@jsongao98
2021-04-24T11:46:56.000000Z
字数 30466
阅读 267
浏览器:文档,事件,接口
JavaScript
window根对象,一是JavaScript代码的全局对象,二是它代表“浏览器窗口”,并提供了控制它的方法。
浏览器对象模型(Browser Object Model),简称 BOM,表示由浏览器(主机环境)提供的用于处理文档(document)之外的所有内容的其他对象。
文档对象模型(Document Object Model),简称 DOM,将所有页面内容表示为可以修改的对象。我们可以使用它来更改或创建页面上的任何内容。
DOM节点类(继承)
HTMLInputElement — 该类提供特定于输入的属性,
HTMLElement — 它提供了通用(common)的 HTML 元素方法(以及 getter 和 setter)
Element — 提供通用(generic)元素方法,
Node — 提供通用 DOM 节点属性,
EventTarget — 为事件(包括事件本身)提供支持,
……最后,它继承自 Object,因为像 hasOwnProperty 这样的“普通对象”方法也是可用的:
alert( document.body.constructor.name ); // HTMLBodyElement
alert( document.body ); // [object HTMLBodyElement]
DOM节点类是常规的JavaScript对象,它们使用基于原型的类进行继承。
alert( document.body instanceof HTMLBodyElement ); // true
alert( document.body instanceof HTMLElement ); // true
alert( document.body instanceof Element ); // true
alert( document.body instanceof Node ); // true
alert( document.body instanceof EventTarget ); // true
DOM树
在DOM树中,标签被称为元素节点,元素节点的根节点是
<html>,元素内文本被称为文本节点,一个文本节点只包含一个字符串,没有子项,总是树的叶子。HTML 中的所有内容,甚至注释,都会成为 DOM 的一部分。甚至 HTML 开头的
<!DOCTYPE...>指令也是一个 DOM 节点。它在 DOM 树中位于<html>之前。我们不会触及那个节点,出于这个原因,我们甚至不会在图表中绘制它,但它确实就在那里。表示整个文档的 document 对象,在形式上也是一个 DOM 节点。总共有12种节点类型,一般用到document、元素节点、文本节点、注释节点。
DOM节点的导航(navigation)属性
1.下列属性可访问所有类型的节点:
childNodes,parentNode,nextSibling,previousSibling
firstChild 和 lastChild 属性是访问第一个和最后一个子元素的快捷方式。
elem.childNodes[0] === elem.firstChild
elem.childNodes[elem.childNodes.length - 1] === elem.lastChild
elem.hasChildNodes() 用于检查节点是否有子节点2.只针对元素节点的一组属性
parentElement,children,firstElementChild,lastElementChild,previousElementSibling,nextElementSibling小细节:parentNode和parentElement,唯一的例外就是 document.documentElement:
alert( document.documentElement.parentNode ); // document
alert( document.documentElement.parentElement ); // null,因为document不是元素节点3.其他元素的一些特定属性
table元素:rows(
<tr>的集合)、cells(<td>的集合)...
...4.DOM集合
DOM集合是一个可迭代的类数组对象
只读、实时,for-of
DOM节点其他属性
console.log(elem) 和 console.dir(elem)
nodeType 通过数值类型查看节点类型,只读取,也可用instanceof查看。
nodeName,tagName 读取标签名,前者支持node后者只支持element类型节点elem.hidden = true 等同于 display:none
DOM节点方法
特性与属性(Attributes and properties)
当浏览器加载页面时,它会“读取”(或者称之为:“解析”)HTML 并从中生成 DOM 对象。对于元素节点,大多数标准的(规范中查看) HTML 特性(attributes)会自动变成 DOM 对象的属性(properties)。但特性—属性映射并不是一一对应的。
DOM属性,方法跟一般JavaScript对象无异。
所有特性都可以通过使用以下方法进行访问:
elem.hasAttribute(name) — 检查特性是否存在。
elem.getAttribute(name) — 获取这个特性值。
elem.setAttribute(name, value) — 设置这个特性值。
elem.removeAttribute(name) — 移除这个特性。
elem.attributes — 读取所有特性,生成一个name-value映射的可迭代对象。特性的值一定是字符串类型,DOM属性值是多类型的。//我们想要读取 HTML 中“所写的”值。对应的 DOM 属性可能不同,例如 href 属性一直是一个 完整的 URL,但是我们想要的是“原始的”值。(...)
特性-属性同步问题(input.value)我们需要一个非标准的特性。所有以 “data-” 开头的特性均被保留供程序员使用。它们可在 dataset 属性中使用。
一个例子:使外部链接(包含:// 且不以http://internal.com开头).style.color = orange
<a name="list">the list</a><ul><li><a href="http://google.com">http://google.com</a></li><li><a href="/tutorial">/tutorial.html</a></li><li><a href="local/path">local/path</a></li><li><a href="ftp://ftp.com/my.zip">ftp://ftp.com/my.zip</a></li><li><a href="http://nodejs.org">http://nodejs.org</a></li><li><a href="http://internal.com/test">http://internal.com/test</a></li></ul><script>// 查找所有 href 中包含 :// 的链接// 但 href 不是以 http://internal.com 开头let selector = 'a[href*="://"]:not([href^="http://internal.com"])';let links = document.querySelectorAll(selector);links.forEach(link => link.style.color = 'orange');</script>
查找 getElement*,querySelector*
document.getElementById('...')// 因为id的唯一性,所以有且仅有document
elem.getElementsByTagName(tag)// tagName 大写
elem.getElementsByClassName(className)
document.getElementsByName(name)document.querySelectorAll('...')
document.querySelector('...') 调用会返回给定 CSS 选择器的第一个元素。
换句话说,结果与 elem.querySelectorAll(css)[0] 相同,但是后者会查找 所有 元素,并从中选取一个,而 elem.querySelector 只会查找一个。因此它在速度上更快,并且写起来更短。elem.matches() 用于检查 elem 与给定的 CSS 选择器是否匹配。
elem.closest() 用于查找与给定 CSS 选择器相匹配的最近的祖先。elem 本身也会被检查。一种用来检查子级与父级之间关系的方法,因为它有时很有用:
如果 elemB 在 elemA 内(elemA 的后代)或者 elemA==elemB,elemA.contains(elemB) 将返回 true。区别:getElementsBy*返回一个实时的NodeList集合,这样的集合始终反映的是文档的当前状态,并且在文档发生更改时会“自动更新”。querySelectorAll返回一个静态的集合。集合有forEach方法...
