证线程安全的同时提高性能
- 锁粗化:如果对同一个锁不停的进行请求、同步和释放,其本身也会消耗系统宝贵的资源,反而不利于性能的优化。在减少锁持有时间的同时,也要避免因此而产生的锁的频繁获取释放。
- 锁消除:编译器级别的操作。编译时,如果发现不可能被共享的对象,则可以消除这些对象的锁操作。
线程基本方法:
- wait(线程等待):调用该方法的线程进入WAITING状态,只有等待另外线程的通知或被中断才会返回,需要注意的是调用wait()方法后,会释放对象的锁。因此,wait方法一般用在同步方法或同步代码块中。
- sleep(线程睡眠):sleep导致当前线程休眠,与wait方法不同的是sleep不会释放当前占有的锁,sleep(long)会导致线程进入TIMED-WATING状态,而wait()方法会导致当前线程进入WATING状态。
- yield(线程让步):yield会使当前线程让出CPU执行时间片,与其他线程一起重新竞争CPU时间片。一般情况下,优先级高的线程有更大的可能性成功竞争得到CPU时间片,但不是绝对的,有的操作系统对线程优先级并不敏感。
- interrupt(线程中断):给这个线程一个通知信号,会影响这个线程内部的一个中断标识位。这个线程本身并不会因此而改变状态(如阻塞,终止等)。在线程的run方法内部可以根据thread.isInterrupted()的值来优雅的终止线程。
- join(等待其他线程终止):等待调用join方法的线程执行完成后,再继续向下执行。
- notify(线程唤醒):Object 类中的 notify()方法,唤醒在此对象监视器上等待的单个线程,如果所有线程都在此对象上等待,则会选择唤醒其中一个线程,选择是任意的,被唤醒的线程将以常规方式与在该对象上主动同步的其他所有线程进行竞争。类似的方法还有 notifyAll() ,唤醒再此监视器上等待的所有线程。
Thread类中的join方法的主要作用就是同步,它可以使得线程之间的并行执行变为串行执行。在当前线程执行另一个线程的join方法,例如在main方法中调用t1.join()表示main线程等待t1线程。
程序在main线程中调用t1线程的join方法,则main线程放弃cpu控制权,并返回t1线程继续执行直到线程t1执行完毕
所以结果是t1线程执行完后,才到主线程执行,相当于在main线程中同步t1线程,t1执行完了,main线程才有执行的机会
join方法中如果传入参数,则表示这样的意思:如果A线程中调用B线程的join(10),则表示A线程会等待B线程执行10毫秒,10毫秒过后,A、B线程并行执行。需要注意的是,jdk规定,join(0)的意思不是A线程等待B线程0秒,而是A线程等待B线程无限时间,直到B线程执行完毕,即join(0)等价于join()。join方法的原理就是调用相应线程的wait方法进行等待操作的。
上下文切换:
CPU寄存器(cpu内置的容量极小速度极快的内存)+程序计数器(存储cpu当前或下一条任务指令的位置)
上下文切换过程中的信息被保存在进程控制块PCB中。PCB又被称作切换帧。上下文切换信息会一直保存在CPU内存中,直到被再次使用。
切换过程:
1. 挂起一个进程,将这个进程在CPU中的状态(上下文)存储于内存中的某处。
2. 在内存中检索下一个进程的上下文并将其在 CPU 的寄存器中恢复。
3. 跳转到程序计数器所指向的位置(即跳转到进程被中断时的代码行),以恢复该进程在程序中的运行。
上下文切换原因:
1. 当前执行任务的时间片用完之后,系统CPU正常调度下一个任务;
2. 当前执行任务碰到IO阻塞,调度器将此任务挂起,继续下一任务;
3. 多个任务抢占锁资源,当前任务没有抢到锁资源,被调度器挂起,继续下一任务;
4. 用户代码挂起当前任务,让出CPU时间;
5. 硬件中断;
同步锁与死锁:
- 同步锁:保证线程同步互斥。并发执行的多个线程,在同一时间内只允许一个线程访问共享数据,如synchronized锁。
- 死锁:多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。
// 死锁产生的情况,两个线程执行类似结构的代码,并且a线程顺序依赖xy资源,b线程顺序依赖yx资源synchronized (resource2) {//代码...synchronized (resource1) {//代码...}}
阻塞队列:
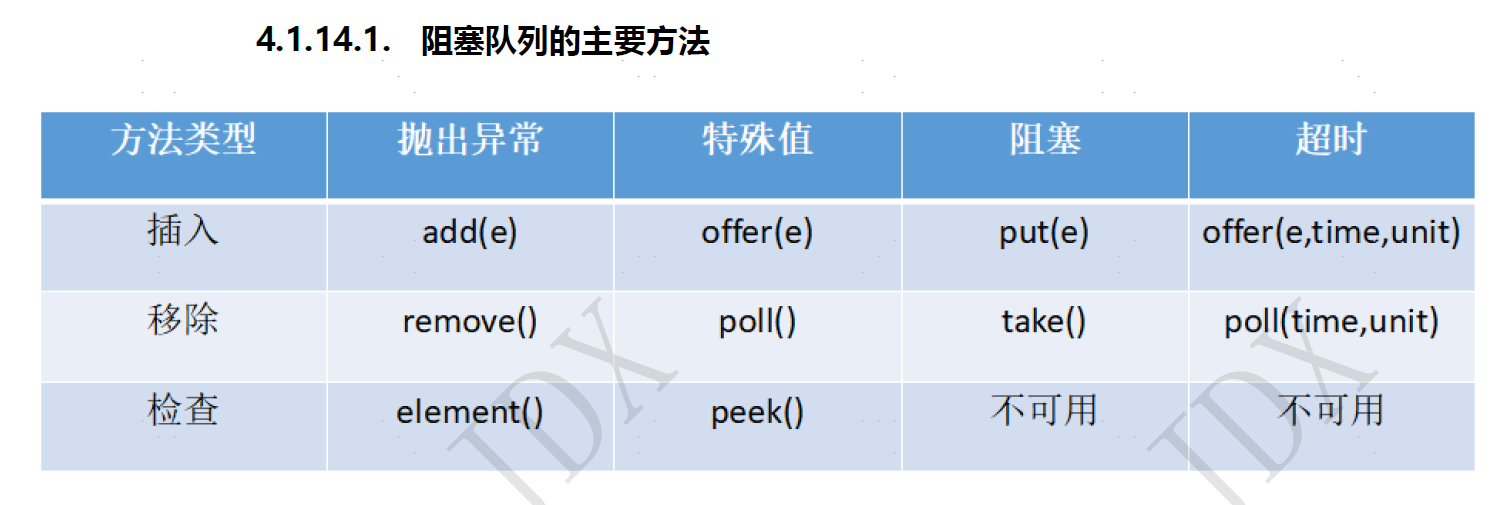
- ArrayBlockingQueue :由数组结构组成的有界阻塞队列,先入先出,使用同一个Retrantlock锁处理添加和取出,默认为不保证公平访问的队列,需要初始化大小。
- LinkedBlockingQueue :由链表结构组成的有界阻塞队列,先入先出,使用两个Retrantlock锁分别处理添加和取出,不用初始化大小。
- PriorityBlockingQueue :支持优先级排序的无界阻塞队列,默认使用元素升序排列,可使用自定义compareTo排序,或初始化时指定Comparator,不能保证同优先级的顺序。
- :支持延时获取元素的无界阻塞队列,使用PriorityQueue实现,可用来做缓存或定时任务。
- SynchronousQueue:不存储元素的阻塞队列,每个put必须等待一个take才可以继续添加。
- LinkedTransferQueue:由链表结构组成的无界阻塞队列,比LinkedBlockingQueue多了transfer和tryTransfer方法,可以直接将元素从生产者交给消费者。
- LinkedBlockingDeque:由链表结构组成的双向阻塞队列。
CyclicBarrier、CountDownLatch、Semaphore的用法:
- CountDownLatch:在Java.util.concurrent包下,继承了AQS,利用它可以实现类似计数器的功能。可以每个线程执行完成后countDown(),在等待线程await()处等待指定数量的线程执行完成后,唤醒继续执行。(不可重用)
await()方法源码还是AQS常见套路,基于getState判断当前锁不再被其他线程占用时结束。而countDown()方法也是基于AQS的state,每次执行将state减一,即将锁的持有数减一。
- CyclicBarrier:使用ReentrantLock实现,可以让一组线程等待至某个状态之后再全部同时执行。在每个线程await()时等待满足条件,再同时继续向下执行。(可重用: 即每次await对应了不同的屏障)
- Semaphore:可以控制同时访问的线程个数。在创建信号量时Semaphore,可以设置是否公平锁,信号量数量。在获取信号量后,需要释放后其他线程才能够获取并使用。信号量只对资源并发访问的线程数进行监控,并不保证线程安全。适用于流量控制、限制最大并发数的场景。
volatile:
Volatile关键字的作用主要有如下两个:
1.线程的可见性:当一个线程修改一个volatile变量时,另外一个线程能读到这个volatile变量修改后的值。即:当前线程将自己的本地内存数据更新至主内存中,然后将其他线程的本地内存中的该数据置为失效。
volatile不能保证原子性。如果是简单的读和直接赋值,原子性操作是可以的,但是类似i++这样的操作是非原子性的,是不能保证原子性的。
2.顺序一致性:禁止指令重排序。因为volatile关键字会在内存读写过程中插入内存屏障,禁止处理器进行重排序。编译器不会对volatile读与volatile读后面的任意内存操作重排序;编译器不会对volatile写与volatile写前面的任意内存操作重排序。
JMM
JMM可以理解为一个规范,并不是真实存在的。
JMM规定所有的变量都存储在主内存中,线程不能直接读写主内存。
java并发采用共享内存模型,即:
- 线程之间的共享变量存储在主内存中
- 每个线程都有一个私有的本地内存
本地内存中存储了该线程已读写的共享变量的副本
JMM围绕三个特征建立:原子性、可见性、有序性。是整个Java并发的基础。
原子性:指一个操作不可分割、不可中断,在执行时不会被其他线程干扰。
JMM只能保证最基础的原子性,如果需要保证代码块的原子性,需要使用Synchronized关键字。
可见性:一个线程公共变量的值被修改时,其他线程可以知道该变量被修改了。volatile、final、synchronized都可以实现可见性。final可见性:被final修饰的字段在构造其中一旦被初始化完成,并且构造器没有把this的引用传递出去,则其他线程能看见final字段的值。synchronized可见性:执行完解锁之前必须将共享变量同步到主内存中。
有序性:synchronized和volatile可以保证多线程间操作的有序性。volatile通过内存屏障禁止指令重排序保证有序性。synchronized相当于在多线程之间是串行执行的。
八种内存交互操作:
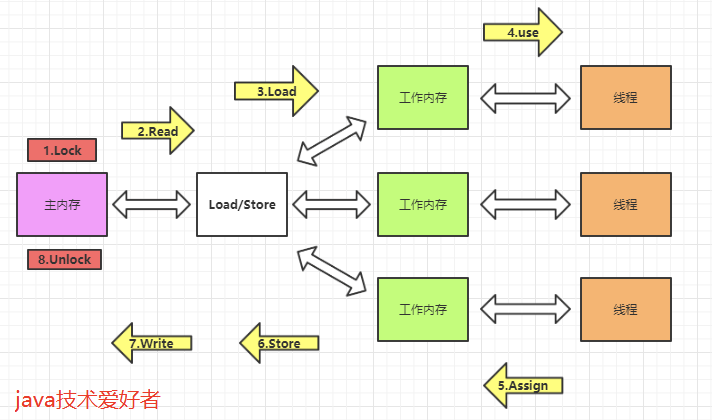
- lock(锁定),作用于主内存中的变量,把变量标识为线程独占的状态。
- read(读取),作用于主内存的变量,把变量的值从主内存传输到线程的工作内存中,以便下一步的load操作使用。
- load(加载),作用于工作内存的变量,把read操作主存的变量放入到工作内存的变量副本中。
- use(使用),作用于工作内存的变量,把工作内存中的变量传输到执行引擎,每当虚拟机遇到一个需要使用到变量的值的字节码指令时将会执行这个操作。
- assign(赋值),作用于工作内存的变量,它把一个从执行引擎中接受到的值赋值给工作内存的变量副本中,每当虚拟机遇到一个给变量赋值的字节码指令时将会执行这个操作。
- store(存储),作用于工作内存的变量,它把一个从工作内存中一个变量的值传送到主内存中,以便后续的write使用。
- write(写入):作用于主内存中的变量,它把store操作从工作内存中得到的变量的值放入主内存的变量中。
- unlock(解锁):作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
八种交互操作的规则:
- 不允许read、load、store、write操作之一单独出现,也就是read操作后必须load,store操作后必须write。
- 不允许线程丢弃他最近的assign操作,即工作内存中的变量数据改变了之后,必须告知主存。
- 不允许线程将没有assign的数据从工作内存同步到主内存。
- 一个新的变量必须在主内存中诞生,不允许工作内存直接使用一个未被初始化的变量。
- 一个变量同一时间只能有一个线程对其进行lock操作。多次lock之后,必须执行相同次数unlock才可以解锁。
- 如果对一个变量进行lock操作,会清空所有工作内存中此变量的值。在执行引擎使用这个变量前,必须重新load或assign操作初始化变量的值。
- 如果一个变量没有被lock,就不能对其进行unlock操作。也不能unlock一个被其他线程锁住的变量。
- 一个线程对一个变量进行unlock操作之前,必须先把此变量同步回主内存。
内存屏障:
- LoadLoad 屏障:对于这样的语句Load1,LoadLoad,Load2。在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
- StoreStore屏障:对于这样的语句Store1, StoreStore, Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
- LoadStore 屏障:对于这样的语句Load1, LoadStore,Store2,在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
- StoreLoad 屏障:对于这样的语句Store1, StoreLoad,Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。
threadLocal
线程局部变量
应用场景:当很多线程需要多次使用同一个对象,并且需要该对象具有相同初始化值的时候最适合使用ThreadLocal。
当我们调用get方法的时候,其实每个当前线程中都有一个ThreadLocal。每次获取或者设置都是对该ThreadLocal进行的操作,是与其他线程分开的。
从本质来讲,就是每个线程都维护了一个map,而这个map的key就是threadLocal,而value就是我们set的那个值,每次线程在get的时候,都从自己的变量中取值,既然从自己的变量中取值,那肯定就不存在线程安全问题,总体来讲,ThreadLocal这个变量的状态根本没有发生变化,他仅仅是充当一个key的角色,另外提供给每一个线程一个初始值。
24、SPRING
特征:轻量级、控制反转、面向切面、容器、框架集合

常用模块:
主要jar包:

常用注解:
两种注解策略:
类级别的注解:Spring容器根据注解的过滤规则扫描读取注解Bean定义类,并将其注册到Spring IoC容器中。
类内部的注解:SpringIoC容器通过Bean后置注解处理器解析Bean内部的注解。
第三方结合:
Spring和SpringBoot
springBoot是spring的扩展框架。
- springBoot可以创建独立的spring应用程序
- springBoot嵌入Tomcat、jetty等容器且不需要部署
- springBoot通过run方法创建了context
- context的onRefresh方法中启动了tomcat
- tomcat启动时将先前创建的springContext设置到tomcat中,然后开始sprintIOC过程
- springBoot提供"starters"POMs来简化Maven配置
- springBoot尽可能的自动配置spring应用
- springBoot简化打包部署应用程序的流程
IOC:
Spring 通过一个配置文件描述 Bean 及 Bean 之间的依赖关系,利用 Java 语言的反射功能实例化 Bean 并建立 Bean 之间的依赖关系。 Spring 的 IoC 容器在完成这些底层工作的基础上,还提供了 Bean 实例缓存、生命周期管理、 Bean 实例代理、事件发布、资源装载等高级服务。
Spring 启动时读取应用程序提供的Bean配置信息,并在Spring容器中生成一份相应的Bean配置注册表,然后根据这张注册表实例化Bean,装配好Bean之间的依赖关系,放入Bean缓存池,为上层应用提供准备就绪的运行环境。其中Bean缓存池为HashMap实现
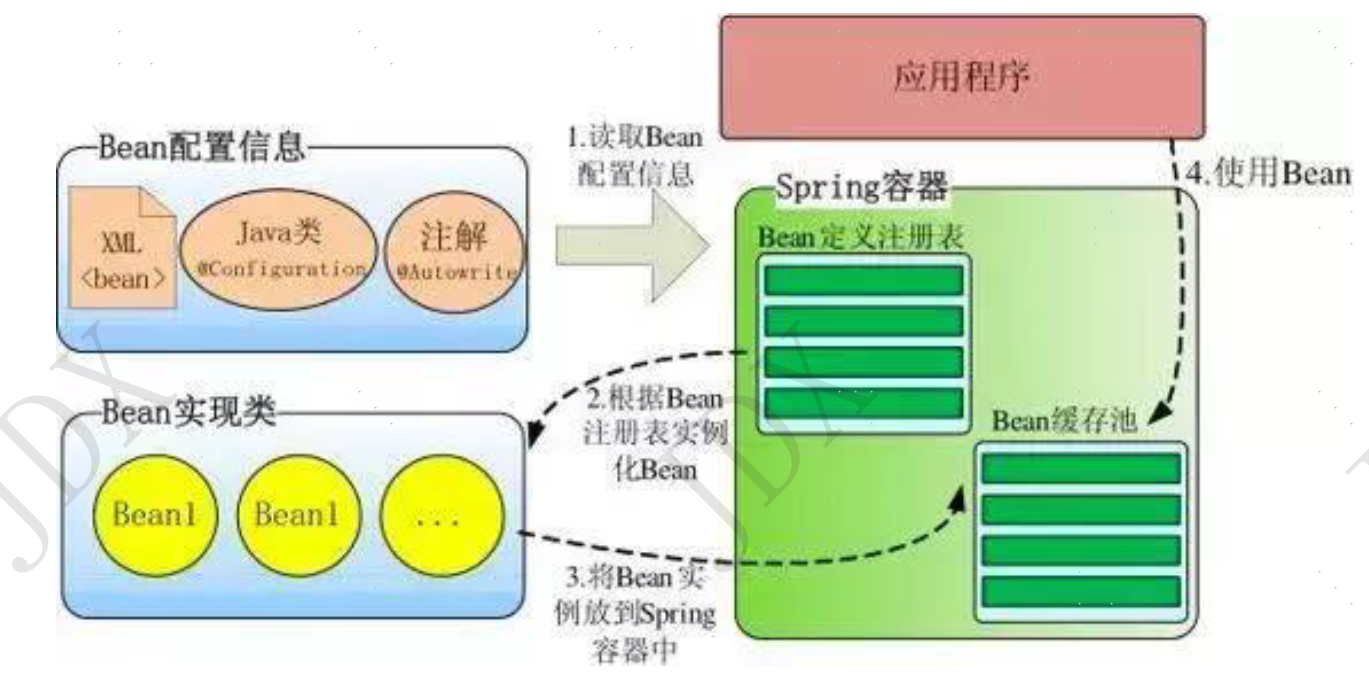
IOC好处:
资源集中管理,实现资源的可配置和易管理。
降低了使用资源双方的依赖程度(对象和业务代码),也就是我们说的耦合度。
Spring的IoC容器是一个高度可扩展的无侵入容器。是指应用程序的组件无需实现Spring的特定接口,组件根本不知道自己在Spring的容器中运行。这种无侵入的设计有以下好处:
应用程序组件既可以在Spring的IoC容器中运行,也可以自己编写代码自行组装配置;
测试的时候并不依赖Spring容器,可单独进行测试,大大提高了开发效率。
spring bean作用域:
1. singleton(默认):单例模式(多线程下不安全)。Spring IoC容器中只会存在一个共享的Bean实例,无论有多少个Bean引用它,始终指向同一对象。Singleton作用域是Spring中的缺省作用域,也可以显式的将Bean定义为singleton模式,配置为: <bean id="userDao" class="com.ioc.UserDaoImpl" scope="singleton"/>
单例模式下,避免使用成员变量,或者使用ThreadLocal,每个线程的成员变量放入ThreadLocal中保证线程安全
2. prototype:原型模式每次使用时创建。每次通过Spring容器获取prototype定义的bean时,容器都将创建一个新的Bean实例,每个Bean实例都有自己的属性和状态,而singleton全局只有一个对象。对有状态的bean使用prototype作用域,而对无状态的bean使用singleton作用域。
3. Request:一次request一个实例。request:在一次Http请求中,容器会返回该Bean的同一实例。而对不同的Http请求则会产生新的Bean,而且该bean仅在当前Http Request内有效,当前Http请求结束,该bean实例也将会被销毁。
4. session:在一次Http Session中,容器会返回该Bean的同一实例。而对不同的Session请求则会创建新的实例,该bean实例仅在当前Session内有效。同Http请求相同,每一次session请求创建新的实例,而不同的实例之间不共享属性,且实例仅在自己的session请求内有效,请求结束,则实例将被销毁。
5. global Session:在一个全局的Http Session中,容器会返回该Bean的同一个实例,仅在使用portlet context时有效。
spring bean生命周期:
1. 实例化:new操作
2. IOC依赖注入:按照Spring上下文对实例化的Bean进行配置,也就是IOC注入。
3. aware实现感知接口则可以获取bean在spring中相应的属性。
4. 相应的后置处理器可以在对应阶段对bean(初始化前后阶段)、factory进行扩展修改。
5. init-method:如果Bean在Spring配置文件中配置了init-method属性会自动调用其配置的初始化方法。
注:以上工作完成以后就可以应用这个Bean了,这个Bean是一个Singleton的,所以一般情况下我们调用同一个id的Bean会是在内存地址相同的实例,当然在Spring配置文件中也可以配置非Singleton。
class --> beanName --> beanDefinition --> beanFactory --> beanFactoryPostProcessor --> new(实例化) --> IoC(依赖注入) --> aware(回调,获取bean自身在spring中的相关属性) --> 初始化(初始化前后都可以使用后置处理器扩展修改bean) --> AOP(若需要) --> 单例池
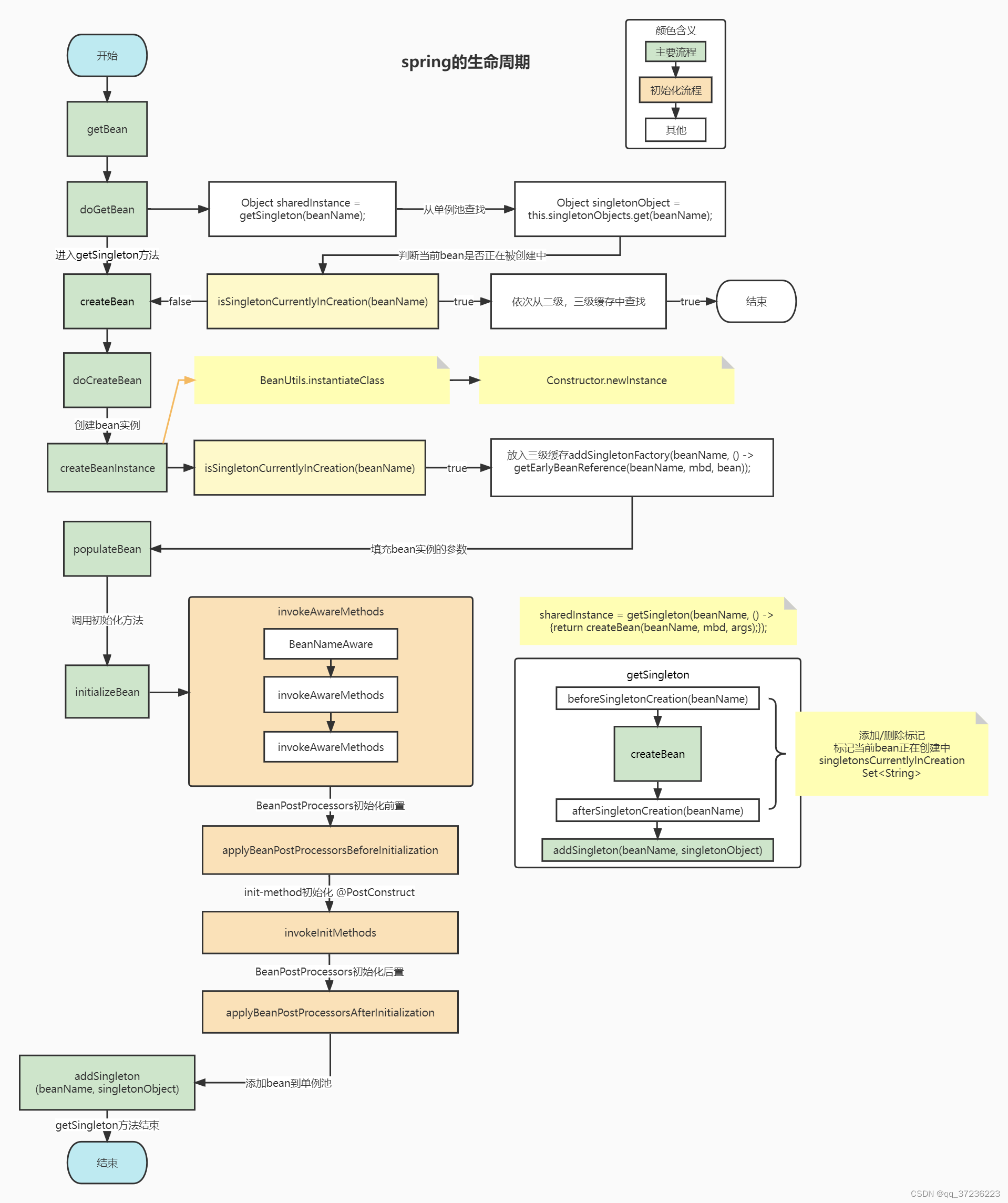
销毁:注册相关销毁回调接口,最后通过DisposableBean 和 destory-method 进行销毁。
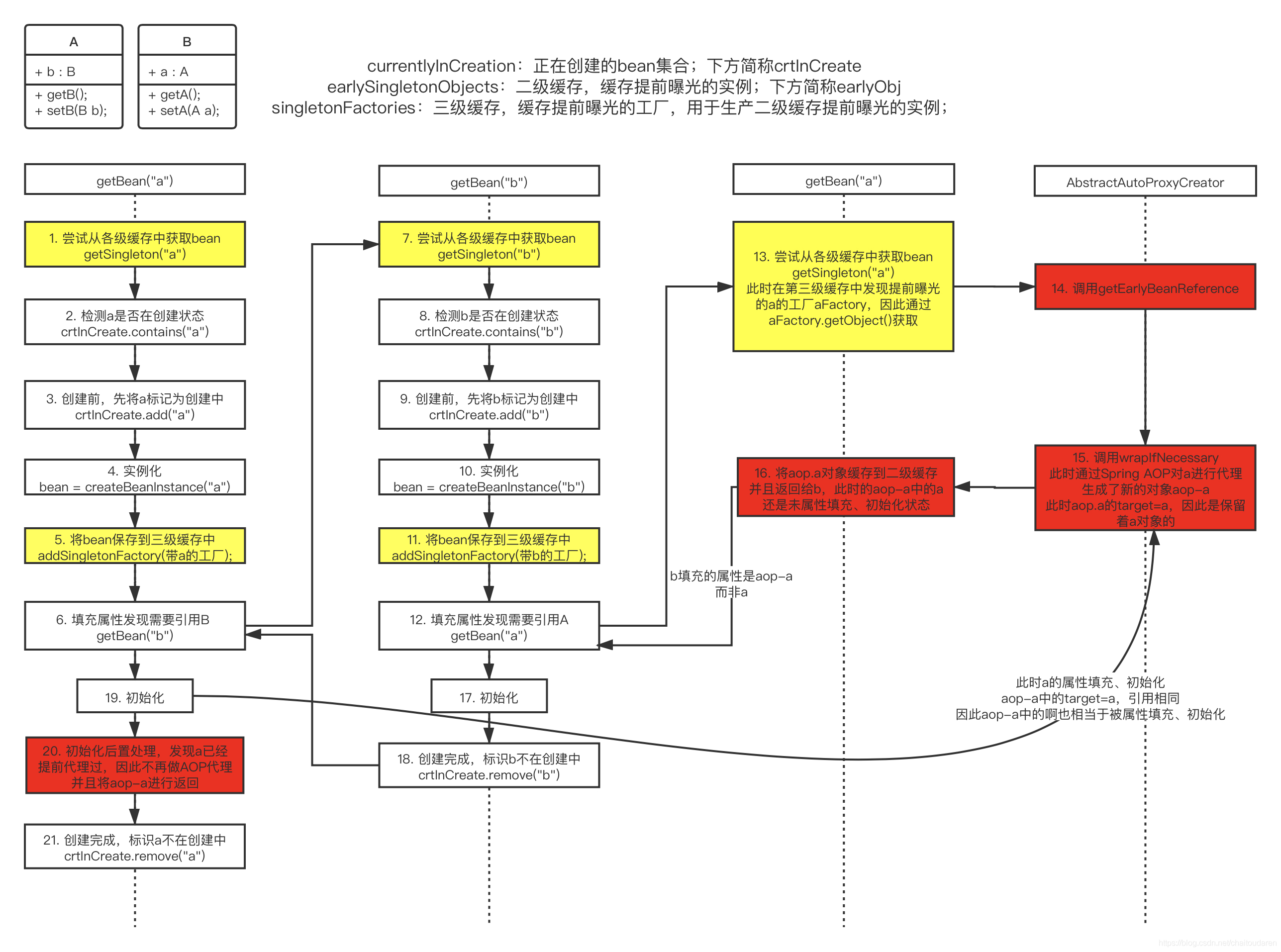
Spring-bean的循环依赖以及解决方式
(1)构造器的循环依赖
(2)field属性的循环依赖。
使用三级缓存解决:singletonObjects -> earlySingletonObjects -> singletonFactories
A的某个field或setter依赖B的实例对象,B的filed或setter依赖A的实例对象。在A实例化后,填充属性时,会实例化B,而B进行到填充属性时,会去获取A的实例,而A此时已经通过ObjectFactory曝光,因此可以被获取到,B完成初始化后,A也可以完成初始化,于是A和B会不断地重复获取对方的过程。
循环依赖:
普通对象AB互相依赖。
创建beanA的时候,如果允许暴露早期对象,则会放置原始对象的工厂到三级缓存。
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&isSingletonCurrentlyInCreation(beanName));if (earlySingletonExposure) {if (logger.isTraceEnabled()) {logger.trace("Eagerly caching bean '" + beanName +"' to allow for resolving potential circular references");}addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));}
接下来填充属性是发现需要另一个beanB,因此重复操作到填充属性处,再次发现需要beanA,于是使用最终到doGetBean获取对象。
依次从123级缓存中获取,由于三级缓存中存在,于是直接从三级缓存工厂中获取对象,并放入二级缓存,清除三级缓存。
最终可以完成两个对象的创建。
代理对象和普通对象互相依赖。
前面的过程类似,但是在三级缓存中的工厂方法中,会进行判断如果有InstantiationAwareBeanPostProcessors动态代理后置处理器存在,则进行早期对象的AOP处理。bean会放入一个earlyProxyReferences中用于在初始化后调用该后置处理器时判断是否进行动态代理过。并且在getObject的时候返回代理对象存入二级缓存。
此时beanB获取的是beanA的代理对象,但是a此时仍然是原始对象。beanA在填充完属性之后,发现需要进行AOP,会从earlyProxyReferences中进行判断是否已经进行过AOP,然后直接从二级缓存中读取AOP对象,最终返回存入一级缓存中。
Spring使用三级缓存解决循环依赖:
第一级缓存:单例池,存放已经经历了完整生命周期的bean对象;
第二级缓存:存放早期暴露出来的bean对象,实例化后就会放到这里(尚未填充属性);或在创建完成被引用的代理对象后,将其存储起来,避免重复创建代理对象;
第三级缓存:存放早期暴露的ObjectFactory,主要用于生成原始对象进行AOP之后的代理对象。如果没有出现循环依赖,这个工厂不会起作用,正常生命周期后将bean放入一级缓存;如果出现循环依赖,没有AOP的情况下,返回原始对象,有AOP的情况下返回代理对象。
使用顺序:一级缓存 --> 二级缓存 --> 三级缓存
为什么是三级缓存而不是二级缓存:
如果所有的对象不会被代理,则二级缓存就可以解决。
但实际很多对象都需要被代理,而代理的处理是在完成了初始化之后才会进行,如果按照这个顺序,注入的原始对象和最后返回的代理对象不是一个对象,不满足单例要求。
如果仅用二级缓存,需要将所有的代理处理步骤提前至实例化和初始化之间,这与spring的bean生命周期设计不符。
因此需要使用三级缓存来延迟代理,在需要代理的时候返回代理对象;不需要的时候返回原始对象,在后续正常进行代理。
Spring的@Import和@ImportResource注解
@Import 注解是用来导入配置类或者一些需要前置加载的类。
最简单给配置类添加Configuration注解和Import注解注入
@ImportResource 注解用于导入Spring 的配置文件。
是用注解在需要导入配置文件的类上定义配置文件路径即可
使用springboot打jar包后,除了会从jar包内的config(3)和根目录下(4)读取application.properties文件,还会从jar包放置的同级目录的config目录下(1)和根目录下(2)读取。优先级如1->2->3->4
25.封装类型和基本类型
1、从参数传递上来说,基本类型只能按值传递,而每个封装类都是按引用传递的;
2、从存储的位置上来说,基本类型是存储在栈中的,而所有的对象都是在堆上创建和存储的,所以基本类型的存取速度要快于在堆中的封装类型的实例对象;JDK5.0开始可以自动封包了,也就是基本数据可以自动封装成封装类,基本数据类型的好处就是速度快(不涉及到对象的构造和回收),封装类的目的主要是更好的处理数据之间的转换,方法很多,用起来也方便。
3、基本类型的优势是:数据存储相对简单,运算效率比较高;
4、封装类型的优势是:类型转换的api更好用了,比如Integer.parseInt(*)等的,每个封装类型都提供了parseXXX方法和toString方法。而且在集合当中,也只能使用封装类型。封装类型满足了Java中一切皆对象的原则。
26、AQS(AbstractQueuedSynchronizer)
AbstractQueuedSynchronizer提供了一个基于FIFO队列,可以用于构建锁或者其他相关同步装置的基础框架。该同步器(以下简称同步器)利用了一个int来表示状态,期望它能够成为实现大部分同步需求的基础。使用的方法是继承,子类通过继承同步器并需要实现它的方法来管理其状态,管理的方式就是通过类似acquire和release的方式来操纵状态, 该状态需要使用同步器提供的方法getState()、setState()、compareAndSetState()来修改。
AQS按照功能在使用中可以分为独占锁和共享锁。
常用的 Retrantlock、Semaphore、CountDownLatch、CyclicBarrier等并发类均是基于AQS实现。具体用法是通过继承AQS,并实现其模板方法,来达到同步状态的管理。
同步器是实现锁的关键,利用同步器将锁的语义实现,然后在锁的实现中聚合同步器。
同步器实现依赖于一个FIFO队列,那么队列中的元素Node就是保存着线程引用和线程状态的容器,每个线程对同步器的访问,都可以看做是队列中的一个节点。Node主要包含以下成员变量:
Node {// 表示节点的状态。其中包含的状态有:// CANCELLED,值为1,表示当前的线程被取消;// SIGNAL,值为-1,表示当前节点的后继节点包含的线程需要运行,也就是unpark;// CONDITION,值为-2,表示当前节点在等待condition,也就是在condition队列中;// PROPAGATE,值为-3,表示当前场景下后续的acquireShared能够得以执行;// 值为0,表示当前节点在sync队列中,等待着获取锁。int waitStatus;// 前驱节点,比如当前节点被取消,那就需要前驱节点和后继节点来完成连接。Node prev;// 后继节点。Node next;// 存储condition队列中的后继节点。Node nextWaiter;// 入队列时的当前线程Thread thread;}// 伪代码// 获取while(获取锁) {if (获取到) {退出while循环} else {if(当前线程没有入队列) {那么入队列}阻塞当前线程}}// 释放if (释放成功) {删除头结点激活原头结点的后继节点}
获取锁(acquire)的逻辑:
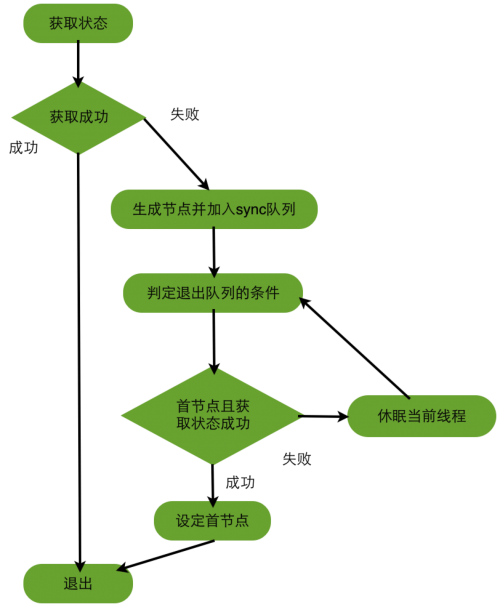
判定退出队列的条件,判定条件是否满足和休眠当前线程就是完成了自旋的过程
AQS维护了一个虚拟双向链表,即不存在队列实例。等待资源的线程信息会被保存为一个node加在CLH队列中。
27.数据库连接池选择
连接到数据库服务器需要经历几个漫长的过程:建立物理通道(例如套接字或命名管道),与服务器进行初次握手,分析连接字符串信息,由服务器对连接进行身份验证,运行检查以便在当前事务中登记等等。
连接池存放了一定数量的与数据库服务器的物理连接。因此,当我们需要连接数据库服务器的时候,只需去池(容器)中取出一条空闲的连接,而不是新建一条连接。这样的话,我们就可以大大减少连接数据库的开销,从而提高了应用程序的性能。
第一、连接池的建立。
一般在系统初始化时,连接池会根据系统配置建立,并在池中创建了几个连接对象,以便使用时能从连接池中获取。连接池中的连接不能随意创建和关闭,这样避免了连接随意建立和关闭造成的系统开销。
Java中提供了很多容器类可以方便的构建连接池,例如Vector、Stack等。
第二、连接池的管理。
连接池管理策略是连接池机制的核心,连接池内连接的分配和释放对系统的性能有很大的影响。其管理策略是:
当客户请求数据库连接时,
1)如果池中有空闲连接可用,返回该连接。
2)如果没有空闲连接,池中连接都已用完,创建一个新连接添加到池中。
3)如果池中连接已达到最大连接数,请求按设定的最大等待时间进入等待队列直到有空闲连接可用。
4)如果超出最大等待时间,则抛出异常给客户。
当客户释放数据库连接时,先判断该连接的引用次数是否超过了规定值,如果超过就从连接池中删除该连接,否则保留为其他客户服务。
该策略保证了数据库连接的有效复用,避免频繁的建立、释放连接所带来的系统资源开销。
如果连接长时间空闲,或检测到与服务器的连接已断开,连接池管理器也会将该连接从池中移除。
第三、连接池的关闭。
当应用程序退出时,关闭连接池中所有的连接,释放连接池相关的资源,该过程正好与创建相反。
Druid
28.kafka
kafka的特点:
高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作。
可扩展性:kafka集群支持热扩展
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
高并发:支持数千个客户端同时读写
常用场景:
日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、HBase、Solr等。
消息系统:解耦和生产者和消费者、缓存消息等。
用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
流式处理:比如spark streaming和 Flink
kafka架构:
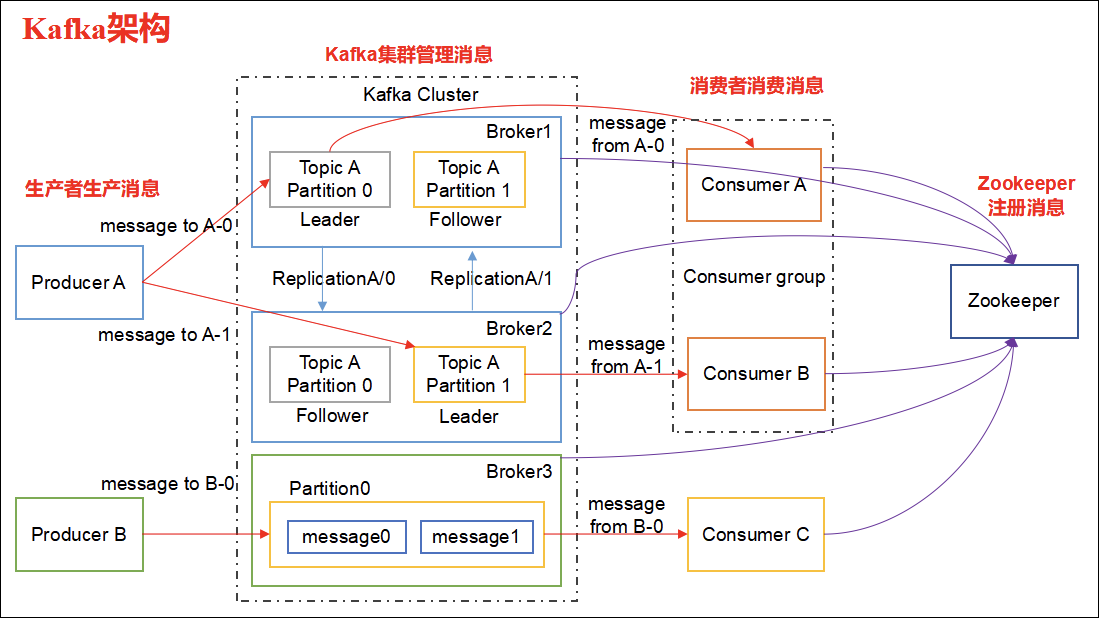
每台服务器就是一个broker;每个broker上可以存在多个topic;每个topic可以分为多个partition存在于多个broker上,每个partition是一个有序队列。进行分区是为了实现负载均衡、提高并发度和效率。每个partition在写入时是有序的,单独每个partition也只能有一个消费者消费,可以保证消息的有序性。
每个partition对应多个log文件,log文件存储的是producer生产的数据。producer生产的数据会不断被追加到该log文件末端,每条数据都有自己的offset,消费组中的每个消费者都会记录自己消费到了哪个offset,便于出错恢复继续消费。
消费组保证了:
一个分区只能被消费组中的一个消费者消费;
一个消费组中的消费者可以消费多个分区;
一个消费组中的消费者消费的分区一定不会重复;
不同消费组可以消费相同的全部分区。
kafka采用了分段和索引机制解决查找效率的问题:将一个partition分为多个segment,每个segment对应一个log文件、index文件和timeindex文件。
