@sasaki
2016-05-25T02:55:46.000000Z
字数 16133
阅读 5879
大数据学习知识疏理及问题解决
BigData Hadoop Spark
版本控制
@Title 大数据学习知识疏理及问题解决@Version v1.0@Timestamp 2015-12-23 17:48@Author Nicholas@Mail redskirt@outlook.com
一、
二、问题解决
在HDFS中添加或修改文件时的root用户无权限问题:
# HDFS会使用和name node 相同的用户名,获取到所有文件的访问权限[root@master ~]# hadoop fs -mkdir /tempmkdir: Permission denied: user=root, access=WRITE, inode="/":hdfs:supergroup:drwxr-xr-x# 查看HDFS目录权限,可知root用户仅相当于访客[root@master ~]# hadoop fs -ls /Found 2 itemsdrwxrwxrwx - hdfs supergroup 0 2015-12-22 15:48 /tmpdrwxr-xr-x - hdfs supergroup 0 2015-12-23 17:41 /user# 使用超级用户hdfs在/user目录新建与系统用户名对应的文件夹,即新增一个用户[root@master ~]# sudo -uhdfs hadoop fs -mkdir /user/root# 更改root用户的权限[root@master ~]# sudo -uhdfs hadoop fs -chown root:root /user/root# 现在可在/user/root目录下进行文件操作[root@master ~]# hadoop fs -mkdir /user/root/temp
在Hadoop环境中运行MapReduce pi测试程序
[root@master ~]# hadoop jar /usr/application/tmp/hadoop-2.6.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar pi 100 100
测试Spark自带的计算Pi程序
在YARN上运行spark测试程序[root@master /]# cd /opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/lib/spark/bin[root@master bin]# ./spark-class org.apache.spark.deploy.yarn.Client --jar /usr/application/tmp/spark-1.3.1-bin-hadoop2.6/lib/spark-assembly-1.3.1-hadoop2.6.0.jar --class org.apache.spark.examples.SparkPi --args yarn-standalone --num-workers 3 --master-memory 512m --worker-memory 512m
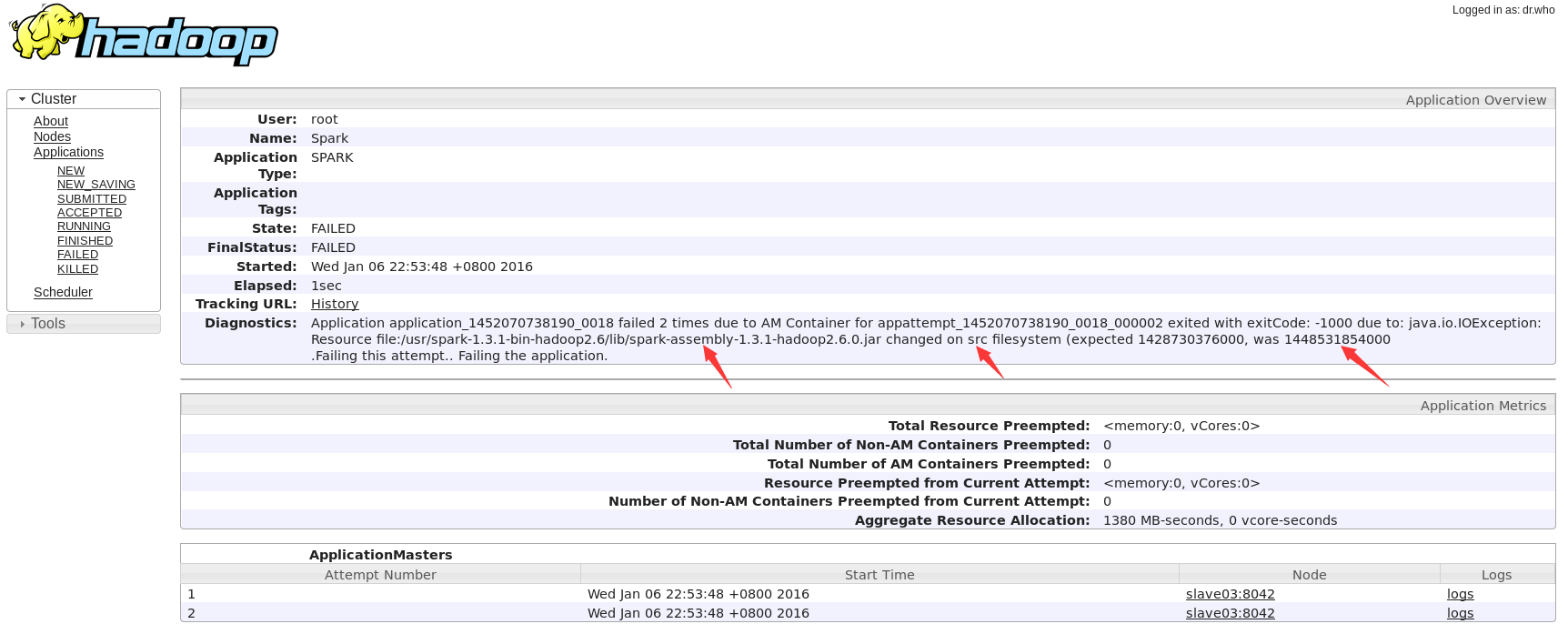
经查Log是如下异常,苦思冥想好长时间未解决:
Application application_1452070738190_0018 failed 2 times due to AM Container for appattempt_1452070738190_0018_000002 exited with exitCode: -1000 due to: java.io.IOException: Resource file:/usr/spark-1.3.1-bin-hadoop2.6/lib/spark-assembly-1.3.1-hadoop2.6.0.jar changed on src filesystem (expected 1428730376000, was 1448531854000.Failing this attempt.. Failing the application.
