@Simon-Sun
2024-11-24T05:02:42.000000Z
字数 1971
阅读 250
搜索讲义
培训讲义
前置知识
1、递推
即利用递推式,有已知状态线性推导出未知状态的方式。
eg:求斐波那契数列的第 n 项
1、1、2、3、5、8……fn
由递推式
从前往后可以推出
2、递归
即函数调用本身的一种思想,可以将一些复杂的问题简单化。
eg:上一个问题用递归可由以下代码实现
int Fibonacci(int x ){if(x == 1) return 1 ;if(x == 2) return 1 ;return Fibonacci(x - 1) + Fibonacci(x - 2) ;}
在主函数中直接调用 即可解决问题。
由此可见递归的思想不需要转换思维方式,可以更直观的去解决问题。
这里需要注意一点,递归调用过程,实质上是不断调用函数的过程,由于递归调用一次,所有子程序的变量(局部变量、变参等)、地址在计算机内部都有用特殊的管理方法——栈(先进后出)来管理,一旦递归调用结束,计算机便开始根据栈中存储的地址返回各子程序变量的值,并进行相应操作。
每个算法题目都会给出相应的系统栈空间,当递归层数很大时,超出了栈空间,程序就会因为爆栈而崩溃。
注:可以用画图的方式去辅助理解递归的原理。可以提一嘴“搜索树”、“栈空间”的概念。
