@darwin-yuan
2016-07-08T08:20:51.000000Z
字数 3354
阅读 2256
正交设计,OO与SOLID
软件设计 OO
正交设计,是普遍的设计原则,与粒度无关,与编程范式无关,更与具体的实现语言无关。(虽然确实在不同的编程范式下,或使用不同的编程语言时,具体的解决方法或难易程度不同,这也正是为何我们总是在寻找更适合的编程范式,更高效的编程语言的原因)。
而具体到面向对象范式,我们都知道著名的SOLID原则。但是:这五个原则是怎么来的?它们的目的何在?它们的关系如何?
为了搞清楚这些疑问,我们再次回到最初的问题:
- 软件模块该如何划分?(怎么分)
- 模块间API该如何定义?(怎么合)
怎样进行分解?
模块的划分,是一个问题分解的过程。
在文章《VBD (Volatility Based Decomposition)》里,引用了一篇70年代的论文《On the Criteria to be Used in Decomposing Systems into Modules》。
在这篇论文里,作者通过一个小例子,清晰的指出了软件模块划分应该以基于信息隐藏为目的,以职责划分为手段,从而封装变化,让软件更加容易修改(即Kent Beck的理想:局部化影响)。
这篇文章也展示了:基于流程(过程)的分解,是一种极其脆弱的模块划分方式。因而我们应该离基于过程的分解越远越好。
这也是为何Matt Cochran将这种分解方法称做:基于易变性的分解(Volatility Based Decomposition)。
总而言之,变化及应对变化,是软件设计最大的挑战,目的和意义。
面向对象究竟要解决什么问题?