log文件:每个log文件大小相同,但由于message内容大小不一定相同,因此条数也不同。log文件命名使用segment中最小的offset命名。log中的message包括三个部分:offset用来唯一确定每条消息在partition中的位置;消息大小:描述消息的大小;消息体:存储被压缩过的消息内容。kafka中的旧文件有两种删除方式:基于时间删除,默认七天;基于segment大小删除,默认1G,超过部分将被删除。
index文件:用来建立消息偏移量到物理地址之间的映射关系,方便快速定位消息所在的物理文件位置。
timeindex文件:根据指定时间戳来查找对应偏移量信息。然后在通过对应偏移量定位文件位置。
kafka的索引文件是以稀疏索引方式构造的索引,不保证每个记录都在索引中存在,而是每当写入一定大小的量的消息后,在index文件和timeindex中增加一个索引项。由于都保持递增,在查询时会使用二分法来查找到指定的偏移量或者是小于目标偏移量的最大偏移量。
数据可靠性:
分区多副本:kafka使用分区存放副本的方式来保证数据的可靠性,一个topic分区为多个partition存在于多个broker时,每个partition会存在一个leader和多个follower,读写都通过leader进行,并且follower会定期与leader同步数据,当leader异常,会重新选举follower作为leader。
消息生产:三种消息确认机制。1、acks=0,producer将消息通过网络发送出去后就进行确认。速度快,但是会丢失消息。2、acks=1,leader收到消息并写入分区数据文件后确认。发送消息时如果发生leader选举,还是有可能丢失消息。如消息已经在发送到原leader的路上,topic选举另一个节点为leader了,若没有定义重新发送机制,这条消息会发生丢失。3、acks=-1,在所有follwer都收到消息后,leader才会确认。速度最慢。
leader选举:
ISR:In-Sync Replicas 副本同步队列
OSR:Out-of-Sync Replicas
AR:Assigned Replicas 所有副本
ISR是由leader维护,follower从leader同步数据有一些延迟,超过相应的阈值会把 follower 剔除出 ISR, 存入OSR(Out-of-Sync Replicas )列表,新加入的follower也会先存放在OSR中。AR=ISR+OSR。
leader选举的核心是ISR列表,每个分区的leader都会维护一个ISR列表,其中是follower的编号,只有数据与leader一致的follower才会在这个列表中。
Controller leader
当broker启动的时候,都会创建KafkaController对象,但是集群中只能有一个leader对外提供服务,这些每个节点上的KafkaController会在指定的zookeeper路径下创建临时节点,只有第一个成功创建的节点的KafkaController才可以成为leader,其余的都是follower。当leader故障后,所有的follower会收到通知,再次竞争在该路径下创建节点从而选举新的leader。
Partition leader
从分区的ISR列表中根据算法选择出分区的leader。
在ISR中至少有一个follower时,Kafka可以确保已经commit的数据不丢失,但如果某个Partition的所有Replica都宕机了,就无法保证数据不丢失了。这种情况下有两种可行的方案:
等待ISR中的任一个Replica“活”过来,并且选它作为Leader (等待时间久,可用性差)
选择第一个“活”过来的Replica(不一定是ISR中的)作为Leader (等待时间短,但一致性差)默认该选项
LEO:是 LogEndOffset 的简称,代表当前日志文件中下一条
HW:水位或水印(watermark)一词,也可称为高水位(high watermark),通常被用在流式处理领域(比如Apache Flink、Apache Spark等),以表征元素或事件在基于时间层面上的进度。在Kafka中,水位的概念反而与时间无关,而是与位置信息相关。严格来说,它表示的就是位置信息,即位移(offset)。取 partition 对应的 ISR中 最小的 LEO 作为 HW,consumer 最多只能消费到 HW 所在的位置上一条信息。
LSO:是 LastStableOffset 的简称,对未完成的事务而言,LSO 的值等于事务中第一条消息的位置(firstUnstableOffset),对已完成的事务而言,它的值同 HW 相同
LW:Low Watermark 低水位, 代表 AR 集合中最小的 logStartOffset 值。
生产者产生消息:
生产者直接将消息发送至topic。
默认分区器:
可以在发送时指定写入某个partition
没有指明partition但是有key的情况下可以根据key的hash值与topic的partition个数进行取余得到对应的目标partition
没有partition指定也没有key的情况下会随机选取一个partition直到该partition的batch已满或已完成,再随机选择一个不同的分区使用
保证数据不丢失:
producer端保证数据一定被发送至broker:
- 使用同步发送方式
- 添加异步回调函数,失败重试
- 使用producer本身提供的重试机制
broker端保证数据持久化:
依赖acks机制控制。根据是否写入硬盘判断。
consumer端:
可以通过修改offset来重新消费
consumer消费速度小于producer生产速度:
会产生消息堆积。
解决方案:
增加partition数量,提高consumer并行能力,加快消费速度;
对于每个partition的consumer方,增加消费任务队列配合线程池,加快消费速度;
避免出现因为任务处理时间过长导致的心跳检测失败,产生partition重新分配consumer重新消费。
数据传输的事务定义通常有以下三种级别:
最多一次:消息不会被重复发送,最多被传输一次,但也有可能一次不传输
最少一次:消息不会被漏发送,最少被传输一次,但也有可能被重复传输
精确的一次(Exactly once):不会漏传输也不会重复传输,每个消息都传输被接收
kafka可以支持consumer获取指定offset的数据。consumer有offset的控制权就可以重新消费历史的数据了。
kafka将数据push到broker,再由consumer从broker拉取数据。对于pull模式,为了避免consumer不断请求没有数据的broker,kafka可以设置阻塞consumer消费直至有新消息产生。
kafka文件存储特点:
1)Kafka把topic中一个parition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用。
2)通过索引信息可以快速定位message和确定response的最大大小。
3)通过index元数据全部映射到memory,可以避免segment file的IO磁盘操作。
4)通过索引文件稀疏存储,可以大幅降低index文件元数据占用空间大小。
5) kafka创建topic时,副本数不能超过broker数,第一个副本放置位置是随机从brokerList中选择的,后续的副本会从broker编号顺序向下放置。
6) kafka创建新分区时,会优先在分区文件夹总数最少得文件目录下创建。
rebalance:
当消费组消费者数量发生变化或topic的parition数量发生变化时,就需要重新分配消费者和partition的对应关系。需要通过coordinator(topic所在的负载最小的borker)分配消费组中的leader,并由leader确定新的消费分配方案,再返回给coordinator,coordinator接收到方案后再发送给全部consumer。
分区分配策略:
在 Kafka 内部存在两种默认的分区分配策略:Range 和 RoundRobin。当以下事件发生时,Kafka 将会进行一次分区分配:
1)同一个 Consumer Group 内新增消费者
2)消费者离开当前所属的Consumer Group,包括shuts down 或 crashes
3)订阅的主题新增分区
Range strategy
Range策略是对每个主题而言的,首先对同一个主题里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。然后将partitions的个数除以消费者线程的总数来决定每个消费者线程消费几个分区。如果除不尽,那么前面几个消费者线程将会多消费一个分区。
RoundRobin strategy
使用RoundRobin策略有两个前提条件必须满足:
同一个Consumer Group里面的所有消费者的num.streams必须相等;
每个消费者订阅的主题必须相同。
将所有主题的分区组成 TopicAndPartition 列表,然后对 TopicAndPartition 列表按照 hashCode 进行排序,再进行分配。
kafka高吞吐原理:
Kafka是分布式消息系统,需要处理海量的消息,Kafka的设计是把所有的消息都写入速度低容量大的硬盘,以此来换取更强的存储能力,但实际上,使用硬盘并没有带来过多的性能损失。kafka主要使用了以下几个方式实现了超高的吞吐率:
1)顺序读写 主要是顺序写,避免随机写的多次io,读操作可以通过索引快速查找
2)零拷贝 减少了从内核空间读取到用户空间、从用户空间再到内核空间的两次拷贝。减少了cpu上下文切换,提高了效率。
3)文件分段 kafka文件都是顺序存写,分为多个文件后可以使用简单的二分查找快速索引到指定的位置。
4)批量发送 kafka会把产生到一定数据量的消息一次批量发送至broker中,减少网络开销。
5)数据压缩 数据压缩后发送,减少网络传输开销,加快传输速度。
Kafka 缺点
1)由于是批量发送,数据并非真正的实时;
2)对于mqtt协议不支持;
3)不支持物联网传感数据直接接入;
4)仅支持统一分区内消息有序,无法实现全局消息有序;
5)监控不完善,需要安装插件;
6)依赖zookeeper进行元数据管理。
7) 分区数只可以增加不可以减少。
kafka保证数据不重复:
在生产者端,需要保证服务器的每个节点都完成数据确认,即ack=-1。另外还需要结合kafka幂等性来对消息进行去重。
在消费者端,可能产生数据重复的情况是先消费后提交offset。多线程场景下,实际获取了消息但是没提交,同时其他线程也可能消费同一条数据;单线程场景下,异步提交方式失败后没有自动重试机制,导致被重复消费。
兜底方案是在业务操作或者落库时进行去重。
kafka幂等性
发送一条消息时,数据在broker上只会持久化一次,数据不丢不重复。但只保证单个会话中的幂等;只保证单个partition中的幂等。需要跨会话跨partition的幂等,需要kafka事务性实现。
kafka幂等通过producer启动时分配的pid和每个partition发送消息时的sequenceNumber配合实现消息的幂等。
- broker验证发送消息batch的sequence number,不连续则直接返回异常
- producer重试时,batch会根据sequenceNumber放置在合适的位置。send线程会从最旧的需要重试的batch开始,保证有序性。
kafka事务性
kafka事务弥补了幂等没有做到的事,即生产者对多个partition写入时的幂等以及会话事务的恢复。kafka事务保证了写入操作的原子性。
为了支持事务性,kafka引入了transactionCoordinator,主要负责分配pid,记录事务状态等操作。而kafka实现事务性的主要原理还是类似分布式事务的方式,所有事务都可以执行才真正提交,否则撤回。
29.redis
redis的特点有高性能(线程模型、网络IO模型、数据结构、持久化机制)、高可用(主从复制、哨兵集群)、高拓展(Cluster分片集群)。
官方数据中redis可以达到单机10w的qps,连接数越多qps越低。
redis性能高的原因主要有:
redis基于内存操作,需要的时候可以手动持久化到硬盘中。
redis的高效数据结构,哈希结构。即使string类型,redis底层会先尝试转换为int类型,如果可以则底层存储为int型,否则为emdstr类型。
redis是单线程模型,避免了线程切换的性能开销。(Redis 的单线程指的是 Redis 的网络 IO 以及键值对指令读写是由一个线程来执行的。 对于 Redis 的持久化、集群数据同步、异步删除等都是其他线程执行。)
redis使用多路复用IO模型,非阻塞IO。

redis核心存储结构:
redis是一个kv的内存型数据库。reidsDb中的dict字典保存了数据库中的全部键值对,这个字典也被称为键空间。key都是字符串类型,value支持多种类型的对象。
redis基本数据结构:
简单动态字符串、链表、字典、跳跃表、整数集合、压缩列表。
简单动态字符串:最基本类型,最大可存储512M。二进制安全,可以存储图片、数字、序列化对象等。redis自行实现了一套字符串,叫做简单动态字符串(Simple Dynamic String),简称SDS。
SDS是一个字符串数组对象,除了字符串数组,还包含了字符串数组已使用长度和未使用长度,可以直接返回字符串长度。
扩容时如果修改后的长度大小于1MB,则会额外分配和len一样长度的free空间;若扩容时修改后的长度大小大于1MB,则会额外分配1MB的free空间。相比原生C字符串,redis字符串每次追加前都会检查并开辟空间,避免出现缓冲区溢出的情况。
对sds进行裁剪操作时,sds并不会直接释放掉被裁剪的空间,而是记录在free中,为未来可能出现的扩容操作留出空间。并且sds也提供了释放未使用空间的API。
常用命令:incr/incrby可以使用redis的自增命令为分库分表的数据库获取不重复的自增ID(但存在资源浪费,可以在获取的时候拿一批ID);mset/mget批量操作;setnx,不存在则创建,否则返回0。
链表:
redis的链表结构核心是双端无环链表,但是额外定义了一个list数据结构,其中包含了链表头尾节点、链表长度和复制、释放、比较的方法。
字典:
redis中的字典包含type、privdata、哈希表ht、rehash索引。
哈希表ht结构包含hashtable、哈希表大小、hash表sizemask(总是等于size-1)、已有节点数量used。
其中hashtable的每个节点hashEntry都保存了一个键值对、以及一个指向下个节点的指针(存在冲突时,否则为null)。
当哈希表ht的负载因子大于等于1(未进行bgsave或bgrewriteaof)或大于等于5(进行bgsave或bgrewriteaof,因为执行该操作时子进程会进行写时复制操作,如果不增加负载因子阈值可能会进行扩展操作)时会进行扩容,当负载因子小于0.1时会进行缩容。
跳跃表(skiplist):
是一种有序数据结构,通过在每个节点维持多个指向其他节点的指针达到快速访问的目的。redis只在两个地方使用了跳跃表:实现有序集合键、在集群节点中用作内部数据结构。
redis中的跳表实现是基于两种结构。zskiplistNode和zskiplist。
zskiplist包含了跳表的头尾结点、跳表层数、跳表长度
zskiplistNode中包含了层(每个层还包含了下一个节点的指针和跨度)、后退指针、分值、成员对象(是一个字符串对象,SDS)。
