@fangyang970206
2017-12-17T15:58:54.000000Z
字数 18201
阅读 3577
SVM笔记
1.前言
SVM(Support Vector Machine)是一种寻求最大分类间隔的机器学习方法,广泛应用于各个领域,许多人把SVM当做首选方法,它也被称之为最优分类器,这是为什么呢?这篇文章将系统介绍SVM的原理、推导过程及代码实践。
2.初识SVM
首先我们先来看看SVM做的是什么样的事,我们先看下面一张图
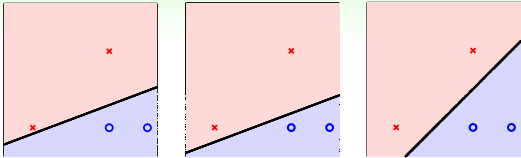
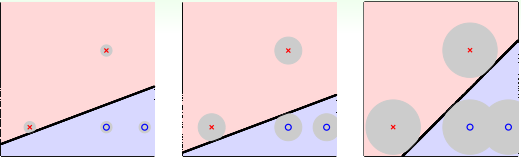
图中有三个分类实例,都将数据正确分类,我们直观上看,会觉得图中第三个效果会比较好,这是为什么呢?个人觉得人的直观感受更偏向于数据均匀对称的结构。当然,这只是直观感受,我们从专业的角度出发,第三种情况更优的原因在于它能容忍更多的数据噪声(tolerate more data noise),从而这个系统更加稳健(Robust),如下图所示,灰色的圈圈代表容忍噪声的大小门限,第三个门限最大,它比前面两个更优,而SVM就是寻求最大门限,构成分离数据正确且抗噪声强的稳健超平面(图中分类线是直线,一般数据维度是高维,对应的分类平面就是超平面)。
3.线性SVM
好了,现在我们知道SVM是那个抗噪声门限最大的超平面(一般说的是间隔margin最大,意思一样),那我们怎样找到这个超平面呢?我们先来分析,这个超平面需要满足那些条件:
- (1) 需要满足将数据都分类正确,以上图为例,超平面为,超平面以上的数据Label为+1,超平面以下的数据Label为-1,则分类正确需要满足 ( 是数据Label )
- (2) 这个超平面关于数据集的最大间隔等于超平面到所有数据集中的样本点的距离的最小值,即
根据上面的条件,我们可以对SVM建立一个最优化模型,目标是最大化间隔,但是这个最优化模型是有限制条件的,即上面提的两个条件.
这样看起来不知道怎么求,那我们现在再进一步地简化这个模型,先简化样本点到超平面的距离,先看下面这一张图
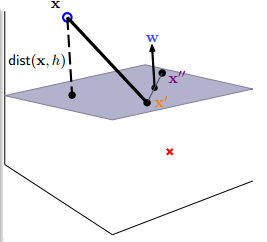
可以取超平面任意点和,它们满足和,将两式相减,得到,这个说明什么呢?由于表示平面上的任意向量,而和它们点乘为0,说明是这个平面的法向量,那距离就好办了,样本点与超平面任一点组成向量,根据我们学过的数学知识知道,平面外一点到平面的距离等于改点与平面内任一点组成的向量点乘上法向量,然后除以法向量的模,即
现在,我们把得到的结果带到原来的模型当中去,得到一个简化模型
现在看看,好像这个模型还是挺复杂的,不知道怎么解,我们在来简化简化,这一项是有些特别的,同倍放大和,这项距离(书上一般写的是几何间隔)是不会变的,我们下面做出了一个强硬的化简:
上面的表达式书上叫做函数间隔,为什么可以这样做呢?实际上我们求距离是用几何间隔,缩放函数间隔不影响几何间隔,举个例子吧,样本点是离超平面最近的点,但是,我们把和同时放缩3.24倍,,几何间隔和以前没变的一样,因为上下是同时缩放的,我们再来看看超平面,也没什么变化,和还是代表同一个超平面.这样缩放后,,而且参数不见了,可以去掉b好了,最小函数间隔为1,所以约束条件也发生了变化。这样简化后,我们再来看看模型变成啥样了
比之前看着简单多了吧,但是这样变换有没有问题呢?其实有一个充要转必要问题,不够直观,原始条件(充要问题)是和,我们把它合起来了,变成(必要问题),后面这个条件其实没有前面两个条件严谨,后面条件不能保证最小值就等于,大于1也同样满足,但其实这里必要问题是等价于充要问题的,为什么呢?我们假设最优在上,满足,可是我们可以找到更优的,同样满足,所以不管怎样,最优一定会在上,所以原问题是等价于简化后的模型的。
为了习惯表示,我们再把最大化问题转化成最小化问题(例如我们习惯用梯度下降法最小化代价函数一样),将变成(,这里去掉了根号和加了一个,加是为了后面求导方便,不影响最优化问题),所以原模型也可以再进一步化简:
好了,我们已经得到非常精简的模型,那么我们现在该想想,要用什么方法去得到这个最优解呢?梯度下降法可不可以呢?好像不太适用,梯度下降法没有约束条件,那怎么办?幸运的是,这是一个二次规划(quadratic programming)问题,简称QP问题,QP问题需要符合两个条件:
- (1) 一个是目标函数是关于自变量的二次函数,而且函数需要是凸(convex)函数,显然,是二次函数,而且确实是凸函数。
- (2) 约束条件必须是关于自变量的线性约束条件,可以看出最后的模型约束条件确实是线性约束条件。
下面举个小例子
是二维平面上的点,分别是,对应中的,现在用上面最优化的模型进行求解超平面,带入所有数据点,可得到如下限制条件:
结合(i)~(iv),得到和,从而得到,所以最优解,最后可画出如下图像
四个点我们算起来可能很容易,但40000个点呢,手算就不切实际了,自己编工作量太大,而且规范性差,还好,前辈们建立很多解优化问题的库,例如libsvm,cvxpy等等。一般求解二次规划函数都可以用以下格式表示:
将上面的模型带入这个优化函数,参数分别如下:
下面用matlab(使用quadprog函数)和python(基于cvxpy)分别生成一个线性可分数据集的分类器
MATLAB版
% 实现线性可分SVMclear all ; close all;file = importdata('testSet.txt');[m,n] =size(file);x_1 = file(:,1);x_2 = file(:,2);y_n = file(:,3);file_1 = sortrows(file,3);%根据第三列进行排序CountNegative1 = sum(y_n==-1);x_3 = file_1(1:CountNegative1,1); %当y_n 是-1的时候,存对应的x_1x_4 = file_1(1:CountNegative1,2); %当y_n 是-1的时候,存对应的x_2x_5 = file_1(CountNegative1+1:m,1); %当y_n 是1的时候,存对应的x_1x_6 = file_1(CountNegative1+1:m,2); %当y_n 是1的时候,存对应的x_2figure;scatter(x_3,x_4,'red','fill');hold on;scatter(x_5,x_6,'blue','fill');H = [0 0 0;0 1 0;0 0 1];p = [0;0;0];A = [ones(CountNegative1,1),file_1(1:CountNegative1,1:2);-ones(m-CountNegative1,1),- file_1(CountNegative1+1:m,1:2)];c = -ones(m,1);u = quadprog(H,p,A,c); %求出参数[b,w]x = linspace(2,8,400);y = -(u(1)/u(3)+u(2)/u(3)*x);plot(x,y,'green');sv_index = find(abs(u'*[ones(m,1),file_1(:,1:2)]')-1<1e-5);[m1,n1]=size(sv_index);for i = 1:n1x_sv =file_1(sv_index(i),1);y_sv =file_1(sv_index(i),2);plot(x_sv,y_sv,'o','Markersize',20);end
这里程序不多讲,懂上面原理,理解程序还是挺简单的,函数不懂的请看MATLAB的帮助文档,这里用的testSet.txt其实是机器学习实战SVM一节的数据集(下载链接),最后运行的结果如下图所示(那些用圈圈圈起来的点叫支持向量Support vecter,是离超平面最近的点)
python版
