@nalan90
2017-09-13T06:55:25.000000Z
字数 11236
阅读 895
Hadoop伪分布式配置
大数据
摘自:http://www.powerxing.com/install-hadoop/
核心组件
- HDFS
- NameNode
- DataNode
- SecondaryNameNode
- MapReduce
- YARN
- ResourceManager (master)
- Scheduler
- Applications Manager
- ApplicationMaster (master)
- NodeManager (slave)
- ResourceManager (master)
- Hadoop common
安装包准备
- Openjdk 1.8.0
- Hadoop-2.7.4
- CentOS 7.3
添加用户并设置权限
## 添加hadoop用户[root@dev-162 zhangshuang]# useradd -m hadoop -s /bin/bash## 设置密码[root@dev-162 zhangshuang]# passwd hadoopChanging password for user hadoop.New password:BAD PASSWORD: The password is shorter than 7 charactersRetype new password:passwd: all authentication tokens updated successfully.## 添加sudo权限(追加如下行)[root@dev-162 zhangshuang]# visudohadoop ALL=(ALL) NOPASSWD:ALL## 切换至hadoop用户[root@dev-162 zhangshuang]# su - hadoop## 生成ssh证书(全部回车即可)[hadoop@dev-162 ~]$ ssh-keygen -t rsaGenerating public/private rsa key pair.Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):Created directory '/home/hadoop/.ssh'.Enter passphrase (empty for no passphrase):Enter same passphrase again:Your identification has been saved in /home/hadoop/.ssh/id_rsa.Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.The key fingerprint is:7a:13:7f:9d:80:37:38:56:e9:b5:de:53:c1:c0:5a:33 hadoop@dev-162The key randomart image is:+--[ RSA 2048]----+| .. || Eo || = +o || * . ..|| S = = . .|| . + o = o.|| . o . . +..|| . . . .|| |+-----------------+## 将公钥写入authorized_keys文件[hadoop@dev-162 ~]$ cat .ssh/id_rsa.pub >> .ssh/authorized_keys## 修改权限[hadoop@dev-162 ~]$ chmod 600 .ssh/authorized_keys## 无密码登录本机[hadoop@dev-162 ~]$ ssh localhostThe authenticity of host 'localhost (::1)' can not be established.ECDSA key fingerprint is fe:0f:40:d7:56:c8:c1:b4:29:c3:ce:d8:d6:12:66:2e.Are you sure you want to continue connecting (yes/no)? yesWarning: Permanently added 'localhost' (ECDSA) to the list of known hosts.Last login: Wed Aug 23 13:56:50 2017
安装java环境
## 安装openjdk[hadoop@dev-162 ~]$ sudo yum -y install java-1.8.0-openjdk[hadoop@dev-162 ~]$ sudo yum -y install java-1.8.0-openjdk-devel## 设置java环境变量 (注意是.bashrc不是.bash_profile)[hadoop@dev-161 ~]$ vim .bashrc## 追加如下行export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdkexport PATH=$JAVA_HOME/bin:$PATH:/usr/local/hadoop/sbin:/usr/local/hadoop/binexport HADOOP_HOME=/usr/local/hadoopexport HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native[hadoop@dev-161 ~]$ source .bashrc[hadoop@dev-161 ~]$ echo $JAVA_HOME/usr/lib/jvm/java-1.8.0-openjdk[hadoop@dev-161 ~]$ java -versionopenjdk version "1.8.0_141"OpenJDK Runtime Environment (build 1.8.0_141-b16)OpenJDK 64-Bit Server VM (build 25.141-b16, mixed mode)[hadoop@dev-161 ~]$ $JAVA_HOME/bin/java -versionopenjdk version "1.8.0_141"OpenJDK Runtime Environment (build 1.8.0_141-b16)OpenJDK 64-Bit Server VM (build 25.141-b16, mixed mode)
下载hadoop
## download hadoop-2.7.4.tar.gz[hadoop@dev-162 ~]$ wget https://mirrors.cnnic.cn/apache/hadoop/common/hadoop-2.7.4/hadoop-2.7.4.tar.gz --no-check-certificate## tar hadoop-2.7.4.tar.gz to /usr/local[hadoop@dev-161 tmp]$ sudo tar -zxvf hadoop-2.7.4.tar.gz -C /usr/local/[hadoop@dev-161 tmp]$ cd /usr/local/## rename /usr/local/hadoop-2.7.4 dir to /usr/local/hadoop[hadoop@dev-161 local]$ sudo mv hadoop-2.7.4/ hadoop## change /usr/local/hadoop dir owner[hadoop@dev-161 local]$ sudo chown -R hadoop hadoop/[hadoop@dev-161 local]$ cd /usr/local/hadoop/## show hadoop version[hadoop@dev-161 hadoop]$ ./bin/hadoop versionHadoop 2.7.4Subversion https://shv@git-wip-us.apache.org/repos/asf/hadoop.git -r cd915e1e8d9d0131462a0b7301586c175728a282Compiled by kshvachk on 2017-08-01T00:29ZCompiled with protoc 2.5.0From source with checksum 50b0468318b4ce9bd24dc467b7ce1148This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-2.7.4.jar
配置core-site.xml
## 配置core-site.xml[hadoop@dev-161 hadoop]$ pwd/usr/local/hadoop[hadoop@dev-161 hadoop]$ vim etc/hadoop/core-site.xml<configuration><property><name>hadoop.tmp.dir</name><value>file:/usr/local/hadoop/tmp</value><description>Abase for other temporary directories.</description></property><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property></configuration>
配置hdfs-site.xml
## 配置 hdfs-site.xml[hadoop@dev-161 hadoop]$ vim etc/hadoop/hdfs-site.xml<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop/tmp/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/tmp/dfs/data</value></property></configuration>
格式化并启动hdfs
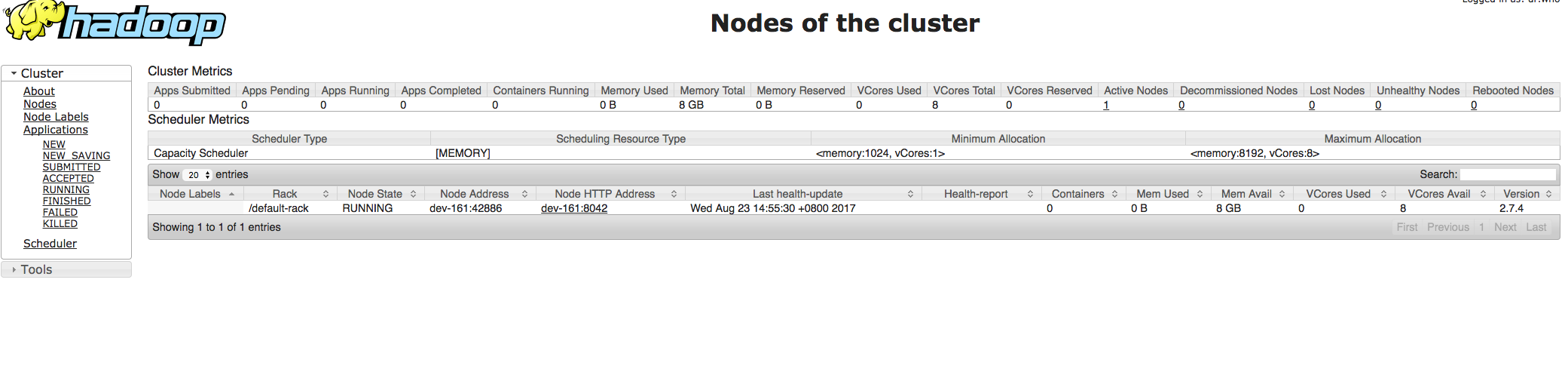
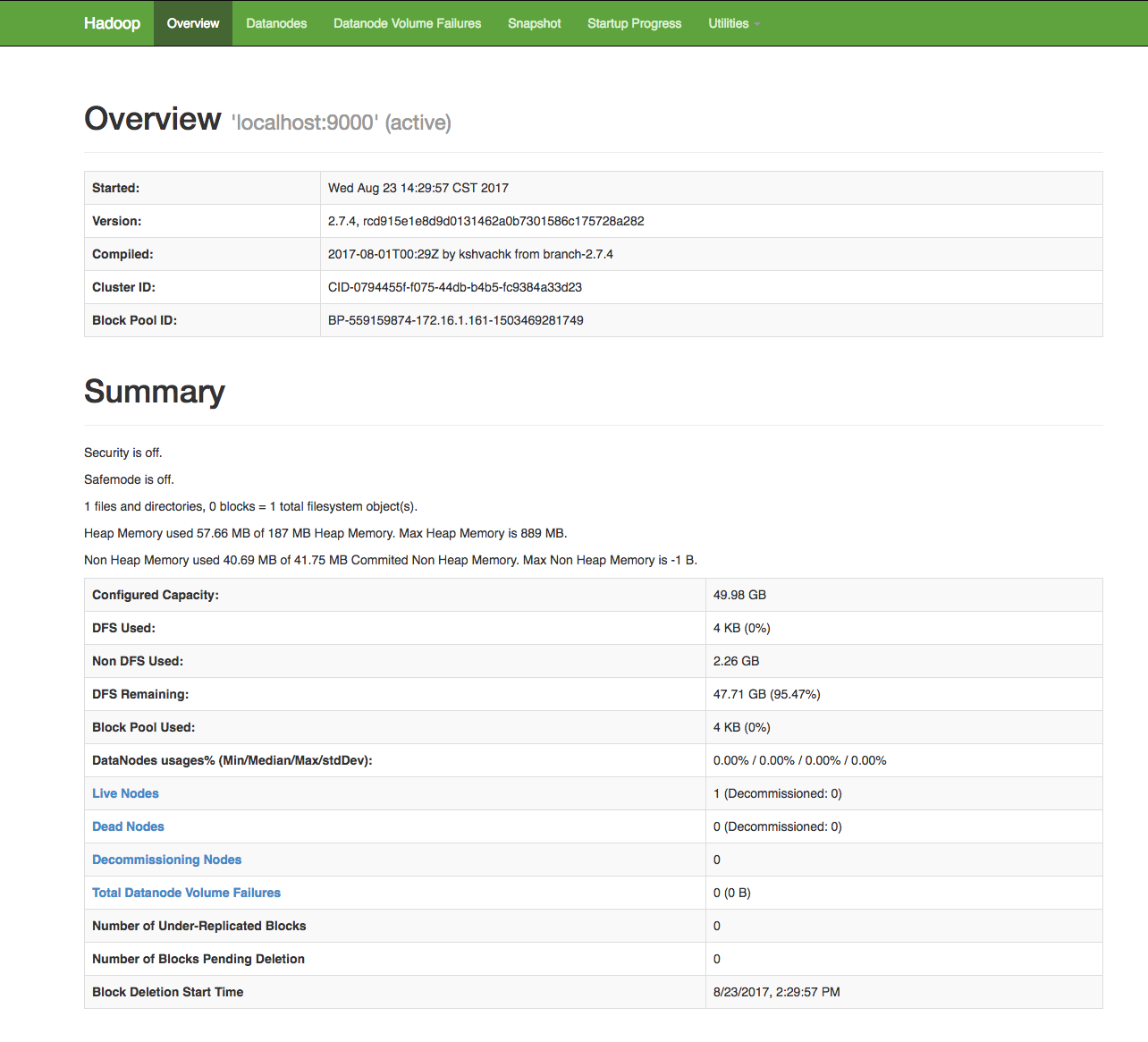