Log界面:
该问题经查应该是导入环境变量有误引起,查看变量如下:
[root@master lib]# cd /etc/spark/conf/[root@master conf]# ls__cloudera_generation__ log4j.properties spark-defaults.conf spark-env.sh[root@master conf]# cat spark-env.sh |grep -v '^#'|grep -v '^$'export SPARK_HOME=/opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/lib/sparkexport DEFAULT_HADOOP_HOME=/opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/lib/hadoopexport SPARK_JAR_HDFS_PATH=${SPARK_JAR_HDFS_PATH:-/user/spark/share/lib/spark-assembly.jar}export SPARK_LAUNCH_WITH_SCALA=0export SPARK_LIBRARY_PATH=${SPARK_HOME}/libexport SCALA_LIBRARY_PATH=${SPARK_HOME}/libexport HADOOP_HOME=${HADOOP_HOME:-$DEFAULT_HADOOP_HOME}if [ -n "$HADOOP_HOME" ]; thenexport LD_LIBRARY_PATH=$LD_LIBRARY_PATH:${HADOOP_HOME}/lib/nativefiexport HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-/etc/hadoop/conf}
发现最后一行是所设环境变量
[root@master hadoop]# pwd/etc/hadoop[root@master hadoop]# lltotal 12lrwxrwxrwx. 1 root root 29 Jan 5 23:35 conf -> /etc/alternatives/hadoop-confdrwxr-xr-x. 2 root root 4096 Dec 26 12:02 conf.cloudera.hdfsdrwxr-xr-x. 2 root root 4096 Dec 26 12:03 conf.cloudera.mapreducedrwxr-xr-x. 2 root root 4096 Jan 6 16:46 conf.cloudera.yarn
据教程中老师说的该目录实际是指向配置文件的一个软链,查看/etc/hadoop发现conf的确是指到一个为/etc/alternatives/hadoop-conf的其他目录,此处开始怀疑自己此前的人生Q_Q
于是又进入目录,查看文件顿时傻眼,/etc/alternatives目录下有200个文件全是软链。此刻终于发现我需要的hadoof-conf目录,然而该软链又链接到/etc/hadoop/conf.cloudera.yarn。[root@master alternatives]# pwd/etc/alternatives[root@master alternatives]# ll #文件过多就不完全列举total 200lrwxrwxrwx. 1 root root 30 Jan 5 23:35 hadoop-conf -> /etc/hadoop/conf.cloudera.yarn[root@master alternatives]# ll |grep hadoop-conflrwxrwxrwx. 1 root root 30 Jan 5 23:35 hadoop-conf -> /etc/hadoop/conf.cloudera.yarn
最后进入/etc/hadoop/conf.cloudera.yarn目录,终于发现里边“深藏的配置文件”,然而这里我并没有轻易尝试该目录。我想找到最原生的CDH部署的配置文件存放目录。