redis在创建跳表新节点时都会随机生成一个1-32之间的数作为节点的层数。
整数集合:(intset)
整数集合是集合键的底层实现之一,当一个集合只包含整数值元素,且集合元素数量不多时,redis会选择使用整数集合作为集合建的底层实现。
整数集合是redis用于保存整数值的几何抽象数据结构。一个整数集合包含编码方式encoding、元素数量length、数组contents。每个元素都是数组的一个数组项,且按值的大小从小到大有序排列。
整数集合的升级:首先根据新元素类型,扩展底层数组的空间大小,并为新元素分配空间;然后将底层数组已有元素转换成与新元素相同的类型,并放置到正确位置;最后将新元素添加到底层数组中。
整数集合不支持降级。
压缩列表:(ziplist)
压缩列表是列表键和哈希键的底层实现之一。当一个列表键或哈希键只包含少量列表项,并且每个列表项或键值对要么是最小整数值,要么就是长度比较短的字符串,redis就会使用压缩列表来作为底层实现。
压缩列表是redis为了节省内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型数据结构。一个压缩列表可以包括任意多个节点,每个节点可以保存一个字节数组或一个整数值。
压缩列表中包括zlbytes节点(记录压缩列表的内存字节数)、zltail(记录压缩列表尾节点距离起始位置的距离)、zllen(记录压缩列表节点数)、zlentryx(压缩列表的数据节点)、zlend(标记压缩列表的结束)。
每个数据节点中有三部分:previous_entry_length(可以通过该属性快速定位前一节点的内存地址)、encoding(保存数据类型和长度)、content(节点值,可以为字节数组或者整数)。
对压缩列表进行插入和删除可能引发连锁更新,即因为previ_entry_length字段长度变化而导致整个节点长度变化重新分配内存,若因此影响到下一个节点也发生相似变化,则发生了连锁更新。
redis对象类型:
reids对象使用了基于引用计数的内存回收机制,以及对象共享机制。每个键值对都分别是独立的对象,每个redisObject包含了type(对象类型)、encoding(对象对应的底层数据结构)、ptr(指向底层实现数据结构的指针)。
五种基础对象:字符串对象、列表对象、哈希对象、集合对象、有序集合对象。
字符串对象:如果保存的是long型,则保存为int;如果保存的长度大于39字节,则保存为raw,即使用一个SDS;如果保存的长度小于等于39字节,则保存为embstr,即用于保存短字符串的优化编码,相比raw给redisObject和sds分配两次内存空间,embstr只调用一次给两个对象分配连续的内存空间;而且embstr是只读对象,被修改后总会变为raw对象。
字符串对象是唯一一个会被其他对象嵌套的对象。
列表对象:可以是ziplist或linkedlist。当列表对象保存的所有字符串元素长度都小于64字节,且列表对象保存的元素数量小于512个时会使用ziplist,否则使用linkedlist。
哈希对象:可以是ziplist或hashtable。当哈希对象保存的所有键值对的字符串元素长度都小于64字节,且哈希对象保存的键值对数量小于512个时会使用ziplist,否则使用hashtable。
集合对象:可以是intset或hashtable。当集合对象都是整数值、且集合对象保存的对象数量不超过512个时使用intset,否则hashtable。
有序集合对象:ziplist或skiplist。有序集合保存的元素数量少于128个、且保存的所有元素的长度都小于64字节时使用ziplist,否则skiplist。有序集合的skiplist编码是用zset数据结构,即是skiplist+dict的方式(保证了O(1)的成员分值查询以及跳表的有序存储带来的范围操作性能)。
redis数据库
redis服务器会默认创建16个数据库,redisDb数组保存了所有的数据库,用户可以通过SELECT命令显示的选择数据库。redis对数据库进行修改后,可以根据订阅配置向客户端发送数据库通知,告知数据库发生的操作。
redis的get命令是阻塞的,client的一个请求对应了redisserver的一个相应,查询一批数据会有比较高的时间消耗。因此可以使用pipeline来实现批量读取。pipeline相当于将一批请求包装在一起发送给redisserver,然后redis将每个请求的执行结果一起返回给client,并且pipeline是非事务的,即如果一批请求中存在报错,后续命令也会继续执行。
缓存雪崩、缓存穿透、缓存击穿
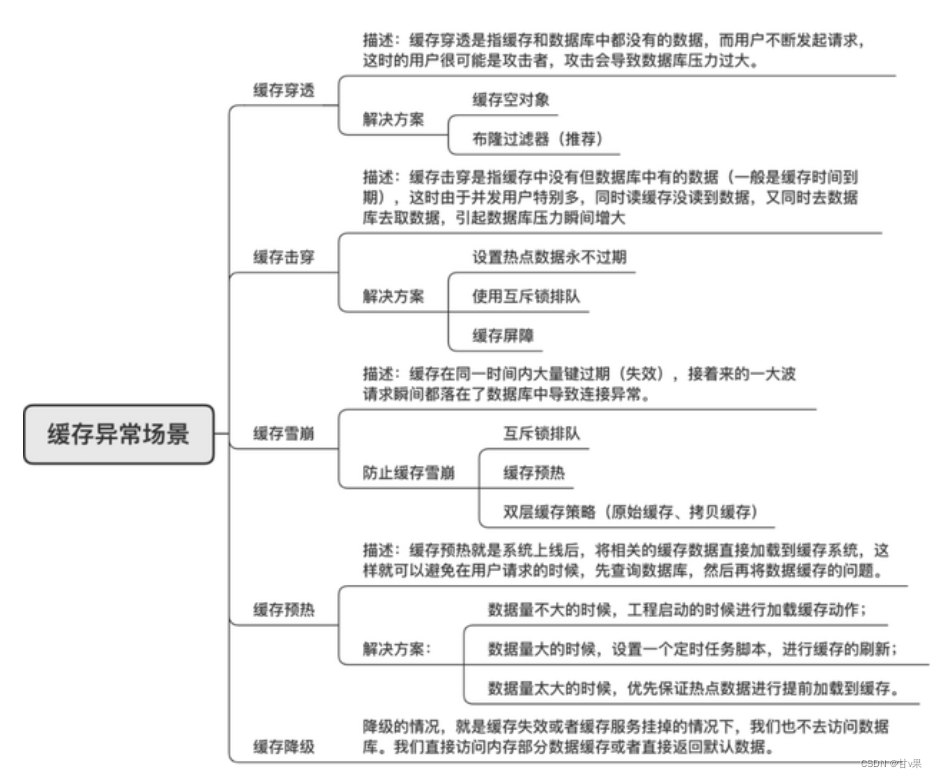
雪崩:缓存大面积同时失效,导致大量请求落到数据库上,数据库压力过大崩溃。
解决方案:随机设置缓存过期时间;维护缓存标记,数据过期则更新;缓存预热,启动前预加载热点数据;互斥锁机制,避免相同请求以及过量请求。
穿透:缓存中和数据库中都没有的数据,导致请求落到数据库上,导致数据库压力过大崩溃。
解决方案:接口校验,拦截无效请求;对不存在的数据,设置为null值缓存,使用较短的缓存时间,避免短时间内大量重复请求;布隆过滤器,将所有可能存在的数据hash到一个足够大的bitmap中,一定不存在的数据会被直接拦截。
击穿:缓存中没有数据库中有的数据,但由于并发高,导致大量请求同时落到数据库,数据库压力过大崩溃。
解决方案:设置热点数据不过期,定期更新;互斥锁机制,避免相同过量请求。
过期策略:
过期相关命令:
EXPIRE(PEXPIRE)设置还有多久过期、EXPIREAT(PEXPIREAT是其他三个命令的基础)设置具体过期时间点、TTL(PTTL)查询还有多久过期。---P代表毫秒。
过期字典保存了每个键空间的键的过期时间,每个键是一个指向对应键空间键的指针,值是对应键空间键的过期时间。
PERSIST移除过期时间,即删除了过期字典中对应的键。
定时删除:是内存友好型策略,使用定时器,检查过期字典,删除过期的键并释放其内存。但对CPU不友好,CPU消耗巨大,但可以保证key的及时下线。
定期删除:每隔一段时间执行一次删除过期键的操作,并且限制执行时间和频率降低对CPU的影响。
惰性删除:CPU友好型策略,在访问key时,redis对key的过期时间进行检查,如果过期了就立即删除。内存消耗大。
redis使用定期删除和惰性删除组合,使用定期删除策略持续清理内存中的过期key,再使用惰性删除保证尚未被清除的过期key不会被读取出去。
默认会每秒进行十次过期扫描(100ms一次),过期扫描不会遍历过期字典中所有的 key,而是采用了一种简单的贪心策略。
1.从过期字典中随机 20 个 key;
2.删除这 20 个 key 中已经过期的 key;
3.如果过期的 key 比率超过 1/4,那就重复步骤 1;
redis默认是每隔 100ms就随机抽取一些设置了过期时间的key,检查其是否过期,如果过期就删除。会产生已经超过超时时间的key没有被删除并且被使用的情况。
淘汰策略;
不管是定期采样删除还是惰性删除都不是一种完全精准的删除,还是会存在key没有被删除掉的场景,所以需要内存淘汰策略进行补充。
1. noeviction:当内存使用超过配置的时候会返回错误,不会驱逐任何键
2. allkeys-lru:加入键的时候,如果过限,首先通过LRU算法驱逐最久没有使用的键
3. volatile-lru:加入键的时候如果过限,首先从设置了过期时间的键集合中驱逐最久没有使用的键
4. allkeys-random:加入键的时候如果过限,从所有key随机删除
5. volatile-random:加入键的时候如果过限,从过期键的集合中随机驱逐
6. volatile-ttl:从配置了过期时间的键中驱逐马上就要过期的键
7. volatile-lfu:从所有配置了过期时间的键中驱逐使用频率最少的键
8. allkeys-lfu:从所有键中驱逐使用频率最少的键
LRU:
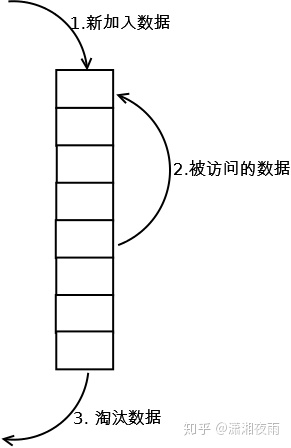
可以使用链表和map实现。链表中记录key,map中存储键值对。
1. 新增key value的时候首先在链表结尾添加Node节点,如果超过LRU设置的阈值就淘汰队头的节点并删除掉HashMap中对应的节点。
2. 修改key对应的值的时候先修改对应的Node中的值,然后把Node节点移动队尾。
3. 访问key对应的值的时候把访问的Node节点移动到队尾即可。
Redis中的LRU与常规的LRU实现并不相同,常规LRU会准确的淘汰掉队头的元素,但是Redis的LRU并不维护队列,只是根据配置的策略要么从所有的key中随机选择N个(N可以配置)要么从所有的设置了过期时间的key中选出N个键,然后再从这N个键中选出最久没有使用的一个key进行淘汰。(通过维护的全局时钟和每个key的时钟确定最久的那个,时钟是24位)
Redis这样的做法主要因为:
1、性能问题,由于近似LRU算法只是最多随机采样N个key并对其进行排序,如果精准需要对所有key进行排序,这样近似LRU性能更高
2、内存占用问题,redis对内存要求很高,会尽量降低内存使用率,如果是抽样排序可以有效降低内存的占用
3、实际效果基本相等,如果请求符合长尾法则,那么真实LRU与Redis LRU之间表现基本无差异
4、在近似情况下提供可自配置的取样率来提升精准度,例如通过 CONFIG SET maxmemory-samples 指令可以设置取样数,取样数越高越精准,如果你的CPU和内存有足够,可以提高取样数看命中率来探测最佳的采样比例。
LFU:
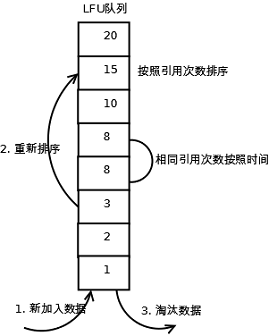
使用TreeNode、map和自定义的节点元素实现,用TreeNode保证节点有序,节点元素中包含频次属性。
只是简单的增加计数器的方法并不完美。访问模式是会频繁变化的,一段时间内频繁访问的key一段时间之后可能会很少被访问到,只增加计数器并不能体现这种趋势。可以记录key最后一个被访问的时间,然后随着时间推移,降低计数器。
分布式锁
分布式锁,即分布式系统中的锁。在单体应用中我们通过锁解决的是控制共享资源访问的问题,而分布式锁,就是解决了分布式系统中控制共享资源访问的问题。与单体应用不同的是,分布式系统中竞争共享资源的最小粒度从线程升级成了进程。
可以基于数据库、zk、redis实现。
数据库实现:
使用数据库表增删:锁的表主要内容包括需要加锁的资源名、时间戳等字段,以资源名作唯一键。保证只有一个操作成功,执行完成后删除记录。优点是简单易理解,缺点是数据库性能开销是瓶颈。
基于redis实现
redis实现分布式锁
入门分布式锁,setnx(如果key存在则不更新值),根据设置结果判断是否可以执行业务逻辑。如果成功没有该记录,则可以直接写入,相当于获取了锁;如果存在记录,则不会做操作,相当于发现该资源已经被其他线程占有。
线程使用完资源后需要释放锁资源,即删除redis中的对应记录。释放锁资源的时候可以使用lua脚本处理,将查询是否是自己的记录和删除记录合并成一个原子操作。
setex(如果key存在,覆盖旧值,并设置超时时间)
对于reids的分布式锁,可以设置超时时间为10s,如果业务线程在接近10s的时候还未完成业务,则进行锁续命。
锁续命:使用另一个线程定期检查当前线程是否还持有锁,如果持有则更新超时时间。redisson使用lua脚本确保操作的原子性,以此来保证在高并发场景下的原子操作。
锁的逻辑实际是将并发强制为串行执行。
redis集群主从架构锁失效:redis集群中是异步同步,如果在同步时节点宕机,则有可能产生并发问题。第一种redis也是通过zookeeper保证数据一致性,但zookeeper并发度不如redis;第二种使用redlock,实现原理与zookeeper类似,也是只有在超过半数的节点操作成功时才算成功。
redLock是相当于将所有节点都设置为master,写入和删除都需要半数以上节点通过才可以成功操作。可以解决主从模式中主节点宕机的数据问题,但是缺点非常明显,成本过高,流程过重。
实现高并发分布式锁:使用分段锁提高并发度。
NPC问题:因为N:Network Delay,网络延迟、P:Process Pause,进程暂停(GC)、C:Clock Drift,时钟漂移而产生的冲突问题。
如A进程获取到锁之后因为NPC问题导致再处理完之前资源超时释放,线程B获取到资源,结果导致线程AB都对数据进行了操作
处理这种问题只能通过业务兜底来尽量解决。比如在获取锁之后立刻记录资源的值,再写入前比较值是否一致。
redis数据库双写不一致:延迟双删(先清除缓存,再更新数据库,延迟几秒后再清除缓存。只能在一定程度上解决,但是无法保证一定解决,导致redis吞吐降低);内存队列,将对同一个key的操作放在一个队列中执行(有实现难度);每个线程排队执行,保证每个线程操作的原子性(导致串行,性能降低),可以使用读写锁优化(redisson源码使用lua脚本实现),但对读多写少优化明显,对写多场景不明显。
redis集群
redis可以有单机模式、主从模式、哨兵模式。
单机模式的瓶颈是高并发,单机最多支持10wQPS的访问,根据数据的复杂度还会有所降低。
主从模式使用了集群即读写分离来保证高并发,即主节点写,从节点读。
哨兵模式增加了哨兵集群来监控redis集群的节点状态,保证集群节点的高可用性。哨兵集群使用类似zk的方式,判断节点是否下线需要集群节点半数以上同意才可以下线。
RedisCluster提供了一种将数据进行分片存储在不同节点上的模式,避免了内存的浪费。
redis集群数据同步
redis的主从复制策略是通过持久化的rdb文件来实现的。
RDB命令可以手动执行,也可以配置定期执行。
redis集群间的数据同步使用读写分离模式。所有节点都可以读,但只有主节点可以写。
第一阶段:主节点与从节点建立连接,由从库发起同步请求。
第二节点:主节点dump出RDB文件(二进制),发送给从库。从库收到文件后加载数据。该阶段主库依然可以执行新的写命令。
第三阶段:主节点将第二阶段接收到的命令同步给从库,从库执行后完成数据同步。
完成初始同步后,主库与从库间会维护一个长连接,同步写命令给从库,保持数据同步。
复制模式下,从节点的过期数据仍然会被读取到,只有当主节点的过期数据被删除后,主节点才会显式通知从节点删除过期数据。保证了数据一致性。
旧版复制:一旦从节点宕机,再次恢复后不论从节点上有多少数据,都会重新做一次完整数据同步。
新版复制:每次从主节点同步数据到从节点时,都会有偏移量记录当前位置。主节点同步N的数据到从节点,从节点更新数据之后会给自己的偏移量增加N。如果从节点宕机,会再次使用偏移量同步数据,主节点接收到从节点发送过来的偏移量,会在缓冲区中查找并将大于从节点偏移量的数据复制到从节点上,完成部分复制。
执行SAVE/BGSAVE创建RDB文件,会检查数据库中的key,已过期的key不会被保存到RDB文件中。
载入RDB文件时,如果是主服务器则载入时会检查过期时间,过期的key不会被加载到redis中;如果是从服务器,则会加载RDB中全部数据,因为主从数据同步时,从节点的数据会被全部清除,不会有影响。
redis还有一种AOF的持久化方式。相比RDB方式,AOF虽然恢复速度慢,但是可以做到实时持久化。在开启AOF时,会优先使用AOF恢复数据。
