@adamhand
2018-12-23T05:07:28.000000Z
字数 24270
阅读 1358
Java集合
- 综述
- Collection
- List
- LinkedList
- ArrayList
- Vector
- Set
- HashSet
- TreeSet
- LinkedHashSet
- List
- Map
- 从Map中取出元素的几种方法
- HashMap
- 按Value排序
- 按Key排序
- Value去重
- HashMap线程安全
- LinkedHashMap
- TreeMap
- 源码分析
- List
- ArrayList
- LinkedList
- Vector
- CopyOnWriteArrayList
- Map
- HashMap
- ConcurrentHashMap
- LinkedHashMap
- WeakHashMap
- List
一. 集合综述
Java中的集合主要分为两种:Collection和Map。Collection存储的都是单个元素,而Map存储的都是键值对元素。比较常用的是Map和Collection下面的Set、List,它们可以称为集合的三大类。(注意:List中的元素可以重复,Set中的元素不可以重复,如果有两个元素相同,那么只能放进去一个,Map中的元素键不可以重复,值可以重复,如果键相同,值会覆盖)具体UML图如下:
Collection
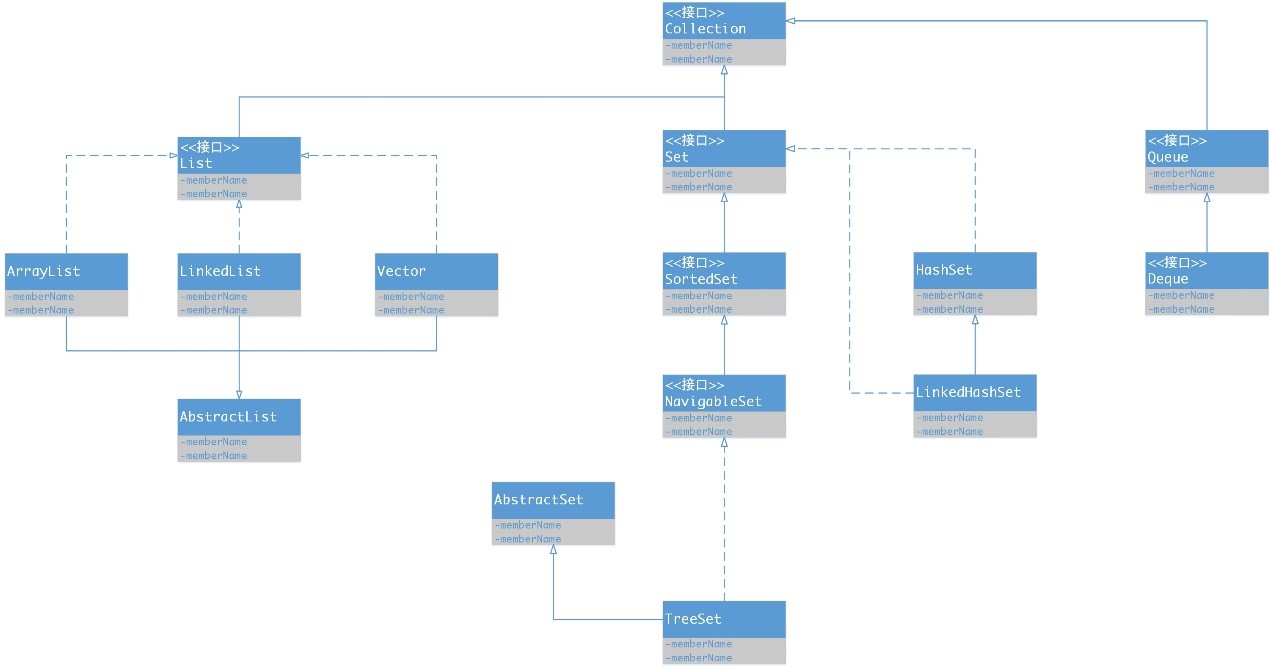
1. Set
- TreeSet:基于红黑树实现,支持有序性操作,例如根据一个范围查找元素的操作。但是查找效率不如 HashSet,HashSet 查找的时间复杂度为 O(1),TreeSet 则为 O(logN)。
- HashSet:基于哈希表实现,支持快速查找,但不支持有序性操作。并且失去了元素的插入顺序信息,也就是说使用 Iterator 遍历 HashSet 得到的结果是不确定的。
- LinkedHashSet:具有 HashSet 的查找效率,且内部使用双向链表维护元素的插入顺序。
2. List
- ArrayList:基于动态数组实现,支持随机访问。
- Vector:和 ArrayList 类似,但它是线程安全的。
- LinkedList:基于双向链表实现,只能顺序访问,但是可以快速地在链表中间插入和删除元素。不仅如此,LinkedList 还可以用作栈、队列和双向队列。
3. Queue
- LinkedList:可以用它来实现双向队列。
- PriorityQueue:基于堆结构实现,可以用它来实现优先队列。
Map
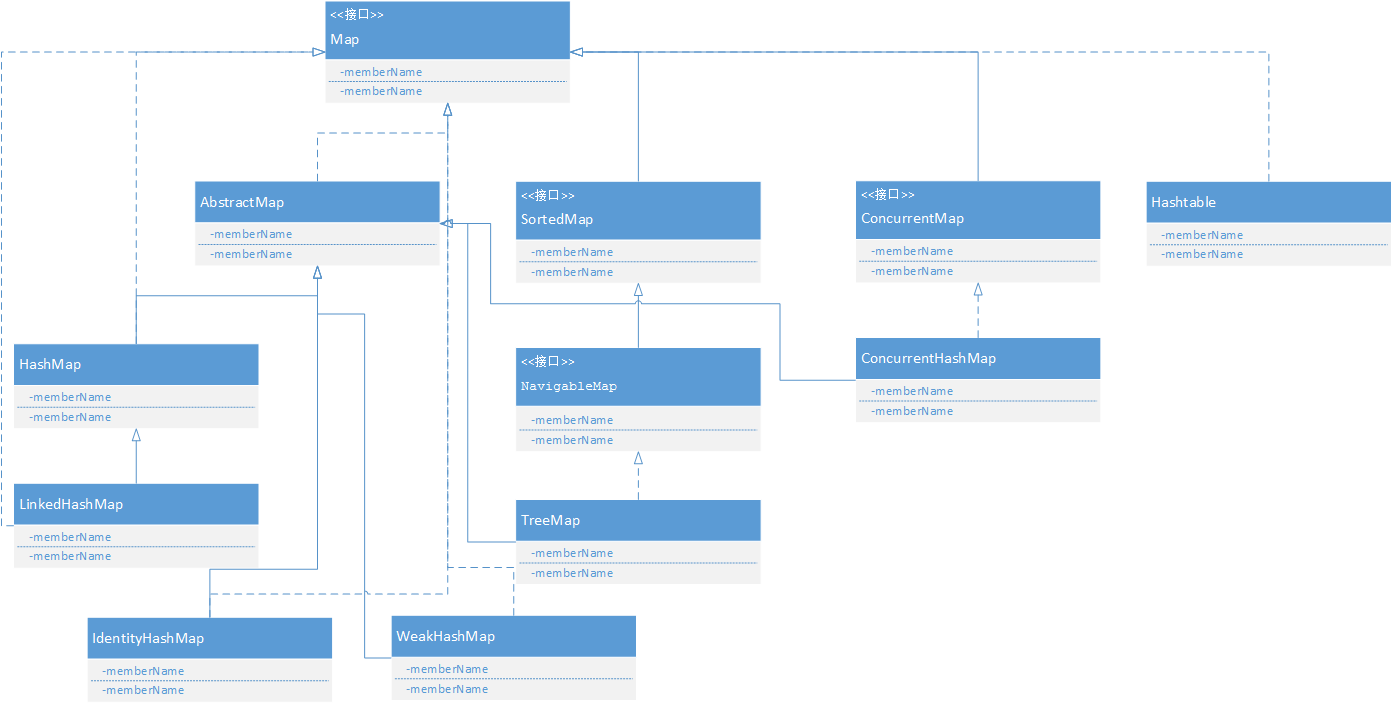
- TreeMap:基于红黑树实现。
- HashMap:基于哈希表实现。
- HashTable:和 HashMap 类似,但它是线程安全的,这意味着同一时刻多个线程可以同时写入 HashTable 并且不会导致数据不一致。它是遗留类,不应该去使用它。现在可以使用 ConcurrentHashMap 来支持线程安全,并且 ConcurrentHashMap 的效率会更高,因为 ConcurrentHashMap 引入了分段锁。
- LinkedHashMap:使用双向链表来维护元素的顺序,顺序为插入顺序或者最近最少使用(LRU)顺序。
二. Collection
Collection中常见的方法:
- 添加
boolean add (Object obj)boolean addAll (Collection coll)
- 删除
boolean remove (Object obj)boolean removeAll (Collection coll)void clear()
- 判断
boolean contains (Object obj)boolean containsAll (Collection coll)boolean isEmpty()
- 获取
int size()Iterator iterator()
Iterator对象必须依赖具体的容器,因为每一个容器的数据结构都不同,所以该容器的对象时在容器内部实现的。对于使用容器者而言,具体的实现并不重要,只要通过容器获取到该实现的迭代器的对象即可,也就是iterator方法。
- 其他
boolean retainAll(Collection coll);//取交集Object[] toArray();//将集合转化成数组
1. List
List中的元素是有序的(存入和取出的顺序一致),元素都有索引,而且可以重复。List中常用的方法有:

1.1 LinkedList
内部是链表数据结构,是不同步的,增删元素比较快。常用方法如下:
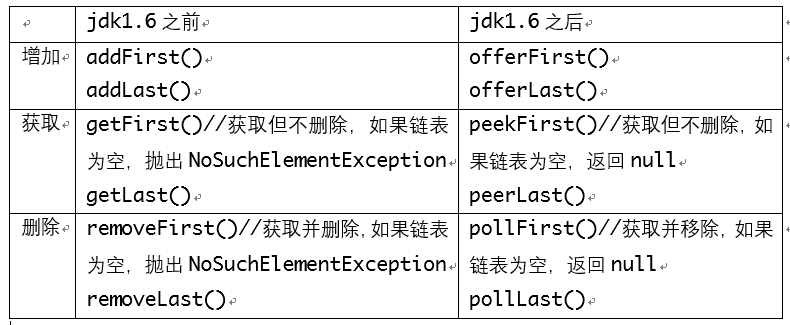
1.2. ArrayList
内部是数组的数据结构,是不同步的,查询速度比较快,代替了Vector。
1.3. Vector
内部是数组数据结构,是同步的,增删、查询都很慢。
2. Set
Set中的元素不可重复的,而且是无序的。
2.1 HashSet
内部是数据结构是哈希表,是不同步的。
HashSet是通过hashCode和equals方法来保证对象唯一性的。如果对象的hashCode不同,那么不用判断equals方法,就直接存储到哈希表中;如果对象的hashCode值相同,那么要再次判断对象的equals方法是否为true,若为true,视为相同元素,否则视为不同元素。
如果元素要存储到HashSet集合中,必须覆盖hashCode和equals方法;一般情况下,如果定义的类会产生很多对象,比如人、学生等,通常都需要覆盖hashCode和equals方法。
当然,hashCode和equals方法是哈希表需要的方法,所以后面的HashMap也要覆盖这两个方法。
2.2 TreeSet
TreeSet可以对Set集合中的元素进行排序,是不同步的。
TreeSet是通过比较方法的返回结果来判断对象是否相等的,如果比较方法返回结果为0,就是相同元素,不会被存储。
TreeSet对元素进行排序的方法有两种:
- 实现Comparable接口,覆盖compareTo方法。让元素本身具备比较功能。例子如下:
public class Person implements Comparable {private int age;private String name;public Person(int age, String name) {this.age = age;this.name = name;}public int getAge() {return age;}public String getName() {return name;}public void setAge(int age) {this.age = age;}public void setName(String name) {this.name = name;}@Overridepublic int compareTo(Object o) {Person p = (Person) o;int tem = this.age - p.age;return tem == 0 ? this.name.compareTo(p.name) : tem;}}/*** 是按照自然顺序来排序的,先按照年龄,然后按照名字的字典顺序*/public class TreeSetDemoOne {public static void main(String[] args) {Person p1 = new Person(12, "bob");Person p2 = new Person(13,"juliy");Person p3 = new Person(14,"jack");Person p4 = new Person(12,"rose");TreeSet t = new TreeSet();t.add(p1);t.add(p2);t.add(p3);t.add(p4);Iterator iterator = t.iterator();while(iterator.hasNext()){Person p = (Person) iterator.next();System.out.println(p.getAge()+" "+p.getName());}}}