最近几年,我听到太多针对OO的批评,其中最为奇葩的说法是:OO只适合GUI编程。因为GUI组件概念上更接近于对象,至于其它领域则不太合适。
对提出这样高论的人,我相当确信,他们不仅对于面向对象一无所知,更是对于复杂软件所面临的真正挑战,以及软件设计究竟要解决什么问题一无所知。
前两天偶然从东海陈光剑的文章《函数式编程与面向对象编程[5]:编程的本质》读到软件模块化的目的和价值(虽然他用的是结构化,但在我看来也是在谈模块化),非常精彩,深合我意:
(软件设计是一个)层次化分解与重新复合的过程
这个思维过程, 并非是受计算机的限制而产生,它反映的是人类思维的局限性。我们的大脑一次只能处理很少的概念。生物学中被广为引用的 一篇论文指出我们我们的大脑中只能保存
7 ± 2个信息块。我们对人类短期记忆的认识可能会有变化,但是可以肯定的是它是有限的。底线就是我们不能处理一大堆乱糟糟的对象或像兰州拉面似的代码。我们需要结构化并非是因为结构化的程序看上去有多么美好,而是我们的大脑无法有效的处理非结构化的东西。我们经常说一些代码片段是优雅的或美观的,实际上那只意味 着它们更容易被人类有限的思维所处理。优雅的代码创造出尺度合理的代码块,它正好与我们的『心智消化系统』能够吸收的数量相符。
那么,对于程序的复合而言,正确的代码块是怎样的?它们的表面积必须要比它们的体积增长的更为缓慢。我喜欢这个比喻,因为几何对象的表面积是以尺寸的平方的速度增长的,而体积是以尺寸的立方的速度增长的,因此表面积的增长速度小于体积。
代码块的表面积是是我们复合代码块时所需要的信息。代码块的体积 是我们为了实现它们所需要的信息。一旦代码块的实现过程结束,我们就可以忘掉它的实现细节,只关心它与其他代码块的相互影响。在面向对象编程中,类或接口的声明就是表面。在函数式编程中,函数的声明就是表面。我把事情简化了一些,但是要点就是这些。
