@contribute
2016-08-29T02:17:02.000000Z
字数 32541
阅读 6015
图的遍历
tinkerpop3
赵亮
weston_contribute@163.com
版权所有
北京太观科技有限公司
摘要
- 图的遍历
- 摘要
- 图遍历步骤
- AddEdge
- AddVertex
- AddProperty
- Aggregate
- And
- As
- Barrier
- By
- Cap
- Coalesce
- Count
- Choose
- Coin
- Constant
- CyclicPath
- Dedup
- Drop
- Explain
- Fold
- Group
- GroupCount
- Has
- Inject
- Is
- Limit
- Local
- Match
- Max
- Mean
- Min
- Or
- Order
- Path
- Profile
- Range
- Repeat
- Sack
- Sample
- Select
- SimplePath
- Store
- Subgraph
- Sum
- Tail
- TimeLimit
- Tree
- Unfold
- Union
- ValueMap
- Vertex Steps
- Where
- 判断语句
Gremlin 是操作图表的一个非常有用的图灵完备的编程语言。它是一种Java DSL语言,对图表进行查询、分析和操作时使用了大量的XPath。本文对gremlin语言的step进行简单的翻译及解释,也可以参考Tinkerpop的 官方英文文档 。
在最一般的情况下,遍历就是Traversal<S,E>,它实现了Iterator<E>接口,其中S代表开始,E代表结束。一个遍历由以下四种组件组成:
1. Step<S,E>:将S产生E的一个独立功能。一个遍历有多个step级联组成。
2. TraversalStrategy:改变遍历执行的拦截方法。(例如:查询重写)。
3. TraversalSideEffects:用于存储关于遍历的全局信息的键值对。
4. Traverser<T>:在当前的Traversal中传播的对象,T代表处理的对象。
GraphTraversal<S,E>提供了一个图遍历的经典概念,它继承的Traversal<S,E>。提供了通过点、边等图术语对图数据的解释。
The underlying Step implementations provided by TinkerPop should encompass most of the functionality required by a DSL author. It is important that DSL authors leverage the provided steps as then the common optimization and decoration strategies can reason on the underlying traversal sequence. If new steps are introduced, then common traversal strategies may not function properly.
图遍历步骤
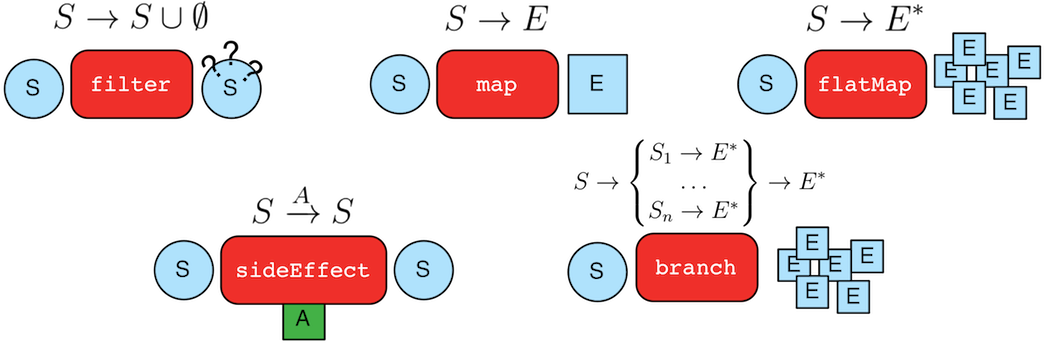
GraphTraversal<S,E>由GraphTraversalSource大量产生,也可以由__匿名产生。一个图遍历是由一个有step组成的有序列表构成。
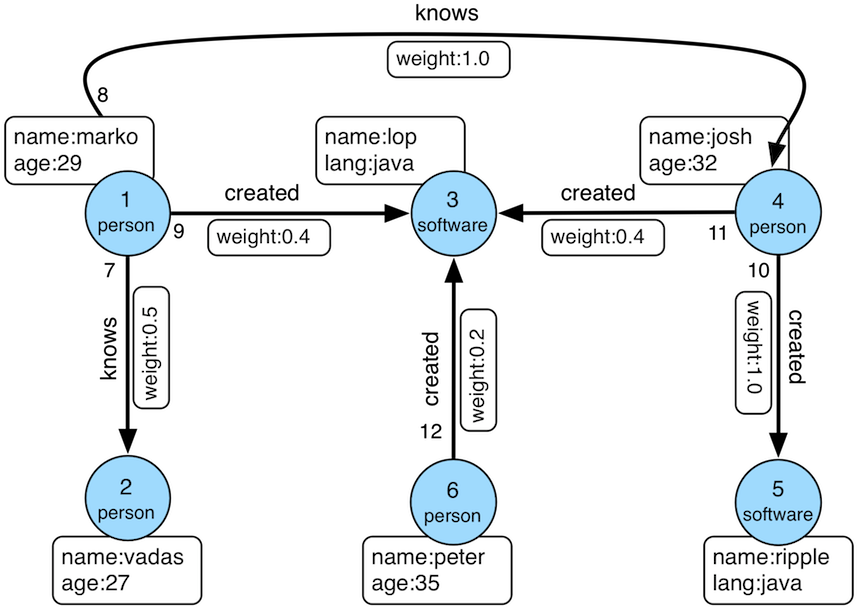
文中的例子使用的图结构关系如下:
AddEdge
推理论证就是将不明确的东西明晰化,在图数据库中明确的东西的就是对象(顶点和边),不明晰的就是遍历。换句话说就是通过遍历定义揭示其中的意义。例如我们拿合作者的概念来说,如果两个人一起参与同一个项目,那么这两个人就是合作者。这个概念可以用遍历来描述。而且不明晰的关系可以通过addE()来明晰化。

gremlin> g.V(1).as('a').out('created').in('created').where(neq('a')).addE('co-developer').from('a').property('year',2009) //(1)==>e[12][1-co-developer->4]==>e[13][1-co-developer->6]gremlin> g.V(3,4,5).aggregate('x').has('name','josh').as('a').select('x').unfold().hasLabel('software').addE('createdBy').to('a') //(2)==>e[14][3-createdBy->4]==>e[15][5-createdBy->4]gremlin> g.V().as('a').out('created').addE('createdBy').to('a').property('acl','public') //(3)==>e[16][3-createdBy->1]==>e[17][5-createdBy->4]==>e[18][3-createdBy->4]==>e[19][3-createdBy->6]gremlin> g.V(1).as('a').out('knows').addE('livesNear').from('a').property('year',2009).inV().inE('livesNear').values('year') //(4)==>2009==>2009gremlin> g.V().match(__.as('a').out('knows').as('b'),__.as('a').out('created').as('c'),__.as('b').out('created').as('c')).addE('friendlyCollaborator').from('a').to('b').property(id,13).property('project',select('c').values('name')) //(5)==>e[13][1-friendlyCollaborator->4]gremlin> g.E(13).valueMap()==>[project:lop]
AddVertex
#添加一个类型为person的顶点g.addV('person').property('name','stephen')
# 在边上添加一个顶点()g.V().outE('knows').addV().property('name','nothing')
查询了g.V(14).valueMap()并没有看到属性name=nothing。
AddProperty
在顶点上添加一个属性
gremlin> g.V(1).property('country','usa')==>v[1]
在顶点上添加多个属性
gremlin> g.V(1).property('city','santa fe').property('state','new mexico').valueMap()==>[country:[usa], city:[santa fe], name:[marko], state:[new mexico], age:[29]]
在顶点上的一个属性添加多个值
