@anboqing
2016-01-11T02:17:43.000000Z
字数 6068
阅读 11380
Caffe官方教程 :Blobs,Layers,Nets: caffe模型解剖
Caffe教程
本文译自官方文档,权当练英语了,请各位英文好看官移步官网自行阅读
引言
深度神经网络是一种聚合模型,可以自然的表示为作用于数据块上的内部相连的网络. Caffe用自己的建模方法将网络一层一层定义出来。网络由输入数据到损失层把整个模型自底向上的定义出来。数据和偏导数在网络中前向、后向流动。Caffe使用blob存储、交换、操纵这些信息。blob是整个框架的标准的数组结构和统一存储接口。layer作为建模和计算的基础,net作为layer的集合和链接。blob的细节描述了信息是怎样在layers和nets间存储和交换的.
Blob 存储和通信
Blob 是Caffe处理和传输的真实数据的包装类,同时它还隐含提供了在CPU和GPU之间同步数据的能力。在数学上,一个blob就是一个N维的数组,它是按照c语言风格存储的。(其实就是行优先还是列优先的风格,参照wiki:row-major order).
caffe使用blob存储和交换数据。blob对不同数据提供了统一的内存接口;例如:一批图片,模型参数,优化过程的偏导数等。
Blob通过在需要时将数据从CPU同步到GPU来隐藏在GPU/CPU之间进行混合操作的计算开销和精力开销.host 和device上的内存都是惰性分配的,从而能够高效使用存储空间。
传统的图片数据维数为图片数量N x 通道数K x 高度H x 宽度W。由于Blob的内存布局是行优先,所以最右边/后边的维度变化的最快。例如,在一个4D的blob里,下标(n,k,h,w)在物理内存中位于下标((n*K+k)*H+h)*W+w).
- Number / N 是数据的 batch size.批处理能获得更大的在GPU设备上的吞吐量。例如,对于ImageNet数据训练一批256个图片,N=256.
- 通道数 / K 是 feature dimension, 例如RGB图片就是3通道的 K = 3.灰度 K=1
注意,尽管Caffe样例中的大多数blob都是4D的带坐标的图片应用,在非图片应用使用Blob也是完全可以的。例如,你仅仅需要一个全连接网络(比如传统多层感知机),使用一个2D的blob(shape(N,D)),调用InnerProductLayer就可以了。
参数blob的维度随着layer的配置和类型变化。例如,对一个有96个filters,每个filter有11X11的空域维度和3个输入的卷积层,它的blob维数为: 96 x 3 x 11 x 11.
对于一个有着1000个输出和1024个输入的内积 / 全连接layer,它的参数blob是1000 x 1024。
对于定制的数据,可能需要自己手工编写输入数据预处理工具或者数据层。但是一旦你的数据准备好了,剩下的工作就交给Caffe了。
实现细节
由于我们经常对blob的值和梯度感兴趣,所以blob存储了2块data和diff.前者是正常的传输数据,后者是网络计算的梯度。
更进一步,由于真实数据可能存储在CPU或者GPU上,有2种方式来访问它们:const方式,不能修改值;mutable方式,可以修改值:
const Dtype* cpu_data() const;Dtype* mutable_cpu_data();
(gpu 和 diff接口类似)。
这样设计的原因是:Blob使用了SyncedMem类来同步CPU和GPU之间的数据以便隐藏同步细节,同时最小化host和device之间的数据交换。第一原则是:当你不需要修改值的时候总是使用const方式,并且绝对不要在你自己的对象里存储指针。没当你使用一个blob的时候,调用上面的函数来获取数据指针,这时SyncedMem就会需要根据这个指针来判断什么时候去复制数据。(这个功能怎么实现的,很有意思,等看完代码再分析)。
在实践中如果使用了GPU,你从磁盘上吧数据读取到CPU模式的内存中的blob里,然后调用GPU的kernel来进行计算,然后把blob数据传给下一层,这一切过程都隐藏了底层的实现细节,并且获得很高的性能。只要所有层都有GPU实现,所有的中间数据和梯度都会保存在GPU中。
如果你像检查什么时候Blob会复制数据,这里有一个演示:
// 假设数据初始在CPU模式下,我们有一个blob.const Dtype* foo;Dtype* bar;foo = blob.gpu_data(); // 数据从 cpu 复制到 gpufoo = blob.cpu_data(); // 没有数据拷贝,因为cpu 和gpu都有最新的数据内容bar = blob.mutable_gpu_data(); // 没有数据拷贝// .. 一些操作 ..bar = blob.mutable_gpu_data(); // 没有数据拷贝,因为仍然处在 GPU上foo = blob.cpu_data(); // 数据从gpu->cpu,因为gpu上修改了数据foo = blob.gpu_data(); // 没有数据拷贝,因为都有最新内容bar = blob.mutable_cpu_data(); // still no data copiedbar = blob.mutable_gpu_data(); // data copied cpu->gpubar = blob.mutable_cpu_data(); // 数据从gpu->cpu