import cvxpy as cvximport numpy as npf = open('testSet.txt')X1_Neg1 = []X1_Pos1 = []X2_Neg1 = []X2_Pos1 = []constraints = []for line in f.readlines():lineSplit = line.strip().split('\t')xAxis = float(lineSplit[0])yAxis = float(lineSplit[1])label = int(lineSplit[2])if label == 1:X1_Pos1.append(xAxis)X2_Pos1.append(yAxis)else:X1_Neg1.append(xAxis)X2_Neg1.append(yAxis)u = cvx.Variable(3)H = np.array([[0,0,0],[0,1,0],[0,0,1]])objective = cvx.Minimize(1.0/2*cvx.quad_form(u,H))for X_Pos1 in zip(X1_Pos1,X2_Pos1):temp1 = np.zeros([3,1])temp1[0] = 1temp1[1] = X_Pos1[0]temp1[2] = X_Pos1[1]constraints.append(temp1.T*u >= 1)for X_Neg1 in zip(X1_Neg1,X2_Neg1):temp2 = np.zeros([3,1])temp2[0] = 1temp2[1] = X_Neg1[0]temp2[2] = X_Neg1[1]constraints.append(-(temp2.T*u) >= 1)prob = cvx.Problem(objective,constraints)prob.solve()print('optimal var:\n\r',u.value)
这里图就不画了,和上面一样。
4.非线性SVM
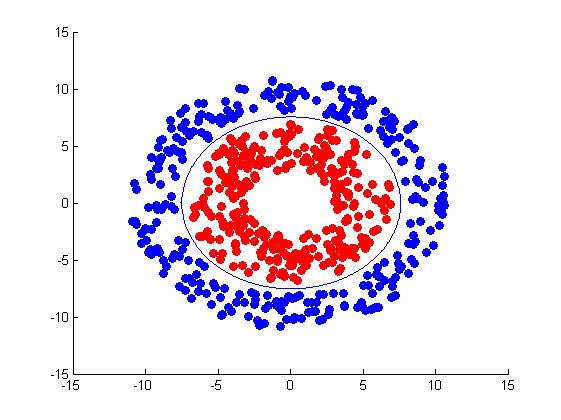
线性SVM是有很大的局限性的,并不是所有数据都能用线性SVM分类,以下图为例,你很难用线性SVM进行分类达到高准确,线性SVM最高只能达到75%准确度。
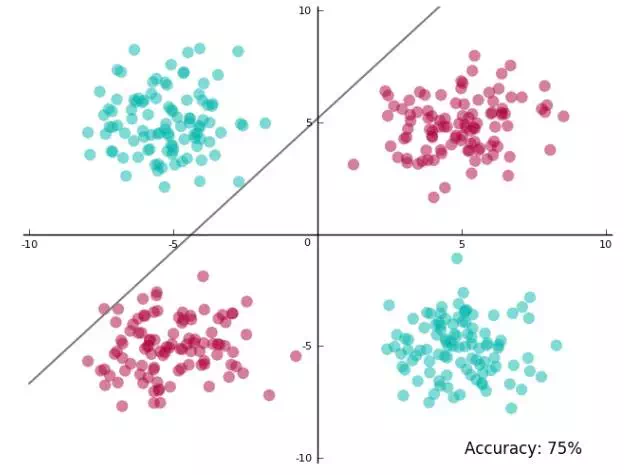
这时候就需要用到一个知识————特征转换(feature transform)
我们将二维数据映射到三维上,转换关系如下
原始数据集分布就变成下图分布
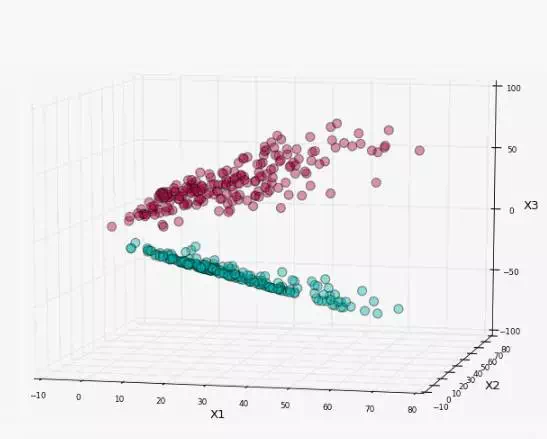
我们就可以在当前三维分布利用线性SVM进行分类,如图所示
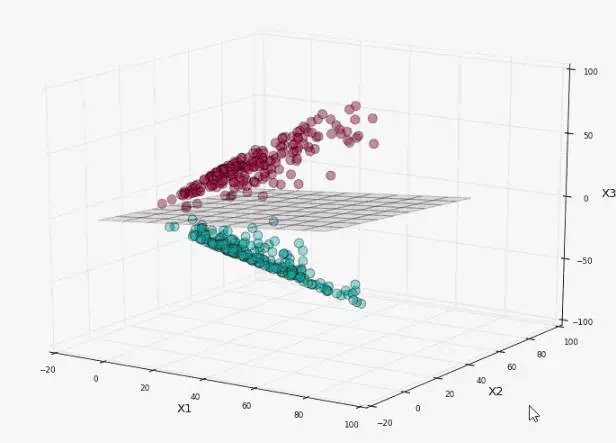
看起来分离得很好,我们再将平面映射回初始的二维空间中,看看决策边界时什么样子
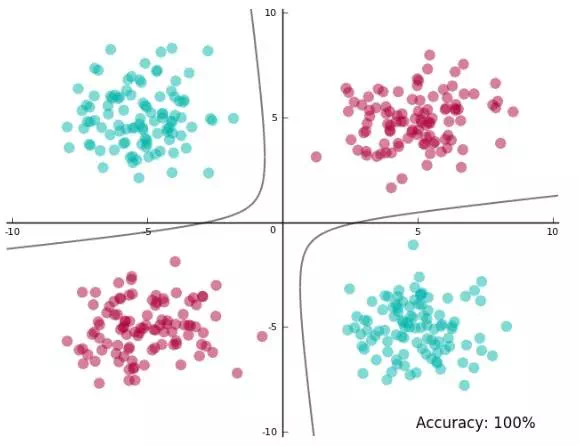
可以看到决策边界不是线性的了,还是两条歪曲的曲线构成的,这就是非线性SVM的一个典型例子,它将数据映射到更高维空间,然后在高维进行线性SVM,最后映射回到原来的状态,得到复杂的决策边界————曲面形(原因在于特征转换是非线性的,所以映射回来,高维线性变成低维非线性)。
我们再来看看非线性SVM模型
这样看起来和线性SVM的模型一样,但其实有区别,约束条件中的是经过特征转换得到的,由于是高维的,也会发生相应的变化,具体要看的维度(和维度相同),我们利用优化库去解这个二次规划问题的方法和之前提到的线性SVM方法几乎一样,假设的维度是,我们可以列出下面的表达式
看起来非线性SVM已经介绍完了,其实这里遗留了一个问题,我们现在的变量维度是,限制条件的个数为N(N为样本数),我们要特别注意这个,它的维度会非常高,以64x64x3的图片为例,它映射后的是百万级的,这样也是百万级的,这无疑是巨大的计算量,前辈们对这一问题,提出了一个非常好的解决方案————引入拉格朗日对偶,将原始问题转换对偶问题,从而极大简化了计算量