输出结果为:
12 bob12 rose13 juliy14 jack
- 让元素具备比较能力的前提是元素本身存在自然顺序,但是如果元素不具备自然顺序或者我们不需要使用自然顺序进行排序,就要使用第二种方法。定义一个类实现Comparator接口,覆盖compare方法,将该类对象作为参数传递给TreeSet集合的构造函数。示例如下:
public class CompareByNameLen implements Comparator {@Overridepublic int compare(Object o1, Object o2) {Person p1 = (Person) o1;Person p2 = (Person) o2;int temp = p1.getName().length() - p2.getName().length();return temp == 0 ? p1.getAge() - p2.getAge() : temp;}}public class Person {private String name;private int age;public Person(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public int getAge() {return age;}public void setName(String name) {this.name = name;}public void setAge(int age) {this.age = age;}}/*** 先按照姓名长度排序,如果相同再按照年龄大小排序。*/public class DemoTwo {public static void main(String[] args) {Person p1 = new Person("bob",12);Person p2 = new Person("bobbo",14);Person p3 = new Person("bobbobo",15);Person p4 = new Person("bobboboobo",10);Person p5 = new Person("bob",10);TreeSet t = new TreeSet(new CompareByNameLen());t.add(p1);t.add(p2);t.add(p3);t.add(p4);t.add(p5);Iterator iterator = t.iterator();while (iterator.hasNext()){Person p = (Person) iterator.next();System.out.println(p.getAge()+ " "+p.getName());}}}
输出结果为:
10 bob12 bob14 bobbo15 bobbobo10 bobboboobo
2.3 LinkedHashSet
LinkedHashSet里面的元素是有顺序的,读出的顺序和写入的顺序一致。例子如下:
public class LinkedHashSetDemo {public static void main(String[] args) {Set<String> linkedHashSet = new LinkedHashSet<>();linkedHashSet.add("hahahah");linkedHashSet.add("hehaee");linkedHashSet.add("haeieieieieie");linkedHashSet.add("aafdfd");linkedHashSet.add("bfdhfjd");Iterator<String> iterator = linkedHashSet.iterator();while(iterator.hasNext()){System.out.println(iterator.next());}}}
输出接结果为:
hahahahhehaeehaeieieieieieaafdfdbfdhfjd
三. Map
Map集合与Collection集合的区别:
- Map集合中存储的是键值对;Collection中存储的是单个元素。
- Map中的存储使用的是put方法;Collection中存储使用的是add方法。
- Map取出元素,是将Map转成Set,再使用迭代器取出;Collection直接使用迭代器。
- 如果对象很多,必须使用容器存储;如果元素存在着映射关系,可以优先考虑使用Map或者数组存储;如果没有映射关系,优先考虑使用Collection存储。
1. 从Map中取出元素的几种方法
/*** map元素提取的几种方法。*/public class MapDemoOne {public static void main(String[] args) {Map<Integer, String> map = new HashMap<>();method(map);}public static void method(Map<Integer, String> map){map.put(8,"zhaoliu");map.put(2,"zhaoliu");map.put(2,"zhaoliu");map.put(5,"wngwu");/*** 使用map中的value,这种方法的缺陷是只能得到value*/Collection<String> values = map.values();Iterator<String> it = values.iterator();while(it.hasNext()){System.out.println(it.next());}System.out.println();/*** 使用map中的key*/Set<Integer> keySet = map.keySet();Iterator<Integer> it1 = keySet.iterator();while(it1.hasNext()){int key = it1.next();String value = map.get(key);System.out.println(key+" "+value);}System.out.println();/*** 使用entrySet。这个方法将key和value的映射关系存储到Set中,这个映射关系就是Map.Entry*/Set<Map.Entry<Integer, String>> entrySet = map.entrySet();Iterator<Map.Entry<Integer, String>> it2 = entrySet.iterator();while(it2.hasNext()){Map.Entry<Integer, String> me = it2.next();Integer key = me.getKey();String value = me.getValue();System.out.println(key+" "+value);}System.out.println();/*** 使用for each循环*/for(Map.Entry<Integer, String> entry : map.entrySet()){System.out.println(entry.getKey()+" "+entry.getValue());}System.out.println();for(Integer key : map.keySet()){System.out.println(key+" "+map.get(key));}}}
