@runzhliu
2018-04-13T03:29:03.000000Z
字数 29155
阅读 1650
JVM 浅讲
JVM 基础
参考资料
《实战 Java 虚拟机》
JVM 的工作原理,层次结构以及 GC 工作原理
Java程序的跨平台性
查看java字节码文件
从 Java 代码到 Java 堆
IDEA中一个很有用的内存调试插件
IntelliJ IDEA集成JProfiler,入门教程
JVM 垃圾回收器工作原理及使用实例介绍
Java Garbage Collection Basics
java JVM运行时栈帧结构
Java 内存之方法区和运行时常量池
JVM 系列
JVM进阶之JVM算法及种类
Java Hotspot G1 GC的一些关键技术
使用 VisualVM 进行性能分析及调优
Java 应用性能调优实践
从实际案例聊聊Java应用的GC优化
Understanding Garbage Collection Logs
G1垃圾收集器入门
JVM内存回收理论与实现
Java Memory Management
深入理解JVM(3)——7种垃圾收集器
1 讲解提纲和时间安排
- JVM 历史简单回顾 5 min
- 虚拟机的基本结构和内存模型 15 min
- JVM 常用参数 10 min
- 垃圾回收概念与算法 15 min
- 常见性能监控工具 10 min
- 提问 5 min
2 JVM 历史简单回顾
虚拟机可以说包括系统虚拟机和程序虚拟机,Visual Box, VMware 是常见的系统虚拟机,而 Java 虚拟机则是著名的程序虚拟机。在 Java 虚拟机中执行的指令称为 Java 字节码指令。无论是何种虚拟机,运行在上面的软件都被限制于虚拟机提供的资源中。
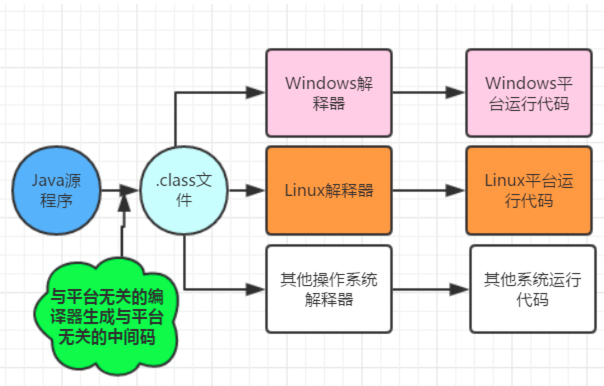
Java 程序被编译成一种中间语言,再由 JVM 将 Java 字节码(.class 文件)翻译成机器语言。Java 源程序编译的结果是生成 Java 字节码,不同平台下生成的 Java 字节码是相同的。
再次强调,跨平台的是 Java 程序(或者说是字节码),因为其后面会被与平台不相关的编译器编译成与平台不相关的中间码。JVM 不是跨平台的,不同平台下需要安装不同的 JVM,可以在 Java 的 Download 页面 找到不同平台的下载链接。跨平台特性可以参考图1。
Q: 如何查看字节码文件?
A: 首先,字节码文件是二进制文件,所以,我们所谓的查看字节码文件,就是对其进行反向解析,将其解释为人类可以理解的类自然语言以供查看,IntelliJ 有一个叫 jclasslib 的插件可供使用,效果和用 javap 工具反编译 Class 文件类似,只是可视化程度会更高,是学习字节码的好工具。
3 认识 Java 虚拟机的基本结构
3.1 Java 虚拟机基本结构
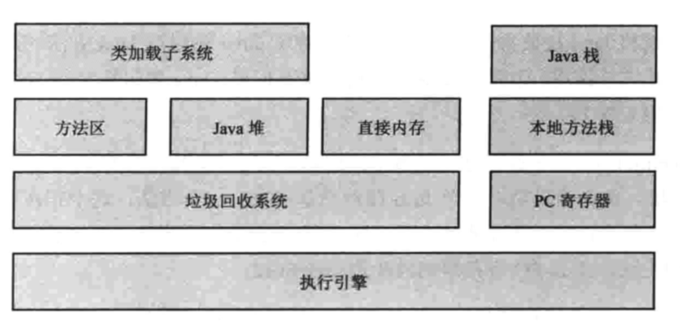
类加载系统: 从文件系统或者网络加载 Class 信息,加载的类信息存放于方法区,除了类的信息,方法区中可能还会存放运行时常量池信息,包括字符串字面量和数字常量。
Java 堆: 在虚拟机启动的时候建立,是 Java 程序最主要的内存工作区域,几乎所有的 Java 实例都存放在 Java 堆中。堆空间是所有线程共享的。
直接内存: Java 的 NIO 库允许 Java 程序使用直接内存,直接内存是 Java 堆以外的内存空间,需要直接向系统申请,所以又称为「堆外内存」。由于存在于堆外,因此其大小不会直接受限于 Xmx 指定的最大堆大小,但是系统内存是有限的,所以还是会间接受限。
垃圾回收器: 是虚拟机重要组成各部分,垃圾回收器会对方法区、Java 堆和直接内存进行回收,其中 Java 堆是回收的重点。
总体来说,垃圾回收的工作就是默默查找、标识并释放垃圾对象,完成包括 Java 堆、方法区和直接内存的全自动化管理。
Java 栈: 每个 Java 虚拟机线程都有一个私有的栈,一个线程的 Java 栈在线程创建的时候被创建,栈中保存帧信息,如局部变量、方法参数,同时和 Java 方法的调用、返回密切相关。
本地方法栈: 它跟 Java 栈类似的,最大不同在于本地方法栈用于本地方法调用。而现在,Java 虚拟机也会允许 Java 直接调用本地方法(如 C 编写的方法)。
Q: 什么叫 Java 调用本地方法?
A: 还记得 Java 调用 TensorFlow 吗?简单地讲,一个 Native Method 就是一个 java 调用非 java 代码的接口。一个 Native Method 是这样一个 java 的方法:该方法的实现由非 java 语言实现,比如 C。
PC 寄存器: 也称为程序计数器,是每个线程私有的空间,Java 虚拟机会为每个 Java 线程创建 PC 寄存器。在任意时刻,一个 Java 线程总是在执行一个方法,这个正在被执行的方法称为当前方法,如果当前方法不是本地方法,PC 寄存器就会指向当前正在执行的指令,如果当前方法是本地方法,那么 PC 寄存器的值是 undefined。它的作用可以看做是当前线程所执行的字节码的行号指示器。字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。由于Java虚拟机的多线程是通过线程轮流切换并分配处理器执行时间的方式来实现的,在任何一个确定的时刻,一个处理器(对于多核处理器来说是一个内核)只会执行一条线程中的指令。因此,为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各条线程之间的计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。
执行引擎: 则是 Java 虚拟机的最核心的组件之一,负责执行虚拟机的字节码,现代虚拟机为了提高执行效率,会使用即时编译技术把方法编译成机器码后再执行。
# java 程序运行示例# java [-options] class [args...]➜ /tmp java ShowJvmDetails a参数1:a-Xmx1908M➜ workspace java -h用法: java [-options] class [args...](执行类)或 java [-options] -jar jarfile [args...](执行 jar 文件)其中选项包括:-d32 使用 32 位数据模型 (如果可用)-d64 使用 64 位数据模型 (如果可用)-server 选择 "server" VM默认 VM 是 server,因为您是在服务器类计算机上运行。-cp <目录和 zip/jar 文件的类搜索路径>-classpath <目录和 zip/jar 文件的类搜索路径>用 : 分隔的目录, JAR 档案和 ZIP 档案列表, 用于搜索类文件。-D<名称>=<值>设置系统属性-verbose:[class|gc|jni]启用详细输出-version 输出产品版本并退出-version:<值>警告: 此功能已过时, 将在未来发行版中删除。需要指定的版本才能运行-showversion 输出产品版本并继续-jre-restrict-search | -no-jre-restrict-search警告: 此功能已过时, 将在未来发行版中删除。在版本搜索中包括/排除用户专用 JRE-? -help 输出此帮助消息-X 输出非标准选项的帮助-ea[:<packagename>...|:<classname>]-enableassertions[:<packagename>...|:<classname>]按指定的粒度启用断言-da[:<packagename>...|:<classname>]-disableassertions[:<packagename>...|:<classname>]禁用具有指定粒度的断言-esa | -enablesystemassertions启用系统断言-dsa | -disablesystemassertions禁用系统断言-agentlib:<libname>[=<选项>]加载本机代理库 <libname>, 例如 -agentlib:hprof另请参阅 -agentlib:jdwp=help 和 -agentlib:hprof=help-agentpath:<pathname>[=<选项>]按完整路径名加载本机代理库-javaagent:<jarpath>[=<选项>]加载 Java 编程语言代理, 请参阅 java.lang.instrument-splash:<imagepath>使用指定的图像显示启动屏幕有关详细信息, 请参阅 http://www.oracle.com/technetwork/java/javase/documentation/index.html。
3.2 堆分代
根据垃圾回收机制的不同,Java 堆有可能拥有不同的结构,最为常见的一种构成是把整个 Java 堆分为新生代和老年代。其中,新生代存放新生对象或者年龄不大的对象,老年代则存放老年对象。新生代有可能分为 eden 区、s0 区、s1 区,s0 和 s1 也被称为 from 和 to 区域,他们是两块大小相等、可以互换角色的内存空间。
Q: 为什么要学习 Java 的内存模型?