[hadoop@dev-161 hadoop]$ ./bin/hdfs namenode -format## 出现以下信息表示成功17/08/23 14:21:21 INFO common.Storage: Storage directory /usr/local/hadoop/tmp/dfs/name has been successfully formatted.17/08/23 14:21:21 INFO util.ExitUtil: Exiting with status 0[hadoop@dev-161 ~]$ cd /usr/local/hadoop/## 启动hdfs[hadoop@dev-161 hadoop]$ ./sbin/start-dfs.shStarting namenodes on [localhost]localhost: starting namenode, logging to /usr/local/hadoop/logs/hadoop-hadoop-namenode-dev-161.outlocalhost: starting datanode, logging to /usr/local/hadoop/logs/hadoop-hadoop-datanode-dev-161.outStarting secondary namenodes [0.0.0.0]The authenticity of host '0.0.0.0 (0.0.0.0)' can not be established.ECDSA key fingerprint is fe:0f:40:d7:56:c8:c1:b4:29:c3:ce:d8:d6:12:66:2e.Are you sure you want to continue connecting (yes/no)? yes0.0.0.0: Warning: Permanently added '0.0.0.0' (ECDSA) to the list of known hosts.0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-hadoop-secondarynamenode-dev-161.out## 启动成功[hadoop@dev-161 hadoop]$ jps5714 DataNode5589 NameNode6022 Jps5881 SecondaryNameNode# webuihttp://172.16.1.161:50070/dfshealth.html#tab-overview
hdfs常用命令
[hadoop@dev-161 hadoop]$ ./bin/hdfsUsage: hdfs [--config confdir] [--loglevel loglevel] COMMANDwhere COMMAND is one of:dfs run a filesystem command on the file systems supported in Hadoop.classpath prints the classpathnamenode -format format the DFS filesystemsecondarynamenode run the DFS secondary namenodenamenode run the DFS namenodejournalnode run the DFS journalnodezkfc run the ZK Failover Controller daemondatanode run a DFS datanodedfsadmin run a DFS admin clienthaadmin run a DFS HA admin clientfsck run a DFS filesystem checking utilitybalancer run a cluster balancing utilityjmxget get JMX exported values from NameNode or DataNode.mover run a utility to move block replicas acrossstorage typesoiv apply the offline fsimage viewer to an fsimageoiv_legacy apply the offline fsimage viewer to an legacy fsimageoev apply the offline edits viewer to an edits filefetchdt fetch a delegation token from the NameNodegetconf get config values from configurationgroups get the groups which users belong tosnapshotDiff diff two snapshots of a directory or diff thecurrent directory contents with a snapshotlsSnapshottableDir list all snapshottable dirs owned by the current userUse -help to see optionsportmap run a portmap servicenfs3 run an NFS version 3 gatewaycacheadmin configure the HDFS cachecrypto configure HDFS encryption zonesstoragepolicies list/get/set block storage policiesversion print the versionMost commands print help when invoked w/o parameters.