[root@master conf.cloudera.yarn]# pwd/etc/hadoop/conf.cloudera.yarn[root@master conf.cloudera.yarn]# ls__cloudera_generation__ hadoop-env.sh log4j.properties ssl-client.xml topology.pycore-site.xml hdfs-site.xml mapred-site.xml topology.map yarn-site.xml
想到上述步骤中用[root@master conf]# cat spark-env.sh |grep -v '^#'|grep -v '^$'命令查看到export DEFAULT_HADOOP_HOME=/opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/lib/hadoop,猜测原生的配置文件应该也存放在这里。
[root@master hadoop]# pwd/opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/lib/hadoop/etc/hadoop[root@master hadoop]# ls__cloudera_generation__ hadoop-env.sh log4j.properties ssl-client.xml topology.pycore-site.xml hdfs-site.xml mapred-site.xml topology.map yarn-site.xml
之后经尝试如下导入,运行测试程序终于没有再遇到同样异常
[root@master hadoop]# export HADOOP_CONF_DIR=/opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/lib/hadoop/etc/hadoop
处理后运行成功但是异常出缺org.apache.spark.examples.SparkPi这个类,找到原因是之前的提交代码给的 --jar错了,给的是spark-assembly-1.2.0-cdh5.3.8-hadoop2.5.0-cdh5.3.8.jar而不是spark-examples-1.2.0-cdh5.3.8-hadoop2.5.0-cdh5.3.8.jar,里边当然没有测试的类。

更换之,为了保险起见,在运行测试前不忘所有节点设置SPARK_JAR变量,为要提交至YARN上的Spark环境,此处因为跑的是CDH环境中的example,为避免不兼容我仍然导入CDH目录中的spark-assembly-1.2.0-cdh5.3.8-hadoop2.5.0-cdh5.3.8.jar。
[root@master hadoop]# SPARK_JAR=/opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/jars/spark-assembly-1.2.0-cdh5.3.8-hadoop2.5.0-cdh5.3.8.jar[root@master hadoop]# ./spark-class org.apache.spark.deploy.yarn.Client \--jar /opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/lib/spark/lib/spark-examples-1.2.0-cdh5.3.8-hadoop2.5.0-cdh5.3.8.jar \--class org.apache.spark.examples.SparkPi \--args yarn-standalone --num-workers 3 \--master-memory 512m --worker-memory 512m
终于可以顺利执行了,然而又爆出一个更奇葩的问题,竟然不识别yarn-standalone,提交的命令写法应该是对 的,经查也找不出这个问题所在。索性就把--args这个参数删掉再尝试。
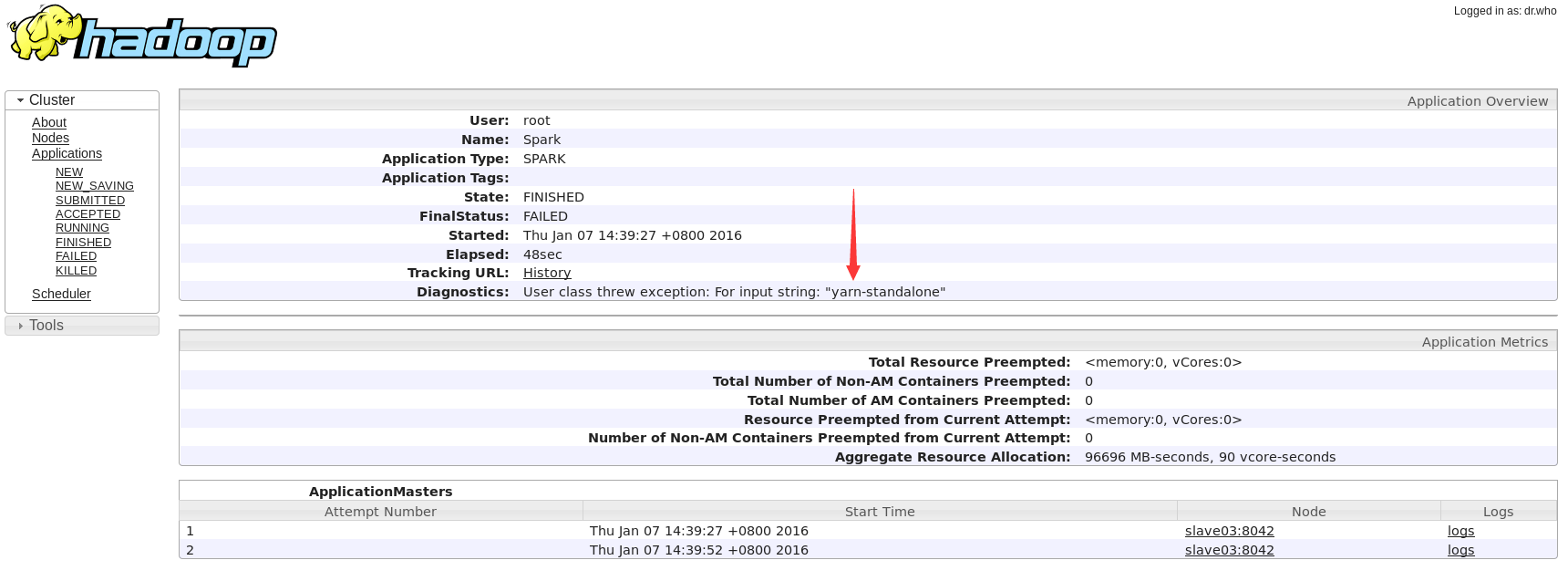
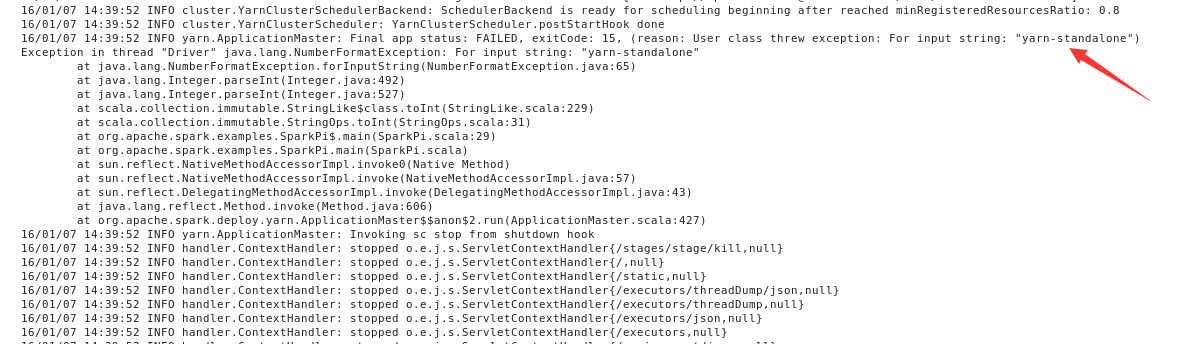
[root@master hadoop]# ./spark-class org.apache.spark.deploy.yarn.Client \--jar /opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/lib/spark/lib/spark-examples-1.2.0-cdh5.3.8-hadoop2.5.0-cdh5.3.8.jar \--class org.apache.spark.examples.SparkPi \--num-workers 3 \--master-memory 512m \--worker-memory 512m