A: 因为只有理解了 Java 内存模型,才可能理解垃圾回收的算法,然后才可能进行内存模型的调优。
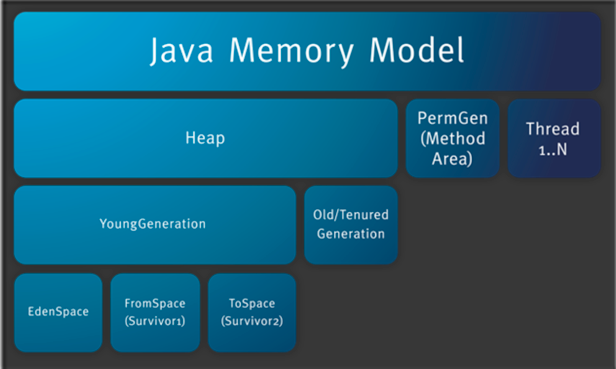
在绝大多数情况下,对象首先分配在 eden 区,在一次新生代回收之后,如果对象还存活的话就会进入 s0/s1,之后每经过一次新生代回收,对象如果存活,年龄就会加1,当对象的年龄达到一定条件后,就会被认为是老年对象,然后进入老年代。
public class SimpleHeap {private int id;public SimpleHeap(int id) {this.id = id;}public void show() {System.out.println("My ID is " + id);}public static void main(String[] args) {SimpleHeap s1 = new SimpleHeap(1);SimpleHeap s2 = new SimpleHeap(2);s1.show();s2.show();}}
Q: 以上示例代码中,谁分配到堆、方法区还有 Java 栈?
A: s1 和 s2 实例 -> Heap; SimpleHeap 类及方法实现 -> 方法区; s1 和 s2 的局部变量 -> Java 栈并且指向堆空间对应的实例
3.3 函数调用与出入 Java 栈
Java 栈是一块线程私有的内存空间,如果说 Java 堆和程序数据密切相关,那么栈就是和线程执行密切相关的。线程执行的基本行为是函数调用,每次函数调用的数据都是通过 Java 栈传递的。
Java 栈保存的主要内容为栈帧,每一次函数调用,都会有一个对应的栈帧被压入 Java 栈,每一个函数调用结束,都会有一个栈帧被弹出 Java 栈。栈帧是用于支持虚拟机进行方法调用和方法执行的数据结构。每一个方法从调用开始到执行完成的过程都可以看作是一个栈帧于虚拟机栈中从入栈到出栈的过程。
一个线程中有很多个栈帧,只有位于这个栈最上方的栈帧才是有效的,最上方栈顶的栈帧我们称之为当前栈帧,当前栈帧关联的方法我们称之为当前方法。虚拟机的执行引擎的字节码指令只会对当前栈帧(当前方法)起作用。
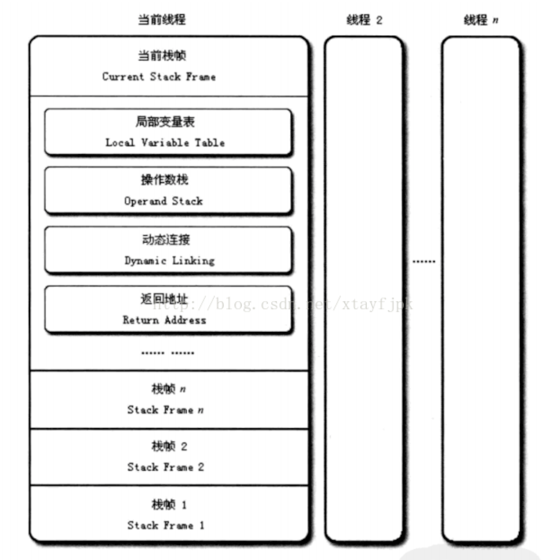
当函数返回的时候,栈帧从 Java 栈中被弹出。Java 方法有两种返回函数的方式,一种是正常函数返回,使用 return 指令,另一种是抛出异常,不管哪种方式,都会导致栈帧被弹出。
Q: 栈帧里放着什么?
A: 栈帧中会包含局部变量表、操作数栈和帧数据等。
每次函数调用都会生成对应的栈帧,从而占一定的栈空间,因此如果栈空间不足,那么函数自然无法继续进行下去,当请求的栈深度大于最大可用栈深度时,系统都会抛出 StackOverflowError 栈溢出错误。
4 常用 Java 虚拟机参数
如果要诊断虚拟机,就需要了解一些基本的配置和跟踪参数,这对系统故障诊断、性能优化有着很重要的作用。使用虚拟机提供了这些跟踪状态的参数,就可以在系统运行过程中打印相关日志,用于问题分析。
4.1 JVM 参数实例
以下是推荐系统目前正在使用的 JVM 参数,不认识这些参数,或者只认识几个的也没关系。
-Xms8g -Xmx8g \-XX:ParallelGCThreads=8 \-XX:SurvivorRatio=1 \-XX:LargePageSizeInBytes=128M \-XX:MaxNewSize=1g \-XX:CMSInitiatingOccupancyFraction=80 \-XX:+UseCMSCompactAtFullCollection \-XX:CMSFullGCsBeforeCompaction=0 \-XX:-UseGCOverheadLimit \-XX:MaxTenuringThreshold=5 \-XX:GCTimeRatio=19 \-XX:+UseConcMarkSweepGC \-XX:+UseParNewGC \-XX:+PrintGCDetails \-XX:+PrintGCTimeStamps \-XX:+HeapDumpOnOutOfMemoryError \-XX:HeapDumpPath=/var/log/release/${APP_NAME}-${MODULE}.dump \-Xloggc:/var/log/release/${APP_NAME}-${MODULE}-gc.$DATE_VERSION.log
4.2 读懂虚拟机的日志
以下是一个真实的 gc 日志,我们的目标就是读懂它。
Java HotSpot(TM) 64-Bit Server VM (25.111-b14) for linux-amd64 JRE (1.8.0_111-b14), built on Sep 22 2016 16:14:03 by "java_re" with gcc 4.3.0 20080428 (Red Hat 4.3.0-8)Memory: 4k page, physical 33554432k(8157020k free), swap 0k(0k free)CommandLine flags: -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/recommender-system-recall.dump -XX:InitialHeapSize=536870912 -XX:MaxHeapSize=8589934592 -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGC1.557: [GC (Allocation Failure) [PSYoungGen: 131584K->12813K(153088K)] 131584K->12821K(502784K), 0.0484572 secs] [Times: user=0.12 sys=0.00, real=0.05 secs]1.968: [GC (Metadata GC Threshold) [PSYoungGen: 36227K->6233K(284672K)] 36235K->6313K(634368K), 0.0124556 secs] [Times: user=0.01 sys=0.05, real=0.01 secs]1.981: [Full GC (Metadata GC Threshold) [PSYoungGen: 6233K->0K(284672K)] [ParOldGen: 80K->6061K(219648K)] 6313K->6061K(504320K), [Metaspace: 20731K->20731K(1067008K)], 0.1044854 secs] [Times: user=0.62 sys=0.01, real=0.11 secs]4.034: [GC (Metadata GC Threshold) [PSYoungGen: 177311K->15769K(284672K)] 183373K->21839K(504320K), 0.0315097 secs] [Times: user=0.15 sys=0.02, real=0.03 secs]4.066: [Full GC (Metadata GC Threshold) [PSYoungGen: 15769K->0K(284672K)] [ParOldGen: 6069K->18964K(391680K)] 21839K->18964K(676352K), [Metaspace: 34751K->34751K(1079296K)], 0.2243983 secs] [Times: user=1.46 sys=0.07, real=0.23 secs]144.113: [GC (Allocation Failure) [PSYoungGen: 262635K->21491K(338432K)] 281600K->45471K(730112K), 0.0289011 secs] [Times: user=0.10 sys=0.02, real=0.03 secs]
Java 的一大特色就是自动垃圾回收,但如果垃圾回收过于频繁,或者占用太多的 CPU 时间,就需要加一些跟踪参数来进行垃圾回收期的效率和效果的诊断了。
4.3 堆参数配置
堆空间是 Java 进程的重要组成部分,与应用相关的内存空间都和堆有关。
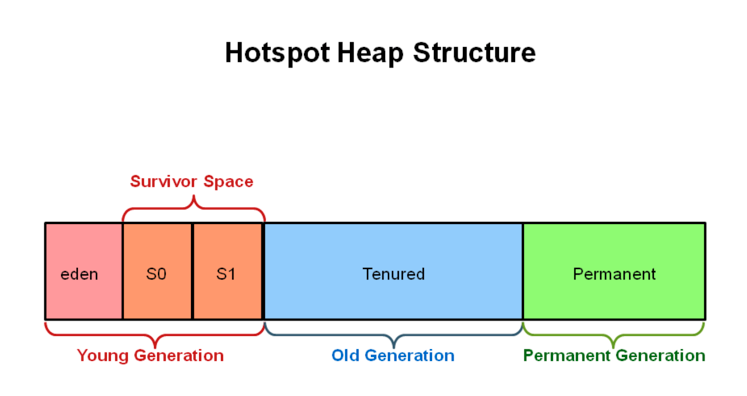
4.3.1 最大堆和初始堆的设置
当 Java 进程启动的时候,虚拟机就会分配一块初始堆空间,可以用使用 -Xms 来指定这块空间的大小,一般来说,虚拟机会尽可能维持在初始堆空间的范围内运行,但是如果初始堆空间耗尽,虚拟机就会对堆空间进行扩展,其扩展上限就是最大堆空间,可以用 -Xmx 指定。
// -Xmx20m -Xms5m -XX:+PrintCommandLineFlags -XX:+PrintGCDetails -XX:+UseSerialGCpublic class GetHeapDetails {public static void main(String[] args) {System.out.println("maxMemory = " + Runtime.getRuntime().maxMemory() + "bytes");System.out.println("freeMemory = " + Runtime.getRuntime().freeMemory() + "bytes");System.out.println("totalMemory = " + Runtime.getRuntime().totalMemory() + "bytes");byte[] b = new byte[2 * 1024 * 1024];System.out.println("分配了 2M 空间给数组");System.out.println("maxMemory = " + Runtime.getRuntime().maxMemory() + "bytes");System.out.println("freeMemory = " + Runtime.getRuntime().freeMemory() + "bytes");System.out.println("totalMemory = " + Runtime.getRuntime().totalMemory() + "bytes");b = new byte[5 * 1024 * 1024];System.out.println("分配了 5M 空间给数组");System.out.println("maxMemory = " + Runtime.getRuntime().maxMemory() + "bytes");System.out.println("freeMemory = " + Runtime.getRuntime().freeMemory() + "bytes");System.out.println("totalMemory = " + Runtime.getRuntime().totalMemory() + "bytes");}}
Q: GC 日志中 XX:MaxHeapSize=20971520 与 maxMemory = 20316160bytes 不一致的原因?