插入
1.创建一个DOM节点:
document.createElement(tag)
document.createTextNode('text')2.添加DOM属性,比如className,innerHTML...
elem.innerHTML
innerHTML 属性允许将元素中的 HTML 获取为字符串形式。仅对元素节点有效。
innerHTML += ...做了以下工作:
移除旧的内容。
然后写入新的 innerHTML(新旧结合)。
因为内容已“归零”并从头开始重写,因此所有的图片和其他资源都将重写加载。
elem.outerHTML注意:与 innerHTML 不同,写入 outerHTML 不会改变元素。而是在 DOM 中替换它。
在div.outerHTML = ...中发生的事情是:
div 被从文档(document)中移除。
另一个 HTML 片段被插入到其位置上。
div 仍拥有其旧的值。新的 HTML 没有被赋值给任何变量。
node.data文本节点内容( 一般带字符串前后带空格,输出时用trim()方法清一下空格 )
elem.textContent纯文本使用 innerHTML,我们将其“作为 HTML”插入,带有所有 HTML 标签。
使用 textContent,我们将其“作为文本”插入,所有符号(symbol)均按字面意义处理。3.所有插入方法都会自动从旧位置删除该节点。
-插入DOM节点,文本字符串
node.append(...nodes or strings) —— 在 node 末尾 插入节点或字符串,
node.prepend(...nodes or strings) —— 在 node 开头 插入节点或字符串,
node.before(...nodes or strings) —— 在 node 前面 插入节点或字符串,
node.after(...nodes or strings) —— 在 node 后面 插入节点或字符串,
node.replaceWith(...nodes or strings) —— 将 node 替换为给定的节点或字符串。
这些方法的参数可以是一个要插入的任意的 DOM 节点列表,或者文本字符串(会被自动转换成文本节点)。比如像‘<html>’中的括号就会自动转义为字符串,出现乱码。-插入HTML代码
"beforebegin" — 将 html 插入到 elem 前插入,
"afterbegin" — 将 html 插入到 elem 开头,
"beforeend" — 将 html 插入到 elem 末尾,
"afterend" — 将 html 插入到 elem 后。
elem.insertAdjacentHTML(where, html)
elem.insertAdjacentText(where, text) — 语法一样,但是将 text 字符串“作为文本”插入而不是作为 HTML,
elem.insertAdjacentElement(where, elem) — 语法一样,但是插入的是一个元素。
它们的存在主要是为了使语法“统一”。实际上,大多数时候只使用 insertAdjacentHTML。因为对于元素和文本,我们有 append/prepend/before/after 方法 — 它们也可以用于插入节点/文本片段,但写起来更短。4.节点移除
node.remove()
请注意:如果我们要将一个元素 移动 到另一个地方,则无需将其从原来的位置中删除
<div id="first">First</div><div id="second">Second</div><script>// 无需调用 removesecond.after(first); // 获取 #second,并在其后面插入 #first</script>
5.克隆节点
调用elem.cloneNode(true)来创建元素的一个“深”克隆 — 具有所有特性(attribute)和子元素。如果我们调用elem.cloneNode(false),那克隆就不包括子元素。6.DocumentFragment是一个特殊的 DOM 节点,用作来传递节点列表的包装器(wrapper)。
几个例子
1.日历
<!DOCTYPE HTML><html><head><style>table {border-collapse: collapse;}td,th {border: 1px solid black;padding: 3px;text-align: center;}th {font-weight: bold;background-color: #E6E6E6;}</style></head><body><div id="calendar"></div><script>function createCalendar(elem, year, month) {let mon = month - 1; // months in JS are 0..11, not 1..12let d = new Date(year, mon);let table = '<table><tr><th>MO</th><th>TU</th><th>WE</th><th>TH</th><th>FR</th><th>SA</th><th>SU</th></tr><tr>';// spaces for the first row// from Monday till the first day of the month// * * * 1 2 3 4for (let i = 0; i < getDay(d); i++) {table += '<td></td>';}// <td> with actual dateswhile (d.getMonth() == mon) {table += '<td>' + d.getDate() + '</td>';if (getDay(d) % 7 == 6) { // sunday, last day of week - newlinetable += '</tr><tr>';}d.setDate(d.getDate() + 1);}// add spaces after last days of month for the last row// 29 30 31 * * * *if (getDay(d) != 0) {for (let i = getDay(d); i < 7; i++) {table += '<td></td>';}}// close the tabletable += '</tr></table>';elem.innerHTML = table;}function getDay(date) { // get day number from 0 (monday) to 6 (sunday)let day = date.getDay();if (day == 0) day = 7; // make Sunday (0) the last dayreturn day - 1;}createCalendar(calendar, 2021, 8);</script></body></html>
2.setInterval时钟
<!DOCTYPE HTML><html><head><style>.hour {color: red}.min {color: green}.sec {color: blue}</style></head><body><div id="clock"><span class="hour">hh</span>:<span class="min">mm</span>:<span class="sec">ss</span></div><script>let timerId;function update() {let clock = document.getElementById('clock');let date = new Date();let hours = date.getHours();if (hours < 10) hours = '0' + hours;clock.children[0].innerHTML = hours;let minutes = date.getMinutes();if (minutes < 10) minutes = '0' + minutes;clock.children[1].innerHTML = minutes;let seconds = date.getSeconds();if (seconds < 10) seconds = '0' + seconds;clock.children[2].innerHTML = seconds;}function clockStart() {timerId = setInterval(update, 1000);update(); // <-- start right now, don't wait 1 second till the first setInterval works}function clockStop() {clearInterval(timerId);}clockStart();</script><!-- click on this button calls clockStart() --><input type="button" onclick="clockStart()" value="Start"><!-- click on this button calls clockStop() --><input type="button" onclick="clockStop()" value="Stop"></body></html>
3.对象转换为嵌套列表,递归遍历对象
修改样式
通常有两种设置元素样式的方式:
在 CSS 中创建一个类,并添加它:<div class="...">
将属性直接写入 style:<div style="...">
JavaScript 既可以修改类,也可以修改 style 属性。类:className和classList
elem.className 对应于 "class" 特性(attribute)。对 elem.className 进行赋值,它将替换类中的整个字符串。
elem.classList 是一个特殊的对象,它具有 add/remove/toggle 单个类的方法。
elem.classList.add/remove(class) — 添加/移除类。
elem.classList.toggle(class) — 如果类不存在就添加类,存在就移除它。
elem.classList.contains(class) — 检查给定类,返回 true/false。
此外,classList 是可迭代的对象:for-of遍历类名。元素样式
elem.style 属性是一个对象,它对应于 "style" 特性(attribute)中所写的内容。
style 属性仅对 "style" 特性(attribute)值起作用,而没有任何 CSS 级联(cascade)。
因此我们无法使用 elem.style 读取来自 CSS 类的任何内容。重置样式
使用elem.style.cssText配合模板字符串进行完全重写样式。 注意要加单位!!!!