gremlin> g.V(1).property(list,'age',35) //(1)==>v[1]gremlin> g.V(1).valueMap()==>[country:[usa], city:[santa fe], name:[marko], state:[new mexico], age:[29, 35]]
为顶点上的一个属性添加私有的访问控制权限
gremlin> g.V(1).property('friendWeight',outE('knows').values('weight').sum(),'acl','private') //(2)==>v[1]gremlin> g.V(1).properties('friendWeight').valueMap() //(3)==>[acl:private]
其中outE('knows').values('weight').sum()表示图中所有边的属性weight值的总和。
Aggregate

aggregate()被用于将某个step后的结果聚合为一个collection。这里使用了eager evaluation的概念,在某个特殊点的结果需要参与未来某个计算时eager evaluation显得尤为重要。通俗的说,在某个step之后使用了aggregate函数时,将此结果(collection)保存起来并命名(例如x),以便后续step的使用,如搭配(without('x')等函数使用)。举个例子:
gremlin> g.V(1).out('created') //marko创建什么==>v[3]gremlin> g.V(1).out('created').aggregate('x') //将他创造的东西聚合起来==>v[3]gremlin> g.V(1).out('created').aggregate('x').in('created') // 谁是marko的合作者==>v[1]==>v[4]==>v[6]gremlin> g.V(1).out('created').aggregate('x').in('created').out('created') //他的合作者创建了什么==>v[3]==>v[5]==>v[3]==>v[3]gremlin> g.V(1).out('created').aggregate('x').in('created').out('created').where(without('x')).values('name') //(5)他的合作者所创建的东西哪些marko没有参与==>ripple
Finally, aggregate()可以通过by()调整并映射出结果。
gremlin> g.V().out('knows').aggregate('x').cap('x')==>{v[2]=1, v[4]=1}gremlin> g.V().out('knows').aggregate('x').by('name').cap('x')==>{vadas=1, josh=1}
And
‘与’操作,跟java中的‘&&’类似。
gremlin> g.V().and(outE('knows'),values('age').is(lt(30))).values('name')==>marko
and()能做任意变量的遍历。但是所有的遍历必须产生至少一个输出传给后续步骤。
gremlin> g.V().where(outE('created').and().outE('knows')).values('name')==>marko
As
其实As()不能真正意义上的step,而是一个步骤调节器,类似by()和option()。为一个step(后续步骤)或数据结构(后续产生的结构)提供标签。
gremlin> g.V().as('a').out('created').as('b').select('a','b') //(1)==>[a:v[1], b:v[3]]==>[a:v[4], b:v[5]]==>[a:v[4], b:v[3]]==>[a:v[6], b:v[3]]gremlin> g.V().as('a').out('created').as('b').select('a','b').by('name') //(2)==>[a:marko, b:lop]==>[a:josh, b:ripple]==>[a:josh, b:lop]==>[a:peter, b:lop]
可以为结果提供多个标签,针对这个集合做不同的处理。如下:
gremlin> g.V().hasLabel('software').as('a','b','c').select('a','b','c').by('name').by('lang').by(__.in('created').values('name').fold())==>[a:lop, b:java, c:[marko, josh, peter]]==>[a:ripple, b:java, c:[josh]]
Barrier
barrier()将将延迟遍历管道(lazy traversal pipeline)转化为容量同步(bulk-synchronous)的管道。barrier()用于以下两种情况:
1. 在barrier()之前的先执行,然后再执行barrier()后面的,在一个iterator()中也是如此。
2. 重复操作一个结果集时使用这个停顿能优化计算。
gremlin> g.V().sideEffect{println "first: ${it}"}.sideEffect{println "second: ${it}"}.iterate()first: v[1]second: v[1]first: v[2]second: v[2]first: v[3]second: v[3]first: v[4]second: v[4]first: v[5]second: v[5]first: v[6]second: v[6]gremlin> g.V().sideEffect{println "first: ${it}"}.barrier().sideEffect{println "second: ${it}"}.iterate()first: v[1]first: v[2]first: v[3]first: v[4]first: v[5]first: v[6]second: v[1]second: v[2]second: v[3]second: v[4]second: v[5]second: v[6]
By
by()不是一个真正的step,而是一个step-modulator,与as()和option()类似。其通用的使用模式为step().by()...by()。
gremlin> g.V().group().by(bothE().count()) //(1)==>[1:[v[2], v[5], v[6]], 3:[v[1], v[3], v[4]]]gremlin> g.V().group().by(bothE().count()).by('name') //(2)==>[1:[vadas, ripple, peter], 3:[marko, lop, josh]]gremlin> g.V().group().by(bothE().count()).by(count()) //(3)==>[1:3, 3:3]
Cap
The cap()-step (barrier) iterates the traversal up to itself and emits the sideEffect referenced by the provided key. If multiple keys are provided, then a Map of sideEffects is emitted.
