@qinian
2018-07-20T08:33:34.000000Z
字数 5704
阅读 1825
XML文件解析
python文件操作
网页基本知识,HTML和XML
一、HTML:
HTML即Hyper Text Markup Language,指的是超文本标记语言(不是编程语言)
超文本标记语言的结构包括“头”部分(英语:Head)、和“主体”部分(英语:Body),其中“头”部提供关于网页的信息,“主体”部分提供网页的具体内容。
标记符:HTML,说明该文件是用超文本标记语言(本标签的中文全称)来描述的,超文本标记语言定义了多种数据类型的元素内容,如脚本数据和样式表的数据,和众多类型的属性值,包括ID、名称、URI、数字、长度单位、语言、媒体描述符、颜色、字符编码、日期和时间等。所有这些数据类型都是专业的字符数据。为了说明文档使用的超文本标记语言标准,所有超文本标记语言文档应该以“文件类型声明”(外语全称加缩写<!DOCTYPE>)开头,引用一个文件类型描述或者必要情况下自定义一个文件类型描述。
二、XML:
XML即ExtentsibleMarkup
Language(可扩展标记语言),是用来定义其它语言的一种元语言,其前身是SGML(标准通用标记语言)。它没有标签集(tagset),也没有语法规则(grammaticalrule),但是它有句法规则(syntax rule)。任何XML文档对任何类型的应用以及正确的解析都必须是良构的(well-formed),即每一个打开的标签都必须有匹配的结束标签,不得含有次序颠倒的标签,并且在语句构成上应符合技术规范的要求。XML文档可以是有效的(valid),但并非一定要求有效。所谓有效文档是指其符合其文档类型定义(DTD)的文档。如果一个文档符合一个模式(schema)的规定,那么这个文档是模式有效的(schema>valid)。
三、HTML与XML的区别
XML和HTML都是用于操作数据或数据结构,在结构上大致是相同的,但它们在本质上却存在着明显的区别。综合网上的各种资料总结如下。
(一)、语法要求不同:
在
HTML中不区分大小写,在XML中严格区分。在
HTML中,有时不严格,如果上下文清楚地显示出段落或者列表键在何处结尾,那么你可以省略</p>或者</li>之类的结束标记。在XML中,是严格的树状结构,绝对不能省略掉结束标记。在
XML中,拥有单个标记而没有匹配的结束标记的元素必须用一个/字符作为结尾。这样分析器就知道不用查找结束标记了。在
XML中,属性值必须分装在引号中。在HTML中,引号是可用可不用的。在
HTML中,可以拥有不带值的属性名。在XML中,所有的属性都必须带有相应的值。在
XML文档中,空白部分不会被解析器自动删除;但是HTML是过滤掉空格的。
(二)、标记不同:
HTML使用固有的标记;而XML没有固有的标记。
HTML标签是预定义的;XML标签是免费的、自定义的、可扩展的。
(三)、作用不同:
HTML是用来显示数据的;XML是用来描述数据、存放数据的,所以可以作为持久化的介质。HTML将数据和显示结合在一起,在页面中把这数据显示出来;XML则将数据和显示分开。XML被设计用来描述数据,其焦点是数据的内容。HTML被设计用来显示数据,其焦点是数据的外观。XML不是HTML的替代品,XML和HTML是两种不同用途的语言。XML不是要替换HTML;实际上XML可以视作对HTML的补充。XML和HTML的目标不同HTML的设计目标是显示数据并集中于数据外观,而XML的设计目标是描述数据并集中于数据的内容。- 没有任何行为的
XML与HTML相似,XML不进行任何操作。(共同点)- 对于
XML最好的形容可能是:XML是一种跨平台的,与软、硬件无关的,处理与传输信息的工具。XML未来将会无所不在。XML将成为最普遍的数据处理和数据传输的工具。
四、XML文档树结构
XML文档必须包含根元素。该元素是所有其他元素的父元素。XML文档中的元素形成了一棵文档树,这棵树从根部开始,并扩展到树的最底端。所有的元素都可以有子元素:
<bookstore><book category="COOKING"><title lang="en">Everyday Italian</title><author>Giada De Laurentiis</author><year>2005</year><price>30.00</price></book><book category="CHILDREN"><title lang="en">Harry Potter</title><author>J K. Rowling</author><year>2005</year><price>29.99</price></book><book category="WEB"><title lang="en">Learning XML</title><author>Erik T. Ray</author><year>2003</year><price>39.95</price></book></bookstore>
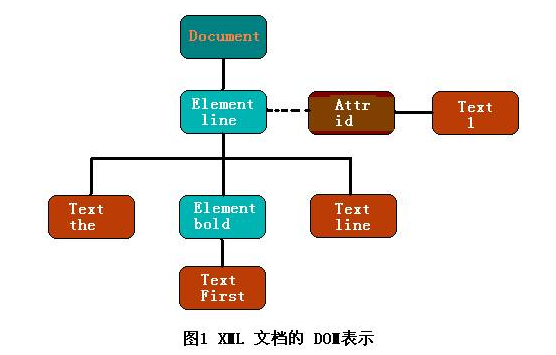
XML将数据组织成为一棵树,DOM通过解析XML文档,为XML文档在逻辑上建立一个树模型,树的节点是一个个的对象。这样通过操作这棵树和这些对象就可以完成对XML文档的操作,为处理文档的所有方面提供了一个完美的概念性框架。
五、XML作用
XML与操作系统、编程语言的开发平台都无关XML实现不同系统之间的数据交互XML是Ajax基石。(Ajax是现在目前比较流行的一个网络交互的技术。Ajax里面最后一个x实际上就是XML的缩写。)
六、XML文件格式
1、首先 info.xml 文件
<?xml version="1.0" encoding="utf-8"?><info><base><platform>Windows</platform><browser>Firefox</browser><url>http://www.baidu.com</url><login username="admin" passwd="123456"/><login username="guest" passwd="123456"/></base><test><province>北京</province><province>广东</province><city>深圳</city><city>珠海</city><province>浙江</province><city>珠海</city></test></info>
tag,即标签,用于标识该元素表示哪种数据,即urllogin开头的那个。attrib,即属性,用Dictionary形式保存,即username="admin"text,文本字符串,可以用来存储一些数据,即hello123456789tail,尾字符串,并不是必须的,例子中没有包含。
七、python对XML文件解析
1、XML文件解析