我们很少使用这个属性,因为这样的赋值会删除所有现有样式:它不是进行添加,而是替换它们。有时可能会删除所需的内容。但是,当我们知道我们不会删除现有样式时,可以安全地将其用于新元素。可以通过设置一个特性(attribute)来实现同样的效果:div.setAttribute('style', 'color: red...')。读取计算样式
getComputedStyle(element, [pseudo])
element
需要被读取样式值的元素。
pseudo
伪元素(如果需要),例如 ::before。空字符串或无参数则意味着元素本身。
结果是一个具有样式属性的对象,像 elem.style,但现在对于所有的 CSS 类来说都是如此。
视窗,滚动,坐标
元素大小和滚动
只读:
elem.offsetWidth/Height元素完整大小(content,padding,border)
clientTop/Left
elem.clientWidth/Height除去滚动条大小之外的content,padding
elem.scrollWidth/Height同上,但是包含了元素隐藏部分(即滚动)的宽或高可写入:
elem.scrollLeft/scrollTop,代表已向上或向左滚动了多少
不要从 CSS 中获取 width/heightWindiow大小和滚动
<html>标签对应的document.documentElement-窗口宽高:
document.documentElement.clientWidth/clientHeight不包含滚动条,换句话说,它们返回的是可用于内容的文档的可见部分的 width/height。
window.innerWidth/innerHeight包含滚动条宽高。-获取文档的top/left/right/bottom:
document.documentElement.getBoundingClientRect().top/left/right/bottom-获取当前滚动:
window.pageXOffset/pageYOffset只读-更改当前滚动:
必须在 DOM 完全构建好之后才能通过 JavaScript 滚动页面。
window.scrollTo(pageX,pageY)— 绝对坐标,使得可见部分的左上角具有相对于文档左上角的坐标 (pageX, pageY)
window.scrollBy(x,y)— 相对当前位置进行滚动,例如,scrollBy(0,10) 会将页面向下滚动 10px。
elem.scrollIntoView(top)— 滚动以使 elem 可见(elem 与窗口的顶部/底部对齐)。元素坐标(相对于窗口)
let coords = elem.getBoundingClientRect()返回elem的最小矩形坐标对象
coords.top/left/right/bottom页面上的任何点都有坐标:
相对于窗口的坐标 — elem.getBoundingClientRect()。
相对于文档的坐标 — elem.getBoundingClientRect() 加上当前页面滚动。
窗口坐标非常适合和 position:fixed 一起使用,文档坐标非常适合和 position:absolute 一起使用。
pageY = clientY + 文档的垂直滚动出的部分的高度。
pageX = clientX + 文档的水平滚动出的部分的宽度。-有一个叫做 document.elementFromPoint(clientX, clientY)
的方法。它会返回在给定的窗口相对坐标处的嵌套的最深的元素(如果给定的坐标在窗口外,则返回 null)。
事件
-事件处理程序(handle)
处理程序中的 this 的值是对应的元素。就是处理程序所在的那个元素。添加/移除handler的方式:
-DOM属性\标记markup(HTML特性):on<event>或 事件监听elem.addEventListener
-赋值为on<event> = null移除该handler 或 elem.removeEventListener:需要移除完全相同(同一内存地址,同一事件处理阶段)的函数当浏览器读取诸如 onclick 之类的 on* 特性(attribute)时,浏览器会根据其内容创建对应的处理程序。
对于 onclick="handler()" 来说,函数是:function(event) { handler() // onclick 的内容}addEventListener 也支持对象作为事件处理程序。在这种情况下,如果发生事件,则会调用 对象中的handleEvent 方法。
element.addEventListener(event, handler[, options]);options具有以下属性的附加可选对象:
once:如果为 true,那么会在被触发后自动删除监听器。
capture:由于历史原因,options 也可以是 false/true,它与 {capture: false/true} 相同。
passive:如果为 true,那么处理程序将不会调用 preventDefault()。-事件对象(event)
无论你如何分类处理程序 —— 它都会将获得一个事件对象作为第一个参数。该对象包含有关所发生事件的详细信息。event 对象的一些属性:
1.event.type
事件类型,这里是 "click"。
2.event.currentTarget
处理事件的元素。这与 this 相同,除非处理程序是一个箭头函数,或者它的 this 被绑定到了其他东西上,之后我们就可以从 event.currentTarget 获取元素了。
3.event.target
4.event.clientX / event.clientY
指针事件(pointer event)的指针的窗口相对坐标。
5.....事件传播(事件流)(Propagation)的三个阶段
1.捕获阶段(Capturing phase)—— 事件(从 Window)向下走近元素。
2.目标阶段(Target phase)—— 事件到达目标元素。
3.冒泡阶段(Bubbling phase)—— 事件从元素上开始冒泡。使用 on 属性或使用 HTML 特性(attribute)或使用两个参数的 addEventListener(event, handler) 添加的处理程序,对捕获一无所知,它们仅在第二阶段和第三阶段运行。
为了在捕获阶段捕获事件,我们需要将处理程序的 capture 选项设置为 true:
elem.addEventListener(..., ..., true)
capture 选项有两个可能的值:
如果为 false(默认值),则在冒泡阶段设置处理程序。
如果为 true,则在捕获阶段设置处理程序。
注意:第二阶段即目标阶段,不管是捕获阶段还是冒泡阶段的处理程序都会被触发。冒泡
当一个事件发生在一个元素上,它会首先运行在该元素上的处理程序,然后运行其父元素上的处理程序,然后一直向上到其他祖先上的处理程序。几乎所有事件都会冒泡。
区别:event.target 和 this(= event.currentTarget)
父元素上的处理程序始终可以获取事件实际发生位置的详细信息。
引发事件的那个嵌套层级最深的元素被称为目标元素,可以通过 event.target 访问。
event.target —— 是引发事件的“目标”元素,它在冒泡过程中不会发生变化。
this —— 是“当前”元素,其中有一个当前正在运行的处理程序。
例如,如果我们有一个处理程序 form.onclick,那么它可以“捕获”表单内的所有点击。无论点击发生在哪里,它都会冒泡到 并运行处理程序。
在 form.onclick 处理程序中:
this(=event.currentTarget)是 元素,因为处理程序在它上面运行。
event.target 是表单中实际被点击的元素。**停止冒泡
避免触发外部事件,谨慎使用,因为会产生死区。
event.stopPropagation() 停止冒泡,但是当前元素上的其他处理程序都会继续运行
event.stopImmediatePropagation()停止冒泡,并阻止当前元素上的处理程序运行。捕获
事件委托
不同元素触发事件(事件从目标元素开始冒泡,我们在冒泡的上层进行event.target判断)
好处:
简化初始化并节省内存:无需添加许多处理程序。
更少的代码:添加或移除元素时,无需添加/移除处理程序。
DOM 修改 :我们可以使用 innerHTML 等,来批量添加/移除元素。事件委托也有其局限性:
首先,事件必须冒泡。而有些事件不会冒泡。此外,低级别的处理程序不应该使用 event.stopPropagation()。
其次,委托可能会增加 CPU 负载,因为容器级别的处理程序会对容器中任意位置的事件做出反应,而不管我们是否对该事件感兴趣。但是,通常负载可以忽略不计,所以我们不考虑它。通过event.target.dataset.来分配
行为模式分为两个部分:
1.我们将自定义特性添加到描述其行为的元素。
算法:
1.在容器(container)上放一个处理程序。
2.在处理程序中 —— 检查源元素 event.target。
3.如果事件发生在我们感兴趣的元素内,那么处理该事件。
<div id="menu"><button data-action="save">Save</button><button data-action="load">Load</button><button data-action="search">Search</button></div><script>class Menu {constructor(elem) {this._elem = elem;elem.onclick = this.onClick.bind(this); // (*)}save() {alert('saving');}load() {alert('loading');}search() {alert('searching');}onClick(event) {let action = event.target.dataset.action;if (action) {this[action]();}};}new Menu(menu);</script>
2.用文档范围级的处理程序追踪事件,如果事件发生在具有特定特性的元素上 —— 则执行行为(action)。
document.addEventListener( ..., function(event){...})
浏览器默认行为
1.主流的方式是使用 event 对象。有一个 event.preventDefault() 方法。
addEventListener 的可选项 passive: true 向浏览器发出信号,表明处理程序将不会调用 preventDefault()。这对于某些移动端的事件(像 touchstart 和 touchmove)很有用,用以告诉浏览器在滚动之前不应等待所有处理程序完成。
2.如果处理程序是使用 on(而不是 addEventListener)分配的,那 return false 也同样有效。
如果默认行为被阻止,event.defaultPrevented 的值会变成 true,否则为 false。创建自定义事件
UI事件(鼠标、指针、拖拽、键盘、滚动)
mouseouver/mouseout 从父元素移入后代元素也算out
mosueenter/mouseleave 区别:和后代无影响;不冒泡指针事件
指针事件允许我们通过一份代码,同时处理鼠标、触摸和触控笔事件。
指针事件是鼠标事件的拓展。我们可以在事件名称中用 pointer 替换 mouse 来让我们的代码既能继续支持鼠标,也能更好地支持其他类型的设备。
对于浏览器可能会决定进行劫持并自行处理的拖放和复杂的触控交互 —— 请记住取消事件的默认操作,并在 CSS 中为涉及到的元素设置touch-events: none。指针事件还额外具备以下能力:
-基于 pointerId 和 isPrimary 的多点触控支持。
-针对特定设备的属性,例如 pressure 和 width/height 等。
-指针捕获:我们可以把 pointerup/pointercancel 之前的所有指针事件重定向到一个特定的元素。目前,指针事件已经被各大主流浏览器支持,尤其是如果不需要支持 IE10 和 Safari 12 以下的版本,我们可以放心地使用它们。不过即便是针对这些老式浏览器,也可以通过 polyfill 来让它们支持指针事件。
指针捕获
elem.setPointerCapture(pointerId)将所有具有给定 pointerId 的后续事件重新定位到 elem。绑定会在以下情况下被移除:
当 pointerup 或 pointercancel 事件出现时,绑定会被自动地移除。
当 elem 被从文档中移除后,绑定会被自动地移除。
当elem.releasePointerCapture(pointerId)被调用,绑定会被移除。指针捕获可以被用于简化拖放类的操作,即使用户在整个文档上移动指针,事件处理程序也将仅在 thumb 上被调用。此外,事件对象的坐标属性,例如 clientX/clientY 仍将是正确的 —— 捕获仅影响 target/currentTarget。
键盘事件
按一个按键总是会产生一个键盘事件,无论是
字符键,数字键,还是例如 Shift 或 Ctrl 等特殊按键。唯一的例外是有时会出现在笔记本电脑的键盘上的 Fn 键。它没有键盘事件,因为它通常是被在比 OS 更低的级别上实现的。-键盘事件:
keydown —— 在按下键时(如果长按按键,则将自动重复),event.repeat = true
keyup —— 释放按键时。-键盘事件的主要属性:
code—— “按键代码”("KeyA","ArrowLeft" 等),特定于键盘上按键的物理位置。
key—— 字符("A","a" 等),对于非字符(non-character)的按键,通常具有与 code 相同的值。
我们想要处理与布局有关的按键?那么 event.key 是我们必选的方式。
或者我们希望一个热键即使在切换了语言后,仍能正常使用?那么 event.code 可能会更好。、滚动
滚动的两个重要特性:
1.滚动是“弹性的”。在某些浏览器/设备中,我们可以在文档的顶端或末端稍微多滚动出一点(超出部分显示的是空白区域,然后文档将自动“弹回”到正常状态)。
2.滚动并不精确。当我们滚动到页面末端时,实际上我们可能距真实的文档末端约 0-50px。因此,实际中
1.“滚动到末端”应该意味着访问者离文档末端的距离不超过 100px。
2. document.getBoundingClientRect().bottom 即文档的底部距离窗口顶部不应该小于窗口高度,,document.documentElement.clientHeight
表单事件
form属性: action , method , ...
表单元素及属性:input(type = checkbox/radio/button/text/password/email/submit/reset...),fieldset和legend ,select和option ,label(for = 'id'), textarea , ...表单导航
1.
document.forms
一个表单元素可以通过 document.forms[name/index] 访问到。
2.form.elements
表单元素可以通过 form.elements[name/index] 的方式访问,或者也可以使用 form[name/index]。elements 属性也适用于<fieldset>。不管元素在表单内嵌套多深都可以找到
3.element.form
元素通过 form 属性来引用它们所属的表单。
value 可以被通过 input.value,textarea.value,select.value 等来获取到,对于单选按钮和复选框来说可以使用 input.checked。select 和 option
1.select.options ——
<option>的子元素的集合,
2.select.value —— 当前所选择的<option>的 value,
3.select.selectedIndex—— 当前所选择的<option>的编号。
select.options[select.selectedIndex]返回一个包含所有被selected的option集合它们提供了三种为
<select>设置 value 的不同方式:
1.找到对应的<option>元素,并将 option.selected 设置为 true。
2.将 select.value 设置为对应的 value。
3.将 select.selectedIndex 设置为对应<option>的编号。1.option.selected
2.option.index
3.option.text
在 规范 中,有一个很好的简短语法可以创建 元素
let option = new Option(text, value, defaultSelected, selected);focus / blur 事件
elem.focus() 和 elem.blur() 方法可以设置和移除元素上的焦点。
JavaScript 导致的焦点丢失
很多种原因可以导致焦点丢失。
其中之一就是用户点击了其它位置。当然 JavaScript 自身也可能导致焦点丢失,例如:
一个 alert 会将焦点移至自身,因此会导致元素失去焦点(触发 blur 事件),而当 alert 对话框被取消时,焦点又回重新回到原元素上(触发 focus 事件)。
如果一个元素被从 DOM 中移除,那么也会导致焦点丢失。如果稍后它被重新插入到 DOM,焦点也不会回到它身上。
这些特性有时候会导致 focus/blur 处理程序发生异常 —— 在不需要它们时触发。
最好的秘诀就是在使用这些事件时小心点。如果我们想要跟踪用户导致的焦点丢失,则应该避免自己造成的焦点丢失。允许在任何元素上聚焦:tabindex特性 或 elem.tabIndex = ...