gremlin> g.V().groupCount('a').by(label).cap('a') //(1)==>[software:2, person:4]gremlin> g.V().groupCount('a').by(label).groupCount('b').by(outE().count()).cap('a','b') //(2)==>[a:[software:2, person:4], b:[0:3, 1:1, 2:1, 3:1]]
Coalesce
coalesce()就是将提供的遍历器顺序执行,如果第一个有值,则返回,否则找第二个,直到有值返回。
gremlin> g.V(1).coalesce(outE('knows'), outE('created')).inV().path().by('name').by(label)==>[marko, knows, vadas]==>[marko, knows, josh]gremlin> g.V(1).coalesce(outE('created'), outE('knows')).inV().path().by('name').by(label)==>[marko, created, lop]gremlin> g.V(1).property('nickname', 'okram')==>v[1]gremlin> g.V().hasLabel('person').coalesce(values('nickname'), values('name'))==>okram==>vadas==>josh==>peter
Count
计算遍历结果的总量。
gremlin> g.V().count()==>6gremlin> g.V().hasLabel('person').count()==>4gremlin> g.V().hasLabel('person').outE('created').count().path() //(1)==>[4]gremlin> g.V().hasLabel('person').outE('created').count().map {it.get() * 10}.path() //(2)==>[4, 40]
Choose
由当前遍历器到一个特殊的遍历器的分支操作,它能实现基于if/else语义甚至更为复杂的语义。

gremlin> g.V().hasLabel('person').choose(values('age').is(lte(30)),__.in(),__.out()).values('name') //如果遍历产生了一个元素,那么做in,否则做out(基于true/false的选择器)==>marko==>ripple==>lop==>lopgremlin> g.V().hasLabel('person').choose(values('age')).option(27, __.in()).option(32, __.out()).values('name') //将遍历的结果集作为遍历选择器map的key。==>marko==>ripple==>lop
然而,choose()也能实现类似switch的功能。
gremlin> g.V().hasLabel('person').choose(values('name')).option('marko', values('age')).option('josh', values('name')).option('vadas', valueMap()).option('peter', label())==>29==>[name:[vadas], age:[27]]==>josh==>person
choose()还能利用Pick.none选项来匹配。不能匹配的选项,这时none就起作用了。
gremlin> g.V().hasLabel('person').choose(values('name')).option('marko', values('age')).option(none, values('name'))==>29==>vadas==>josh==>peter
Coin
一个随机过滤的遍历器,提供了一个浮点参数的偏差值
gremlin> g.V().coin(0.5)==>v[1]==>v[3]==>v[4]==>v[5]gremlin> g.V().coin(0.0)gremlin> g.V().coin(1.0)==>v[1]==>v[2]==>v[3]==>v[4]==>v[5]==>v[6]
Constant
为某个遍历器指定一个常量值,这个配合基于条件的步骤如
choose()或coalesce()
gremlin> g.V().choose(hasLabel('person'),values('name'),constant('inhuman')) //(1)==>marko==>vadas==>inhuman==>josh==>inhuman==>petergremlin> g.V().coalesce(hasLabel('person').values('name'),constant('inhuman')) //显示人名,如果不是人,则显示'inhuman'==>marko==>vadas==>inhuman==>josh==>inhuman==>peter
CyclicPath

每个遍历器在图中遍历时都有其轨迹,也就是path()。在遍历的过程中有可能重复其轨迹,这是cyclicPath()就能用到。如果想过滤遍历过程中重复的路径,就是说不希望重复其路径,则可以使用simplePath()
gremlin> g.V(1).both().both()==>v[1]==>v[4]==>v[6]==>v[1]==>v[5]==>v[3]==>v[1]gremlin> g.V(1).both().both().cyclicPath()==>v[1]==>v[1]==>v[1]gremlin> g.V(1).both().both().cyclicPath().path()==>[v[1], v[3], v[1]]==>[v[1], v[2], v[1]]==>[v[1], v[4], v[1]]
Dedup
dedup()用于对结果集去重。
gremlin> g.V().values('lang')==>java==>javagremlin> g.V().values('lang').dedup()==>javagremlin> g.V(1).repeat(bothE('created').dedup().otherV()).emit().path() //(1)==>[v[1], e[9][1-created->3], v[3]]==>[v[1], e[9][1-created->3], v[3], e[11][4-created->3], v[4]]==>[v[1], e[9][1-created->3], v[3], e[12][6-created->3], v[6]]==>[v[1], e[9][1-created->3], v[3], e[11][4-created->3], v[4], e[10][4-created->5], v[5]]
dedup()也可以配合by()来使用:
gremlin> g.V().valueMap(true, 'name')==>[label:person, name:[marko], id:1]==>[label:person, name:[vadas], id:2]==>[label:software, name:[lop], id:3]==>[label:person, name:[josh], id:4]==>[label:software, name:[ripple], id:5]==>[label:person, name:[peter], id:6]gremlin> g.V().dedup().by(label).values('name')==>marko==>lop
Finally, if dedup() is provided an array of strings, then it will ensure that the de-duplication is not with respect to the current traverser object, but to the path history of the traverser.
gremlin> g.V().as('a').out('created').as('b').in('created').as('c').select('a','b','c')==>[a:v[1], b:v[3], c:v[1]]==>[a:v[1], b:v[3], c:v[4]]==>[a:v[1], b:v[3], c:v[6]]==>[a:v[4], b:v[5], c:v[4]]==>[a:v[4], b:v[3], c:v[1]]==>[a:v[4], b:v[3], c:v[4]]==>[a:v[4], b:v[3], c:v[6]]==>[a:v[6], b:v[3], c:v[1]]==>[a:v[6], b:v[3], c:v[4]]==>[a:v[6], b:v[3], c:v[6]]gremlin> g.V().as('a').out('created').as('b').in('created').as('c').dedup('a','b').select('a','b','c') //(1)==>[a:v[1], b:v[3], c:v[1]]==>[a:v[4], b:v[5], c:v[4]]==>[a:v[4], b:v[3], c:v[1]]==>[a:v[6], b:v[3], c:v[1]]
Drop
drop()用于删除图中的元素(点和边)或属性:
gremlin> g.V().outE().drop()gremlin> g.E()gremlin> g.V().properties('name').drop()gremlin> g.V().valueMap()==>[age:[29]]==>[age:[27]]==>[lang:[java]]==>[age:[32]]==>[lang:[java]]==>[age:[35]]gremlin> g.V().drop()gremlin> g.V()
Explain
The explain()-step (sideEffect) will return a TraversalExplanation. A traversal explanation details how the traversal (prior to explain()) will be compiled given the registered traversal strategies. A TraversalExplanation has a toString() representation with 3-columns. The first column is the traversal strategy being applied. The second column is the traversal strategy category: [D]ecoration, [O]ptimization, [P]rovider optimization, [F]inalization, and [V]erification. Finally, the third column is the state of the traversal post strategy application. The final traversal is the resultant execution plan.