这里一路畅通,看到最终结果,结果在Log最后一行:
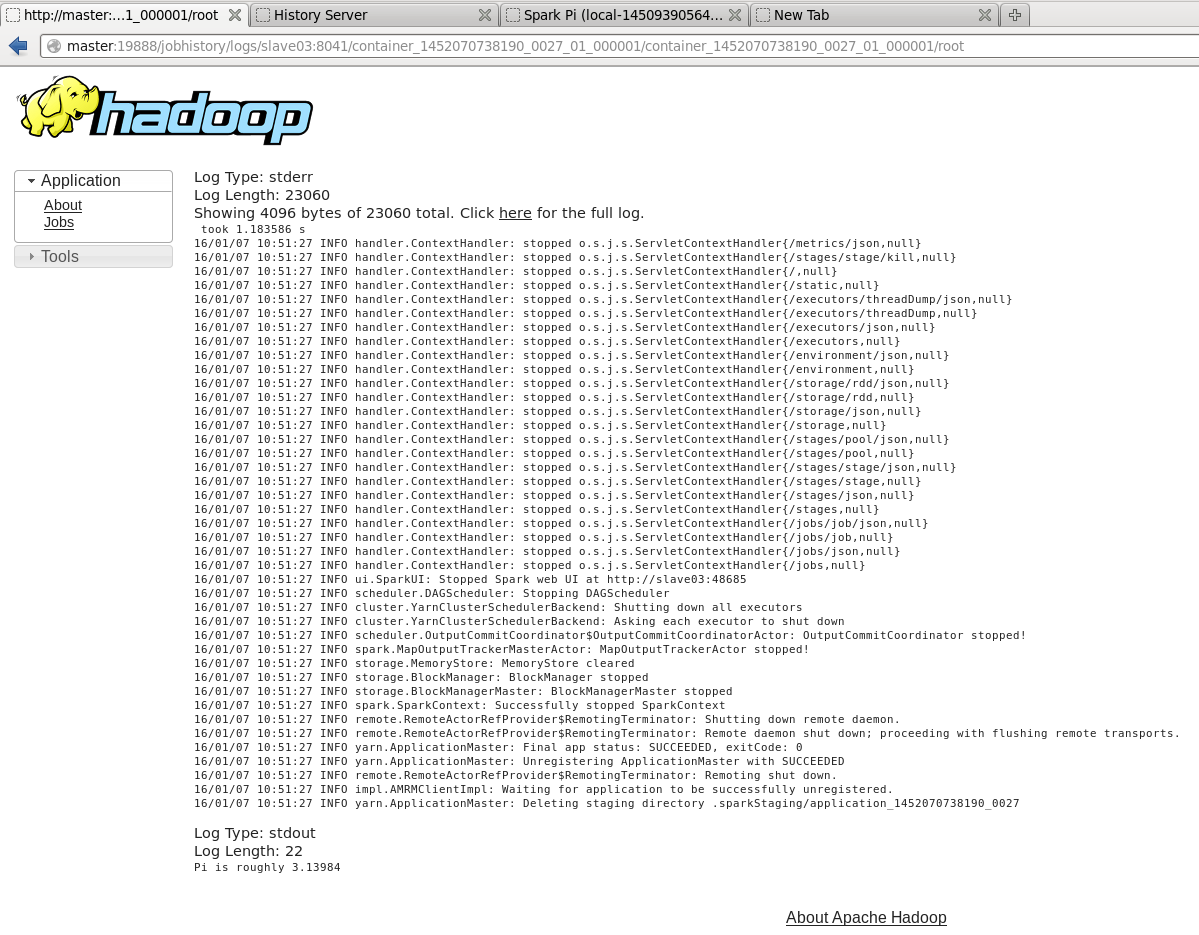
测试程序
[root@master ~]# spark-submit --class com.spark.test.NyTime --master \ yarn-cluster --executor-memory 512m --executor-cores 10 /usr/application/tmp/spark-yarn.jar hdfs://localhost:8020/user/root/wordcount/input/ hdfs://localhost:8020/user/root/wordcount/output
部署Kafka测试代码,Maven环境
因Nexus中下载Maven依赖有缺失,特更换OpenSource China的Maven仓库。<mirror><id>oschina</id><mirrorOf>*</mirrorOf><name>Human Readable Name for this Mirror.</name><url>http://maven.oschina.net/content/groups/public/</url></mirror>
后发现还有一个jdk.tools-*.jar的包缺失,本地repo目录中也不存在目录。
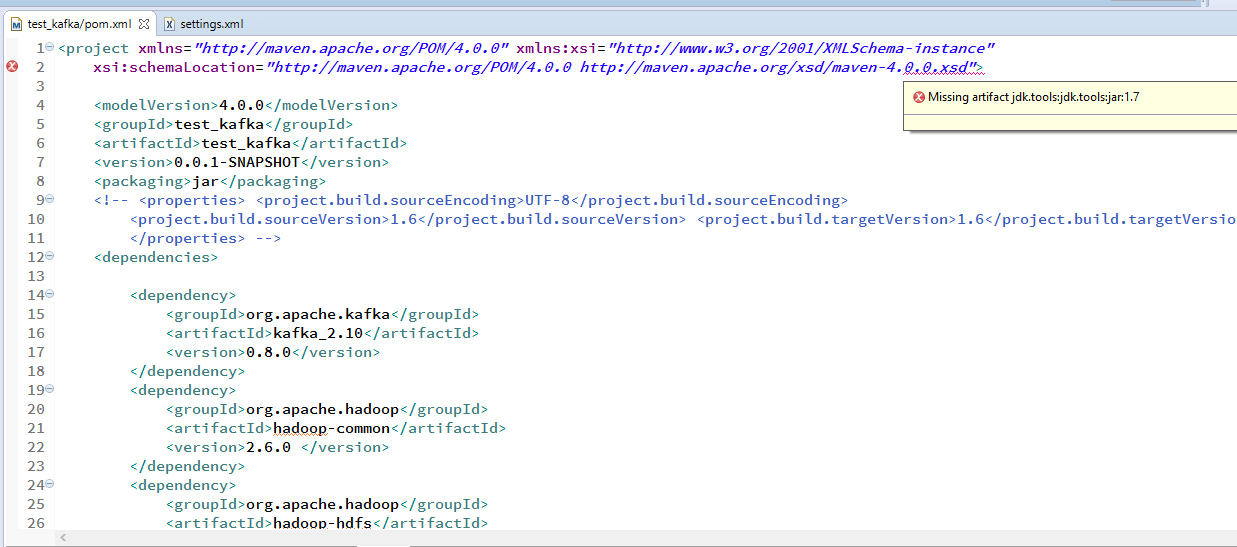
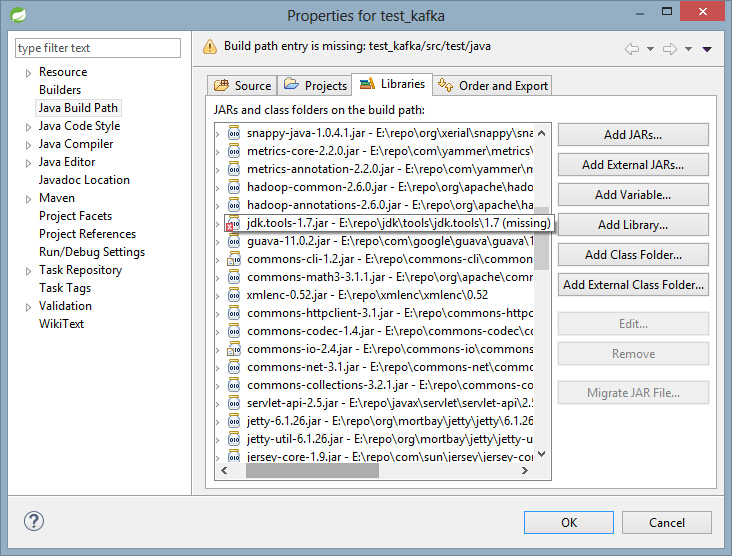
经查jdk.tools:jdk.tools是与JDK一起分发的一个JAR文件,可以如下方式加入到Maven项目中:
<dependency><groupId>jdk.tools</groupId><artifactId>jdk.tools</artifactId><version>1.7</version><scope>system</scope><systemPath>${JAVA_HOME}/lib/tools.jar</systemPath></dependency>
hive shell启动问题
CM中Hive服务启动完成,但是CLI中使用hive命令,时一直没有回应,也不报错,发现CM中Hive服务Hive Metastore Server有异常大概为不能创建测试的meterstore,经看Log怀疑是Hive没有mysql驱动jar文件,但是在初次安装过程中已经放入lib中了,可能是之后删除hive服务又会初始化Hive的lib,再次将jar文件放入/opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/lib/hive/lib/中,顺利进入hive CLI。[root@master hive]# pwd/var/log/hive[root@master hive]# cat hadoop-cmf-hive-HIVEMETASTORE-master.log.outCaused by: org.datanucleus.exceptions.NucleusException: Attempt to invoke the "BONECP" plugin to create a ConnectionPool gave an error : The specified datastore driver ("com.mysql.jdbc.Driver") was not found in the CLASSPATH. Please check your CLASSPATH specification, and the name of the driver.at org.datanucleus.store.rdbms.ConnectionFactoryImpl.generateDataSources(ConnectionFactoryImpl.java:259)at org.datanucleus.store.rdbms.ConnectionFactoryImpl.initialiseDataSources(ConnectionFactoryImpl.java:131)at org.datanucleus.store.rdbms.ConnectionFactoryImpl.