A: 最大内存正好是 20 * 1024 * 1024 = 20971520,而打印出来的最大可用内存仅为 20316160,原因在于分配给堆内存空间和实际可用内存空间并不是一个概念,由于垃圾回收需要,虚拟机会对堆空间进行进行分区管理,不同区域采用不同算法,一些算法会使用空间换时间的策略,这样会造成可用内存的损失。注意实际最大可用内存为-Xmx的值减去from的大小(可能会更小),因此需要区分最大堆和可用堆的区别。
4.3.2 新生代的配置
参数 -Xmn 可以用于设置新生代的大小,设置一个较大的新生代会减少老年代的大小,这个参数对系统性能以及 GC 行为会有很大的影响,因此在设置的时候需要谨慎考虑。新生代的大小一般设置为整个堆空间的1/3到1/4左右。
参数 -XX:SurvivorRatio 用来设置新生代中 eden 空间和 from/to 空间的比例关系。其中 -XX:SurvivorRatio=eden/from=eden/to。
// -Xmx20m -Xms20m -Xmn1m -XX:SurvivorRatio=2 -XX:+PrintGCDetails -XX:+UseSerialGC// -Xmx20m -Xms20m -Xmn7m -XX:SurvivorRatio=2 -XX:+PrintGCDetails -XX:+UseSerialGC// -Xmx20m -Xms20m -Xmn15m -XX:SurvivorRatio=8 -XX:+PrintGCDetails -XX:+UseSerialGCpublic class NewGenDetails {public static void main(String[] args) {byte[] b = null;for (int i = 0; i < 10; i++) {b = new byte[1 * 1024 * 1024];}}}
第一组参数下 eden 区是无法容纳任何一个程序中的分配的 1MB 的数组,故触发了一次新生代 GC,对 eden 区进行了部分回收,同时,这个偏小的新生代无法为 1MB 数组预留空间,所以所有的数组都分配在老年代,老年代最终占据了 10MB 的空间。
第二组参数下,eden 区有足够的空间,因此所有的数组都首先分配到 eden 区,但又不足以预留全部 10MB 的空间,故在程序运行期间,出现了3次新生代 GC。由于程序中每申请一次空间,也同时废弃了上一次申请的内存(上次申请的内存失去了引用),所以在新生代 GC 中,有效回收了这些失效的内存,最终结果就是所有的内存分配都在新生代进行,通过 GC 保证了新生代有足够的空间,而老年代没有为这些数组预留任何空间,只是在 GC 过程中部分新生代对象晋升到老年代了。
第三组参数下,新生代使用 15MB 空间,其中 eden 区完全满足 10MB 数组的分配,因此所有分配行为都在 eden 直接进行,且没有触发任何 GC 行为,因此 from/to 和老年代的使用率都是0。
以上可以见,不同堆分布情况,对系统执行和 GC 都会有一定的影响。一般策略是尽可能把对象预留在新生代,减少老年代 GC 的次数。
另外可以设置 -XX:NewRatio=2 来代表老年代/新生代的内存比例。
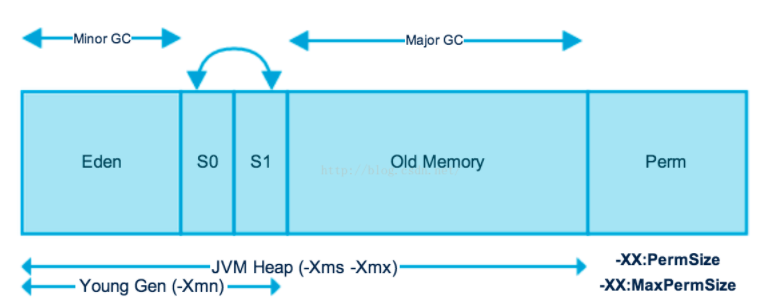
4.3.3 堆溢出处理
也称为内存溢出错误,OOM。如果发生在生产环境,可能会引起严重的业务中断,为了能够避免这类错误的发送,除了需要写代码的时候严谨一点,当发生错误的时候,也需要获得尽可能多的现场信息,来排查具体的问题。参数 -XX:+HeapDumpOnOutOfMemoryError,使用这个参数,可以在内存溢出的时候导出整个堆信息,配合使用的还有 -XX:HeapDumpPath,可以指定导出堆的存放路径。可以通过一些工具打开堆快照来查看对象分配的情况。
// -Xmx20m -Xms5m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/ShowOOM.dumppublic class OutOfMemory {public static void main(String[] args) {Vector v = new Vector<>();for (int i = 0; i < 25; i++) {v.add(new byte[1 * 1024 * 1024]);}}
4.4 了解非堆内存的参数配置
虚拟机还有一些内存用于方法区、线程区和直接内存的使用。它们与堆内存是相对独立的,虽然和堆内存相比,这些内存空间和应用程序可能关系不那么密切,但是从系统层面上合理、有效地配置内存参数,对系统性能和稳定性也有重要的作用。
4.4.1 方法区配置
回顾一下内存模型图
同 Java 堆一样,方法区也是全局共享的一块内存区域。方法区的作用是存储 Java 类的结构信息,当我们创建对象实例后,对象的类型信息存储在方法堆之中,实例数据存放在堆中;实例数据指的是在 Java 中创建的各种实例对象以及它们的值,类型信息指的是定义在 Java 代码中的常量、静态变量、以及在类中声明的各种方法、方法字段等等;同时可能包括即时编译器编译后产生的代码数据。
JDK 1.6 和 1.7 可以使用 -XX:PermSize 和 -XX:MaxPermSize 配置永久区的大小,其中前者是初始化的永久区大小,而后者则是表示最大永久区(与堆大小的控制参数很像)。而在 JDK 1.8 中,永久区被彻底移除,使用了新的元数据区存放类的元数据,默认情况下,元数据区只受系统可用内存的限制,但依然可以使用参数 -XX:MaxMetaspaceSize 指定永久区最大可用值。
// -XX:PermSize=5m -XX:MaxPermSize=5m// -XX:MaxMetaspaceSize=2mpublic class PermSize {public static void main(String[] args) {List list = new ArrayList();int i = 0;while (true) {list.add((String.valueOf(i++)).intern());}}}
Q: 为什么需要了解方法区?
A: 一个大的永久区可以保存更多的类信息,如果系统使用一些动态代理的技术,那么有可能会在运行的过程中生成大量的类,如果这样,就需要设置一个合理的永久区大小,确保不发生永久区内存溢出。方法区溢出也是一种常见的内存溢出异常,一个类如果要被垃圾收集器回收掉,判定条件是非常苛刻的。在经常动态生成大量 Class 的应用中,需要特别注意类的回收状况。
4.4.2 栈配置
栈是每个线程私有的内存空间。在 Java 虚拟机中可以使用 -Xss 参数指定线程的栈大小。以下程序可以显示,相同的栈容量下,局部变量少的函数,可以支持更深的函数调用。
// -Xss128K// -Xss256Kpublic class StackDeep {private static int count = 0;public static void recrusion(long a, long b, long c) {long e = 1, f = 2, g = 3, h = 4, i = 5, k = 6, q = 7, x = 8, y = 9, z = 10;count++;recrusion(a, b, c);}public static void recrusion() {count++;// recrusion();recrusion(0L, 0L, 0L);}public static void main(String[] args) {try {recrusion();} catch (Throwable e) {System.out.println("deep of calling = " + count);e.printStackTrace();}}}
4.4.3 直接内存配置
Q: 什么时候用直接内存?