gremlin> g.V().hasLabel('person').outE().identity().inV().count().is(gt(5)).explain()==>Traversal Explanation===============================================================================================================================================================================Original Traversal [GraphStep([],vertex), HasStep([~label.eq(person)]), VertexStep(OUT,edge), IdentityStep, EdgeVertexStep(IN), CountGlobalStep, IsStep(gt(5))]ConnectiveStrategy [D] [GraphStep([],vertex), HasStep([~label.eq(person)]), VertexStep(OUT,edge), IdentityStep, EdgeVertexStep(IN), CountGlobalStep, IsStep(gt(5))]IdentityRemovalStrategy [O] [GraphStep([],vertex), HasStep([~label.eq(person)]), VertexStep(OUT,edge), EdgeVertexStep(IN), CountGlobalStep, IsStep(gt(5))]IncidentToAdjacentStrategy [O] [GraphStep([],vertex), HasStep([~label.eq(person)]), VertexStep(OUT,vertex), CountGlobalStep, IsStep(gt(5))]AdjacentToIncidentStrategy [O] [GraphStep([],vertex), HasStep([~label.eq(person)]), VertexStep(OUT,edge), CountGlobalStep, IsStep(gt(5))]FilterRankingStrategy [O] [GraphStep([],vertex), HasStep([~label.eq(person)]), VertexStep(OUT,edge), CountGlobalStep, IsStep(gt(5))]MatchPredicateStrategy [O] [GraphStep([],vertex), HasStep([~label.eq(person)]), VertexStep(OUT,edge), CountGlobalStep, IsStep(gt(5))]RangeByIsCountStrategy [O] [GraphStep([],vertex), HasStep([~label.eq(person)]), VertexStep(OUT,edge), RangeGlobalStep(0,6), CountGlobalStep, IsStep(gt(5))]TinkerGraphStepStrategy [P] [TinkerGraphStep(vertex,[~label.eq(person)]), VertexStep(OUT,edge), RangeGlobalStep(0,6), CountGlobalStep, IsStep(gt(5))]EngineDependentStrategy [F] [TinkerGraphStep(vertex,[~label.eq(person)]), VertexStep(OUT,edge), RangeGlobalStep(0,6), CountGlobalStep, IsStep(gt(5))]ProfileStrategy [F] [TinkerGraphStep(vertex,[~label.eq(person)]), VertexStep(OUT,edge), RangeGlobalStep(0,6), CountGlobalStep, IsStep(gt(5))]StandardVerificationStrategy [V] [TinkerGraphStep(vertex,[~label.eq(person)]), VertexStep(OUT,edge), RangeGlobalStep(0,6), CountGlobalStep, IsStep(gt(5))]ComputerVerificationStrategy [V] [TinkerGraphStep(vertex,[~label.eq(person)]), VertexStep(OUT,edge), RangeGlobalStep(0,6), CountGlobalStep, IsStep(gt(5))]Final Traversal [TinkerGraphStep(vertex,[~label.eq(person)]), VertexStep(OUT,edge), RangeGlobalStep(0,6), CountGlobalStep, IsStep(gt(5))]
Fold
当遍历流需要一个“界限”来聚合所有对象时就会用到fold(),可以用unfold()进行反向操作。
gremlin> g.V(1).out('knows').values('name')==>vadas==>joshgremlin> g.V(1).out('knows').values('name').fold() //聚合所有的对象为一个list==>[vadas, josh]gremlin> g.V(1).out('knows').values('name').fold().next().getClass() //可以看到这是一个list==>class java.util.ArrayListgremlin> g.V(1).out('knows').values('name').fold(0) {a,b -> a + b.length()} //(3)==>9gremlin> g.V().values('age').fold(0) {a,b -> a + b} //(4)==>123gremlin> g.V().values('age').fold(0, sum) //整个图中所有年龄的总和。==>123gremlin> g.V().values('age').sum() //(6)==>123
Group
group()配合by()使用,类似与sql语言中的group by()
gremlin> g.V().group().by(label) //(1)==>[software:[v[3], v[5]], person:[v[1], v[2], v[4], v[6]]]gremlin> g.V().group().by(label).by('name') //(2)==>[software:[lop, ripple], person:[marko, vadas, josh, peter]]gremlin> g.V().group().by(label).by(count()) //(3)==>[software:2, person:4]
GroupCount
当某个遍历的过程中,想知道一个特别对象出现的次数,则用到groupCount()
gremlin> g.V().hasLabel('person').values('age').groupCount()==>[32:1, 35:1, 27:1, 29:1]gremlin> g.V().hasLabel('person').groupCount().by('age') //(1)==>[32:1, 35:1, 27:1, 29:1]
Has

has()用于过滤点、边以及属性。这里有多个变种:
1. has(key,value):如果遍历器中没有提供的key/value属性时,过滤掉。
2. has(key,predicate):过滤掉元素中不提供这个值或提供的值不满足后面的判断条件。
3. hasLabel(labels...):过滤没有这个标签的。
4. hasId(ids...):过滤没有这些标签的元素。
5. hasKey(keys...):过滤没有这些没有这个key属性遍历器。
6. hasValue(values...):删除属性中没有这些值的遍历器。
7. has(key):过滤元素中没有这些值的遍历器
8. hasNot(key):过滤元素中有这些值遍历器
9. has(key, traversal):
gremlin> g.V().hasLabel('person')==>v[1]==>v[2]==>v[4]==>v[6]gremlin> g.V().hasLabel('person').out().has('name',within('vadas','josh'))==>v[2]==>v[4]gremlin> g.V().hasLabel('person').out().has('name',within('vadas','josh')).outE().hasLabel('created')==>e[10][4-created->5]==>e[11][4-created->3]gremlin> g.V().has('age',inside(20,30)).values('age') //找出所有年龄在[20-30)之间的顶点。==>29==>27gremlin> g.V().has('age',outside(20,30)).values('age') //找出所有年龄不在[20-30)之间的顶点。==>32==>35gremlin> g.V().has('name',within('josh','marko')).valueMap() //找出名字为josh或marko的属性。==>[name:[marko], age:[29]]==>[name:[josh], age:[32]]gremlin> g.V().has('name',without('josh','marko')).valueMap() //找出名字不为josh和marko的属性。==>[name:[vadas], age:[27]]==>[name:[lop], lang:[java]]==>[name:[ripple], lang:[java]]==>[name:[peter], age:[35]]gremlin> g.V().has('name',not(within('josh','marko'))).valueMap() //找出名字不为josh和marko的属性。==>[name:[vadas], age:[27]]==>[name:[lop], lang:[java]]==>[name:[ripple], lang:[java]]==>[name:[peter], age:[35]]
Inject

Tinkerpop3一个主要的特征是jnject()。这就可以让我们任意的在遍历流中注入对象。
gremlin> g.V(4).out().values('name').inject('daniel')==>daniel==>ripple==>lopgremlin> g.V(4).out().values('name').inject('daniel').map {it.get().length()}==>6==>6==>3gremlin> g.V(4).out().values('name').inject('daniel').map {it.get().length()}.path()==>[daniel, 6]==>[v[4], v[5], ripple, 6]==>[v[4], v[3], lop, 3]
如果开始的不是一个图中的对象(顶点和边),inject()也可以这样用:
gremlin> inject(1,2)==>1==>2gremlin> inject(1,2).map {it.get() + 1}==>2==>3gremlin> inject(1,2).map {it.get() + 1}.map {g.V(it.get()).next()}.values('name')==>vadas==>lop
Is
is()用于过滤数量值。
gremlin> g.V().values('age').is(32)==>32gremlin> g.V().values('age').is(lte(30))==>29==>27gremlin> g.V().values('age').is(inside(30, 40))==>32==>35gremlin> g.V().where(__.in('created').count().is(1)).values('name') //(1)==>ripplegremlin> g.V().where(__.in('created').count().is(gte(2))).values('name') //(2)==>lopgremlin> g.V().where(__.in('created').values('age').mean().is(inside(30d, 35d))).values('name') //(3)==>lop==>ripple
Limit
limit()跟range()的功能类似,从1开始计数。
gremlin> g.V().limit(2)==>v[1]==>v[2]gremlin> g.V().range(0, 2)==>v[1]==>v[2]gremlin> g.V().limit(2).toString()==>[GraphStep([],vertex), RangeGlobalStep(0,2)]
Local

Match
match()提供一种基于模式匹配概念的图查询的声明形式。使用它,用户提供了遍历片段的集合,这些定义的遍历片段在match过程中必须返回true值。
"Who created a project named 'lop' that was also created by someone who is 29 years old? Return the two creators."