AOF持久化会在redis执行完成一个命令后,将命令追加至AOF缓冲区尾部,然后在缓冲区满或达到指定周期将缓冲区数据写入AOF文件。
通过AOF文件恢复数据时,节点会读取AOF文件并重新执行一遍AOF中记录的命令。
还未删除的过期数据会被写入AOF文件中,当该数据被删除后会追加删除命令到AOF文件中。
AOF文件重写时,会检查数据,已经过期的键不会被保存到重写后的AOF文件中。
RDB
SAVE命令阻塞redis服务器创建RDB文件,BGSAVE生成子线程执行RDB创建工作。BGSAVE执行时不允许SAVE和其他BGSAVE同时执行,并且和BGREWRITEAOF命令互斥(执行BGSAVE时不允许执行BGREWRITEAOF,会延后执行;执行BGREWRITEAOF时不允许执行BGSAVE,直接拒绝)。
AOF
AOF持久化的方式是直接保存在redis中的命令。
命令追加:redis中的任何操作命令会追加到aof缓冲区的末尾。
AOF重写:不是分析AOF文件,而是直接去redis中查询对应key现在的值,作为重写后AOF中对应key的命令。使用子进程处理,避免影响可用性。
事件
redis服务器是一个事件驱动程序,包括文件事件、时间时事件。
文件事件处理器基于reactor模式实现,使用IO多用复用同时监听多个socket,并根据socket当前执行的任务关联不同的处理器。多路复用程序总是将产生的事件的socket放到一个队列中,有序、同步的分派给文件事件分派器。
文件事件是对socket的抽象:每次socket变为acceptable、writable、readable时会产生相应的文件事件。
文件事件分为读事件和写事件。
时间事件分为定时事件和周期事件。
文件事件和时间事件合作关系,服务器会轮流处理两类事件,处理过程中也不会进行抢占。
redis客户端
常见redis客户端有lettuce和jedis。
jedis实际是直接连接redisserver,多线程环境下是线程不安全的,因为jedis设计时就是针对redis的单线程的。多线程使用一个jedis实例时会导致共享socket或数据流产生问题,因此需要每个线程一个实例,需要配合连接池使用。
lettuce的实现是基于netty的,一个连接实例可以并发使用,线程安全。也可以扩展连接数。lettuce相比较jedis有更好的能力支撑。
30.Spring事务传播
事务传播行为(propagation behavior)指的就是当一个事务方法被另一个事务方法调用时,这个事务方法应该如何进行。

1、PROPAGATION_REQUIRED
如果存在事务,则直接在事务中运行,如果不存在则新建一个事务运行。
2、PROPAGATION_SUPPORTS
如果存在事务,则直接在事务中运行,如果不存在则不使用事务。
3、PROPAGATION_MANDATORY
如果存在事务,则直接在事务中运行,如果不存在则抛出异常。
4、PROPAGATION_REQUIRES_NEW
不论是否存在事务,均新建事务运行。(需要使用 JtaTransactionManager作为事务管理器)
5、PROPAGATION_NOT_SUPPORTED
总是非事务的运行。如果不存在事务,则直接运行;如果存在事务,则直接在事务外运行。
6、PROPAGATION_NEVER
总是非事务地执行,如果存在一个活动事务,则抛出异常。
7、PROPAGATION_NESTED
事务嵌套执行,如果内层事务失败,外层事务也会回滚;如果外层事务失败,内层事务不会回滚。
31.IO
IO:基于字节流和字符流进行操作。面向流。
字节流:处理的最基本单位为单个字节,它通常用来处理二进制数据。常用InputStream和OutputStream。默认不使用缓冲区。
字符流:处理的最基本的单元是Unicode码元(大小2字节),它通常用来处理文本数据。BufferedReader\InputStreamReader、BufferedWriter\OutputStreamWriter
- 阻塞IO模型(BIO):读写过程中会发生阻塞现象。用户线程请求IO->查看数据是否就绪->若未准备好则进入阻塞,交出CPU;若准备好,内核拷贝数据到用户线程,解除block状态。服务端会使用accept方法监听客户端连接,是阻塞方法;并且在从sokect读取数据时也会阻塞。
- 非阻塞IO模型:用户线程请求数据,如果数据没有准备好就会再次请求数据,不会交出CPU。当数据准备好且接到请求时,会拷贝数据到用户线程。CPU占用高。
- 多路复用IO模型:有一个线程不断去轮询多个socket的状态,只有当socket真正有读写事件时,才真正调用实际的IO读写操作。轮询每个socket状态是内核在进行的,这个效率要比用户线程要高的多。一旦事件响应体很大,那么就会导致后续的事件迟迟得不到处理,并且会影响新的事件轮询。
- 信号驱动IO模型:用户线程请求IO->对应socket注册信号函数,用户线程继续执行->数据就绪后内核发送信号给用户线程->用户线程调用IO发起实际IO操作。
- 异步IO模型(AIO):当用户线程发起read操作之后,立刻就可以开始去做其它的事。用户线程请求IO->内核接收到请求并立刻返回表示接收到请求->内核准备好数据后,将数据拷贝到用户线程中,再给用户线程发送信号表示IO操作完成。(用户线程不需要执行额外的调用IO实际操作)
NIO-是一种同步非阻塞IO模型:包括channel,buffer,selector三大核心。基于Channel和Buffer(缓冲区)进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。面向缓冲区。
NIO是非阻塞的,读取时,一个线程通过一个通道只获取到当前可以获取到的数据,如果没有就不获取,不会一直等待;写入时也是,写入内容到某通道后不必等待数据完全写入。非阻塞的空闲时间可以用来管理其他通道IO操作,因此一个线程可以管理多个输入和输出通道。
- channel:和IO中的stream是差不多等级的,但stream是单向的,channel是双向的。
- buffer:实际上是一个容器,一个连续数组。读取:从channel到buffer再到客户端;写入:从客户端到buffer再到channel。
- selector:Selector类是NIO的核心类,Selector能够检测多个注册的通道上是否有事件发生,如果有事件发生,便获取事件然后针对每个事件进行相应的响应处理。单线程可以管理多个连接,减少线程开销,减少读写开销。
31.HBase
1、Hbase是什么?
(1) Hbase是一个分布式的基于列式存储(列簇数据库)的数据库,基于Hadoop的hdfs存储,使用zookeeper进行管理。
列式数据库是指数据库中的记录存储方式是将每条记录的不同列存储在不同的文件中。
(2) Hbase适合存储半结构化或非结构化数据,对于数据结构字段不够确定或者杂乱无章很难按一个概念去抽取的数据。
(3) Hbase为null的记录不会被存储.
(4) 表数据包含rowkey,时间戳,和列族。新写入数据时,时间戳更新,同时可以查询到以前的版本.
(5) hbase是主从架构。hmaster作为主节点,hregionserver作为从节点。
HMaster负责管理regionServer,实现其负载均衡;管理和分配region,如region数据量达到阈值后分裂成多个新的region,或在regionServer退出集群时迁移对应的region到其他regionServer种。
RegionServer存放和管理本地region;读写hdfs,管理table中的数据;client从HMaster中获取元数据,找到rowkey对应的regionServer进行数据读写。
ZK存放整个HBase集群的元数据及集群状态信息,实现HMaster主从节点的failover(故障转移)。
2、HBase 的特点是什么?
1)大:一个表可以有数十亿行,上百万列;
2)无模式:每行都有一个可排序的主键和任意多的列,列可以根据需要动态的增加,同一张表中不同的行可以有截然不同的列;
3)面向列:面向列(族)的存储和权限控制,列(族)独立检索;
4)稀疏:空(null)列并不占用存储空间,表可以设计的非常稀疏;
5)数据多版本:每个单元中的数据可以有多个版本,默认情况下版本号自动分配,是单元格插入时的时间戳;
6)数据类型单一:Hbase 中的数据都是字符串,没有类型。
7)强一致性
hbase的一条数据只会出现在一个region中,虽然底层数据存储在hdsf上是有多份副本的。但是其中是通过hlog保证数据不会丢失,并且写入memstore的数据也会flush到fliestore的,具体在hdsf上的数据同步,包括了filestore的异步同步。
3、HBase 和 Hive的区别
Hive 和 Hbase 是两种基于 Hadoop 的不同技术。Hive 是一种类 SQL 的引擎,并且运行MapReduce 任务,Hbase 是一种在 Hadoop 之上的NoSQL 的 Key/vale 数据库。当然,这两种工具是可以同时使用的。就像用Google来搜索,用FaceBook进行社交一样,Hive可以用来进行统计查询,HBase 可以用来进行实时查询,数据也可以从 Hive 写到 Hbase,再从 Hbase 写回 Hive。
4、HBase 适用于怎样的情景?
① 半结构化或非结构化数据
② 记录非常稀疏
③ 多版本数据
④ 超大数据量
5、描述 HBase 的 rowKey 的设计原则?
cell是由{rowkey, column Family:columu, version} 唯一确定的单元。cell中的数据是没有类型的,全部是字节码形式存贮。关键字:无类型、字节码
① Rowkey 长度原则
Rowkey 是一个二进制码流,Rowkey 的长度被很多开发者建议说设计在 10~100 个字节,不过建议是越短越好,不要超过 16 个字节。
原因如下:
(1)数据的持久化文件 HFile 中是按照 KeyValue 存储的,如果 Rowkey 过长比如 100个字节,1000 万行数据光 Rowkey 就要占用 100*1000 万=10 亿个字节,将近 1G 数据,这会极大影响 HFile 的存储效率;
(2)MemStore 将缓存部分数据到内存,如果 Rowkey 字段过长内存的有效利用率会降低,系统将无法缓存更多的数据,这会降低检索效率。因此 Rowkey 的字节长度越短越好。
(3)目前操作系统是都是 64 位系统,内存 8 字节对齐。控制在 16 个字节,8 字节的整数倍利用操作系统的最佳特性。
② Rowkey 散列原则
如果Rowkey 是按时间戳的方式递增,不要将时间放在二进制码的前面,建议将Rowkey的高位作为散列字段,由程序循环生成,低位放时间字段,这样将提高数据均衡分布在每个Regionserver 实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息将产生所有新数据都在一个 RegionServer 上堆积的热点现象,这样在做数据检索的时候负载将会集中在个别 RegionServer,降低查询效率。
③ Rowkey 唯一原则
必须在设计上保证其唯一性。
6、描述 HBase 中 scan 和 get 的功能以及实现的异同?
HBase 的查询实现只提供两种方式:
1)按指定 RowKey 获取唯一一条记录,get 方法(org.apache.hadoop.hbase.client.Get)Get 的方法处理分两种 : 设置了 ClosestRowBefore 和没有设置 ClosestRowBefore 的rowlock。主要是用来保证行的事务性,即每个 get 是以一个 row 来标记的。一个 row 中可以有很多 family 和 column。
2)按指定的条件获取一批记录,scan 方法(org.apache.Hadoop.hbase.client.Scan)实现条件查询功能使用的就是 scan 方式。
7、 简述 HBase 中 compact 用途是什么,什么时候触发,分为哪两种,有什么区别,有哪些相关配置参数?
在 hbase 中每当有 memstore 数据 flush 到磁盘之后,就形成一个 storefile,当 storeFile的数量达到一定程度后,就需要将 storefile 文件来进行 compaction 操作。
Compact 的作用:
① 合并文件
② 清除过期,多余版本的数据
③ 提高读写数据的效率
HBase 中实现了两种 compaction 的方式:minor and major. 这两种 compaction 方式的
区别是:
1、Minor 操作只用来做部分文件的合并操作以及包括 minVersion=0 并且设置 ttl 的过期版本清理,不做任何删除数据、多版本数据的清理工作。
2、Major 操作是对 Region 下的 HStore 下的所有 StoreFile 执行合并操作,最终的结果是整理合并出一个文件。
8、HBase 优化?
(1)高可用
在 HBase 中 Hmaster 负责监控 RegionServer 的生命周期,均衡 RegionServer 的负载,如果 Hmaster 挂掉了,那么整个 HBase 集群将陷入不健康的状态,并且此时的工作状态并不会维持太久。所以 HBase 支持对 Hmaster 的高可用配置。
(2)预分区
每一个 region 维护着 startRow 与 endRowKey,如果加入的数据符合某个 region 维护的rowKey 范围,则该数据交给这个 region 维护。那么依照这个原则,我们可以将数据所要投放的分区提前大致的规划好,以提高 HBase 性能 .
(3)RowKey 设计
一条数据的唯一标识就是 rowkey,那么这条数据存储于哪个分区,取决于 rowkey 处于哪个一个预分区的区间内,设计 rowkey 的主要目的 ,就是让数据均匀的分布于所有的 region中,在一定程度上防止数据倾斜。
(4)内存优化
HBase 操作过程中需要大量的内存开销,毕竟 Table 是可以缓存在内存中的,一般会分配整个可用内存的 70%给 HBase 的 Java 堆。但是不建议分配非常大的堆内存,因为 GC 过程持续太久会导致 RegionServer 处于长期不可用状态,一般 16~48G 内存就可以了,如果因为框架占用内存过高导致系统内存不足,框架一样会被系统服务拖死。
9、Region 如何预建分区?
预分区的目的主要是在创建表的时候指定分区数,提前规划表有多个分区,以及每个分区的区间范围,这样在存储的时候 rowkey 按照分区的区间存储,可以避免 region 热点问题。
通常有两种方案:
方案 1:shell 方法
create ‘tb_splits’, {NAME => ‘cf’,VERSIONS=> 3},{SPLITS => [‘10’,‘20’,‘30’]}
方案 2: JAVA 程序控制
· 取样,先随机生成一定数量的 rowkey,将取样数据按升序排序放到一个集合里;
· 根据预分区的 region 个数,对整个集合平均分割,即是相关的 splitKeys;
· HBaseAdmin.createTable(HTableDescriptor tableDescriptor,byte[][]splitkeys)可以指定预分区的 splitKey,即是指定 region 间的 rowkey 临界值。
10、HRegionServer 宕机如何处理?