A: 读写频繁的场合,出于性能考虑,可以考虑使用直接内存。
直接内存也是 Java 程序中非常重要的组成部分,特别是 NIO 被广泛使用之后,直接内存可以跳过 Java 堆,使 Java 程序可以直接访问原生堆空间。因此可以在一定程度上加快内存的访问速度。直接内存可以用 -XX:MaxDirectMemorySize 设置,默认值为最大堆空间,也就是 -Xmx。当直接内存达到最大值的时候,也会触发垃圾回收,如果垃圾回收不能有效释放空间,直接内存溢出依然会引起系统的 OOM。
而在访问读写上直接内存有较大优势,但是在内存空间申请的时候,直接内存毫无优势而言。
DirectAndHeapMemory.javaApplyMemory.java
因此结论是直接内存适合申请次数较少,访问频繁的场合。如果内存空间本身需要频繁申请,则不适合使用直接内存。
4.5 Client 和 Server 二选一
目前 Java 虚拟机支持 Client 和 Server 两种运行模式。使用参数 -client 可以指定使用 Client 模式,使用 -server 可以指定使用 Server 模式,默认情况下,虚拟机会根据当前系统自动选择模式。
➜ workspace java -versionjava version "1.8.0_121"Java(TM) SE Runtime Environment (build 1.8.0_121-b13)Java HotSpot(TM) 64-Bit Server VM (build 25.121-b13, mixed mode)lrz@uchadoop2:~/recommender-system$ java -versionjava version "1.8.0_111"Java(TM) SE Runtime Environment (build 1.8.0_111-b14)Java HotSpot(TM) 64-Bit Server VM (build 25.111-b14, mixed mode)
与 Client 模式相比,Server 模式启动比较慢,因为 Server 模式会尝试手机更多系统性能信息,使用更复杂的优化算法对程序进行优化。因此当系统完全启动并进入运行稳定期后,Server 模式的执行速度会远远快于 Client 模式。
5 JVM 垃圾回收算法简介
使用 Java 的程序员都知道,JVM 提供了全自动的内存管理方案,相较于 C/C++ 的手工内存管理,JVM 可以减少开发人员在内存资源管理方面的工作。
5.1 认识垃圾回收
GC 中的垃圾特指内存中,不会再被使用的对象,如果不及时回收这些无用的对象,当需要内存空间的时候就有可能无法使用内存了,最终导致内存溢出的问题。在 JVM 中开发人员只需要关注内存的申请,而内存的释放可以由系统自动识别和完成。
5.2 垃圾回收算法
5.2.1 引用计数法
介绍自动内存管理的科普文章可能会提到引用计数(reference-counting)方式,但现在主流的JVM无一使用引用计数方式来实现Java对象的自动内存管理。引用计数方式最基本的形态就是让每个被管理的对象与一个引用计数器关联在一起,该计数器记录着该对象当前被引用的次数,每当创建一个新的引用指向该对象时其计数器就加1,每当指向该对象的引用失效时计数器就减1。当该计数器的值降到0就认为对象死亡。每个计数器只记录了其对应对象的局部信息——被引用的次数,而没有(也不需要)一份全局的对象图的生死信息。由于只维护局部信息,所以不需要扫描全局对象图就可以识别并释放死对象;但也因为缺乏全局对象图信息,所以无法处理循环引用的状况。更高级的引用计数实现会引入“弱引用”的概念来打破某些已知的循环引用,作为最古老的垃圾回收算法,引用计数法有以下两个问题:
1. 无法处理循环引用的情况。
2. 每次引用产生和消除的时候伴随一个加法或者减法操作。
作者:RednaxelaFX
链接:https://www.zhihu.com/question/21539353/answer/18596488
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
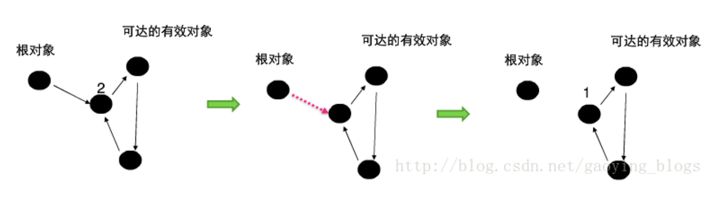
5.2.2 标记清除法
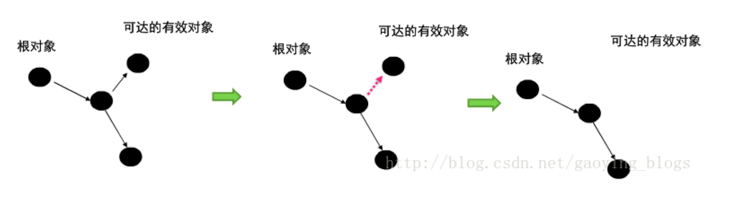
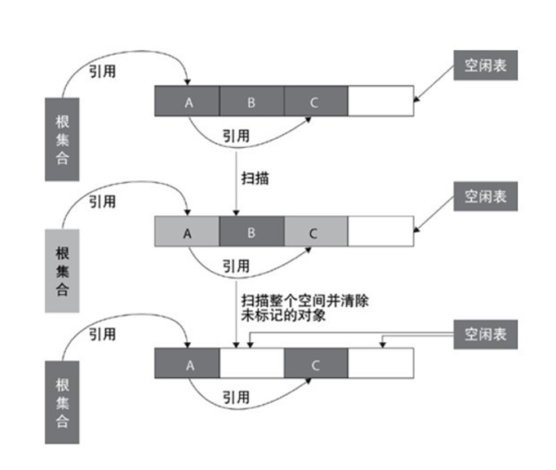
标记清除算法是现代垃圾回收算法的思想基础。标记清除算法把回收分为两个阶段,标记阶段和清除阶段。在标记阶段通过根节点,标记所有从根节点开始的可达对象,因此未被标记的对象就是未被引用的垃圾对象,然后在清除阶段清除所有未被标记的对象。
这样会导致空间碎片的问题,而对于大对象的内存分配,不连续的内存空间的工作效率要低于连续的空间。
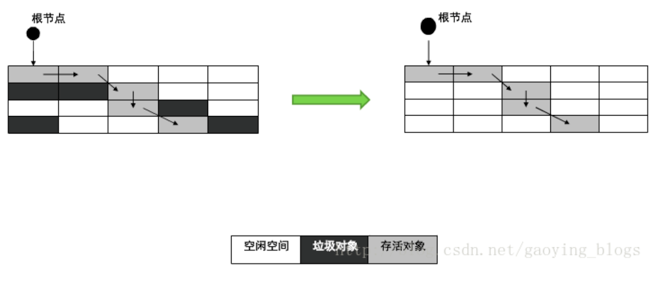
5.2.3 复制算法
其核心是把原有的内存空间分为两块,每次只使用其中一块,GC 过程中先把存活对象复制到另一块中,然后进行回收,最后交换角色。
这样的好处在于,如果系统的垃圾对象很多,复制算法需要复制的存活对象数量就相对比较少。复制算法的的存活对象相对较少,复制的效率比较高,然后又可以减少空间碎片的情况。但是复制算法的代价在于会把系统内存折半,这就是所谓的空间换时间,所以单纯的复制算法是难以让人接受的。
其中 Java 的新生代串行垃圾回收器中使用了复制算法的新思想,新生代分为 eden 空间、from 空间、to 空间3个部分。其中 from 和 to 空间可以视为用于复制的两块大小相同、地位相等可以角色互换的空间块。也合称 survivor 空间,存放未被回收的对象。
在垃圾回收的时候,eden 区和正在使用的 survivor 空间的存活对象都会复制到 survivor 空间未被使用的空间,然后就可以进行垃圾回收了,既保证了空间的连续性也避免了大量的内存空间浪费。
回顾一下,为什么分配的最大堆空间和实际可用最大堆空间会不相等
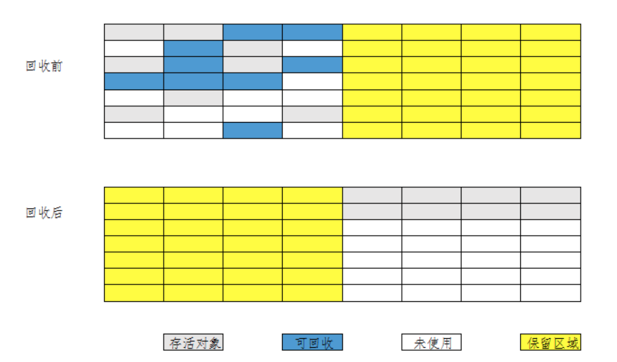
5.2.4 标记压缩法
复制算法的高效是建立在存活对象少、垃圾对象多的前提下,这种情况在新生代经常发生,但是在老年代更常见的情况是大部分对象都是存活对象,如果依然使用复制算法的话,复制成本会很高。
标记压缩法主要应用在老年代中,与标记清除算法一样,会对可达对象做一次标记,然后会把所有的存活对象压缩到内存的一端,之后再进行清除,这样的方法避免了碎片产生,也避免了浪费内存空间。

5.2.5 分代算法
以上算法并没有一种可以完全代替其他算法,都个子具有自身的优势和特点,因此根据垃圾回收对象的特性,使用合适的算法回收,才是明智的选择。
分代算法就是基于这种思想,将内存区间根据对象的特点分为几块,根据每块内存区间的特点来使用不同的算法,才能有效提高垃圾回收的效率(垃圾桶问题)。
新生代的对象「朝生夕灭」,大约90%的新建对象都会很快被回收,因此新生代适合复制算法。而老年代的对象存活率比较大,就适合使用标记压缩或者标记清除算法。
几乎所有的垃圾回收器都会区分新生代和老年代,对于新生代来说,回收的频率很高,但是耗时比较高,而对于老年代来说,回收频率会比较低,但会消耗更多的时间。
由于老年代也有可能会存放新生对象(较大的对象会直接进入老年代),因此 JVM 应该有一种数据结构来记录老年代的某一区域的所有对象是否持有新生代对象的引用。因此新生代 GC 的时候就不需要花大量时间来扫描所有老年代的对象了,大大加快了新生代的回收速度。
5.2.6 分区算法
把整个堆空间划分成连续的不同小区间,每个小区间都独立使用、独立回收,这样的好处在于可以控制一次回收多少空间,这是由于一般条件下,堆空间越大需要 GC 的时间就会越长,从而产生的停顿也会越长,而如果控制进行 GC 的空间,合理的安排,而不是一次回收整个堆空间,这样就可以减少 GC 产生的停顿了。
G1 回收器就是基于分区算法
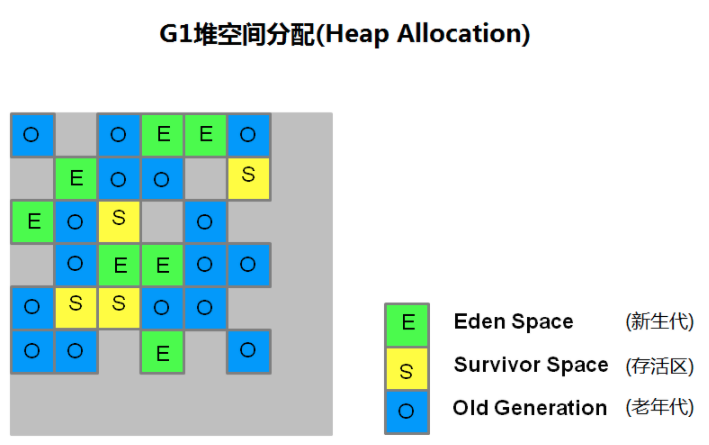