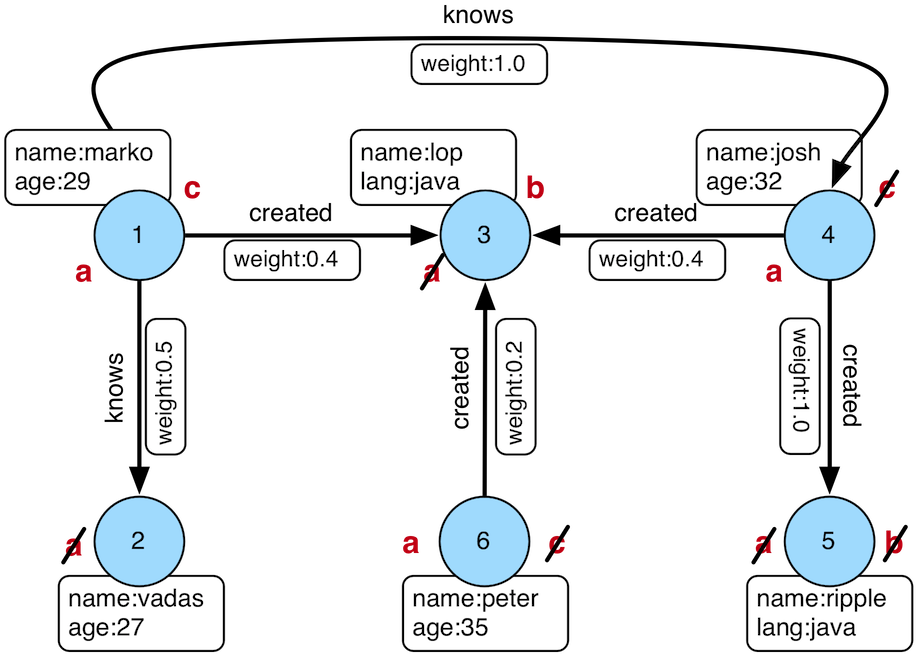
gremlin> g.V().match(__.as('a').out('created').as('b'),__.as('b').has('name', 'lop'),__.as('b').in('created').as('c'),__.as('c').has('age', 29)).select('a','c').by('name')==>[a:marko, c:marko]==>[a:josh, c:marko]==>[a:peter, c:marko]
使用where()与其配合使用
gremlin> g.V().match(__.as('a').out('created').as('b'),__.as('b').in('created').as('c')).where('a', neq('c')).select('a','c').by('name')==>[a:marko, c:josh]==>[a:marko, c:peter]==>[a:josh, c:marko]==>[a:josh, c:peter]==>[a:peter, c:marko]==>[a:peter, c:josh]
Max
找出结果集中最大的数
gremlin> g.V().values('age').max()==>35gremlin> g.V().repeat(both()).times(3).values('age').max()==>35
注意:
max(local)检测的是当前本地的最大值(而不是遍历结果集中的值),操作的对象为Collection和Number类型的对象。操作其他对象就会返回Double.NaN
Mean
mean()求平均值
gremlin> g.V().values('age').mean()==>30.75gremlin> g.V().repeat(both()).times(3).values('age').mean() //(1)==>30.645833333333332gremlin> g.V().repeat(both()).times(3).values('age').dedup().mean()==>30.75
Min
求最小值
gremlin> g.V().values('age').min()==>27gremlin> g.V().repeat(both()).times(3).values('age').min()==>27
Or
相当与一个或操作,可以参考and()方法
gremlin> g.V().or(__.outE('created'),__.inE('created').count().is(gt(1))).values('name')==>marko==>lop==>josh==>peter
Order
对结果集进行排序
gremlin> g.V().values('name').order()==>josh==>lop==>marko==>peter==>ripple==>vadasgremlin> g.V().values('name').order().by(decr)==>vadas==>ripple==>peter==>marko==>lop==>joshgremlin> g.V().hasLabel('person').order().by('age', incr).values('name')==>vadas==>marko==>josh==>peter
遍历器遍历的结果集大部分都是元素,而元素都有相关属性与之关联,在很多情况下,很多情况下,都需要对元素的属性进行排序。如下:
gremlin> g.V().values('name')==>marko==>vadas==>lop==>josh==>ripple==>petergremlin> g.V().order().by('name',incr).values('name')==>josh==>lop==>marko==>peter==>ripple==>vadasgremlin> g.V().order().by('name',decr).values('name')==>vadas==>ripple==>peter==>marko==>lop==>josh
Path
一个遍历器的遍历被转化为多个遍历的step的顺序执行,那么遍历路径可以通过path()来显示执行的路径。如下图:
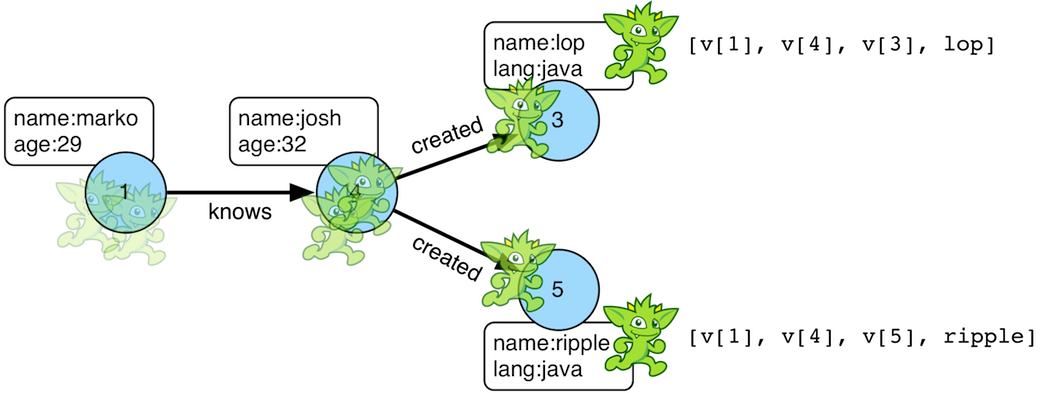
举例:
gremlin> g.V().out().out().values('name')==>ripple==>lopgremlin> g.V().out().out().values('name').path()==>[v[1], v[4], v[5], ripple]==>[v[1], v[4], v[3], lop]
如果希望边显示路径,那么需确保明确的遍历这些边:
gremlin> g.V().outE().inV().outE().inV().path()==>[v[1], e[8][1-knows->4], v[4], e[10][4-created->5], v[5]]==>[v[1], e[8][1-knows->4], v[4], e[11][4-created->3], v[3]]
如果以循环的方式遍历这些元素的路径可以通过path()搭配by()使用:
gremlin> g.V().out().out().path().by('name').by('age')==>[marko, 32, ripple]==>[marko, 32, lop]
Path的数据结构
path的数据结构是一个有序的对象列表,每个对象对应Set集合标签。举个例子:
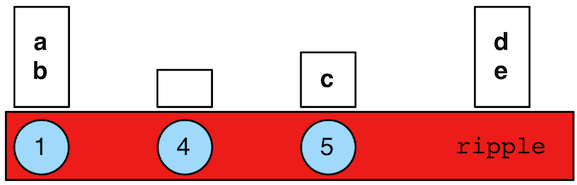
gremlin> path = g.V(1).as('a').has('name').as('b').out('knows').out('created').as('c').has('name','ripple').values('name').as('d').identity().as('e').path().next()==>v[1]==>v[4]==>v[5]==>ripplegremlin> path.size()==>4gremlin> path.objects()==>v[1]==>v[4]==>v[5]==>ripplegremlin> path.labels()==>[a, b]==>[]==>[c]==>[d, e]gremlin> path.a==>v[1]gremlin> path.b==>v[1]gremlin> path.c==>v[5]gremlin> path.d == path.e==>true
Profile
The
profile()-step (sideEffect) exists to allow developers to profile their traversals to determine statistical information like step runtime, counts, etc.