2 HashMap
2.1 按Value排序
注意student类中要实现hashCode和equals方法。
/*** 按照Key排序*/public class HashMapDemo {public static void main(String[] args) {HashMap<Integer, String> hs = new HashMap<>();hs.put(23,"张三");hs.put(24,"李四");hs.put(25,"王五");hs.put(21,"bob");hs.put(22,"alice");sortHashMap(hs);}public static void sortHashMap(Map<Integer, String> hashMap){//1.用HashMap构造一个LinkedListSet<Map.Entry<Integer, String>> set = hashMap.entrySet();LinkedList<Map.Entry<Integer, String>> linkedList = new LinkedList<>(set);//2.用Collection的sort方法排序Collections.sort(linkedList, new Comparator<Map.Entry<Integer, String>>() {@Overridepublic int compare(Map.Entry<Integer, String> o1, Map.Entry<Integer, String> o2) {return o1.getValue().compareTo(o2.getValue());}});//3.将排序后的LinkedList赋值LinkedHashMapMap<Integer, String> map = new LinkedHashMap<>();for(Map.Entry<Integer, String> entry : linkedList){map.put(entry.getKey(), entry.getValue());}for(Map.Entry<Integer, String> entry : map.entrySet()){System.out.println(entry.getKey()+" "+entry.getValue());}}}
2.2 按key排序
(1)和按value排序差不多,唯一的区别就是在比较的时候变为key的比较。
(2)因为TreeMap是按照key排列的,所以可以利用TreeMap来对HashMap进行排序。
/*** 利用TreeMap对HashMap的key进行排序*/public class HashMapDemoTwo {public static void main(String[] args) {HashMap<Integer, String> hs = new HashMap<>();hs.put(23,"张三");hs.put(24,"李四");hs.put(25,"王五");hs.put(21,"bob");hs.put(22,"alice");sortHashMapByKey(hs);}public static void sortHashMapByKey(Map<Integer, String> hashMap){TreeMap<Integer, String> treeMap = new TreeMap<>(new Comparator<Integer>() {@Overridepublic int compare(Integer o1, Integer o2) {return Integer.compare(o1, o2);}});treeMap.putAll(hashMap);for(Map.Entry<Integer, String> entry : treeMap.entrySet()){System.out.println(entry.getKey()+" "+entry.getValue());}}}
2.3 Value去重
使用containsValue方法实现去重:
/*** value去重*/public class HashMapDemoThree {public static void main(String[] args) {HashMap<Integer, String> hs = new HashMap<>();hs.put(23,"张三");hs.put(24,"张三");hs.put(25,"王五");hs.put(21,"bob");hs.put(22,"alice");System.out.println(hs.toString());hs = method(hs);System.out.println(hs.toString());}public static HashMap<Integer, String> method(HashMap<Integer, String> hs){HashMap<Integer, String> hashMap = new HashMap<>();for(Integer key : hs.keySet()){if(!hashMap.containsValue(hs.get(key)))hashMap.put(key, hs.get(key));}return hashMap;}}
2.4 HashMap线程同步
- 方法一:
Map<Integer , String> hs = new HashMap<Integer , String>();hs = Collections.synchronizedMap(hs);
- 方法二:
ConcurrentHashMap<Integer , String> hs = new ConcurrentHashMap<Integer , String>();
3. LinkedHashMap
4. TreeMap
四. 源码分析
List
ArrayList
1. 概览
实现了 RandomAccess 接口,因此支持随机访问。在ArrayList中,我们即可以通过元素的序号快速获取元素对象;这就是快速随机访问。这是理所当然的,因为 ArrayList 是基于数组实现的。
public class ArrayList<E> extends AbstractList<E>implements List<E>, RandomAccess, Cloneable, java.io.Serializable
关键属性。