Original SVM Equivalent SVM
我们接下来来看看这个转换是如何做到的,首先这里要引入一个拉格朗日乘子法,将原始带有限制条件问题,转换成没有限制条件的问题,原始问题经过拉格朗日乘子法后,得到如下表达式(其中是拉格朗日乘子):
这样,原始问题就可以转化成求解,那么为什么可以这样转换呢?我们可以先分析里面这一项,里面最大化的自变量只有,我们现在可以分情况讨论了
- 如果使得,由于是取最大值且,那么会趋近于无穷大,这样我们在最外层的最小化会将它淘汰掉(最小化无穷大没有意义)
- 如果使得,那么会趋近于0,我们的最大值就是,这样外层最小化才可以进行.
- 所以这里是隐藏在最大化中,也就是原始约束条件并没有消失,只是换了一种方式。
好了,现在我们已经将原始问题转化成求解,那我们在进行下一步地操作吧,我们知道对于任意,有
这是因为最大值大于等于任意取值,然后我们再往右边加一个最大化,得
加上后依然成立,这是因为最好的也是任意中的一个。
然后,我们是可以把换成,这是由于原问题满足以下三个条件
- 原问题是一个凸的二次规划问题
- 原问题是有解的
- 限制条件是线性约束条件
满足上面三个条件,就可以将的弱对偶转换成的强对偶,具体证明我也不清楚,这是前辈们推导出来了,知道就行了,好了,这就完成了拉格朗日对偶,如下
我们接下来用对偶SVM来求解原问题,对偶SVM如下
里面的最小化是没有约束条件的,约束条件在最大化上,于是我们可以取梯度为0来求极值,由=0,得,代入对偶SVM,化简得
再由=0,得,代入对偶SVM,化简得
将上面的表达式再变换一下,得
好了,到现在,我们终于把原始的转换成。
我们根据上面的推导知道,原始和对偶之间是满足一些条件的,Karush,Kuhn,Tucker三位科学家总结了它们之间的关系,包含四个条件:
primal-dual optimal(w,b,)
(1) 原问题需满足
(2) 对偶问题
(3) 对偶问题最优解
(4) =0
后人命名为KKT条件(Karush-Kuhn-Tucker,以三位科学家命名),根据KKT条件,我们就可以通过求解,求显而易见,这里说一下,根据KKT第四个条件,当的一个分量大于0时,对应的点必须满足,从而可以求出
下面进行代码实践
matlab版
%非线性SVMclear all ; close all;data = csvread('test_nonlinear_SVM.csv');[m,n] = size(data);figure;scatter(data(1:300,1),data(1:300,2),'red','fill');hold on;scatter(data(301:600,1),data(301:600,2),'blue','fill');%feature transfrom x3 = x1^2+x2^2(x1,x2不变)data_z = [data(:,1),data(:,2),data(:,1).^2+data(:,2).^2,data(:,3)];H = (kron(data_z(:,4),ones(1,3)).*data_z(:,1:3))*(data_z(:,1:3)'.*kron(data_z(:,4),ones(1,3))');f = -ones(m,1);A = -eye(m);b = zeros(m,1);Aeq = data_z(:,4)';beq = 0;alpha = quadprog(H,f,A,b,Aeq,beq);%每个参数的具体意义请参考quadprog函数w = (alpha.*data_z(:,4))'*data_z(:,1:3);b = -1-w*data_z(377,1:3)'; %第377个点的alpha大于0x = linspace(-7.6,7.6,400);y1 = sqrt((-(b+w(1)*x+w(3)*x.^2)/w(3))+((w(2)^2)/(4*w(3))))-w(2)/(2*w(3));y2 = -sqrt((-(b+w(1)*x+w(3)*x.^2)/w(3))+((w(2)^2)/(4*w(3))))-w(2)/(2*w(3));plot(x,y1);plot(x,y2);