<init>(ConnectionFactoryImpl.java:85)... 53 moreCaused by: org.datanucleus.store.rdbms.connectionpool.DatastoreDriverNotFoundException: The specified datastore driver ("com.mysql.jdbc.Driver") was not found in the CLASSPATH. Please check your CLASSPATH specification, and the name of the driver.at org.datanucleus.store.rdbms.connectionpool.AbstractConnectionPoolFactory.loadDriver(AbstractConnectionPoolFactory.java:58)at org.datanucleus.store.rdbms.connectionpool.BoneCPConnectionPoolFactory.createConnectionPool(BoneCPConnectionPoolFactory.java:54)at org.datanucleus.store.rdbms.ConnectionFactoryImpl.generateDataSources(ConnectionFactoryImpl.java:238)... 55 more
hive创建外部表问题
Hive创建外部表时hive> create external table test_sogo(time varchar(8), userid varchar(30), query string, pagerank int, clickrank int, site string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LOCATION 'hdfs://master:8020/user/root/sogo/SogouQ.reduced';
报错如下
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException(message:hdfs://master:8020/user/root/sogo/SogouQ.reduced is not a directory or unable to create one)gouQ.reduced';
可是确定
hdfs://master:8020/user/root/sogo/SogouQ.reduced文件确实存在。经查:location后面跟的是目录,不是文件,hive会把整个目录下的文件都加载到表中,否则就会找不到文件。
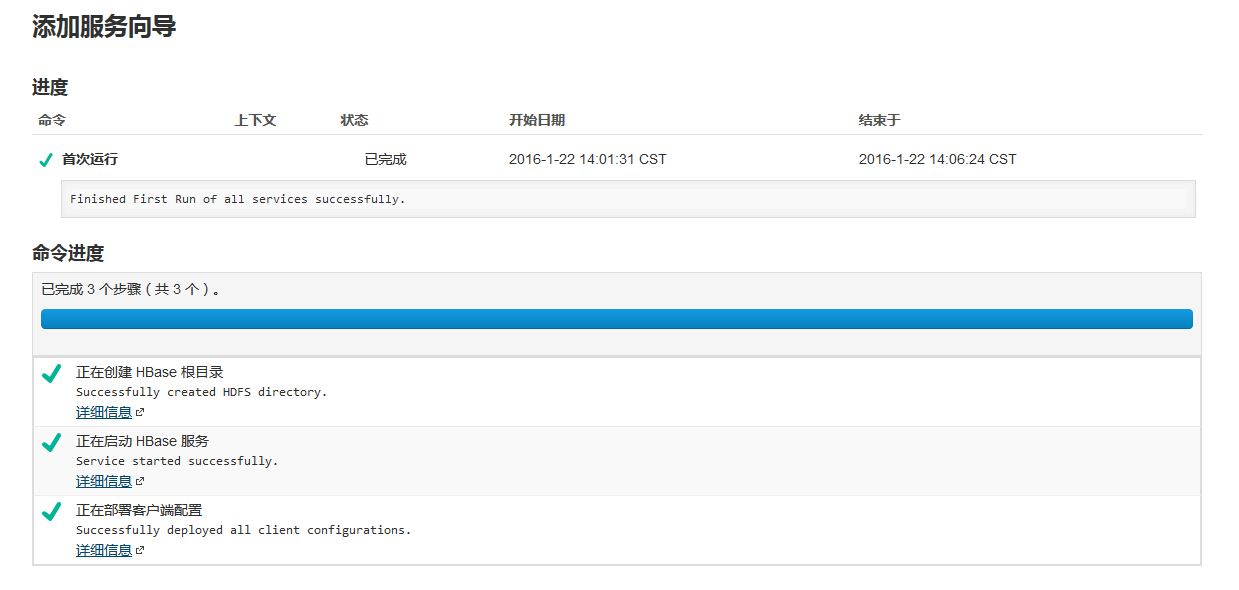
hbase启动时Master启动失败
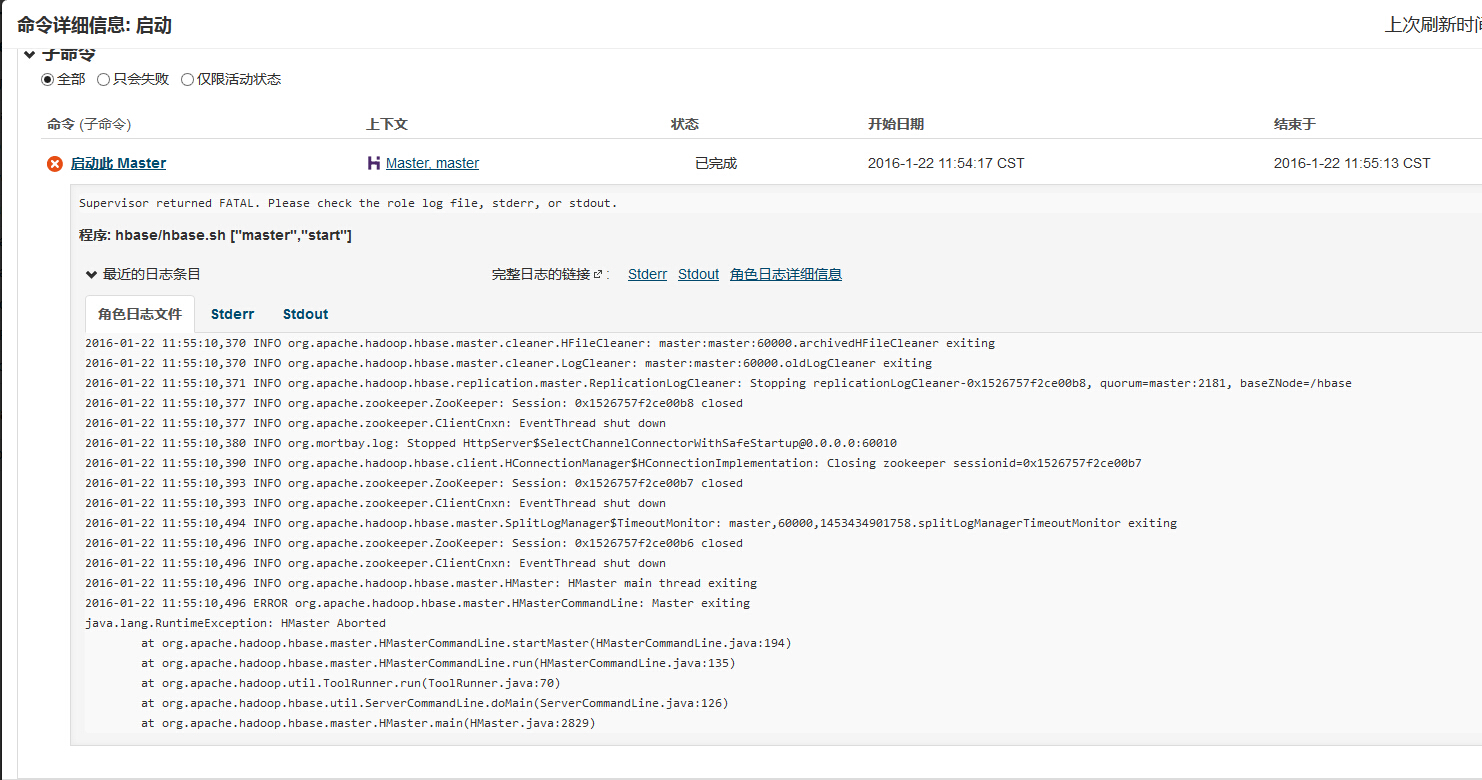
2016-01-22 11:55:10,496 ERROR org.apache.hadoop.hbase.master.HMasterCommandLine: Master exitingjava.lang.RuntimeException: HMaster Abortedat org.apache.hadoop.hbase.master.HMasterCommandLine.startMaster(HMasterCommandLine.java:194)at org.apache.hadoop.hbase.master.HMasterCommandLine.run(HMasterCommandLine.java:135)at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)at org.apache.hadoop.hbase.util.ServerCommandLine.doMain(ServerCommandLine.java:126)at org.apache.hadoop.hbase.master.HMaster.main(HMaster.java:2829)
经查详细日志有以下异常:
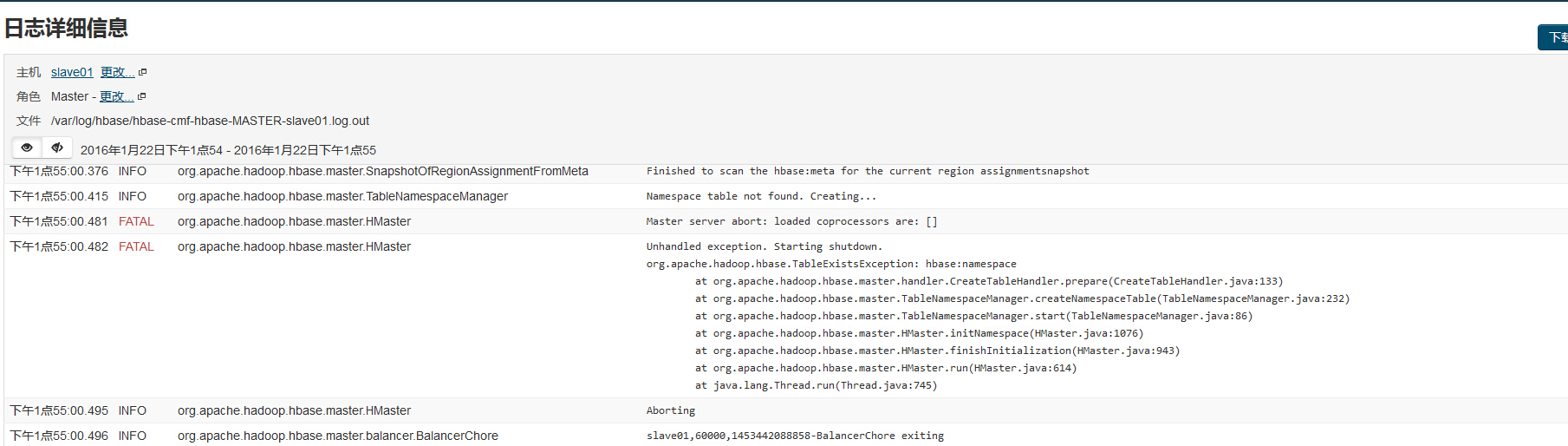
Unhandled exception. Starting shutdown.org.apache.hadoop.hbase.TableExistsException: hbase:namespaceat org.apache.hadoop.hbase.master.handler.CreateTableHandler.prepare(CreateTableHandler.java:133)at org.apache.hadoop.hbase.master.TableNamespaceManager.createNamespaceTable(TableNamespaceManager.java:232)at org.apache.hadoop.hbase.master.TableNamespaceManager.start(TableNamespaceManager.java:86)at org.apache.hadoop.hbase.master.HMaster.initNamespace(HMaster.java:1076)at org.apache.hadoop.hbase.master.HMaster.finishInitialization(HMaster.java:943)at org.apache.hadoop.hbase.master.HMaster.run(HMaster.java:614)at java.lang.Thread.run(Thread.java:745)
进入zookeeper查看目录,zookeeper还保留着上一次的Hbase设置,所以造成了冲突,删除之。
[root@master ~]# zookeeper-client[zk: localhost:2181(CONNECTED) 0] ls /[hbase, zookeeper][zk: localhost:2181(CONNECTED) 1] rmr /hbase
再次尝试,顺利启动Hbase服务。
Linux root用户不能删除文件
rm: cannot remove 'd': Operation not permitted[root@ntp etc]# lsattr ntp.conf----i--------e- ntp.conf# 该文件带有一个"i"的属性,所以才不可以删除[root@ntp etc]# chattr -i ntp.conf
这个属性专门用来保护重要的文件不被删除。
Flume收集日志导入Kafka时遇到的问题
16/02/02 17:25:24 INFO instrumentation.MonitoredCounterGroup: Component type: SOURCE, name: s started16/02/02 17:25:24 ERROR source.SpoolDirectorySource: FATAL: Spool Directory source s: { spoolDir: /usr/git-repo/bootcamp/practise/sogouquery/data }: Uncaught exception in SpoolDirectorySource thread. Restart or reconfigure Flume to continue processing.java.nio.charset.MalformedInputException: Input length = 1at java.nio.charset.CoderResult.throwException(CoderResult.java:277)at org.apache.flume.serialization.ResettableFileInputStream.readChar(ResettableFileInputStream.java:282)at org.apache.flume.serialization.LineDeserializer.readLine(LineDeserializer.java:133)at org.apache.flume.serialization.LineDeserializer.readEvent(LineDeserializer.java:71)at org.apache.flume.serialization.LineDeserializer.readEvents(LineDeserializer.java:90)at