5.3 判断真正的垃圾
垃圾回收的基本思想是考察每一个对象的可触及性,即从根节点开始是否可以访问到这个对象,如果可以,则说明当前对象正在被使用,如果从所有的根节点都无法访问到某个对象,说明对象已经不再使用了,一般来说,此对象需要被回收。而有时候这些无法触及的对象有可能会在某个条件下复活自己,此时如果还回收他就显得不太合理了。
5.3.1 可触及性是什么
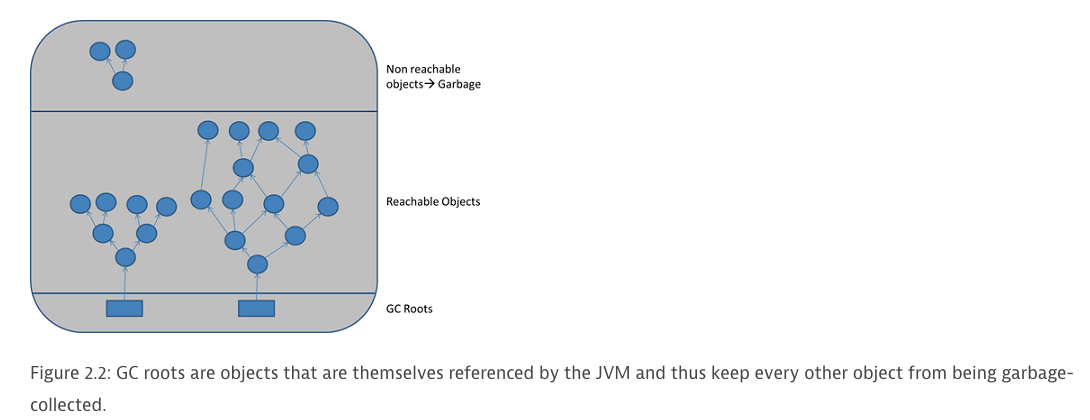
简单来说,可触及性可以包含以下3种状态:
1.可触及性:从根节点开始可以到达的这个对象
2.可复活性: 对象的所有引用都被释放,但是对象有可能在 finalize() 函数中复活
3.不可触及的:对象的 finalize() 函数被调用,并且没有复活,那么就会进入不可触及状态,不可触及状态的对象不可能被复活,因为 finalize() 函数只会被调用一次
public class CanReliveObj {public static CanReliveObj obj;@Overrideprotected void finalize() throws Throwable {super.finalize();System.out.println("CanReliveObj finalize called");obj = this;}@Overridepublic String toString() {return "I am CanReliveObj";}public static void main(String[] args) throws InterruptedException {obj = new CanReliveObj();obj = null;System.gc();Thread.sleep(1000);if (obj == null) {System.out.println("obj is null");} else {System.out.println("obj is alive");}System.out.println("gc again");obj = null;System.gc();Thread.sleep(1000);if (obj == null) {System.out.println("obj is null");} else {System.out.println("obj is alive");}}}
对于
finallize()函数引起的问题,推荐在 try-catch-finally 中进行资源释放
5.3.2 引用和可触及性的强度
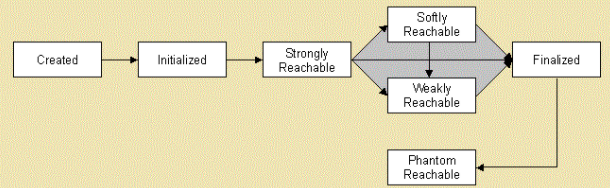
在 Java 中提供了4个级别的引用,强引用、软引用、弱引用和虚引用。
以下是强引用的一个例子 StringBuffer str = new StringBuffer("Hello World");
假设以上代码是在函数体内运行,那么局部变量 str 将分配在栈上的局部变量表里。而对象 StringBuffer 实例被分配在堆上,局部变量 str 指向 StringBuffer 实例所在堆空间,通过 str 可以操作该实例,那么 str 就是 StringBuffer 实例的强引用。
此时再有一个赋值语句 StringBuffer str1 = str; 那么 str 所指向的对象也会被 str1 所指向,同时在局部变量表上分配空间存放 str1 变量,此时,StringBuffer 实例就会有两个引用。需要记住的是,强引用有以下特点:
1.强引用可以直接访问目标对象
2.强引用所指向的对象在任何时候都不会被系统回收,虚拟机宁愿抛出 OOM 异常,也不会回收强引用所指向对象
3.强引用可能会导致内存泄漏
5.3.4 软引用,可以被回收的引用
一个对象只持有软引用,那么当堆空间不足的时候,就会被回收。
public class SoftRef {public static class User {public User(int id, String name) {this.id = id;this.name = name;}public int id;public String name;@Overridepublic String toString() {return "[id=" + String.valueOf(id) + ", name=" + name + "]";}}public static void main(String[] args) {User u = new User(1, "geym");SoftReference<User> userSoftRef = new SoftReference<User>(u);u = null;System.out.println(userSoftRef.get());System.gc();System.out.println("After GC:");System.out.println(userSoftRef.get());byte[] b = new byte[1024 * 1024 * 10];System.gc();System.out.println(userSoftRef.get());}}
5.3.5 弱引用,发现即回收
在系统 GC 时,只要发现弱引用,不管系统堆空间使用情况如何,都会把对象进行回收,但是由于垃圾回收期的线程优先级通常都比较低,因此并不一定能很快发现持有弱引用的对象,这种情况下,弱引用搞对象可以存放较长的时间。
5.3.6 虚引用,对象回收跟踪
一个持有虚引用的对象,和没有引用几乎是一样的。随时都可以被垃圾回收期回收。当试图通过虚引用的 get() 方法取得强引用的时候,总会失败。并且,虚引用必须和引用队列一起使用,它的作用在于跟踪垃圾回收过程。
当垃圾回收期准备回收一个对象,当发现还有虚引用个,就会在回收对象后,把这个虚引用加入引用队列,以通知应用程序对象的回收情况。
5.3.7 垃圾回收的停顿现象
垃圾回收器的任务是识别和回收垃圾对象进行内存清理,为了让垃圾回收器可以正常高效执行,大部分情况下,会要求系统进入一个停顿的状态。停顿的目的是终止所有应用线程的执行,只有这样,系统才不会继续有新的垃圾产生。同时保证了系统状态在某一个瞬间的一致性,也有益于垃圾回收器更好的标记垃圾对象,因此在垃圾回收时,都会产生应用程序的停顿,这个时候整个应用程序都会被卡死,没有任何响应,因此也叫 Stop The World。
// -Xmx1g -Xms1g -Xmn512k -XX:+UseSerialGC -Xloggc:gc.log -XX:+PrintGCDetailspublic class StopTheWorld {public static class MyThread extends Thread {HashMap map = new HashMap();@Overridepublic void run() {try {while (true) {if (map.size() * 512 / 1024 / 1024 >= 900) {map.clear();System.out.println("clean map");}byte[] b1;for (int i = 0; i < 100; i++) {b1 = new byte[512];map.put(System.nanoTime(), b1);}Thread.sleep(1);}} catch (Exception e) {}}}public static class PrintThread extends Thread {public static final long starttime = System.currentTimeMillis();@Overridepublic void run() {try {while (true) {long t = System.currentTimeMillis() - starttime;System.out.println(t / 1000 + "." + t % 1000);Thread.sleep(100);}} catch (Exception e) {}}}public static void main(String[] args) {MyThread t = new MyThread();PrintThread p = new PrintThread();t.start();p.start();}}