这里cmd markdown有一个高亮bug,代码单引号与markdown的单引号冲突,不用管,直接复制用就可以了,test_nonlinear_SVM.csv和生成它的matlab代码请在这个百度云链接下载,这里说一下y1和y2,我们知道决策边界是,而,x1已经用linspace生成,画图,我们需要求x2,根据方程,我们可以求出x2的两个解(即y1和y2),最后运行结果如下
import numpy as npimport cvxpy as cvxtmp = np.loadtxt(open("test_nonlinear_SVM.csv","rb"),delimiter=',',skiprows=0)X,Y = tmp[:,0:2],tmp[:,2]X_z = np.array([X[:,0],X[:,1],X[:,0]**2+X[:,1]**2])alpha = cvx.Variable(X.shape[0],1)H = np.dot((X_z*np.kron(Y,np.ones([3,1]))).T,(X_z*np.kron(Y,np.ones([3,1]))))f = -np.ones([X.shape[0],1])objective = cvx.Minimize(1.0/2*cvx.quad_form(alpha,H)+cvx.sum_entries(cvx.mul_elemwise(f,alpha)))constraints = [alpha>=0,cvx.sum_entries(cvx.mul_elemwise(Y,alpha))==0]prob = cvx.Problem(objective,constraints)prob.solve()print('alpha_value:',alpha.value)w = np.dot((np.array(alpha.value)*Y.reshape((X.shape[0],1))).T,X_z.T)b = Y[np.argmax(alpha.value)]-np.dot(w,X_z[0:3,np.argmax(alpha.value)].reshape(3,1))print('w:',w,'\r\n','b:',b)
图就不画了,和matlab的差不多,大家可以将结果与matlab的最优w和最优b进行比较
5.kernel SVM
核SVM的引入,将大大减少上面非线性SVM的计算量,我们知道,根据上面非线性SVM问题,需要计算,而我们要注意一下,的维度通常情况是远远大于的维度的,甚至可以是无限大(上面实例为了简单,画图方便,差的维度看不太出来),当转换到非常高的维度时,的内积计算量会是非常大的,这时发现了一种新的方法,使用它,大大减少了计算量,这个方法叫核方法。
以二次多项式变换为例,原始的维度是,变换后的维度是
所以
一般的二次项核(更常用)可以表达为如下形式
通用多项式核可以如下表示
(1)比线性核(xx')强大,限制更小
(2)Q值具有强控制性
多项式核的缺陷
(1)数值计算困难,时,会非常大,当时,会非常小,趋近于0
(2)三个参数()很不好选
下面介绍高斯核,也叫RBF kernel,高斯核是可以表示无限维度的,下图是原理推导
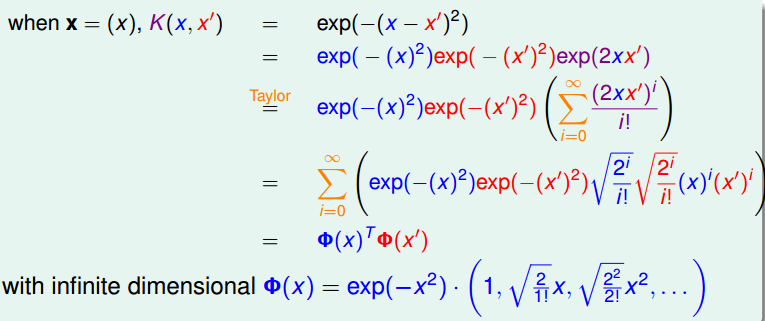
一般的高斯核可以表示为如下表达式
(1)比多项式核和线性核更强大
(2)数值计算困难程度比多项式核小
(3)只有一个参数,比较好选择
高斯核的缺陷
(1)没有w(无限维度的原因)
(2)运算速度比线性慢
(3)太强大,容易过拟合,如下图

给定一个函数K,我们如何怎样判断它是否是一个有效的核函数呢?