org.apache.flume.client.avro.ReliableSpoolingFileEventReader.readEvents(ReliableSpoolingFileEventReader.java:252)at org.apache.flume.source.SpoolDirectorySource$SpoolDirectoryRunnable.run(SpoolDirectorySource.java:228)at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:304)at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:178)at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)at java.lang.Thread.run(Thread.java:745)
初步判断为不能识别输入的字符。
这个字节是双字节汉字的一部分,这样我们解码时就不要包含这个字节,而是把这个字节放进下次解码之前的Bytebuffer中。这样做,系统就不会抛出“无法正确解码”这类的异常了。
原因:日志文件创建时的字符编码与读取时不同,在Windows平台创建的文件放入Linux中可能会出现乱码问题。
解决:在Linux中创建日志文件,在终端Copy原日志内容进入该文件中保存。得到日志文件如下,再尝试Flume启动导入不会出现该异常。

java.lang.ClassCastException: [B cannot be cast to java.lang.Stringat kafka.serializer.StringEncoder.toBytes(Encoder.scala:46)at kafka.producer.async.DefaultEventHandler$$anonfun$serialize$1.apply(DefaultEventHandler.scala:130)at kafka.producer.async.DefaultEventHandler$$anonfun$serialize$1.apply(DefaultEventHandler.scala:125)at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)at scala.collection.TraversableLike$class.map(TraversableLike.scala:244)at scala.collection.AbstractTraversable.map(Traversable.scala:105)at kafka.producer.async.DefaultEventHandler.serialize(DefaultEventHandler.scala:125)at kafka.producer.async.DefaultEventHandler.handle(DefaultEventHandler.scala:52)at kafka.producer.async.ProducerSendThread.tryToHandle(ProducerSendThread.scala:104)at kafka.producer.async.ProducerSendThread$$anonfun$processEvents$3.apply(ProducerSendThread.scala:87)at kafka.producer.async.ProducerSendThread$$anonfun$processEvents$3.apply(ProducerSendThread.scala:67)at scala.collection.immutable.Stream.foreach(Stream.scala:547)at kafka.producer.async.ProducerSendThread.processEvents(ProducerSendThread.scala:66)at kafka.producer.async.ProducerSendThread.run(ProducerSendThread.scala:44)
配置文件中的Producer输入类型须原源码中保持一致。
