@fangyang970206
2018-12-01T10:34:25.000000Z
字数 10724
阅读 1206
基于交通灯数据集的端到端分类
pytorch Classification Traffic_Light_Dataset
抓住11月的尾巴,这里写上昨天做的一个DL的作业吧,作业很简单,基于交通灯的图像分类,但这确是让你从0构建深度学习系统的好例子,很多已有的数据集都封装好了,直接调用,这篇文章将以pytorch这个深度学习框架一步步搭建分类系统。
软件包要求:
pytorch:0.4.0
torchsummary:pip install torchsummary
cv2: pip install opencv-python
matplotlib
numpy
所有代码托管到github上,链接如下:https://github.com/FangYang970206/TL_Dataset_Classification,git clone https://github.com/FangYang970206/TL_Dataset_Classification到本地。
1.数据集简介
数据集有10个类别,分别是红灯的圆球,向左,向右,向上和负例以及绿灯的圆球,向左,向右,向上和负例,如下图所示:

数据集的可通过如下链接进行下载:onedrive,baiduyun,google。
下完数据集后,解压到文件夹TL_Dataset_Classification-master中,得到一个新的文件夹TL_Dataset,可以看到TL_Dataset有以下目录:
2.代码实战
代码是在vscode上编写的,支持flask8,总共有9个文件,下面一一介绍。建议在看代码的时候从main.py文件开始看,大致脉络就清楚了。
2.1 model.py
对于一个深度学习系统来说,model应该是最初的想法,我们想构造什么样的模型来拟合数据集,所以先写model,代码如下:
import torch.nn as nnfrom torchsummary import summaryclass A2NN(nn.Module):def __init__(self, ):super(A2NN, self).__init__()self.main = nn.Sequential(nn.Conv2d(3, 16, 3, 1, 1),nn.BatchNorm2d(16),nn.ReLU(inplace=True),nn.Conv2d(16, 32, 3, 1, 1),nn.MaxPool2d(2, 2),nn.BatchNorm2d(32),nn.ReLU(inplace=True),nn.Conv2d(32, 32, 3, 1, 1),nn.MaxPool2d(2, 2),nn.BatchNorm2d(32),nn.ReLU(inplace=True),nn.Conv2d(32, 64, 3, 1, 1),nn.MaxPool2d(2, 2),nn.BatchNorm2d(64),nn.ReLU(inplace=True),)self.linear = nn.Linear(4*4*64, 9)def forward(self, inp):x = self.main(inp)x = x.view(x.shape[0], -1)x = self.linear(x)return xif __name__ == "__main__":nn = A2NN()summary(nn, (3, 32, 32))
model代码不复杂,很简单,这里不多介绍,缺少基础的朋友还请自行补基础。
2.2 dataset.py
第二步我们要构建数据集类,pytorch封装了一个torch.utils.data.Dataset的类,我们可以重载__len__和__getitem__方法,来得到自己的数据集管道,__len__方法是返回数据集的长度,__getitem__是支持从0到len(self)互斥范围内的整数索引,返回的是索引对应的数据和标签。代码如下:
import torchimport cv2import torch.utils.data as dataclass_light = {'Red Circle': 0,'Green Circle': 1,'Red Left': 2,'Green Left': 3,'Red Up': 4,'Green Up': 5,'Red Right': 6,'Green Right': 7,'Red Negative': 8,'Green Negative': 8}class Traffic_Light(data.Dataset):def __init__(self, dataset_names, img_resize_shape):super(Traffic_Light, self).__init__()self.dataset_names = dataset_namesself.img_resize_shape = img_resize_shapedef __getitem__(self, ind):img = cv2.imread(self.dataset_names[ind])img = cv2.resize(img, self.img_resize_shape)img = img.transpose(2, 0, 1)-127.5/127.5for key in class_light.keys():if key in self.dataset_names[ind]:label = class_light[key]# pylint: disable=E1101,E1102return torch.from_numpy(img), torch.tensor(label)# pylint: disable=E1101,E1102def __len__(self):return len(self.dataset_names)if __name__ == '__main__':from torch.utils.data import DataLoaderfrom glob import globimport ospath = 'TL_Dataset/Green Up/'names = glob(os.path.join(path, '*.png'))dataset = Traffic_Light(names, (32, 32))dataload = DataLoader(dataset, batch_size=1)for ind, (inp, label) in enumerate(dataload):print("{}-inp_size:{}-label_size:{}".format(ind, inp.numpy().shape,label.numpy().shape))