----------[hadoop@dev-161 hadoop]$ ./bin/hdfs dfsUsage: hadoop fs [generic options][-appendToFile <localsrc> ... <dst>][-cat [-ignoreCrc] <src> ...][-checksum <src> ...][-chgrp [-R] GROUP PATH...][-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...][-chown [-R] [OWNER][:[GROUP]] PATH...][-copyFromLocal [-f] [-p] [-l] <localsrc> ... <dst>][-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>][-count [-q] [-h] <path> ...][-cp [-f] [-p | -p[topax]] <src> ... <dst>][-createSnapshot <snapshotDir> [<snapshotName>]][-deleteSnapshot <snapshotDir> <snapshotName>][-df [-h] [<path> ...]][-du [-s] [-h] <path> ...][-expunge][-find <path> ... <expression> ...][-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>][-getfacl [-R] <path>][-getfattr [-R] {-n name | -d} [-e en] <path>][-getmerge [-nl] <src> <localdst>][-help [cmd ...]][-ls [-d] [-h] [-R] [<path> ...]][-mkdir [-p] <path> ...][-moveFromLocal <localsrc> ... <dst>][-moveToLocal <src> <localdst>][-mv <src> ... <dst>][-put [-f] [-p] [-l] <localsrc> ... <dst>][-renameSnapshot <snapshotDir> <oldName> <newName>][-rm [-f] [-r|-R] [-skipTrash] <src> ...][-rmdir [--ignore-fail-on-non-empty] <dir> ...][-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]][-setfattr {-n name [-v value] | -x name} <path>][-setrep [-R] [-w] <rep> <path> ...][-stat [format] <path> ...][-tail [-f] <file>][-test -[defsz] <path>][-text [-ignoreCrc] <src> ...][-touchz <path> ...][-truncate [-w] <length> <path> ...][-usage [cmd ...]]Generic options supported are-conf <configuration file> specify an application configuration file-D <property=value> use value for given property-fs <local|namenode:port> specify a namenode-jt <local|resourcemanager:port> specify a ResourceManager-files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster-libjars <comma separated list of jars> specify comma separated jar files to include in the classpath.-archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines.The general command line syntax isbin/hadoop command [genericOptions] [commandOptions]----------## 在HDFS上创建目录[hadoop@dev-161 hadoop]$ ./bin/hdfs dfs -mkdir -p /user/hadoop[hadoop@dev-161 hadoop]$ ./bin/hdfs dfs -mkdir input## 查看HDFS的目录结构[hadoop@dev-161 hadoop]$ ./bin/hdfs dfs -ls /user/hadoopFound 1 itemsdrwxr-xr-x - hadoop supergroup 0 2017-08-23 14:40 /user/hadoop/input## 上传本地文件至HDFS指定目录[hadoop@dev-161 hadoop]$ ./bin/hdfs dfs -put etc/hadoop/*.xml input[hadoop@dev-161 hadoop]$ ./bin/hdfs dfs -ls inputFound 8 items-rw-r--r-- 1 hadoop supergroup 4436 