具有 tabindex 的元素按文档源顺序(默认顺序)切换。
这里有两个特殊的值:
tabindex="0" 会使该元素被与那些不具有 tabindex 的元素放在一起。也就是说,当我们切换元素时,具有 tabindex="0" 的元素将排在那些具有 tabindex ≥ 1 的元素的后面。
通常,它用于使元素具有焦点,但是保留默认的切换顺序。使元素成为与 一样的表单的一部分。
tabindex="-1" 只允许以编程的方式聚焦于元素。Tab 键会忽略这样的元素,但是 elem.focus() 有效。focus/blur 委托
focus/blur 不会向上冒泡,但会在捕获阶段向下传播。
所以有两个方案:
1.form.addEventListener(...,...,true)//设置captrue为true
2.可以使用 focusin 和 focusout 事件 —— 与 focus/blur 事件完全一样,只是它们会冒泡。值得注意的是,必须使用 elem.addEventListener 来分配它们,而不是 on。伴随数据更新的各种事件(change,input,cut,copy,paste)
事件 描述 特点 change 值被改变。 对于文本输入,当失去焦点时触发。 input 文本输入的每次更改。 立即触发,与 change 不同 copy,cut,paste 剪贴/拷贝/粘贴行为。 行为可以被阻止。event.clipboardData 属性可以用于读/写剪贴板。 事件:submit
提交表单主要有两种方式:
第一种 —— 点击<input type="submit">或<input type="image">。
第二种 —— 在 input 字段中按下 Enter 键。
这两个行为都会触发表单的 submit 事件。处理程序可以检查数据,如果有错误,就显示出来,并调用 event.preventDefault(),这样表单就不会被发送到服务器了。
手动调用form.submit(),但在这之前表单必须存在于文档中
页面生命周期
DOMContentLoaded—— 浏览器已完全加载 HTML,并构建了 DOM 树,但像 和样式表之类的外部资源可能尚未加载完成。docuemnt.addEventListener('DOMContentLoaded',...)
windnow.onload—— 浏览器不仅加载完成了 HTML,还加载完成了所有外部资源:图片,样式等。
window.onbeforeunload/unload—— 当用户正在离开页面时。每个事件都是有用的:
DOMContentLoaded 事件 —— DOM 已经就绪,因此处理程序可以查找 DOM 节点,并初始化接口。
load 事件 —— 外部资源已加载完成,样式已被应用,图片大小也已知了。
beforeunload 事件 —— 用户正在离开:我们可以检查用户是否保存了更改,并询问他是否真的要离开。
unload 事件 —— 用户几乎已经离开了,但是我们仍然可以启动一些操作,例如发送统计数据。不会阻塞 DOMContentLoaded 的脚本:
1.具有 async 特性(attribute)的脚本不会阻塞 DOMContentLoaded。
2.使用 document.createElement('script') 动态生成并添加到网页的脚本也不会阻塞 DOMContentLoaded。
document.readyState属性可以为我们提供当前加载状态的信息。
它有 3 个可能值:
loading—— 文档正在被加载。
interactive—— 文档被全部读取。在 DOMContentLoaded 之前,document.readyState 会立即变成 interactive。它们俩的意义实际上是相同的。
complete—— 文档被全部读取,并且所有资源(例如图片等)都已加载完成。当所有资源(iframe 和 img)都加载完成后,document.readyState 变成 complete。这里我们可以发现,它与 img.onload(img 是最后一个资源)和 window.onload 几乎同时发生。转换到 complete 状态的意义与 window.onload 相同。区别在于 window.onload 始终在所有其他 load 处理程序之后运行。
脚本:async,defer
defer:
--具有 defer 特性的脚本不会阻塞页面。
--具有 defer 特性的脚本总是要等到 DOM 解析完毕,但在 DOMContentLoaded 事件之前!!执行!!。
--defer 特性仅适用于外部脚本。如果 脚本没有 src,则会忽略 defer 特性。
--defer 特性除了告诉浏览器“不要阻塞页面”之外,还可以确保脚本!!执行!!的相对顺序。脚本并行下载,但是执行顺序按照脚本在文档中的顺序执行
async异步脚本:换句话说,async 脚本会在后台加载,并在加载就绪时运行。
--同样不会阻塞页面。
--其他脚本不会等待 async 脚本加载完成再执行,同样,async 脚本也不会等待其他脚本再执行。换句话说,异步脚本以“加载优先”的顺序执行。
--DOMContentLoaded 和异步脚本不会彼此等待:
DOMContentLoaded 可能会发生在异步脚本之前(如果异步脚本在页面完成后才加载完成)
DOMContentLoaded 也可能发生在异步脚本之后(如果异步脚本很短,或者是从 HTTP 缓存中加载的)
动态脚本
当脚本被附加到文档时,脚本就会立即开始加载。
默认情况下,动态脚本的行为是“异步”的。如果我们显式地设置了 script.async=false,则可以改变这个规则。然后脚本将按照脚本在文档中的顺序执行,就像 defer 那样。
资源加载:onload,onerror
脚本资源:script.onload/onerror
onload/onerror 事件仅跟踪加载本身。
在脚本处理和执行期间可能发生的 error 超出了这些事件跟踪的范围。也就是说:如果脚本成功加载,则即使脚本中有编程 error,也会触发 onload 事件。如果要跟踪脚本 error,可以使用 window.onerror 全局处理程序。其他资源:load 和 error 事件也适用于其他资源,基本上(basically)适用于具有外部 src 的任何资源。
注意事项:
大多数资源在被添加到文档中后,便开始加载。但是 是个例外。它要等到获得 src (*) 后才开始加载。
对于 来说,iframe 加载完成时会触发 iframe.onload 事件,无论是成功加载还是出现 error。跨源策略(CORS)
一个源(域/端口/协议三者)无法获取另一个源(origin)的内容。因此,即使我们有一个子域,或者仅仅是另一个端口,这都是不同的源,彼此无法相互访问。
要允许跨源访问, 标签需要具有 crossorigin 特性(attribute),并且远程服务器必须提供特殊的 header。
这里有三个级别的跨源访问:
1.无 crossorigin 特性 —— 禁止访问。
2.
crossorigin="anonymous"—— 如果服务器的响应带有包含 * 或我们的源(origin)的 header Access-Control-Allow-Origin,则允许访问。
!! 浏览器不会将授权信息和 cookie 发送到远程服务器。!!3.
crossorigin="use-credentials"—— 如果服务器发送回带有我们的源的 header Access-Control-Allow-Origin 和 Access-Control-Allow-Credentials: true,则允许访问。
!! 浏览器会将授权信息和 cookie 发送到远程服务器。!!