解析思想: DOM解析和SAX解析,ET解析(元素树,前面都是自带),采用外部库。
一、是xml.dom.*模块,它是W3C DOM API的实现,若需要处理DOMAPI则该模块很适合;
二、是xml.sax.*模块,它是SAX API的实现,这个模块牺牲了便捷性来换取速度和内存占用,SAX是一个基于事件的API,这就意味着它可以“在空中”处理庞大数量的的文档,不用完全加载进内存;
三、是xml.etree.ElementTree模块(简称ET),它提供了轻量级的Python式的API,相对于DOM来说ET快了很多,而且有很多令人愉悦的API可以使用,相对于SAX来说ET的ET.iterparse也提供了 “在空中” 的处理方式,没有必要加载整个文档到内存,ET的性能的平均值和SAX差不多,但是API的效率更高一点而且使用起来很方便。
四、使用libxml2解析xml,libxml2是使用C语言开发的xml解析器,是一个基于MIT License的免费开源软件,多种编程语言都有基于它的实现。
五、使用lxml解析xml。lxml是以上述介绍过的libxml2为基础采用python语言开发的,从使用层面上说比libxml2更适合python开发者
2.1
xml.dom.*
文件对象模型(Document Object Model,简称DOM),是W3C组织推荐的处理可扩展置标语言的标准编程接口。一个DOM的解析器在解析一个XML文档时,一次性读取整个文档,把文档中所有元素保存在内存中的一个树结构里,之后你可以利用DOM提供的不同的函数来读取或修改文档的内容和结构,也可以把修改过的内容写入xml文件。python中用xml.dom.minidom来解析xml文件。
'''通过minidom解析xml文件'''import xml.dom as minidom# XML文件读取dom = minidom.parse('info.xml')# 得到文档元素以及他的对象root = dom.documentElenmentlogins = root.getElementsByTagName('login')# 得到元素对象第一个logins标签的username属性值username = logins[0].getAttribute('username')print(username)# 得到元素对象第一个logins标签的password属性值username = logins[0].getAttribute('password')print(password)# 得到元素对象logins第二个标签的username属性值username = logins[1].getAttribute('username')print(username)# 得到元素对象logins第二个标签的password属性值username = logins[1].getAttribute('password')print(password)
2.2 xml.etree.ElementTree
ElementTree生来就是为了处理XML,它在Python标准库中有两种实现:
一、纯Python实现的,如xml.etree.ElementTree,
二、是速度快一点的xml.etree.cElementTree,从Python3.3开始ElementTree模块会自动寻找可用的C库来加快速度 。
import xml.etree.ElementTree as ET# 解析xml文件root = ET.parse("info.xml")#获得根节点,查看根节点所有标签以及属性。root = tree.getroot()print('root.tag =', root.tag)print('root.attrib =', root.attrib)#遍历根节点可以获得子节点,遍历子节点可以获得孙子节点。for child in root: #仅可以解析出root的儿子,不能解析出root的子孙print(child.tag)print(child.attrib) # attrib is a dict#通过索引解析根的子孙print(root[1][2].tag)print(root[1][3].text)#迭代解析出所有的指定element,,返回字典for element in root.iter('test'):print(element.attrib)# element.findall()解析出指定test的所有儿子# element.find()解析出指定test的第一个儿子# element.get()解析出指定test的属性attribfor environment in root.findall('test'):first_variable = test.find('variable')print(first_variable.get('name'))#假设我们需要给每个text元素添加一个属性size="50",修改其text为"Benxin Tuzi",添加一个子元素date="2016/01/16"for text in root.iter('text'):text.set('size', '50')text.text = 'Benxin Tuzi'text.append(ET.Element('date', attrib={}, text='2016/01/16'))tree.write('output.xml')
2.2 lxml.etree
python lxml包用于解析XML和html文件,可以使用xpath和css定位元素。可参考:lxml手册,静觅博客Xpath
from lxml import etreetree = etree.parse('info.xml') #构建xml树root = tree.getroot() #获得该树的树根for article in root:#这样便可以遍历根元素的所有子元素(这里是article元素)print "元素名称:",article.tag#用.tag得到该子元素的名称for field in article:#遍历article元素的所有子元素(这里是指article的author,title,volume,year等)print field.tag,":",field.text#同样地,用.tag可以得到元素的名称,而.text可以得到元素的内容mdate=article.get("city")#用.get("属性名")可以得到元素相应属性的值print ("city:",city)'''结合xpath选取节点'''result = tree.xpath("//test")print result
参考:XML介绍/菜鸟教程
参考:Python XML解析
参考:Python实现XML文件解析/小兵千睿
参考:使用xml.etree.ElementTree模块来解析XML文件/benxintuzi
参考:python解析xml之lxml/编程浪子