2.3 util.py
在上面的dataset.py中,class初始化时,传入了dataset_names,所以utils.py文件中就通过get_train_val_names函数得到训练数据集和验证数据集的names,还有一个函数是检查文件夹是否存在,不存在建立文件夹。代码如下:
import osfrom glob import globdef get_train_val_names(dataset_path, remove_names, radio=0.3):train_names = []val_names = []dataset_paths = os.listdir(dataset_path)for n in remove_names:dataset_paths.remove(n)for path in dataset_paths:sub_dataset_path = os.path.join(dataset_path, path)sub_dataset_names = glob(os.path.join(sub_dataset_path, '*.png'))sub_dataset_len = len(sub_dataset_names)val_names.extend(sub_dataset_names[:int(radio*sub_dataset_len)])train_names.extend(sub_dataset_names[int(radio*sub_dataset_len):])return {'train': train_names, 'val': val_names}def check_folder(path):if not os.path.exists(path):os.mkdir(path)
2.4 trainer.py
model构造好了,数据集也准备好了,现在就需要准备如果训练了,这就是trainer.py文件的作用,trainer.py构建了Trainer类,通过传入训练的一系列参数,调用Trainer.train函数进行训练,并返回loss,代码如下:
import torch.nn as nnfrom torch.optim import Adamclass Trainer:def __init__(self, model, dataload, epoch, lr, device):self.model = modelself.dataload = dataloadself.epoch = epochself.lr = lrself.device = deviceself.optimizer = Adam(self.model.parameters(), lr=self.lr)self.criterion = nn.CrossEntropyLoss().to(self.device)def __epoch(self, epoch):self.model.train()loss_sum = 0for ind, (inp, label) in enumerate(self.dataload):inp = inp.float().to(self.device)label = label.long().to(self.device)self.optimizer.zero_grad()out = self.model.forward(inp)loss = self.criterion(out, label)loss.backward()loss_sum += loss.item()self.optimizer.step()print('epoch{}_step{}_train_loss_: {}'.format(epoch,ind,loss.item()))return loss_sum/(ind+1)def train(self):train_loss = self.__epoch(self.epoch)return train_loss
2.5 validator.py
trainer.py文件是用来进行训练数据集的,训练过程中,我们是需要有验证集来判断我们模型的训练效果,所以这里有validator.py文件,里面封装了Validator类,与Trainer.py类似,但不同的是,我们不训练,不更新参数,model处于eval模式,代码上会有一些跟Trainer不一样,通过调用Validator.eval函数返回loss,代码如下:
import torch.nn as nnclass Validator:def __init__(self, model, dataload, epoch, device, batch_size):self.model = modelself.dataload = dataloadself.epoch = epochself.device = deviceself.batch_size = batch_sizeself.criterion = nn.CrossEntropyLoss().to(self.device)def __epoch(self, epoch):self.model.eval()loss_sum = 0for ind, (inp, label) in enumerate(self.dataload):inp = inp.float().to(self.device)label = label.long().to(self.device)out = self.model.forward(inp)loss = self.criterion(out, label)loss_sum += loss.item()return {'val_loss': loss_sum/(ind+1)}def eval(self):val_loss = self.__epoch(self.epoch)return val_loss
2.6 logger.py
我们想看整个学习的过程,可以通过看学习曲线来进行观察。所以这里写了一个logger.py文件,用来对训练loss和验证loss进行统计并画图。代码如下:
import matplotlib.pyplot as pltimport osclass Logger:def __init__(self, save_path):self.save_path = save_pathdef update(self, Kwarg):self.__plot(Kwarg)def __plot(self, Kwarg):save_img_path = os.path.join(self.save_path, 'learning_curve.png')plt.clf()plt.plot(Kwarg['train_losses'], label='Train', color='g')plt.plot(Kwarg['val_losses'], label='Val', color='b')plt.xlabel('epoch')plt.ylabel('loss')plt.legend()plt.title('learning_curve')plt.savefig(save_img_path)
2.7 main.py
main.py文件将上面所有的东西结合到一起,代码如下:
import torchimport argparsefrom model import A2NNfrom dataset import Traffic_Lightfrom utils import get_train_val_names, check_folderfrom trainer import Trainerfrom validator import Validatorfrom logger import Loggerfrom torch.utils.data import DataLoaderdef main():parse = argparse.ArgumentParser()parse.add_argument('--dataset_path', type=str, default='TL_Dataset/')parse.add_argument('--remove_names', type=list, default=['README.txt','README.png','Testset'])parse.add_argument('--img_resize_shape', type=tuple, default=(32, 32))parse.add_argument('--batch_size', type=int, default=1024)parse.add_argument('--lr', type=float, default=0.001)parse.add_argument('--num_workers', type=int, default=4)parse.add_argument('--epochs', type=int, default=200)parse.add_argument('--val_size', type=float, default=0.3)parse.add_argument('--save_model', type=bool, default=True)parse.add_argument('--save_path', type=str, default='logs/')args = vars(parse.parse_args())check_folder(args['save_path'])# pylint: disable=E1101device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# pylint: disable=E1101model = A2NN().to(device)names = get_train_val_names(args['dataset_path'], args['remove_names'])train_dataset = Traffic_Light(names['train'], args['img_resize_shape'])val_dataset = Traffic_Light(names['val'], args['img_resize_shape'])train_dataload = DataLoader(train_dataset,batch_size=args['batch_size'],shuffle=True,num_workers=args['num_workers'])val_dataload = DataLoader(val_dataset,batch_size=args['batch_size'],shuffle=True,num_workers=args['num_workers'])loss_logger = Logger(args['save_path'])logger_dict = {'train_losses': [],'val_losses': []}for epoch in range(args['epochs']):print('<Main> epoch{}'.format(epoch))trainer = Trainer(model, train_dataload, epoch, args['lr'], device)train_loss = trainer.train()if args['save_model']:state = model.state_dict()torch.save(state, 'logs/nn_state.t7')validator = Validator(model, val_dataload, epoch,device, args['batch_size'])val_loss = validator.eval()logger_dict['train_losses'].append(train_loss)logger_dict['val_losses'].append(val_loss['val_loss'])loss_logger.update(logger_dict)if __name__ == '__main__':main()
2.8 compute_prec.py和submit.py
其实上面的七个文件,已经是结束了,下面两个文件一个是用来计算精确度的,一个是用来提交答案的。有兴趣可以看看。
compute_prec.py代码如下:
import torchimport numpy as npimport argparsefrom model import A2NNfrom dataset import Traffic_Lightfrom torch.utils.data import DataLoaderfrom utils import get_train_val_names, check_folderdef main():parse = argparse.ArgumentParser()parse.add_argument('--dataset_path', type=str, default='TL_Dataset/')parse.add_argument('--remove_names', type=list, default=['README.txt','README.png','Testset'])parse.add_argument('--img_resize_shape', type=tuple, default=(32, 32))parse.add_argument('--num_workers', type=int, default=4)parse.add_argument('--val_size', type=float, default=0.3)parse.add_argument('--save_path', type=str, default='logs/')args = vars(parse.parse_args())check_folder(args['save_path'])# pylint: disable=E1101device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# pylint: disable=E1101model = A2NN().to(device)model.load_state_dict(torch.load(args['save_path']+'nn_state.t7'))model.eval()names = get_train_val_names(args['dataset_path'], args['remove_names'])val_dataset = Traffic_Light(names['val'], args['img_resize_shape'])val_dataload = DataLoader(val_dataset,batch_size=1,num_workers=args['num_workers'])count = 0for ind, (inp, label) in enumerate(val_dataload):inp = inp.float().to(device)label = label.long().to(device)output = model.forward(inp)output = np.argmax(output.to('cpu').detach().numpy(), axis=1)label = label.to('cpu').numpy()count += 1 if output == label else 0print('precision: {}'.format(count/(ind+1)))if __name__ == "__main__":main()
submit.py代码如下:
import torchimport numpy as npimport argparseimport osimport cv2from model import A2NNfrom utils import check_folderdef main():parse = argparse.ArgumentParser()parse.add_argument('--dataset_path', type=str,default='TL_Dataset/Testset/')parse.add_argument('--img_resize_shape', type=tuple, default=(32, 32))parse.add_argument('--num_workers', type=int, default=4)parse.add_argument('--save_path', type=str, default='logs/')args = vars(parse.parse_args())check_folder(args['save_path'])# pylint: disable=E1101device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# pylint: disable=E1101model = A2NN().to(device)model.load_state_dict(torch.load(args['save_path']+'nn_state.t7'))model.eval()txt_path = os.path.join(args['save_path'], 'result.txt')with open(txt_path, 'w') as f:for i in range(20000):name = os.path.join(args['dataset_path'], '{}.png'.format(i))img = cv2.imread(name)img = cv2.resize(img, args['img_resize_shape'])img = img.transpose(2, 0, 1)-127.5/127.5img = torch.unsqueeze(torch.from_numpy(img).float(), dim=0)img = img.to(device)output = model.forward(img).to('cpu').detach().numpy()img_class = np.argmax(output, axis=1)f.write(name.split('/')[2] + ' ' + str(img_class[0]))f.write('\n')if __name__ == "__main__":main()
3. 代码如下运行
将数据集下载在文件夹TL_Dataset_Classification,解压后,在TL_Dataset_Classification文件中进入终端,运行命令:
$ python main.py
如果还想计算精确度,在训练玩数据集之后,运行命令:
$ python compute_prec.py
有运行可以到github上提issue或者在给我的邮箱867540289@qq.com发邮件。
4. 结果
学习曲线:
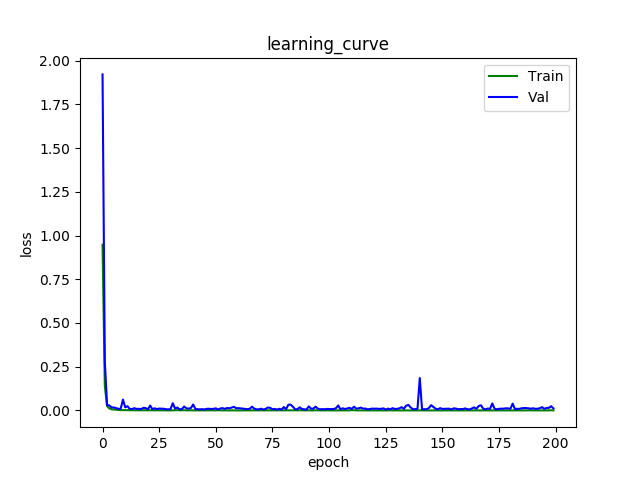
在测试集中,实现97.425%的精确度。(继续提升中)
5. 总结
好了,11月的尾巴到此结束,希望能对你学习深度学习问题和pytorch有所帮助。12月马上到,祝我数学考试顺利,也祝各位开开心心!