6 垃圾收集器和内存分配
在 Java 虚拟机中,垃圾回收器不止一种,什么情况下用哪种,对性能会产生什么影响,都是需要了解的。
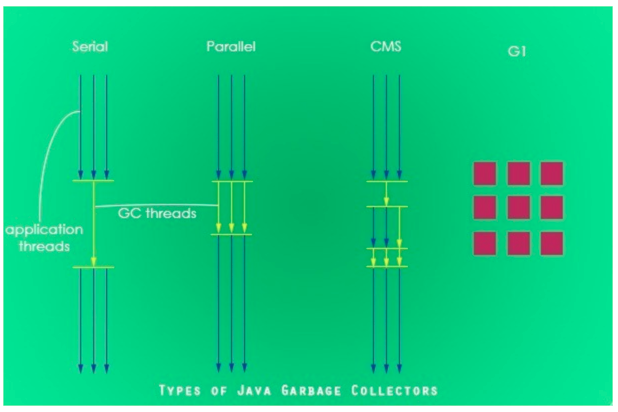
6.1 串行回收器
使用单线程进行垃圾回收的回收器。回收的时候,只有一个工作线程,对于并行能力比较弱的计算机来说,串行回收器的专注和独占性会有更好的表现。串行回收器可以在新生代和老生代使用,根据作用于不同的堆空间,分为新生代串行回收器和老生代串行回收器。
6.1.1 新生代串行回收器
串行回收器是最古老的一种垃圾回收器,也是 JDK 最基本的回收器之一,其两个主要特点是:
1. 仅仅使用单线程进行垃圾回收
2. 独占式垃圾回收
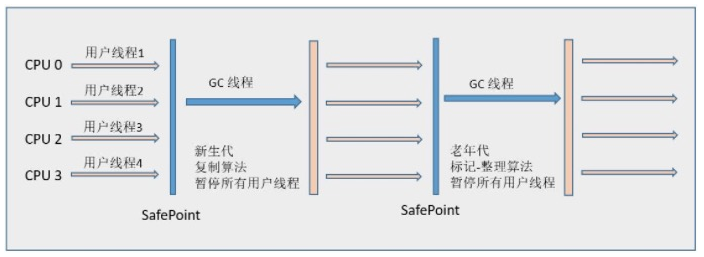
在串行收集器进行工作的时候,Java 应用程序中的线程都需要暂停,等待垃圾回收的完成。这种等待又称为 Stop-The-World,而在实时敏感的场景中是不可接受的。
-XX:+UseSerialGC 参数可以指定使用新生代串行收集器和老年代串行收集器,当在 Client 模式下进行的时候,它是默认的垃圾回收器。
6.1.2 老年代串行回收器
老年代串行收集器使用标记压缩算法,由于老年代回收通常比新生代回收时间更长,一旦老年代串行收集器启动,应用程序可能会因此停顿较长时间。
-XX:+UseSerialGC 参数表示新、老年代都使用串行收集器。
-XX:+UseParNewGC 新生代使用 ParNew 回收器,老年代使用串行回收器。
-XX:+UseParallelGC 新生代使用 ParallelGC 回收器,老年代使用串行收集器。
6.2 并行回收器

使用多个线程同时进行垃圾回收,对于并行能力强的计算机,可以有效缩短垃圾回收的实际时间。
6.2.1 新生代 ParNew 回收器
这是一个工作在新生代的垃圾回收器,将串行回收器多线程化。开启 ParNew 回收器使用以下参数:
-XX:+UseParNewGC 新生代使用 ParNew 回收器,老年代使用串行回收器。
-XX:+UseConcMarkSweepGC 新生代使用 ParNew 回收器,老年代使用 CMS。
ParNew 回收器工作时的线程数量可以使用 -XX:ParallelGCThreads 参数指定,一般最好与 CPU 数量相当,避免过多的线程数,影响垃圾收集性能。默认情况下,当 CPU 数量小于8个时,ParallelGCThreads 的值等于 CPU 数量,当 CPU 数量大于8个时,ParallelGCThreads 的值等于 3 + ((5 * CPU_COUNT) / 8)。
6.2.2 新生代 ParallelGC 回收器
新生代 ParallelGC 回收器也是使用复制算法的收集器,与 ParNew 有很多相似之处,但是其有一个很重要的特点,就是非常关注系统的吞吐量。
新生代 ParallelGC 回收器可以使用以下参数启用
-XX:+UseParallelGC 新生代使用 ParallelGC 回收器,老年代使用串行回收器。
-XX:+UseParallelOldGC 新生代使用 ParallelGC 回收器,老年代使用 ParallelOldGC 回收器。
ParallelGC 提供两个重要的参数用于控制系统的吞吐量。
1. -XX:MaxGCPauseMillis: 设置最大的垃圾收集停顿时间,为一个大于0的整数,工作时候会调整 Java 堆大小或者其他一些参数,尽可能地把停顿时间控制在参数设置以内,如果希望减少停顿时间而把这个值设置很小,为了达到该值的停顿时间,虚拟机可能会使用一个较小的堆,因为一个小堆会比大堆回收更快,更导致垃圾回收变得非常频繁,从而增加了垃圾回收总时间,降低吞吐量。
2. -XX:GCTimeRatio: 设置吞吐量大小,为0-100之间的整数,加入值为 n,那么系统把花费不超过1/(1+n)的时间用于垃圾回收。
此外他与 ParNew 回收器还有不同之处在于还支持一种自适应的 GC 调整策略,-XX:+UseAdaptiveSizePolicy 可以打开,这种模式下,新生代的大小、eden 和 survivor 的比例、晋升老年代的对象年龄等参数会被自动调整,以达到在堆大小、吞吐量和停顿之间的平衡点。这在手工调优比较困难的情况下,可以直接使用这种自适应的方式,仅指定虚拟机的最大堆、目标吞吐量和停顿时间,让虚拟机可以自行完成调优的工作。
6.2.3 老年代 ParalleOldGC 回收器
老年代 ParallelOldGC 回收器也是一种多线程并发的收集器,和新生代 ParallelGC 回收器一样,也是一种关注吞吐量的收集器。使用标记压缩算法(似乎只有 JDK 1.6 才有?)。
-XX:+UserParallelOldGC 可以在新生代使用 ParallelGC 回收器,老年代使用他,这是一对非常关注吞吐量的垃圾回收器组合,对吞吐量敏感的系统中可以考虑使用。(通过 -XX:ParallelGCThreads 可以用于设置垃圾回收时的线程数量)
6.3 CMS 回收器
主要关注系统停顿时间,CMS 也是 Concurrent Mark Sweep 的缩写,表示并发标记清除,使用的也就是标记清除算法,同时也是一个使用多线程并行回收的垃圾回收器。
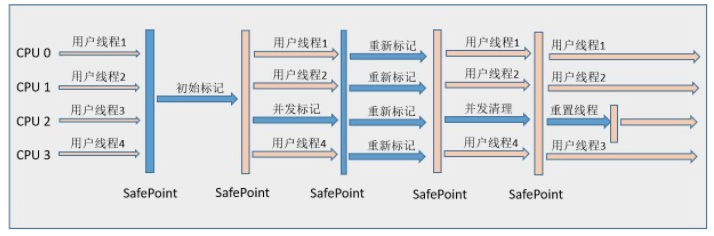
6.3.1 CMS 主要工作步骤
与其他垃圾回收器相比,其工作步骤稍显复杂,初始标记、并发标记、预清理、重新标记和并发重置。其中初始标记和重新标记独占系统资源,而其他是可以和用户线程一起执行的。从整体上说,CMS 收集不是独占式的,可以在应用程序运行过程中进行垃圾回收。
初始标记 -> 并发标记 -> 预清理 -> 重新标记 -> 并发清理 -> 并发重置
初始标记(CMS initial mark): 仅仅只是标记一下GC Roots能直接关联到的对象,速度很快,需要“Stop The World”。
并发标记(CMS concurrent mark): 进行GC Roots Tracing的过程,在整个过程中耗时最长。
重新标记(CMS remark): 为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段稍长一些,但远比并发标记的时间短。此阶段也需要“Stop The World”。
并发清除(CMS concurrent sweep)
6.3.2 CMS 主要的设置参数
-XX:+UseConCMarkSweepGC 是启动参数。
-XX:ParallelGCThreads 是指 GC 并行时使用的线程数量。CMS 启动的默认并发线程是 (ParallelGCThreads+3)/4,如果新生代使用 ParNew,那么 ParallelGCThreads 就是新生代 GC 的线程数量,意味着4个 ParallelGCThreads 只有1个并发线程,而两个并发线程时,有5-8个 ParallelGCThreads 线程数。
6.4 G1 回收器
在 G1 中,堆被划分成许多个连续的区域(region)。每个区域大小相等,在 1M~32M 之间。JVM 最多支持2000个区域,可推算 G1 能支持的最大内存为 2000*32M=62.5G。区域(region)的大小在 JVM 初始化的时候决定,也可以用 -XX:G1HeapReginSize 设置。
在 G1 中没有物理上的 Yong(Eden/Survivor)/Old Generation,它们是逻辑的,使用一些非连续的区域(Region)组成的。
此时应该回顾一下内存模型图......