层的连接和计算
layer是一个模型的精华所在,它也是计算的基本单元。layer包括了filter过滤,pool池化,进行inner product计算,应用诸如rectified-linear和sigmoid等元素级的非线性变换,正则化,读取数据,计算诸如softmax或hinge等代价损失。查看Layer catalogue获取全部操作。大部分最新的深度学习任务都在那里。
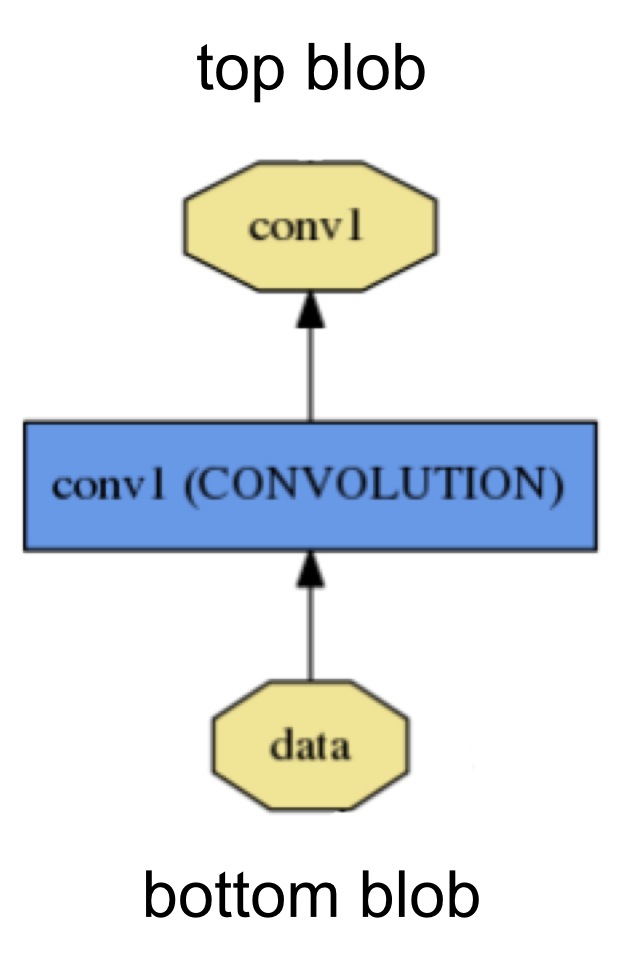
每个layer都定义了3个关键的计算操作:setup,forward和backward.
- Setup: 在模型初始化的时候初始化
layer和它的connections - Forward: 从底层给出输入并计算输出,然后发送给顶层
- Backward: 给出顶层输出的梯度,计算输入的梯度,然后发送给底层。一个有参数的层会计算关于参数的梯度然后在内部存储这些梯度。
更详细的说,caffe将会实现2个Forward和Backward函数,一个给CPU,另一个给GPU.如果你没有实现GPU版本,那么layer就会退化成CPU函数作为一个后备选项。
如果你要做快速实验,这个会用起来很顺手,尽管它会造成附加的数据传输开销(它的输入会从GPU复制到CPU,并且它的输出会从CPU拷贝到GPU);
layer在把网络当做整体进行操作的时候有两个关键责任:前向传播从输入计算输出,反向传播获取输出的梯度,然后根据参数向前计算输入的梯度,这些梯度再依次向前传播。这些过程都是简单的前向传播和后向传播的组合。
开发自己定义的层需要一点很小的努力,需要学习网络的组织和代码的模块画。定义每层的setup,forward,backward,然后你定义的这个层就可以包含进一个网络了。
网络定义和操作
net通过组合和自动求导联合定义了一个函数和它的导数.把每一层output组合起来计算一个特定任务的函数,把每一层的backward组合起来从loss计算梯度来学习该任务。Caffe模型是端对端的机器学习引擎。(这个和Theano类似的)
net可以看做一个由layers组成的计算图(computation graph),确切的说是一个有向无环图。Caffe为所有层做了所有bookkeeping的工作来保证前向传播和后向传播的正确性。典型的net由一个从磁盘读取数据的数据层开始,以一个loss层结束,是计算诸如分类或者重构之类的目标任务的。
net用普通文本建模语言protocol buffer被定义为一组layer和它们之间的连接,一个简单的 logistic regression 分类器如下:
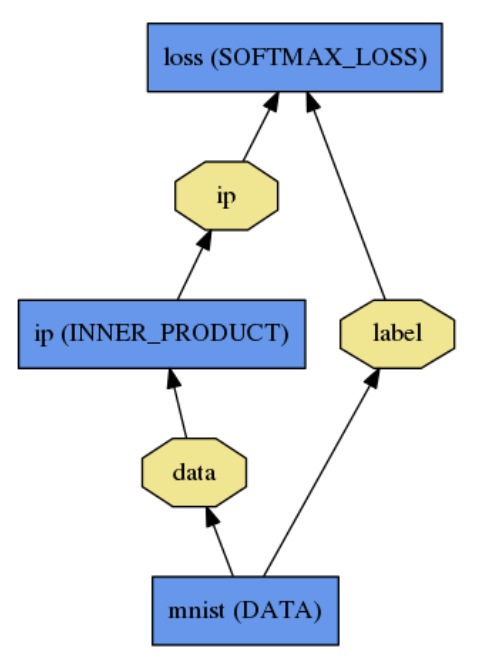
定义为:
name: "LogReg"layer {name: "mnist"type: "Data"top: "data"top: "label"data_param {source: "input_leveldb"batch_size: 64}}layer {name: "ip"type: "InnerProduct"bottom: "data"top: "ip"inner_product_param {num_output: 2}}layer {name: "loss"type: "SoftmaxWithLoss"bottom: "ip"bottom: "label"top: "loss"}
模型初始化由函数Net::Init()处理。初始化主要做了2件事:创建blobs和layers架起整个DAG(对c++使用者:在整个生命周期里network会持有blobs和layers的所有权),并且调用layer的Setup()函数。它同样做了一系列其他的准备工作,例如验证整个网络结构的正确性。同样,在初始化的过程中,Net会通过日志解释它的初始化工作,像这样:
I0902 22:52:17.931977 2079114000 net.cpp:39] Initializing net from parameters:name: "LogReg"[...model prototxt printout...]