给定m个训练样本,每一个对应一个特征向量。那么,我们可以将任意两个和带入K中,计算得到。i可以从1到m,j可以从1到m,这样可以计算出m*m的核函数矩阵。如果假设K是有效地核函数,则有
下面来看看另一个条件,对于任意向量z,有

由此知道矩阵K需要是半正定的,综合起来K是有效的核函数 <==> 核函数矩阵K是对称半正定的。
python实践(仅供参考,cvx.quad_form(alpha,Q)不遵守DCP,我用非线性SVM算出的Q没问题,这个就有问题,具体原因不清楚)
import numpy as npimport h5pyimport cvxpy as cvxdef load_dataset():train_dataset = h5py.File('datasets/train_catvnoncat.h5', "r")train_set_x_orig = np.array(train_dataset["train_set_x"][:]) # your train set featurestrain_set_y_orig = np.array(train_dataset["train_set_y"][:]) # your train set labelstest_dataset = h5py.File('datasets/test_catvnoncat.h5', "r")test_set_x_orig = np.array(test_dataset["test_set_x"][:]) # your test set featurestest_set_y_orig = np.array(test_dataset["test_set_y"][:]) # your test set labelsclasses = np.array(test_dataset["list_classes"][:]) # the list of classestrain_set_y_orig = train_set_y_orig.reshape((1, train_set_y_orig.shape[0]))test_set_y_orig = test_set_y_orig.reshape((1, test_set_y_orig.shape[0]))for i in range(train_set_y_orig.shape[1]):if(train_set_y_orig[0,i]==0):train_set_y_orig[0,i]=-1for i in range(test_set_y_orig.shape[1]):if(test_set_y_orig[0,i]==0):test_set_y_orig[0,i]=-1return train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classesdef main():train_set_x_orig, train_set_y, test_set_x_orig, test_set_y, classes = load_dataset()train_set_x_orig=train_set_x_orig.reshape((train_set_x_orig.shape[0],-1))alpha = cvx.Variable(train_set_x_orig.shape[0],1)f = -np.ones([train_set_x_orig.shape[0],1])K2 = (np.ones([train_set_x_orig.shape[0],train_set_x_orig.shape[0]])+1.0/2*np.dot(train_set_x_orig,train_set_x_orig.T))**2y_m=np.kron(train_set_y,np.ones([train_set_x_orig.shape[0],1]))Q=np.array(y_m.T*K2*y_m)objective = cvx.Minimize(1.0/2*cvx.quad_form(alpha,Q)+cvx.sum_entries(cvx.mul_elemwise(f,alpha)))constraints = [alpha>=0,cvx.sum_entries(cvx.mul_elemwise(train_set_y.T,alpha))==0]prob = cvx.Problem(objective,constraints)prob.solve()if __name__ == '__main__':main()
6.软间隔SVM
有的时候,我们强行要把所有的样本点都分隔正确,会产生过拟合。如下图所示
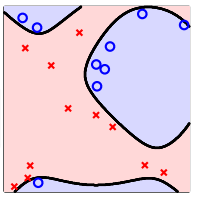
这个时候,我们可以放低标准,容许分类器有一定的错误,像下图一样
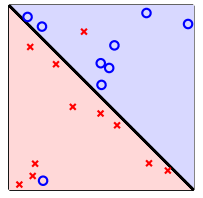
这样做的好处是使分类器准确地泛化了样本的分布,这样的SVM分类器叫软间隔SVM,那么怎样实现它呢?