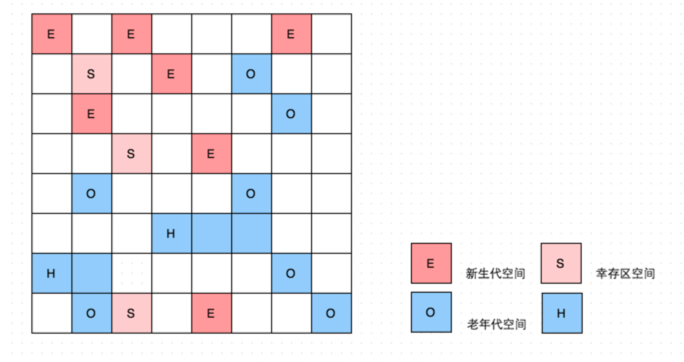
在上图中,我们注意到还有一些 region 标明了H,它代表 Humongous,这表示这些 region 存储的是巨大对象(humongous object,H-obj),即大小大于等于 region 一半的对象。
G1 提供了两种 GC 模式,Young GC 和 Mixed GC,两种都是完全 Stop The World 的。
6.5 有关对象内存分配和回收的一些细节问题
6.5.1 禁用 System.gc()
默认情况下,System.gc() 会显示直接出发 Full GC,同时对老年代和新生代进行回收。频繁出发垃圾回收对系统性能是没有好处的,因此可以通过参数 DisableExplicitGC 来控制手工触发。
6.5.2 对象何时进入老年代
对象先在 eden 区落脚
在堆中分配的对象首先会被安置在 eden 区,如果没有 GC 介入,对象是不会离开 eden的。
// -Xmx64M -Xms64M -XX:+PrintGCDetailspublic class AllocEden {public static final int _1K = 1024;public static void main(String[] args) {for (int i = 0; i < 5 * _1K; i++) {byte[] b = new byte[_1K];}}}
从日志看,整个过程没有 GC 发生,除了 eden 区都没有使用。
老年对象进入老年代
当对象的年龄达到一定的大小,就自然可以离开年轻代,进入老年代,一般可以把对象进入老年代的事件,称为晋升。对象的年龄是由对象经历的 GC 次数决定的,对象如果经历一次 GC,如果没有被回收,年龄就要加1,虚拟机提供了一个参数来限制新生代对象的最大年龄,MaxTenuringThreshold。
// -Xmx1024M -Xms1024M -XX:+PrintGCDetails -XX:MaxTenuringThreshold=15 -XX:+PrintHeapAtGCpublic class MaxTenuringThreshold {public static final int _1M = 1024 * 1024;public static final int _1K = 1024;public static void main(String[] args) {Map<Integer, byte[]> map = new HashMap<>();for (int i = 0; i < 5 * _1K; i++) {byte[] b = new byte[_1K];map.put(i, b);}for (int k = 0; k < 17; k++) {for (int i = 0; i < 270; i++) {byte[] g = new byte[_1M];}}}}
需要知道的是,MaxTenuringThreshold 指的是最大晋升年龄,它是对象晋升老年代的充分非必要条件,年龄达到了肯定要晋升,而未达到年龄,通过虚拟机内部的运行机制,也是有可能晋升的。
大对象直接进入老年代
除了年龄外,对象的体积也会影响对象的晋升。比如说对象体积很大,新生代无论是 eden 区还是 survivor 区都无法直接容纳这个对象,自然这个对象就没办法存放在新生代中,因此由于体积太大,也是有可能直接晋升到老年代的。
另外 PretenureSizeThreshold 用来设置对象直接晋升到老年代的阈值,单位是字节。只要对象的大于指定值,就会绕过新生代,直接在老年代进行分配。这个参数只对串行回收器和 ParNew 有效,对于 ParallelGC 无效,默认情况下为0,也就是不指定最大的已晋升大小,由运行情况决定。
7 JVM 监控工具
7.1 Linux 的性能监控工作
7.1.1 top 命令显示系统整体资源情况
top - 19:46:02 up 52 days, 8:18, 4 users, load average: 4.40, 5.24, 5.99Tasks: 47 total, 1 running, 44 sleeping, 1 stopped, 1 zombie%Cpu(s): 3.7 us, 1.4 sy, 0.0 ni, 94.4 id, 0.0 wa, 0.0 hi, 0.5 si, 0.0 stKiB Mem: 33554432 total, 475020 used, 33079412 free, 0 buffersKiB Swap: 0 total, 0 used, 0 free. 461060 cached MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND18841 carbon-+ 20 0 19.908g 2.343g 34372 S 0.3 7.3 132:35.50 java24669 logstash 20 0 10.910g 787856 13360 S 1.0 2.3 2035:11 java24821 chenfu 20 0 17.748g 768000 16680 S 0.0 2.3 4:30.73 java30680 chenfu 20 0 16.639g 745612 14512 S 0.7 2.2 4:48.02 java14805 lrz 20 0 15.676g 657736 20184 S 0.3 2.0 65:40.95 java16968 logstash 20 0 10.912g 614016 13684 S 0.3 1.8 228:35.42 java25496 lrz 20 0 19.798g 568580 23184 S 0.7 1.7 0:28.87 java25525 lrz 20 0 17.758g 519656 23136 S 0.0 1.5 0:19.69 java25457 lrz 20 0 25.317g 518352 23144 S 0.0 1.5 0:30.90 java19701 lrz 20 0 13.382g 489984 22948 S 0.0 1.5 0:23.46 java11530 chenfu 20 0 13.640g 461360 16236 S 0.3 1.4 21:33.88 java4913 kechao 20 0 316748 44736 4752 S 0.0 0.1 0:17.01 gunicorn8797 yzp 20 0 127328 25460 4724 T 0.0 0.1 0:00.36 pip31904 root 20 0 75036 17352 2804 S 0.0 0.1 0:07.11 gunicorn4902 kechao 20 0 87788 17148 2116 S 0.0 0.1 1:58.60 gunicorn16967 root 20 0 68328 12760 2036 S 0.0 0.0 4:58.22 python12535 root 20 0 51136 10728 2464 S 0.0 0.0 1:12.76 gunicorn19368 redis 20 0 40252 6668 1076 S 0.0 0.0 15:10.75 redis-server2479 yzp 20 0 54716 5672 2940 S 0.0 0.0 0:00.13 vim651 syslog 20 0 340104 5364 1096 S 0.0 0.0 0:25.28 rsyslogd11729 root 20 0 103584 4200 3224 S 0.0 0.0 0:00.01 sshd
top 命令分为两部分,上一半是系统统计信息,后半部分是进程信息。第一行是任务队列信息,等同于 uptime 命令,分别代表系统时间、系统运行时间、当前登录用户数。第二行是进程统计信息,分别有正在运行的进程数,睡眠进程数,停止的进程数和僵尸进程数。
然后是 CPU 统计信息,us 表示用户空间 CPU 占用率。再然后是内存统计信息,依次为物理内存总量、已经使用的物理内存、空闲的物理内存、内核缓冲使用了。再然后就是表示交换区总量、空闲交换区大小、换从交换区大小。
top 交互式命令
h 显示帮助画面,给出一些简短的命令总结说明k 终止一个进程。i 忽略闲置和僵死进程。这是一个开关式命令。q 退出程序r 重新安排一个进程的优先级别S 切换到累计模式o或者O改变显示项目的顺序l 切换显示平均负载和启动时间信息m 切换显示内存信息t 切换显示进程和CPU状态信息c 切换显示命令名称和完整命令行M 根据驻留内存大小进行排序P 根据CPU使用百分比大小进行排序T 根据时间/累计时间进行排序
7.1.2 vmstat 命令
vmstat 可以统计 CPU、内存使用情况,swap 使用情况等。当线程切换频繁的时候,用户 CPU 占用率会很高。
lrz@uchadoop2:~/recommender-system$ vmstat 1 3procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----r b swpd free buff cache si so bi bo in cs us sy id wa st5 0 0 33080288 0 461112 0 0 1 1957 0 0 3 1 96 0 05 0 0 33080288 0 461112 0 0 0 476 22015 20900 45 2 53 0 04 0 0 33080288 0 461112 0 0 0 196 34076 23962 45 1 53 0 0
7.2 JDK 性能监控工具
JDK 开发包其实有很多工具。