事件循环:微任务和宏任务
浏览器中 JavaScript 的执行流程和 Node.js 中的流程都是基于 事件循环 的,但二者机制不同。
- 进程线程:浏览器是多进程的,一个进程(页面)是多线程的。常见线程有:
- GUI渲染线程
- 负责渲染浏览器界面,解析HTML,CSS,构建DOM树和RenderObject树,布局和绘制等。
- 当界面需要重绘(Repaint)或由于某种操作引发回流(reflow)时,该线程就会执行
- 注意,GUI渲染线程与JS引擎线程是互斥的,当JS引擎执行时GUI线程会被挂起(相当于被冻结了),GUI更新会被保存在一个队列中等到JS引擎空闲时立即被执行。
- JS引擎线程
- 也称为JS内核,负责处理Javascript脚本程序。(例如V8引擎)
- JS引擎线程负责解析Javascript脚本,运行代码。
- JS引擎一直等待着任务队列中任务的到来,然后加以处理,一个Tab页(renderer进程)中无论什么时候都只有一个JS线程在运行JS程序
- 同样注意,GUI渲染线程与JS引擎线程是互斥的,所以如果JS执行的时间过长,这样就会造成页面的渲染不连贯,导致页>面渲染加载阻塞。
- 事件触发线程
- 归属于浏览器而不是JS引擎,用来控制事件循环(可以理解,JS引擎自己都忙不过来,需要浏览器另开线程协助)
- 当JS引擎执行代码块如setTimeOut时(也可来自浏览器内核的其他线程,如鼠标点击、AJAX异步请求等),会将对应任务添加到事件线程中
- 当对应的事件符合触发条件被触发时,该线程会把事件添加到待处理队列的队尾,等待JS引擎的处理
- 注意,由于JS的单线程关系,所以这些待处理队列中的事件都得排队等待JS引擎处理(当JS引擎空闲时才会去执行)
- 定时触发器线程
- 传说中的setInterval与setTimeout所在线程
- 浏览器定时计数器并不是由JavaScript引擎计数的,(因为JavaScript引擎是单线程的,如果处于阻塞线程状态就会影响记计时的准确)
- 因此通过单独线程来计时并触发定时(计时完毕后,添加到事件队列中,等待JS引擎空闲后执行)
- 注意,W3C在HTML标准中规定,规定要求setTimeout中低于4ms的时间间隔算为4ms。
- 异步http请求线程
- 在XMLHttpRequest在连接后是通过浏览器新开一个线程请求
- 将检测到状态变更时,如果设置有回调函数,异步线程就产生状态变更事件,将这个回调再放入事件队列中。再由JavaScript引擎执行。
- 事件循环
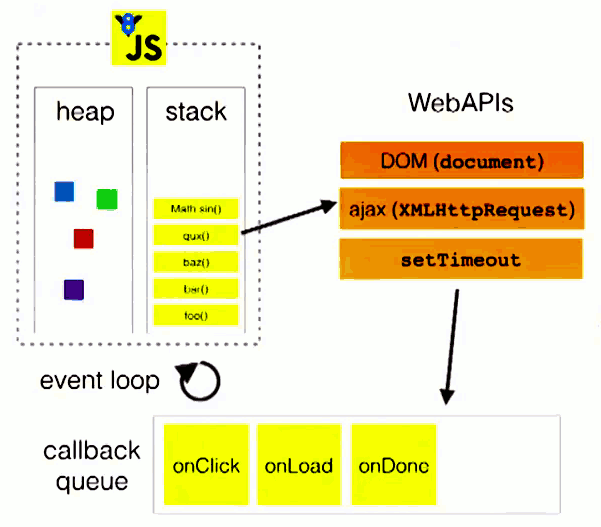
总结下事件循环运行机制:
- 执行一个宏任务(栈中没有就从事件队列中获取)
- 执行过程中如果遇到微任务,就将它添加到微任务的任务队列中(微任务队列存在于主线程执行栈中的全局执行上下文,在当前宏任务执行完后准备退出全局执行上下文进行渲染进程的时候,引擎会检查存在于全局执行上下文的微任务队列并依次执行)
- 当前宏任务执行完毕后,立即执行当前微任务队列中的所有微任务(依次执行)
- 当前JS线程执行栈清空,开始检查渲染,然后GUI线程接管渲染
- 渲染完毕后,JS线程继续接管,开始下一个宏任务(从事件队列中获取)
(schedule一个零延时的setTimeout会在执行栈执行完毕之后从立刻从事件队列中被推进主线程执行栈中执行)
(了解了机制之后我们就知道为什么setTimeout不一定是准时的)
如何做到‘准时’的定时
- web worker
- 在 worker 中写入一个while循环,当达到我们的预取时间的时候,再向主线程发送一个完成事件
- 线程间通信存在极其微小误差
- 但是一方面, worker线程会被while给占用,导致无法接受到信息,多个定时器无法同时执行
- 另一方面,由于 onmessage还是属于事件循环内,如果主线程有大量阻塞还是会让时间越差越大,因此这并不是个完美的方案。
- requestAnimationFrame
- setTimeout系统时间补偿
- 多个setTimeout嵌套
- 每次通过
new Date.getTime()获取系统时间进行补偿- 每次运行可能会有误差,但是通过系统时间对每次运行的修复,能够让后面每一次时间都得到一个补偿。
宏任务macrotask
主代码块,setTimeout,setInterval等(可以看到,事件队列中的每一个事件都是一个macrotask,由事件触发线程维护)
# 浏览器 Node I/O✅ ✅ setTimeout✅ ✅ setInterval✅ ✅ setImmediate❌ ✅ requestAnimationFrame✅ ❌
微任务microtask
(由js引擎线程维护)
# 浏览器 Node process.nextTick❌ ✅ MutationObserver✅ ❌ Promise.then catch finally✅ ✅
浏览器渲染机制
- 1. 根据 HTML 解析 DOM 树(dom)
根据 HTML 的内容,将标签按照结构解析成为 DOM 树,DOM
树解析的过程是一个深度优先遍历。即先构建当前节点的所有子节点,再构建下一个兄弟节点。
在读取 HTML 文档,构建 DOM 树的过程中,若遇到 script 标签,则 DOM 树的构建会暂停,直至脚本执行完毕。
- 2. 根据 CSS 解析生成 CSS 规则树(cssom)
解析 CSS 规则树时 js 执行将暂停,直至 CSS 规则树就绪。
浏览器在 CSS 规则树生成之前不会进行渲染。
- 3. 结合 DOM 树和 CSS 规则树,生成渲染树(render tree)
DOM 树和 CSS 规则树全部准备好了以后,浏览器才会开始构建渲染树。
精简 CSS 并可以加快 CSS 规则树的构建,从而加快页面相应速度。
- 4. 根据渲染树计算每一个节点的信息(布局)
布局:通过渲染树中渲染对象的信息,计算出每一个渲染对象的位置和尺寸
回流:在布局完成后,发现了某个部分发生了变化影响了布局,那就需要倒回去重新渲染。
- 5. 根据计算好的信息绘制页面
绘制阶段,系统会遍历呈现树,并调用呈现器的“paint”方法,将呈现器的内容显示在屏幕上。
重绘:某个元素的背景颜色,文字颜色等,不影响元素周围或内部布局的属性,将只会引起浏览器的重绘。
回流:某个元素的尺寸发生了变化,则需重新计算渲染树,重新渲染。
回流必将引起重绘,重绘不一定会引起回流。
参考:https://juejin.cn/post/6844903569087266823
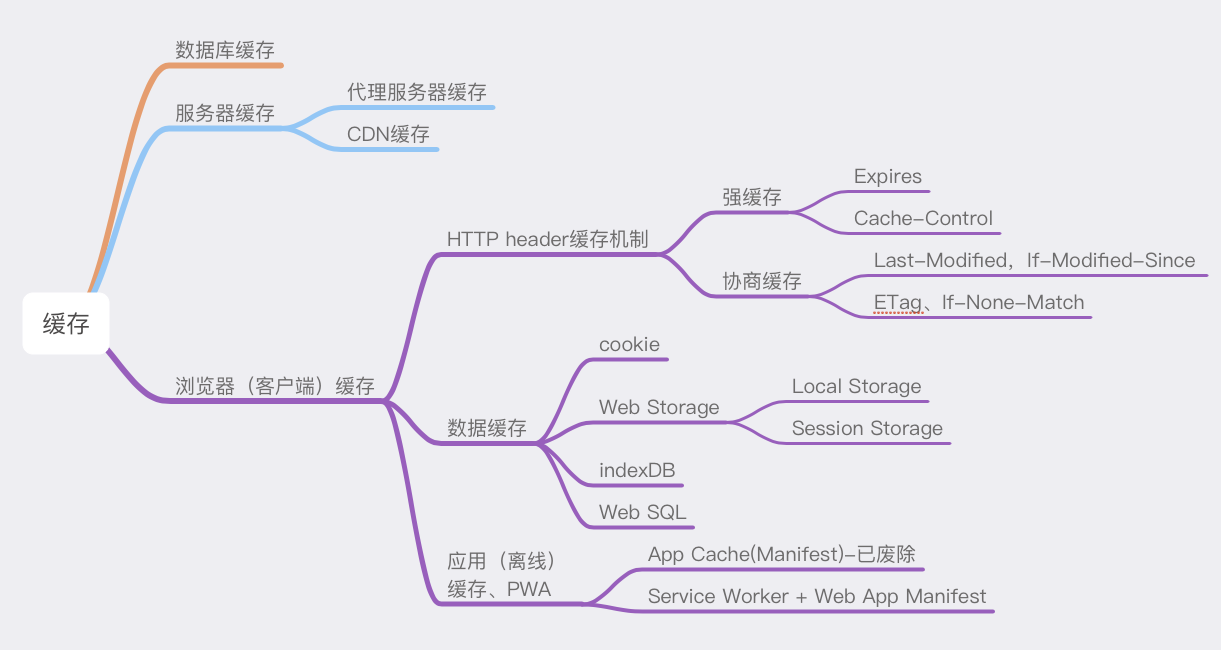
浏览器缓存
强缓存和协商缓存机制
一、概述
1、基本原理
1)浏览器在加载资源时,根据请求头的 expires和cache-control判断是否命中强缓存,是则直接从缓存读取资源,不会发请求到服务器。
2)如果没有命中强缓存,浏览器一定会发送一个请求到服务器,通过 last-modified和etag验证资源是否命中协商缓存,如果命中,服务器会将这个请求返回,但是不会返回这个资源的数据,依然是从缓存中读取资源
3)如果前面两者都没有命中,直接从服务器加载资源 2、相同点