首先,我们需要对原始问题进行修改
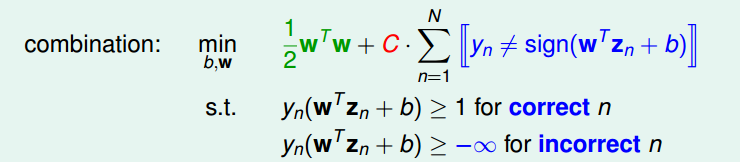
这里引入了变量C,它是用来平衡大间隔和容忍噪声的,C越大,对噪声容忍度越小,希望分类错误的点越少越好,反之,C越小,则希望我们的大间隔越大越好
将上面两个条件合起来,得到如下问题
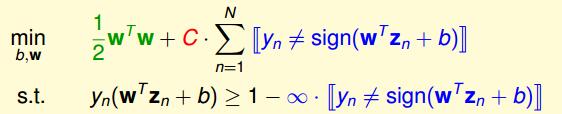
但这里出现两个问题了,一个是【】非线性的,这样导致这个问题不是QP问题,对偶和核函数都用不了,第二个是这样的问题不能区分小错误和大错误,比如,一个分类错误样本离边界0.001和离边界1000,这样分类器认为这两种是一样的,这显然也不合适。
于是,我们引入参数,表示错误的点离间隔边界的距离,用它替换条件中的【】,这样限制条件变成了线性的,同时,最小化中的错误个数计数也被错误程度取代,问题也变成了QP问题,皆大欢喜!
soft-margin SVM:
现在我们来看看这个QP问题的变量和条件,变量有(有,有1个,有个),限制条件有个
接下来就是用拉格朗日对偶来去掉,过程详细解说就不写了,原理和上面对偶SVM类似,这里附上过程
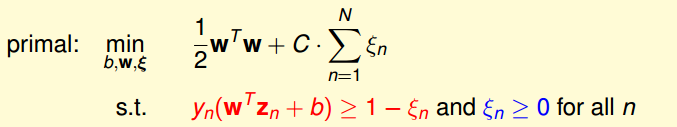
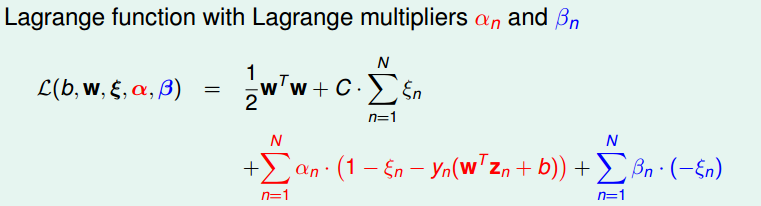

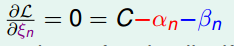
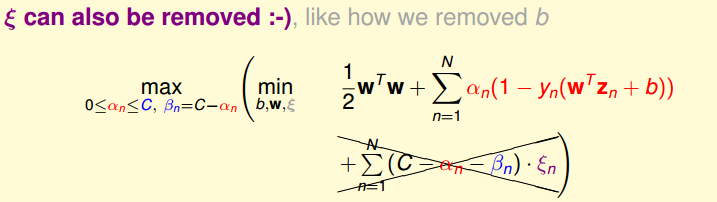

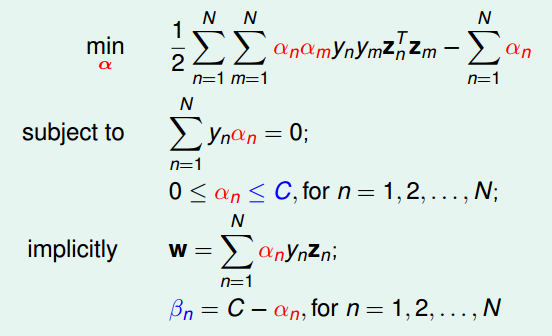
最后得到N个变量和2N+1个限制条件的QP问题。
参考:
1 林轩田——机器学习技法课程
2 http://blog.csdn.net/myarrow/article/details/51261971