lrz@uchadoop2:~/recommender-system$ lt /opt/java8/bin/total 772-rwxr-xr-x 1 root 143 7965 9月 23 2016 appletviewerlrwxrwxrwx 1 root 143 8 9月 23 2016 ControlPanel -> jcontrol-rwxr-xr-x 1 root 143 7941 9月 23 2016 extcheck-rwxr-xr-x 1 root 143 7973 9月 23 2016 idlj-rwxr-xr-x 1 root 143 7925 9月 23 2016 jar-rwxr-xr-x 1 root 143 7957 9月 23 2016 jarsigner-rwxr-xr-x 1 root 143 7734 9月 23 2016 java-rwxr-xr-x 1 root 143 7941 9月 23 2016 javac-rwxr-xr-x 1 root 143 7941 9月 23 2016 javadoc-rwxr-xr-x 1 root 143 7941 9月 23 2016 javah-rwxr-xr-x 1 root 143 7941 9月 23 2016 javap-rwxr-xr-x 1 root 143 1809 9月 23 2016 java-rmi.cgi-rwxr-xr-x 1 root 143 128791 9月 23 2016 javaws-rwxr-xr-x 1 root 143 7925 9月 23 2016 jcmd-rwxr-xr-x 1 root 143 8013 9月 23 2016 jconsole-rwxr-xr-x 1 root 143 6264 9月 23 2016 jcontrol-rwxr-xr-x 1 root 143 7981 9月 23 2016 jdb-rwxr-xr-x 1 root 143 7941 9月 23 2016 jdeps-rwxr-xr-x 1 root 143 7941 9月 23 2016 jhat-rwxr-xr-x 1 root 143 8109 9月 23 2016 jinfo-rwxr-xr-x 1 root 143 7941 9月 23 2016 jjs-rwxr-xr-x 1 root 143 8109 9月 23 2016 jmap-rwxr-xr-x 1 root 143 7925 9月 23 2016 jps-rwxr-xr-x 1 root 143 7949 9月 23 2016 jrunscript-rwxr-xr-x 1 root 143 7981 9月 23 2016 jsadebugd-rwxr-xr-x 1 root 143 8109 9月 23 2016 jstack-rwxr-xr-x 1 root 143 7941 9月 23 2016 jstat-rwxr-xr-x 1 root 143 7941 9月 23 2016 jstatd-rwxr-xr-x 1 root 143 7941 9月 23 2016 keytool-rwxr-xr-x 1 root 143 7949 9月 23 2016 native2ascii-rwxr-xr-x 1 root 143 8149 9月 23 2016 orbd-rwxr-xr-x 1 root 143 7957 9月 23 2016 pack200-rwxr-xr-x 1 root 143 7997 9月 23 2016 policytool-rwxr-xr-x 1 root 143 7925 9月 23 2016 rmic-rwxr-xr-x 1 root 143 7941 9月 23 2016 rmid-rwxr-xr-x 1 root 143 7949 9月 23 2016 rmiregistry-rwxr-xr-x 1 root 143 7957 9月 23 2016 schemagen-rwxr-xr-x 1 root 143 7941 9月 23 2016 serialver-rwxr-xr-x 1 root 143 7965 9月 23 2016 servertool-rwxr-xr-x 1 root 143 8181 9月 23 2016 tnameserv-rwxr-xr-x 1 root 143 228933 9月 23 2016 unpack200-rwxr-xr-x 1 root 143 7941 9月 23 2016 wsgen-rwxr-xr-x 1 root 143 7957 9月 23 2016 wsimport-rwxr-xr-x 1 root 143 7957 9月 23 2016 xjc-rwxr-xr-x 1 root 143 2293 9月 23 2016 javafxpackager-rwxr-xr-x 1 root 143 2293 9月 23 2016 javapackager-rwxr-xr-x 1 root 143 402 2月 10 2015 jmc.ini-rwxr-xr-x 1 root 143 74675 2月 10 2015 jmc-rwxr-xr-x 1 root 143 5185 9月 10 2014 jvisualvm
7.2.1 jps 工具
jps 可以用来产看 Java 进程信息。
-l 列出类名-v 列出虚拟机参数-q 只列出 PID
7.2.2 jstat 工具
jstat 可以用于观察 Java 应用程序运行时相关信息的工具,可以通过它查看堆信息的详细情况。
lrz@uchadoop2:~$ jstat -gcutil -t -h5 25457 1000 10Timestamp S0 S1 E O M CCS YGC YGCT FGC FGCT GCT5464.6 98.33 0.00 74.12 6.85 97.85 93.60 4 0.221 2 0.237 0.4585465.6 98.33 0.00 74.12 6.85 97.85 93.60 4 0.221 2 0.237 0.4585466.6 98.33 0.00 74.12 6.85 97.85 93.60 4 0.221 2 0.237 0.4585467.6 98.33 0.00 74.12 6.85 97.85 93.60 4 0.221 2 0.237 0.4585468.8 98.33 0.00 74.12 6.85 97.85 93.60 4 0.221 2 0.237 0.458Timestamp S0 S1 E O M CCS YGC YGCT FGC FGCT GCT5469.8 98.33 0.00 74.12 6.85 97.85 93.60 4 0.221 2 0.237 0.4585470.8 98.33 0.00 74.12 6.85 97.85 93.60 4 0.221 2 0.237 0.4585471.8 98.33 0.00 74.12 6.85 97.85 93.60 4 0.221 2 0.237 0.4585472.8 98.33 0.00 74.12 6.85 97.85 93.60 4 0.221 2 0.237 0.4585473.8 98.33 0.00 74.12 6.85 97.85 93.60 4 0.221 2 0.237 0.458
7.2.3 jmap 工具
jmap 可以生产 Java 程序的堆 Dump 文件,也可以查看堆内对象实例的统计信息、查看 ClassLoader 的信息以及 finalizer 队列。
lrz@uchadoop2:~$ jmap -histo 25457 > ./jmap.txt# 输出文件num #instances #bytes class name----------------------------------------------1: 188087 79346544 [I2: 1289163 55029208 [C3: 339593 41043224 [B4: 477778 23184240 [Ljava.lang.Object;5: 765071 18361704 java.lang.String6: 595609 14294616 akka.dispatch.AbstractNodeQueue$Node7: 595451 14290824 akka.actor.LightArrayRevolverScheduler$TaskQueue8: 78845 6307184 [S9: 201393 4833432 java.lang.StringBuilder10: 63966 4093824 java.util.regex.Matcher11: 118547 3793504 scala.collection.immutable.HashMap$HashMap112: 149218 3581232 scala.Tuple213: 100775 3224800 java.util.HashMap$Node14: 86971 2923432 [Lscala.collection.immutable.HashMap;
以上例子可以看到输出显示了内存中的实例数量和合计。
分析 dump 出的堆文件后,使用 HTTP 服务器展示其分析结果。在浏览器中访问 localhost:7000。
➜ learning-jvm git:(master) ✗ jhat heap.hprofReading from heap.hprof...Dump file created Thu Jan 04 20:41:15 CST 2018Snapshot read, resolving...Resolving 7446178 objects...Chasing references, expect 1489 dots .....Eliminating duplicate references ....Snapshot resolved.Started HTTP server on port 7000Server is ready.
7.3 JVM 图形化分析工具
7.3.1 JConsole
JConsole 是 JDK 自带的图形化性能监督工具,通过 JConsole 可以查看 Java 应用程序的运行概括,可以监控堆空间,永久区使用的情况,类加载的情况。
7.3.2 VisualVM
VisualVM 是一个功能强大的多合一故障诊断和性能监控的可视化工具,集成了多重性能统计工具的功能,使用 VisualVM 可以代替 jstat, jmap, jhat, jstack 甚至代替 JConsole。
VisualVM 是一款免费的性能分析工具。它通过 jvmstat、JMX、SA(Serviceability Agent)以及 Attach API 等多种方式从程序运行时获得实时数据,从而进行动态的性能分析。同时,它能自动选择更快更轻量级的技术尽量减少性能分析对应用程序造成的影响,提高性能分析的精度。
VisualVM 插件中心提供很多插件以供安装向 VisualVM 添加功能。可以通过 VisualVM 应用程序安装,或者从 VisualVM 插件中心手动下载插件,然后离线安装。另外,用户还可以通过下载插件分发文件 (.nbm 文件 ) 安装第三方插件为 VisualVM 添加功能。
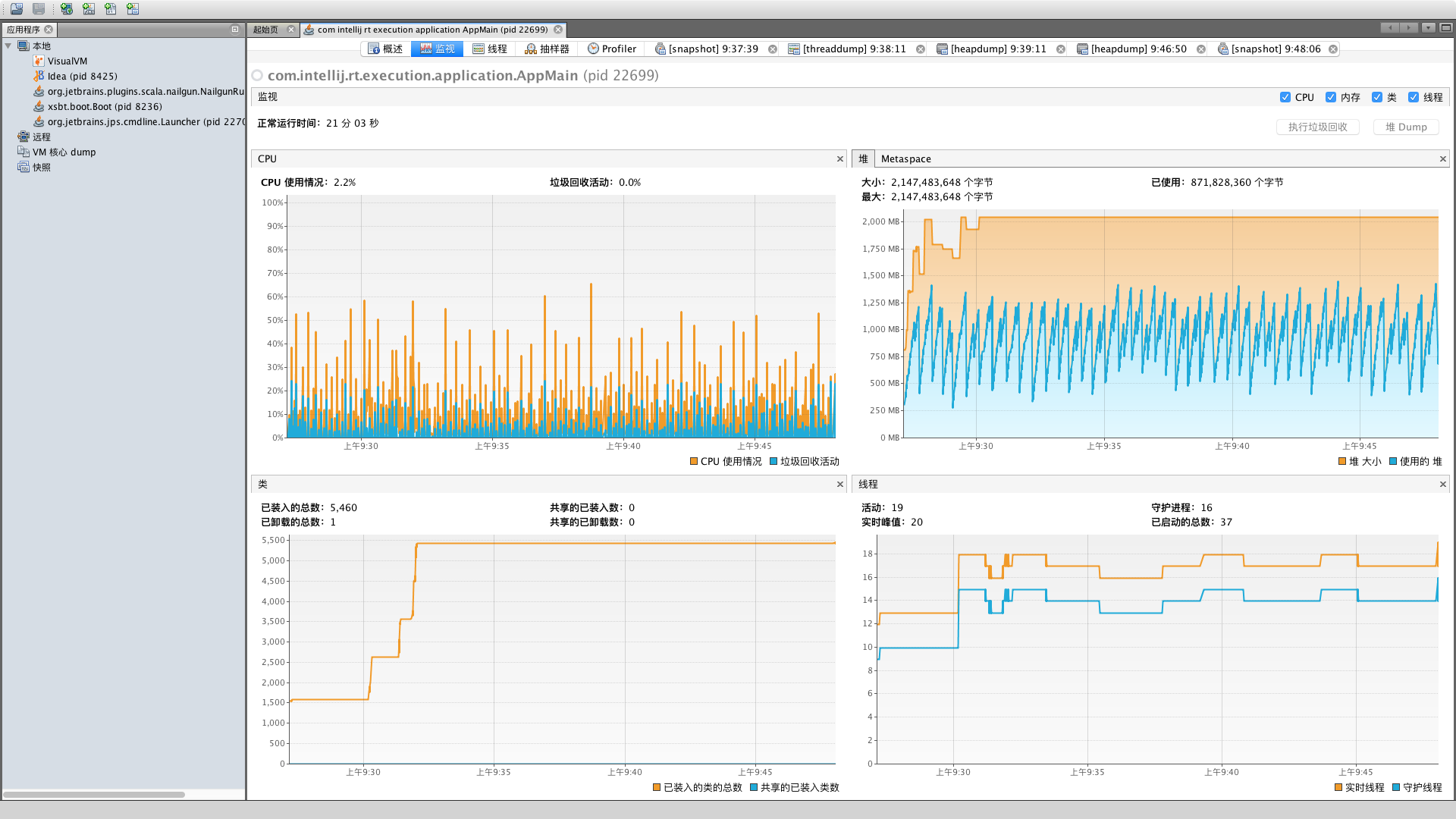
VisualVM 相关操作
内存分析
- 内存堆使用情况
- 永久保留区域使用情况
- 开启“在出现 OOME 时生成堆”功能
CPU 分析
- CPU 使用情况
- CPU 性能分析结果
线程分析
- 活跃线程情况
- 线程时间线视图
快照功能
- Profiler 快照
- 应用程序快照
转储功能
- 线程标签及线程转储功能
- 线程转储结果
堆转储的生成与分析
- 监视标签及堆转储功能
- 堆转储的摘要视图
- 堆转储的类视图
- 选择查询实例数的类
- 堆转储的比较
7.3.3 Mission Control
7.3.4 JProfiler
【未完待续】