Range
当遍历器在遍历的过程中,只能允许结果集中的一定数量的结果参与后续的处理,这时可以使用profile()。如果结果集中小于最小范围时,则继续迭代;如果在range的范围内,则可以参与后续操作;如果大于最大范围,则停止。如下:
gremlin> g.V().range(0,3)==>v[1]==>v[2]==>v[3]gremlin> g.V().range(1,3)==>v[2]==>v[3]gremlin> g.V().repeat(both()).times(1000000).emit().range(6,10)==>v[1]==>v[5]==>v[3]==>v[1]
当操作一个集合时,range()可以与Scope.local使用。
gremlin> g.V().as('a').out().as('b').in().as('c').select('a','b','c').by('name').range(local,1,2)==>[b:lop]==>[b:lop]==>[b:lop]==>[b:vadas]==>[b:josh]==>[b:ripple]==>[b:lop]==>[b:lop]==>[b:lop]==>[b:lop]==>[b:lop]==>[b:lop]
Repeat
repeat()被用于循环执行给定执行语句或step。
gremlin> g.V(1).repeat(out()).times(2).path().by('name') //与out()方法配合,实现do-while语法==>[marko, josh, ripple]==>[marko, josh, lop]gremlin> g.V().until(has('name','ripple')).repeat(out()).path().by('name') //while-do语法。==>[marko, josh, ripple]==>[josh, ripple]==>[ripple]
重点:针对
repeat()配合使用的两个step:until()和emit()。如果repeat()在until()的前面,则实现do/while循环;如果repeat()出现在until()后面,则实现while/do循环。如果emit()出现在repeat()后面,则处理repeat()之后的结果集;如果emit()出现在repeat()前面,则优先处理repeat()之前的结果集。
gremlin> g.V(1).repeat(out()).times(2).emit().path().by('name') //(1)==>[marko, lop]==>[marko, vadas]==>[marko, josh]==>[marko, josh, ripple]==>[marko, josh, lop]gremlin> g.V(1).emit().repeat(out()).times(2).path().by('name') //(2)==>[marko]==>[marko, lop]==>[marko, vadas]==>[marko, josh]==>[marko, josh, ripple]==>[marko, josh, lop]
Sack
Sample
sample()用于对结果集进行抽样。
gremlin> g.V().outE().sample(1).values('weight')==>0.5gremlin> g.V().outE().sample(1).by('weight').values('weight')==>1.0gremlin> g.V().outE().sample(2).by('weight').values('weight')==>1.0==>0.4
sample()一个最有趣的使用案例是与local()配合使用。这种配合使用支持 random walks 的执行。
gremlin> g.V(1).repeat(local(bothE().sample(1).by('weight').otherV())).times(5)==>v[2]gremlin> g.V(1).repeat(local(bothE().sample(1).by('weight').otherV())).times(5).path()==>[v[1], e[8][1-knows->4], v[4], e[11][4-created->3], v[3], e[9][1-created->3], v[1], e[8][1-knows->4], v[4], e[8][1-knows->4], v[1]]gremlin> g.V(1).repeat(local(bothE().sample(1).by('weight').otherV())).times(10).path()==>[v[1], e[8][1-knows->4], v[4], e[8][1-knows->4], v[1], e[9][1-created->3], v[3], e[11][4-created->3], v[4], e[10][4-created->5], v[5], e[10][4-created->5], v[4], e[10][4-created->5], v[5], e[10][4-created->5], v[4], e[10][4-created->5], v[5], e[10][4-created->5], v[4]]
Select
函数式语言利用函数组合和惰性计算能创建复杂的计算。这正是Traversal所做的事情。gremlin数据流一个小区分就是数据流不一直是向前流动,事实上而是可能回到之间的数据集计算。这样的例子包括path()和select()。有两种使用select()方式:
1. 在路径中选择标签steps。
2. 从Map中选择结果。
gremlin> g.V().as('a').out().as('b').out().as('c') // no select==>v[5]==>v[3]gremlin> g.V().as('a').out().as('b').out().as('c').select('a','b','c')==>[a:v[1], b:v[4], c:v[5]]==>[a:v[1], b:v[4], c:v[3]]gremlin> g.V().as('a').out().as('b').out().as('c').select('a','b')==>[a:v[1], b:v[4]]==>[a:v[1], b:v[4]]gremlin> g.V().as('a').out().as('b').out().as('c').select('a','b').by('name')==>[a:marko, b:josh]==>[a:marko, b:josh]gremlin> g.V().as('a').out().as('b').out().as('c').select('a') //(1)==>v[1]==>v[1]
配合where使用
gremlin> g.V().as('a').out('created').in('created').as('b').select('a','b').by('name') //(1)==>[a:marko, b:marko]==>[a:marko, b:josh]==>[a:marko, b:peter]==>[a:josh, b:josh]==>[a:josh, b:marko]==>[a:josh, b:josh]==>[a:josh, b:peter]==>[a:peter, b:marko]==>[a:peter, b:josh]==>[a:peter, b:peter]gremlin> g.V().as('a').out('created').in('created').as('b').select('a','b').by('name').where('a',neq('b')) //(2)==>[a:marko, b:josh]==>[a:marko, b:peter]==>[a:josh, b:marko]==>[a:josh, b:peter]==>[a:peter, b:marko]==>[a:peter, b:josh]gremlin> g.V().as('a').out('created').in('created').as('b').select('a','b'). //(3)where('a',neq('b')).where(__.as('a').out('knows').as('b')).select('a','b').by('name')==>[a:marko, b:josh]
SimplePath
simplePath()用于过滤重复的路径,可以参考path()和cyclicPath()。
gremlin> g.V(1).both().both()==>v[1]==>v[4]==>v[6]==>v[1]==>v[5]==>v[3]==>v[1]gremlin> g.V(1).both().both().simplePath()==>v[4]==>v[6]==>v[5]==>v[3]gremlin> g.V(1).both().both().simplePath().path()==>[v[1], v[3], v[4]]==>[v[1], v[3], v[6]]==>[v[1], v[4], v[5]]==>[v[1], v[4], v[3]]
Store
当需要延迟聚合时,可以使用store()替代aggregate(),这里有两点区别:1. 非阻塞。2. 当经过时,存储副作用的对象集合。
gremlin> g.V().aggregate('x').limit(1).cap('x')==>{v[1]=1, v[2]=1, v[3]=1, v[4]=1, v[5]=1, v[6]=1}gremlin> g.V().store('x').limit(1).cap('x')==>{v[1]=1, v[2]=1}
Subgraph
![]()
在对图的分析和开发中,从一个大图中提取一个小图用于分析、可视化或其他目的是很常见的。subgraph()提供了从任意遍历中产生一个边导向的子图(edge-induced subgraph)
gremlin> subGraph = g.E().hasLabel('knows').subgraph('subGraph').cap('subGraph').next() //(1)==>tinkergraph[vertices:3 edges:2]gremlin> sg = subGraph.traversal(standard())==>graphtraversalsource[tinkergraph[vertices:3 edges:2], standard]gremlin> sg.E() //(2)==>e[7][1-knows->2]==>e[8][1-knows->4]
A more common subgraphing use case is to get all of the graph structure surrounding a single vertex:
gremlin> subGraph = g.V(3).repeat(__.inE().subgraph('subGraph').outV()).times(3).cap('subGraph').next() //(1)==>tinkergraph[vertices:4 edges:4]gremlin> sg = subGraph.traversal(standard())==>graphtraversalsource[tinkergraph[vertices:4 edges:4], standard]gremlin> sg.E()==>e[8][1-knows->4]==>e[9][1-created->3]==>e[11][4-created->3]==>e[12][6-created->3]
There can be multiple subgraph() calls within the same traversal. Each operating against either the same graph (i.e. same side-effect key) or different graphs (i.e. different side-effect keys).