搜索
1、DFS(Depth First Search)
因为dfs的概念用语言是太不方便阐述的,建议大家先尝试尝试UVA524素数环这道题,这里为了方便大家理解,只要求解“n == 20 ,输出一个可行方案即可”。这个修改后的题目,后续我会提供给大家一个 用于检验自己的答案是否正确。
基本概念:
搜索树
如果把问题空间中的每一个状态定义为一个节点,递归过程定义成边,可以发现,整个搜索过程就会形成一棵树形的结构,称之为搜索树。
整个搜索过程就是在搜索树上实现的————为了避免重复访问,我们对状态进行记录和检索;
为使得搜索算法更加高效,提前剪去搜索树上一些肯定不是答案的分枝的操作即为“剪枝”。
(本身dfs的过程就比较难理解,一些没来参加培训的同学可能到这里也没看懂。我会找时间给未参加培训的同学再讲一遍的,所以不用担心)
迭代加深搜索(Iterative Deepening Search)
答案在4这个节点上。

设想一种情况若答案不在以一开始进入的节点为根的子树上,并且是在右侧的一个深度很浅的节点上。那么我们左侧所有的搜索过程是不是就是无用的,因为dfs是“一条路走到黑”的,不到搜索的边界是不会回溯的,如果左侧的这棵子树每个父节点都有很多子节点,如此一来,程序便被左侧这棵毫无意义的子树极大地消耗了时间,甚至有可能爆栈。