//数组的默认大小为10private static final int DEFAULT_CAPACITY = 10;//一个空数组。当用户指定该 ArrayList 容量为 0 时,返回该空数组。见构造函数private static final Object[] EMPTY_ELEMENTDATA = {};/*** 一个空数组实例* 当用户没有指定 ArrayList 的容量时(即调用无参构造函数),返回的是该数组。刚创建一个 ArrayList 时,其内数据量为 0。* 当用户第一次添加元素时,该数组将会扩容,变成默认容量为 10(DEFAULT_CAPACITY) 的一个数组===>通过 ensureCapacityInternal() 实现* 它与 EMPTY_ELEMENTDATA 的区别就是:该数组是默认返回的,而后者是在用户指定容量为 0 时返回。见构造函数。*/private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};/*** ArrayList基于数组实现,用该数组保存数据, ArrayList 的容量就是该数组的长度* 该值为 DEFAULTCAPACITY_EMPTY_ELEMENTDATA 时,当第一次添加元素进入 ArrayList 中时,数组将扩容至 DEFAULT_CAPACITY(10)* 那么,该数组为什么被transient修饰?transient表示一个域不属于该对象序列化的一部分,但是ArrayList又是能够被序列化的,这样的话,在反序列化的时候,ArrayList中的值不是就会丢失了吗?玄机在于ArrayList中的两个方法:writeObject()和readObject()(这里就不贴出来了,详见第5点,序列化)。ArrayList在序列化的时候会调用writeObject,直接将size和element写入ObjectOutputStream;反序列化时调用readObject,从ObjectInputStream获取size和element,再恢复到elementData。为什么不直接用elementData来序列化,而采用上诉的方式来实现序列化呢?原因在于elementData是一个缓存数组,它通常会预留一些容量,等容量不足时再扩充容量,那么有些空间可能就没有实际存储元素,采用上诉的方式来实现序列化时,就可以保证只序列化实际存储的那些元素,而不是整个数组,从而节省空间和时间。*/transient Object[] elementData; // non-private to simplify nested class access
2. 扩容
添加元素时使用 ensureCapacityInternal() 方法来保证容量足够,如果不够时,需要使用 grow() 方法进行扩容,新容量的大小为 oldCapacity + (oldCapacity >> 1),也就是旧容量的 1.5 倍。
扩容操作需要调用 Arrays.copyOf() 把原数组整个复制到新数组中,这个操作代价很高,因此最好在创建 ArrayList 对象时就指定大概的容量大小,减少扩容操作的次数。
public boolean add(E e) {ensureCapacityInternal(size + 1); // Increments modCount!!elementData[size++] = e;return true;}private void ensureCapacityInternal(int minCapacity) {if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);}ensureExplicitCapacity(minCapacity);}private void ensureExplicitCapacity(int minCapacity) {modCount++;// overflow-conscious codeif (minCapacity - elementData.length > 0)grow(minCapacity);}private void grow(int minCapacity) {// overflow-conscious codeint oldCapacity = elementData.length;int newCapacity = oldCapacity + (oldCapacity >> 1);if (newCapacity - minCapacity < 0)newCapacity = minCapacity;if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);// minCapacity is usually close to size, so this is a win:elementData = Arrays.copyOf(elementData, newCapacity);}
3. 删除元素
需要调用 System.arraycopy() 将 index+1 后面的元素都往前移动,该操作的时间复杂度为 O(N),可以看出 ArrayList 删除元素的代价是非常高的。
public E remove(int index) {rangeCheck(index);modCount++;E oldValue = elementData(index);int numMoved = size - index - 1;if (numMoved > 0)System.arraycopy(elementData, index+1, elementData, index, numMoved);elementData[--size] = null; // clear to let GC do its workreturn oldValue;}
4. Fail-Fast
fail-fast 机制,即快速失败机制,是java集合(Collection)中的一种错误检测机制。当在迭代集合的过程中该集合在结构上发生改变的时候,就有可能会发生fail-fast,即抛出ConcurrentModificationException异常。fail-fast机制并不保证在不同步的修改下一定会抛出异常,它只是尽最大努力去抛出,所以这种机制一般仅用于检测bug。
modCount 用来记录 ArrayList 结构发生变化的次数。结构发生变化是指添加或者删除至少一个元素的所有操作,或者是调整内部数组的大小,仅仅只是设置元素的值不算结构发生变化。
在进行序列化或者迭代等操作时,需要比较操作前后 modCount 是否改变,如果改变了需要抛出 ConcurrentModificationException。
private void writeObject(java.io.ObjectOutputStream s)throws java.io.IOException{// Write out element count, and any hidden stuffint expectedModCount = modCount;s.defaultWriteObject();// Write out size as capacity for behavioural compatibility with clone()s.writeInt(size);// Write out all elements in the proper order.for (int i=0; i<size; i++) {s.writeObject(elementData[i]);}if (modCount != expectedModCount) {throw new ConcurrentModificationException();}}