如果命中,都是从客户端缓存中加载资源,而不是从服务器加载资源数据;3、不同点
强缓存不发请求到服务器,协商缓存会发请求到服务器。二、强缓存
强缓存通过
Expires和Cache-Control两种响应头实现1、Expires
Expires是http1.0提出的一个表示资源过期时间的header,它描述的是一个绝对时间,由服务器返回。
Expires 受限于本地时间,如果修改了本地时间,可能会造成缓存失效
Expires: Wed, 11 May 2018 07:20:00 GMT2、Cache-Control
Cache-Control 出现于 HTTP / 1.1,优先级高于 Expires ,表示的是相对时间
Cache-Control: max-age=315360000
Cache-Control: no-cache缓存存储在本地,在于服务器进行新鲜度验证之前,缓存不提供给客户端(即会向服务器发送再验证请求,如果内容没有变化,服务器会发送304 NOT Modified进行响应,被称为再验证命中,比直接的缓存命中要慢)Cache-Control: no-store才是真正的不缓存数据到本地Cache-Control: public可以被所有用户缓存(多用户共享),包括终端和CDN等中间代理服务器Cache-Control: private只能被终端浏览器缓存(而且是私有缓存),不允许中继缓存服务器进行缓存

三、协商缓存
协商缓存是利用的是【
Last-Modified,If-Modified-Since】和【ETag、If-None-Match】这两对Header来管理的1、Last-Modified(服务器端生成返回给客户端),If-Modified-Since(请求头)
Last-Modified 表示本地文件最后修改日期,浏览器会在request header加上If-Modified-Since:(上次返回的Last-Modified的值),询问服务器在该日期后资源是否有更新,有更新的话就会将新的资源发送回来
但是如果在本地打开缓存文件,就会造成 Last-Modified 被修改,所以在 HTTP / 1.1 出现了 ETag
2、ETag(服务器端生成返回给客户端)、If-None-Match(请求头)
Etag就像一个指纹,资源变化都会导致ETag变化,跟最后修改时间没有关系,ETag可以保证每一个资源是唯一的
If-None-Match的header会将上次返回的Etag发送给服务器,询问该资源的Etag是否有更新,有变动就会发送新的资源回来
ETag的优先级比Last-Modified更高
前端文件如何触发304协商缓存:webpack打包配置output的filename或者chunkfilename中添加chunkhash或者contenthash
ETag没有发生变化的情况:

具体为什么要用ETag,主要出于下面几种情况考虑:
- 一些文件也许会周期性的更改,但是他的内容并不改变(仅仅改变的修改时间),这个时候我们并不希望客户端认为这个文件被修改了,而重新GET;
- 某些文件修改非常频繁,比如在秒以下的时间内进行修改,(比方说1s内修改了N次),If-Modified-Since能检查到的粒度是s级的,这种修改无法判断(或者说UNIX记录MTIME只能精确到秒);
- 某些服务器不能精确的得到文件的最后修改时间。
四、整体流程图
五、几种状态码的区别
- 200:强缓Expires/Cache-Control存失效时,返回新的资源文件
- 200(from cache): 强缓Expires/Cache-Control两者都存在,未过期,Cache-Control优先Expires时,浏览器从本地获取资源成功
- 304(Not Modified ):协商缓存Last-modified/Etag没有过期时,服务端返回状态码304
六、场景
- 协商缓存需要配合强缓存使用,如果不启用强缓存的话,协商缓存根本没有意义
- 分布式系统里多台机器间文件的Last-Modified必须保持一致,以免负载均衡到不同机器导致比对失败;
- 分布式系统尽量关闭掉ETag(每台机器生成的ETag都会不一样);
数据存储
储存的数据可能是从服务器端获取到的数据,也可能是在多个页面中需要频繁使用到的数据
Cookie,document.cookie
- Cookie 通常是由
Web 服务器使用响应Set-CookieHTTP-header 设置的。然后浏览器使用CookieHTTP-header 将它们自动添加到(几乎)每个对相同域的请求中。- Cookie大小不得超过4KB,每个域的cookie总数不得超过20+左右,具体限制取决于浏览器
- document.cookie 的值由
name=value对组成,以;分隔。每一个都是独立的 cookie。- document.cookie不是一个数据属性,它是一个访问器(getter/setter)。对其的赋值操作会被特殊处理。
对 document.cookie 的写入操作只会更新其中提到的 cookie,而不会涉及其他 cookie。为了格式,我们最好使用内置的encodeURIComponent函数进行cookie编码写入。
// 特殊字符(空格),需要编码let name = "my name";let value = "John Smith"// 将 cookie 编码为 ...; my%20name=John%20Smithdocument.cookie = encodeURIComponent(name) + '=' + encodeURIComponent(value);//decodeURIComponent可以对已编码的cookie进行解码
- Cookie 有几个选项,被列在 key=value 之后,以 ; 分隔
- path
- path=/mypath
url 路径前缀,该路径下的页面可以访问该 cookie。必须是绝对路径。默认为当前路径。
如果一个 cookie 带有 path=/admin 设置,那么该 cookie 在 /admin 和 /admin/something 下都是可见的,但是在 /home 或 /adminpage 下不可见。
通常,我们应该将 path 设置为根目录:path=/,以使 cookie 对此网站的所有页面可见。- domain
- domain=site.com
默认情况下,cookie只能在被设置的域下被访问,就算是当前域的子域也无法访问。
将domain 选项显式地设置为根域,比如domain=site.com,则forum.site.com也能访问到父域的cookie。
所以,domain 选项允许设置一个可以在子域访问的 cookie。- expires , max-age
- expires=Tue, 19 Jan 2038 03:14:07 GMT
- max-age=3600
默认情况下,如果一个cookie没有设置这两个参数中的任何一个,那么在关闭浏览器之后,它就会消失。此类 cookie 被称为 "session cookie”。- secure