怎样才能做到表面积增长速度小于体积增长速度?当然是分解,信息隐藏,抽象。而这些也正是面向对象所追求和擅长的。
面向对象主要目的是为了模块化。虽然在一些数学家看来:由于面向对象没有很好的数学理论基础,因而必然是一个错误的方法论。可对于如何编写一个易于应对变化的软件,并不是一个纯数学理论问题(或许确实有数学家也可以抽象出一套数学理论),而更多的是一个实践问题。作为长期处于实践一线的我们,不应把几个数学家的看法当作金科玉律(对于那些没有实践经验,却对如何实践指手画脚的纯理论派,每次看到他们的不负责任的言论,考虑到他们的影响力和对新手的误导,就禁不住想对他们竖中指)(参见《学习的逻辑3: 三人行必有我徒》)。
软件工业最近20年来,能够构建如此大规模的需求频繁变化的软件系统,很大程度上得益于面向对象对于模块化的良好支持。
而现在风头正劲的微服务化,无非是把模块化的思想,从进程内模块(类),变为进程间而已。
OO和FP
面向对象与函数式编程的最大区别在于数据是否是强制不变性。这个前提,导致了一系列其它的差异。
因为可变性,面向对象可以将算法和数据放在一起,当数据是一种实现细节时,可对其进行信息隐藏和封装。但在Pure FP里,数据和算法是必须分离的。这种分离,在很多场景下,对于信息隐藏相当不利(在这里我们先不谈性能)。因而,当系统规模足够复杂时,FP对于构造易于维护软件的能力比面向对象要弱。
因而,FP为了实用,要么部分放弃对不变性的坚持(如LISP所做的那样),从而允许模拟面向对象范式(参见SICP);要么通过Existential Quantification,来模拟OO的运行时多态,以达到信息隐藏,隔离变化的目的;要么使用轻量级进程(轻量很关键):让每个轻量级进程承担一个很小的职责,从进程外部看,每个轻量级进程都可以有可修改的数据,以及基于消息的行为驱动(如erlang或akka的Actor模型),而这正是对于smalltalk的对象模拟,从而缓解了不变性带来的尴尬。