5. 序列化
ArrayList 基于数组实现,并且具有动态扩容特性,因此保存元素的数组不一定都会被使用,那么就没必要全部进行序列化。
保存元素的数组 elementData 使用 transient 修饰,该关键字声明数组默认不会被序列化。
为了防止一个包含大量空对象的数组被序列化,为了优化存储,所以,ArrayList使用transient来声明elementData。 但是,作为一个集合,在序列化过程中还必须保证其中的元素可以被持久化下来,所以,通过重写writeObject 和 readObject方法的方式把其中的元素保留下来。
transient Object[] elementData; // non-private to simplify nested class access
ArrayList 实现了 writeObject() 和 readObject() 来控制只序列化数组中有元素填充那部分内容。
private void readObject(java.io.ObjectInputStream s)throws java.io.IOException, ClassNotFoundException {elementData = EMPTY_ELEMENTDATA;// Read in size, and any hidden stuffs.defaultReadObject();// Read in capacitys.readInt(); // ignoredif (size > 0) {// be like clone(), allocate array based upon size not capacityensureCapacityInternal(size);Object[] a = elementData;// Read in all elements in the proper order.for (int i=0; i<size; i++) {a[i] = s.readObject();}}}private void writeObject(java.io.ObjectOutputStream s)throws java.io.IOException{// Write out element count, and any hidden stuffint expectedModCount = modCount;s.defaultWriteObject();// Write out size as capacity for behavioural compatibility with clone()s.writeInt(size);// Write out all elements in the proper order.for (int i=0; i<size; i++) {s.writeObject(elementData[i]);}if (modCount != expectedModCount) {throw new ConcurrentModificationException();}}
序列化时需要使用 ObjectOutputStream 的 writeObject() 将对象转换为字节流并输出。而 writeObject() 方法在传入的对象存在 writeObject() 的时候会去反射调用该对象的 writeObject() 来实现序列化。反序列化使用的是 ObjectInputStream 的 readObject() 方法,原理类似。
ArrayList list = new ArrayList();ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(file));oos.writeObject(list);
Vector
1. 同步
它的实现与 ArrayList 类似,但是使用了 synchronized 进行同步。
public synchronized boolean add(E e) {modCount++;ensureCapacityHelper(elementCount + 1);elementData[elementCount++] = e;return true;}public synchronized E get(int index) {if (index >= elementCount)throw new ArrayIndexOutOfBoundsException(index);return elementData(index);}
2. 与 ArrayList 的比较
- Vector 是同步的,因此开销就比 ArrayList 要大,访问速度更慢。最好使用 ArrayList 而不是 Vector,因为同步操作完全可以由程序员自己来控制;
- Vector 每次扩容请求其大小的 2 倍空间,而 ArrayList 是 1.5 倍。
3. 替代方案
可以使用 Collections.synchronizedList(); 得到一个线程安全的 ArrayList。
List<String> list = new ArrayList<>();List<String> synList = Collections.synchronizedList(list);
也可以使用 concurrent 并发包下的 CopyOnWriteArrayList 类。
List<String> list = new CopyOnWriteArrayList<>();
CopyOnWriteArrayList
1. 概述
Copy-On-Write简称COW,是一种用于程序设计中的优化策略。其基本思路是,从一开始大家都在共享同一个内容,当某个人想要修改这个内容的时候,才会真正把内容Copy出去形成一个新的内容然后再改,这是一种延时懒惰策略。从JDK1.5开始Java并发包里提供了两个使用CopyOnWrite机制实现的并发容器,它们是CopyOnWriteArrayList和CopyOnWriteArraySet。CopyOnWrite容器非常有用,可以在非常多的并发场景中使用到。
2. 什么是CopyOnWrite容器
CopyOnWrite容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁(注意,写还是要加锁的),因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。具体过程如下:
当有新元素加入的时候,如下图,创建新数组,并往新数组中加入一个新元素,这个时候,array这个引用仍然是指向原数组的。
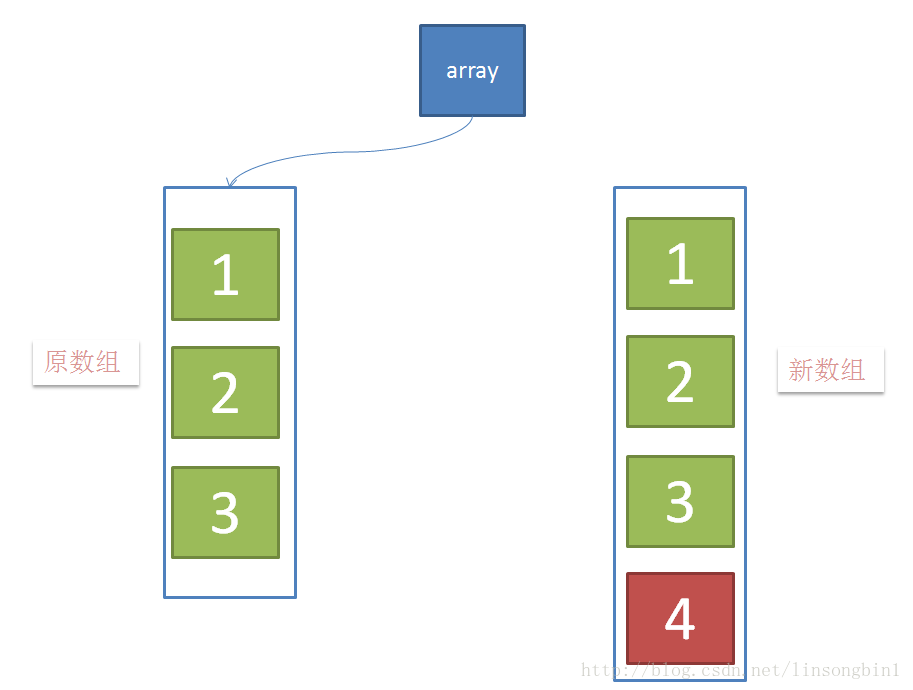
当元素在新数组添加成功后,将array这个引用指向新数组。
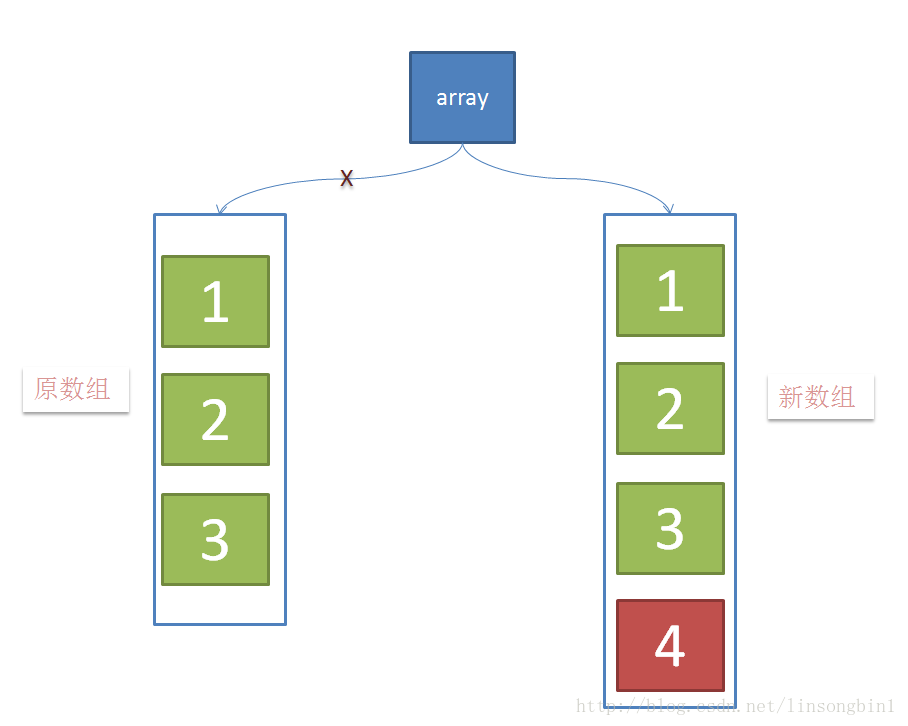
3. 写操作
CopyOnWriteArrayList的整个add操作都是在锁的保护下进行的。
这样做是为了避免在多线程并发add的时候,复制出多个副本出来,把数据搞乱了,导致最终的数组数据不是我们期望的。