- 默认情况下,如果我们在 http://site.com 上设置了 cookie,那么该 cookie 也会出现在 https://site.com 上,反之亦然。也就是说,cookie 是基于域的,它们不区分协议。
使用此选项,cookie只能通过加密的HTTPS协议传输。- samesite
- 这是另外一个关于安全的特性。它旨在防止 CSRF(跨网站请求伪造)攻击, 但由于不兼容旧版本浏览器。最好配合CSRF token使用。
- samesite=strict(和没有值的 samesite 一样)
- 只有来自同一域下的请求才会发送带有samesite的cookie
这样做有一个问题,虽然防止了CSRF攻击,但如果我们是从合法链接进行跳转呢?我们的cookie也不会被发送
为了解决上面的问题,我们可以设置两个cookie,一个单纯用来做一般识别,另一个带有samesite选项的cookie用来作为重要数据更改的身份认证。- samesite=lax
- 宽松(lax)模式,和 strict 模式类似,当从外部来到网站,则禁止浏览器发送 cookie,但是增加了一个例外。
如果以下两个条件均成立,则会发送 samesite=lax cookie:- 1.HTTP 方法是“安全的”(例如 GET 方法,而不是 POST)。
- 2.该操作执行顶级导航(更改浏览器地址栏中的 URL)。
这通常是成立的,但是如果导航是在一个<iframe>中执行的,那么它就不是顶级的。此外,用于网络请求的 JavaScript 方法不会执行任何导航,因此它们不适合。- httpOnly
- Web 服务器使用 Set-Cookie header 来设置 cookie。并且,它可以设置 httpOnly 选项。
这个选项禁止任何 JavaScript 访问 cookie。我们使用 document.cookie 看不到此类 cookie,也无法对此类 cookie 进行操作。
比如,用户访问了带有黑客 JavaScript 代码的页面,黑客代码将执行并通过 document.cookie 获取到包含用户身份验证信息的 cookie。从而进行CSRF攻击。
- 第三方Cookie
- 如果 cookie 是由用户所访问的页面的域以外的域放置的,则称其为第三方 cookie。
- https://zh.javascript.info/cookie#xie-ru-documentcookie
LocalStorage,sessionStorage
- 与cookie比较
- 与 cookie 不同,Web存储对象不会随每个请求被发送到服务器。因此,我们可以保存更多数据。大多数浏览器都允许保存至少 2MB 的数据(或更多),并且具有用于配置数据的设置。
- 还有一点和 cookie 不同,服务器无法通过 HTTP header 操纵存储对象。一切都是在 JavaScript 中完成的。
- 不会过期,除非人为.
概述
- 大小:官方建议是5M存储空间
- 类型:只能操作字符串,在存储之前应该使用
JSON.stringfy()方法先进行一步安全转换字符串,取值时再用JSON.parse()方法再转换一次- 存储的内容: 数组,图片,json,样式,脚本。。。(只要是能序列化成字符串的内容都可以存储)
- 注意:数据是明文存储,毫无隐私性可言,绝对不能用于存储重要信息
- 存储绑定到源(域/协议/端口三者)。也就是说,不同协议或子域对应不同的存储对象,它们之间无法访问彼此数据。
- 区别:
LocalStorage sessionStorage 在同源的所有标签页和窗口之间共享数据 在当前浏览器标签页中可见,包括同源的 iframe 浏览器重启后数据仍然保留 页面刷新后数据仍然保留(但标签页关闭后数据则不再保留) - 两个存储对象都提供相同的方法和属性:
setItem(key, value)—— 存储键/值对。getItem(key)—— 按照键获取值。removeItem(key)—— 删除键及其对应的值。clear()—— 删除所有数据。key(index)—— 获取该索引下的键名。length—— 存储的内容的长度。- Storage事件
- 当 localStorage 或 sessionStorage 中的数据更新后,storage 事件就会触发.
- 该事件会在所有可访问到存储对象的 window 对象上触发(对于 sessionStorage 是在当前标签页下,对于 localStorage 是在全局,即所有同源的窗口),导致当前数据改变的 window 对象除外。
- 这允许同源的不同窗口交换消息。
现代浏览器还支持 Broadcast channel API,这是用于同源窗口之间通信的特殊 API,它的功能更全,但被支持的情况不好。有一些库基于 localStorage 来 polyfill 该 API,使其可以用在任何地方。
IndexedDB

JavaScript引擎的垃圾回收与内存泄露
垃圾回收的必要性
下面这段话引自《JavaScript权威指南(第四版)》
由于字符串、对象和数组没有固定大小,所有当他们的大小已知时,才能对他们进行动态的存储分配。JavaScript程序每次创建字符串、数组或对象时,解释器都必须分配内存来存储那个实体。只要像这样动态地分配了内存,最终都要释放这些内存以便他们能够被再用,否则,JavaScript的解释器将会消耗完系统中所有可用的内存,造成系统崩溃。
所谓内存泄露,就是指不再用到的内存没有被及时释放。
垃圾回收机制
标记清除法(mark and sweep)
可达性:
①固有的可达值称为根(roots),这些值明显不能从内存中被释放,例如
- 当前函数的局部变量和参数。
- 嵌套调用时,当前调用链上所有函数的变量与参数。
- 全局变量。
- (还有一些内部的)
②如果一个值可以通过引用或引用链从根访问任何其他值,则认为该值是可达的。
- 标记清除法的步骤:
① 垃圾收集器找到所有的根,并“标记”(记住)它们。
② 然后它遍历并“标记”来自它们的所有引用。
③ 然后它遍历标记的对象并标记它们的引用。所有被遍历到的对象都会被记住,以免将来再次遍历到同一个对象。
④ ……如此操作,直到所有可达的(从根部)引用都被访问到。
⑤ 没有被标记的对象都会被删除。
⑥ 引擎会定期执行垃圾回收
引用计数法
一些优化建议
分代收集(Generational collection)
对象被分成两组:“新的”和“旧的”。许多对象出现,完成它们的工作并很快死去,它们可以很快被清理。那些长期存活的对象会变得“老旧”,而且被检查的频次也会减少。增量收集(Incremental collection)
如果有许多对象,并且我们试图一次遍历并标记整个对象集,则可能需要一些时间,并在执行过程中带来明显的延迟。所以引擎试图将垃圾收集工作分成几部分来做。然后将这几部分会逐一进行处理。这需要它们之间有额外的标记来追踪变化,但是这样会有许多微小的延迟而不是一个大的延迟。闲时收集(Idle-time collection)
垃圾收集器只会在 CPU 空闲时尝试运行,以减少可能对代码执行的影响。
图片懒加载与资源预加载
cookie,session,token三种登录认证