# construct the network layer-by-layerI0902 22:52:17.932152 2079114000 net.cpp:67] Creating Layer mnistI0902 22:52:17.932165 2079114000 net.cpp:356] mnist -> dataI0902 22:52:17.932188 2079114000 net.cpp:356] mnist -> labelI0902 22:52:17.932200 2079114000 net.cpp:96] Setting up mnistI0902 22:52:17.935807 2079114000 data_layer.cpp:135] Opening leveldb input_leveldbI0902 22:52:17.937155 2079114000 data_layer.cpp:195] output data size: 64,1,28,28I0902 22:52:17.938570 2079114000 net.cpp:103] Top shape: 64 1 28 28 (50176)I0902 22:52:17.938593 2079114000 net.cpp:103] Top shape: 64 (64)I0902 22:52:17.938611 2079114000 net.cpp:67] Creating Layer ipI0902 22:52:17.938617 2079114000 net.cpp:394] ip <- dataI0902 22:52:17.939177 2079114000 net.cpp:356] ip -> ipI0902 22:52:17.939196 2079114000 net.cpp:96] Setting up ipI0902 22:52:17.940289 2079114000 net.cpp:103] Top shape: 64 2 (128)I0902 22:52:17.941270 2079114000 net.cpp:67] Creating Layer lossI0902 22:52:17.941305 2079114000 net.cpp:394] loss <- ipI0902 22:52:17.941314 2079114000 net.cpp:394] loss <- labelI0902 22:52:17.941323 2079114000 net.cpp:356] loss -> loss# set up the loss and configure the backward passI0902 22:52:17.941328 2079114000 net.cpp:96] Setting up lossI0902 22:52:17.941328 2079114000 net.cpp:103] Top shape: (1)I0902 22:52:17.941329 2079114000 net.cpp:109] with loss weight 1I0902 22:52:17.941779 2079114000 net.cpp:170] loss needs backward computation.I0902 22:52:17.941787 2079114000 net.cpp:170] ip needs backward computation.I0902 22:52:17.941794 2079114000 net.cpp:172] mnist does not need backward computation.# determine outputsI0902 22:52:17.941800 2079114000 net.cpp:208] This network produces output loss# finish initialization and report memory usageI0902 22:52:17.941810 2079114000 net.cpp:467] Collecting Learning Rate and Weight Decay.I0902 22:52:17.941818 2079114000 net.cpp:219] Network initialization done.I0902 22:52:17.941824 2079114000 net.cpp:220] Memory required for data: 201476
注意构建网络是和设备无关的,回忆前面解释blob和layer的时候他们也在构建的时候隐藏了实现细节。构建完成之后,网络就可以在CPU或者GPU上运行,只需要调用Caffe::mode()就能切换,Caffe::set_mode()是用来设置mode的函数。在GPU或者CPU上运行的过程会产生相同的结果。CPU和GPU可以无缝切换并且和模型定义无关。对研究和部署来说,把模型和实现分离是最好的方案。
模型格式
模型是用普通文本文件存储的protocol buffer schema(存在prototxt文件里),学习到的模型是被序列化为二进制格式的protocol buffer(binaryproto),存在caffemodel文件里。
模型格式是定义在caffe.proto文件里的。这个文件基本上是自解释的,推荐初学者仔细阅读它。
Most important tip...
Don’t be afraid to read the code!