进而也说明了基于高内聚,低耦合原则进行的模块化是超越范式的。
因而,一些FPer对于OO的盲目批评,和认为面向对象只适合GUI领域一样,都并不真正明白一个复杂软件的关键挑战,以及解决方案何在。
当然,具体到编程语言,即便都是OO语言,差别也巨大。但这是另外一个宏大的话题,这里暂且不谈。只重点说一句:不要把某种OO语言,当作OO本身。
关于FP和OO的话题,值得专门写一篇文章全面论述,而本文的目的在于介绍SOLID,因而不再赘述。
正交原则与SOLID的关系
一个好的面向对象设计,自然是符合高内聚,低耦合原则的对象划分和协作方式。
单一职责和开放封闭,更多的在强调类划分时的高内聚;而里氏替换,依赖倒置,接口隔离则更多的强调类与类之间协作接口(即API)定义的低耦合。
高内聚(怎么分)
单一职责,通过对变化原因的识别,将一个承担多重职责的类,不断分割为更小的,只具备单一变化原因的类。而单一变化原因指的是:一个变化,会引起整个类都发生变化。只有关联极其紧密的情况,才会导致这样的局面。因而,单一职责和高内聚某种程度是同义词。
但单一职责原则本身,并没有明确指示我们该如何判定一个类属于单一职责的,以及如何达到单一职责的状态。而策略消除重复,分离不同变化方向,正是让类达到单一职责的策略与途径。
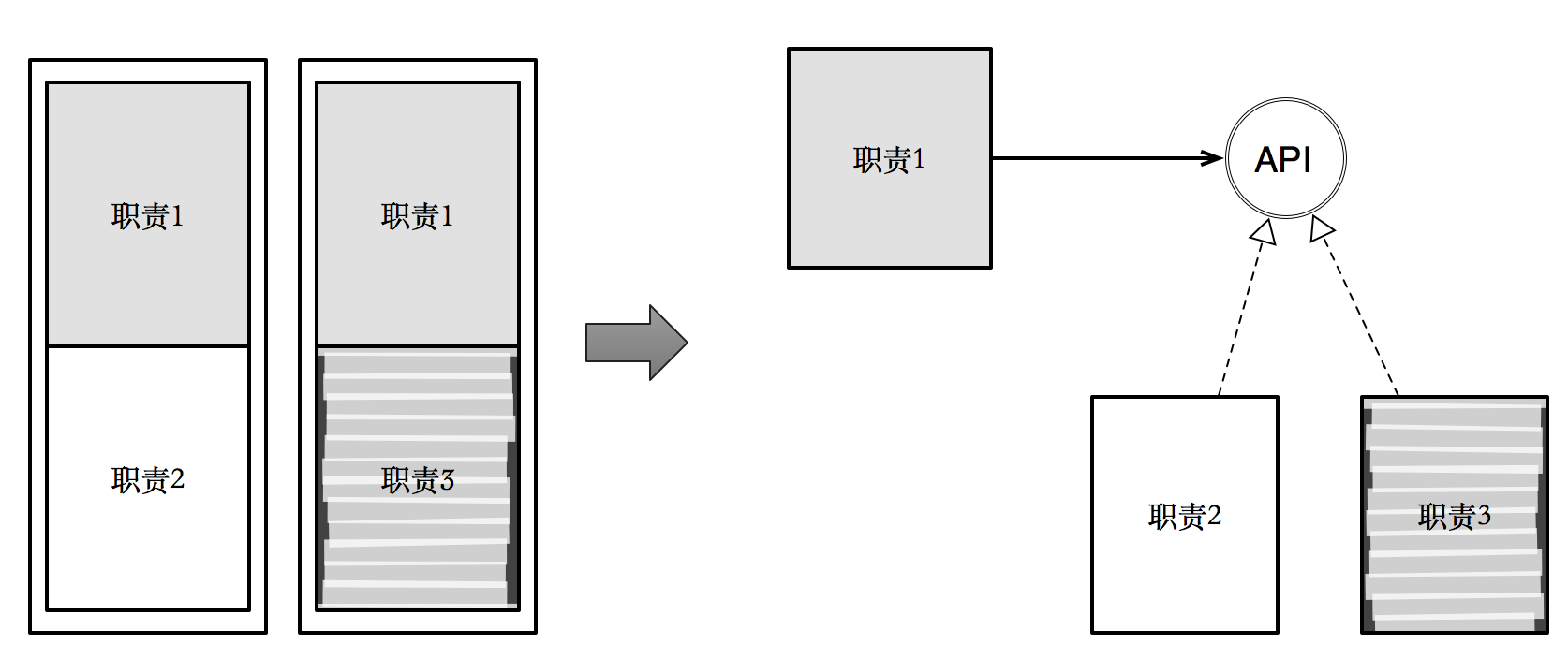
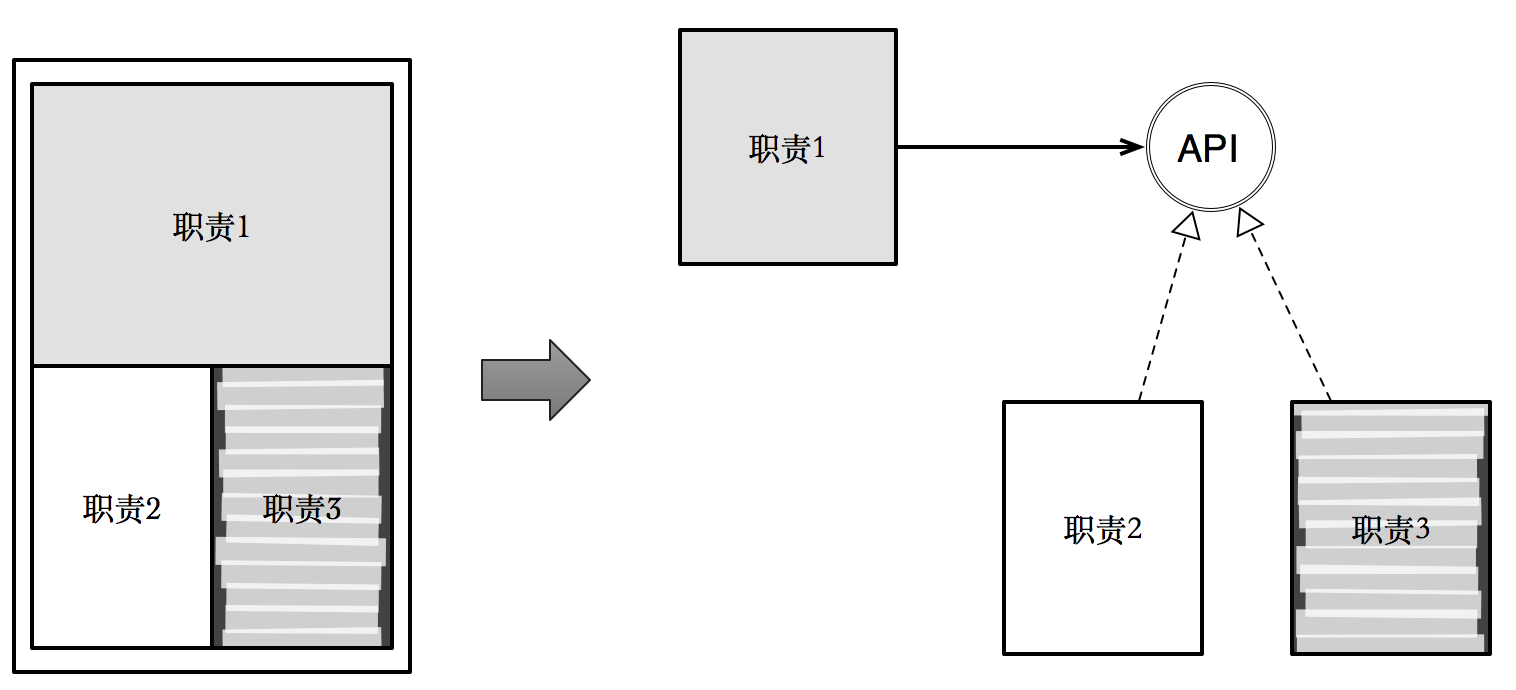
低耦合 (怎么合)