1)ZooKeeper 会监控 HRegionServer 的上下线情况,当 ZK 发现某个 HRegionServer 宕机之后会通知 HMaster 进行失效备援;
2)该 HRegionServer 会停止对外提供服务,就是它所负责的 region 暂时停止对外提供服务;
3)HMaster 会将该 HRegionServer 所负责的 region 转移到其他 HRegionServer 上,并且会对 HRegionServer 上存在 memstore 中还未持久化到磁盘中的数据进行恢复;
4)这个恢复的工作是由 WAL 重播来完成,这个过程如下:
· wal 实际上就是一个文件,存在/hbase/WAL/对应 RegionServer 路径下。
· 宕机发生时,读取该 RegionServer 所对应的路径下的 wal 文件,然后根据不同的region 切分成不同的临时文件 recover.edits。
· 当 region 被分配到新的 RegionServer 中,RegionServer 读取 region 时会进行是否存在 recover.edits,如果有则进行恢复。
11、HBase 读写流程?
读:
① HRegionServer 保存着 meta 表以及表数据,要访问表数据,首先 Client 先去访问zookeeper,从 zookeeper 里面获取 meta 表所在的位置信息,即找到这个 meta 表在哪个HRegionServer 上保存着。
② 接着 Client 通过刚才获取到的 HRegionServer 的 IP 来访问 Meta 表所在的HRegionServer,从而读取到 Meta,进而获取到 Meta 表中存放的元数据。
③ Client 通过元数据中存储的信息,访问对应的 HRegionServer,然后扫描所在HRegionServer 的 Memstore 和 Storefile 来查询数据。
④ 最后 HRegionServer 把查询到的数据响应给 Client。
写:
① Client 先访问 zookeeper,找到 Meta 表,并获取 Meta 表元数据。
② 确定当前将要写入的数据所对应的 HRegion 和 HRegionServer 服务器。
③ Client 向该 HRegionServer 服务器发起写入数据请求,然后 HRegionServer 收到请求并响应。
④ Client 先把数据写入到 HLog,以防止数据丢失。
⑤ 然后将数据写入到 Memstore。
⑥ 如果 HLog 和 Memstore 均写入成功,则这条数据写入成功
⑦ 如果 Memstore 达到阈值,会把 Memstore 中的数据 flush 到 Storefile 中。
⑧ 当 Storefile 越来越多,会触发 Compact 合并操作,把过多的 Storefile 合并成一个大的 Storefile。
⑨ 当 Storefile 越来越大,Region 也会越来越大,达到阈值后,会触发 Split 操作,将Region 一分为二。
一个表会被自动分为多个region,每个region中存储了一个表中的一段连续数据。
一个region包含多个store,一个store对应一个列簇。sotre包括位于内存中的memstore和磁盘的filestore。
12、如何提高 HBase 客户端的读写性能?请举例说明
1 开启 bloomfilter 过滤器,开启 bloomfilter 比没开启要快 3、4 倍
2 Hbase 对于内存有特别的需求,在硬件允许的情况下配足够多的内存给它
3 通过修改 hbase-env.sh 中的export HBASE_HEAPSIZE=3000 #这里默认为 1000m
4 增大 RPC 数量通过修改 hbase-site.xml 中的 hbase.regionserver.handler.count 属性,可以适当的放大RPC 数量,默认值为 10 有点小。
hbase批量导入:bulk load
使用MapReduce作业以hbase内部数据格式输出表数据,然后将生成的hfile加载到正在运行的hbse的底层hdsf中,并映射到对应的region,通知regionServer。
优点:不用写hlog,避免了过量的split和flush;数据可以立即被使用,不会对集群造成额外的负载和延迟。
为什么选择hbase而不是mysql:
hbase是完全分布式(有数据分片、故障自恢复能力),底层使用hadoop架构(存储分离)。
mysql支持的数据量级较小,对于上亿级别的数据,mysql需要进行分库分表改造,并且查询效率会下降;而hbase数据是从内存读取,如果内存没有再从硬盘中读取,数据是顺序写入,查询效率更高。
lindorm
lindorm是基于hbase的多模数据库,同时提供宽表引擎、时序引擎、搜索引擎和文件引擎。
lindorm和hbase的区别在于,lindorm将每个数据分区存储在多个副本、多个机房,避免了hbase中一个regionServer挂掉之后需要停止这部分的服务进行数据转移恢复。
32.ZooKeeper
zk是一个分布式协调服务,为分布式应用提供一致性服务。
zk保证了如下分布式一致特性:
顺序一致性(所有的更新都是全局有序的,每个更新都有一个唯一的时间戳,操作都会顺序执行)、原子性(只有成功和失败没有其他状态)、可靠性(持久性,节点更新后,在下次更新前不会发生变更)、实时性(最终一致性)。
zk的结构:

zk是主从集群,客户端可以与任意节点连接,且均可以执行读写操作。对主节点的写操作会直接执行,但是对从节点的写操作会由从节点转发至主节点执行。
zk的数据是存在内存中的,效率高。存储方式类似文件存储,采用分层存储结构,每个节点都可以存储数据,但不能超过1M。
zk中创建的节点分为两种:永久性节点和临时性节点。永久性节点即创建以后,在不执行delete命令的前提下,该节点是永久存在的;而临时节点与session有关,每个客户端与zk建立链接的时候会生成一个session,这个session不会因为链接zk服务器节点的变化而变化,只有当客户端断开连接以后,该session才会消失,而临时节点会随着session的消失而消失。
zk拥有watch机制,也就是监视机制,可以支持响应式编程模式,它可以对某个路径的终节点及其子节点的变更进行监视,当其发生变更以后,会调用注册的callback方法,然后进行具体的业务逻辑。例如监测路径为/A/A1,那么它会监测A1节点,以及附属于A1的所有子节点,这个子不单单只一层子节点,是指所有层的子节点。
主节点选举:
主从节点之间是通过心跳检查服务是否可用,只要任意一台节点发现主节点挂掉就会开始通知整个集群进行选举,并停止对外服务。
初始启动时:选举最低需要有三台节点才可以进行,因此在启动到第三台机器的时候会进行选举,没有zxid时是通过每台机器分配的myid选举,第三台机器的myid最大,因此主节点被选为第三台机器。
运行过程中:如果主节点挂掉,则从剩下的机器中的zxid和myid进行选举,优先zxid,然后才是myid。
zk数据一致性:
zookeeper在同步数据时,不允许客户端读写,阻塞状态。
从节点上的写操作会先转给主节点进行处理。主节点先更新zxid,表示已经接收了这个操作,然后会将操作更新到自己的日志中,再通知从节点更新日志,成功后通知主节点。过半节点日志写入成功后主节点会将操作写入内存,然后通知从节点执行操作。同样过半节点完成后通知主节点表示操作完成。然后主节点返回消息给发起操作的节点返回给客户端,完成整个操作流程。
zk实现分布式锁
zk分布式锁主要分为两类:保持独占(所有竞争的线程都去创建同一个节点,成功创建的线程获取锁)和控制时序(所有线程都去创建临时节点,只有编号最小的获取锁)。
zk实现分布式锁主要依赖的是zk节点的顺序递增特性,每个创建的节点都会有唯一的编号,且下一个创建的节点也会有新的+1的编号。
每个线程尝试获取锁的时候,就是在某个持久父节点下创建临时节点的过程,创建了对应的Znode后,会调用watch来判断自己的节点是否为最小序号,如果是则获取锁,如果不是则等待watch通知上一个节点完成(上一个节点删除时,会调用回调机制,告诉下一个节点)。
zk的分布式锁还可以避免因为网络原因而产生的死锁,因为客户端断开连接后会自动删除临时节点。
zk的节点还具有顺序访问的特性,即后面的节点监听上一个节点,避免了羊群效应(某个节点挂掉之后,集群所有节点都要去监听并做出回应,会有较大的服务器压力)。
zk脑裂问题
假如一个集群部署在了两个机房中,因为某些原因导致两个机房之间网络断开,心跳中断,会使两个机房中的节点再次进行选举,不考虑过半原则的情况下,各自都会选举出一个leader,待两个机房间的网络恢复后会出现两个leader同时存在的情况,会导致数据不一致等问题。
zk为了解决脑裂问题,使用了过半原则,即选举leader需要一半以上的节点都同意才可以成功。
另外还可以通过仲裁机制解决脑裂问题:除了心跳之外,增加一个参考IP,当心跳断开后,发现断开的节点都去ping参考ip,不通则表示问题出在本节点,则主动放弃竞争,还可以直接重启,释放共享资源。
33.ABA问题及其解决方法
多个线程操作同一个数据A,线程1读取到A=10,在进行操作前其他线程操作了数据A,使其值被修改为11,又修改为10。虽然线程1读取到的数据仍然是10,但其他线程已经使用11进行过业务操作,线程1不应该再使用10进行操作。
简单的解决方案就是使用版本号,每次操作都会有对应的版本号,版本号不同则不进行操作。JDK1.5开始引入了AtomicStampedReference类,其中的compareAndSet方法首先检查当前引用值是否等于预期值,如果相等才更新值。
34.分布式中间件的CAP
CAP(Consistency一致性,Availability可用性,Partition tolerance分区容错性)
一致性:割接点的数据保证一致。强一致性:写操作完成后,后续读都能看到最新数据;弱一致性:能容忍部分或全部都看不到最新数据;最终一致性:经过一段时间后都能看到最新数据。
可用性:每次向未崩溃的节点请求数据,总能收到响应。
分区容错性:允许节点间数据存在延迟或丢失,但不影响系统继续运行。BASE(Basically Available基本可用,Soft state软状态,Eventually consistent最终一致性)
基本可用:
响应时间上的损失:正常情况下,处理用户请求需要0.5s返回结果,但是由于系统出现故障,处理用户请求的时间变成3s。
系统功能上的损失:正常情况下,用户可以使用系统的全部功能,但是由于系统访问量突然剧增,系统的非核心功能无法使用。
软状态:数据同步允许一定的延迟。
最终一致性:系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态,不要求实时。
redis侧重AP:在数据同步过程中,从节点也可以提供服务,此时会返回旧数据。因此redis实现的分布式锁也是AP
zookeeper侧重CP:因为zk的数据会等待超过半数节点完成同步后才会响应客户端。因此zk实现的分布式锁也是cp
kafka:kafka官方声明是侧重AC,因为kafka设计运行在一个数据中心,基本不会发生网络问题。但是通过配置acks可以使得kafka满足ap或者cp。当acks=1时,主节点commit数据之后就进行确认,可能会导致数据丢失,但保证了可用性,AP。而当acks=all时,每条数据都需要等待全部节点收到消息之后才确认,保证了一致性,但是牺牲了可用性,CP。
Hbase侧重CP:对于hbase,每一个region只有一个regionServer响应,一旦这个regionServer挂掉,region则会被分到其他的regionServer种进行重新加载,而这个过程中,regionServer是停止服务的,保证了c但舍弃了a。
35.java的零拷贝
传统的Java IO模型中,从硬盘读取数据并发送到客户端的操作流程如下
因为java无法直接读取文件,需要从硬盘读取到内核缓冲区,再读取到用户缓冲区,处理后再写入socket缓冲区,最后复制到网卡进行数据发送。期间有四次数据拷贝。
因此NIO中进行了改进,使用FileChannel读,写入ByteBuffer,再从byteBuffer读,写入SocketChannel。其中使用了ByteBuffer.allocateDirect(16),可以直接使用操作系统内存,而且java也可以直接操作。数据就可以直接从内核缓冲区写入socket缓冲区,不拷贝至用户缓冲区,减少了两次拷贝操作。
36.RPC-------HSF和Dubbo
RPC是用来屏蔽远程调用网络相关的细节,使得远程调用和本地调用一致,提高开发效率。
在本地通过接口调用远程服务的具体实现是通过动态代理实现的。
RPC会给接口生成一个代理类,调用这个接口实际调用的是动态生成的代理类,由代理类来出发远程调用。
RPC的协议:
一般RPC协议都是采用协议头+协议体的方式。
协议头放置元数据:包括魔法位(用来判断是否约定的协议)、协议版本、消息的类型、序列化的方式、整体长度、头长度、扩展位等。
协议体是请求的数据。
RPC网络传输:
一般RPC框架会使用OD多路复用,可以使用较少线程支持大量请求,如Netty。
HSF:
HSF是rpc框架的一种实现,服务调用是通过client和server点对点进行,其中配置中心是diamond实现,注册中心通过configServer实现。
配置中心用来控制服务器分组、路由、动态负载等规则。
注册中心负责处理服务上线的ip注册等操作。
Dubbo:
也是一种RPC框架实现。
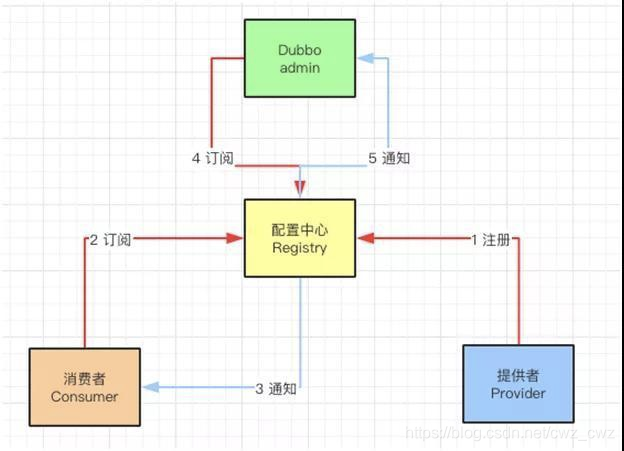