public boolean add(T e) {final ReentrantLock lock = this.lock;lock.lock();try {Object[] elements = getArray();int len = elements.length;// 复制出新数组Object[] newElements = Arrays.copyOf(elements, len + 1);// 把新元素添加到新数组里newElements[len] = e;// 把原数组引用指向新数组setArray(newElements);return true;} finally {lock.unlock();}}final void setArray(Object[] a) {array = a;}
4. 读操作
由于所有的写操作都是在新数组进行的,这个时候如果有线程并发的写,则通过锁来控制,如果有线程并发的读,则分几种情况:
(1)如果写操作未完成,那么直接读取原数组的数据;
(2)如果写操作完成,但是引用还未指向新数组,那么也是读取原数组数据;
(3)如果写操作完成,并且引用已经指向了新的数组,那么直接从新数组中读取数据。
可见,CopyOnWriteArrayList的读操作是可以不用加锁的。
public E get(int index) {return get(getArray(), index);}
5. 使用场景
&emsp; 通过上面的分析,CopyOnWriteArrayList 有几个缺点:
(1)由于写操作的时候,需要拷贝数组,会消耗内存,如果原数组的内容比较多的情况下,可能导致young gc或者full gc
(2)不能用于实时读的场景,像拷贝数组、新增元素都需要时间,所以调用一个set操作后,读取到数据可能还是旧的,虽然CopyOnWriteArrayList 能做到最终一致性,但是还是没法满足实时性要求;
CopyOnWriteArrayList 合适读多写少的场景,不过这类慎用,因为谁也没法保证CopyOnWriteArrayList 到底要放置多少数据,万一数据稍微有点多,每次add/set都要重新复制数组,这个代价实在太高昂了。在高性能的互联网应用中,这种操作分分钟引起故障。
6. 自己实现CopyOnWriteMap
JDKCopyOnWriteMap,但是可以模仿CopyOnWriteArrayList写一个:
import java.util.Collection;import java.util.Map;import java.util.Set;public class CopyOnWriteMap<K, V> implements Map<K, V>, Cloneable {private volatile Map<K, V> internalMap;public CopyOnWriteMap() {internalMap = new HashMap<K, V>();}public V put(K key, V value) {synchronized (this) {Map<K, V> newMap = new HashMap<K, V>(internalMap);V val = newMap.put(key, value);internalMap = newMap;return val;}}public V get(Object key) {return internalMap.get(key);}public void putAll(Map<? extends K, ? extends V> newData) {synchronized (this) {Map<K, V> newMap = new HashMap<K, V>(internalMap);newMap.putAll(newData);internalMap = newMap;}}}
7. 透露的思想
- 读写分离,读和写分开
- 最终一致性
- 使用另外开辟空间的思路,来解决并发冲突
LinkedList
Map
HashMap
详见“HashMap--从jdk1.7到jdk1.8”
ConcurrentHashMap
详见“ConcurrentHashMap--从jdk1.7到jdk1.8”
LinkedHashMap
LinkedHashMap继承自HashMap,所以很多特性和HashMap中一样,不同的是LinkedHashMap使用双链表来维护节点之间的先后关系。下面主要叙述LinkedHashMap和HashMap的不同。
1. LinkedHashMap的成员变量
private static final long serialVersionUID = 3801124242820219131L;// 用于指向双向链表的头部transient LinkedHashMap.Entry<K,V> head;//用于指向双向链表的尾部transient LinkedHashMap.Entry<K,V> tail;/*** 用来指定LinkedHashMap的迭代顺序,* true则表示按照基于访问的顺序来排列,意思就是**最近使用的entry,放在链表的最末尾*** false则表示按照插入顺序来*/final boolean accessOrder;
可以看到,LinkedHashMap支持的遍历顺序有两个:插入顺序和访问顺序。具体的区别可以看下面的例子:
public static void testLinkedList(){//非accessOrder模式,迭代顺序为插入顺序HashMap<String, Integer> map = new LinkedHashMap<>();map.put("s1", 1);map.put("s2", 2);map.put("s3", 3);map.put("s4", 4);map.put("s5", 5);map.put(null, 9);map.put("s6", 6);map.put("s7", 7);map.put("s8", 8);map.put(null, 11);for(Map.Entry<String,Integer> entry:map.entrySet()){System.out.println(entry.getKey()+":"+entry.getValue());}System.out.println(map);System.out.println();//accessOrder模式,迭代顺序为最近访问顺序HashMap<String, Integer> map1 = new LinkedHashMap<>(16, 0.75f, true);map1.put("s1", 1);map1.put("s2", 2);map1.put("s3", 3);map1.put("s4", 4);map1.put("s5", 5);map1.put(null, 9);map1.put("s6", 6);map1.put("s7", 7);map1.put("s8", 8);map1.put(null, 11);for(Map.Entry<String,Integer> entry:map1.entrySet()){System.out.println(entry.getKey()+":"+entry.getValue());}System.out.println(map1);}
输入结果为:
s1:1s2:2s3:3s4:4s5:5null:11s6:6s7:7s8:8{s1=1, s2=2, s3=3, s4=4, s5=5, null=11, s6=6, s7=7, s8=8}s1:1s2:2s3:3s4:4s5:5s6:6s7:7s8:8null:11{s1=1, s2=2, s3=3, s4=4, s5=5, s6=6, s7=7, s8=8, null=11}
注意:如果将上面accessOrder中的的遍历方式改为:
for(Iterator<String> iterator = map.keySet().iterator();iterator.hasNext();){String name = iterator.next();System.out.println(name+"->"+map.get(name));}
结果会报错:
s1->1Exception in thread "main" java.util.ConcurrentModificationExceptionat java.util.LinkedHashMap$LinkedHashIterator.nextEntry(Unknown Source)at java.util.LinkedHashMap$KeyIterator.next(Unknown Source)at collections.map.LinkedHashMapTest.main(LinkedHashMapTest.java:33)
这是因为在accessOrder模式下,get()方法会修改LinkedHashMap中的链表结构(具体见下main的get()方法解析),以便将最近访问的元素放置到链表的末尾,因此,这个操作在集合迭代过程中修改了集合的元素,就会发生报错。所以,当LinkedHashMap工作在这个模式时,不能再迭代器中使用get()操作。Map的遍历建议使用entrySet的方式。
2. LinkedHashMap的构造方法
跟HashMap类似的构造方法这里就不一一赘述了,里面唯一的区别就是添加了前面提到的accessOrder,默认赋值为false——按照插入顺序来排列,这里主要说明一下不同的构造方法。
//多了一个 accessOrder的参数,用来指定按照LRU排列方式还是顺序插入的排序方式public LinkedHashMap(int initialCapacity,float loadFactor,boolean accessOrder) {super(initialCapacity, loadFactor);this.accessOrder = accessOrder;}
3. 三个重点实现的函数
在HashMap中提到了下面的定义:
// Callbacks to allow LinkedHashMap post-actionsvoid afterNodeAccess(Node<K,V> p) { }void afterNodeInsertion(boolean evict) { }void afterNodeRemoval(Node<K,V> p) { }
LinkedHashMap继承于HashMap,因此也重新实现了这3个函数,顾名思义这三个函数的作用分别是:节点访问后、节点插入后、节点移除后做一些事情,即分别用于get()操作、put()操作、remove()操作之后的后序操作。
下面通过分析get()、put()和remove()操作来分析这三个函数的作用。
get()方法
get()方法的源码如下:
public V get(Object key) {Node<K,V> e;//调用HashMap的getNode的方法,详见HashMap源码解析if ((e = getNode(hash(key), key)) == null)return null;//在取值后对参数accessOrder进行判断,如果为true,执行afterNodeAccessif (accessOrder)afterNodeAccess(e);return e.value;}
从上面的代码可以看到,LinkedHashMap的get方法,调用HashMap的getNode方法后,对accessOrder的值进行了判断,之前提到:
accessOrder为true则表示按照基于访问的顺序来排列,意思就是最近使用的entry,放在链表的最末尾
由此可见,afterNodeAccess(e)就是基于访问的顺序排列的关键,让我们来看一下它的代码:
//此函数执行的效果就是将最近使用的Node,放在链表的最末尾void afterNodeAccess(Node<K,V> e) {LinkedHashMap.Entry<K,V> last;//仅当按照LRU原则且e不在最末尾,才执行修改链表,将e移到链表最末尾的操作if (accessOrder && (last = tail) != e) {//将e赋值临时节点p, b是e的前一个节点, a是e的后一个节点LinkedHashMap.Entry<K,V> p =(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;//设置p的后一个节点为null,因为执行后p在链表末尾,after肯定为nullp.after = null;//p前一个节点不存在,情况一if (b == null) // ①head = a;elseb.after = a;if (a != null)a.before = b;//p的后一个节点不存在,情况二else // ②last = b;//情况三if (last == null) // ③head = p;//正常情况,将p设置为尾节点的准备工作,p的前一个节点为原先的last,last的after为pelse {p.before = last;last.after = p;}//将p设置为将p设置为尾节点tail = p;// 修改计数器+1++modCount;}}
标注的情况如下图所示(特别说明一下,这里是显示链表的修改后指针的情况,实际上在桶里面的位置是不变的,只是前后的指针指向的对象变了):
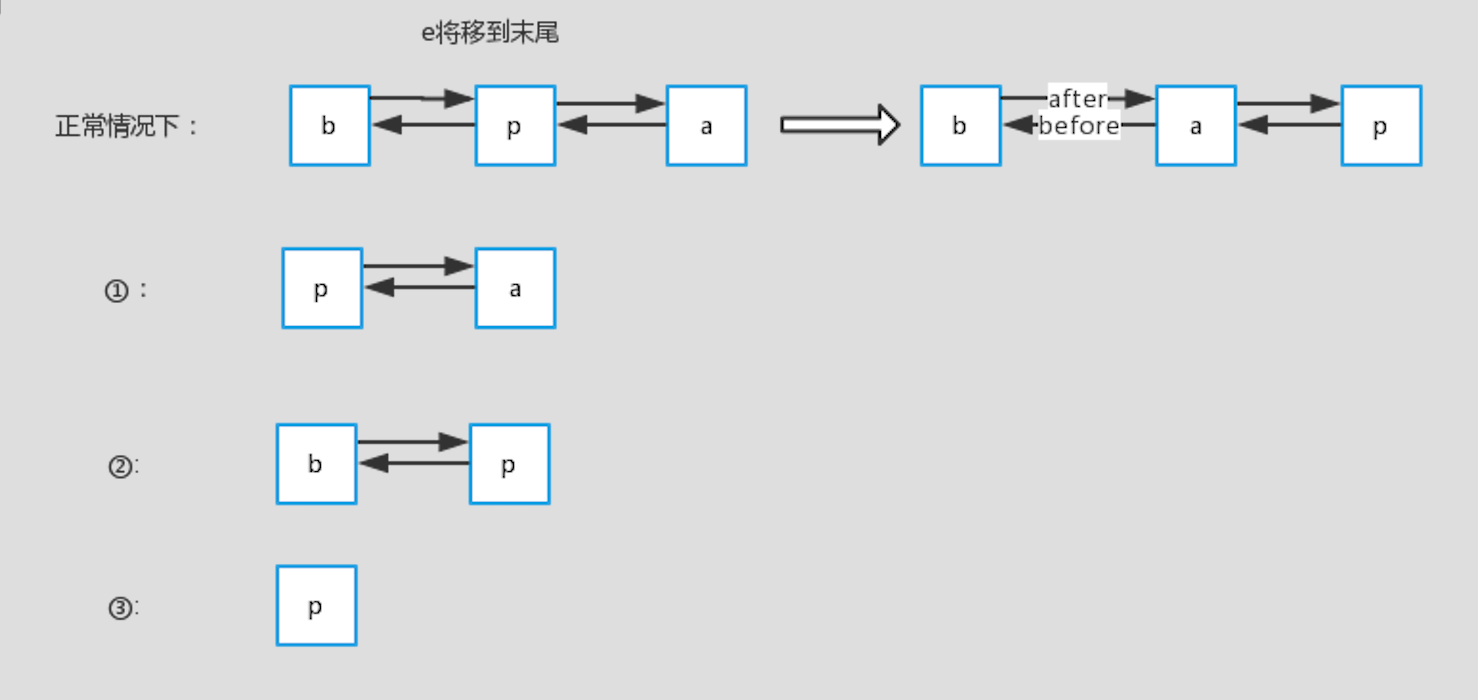
下面来简单说明一下:
- 正常情况下:查询的p在链表中间,那么将p设置到末尾后,它原先的前节点b和后节点a就变成了前后节点。
- 情况一:p为头部,前一个节点b不存在,那么考虑到p要放到最后面,则设置p的后一个节点a为head
- 情况二:p为尾部,后一个节点a不存在,那么考虑到统一操作,设置last为b
- 情况三:p为链表里的第一个节点,head=p
put()方法
接下来看一下LinkedHashMap是怎么插入Entry的:LinkedHashMap的put方法调用的还是HashMap里的put,不同的是重写了里面的部分方法:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {...tab[i] = newNode(hash, key, value, null);...e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);...if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);...afterNodeAccess(e);...afterNodeInsertion(evict);return null;}
省略部分的代码可以参考HashMap的put方法。LinkedHashMap将其中newNode方法以及之前设置下的钩子方法afterNodeAccess和afterNodeInsertion进行了重写,从而实现了加入链表的目的:
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {//秘密就在于 new的是自己的Entry类,然后调用了linkedNodeLastLinkedHashMap.Entry<K,V> p =new LinkedHashMap.Entry<K,V>(hash, key, value, e);linkNodeLast(p);return p;}//顾名思义就是把新加的节点放在链表的最后面private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {//将tail给临时变量lastLinkedHashMap.Entry<K,V> last = tail;//把new的Entry给tailtail = p;//若没有last,说明p是第一个节点,head=pif (last == null)head = p;//否则就做准备工作,你懂的 ( ̄▽ ̄)"else {p.before = last;last.after = p;}}//这里笔者也把TreeNode的重写也加了进来,因为putTreeVal里有调用了这个TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next) {TreeNode<K,V> p = new TreeNode<K,V>(hash, key, value, next);linkNodeLast(p);return p;}//插入后把最老的Entry删除,不过removeEldestEntry总是返回false,所以不会删除,估计又是一个钩子方法给子类用的void afterNodeInsertion(boolean evict) {LinkedHashMap.Entry<K,V> first;if (evict && (first = head) != null && removeEldestEntry(first)) {K key = first.key;removeNode(hash(key), key, null, false, true);}}protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {return false;}
remove()方法
remove里面设计者也设置了一个钩子方法:
final Node<K,V> removeNode(int hash, Object key, Object value,boolean matchValue, boolean movable) {...//node即是要删除的节点afterNodeRemoval(node);...}
这个方法的源码如下:
void afterNodeRemoval(Node<K,V> e) {//与afterNodeAccess一样,记录e的前后节点b,aLinkedHashMap.Entry<K,V> p =(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;//p已删除,前后指针都设置为null,便于GC回收p.before = p.after = null;//与afterNodeAccess一样类似,一顿判断,然后b,a互为前后节点if (b == null)head = a;elseb.after = a;if (a == null)tail = b;elsea.before = b;}
4. 迭代器
迭代器LinkedHashIterator的源码及注释如下:
abstract class LinkedHashIterator {//记录下一个EntryLinkedHashMap.Entry<K,V> next;//记录当前的EntryLinkedHashMap.Entry<K,V> current;//记录是否发生了迭代过程中的修改int expectedModCount;LinkedHashIterator() {//初始化的时候把head给nextnext = head;expectedModCount = modCount;current = null;}public final boolean hasNext() {return next != null;}//这里采用的是链表方式的遍历方式,有兴趣的园友可以去上一章看看HashMap的遍历方式final LinkedHashMap.Entry<K,V> nextNode() {LinkedHashMap.Entry<K,V> e = next;if (modCount != expectedModCount)throw new ConcurrentModificationException();if (e == null)throw new NoSuchElementException();//记录当前的Entrycurrent = e;//直接拿after给nextnext = e.after;return e;}public final void remove() {Node<K,V> p = current;if (p == null)throw new IllegalStateException();if (modCount != expectedModCount)throw new ConcurrentModificationException();current = null;K key = p.key;removeNode(hash(key), key, null, false, false);expectedModCount = modCount;}}
5. 补充:LRU方法
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。是内存不够的场景下,淘汰旧内容的策略。
以下是使用 LinkedHashMap 实现的一个 LRU 缓存:
- 设定最大缓存空间 MAX_ENTRIES 为 3;
- 使用 LinkedHashMap 的构造函数将 accessOrder 设置为 true,开启 LRU 顺序;
- 覆盖 removeEldestEntry() 方法实现,在节点多于 MAX_ENTRIES 就会将最近最久未使用的数据移除。
public class LCUCache {static class LRUCache<K, V> extends LinkedHashMap<K, V> {private static final int MAX_ENTRIES = 3;protected boolean removeEldestEntry(Map.Entry eldest) {return size() > MAX_ENTRIES;}LRUCache() {super(MAX_ENTRIES, 0.75f, true);}}public static void main(String[] args) {LRUCache<Integer, String> cache = new LRUCache<>();cache.put(1, "a");cache.put(2, "b");cache.put(3, "c");cache.get(1);cache.put(4, "d");System.out.println(cache.keySet());}}
输入结果为:
[3, 1, 4]