2017-08-23 14:40 input/capacity-scheduler.xml-rw-r--r-- 1 hadoop supergroup 1115 2017-08-23 14:40 input/core-site.xml-rw-r--r-- 1 hadoop supergroup 9683 2017-08-23 14:40 input/hadoop-policy.xml-rw-r--r-- 1 hadoop supergroup 1180 2017-08-23 14:40 input/hdfs-site.xml-rw-r--r-- 1 hadoop supergroup 620 2017-08-23 14:40 input/httpfs-site.xml-rw-r--r-- 1 hadoop supergroup 3518 2017-08-23 14:40 input/kms-acls.xml-rw-r--r-- 1 hadoop supergroup 5540 2017-08-23 14:40 input/kms-site.xml-rw-r--r-- 1 hadoop supergroup 690 2017-08-23 14:40 input/yarn-site.xml[hadoop@dev-161 hadoop]$ ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar grep input output 'dfs[a-z.]+'## 查看HDFS文件内容[hadoop@dev-161 hadoop]$ ./bin/hdfs dfs -cat output/*1 dfsadmin1 dfs.replication1 dfs.namenode.name.dir1 dfs.datanode.data.dir[hadoop@dev-161 hadoop]$ ./bin/hdfs dfs -lsFound 2 itemsdrwxr-xr-x - hadoop supergroup 0 2017-08-23 14:40 inputdrwxr-xr-x - hadoop supergroup 0 2017-08-23 14:42 output## 下载HDFS目录至本地[hadoop@dev-161 hadoop]$ ./bin/hdfs dfs -get output output[hadoop@dev-161 hadoop]$ cat output/*1 dfsadmin1 dfs.replication1 dfs.namenode.name.dir1 dfs.datanode.data.dir## 删除HDFS指定目录[hadoop@dev-161 hadoop]$ ./bin/hdfs dfs -rm -r output17/08/23 14:48:55 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.Deleted output[hadoop@dev-161 hadoop]$ ./bin/hdfs dfs -lsFound 1 itemsdrwxr-xr-x - hadoop supergroup 0 2017-08-23 14:40 input
修改配置并启动YARN
[hadoop@dev-161 hadoop]$ mv etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml[hadoop@dev-161 hadoop]$ vim etc/hadoop/mapred-site.xml<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>[hadoop@dev-161 hadoop]$ vim etc/hadoop/yarn-site.xml<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property></configuration>## 然后就可以启动 YARN 了(需要先执行过 ./sbin/start-dfs.sh)[hadoop@dev-161 hadoop]$ ./sbin/start-yarn.shstarting yarn daemonsstarting resourcemanager, logging to /usr/local/hadoop/logs/yarn-hadoop-resourcemanager-dev-161.outlocalhost: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-hadoop-nodemanager-dev-161.out[hadoop@dev-161 hadoop]$ ./sbin/mr-jobhistory-daemon.sh start historyserverstarting historyserver, logging to /usr/local/hadoop/logs/mapred-hadoop-historyserver-dev-161.out[hadoop@dev-161 hadoop]$ jps5714 DataNode5589 NameNode7189 Jps6726 ResourceManager6838 NodeManager5881 SecondaryNameNode7150 JobHistoryServer## webuihttp://172.16.1.161:8088/cluster