gremlin> t = g.V().outE('knows').subgraph('knowsG').inV().outE('created').subgraph('createdG').inV().inE('created').subgraph('createdG').iterate()gremlin> t.sideEffects.get('knowsG').get().traversal(standard()).E()==>e[7][1-knows->2]==>e[8][1-knows->4]gremlin> t.sideEffects.get('createdG').get().traversal(standard()).E()==>e[9][1-created->3]==>e[10][4-created->5]==>e[11][4-created->3]==>e[12][6-created->3]
Sum
求和
gremlin> g.V().values('age').sum()==>123gremlin> g.V().repeat(both()).times(3).values('age').sum()==>1471
Tail
tail()与limit()类似,获取结果集中的最后的n个。
gremlin> g.V().values('name').order()==>josh==>lop==>marko==>peter==>ripple==>vadasgremlin> g.V().values('name').order().tail() //(1)==>vadasgremlin> g.V().values('name').order().tail(1) //(2)==>vadasgremlin> g.V().values('name').order().tail(3) //(3)==>peter==>ripple==>vadas
tail()可以与Scope.local配合使用。
gremlin> g.V().as('a').out().as('a').out().as('a').select('a').by(tail(local)).values('name') //(1)==>ripple==>lopgremlin> g.V().as('a').out().as('a').out().as('a').select('a').by(unfold().values('name').fold()).tail(local) //(2)==>ripple==>lopgremlin> g.V().as('a').out().as('a').out().as('a').select('a').by(unfold().values('name').fold()).tail(local, 2) //(3)==>[josh, ripple]==>[josh, lop]gremlin> g.V().valueMap().tail(local) //(4)==>[age:[29]]==>[age:[27]]==>[lang:[java]]==>[age:[32]]==>[lang:[java]]==>[age:[35]]
TimeLimit
Tree
对于任何一个元素,从这里经过的路径都可以被聚合形成tree,gremlin提供了这个功能:tree()
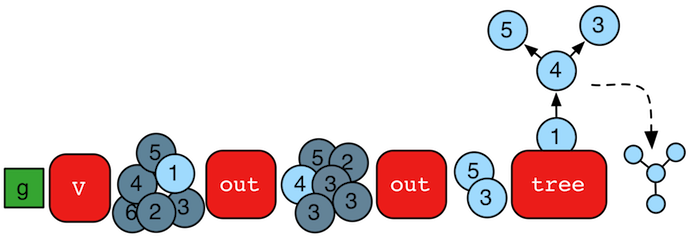
gremlin> tree = g.V().out().out().tree().next()==>v[1]={v[4]={v[3]={}, v[5]={}}}
看看这个过程是怎样的:
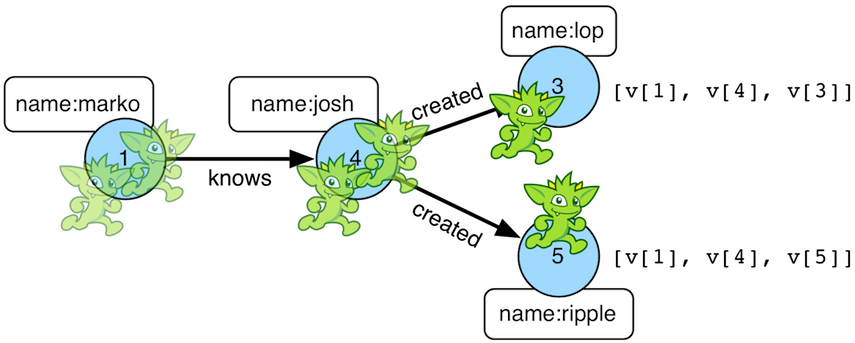
这个聚合的树形结构可以被用于其他操作:
gremlin> tree = g.V().out().out().tree().by('name').next()==>marko={josh={ripple={}, lop={}}}gremlin> tree['marko']==>josh={ripple={}, lop={}}gremlin> tree['marko']['josh']==>ripple={}==>lop={}gremlin> tree.getObjectsAtDepth(3)==>ripple==>lop
Unfold
unfold()是fold()的反向操作:
gremlin> g.V(1).out().fold().inject('gremlin',[1.23,2.34])==>gremlin==>[1.23, 2.34]==>[v[3], v[2], v[4]]gremlin> g.V(1).out().fold().inject('gremlin',[1.23,2.34]).unfold()==>gremlin==>1.23==>2.34==>v[3]==>v[2]==>v[4]
Union
ValueMap
获得元素属性,以Map的形式展现。
gremlin> g.V().valueMap()==>[name:[marko], age:[29]]==>[name:[vadas], age:[27]]==>[name:[lop], lang:[java]]==>[name:[josh], age:[32]]==>[name:[ripple], lang:[java]]==>[name:[peter], age:[35]]gremlin> g.V().valueMap('age')==>[age:[29]]==>[age:[27]]==>[:]==>[age:[32]]==>[:]==>[age:[35]]gremlin> g.V().valueMap('age','blah')==>[age:[29]]==>[age:[27]]==>[:]==>[age:[32]]==>[:]==>[age:[35]]gremlin> g.E().valueMap()==>[weight:0.5]==>[weight:1.0]==>[weight:0.4]==>[weight:1.0]==>[weight:0.4]==>[weight:0.2]
非常要注意的是vertex的Map为每个key维护一个list。边或点属性的map代表一个属性(不是一个list)。原因是tinkerpop3中的顶点采用了顶点属性,顶点属性支持一个key可以有多个值。
gremlin> g.V().valueMap()==>[name:[marko], location:[san diego, santa cruz, brussels, santa fe]]==>[name:[stephen], location:[centreville, dulles, purcellville]]==>[name:[matthias], location:[bremen, baltimore, oakland, seattle]]==>[name:[daniel], location:[spremberg, kaiserslautern, aachen]]==>[name:[gremlin]]==>[name:[tinkergraph]]gremlin> g.V().has('name','marko').properties('location')==>vp[location->san diego]==>vp[location->santa cruz]==>vp[location->brussels]==>vp[location->santa fe]gremlin> g.V().has('name','marko').properties('location').valueMap()==>[startTime:1997, endTime:2001]==>[startTime:2001, endTime:2004]==>[startTime:2004, endTime:2005]==>[startTime:2005]
如果需要元素的id,label,key,则在valueMap(boolean need)传一个true属性。
gremlin> g.V().hasLabel('person').valueMap(true)==>[label:person, name:[marko], location:[san diego, santa cruz, brussels, santa fe], id:1]==>[label:person, name:[stephen], location:[centreville, dulles, purcellville], id:7]==>[label:person, name:[matthias], location:[bremen, baltimore, oakland, seattle], id:8]==>[label:person, name:[daniel], location:[spremberg, kaiserslautern, aachen], id:9]gremlin> g.V().hasLabel('person').valueMap(true,'name')==>[label:person, name:[marko], id:1]==>[label:person, name:[stephen], id:7]==>[label:person, name:[matthias], id:8]==>[label:person, name:[daniel], id:9]gremlin> g.V().hasLabel('person').properties('location').valueMap(true)==>[startTime:1997, endTime:2001, id:6, key:location, value:san