服务提供者:
在读取配置文件生成服务实体以后,会通过 ProxyFactory 将 Proxy 转换成 Invoker。
此时,Invoker 会被定义 Protocol,之后会被包装成 Exporter。
最后,Exporter 会发送到注册中心,作为服务的注册信息
服务消费者:
服务消费者首先持有远程服务实例生成的 Invoker,然后把 Invoker 转换成用户接口的动态代理引用
hsf和dubbo的区别:
Dubbo比HSF的部署方式更轻量。HSF要求使用指定的JBoss等容器,还需要在JBoss等容器中加入sar包扩展,对用户运行环境的侵入性大
Dubbo比HSF的扩展性更好,很方便二次开发
HSF依赖比较多内部系统,比如配置中心,通知中心,监控中心,单点登录等等
Dubbo比HSF的功能更多,除了ClassLoader隔离,Dubbo基本上是HSF的超集,Dubbo也支持更多协议,更多注册中心的集成,以适应更多的网站架构
37.跳表(skiplist)
跳表是一种链表加多级索引的数据结构。
与二分查找类似,跳表能够在O(logn)时间复杂度内完成查找,与红黑树等查找时间复杂度相同,但跳表能更好的支持并发,并且数据结构更加简单直观。
插入:
跳表的插入过程首先是找到小于被插入数据的第一个节点,然后在原始链表中插入目标数据。然后对新插入的节点进行随机晋升(抛硬币的方式),即成功则在上一层索引中也增加该节点,直到晋升失败或者增加索引层。
删除:
删除的过程与插入类似,首先找到待删除节点,然后从原始链表中删除,如果该节点有对应的索引层节点,则一并删除并维护好对应的前后节点关系。
跳表对并发的更好的支持是因为通过cas操作,可以对链表实现无锁写入的能力。简单来说就是每个对链表的操作都是原子性的,同时只能有一个线程成功,而其他线程在当前线程完成后,会再次执行cas操作比较应该执行操作的位置,从而保证链表的有序性。而基于链表产生的索引层也可以看做是有序地。
38.ES
es是面向文档的分布式可扩展的实时搜索和分析引擎。
ES存储结构是索引->文档->字段。
Elasticsearch采用一主多副复制方式,没有采用节点级别的主从复制,而是基于分片。
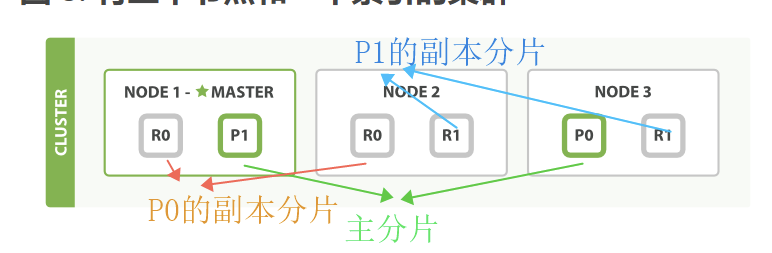
每个节点中都会存在分片的备份。
数据写入流程:从访问的节点上路由到对应分片的主分片的节点,然后进行写操作,主分片完成后再同步至副分片,全部同步完成后才会返回给客户端。
ES是通过倒排索引的方式来实现文档的搜索。对于一个doc,会被拆分为多个term,然后根据每个term建立索引,即每个term出现的次数和与之相对应的文档list。
由于是采用倒排索引结构,所以ES的搜索查询速度非常快,但是更新写入比较慢。
39.raft算法
raft是一种分布式系统常用的共识算法,即所有节点对同一份数据的认知能够达成一致。
将分布式一致性分解为多个子问题:leader选举、日志复制、安全性、日志压缩。
leader选举:
成员身份:领导者(负责处理写请求,管理日志复制和发送心跳信息)、候选者(向其他节点发送请求投票RPC消息)、跟随者(接收和处理来自领导者的消息,当等待领导者心跳超时后主动推荐自己做候选者)。
投票过程:初始状态下所有节点都是follower,但每个节点的超时时间都是随机(随机避免多个节点同时发起选举)的,超时时间(没有接收到leader心跳消息的超时时间)最短的节点会先向其他节点发送投票请求,并且自身任期+1。
任期:节点推举自己为候选者时自身任期会+1;当follower节点发现自己任期编号比其他节点小,则会更新自己的任期编号到较大的编号;当leader或candidate发现自己任期比其他节点小,会立即恢复为follower;如果一个节点接收到一个小于自己任期的投票请求,则会直接拒绝;日志完整性高的节点拒绝给日志完整性低的节点投票。
强领导者模型会导致leader节点写操作和数据转发压力过大,kafka使用了partition的方式,每个partition有一个leader,降低了leader压力。
日志复制:
leader会强制要求follower跟随自己的日志,每次日志复制RPC请求或心跳RPC都会带上最新的日志节点数据和前一节点的任期编号+索引值,如果follower节点的前一节点匹配,则直接增加新日志,如果不匹配,则返回给leader在follower上的最新日志的值和前一节点的任期编号+索引值,leader找到对应日之后将其后的全部数据发送给follower。
安全性:
拥有最新已提交的logEntry的follower才有资格成为leader。
日志压缩:
避免日志无限增长,raft采用对整个系统进行snapshot解决。snapshot只能对已经提交的日志记录进行,snapshot包含日志最新logEntry的logIndex和term,还有一个存有所有数据最新记录的状态机。
40.String相关
String中的字符串是不可变的,因为char[] value数组使用private final修饰,而StringBuffer和StringBuilder没有final修饰符,可变。
操作少量字符串使用String,操作大量字符串单线程使用StringBuffer(非线程安全,效率高),多线程使用StringBuilder(线程安全,加锁,效率低)
41.深拷贝浅拷贝
浅拷贝:对于基本数据而言传递的是值,对于引用类型是传递引用拷贝。
深拷贝:对于基本数据而言是传递值,对于引用类型,是创建一个新对象,将值拷贝进新对象。
clone方法可以拷贝当前对象,但对于对象中持有的其他对象的引用,需要递归调用clone来实现深拷贝。或者使用序列化方式
42.内部类
成员内部类:与成员变量一起定义,可以访问外部类中的所有变量,包括private修饰的。
静态内部类:与成员变量一起定义,只能访问外部类的静态资源,不能访问非静态资源。
局部(方法)内部类:定义在方法内部,访问局部变量时,必须访问带有final修饰的变量保证一致性。
匿名内部类:必须继承自一个抽象类或实现一个接口,是一个匿名对象。
43.分布式事务
2pc:两阶段提交协议。
阶段1:协调者询问所有参与者是否可以执行事务提交操作,并等待响应;参与者执行事务,写undo/redo日志;参与者响应(如果有任何一个参与者超时或反馈失败,则回滚事务)
阶段2:协调者发送commit请求;参与者正式执行事务提交操作;反馈事务执行结果;全部成功后完成事务(如果有任何一个参与者超时或反馈失败,则回滚事务)
优点:简单
缺点:同步阻塞(所有参与者在事务期间都在阻塞,影响可用性)、过于保守(任何节点失败都会取消事务)
3pc:三阶段提交协议
阶段1:询问是否可以执行事务
阶段2:预提交,写undo/redo日志
阶段3:提交
3pc和2pc:3pc在2pc的基础上将提交前的询问操作分为询问和预提交两个阶段,好处是在预提交后如果等待提交时超过超时时间会自动执行提交,避免了阻塞。
44.HDFS
hdfs(Hadoop Distributed File System)是Hadoop种最重要的组成部分,主要用于解决海量大数据的存储问题,是目前应用最广的分布式文件存储系统。
hdfs解决了传统文件存储的两个问题:
1、数据量增大后扩容;2、文件太大传输耗时过高。
解决:1、纵向扩容:增加内存和磁盘;横向扩容:增加服务器数量;2、大文件分成多个数据库,并行处理。
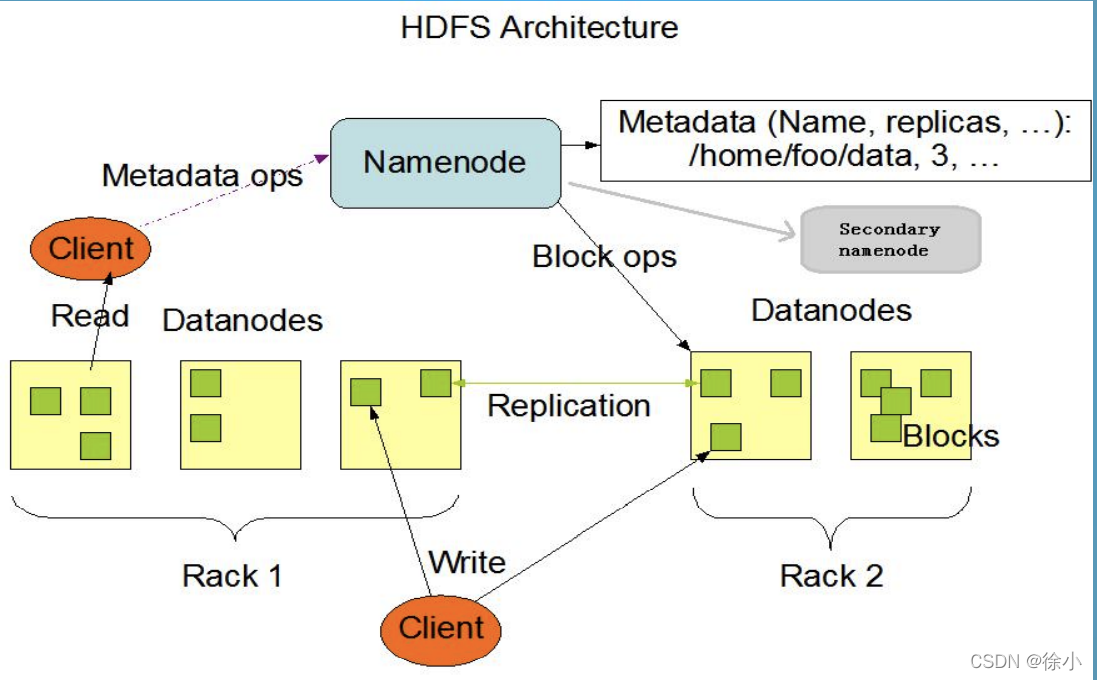
hdfs上的文件不支持直接修改,如果需要修改需要将文件下载到本地,在本地修改完成后再上传到hdfs上。hdfs支持appendToFile进行追加。
hdfs被设计成适应一次写入多次读出的场景,且不支持文件的修改。
正因如此,hdfs适合用来做大数据分析的底层存储服务莫不是和用来做网盘等应用,因为修改不方便、延迟大、网络开销大、成本高。
hdfs节点:
nameNode:是hdfs集群的主服务器,负责客户端请求的响应,以及元数据的管理,包括了数据块的映射信息。nameNode中包含了fsimage(包含了全部文件和目录的元数据信息)和editLogs(针对元数据的修改操作日志)。每隔一段时间或editLogs达到一定大小后会将日志中记录的操作更新至fsimage中。保证hdfs中元数据信息的安全性。
secondaryNameNode:负责合并nameNode的editLogs到fsimage中。定时获取nameNode中的editLogs,并且通知nameNode使用新的editLogs文件,将旧editLogs更新至自身的fsimage中,然后拷贝回nameNode中并替换fsimage和editLogs,下次nameNode重启时会使用新的fsimage文件。
dataNode:是hdfs集群中的从服务器,提供真是文件数据的存储服务。响应来自客户机的读写请求,同时还响应来自nameNode的创建、删除、复制块的命令。nameNode和dataNode间使用心跳保持状态,dataNode发送心跳包含块报告,nameNode使用该报告验证块映射和其他文件系统元数据。
读流程:

- client向nameNode请求block所在的位置。
- nameNode视情况返回文件的部分或全部block列表,即包含该block副本的dataNode地址。
- client选取排序靠前的dataNode读取block。并行读取block。
- 读取完获取的block列表后,如果还未完成,继续向nameNode请求。
- 最终读取完成后,关闭读流,将所有的读取来的block合并成一个完整的最终文件。
写流程:

- client发起上传请求,nameNode检查目标文件是否存在、父目录是否存在,返回是否可以上传。
- client请求第一个block应该放到哪些dataNode上。
- nameNode根据配置文件中指定的备份数量和机架感知原理进行文件分配,返回可用dataNode地址。
- client请求可用dataNode中的一台进行传输,该dataNode回调用可用dataNode中的另一台,依次传输。
- 数据按packet为单位在pipeline上依次传输,接收到后返回ack依次应答。
- 一个block传输完成后,关闭写入流。再请求上传下一个block。
hdfs高可用架构:
在Hadoop2.X之前,Namenode在HDFS集群中是单点的,每个HDFS集群只有一个namenode,一旦这个节点不可用,则整个HDFS集群将处于不可用状态。HDFS高可用(HA)方案就是为了解决上述问题而产生的,在HA HDFS集群中会同时运行两个Namenode,一个作为Active Namenode(Active),一个作为Standby Namenode。Standby Namenode的命名空间与Active Namenode是实时同步的,所以当Active Namenode发生故障而停止服务时,Standby Namenode可以立即切换为活动状态,从而不影响HDFS集群服务。
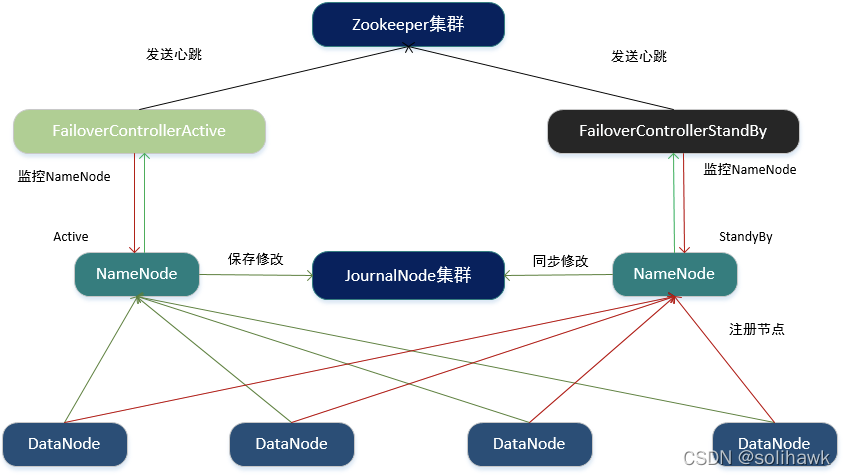
独立集群journalNode记录了editLogs,standby节点会监听变化,同步editLogs以达到和activeNameNode一致的效果。并且dataNode会同时向active和standby发送心跳和块信息,保证了元数据的一致,发生故障时可以快速切换。
secondaryNameNode和journalNode:
secondaryNameNode只是NameNode的辅助,而journalNode是用来保证两个nameNode间数据一致性。
45.IOC容器源码
IOC容器包括BeanFactory(简单容器系列)和ApplicationContext(应用上下文)。
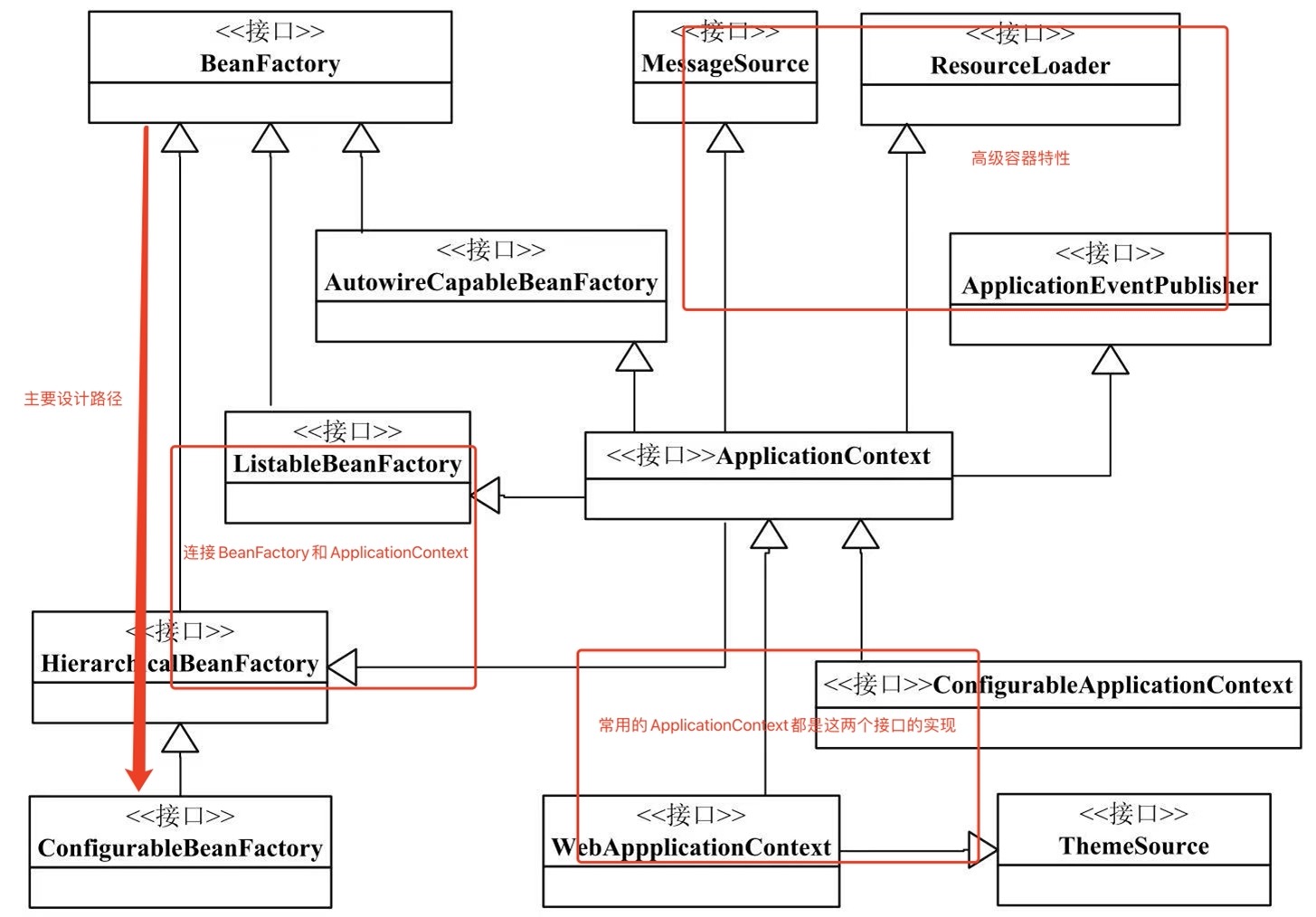
IOC容器中主要接口设计。
BeanFactory->HierarchicalBeanFactory->ConfigurableBeanFactory是一条主要设计路径。该路径中,BeanFactory定义了基本的IOC容器的规范,包括getBean()这种基本方法;
Object getBean(String name) throws BeansException;<T> T getBean(String name, Class<T> requiredType) throws BeansException;// 获取prototype类型的bean,可以传入该bean的构造函数的参数Object getBean(String name, Object... args) throws BeansException;<T> T getBean(Class<T> requiredType) throws BeansException;<T> T getBean(Class<T> requiredType, Object... args) throws BeansException;
HierarchicalBeanFactory继承了BeanFactory后增加了getParentBeanFactory()功能,使BeanFactory具备了双亲IOC容器的管理功能;
@NullableBeanFactory getParentBeanFactory();
ConfigurableBeanFactory定义了对BeanFactory的配置功能,如setParentBeanFactory()、addBeanPostProcessor()。