而迭代加深的思想就是————限制搜索节点的深度,如果当前节点的深度大于了我限制的深度,直接回溯。
然后“限制的深度”是递增的。由此我们可以发现,迭代加深的思想其实就是一个深搜和广搜的结合体,缝合怪。
也就是因为此,这个算法的的弊端也很多。因为每更改一次限制深度,我们就需要从根节点重新搜索,如果答案在深层的节点,浅层的节点就会被无意义的搜索很多遍。到最后复杂度甚至不如直接进行深搜来的优秀。
所以如果你可以确定答案一定在浅层的节点上,否则还是不要轻易用这个算法。
2、BFS(Breadth First Search)
广度优先算法的核心思想是:从初始节点开始,应用算符生成第一层节点,检查目标节点是否在这些后继节点中,若没有,再用产生式规则将所有第一层的节点逐一扩展,得到第二层节点,并逐一检查第二层节点中是否包含目标节点,若没有,再用算符逐一扩展第二层的所有节点···,如此依次扩展,检查下去,直到发现目标节点为止。
显然,bfs是以层进式的结构进行搜索的,同一层的节点全部扩展完成后,才能进入下一层。此时不难想到用队列的方式去存储每个节点。
注:如果没有学过队列,讲一下队列的基本结构。
queue是一个先进先出的数据结构,基于q的这个性质可以很容易实现层进式的搜索顺序,由此便可由一个节点“横向”扩展出整张图。也正因其横向扩展的方式,被称为“广度优先搜索”