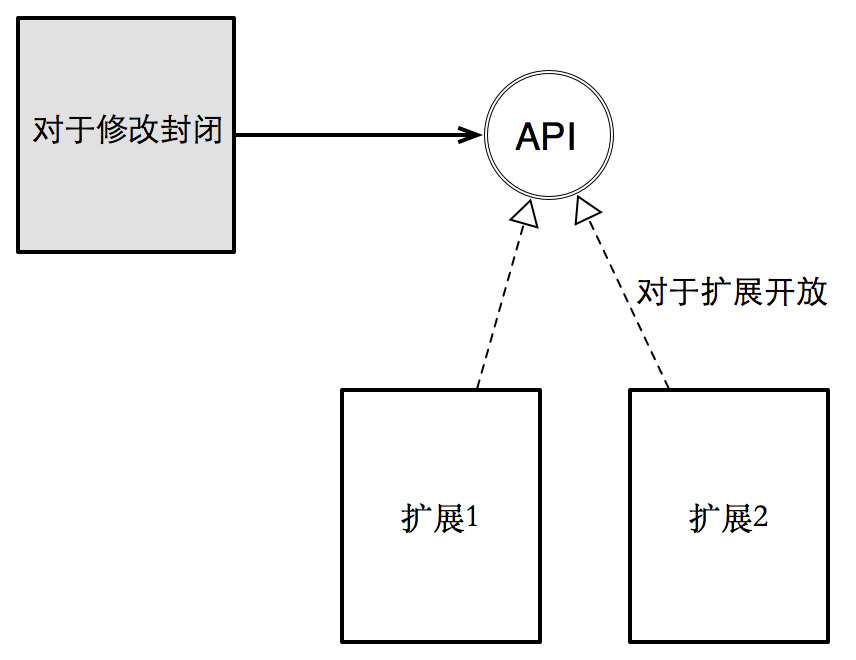
而开放封闭原则,正是通过将不同变化方向进行分离,从而达到对于已经出现的变化方向,对于修改是封闭的,对于扩展是开放的。
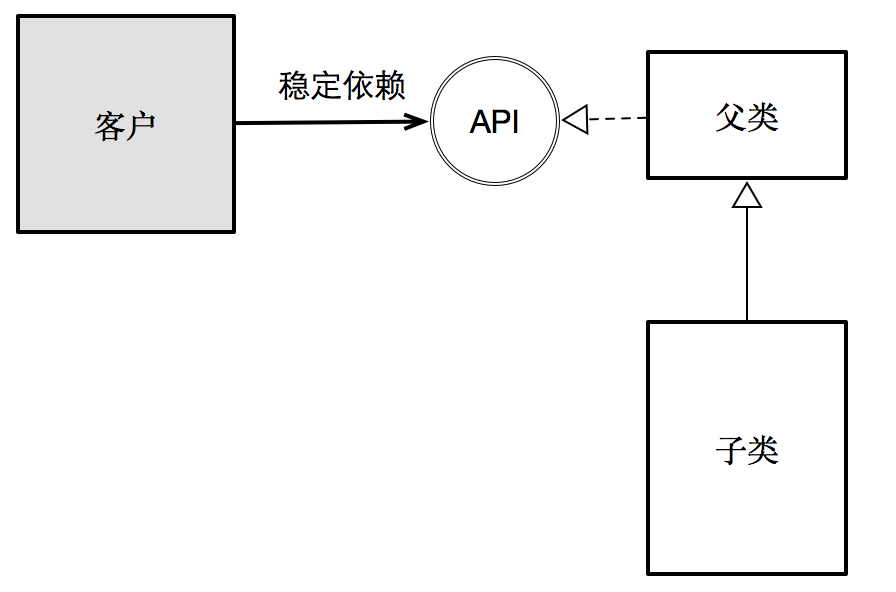
里氏替换原则强调的是,一个子类不应该破坏其父类与客户之间的契约。唯有如此,才能保证:客户与其父类所暴露的接口(即API)所产生的依赖关系是稳定的。子类只应该成为隐藏在API背后的某种具体实现方式。
依赖倒置原则则强调:为了让依赖关系是稳定的,不应该由实现侧根据自己的技术实现方式定义接口,然后强迫上层(即客户)依赖这种不稳定的API定义,而是应该站在上层(即客户)的角度去定义API(正所谓依赖倒置)。
但是,虽然接口由上层定义,但最终接口的实现却依然由下层完成,因此依赖倒置描述为:上层不依赖下层,下层也不依赖上层,双方共同依赖于抽象。
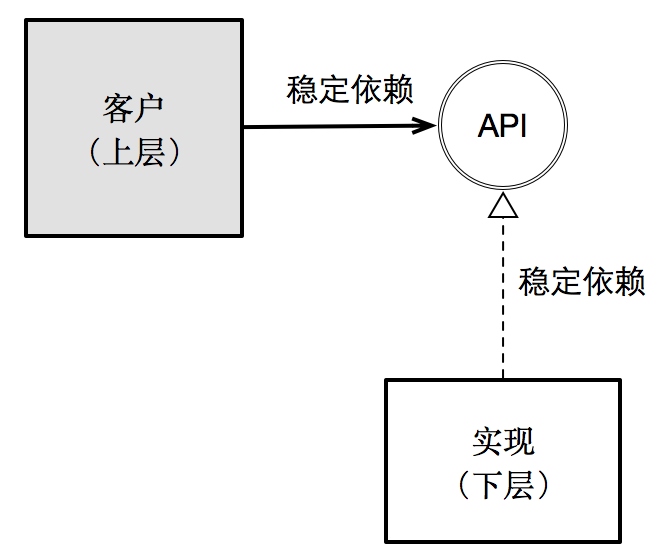
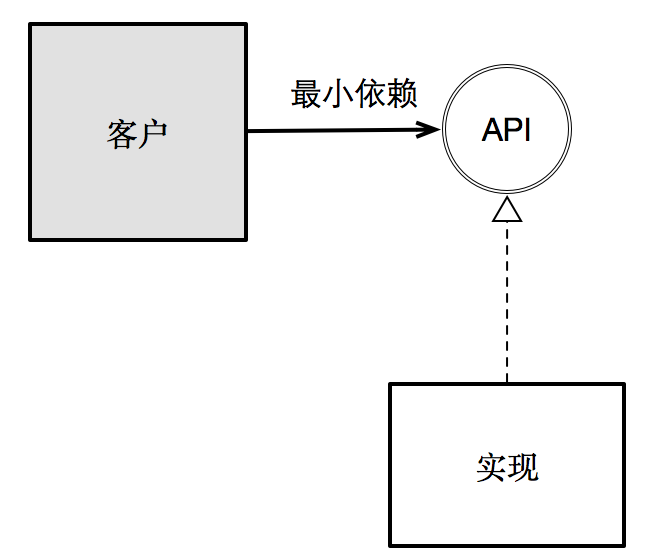
最后,接口隔离原则强调的是:不应该强迫客户依赖它不需要的东西。显然,这是缩小依赖范围策略在面向对象范式下的产物。
结论
正交设计是一种与范式,语言无关的设计原则。为了解决在模块化的过程中,如何让软件在长期范围内更容易应对变化。
而面向对象是一种对模块化支持良好的范式。通过高内聚,低耦合原则,或正交策略的运用,面向对象范式下SOLID原则会自然浮现。
我们耳熟能详的软件设计相关原则,模式与实践的关系如下:
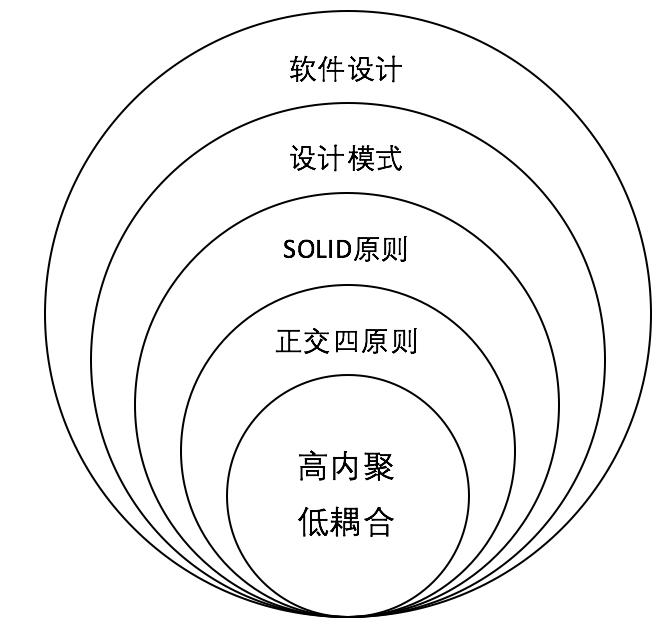
关于正交设计的更多细节,请参阅《变化驱动:正交设计》。