void setParentBeanFactory(BeanFactory parentBeanFactory) throws IllegalStateException;void addBeanPostProcessor(BeanPostProcessor beanPostProcessor);
ApplicationContext应用上下文为核心的接口设计路径。
BeanFactory->ListableBeanFactory->ApplicationContext->WebApplicationContext/ConfigurableApplicationContext
我们常用的应用上下文基本都是WebApplicationContext/ConfigurableApplicationContext的实现。
ListableBeanFactory细化了BeanFactory的接口功能,如getBeanDefinitionNames()方法
String[] getBeanDefinitionNames();
BeanFactory提供的是最基本的IOC容器功能,提供多种getBean()方法获取BeanFactory中管理的Bean。
BeanFactory实现的是IOC容器的基本形式,而ApplicationContext的实现是IOC容器的高级表现形式。
DefaultListableBeanFactory包含了基本IOC容器所具有的重要功能,在很多地方都会当做一个默认功能完整的IOC容器使用。
Resource是spring用来封装IO操作的类。
使用IOC容器的步骤:
- 创建IOC配置文件资源,包含BeanDefinition的定义信息。
- 创建BeanFactory,如DefaultListableBeanFactory。
- 创建BeanDefinition读取器(如XmlBeanDefinitionReader载入XML形式的BeanDefinition,通过回调配置给BeanFactory)。
- 从资源读取配置,由BeanDefinitionReader完成。
public interface Resource extends InputStreamSource
与BeanFactory相对的有FactoryBean。FactoryBean使用时,通过对象名获取的是FactoryBean获取的是产生的对象,增加&前缀获取的是FactoryBean本身。
BeanFactory是,IOC容器或对象工厂;FactoryBean是一个Bean。
Spring中所有的Bean都是由BeanFactory管理的;但FactoryBean不是一个简单的Bean,是可以产生或修饰对象生成的工厂Bean,与工厂模式和装饰器模式类似。
ApplicationContext是一个高级形态意义的IOC容器,提供了更加丰富的附加服务,是一种面向框架的使用风格,开发时一般建议使用ApplicationContext作为IOC容器的基本形式。
扩展MessageSource提供了国际化的支持,如时间、货币等。
扩展ResourceLoader支持了多种来源的Bean定义资源,文件、网络等。
扩展ApplicationEventPublisher,引入了事件机制。与Bean生命周期结合为Bean的管理提供了便利。
IOC容器初始化过程:
IOC容器的初始化是由refresh()启动的,这个方法标志着IOC容器的正式启动。这个启动包括BeanDefinition的Resource定位、载入和注册三个基本过程。
Spring把这三个过程分开,使用不同的模块完成,如使用对应的ResourceLoader、BeanDefinitionReader等。可以让用户更灵活的对这三个过程进行剪裁或扩展,定义出最适合的IOC容器初始化过程。
refresh()做了什么:
1、调用了prepareRefresh()方法。对内部状态字段的设置、applicationListeners的设置。
2、调用prepareBeanFactory()方法。设置ClassLoader、设置BeanExpression解析器、设置property注册器、向容器添加BeanPostProcessor(包括ApplicationContextAwareProcessor、ApplicationListenerDetecor、对AspectJ支持的LoadTimeWeaverAwareProcessor)、注册环境beans。
- Resource定位。由ResourceLoader使用统一的Resource接口完成,类似于容器寻找数据的过程。
使用较底层BeanFactory定位Resource时需要自己实现BeanDefinition的读取,而使用ApplicationContext时,可以使用Spring已经实现好的一系列读取不同Resource的ApplicationContext。但使用底层BeanFactory有更好的IOC容器定制的灵活性。 - BeanDefinition载入和解析。将定义好的Bean表示成IOC容器内部的数据结构,使IOC容器能够方便的对bean进行管理。
BeanDefinition的载入分两部分:首先通过调用XML解析器得到document对象,然后使用documentReader按照spring的bean规则进行解析。 - 注册BeanDefinition。通过调用BeanDefinitionRegistry接口的实现来完成。在IOC容器内部将BeanDefinition注入到一个HashMap中,IOC容器通过这个HashMap持有这些BeanDefinition。
Bean定义的载入和依赖注入是两个独立的过程。依赖注入一般发生在应用第一次通过getBean向容器索取Bean的时候。
例外是如果设置了lazyinit,这个bean则会在IOC容器初始化时就预先完成。
46.hadoop
Hadoop是一个由Apache基金会开发的分布式系统基础架构。
优势:
- 高可靠性:hadoop底层维护多个数据版本,即时某个计算元素或存储出现故障,也不会导致数据丢失
- 高扩展性:在即群间分配任务数据,可以方便的扩展数以千计的节点
- 高效性:在MapReduce的思想下,hadoop是并行工作的,以加快任务处理速度
- 高容错性:能够自动将失败的任务重新分配
hadoop组成:
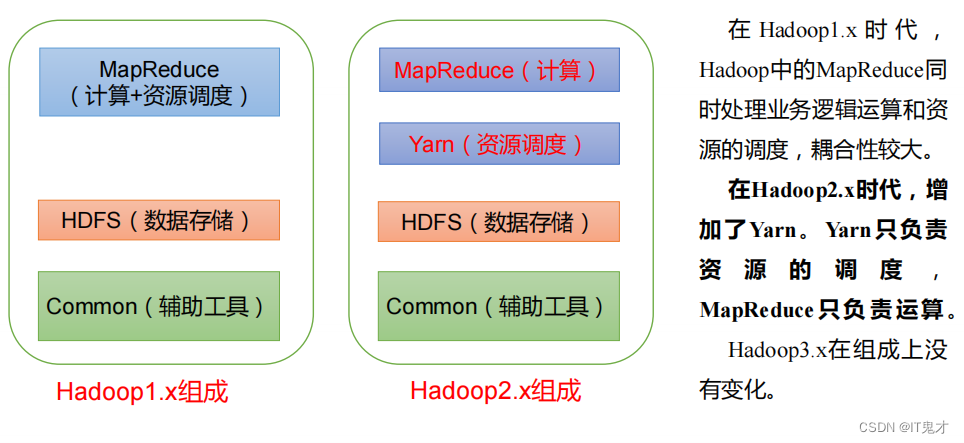
YARN:
Yet Another Resource Negotiator,另一种资源协调者,是 Hadoop 的资源管理器。
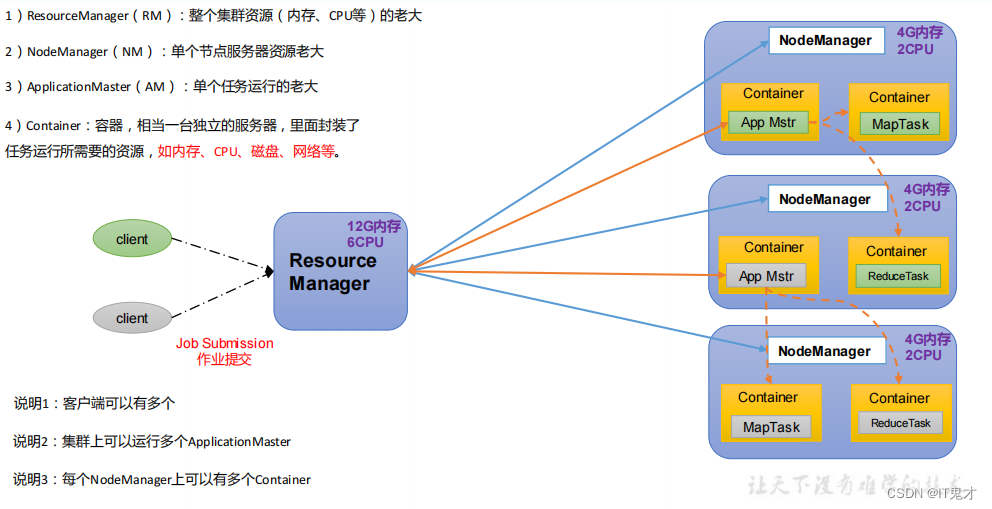
MapReduce:
MapReduce 将计算过程分为两个阶段: Map 和 Reduce
(1 ) Map 阶段并行处理输入数据。(将代码发送至数据存储的位置执行,如果分片大小超过HDFS的block大小,则会导致同一个分片的任务需要包括从另一个block到map任务节点的传输过程,降低了效率)
(2 ) Reduce 阶段对 Map 结果进行汇总。(将结果写入分布式存储)
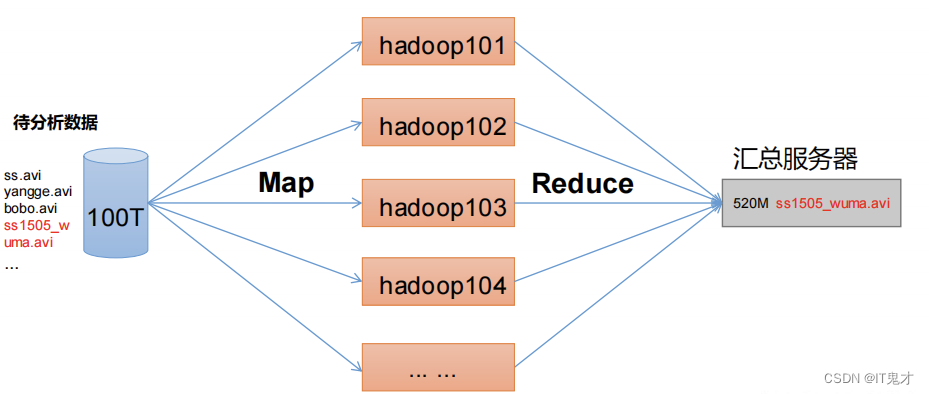
HDFS、YARN、MapReduce关系:
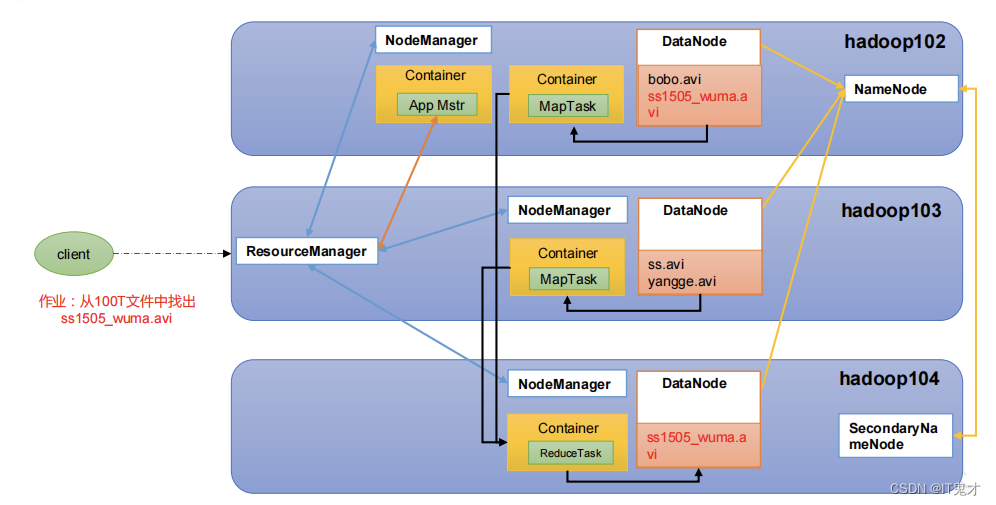
用户提交任务,任务给到ResourceManager,ResourceManager 会找一个节点NodeManager,开启一个Container ,把任务(App Mstr)放在Container App Mstr会向ResourceManager申请说自己需要多少资源 ResourceManager 看哪一个DataNode有资源,给他分配资源 之后 App Mstr 会在被分配的资源节点上开启计算任务(MapTask ),每个计算任务会向HDFS请求所需要的数据,这个其实就是MapReduce 的map阶段,之后会返回一个Reduce到各自对应的节点
47.Spark
spark是为大规模分布式数据处理而设计的一站式引擎,可以用于数据中心的物理机,也可以在云上使用。
spark为中间计算结果提供了基于内存的存储,比hadoop的MapReduce快了很多。
spark有四大特性:快速、易用、模块化、可扩展
48.红黑树
二叉搜索树:左子树节点都小于根节点,右子树节点都大于根节点。二叉搜索树容易退化为一条链表,查找时间复杂度会从降为。
平衡二叉树:平衡二叉树通过对高度差进行控制,避免了查找时间复杂度的的下降,基本维持在。但为了保持高度差不超过1,每次插入删除操作后都需要通过旋转保持平衡。在频繁插入删除的场景下,性能会有下降。
平衡二叉树的旋转:
左旋:如果root右子树比左子树高2,并且右子树的右子树比右子树的左子树高,则执行左旋转
右旋:如果root左子树比右子树高2,并且左子树的左子树比左子树的右子树高,则执行右旋转
左右旋转:如果root左子树比右子树高2,并且左子树的右子树比左子树的左子树高2,则先执行左旋转,再执行右旋转
右左旋转:如果root右子树比左子树高2, 并且右子树的左子树比右子树的右子树高2, 则执行右旋转后再执行左旋转
红黑树:红黑树通过牺牲严格的平衡,换取插入删除时少量的旋转操作。整体性能优于平衡二叉树:插入时的不平衡,不超过两次旋转可以解决;删除时的不平衡,不超过三次旋转可以解决。保证最坏的情况下,能在时间内完成查找。
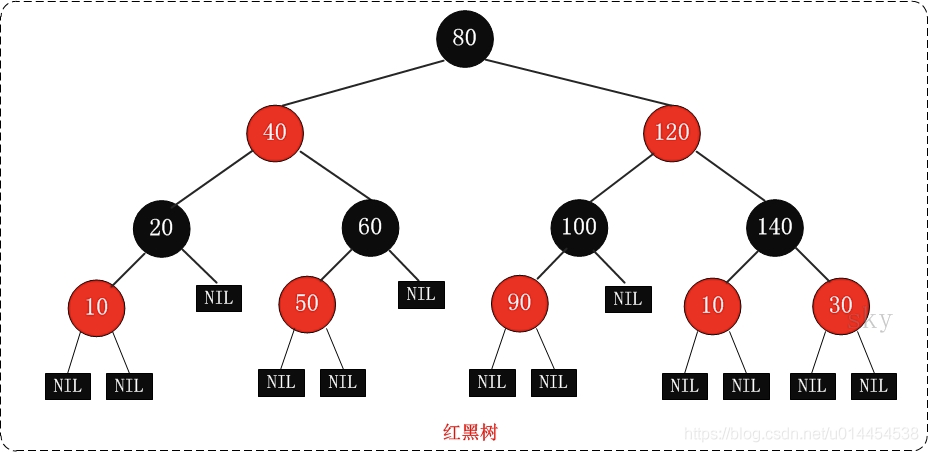
红黑规则:
- 节点不是黑色就是红色
- 根节点为黑色
- 叶子结点为黑色(即null节点)
- 一个节点为红色,则其两个子节点必须是黑色的
- 每个节点到叶子结点的所有路径都包含相同数目的黑色节点
49.MVCC
MVCC(Multi-Version Concurrency Control)即多版本并发控制。MVCC使得大部分支持行锁的事务引擎,不再单纯的使用行锁来进行数据库的并发控制,取而代之的是把数据库的行锁与行的多个版本结合起来,只需要很小的开销,就可以实现非锁定读,从而大大提高数据库系统的并发性能。
如果有人从数据库中读数据的同时,有另外的人写入数据,有可能读数据的人会看到『半写』或者不一致的数据。最简单的方法,通过加锁,让所有的读者等待写者工作完成,但是这样效率会很差。MVCC使用了一种不同的手段,每个连接到数据库的读者,在某个瞬间看到的是数据库的一个快照,写者写操作造成的变化在写操作完成之前(或者数据库事务提交之前)对于其他的读者来说是不可见的。
MVCC就像是Java语言中的接口,各个数据库厂商的实现机制不尽相同。可以认为MVCC是行级锁的一个变种,但是它在很多情况下避免了加锁操作,因此开销更低。虽然实现机制有所不同,但大都实现了非阻塞的读操作,写操作也只是锁定必要的行。MVCC会保存某个时间点上的数据快照。这意味着事务可以看到一个一致的数据视图,不管他们需要跑多久。这同时也意味着不同的事务在同一个时间点看到的同一个表的数据可能是不同的。前面说到不同的存储引擎的MVCC实现是不同的,典型的有乐观并发控制和悲观并发控制。
MVCC实现的读写不阻塞正如其名:多版本并发控制--->通过一定机制生成一个数据请求时间点的一致性数据快照(Snapshot),并用这个快照来提供一定级别(语句级或事务级)的一致性读取。从用户的角度来看,好像是数据库可以提供同一数据的多个版本。
Mysql的InnoDB引擎实现MVCC策略:
在每一行数据中有两个隐藏的列:当前行创建时的版本号和删除时的版本号(可能为空,其实还有一列称为回滚指针,用于事务回滚)。这里的版本号并不是实际的时间值,而是系统版本号。每开始新的事务,系统版本号都会自动递增。事务开始时刻的系统版本号会作为事务的版本号,用来和查询每行记录的版本号进行比较。每个事务又有自己的版本号,这样事务内执行CRUD操作时,就通过版本号的比较来达到数据版本控制的目的。
MVCC只在读已提交和可重复读两种隔离级别使用。RC中每次普通查询前都会生成一个视图,而RR只在第一次普通查询前生成视图。
快照读只在简单select操作中使用,不用加锁;其他复杂操作则使用当前读,保证其他事物不会修改该记录,保证安全性。
SELECT:只查找版本早于当前事务版本的数据行,要么是在事务开始前已经存在的,要么是事务自身插入或者修改过的。
INSERT:为新插入的每一行保存当前系统版本号作为行版本号。
DELETE:为删除的每一行保存当前系统版本号作为行删除标识。
UPDATE:插入一行新记录,保存当前系统版本号作为行版本号,同时保存当前系统版本号到原来的行作为删除标识。(实际是通过undolog备份旧记录)
每行数据中包含额外字段:
DATA_TRX_ID:最近更新该数据的事务ID
DATA_ROLL_PTR:指向undolog的指针
DATA_ROW_ID:聚集索引使用的行ID
DELETE_BIT:commit之前的逻辑删除标志位
事务更新值的操作:排它锁锁定行->记录redolog->将修改前的行复制为undolog->修改当前行,填写事务编号,修改回滚指针
50.类型擦除-泛型
Java的泛型是伪泛型,这是因为Java在编译期间,所有的泛型信息都会被擦掉,正确理解泛型概念的首要前提是理解类型擦除。Java的泛型基本上都是在编译器这个层次上实现的,在生成的字节码中是不包含泛型中的类型信息的,使用泛型的时候加上类型参数,在编译器编译的时候会去掉,这个过程成为类型擦除。
泛型编译过程中会擦除掉泛型信息。如ArrayList<Integer>编译后的对象类型就只是ArrayList,限定类型会被擦除,并且添加元素的时候使用的类型也是Object。
泛型转译:擦除后的泛型会使用其限定类型(没有指定的会使用Object)来替换,即原始类型,在字节码中的类型变量的真正类型。因此只要使泛型类型变量的类继承需要被限定的类型就可以在字节码中保留想要的类型。