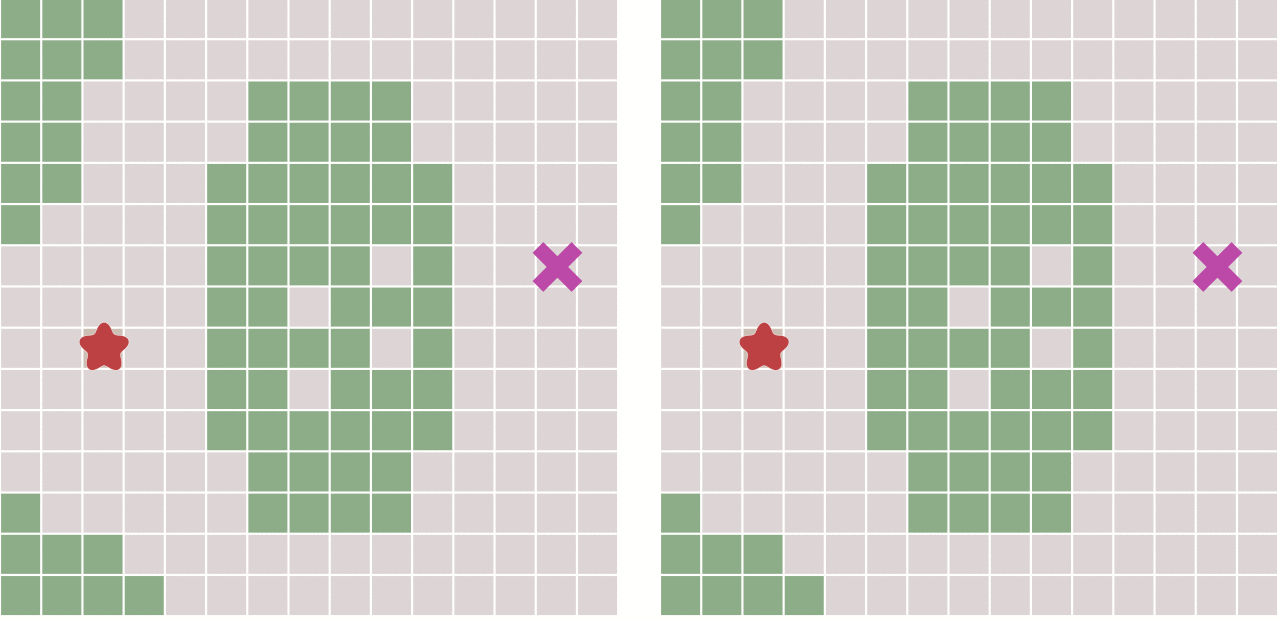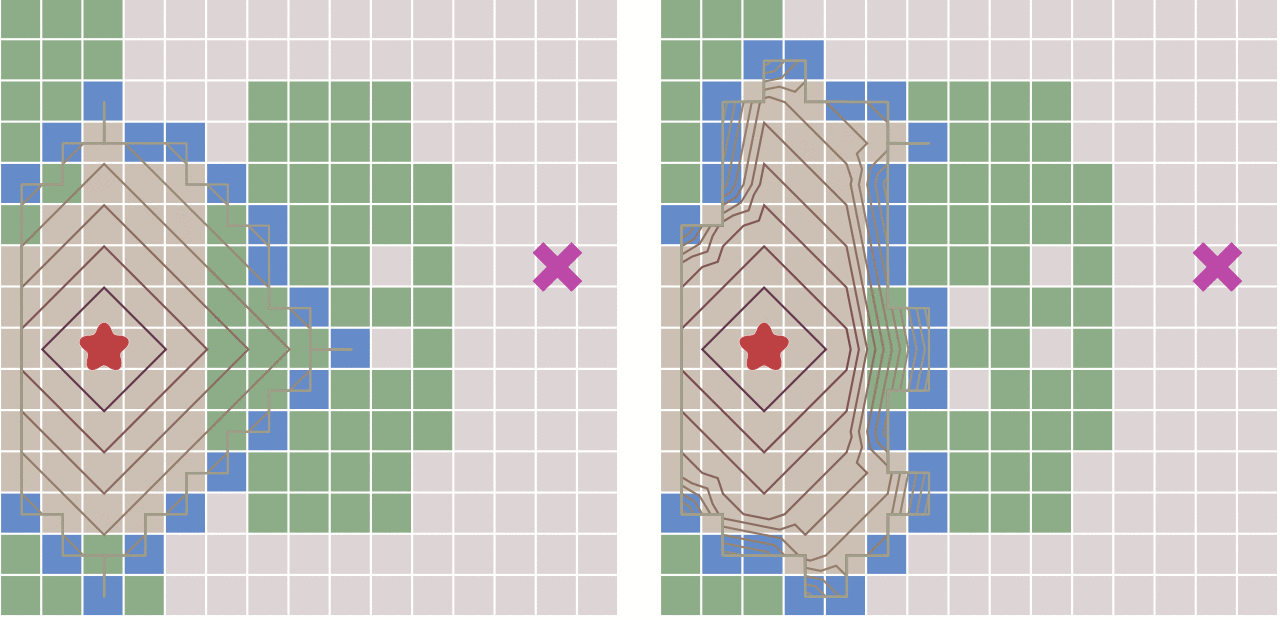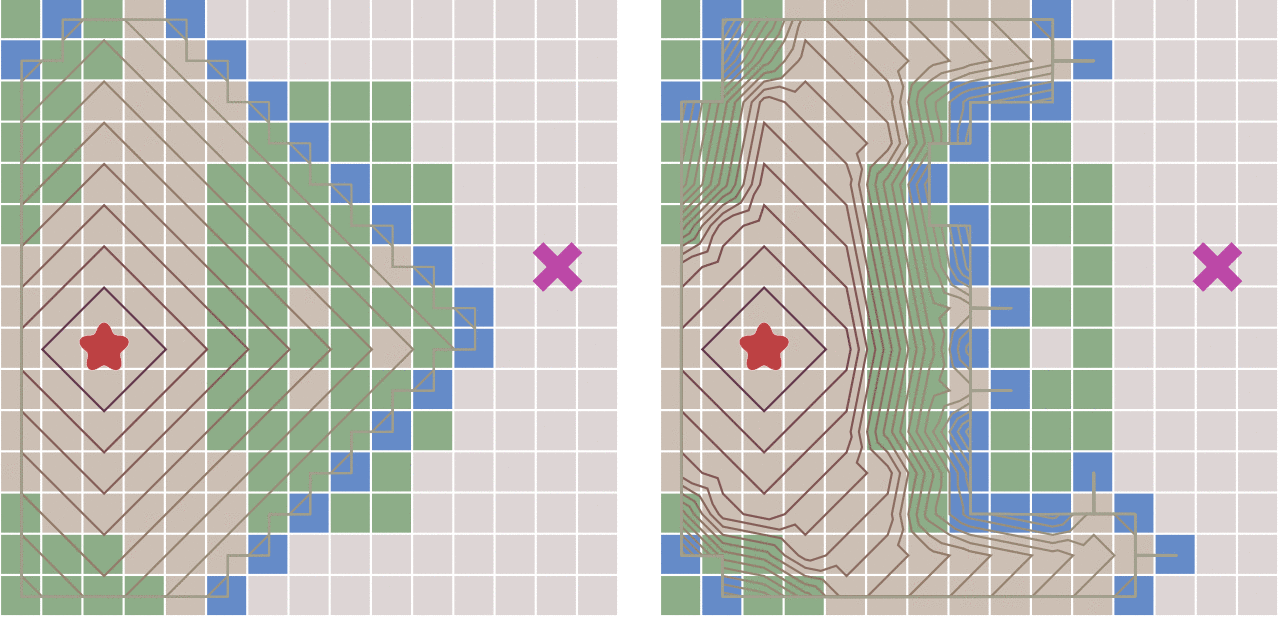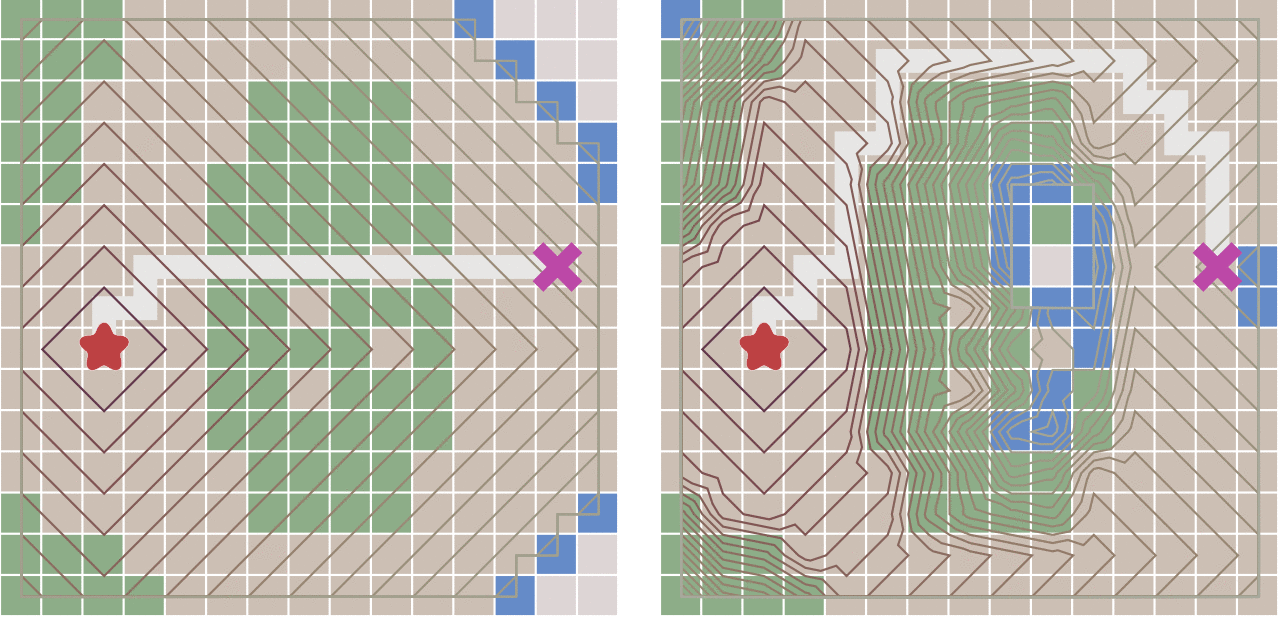
例题A、池塘计数
void bfs(int X , int Y){queue<pair<int , int> > q ;q.push({X , Y}) ;while(! q.empty()){int x = q.front().first , y = q.front().second ;q.pop() ;if(pd[x][y]) continue ;pd[x][y] = true ;for(int i = 0 ; i < 8 ; i++ ){int xx = x + wy[0][i] , yy = y + wy[1][i] ;if(xx < 1 || xx > n || yy < 1 || yy > m) continue ;if(mp[xx][yy] == '.') continue ;if(pd[xx][yy]) continue ;q.push({xx , yy}) ;}}}