diego]==>[startTime:2001, endTime:2004, id:7, key:location, value:santa cruz]==>[startTime:2004, endTime:2005, id:8, key:location, value:brussels]==>[startTime:2005, id:9, key:location, value:santa fe]==>[startTime:1990, endTime:2000, id:10, key:location, value:centreville]==>[startTime:2000, endTime:2006, id:11, key:location, value:dulles]==>[startTime:2006, id:12, key:location, value:purcellville]==>[startTime:2004, endTime:2007, id:13, key:location, value:bremen]==>[startTime:2007, endTime:2011, id:14, key:location, value:baltimore]==>[startTime:2011, endTime:2014, id:15, key:location, value:oakland]==>[startTime:2014, id:16, key:location, value:seattle]==>[startTime:1982, endTime:2005, id:17, key:location, value:spremberg]==>[startTime:2005, endTime:2009, id:18, key:location, value:kaiserslautern]==>[startTime:2009, id:19, key:location, value:aachen]
Vertex Steps
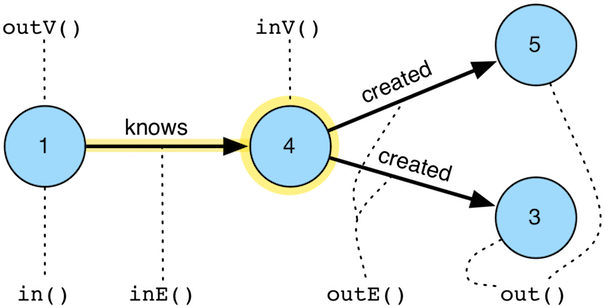
这里包含一下步骤:
1. out(string...): Move to the outgoing adjacent vertices given the edge labels.
2. out(string...): Move to the outgoing adjacent vertices given the edge labels.
3. in(string...): Move to the incoming adjacent vertices given the edge labels.
4. both(string...): Move to both the incoming and outgoing adjacent vertices given the edge labels.
5. outE(string...): Move to the outgoing incident edges given the edge labels.
6. inE(string...): Move to the incoming incident edges given the edge labels.
7. bothE(string...): Move to both the incoming and outgoing incident edges given the edge labels.
8. outV(): Move to the outgoing vertex.
9. inV(): Move to the incoming vertex.
10. bothV(): Move to both vertices.
11. otherV() : Move to the vertex that was not the vertex that was moved from.
举几个例子:
gremlin> g.V(4)==>v[4]gremlin> g.V(4).outE() //(1)==>e[10][4-created->5]==>e[11][4-created->3]gremlin> g.V(4).inE('knows') //(2)==>e[8][1-knows->4]gremlin> g.V(4).inE('created') //(3)gremlin> g.V(4).bothE('knows','created','blah')==>e[10][4-created->5]==>e[11][4-created->3]==>e[8][1-knows->4]gremlin> g.V(4).bothE('knows','created','blah').otherV()==>v[5]==>v[3]==>v[1]gremlin> g.V(4).both('knows','created','blah')==>v[5]==>v[3]==>v[1]gremlin> g.V(4).outE().inV() //(4)==>v[5]==>v[3]gremlin> g.V(4).out() //(5)==>v[5]==>v[3]gremlin> g.V(4).inE().outV()==>v[1]gremlin> g.V(4).inE().bothV()==>v[1]==>v[4]
Where
where()经常配合match()和select()使用,但也可以单独使用。
gremlin> g.V(1).as('a').out('created').in('created').where(neq('a')) //(1)==>v[4]==>v[6]gremlin> g.withSideEffect('a',['josh','peter']).V(1).out('created').in('created').values('name').where(within('a')) //(2)==>josh==>petergremlin> g.V(1).out('created').in('created').where(out('created').count().is(gt(1))).values('name') //(3)==>josh
where()可以过滤任意的遍历结果的任意对象:
gremlin> g.V().where(out('created')).values('name') //(1)==>marko==>josh==>petergremlin> g.V().out('knows').where(out('created')).values('name') //(2)==>joshgremlin> g.V().where(out('created').count().is(gte(2))).values('name') //(3)==>joshgremlin> g.V().where(out('knows').where(out('created'))).values('name') //(4)==>markogremlin> g.V().where(__.not(out('created'))).where(__.in('knows')).values('name') //(5)==>vadasgremlin> g.V().where(__.not(out('created')).and().in('knows')).values('name') //(6)==>vadas
判断语句
| 语句 | 说明 |
|---|---|
| eq(object) | 是否相等 |
| neq(object) | 是否不相等 |
| lt(number) | 小于 |
| lte(number) | 小于等于 |
| gt(number) | 大于 |
| gte(number) | 大于等于 |
| inside(number1,number2) | >number1 && <number2 |
| outside(number1,number2) | >number2 | <number1 |
| between(number1,number2) | <=number1 | >=number2 |
| within(objects...) | 是否包含 |
| without(objects...) | 是否不包含 |
gremlin> eq(2)==>eq(2)gremlin> not(neq(2)) //(1)==>eq(2)gremlin> not(within('a','b','c'))==>without([a, b, c])gremlin> not(within('a','b','c')).test('d') //(2)==>truegremlin> not(within('a','b','c')).test('a')==>falsegremlin> within(1,2,3).and(not(eq(2))).test(3) //(3)==>truegremlin> inside(1,4).or(eq(5)).test(3) //(4)==>truegremlin> inside(1,4).or(eq(5)).test(5)==>truegremlin> between(1,2) //(5)==>and([gte(1), lt(2)])gremlin> not(between(1,2))==>or([lt(1), gte(2)])