解决:看源码中Producer的value类型为byte[],则在配置文件中更改producer.sinks.r.serializer.class=kafka.serializer.DefaultEncoderkey的类型需要和serializer保持一致,如果key是String,则需要配置为kafka.serializer.StringEncoder,如果不配置,默认为kafka.serializer.DefaultEncoder,即二进制格式
Kafka Consumer消费时的问题
[root@master ~]# /usr/kafka_2.10-0.8.2.0/bin/kafka-console-consumer.sh --zookeeper master:2181 --from-beginning --topic topic[2016-02-19 10:55:47,066] WARN [console-consumer-29985_master-1455850545951-88b63a80-leader-finder-thread], Failed to add leader for partitions [topic,0]; will retry (kafka.consumer.ConsumerFetcherManager$LeaderFinderThread)kafka.common.NotLeaderForPartitionExceptionat sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57)at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)at java.lang.reflect.Constructor.newInstance(Constructor.java:526)at java.lang.Class.newInstance(Class.java:379)at kafka.common.ErrorMapping$.exceptionFor(ErrorMapping.scala:86)at kafka.consumer.SimpleConsumer.earliestOrLatestOffset(SimpleConsumer.scala:169)at kafka.consumer.ConsumerFetcherThread.handleOffsetOutOfRange(ConsumerFetcherThread.scala:60)at kafka.server.AbstractFetcherThread$$anonfun$addPartitions$2.apply(AbstractFetcherThread.scala:177)at kafka.server.AbstractFetcherThread$$anonfun$addPartitions$2.apply(AbstractFetcherThread.scala:172)at scala.collection.TraversableLike$WithFilter$$anonfun$foreach$1.apply(TraversableLike.scala:772)at scala.collection.immutable.Map$Map1.foreach(Map.scala:109)at scala.collection.TraversableLike$WithFilter.foreach(TraversableLike.scala:771)at kafka.server.AbstractFetcherThread.addPartitions(AbstractFetcherThread.scala:172)at kafka.server.AbstractFetcherManager$$anonfun$addFetcherForPartitions$2.apply(AbstractFetcherManager.scala:87)at kafka.server.AbstractFetcherManager$$anonfun$addFetcherForPartitions$2.apply(AbstractFetcherManager.scala:77)at scala.collection.TraversableLike$WithFilter$$anonfun$foreach$1.apply(TraversableLike.scala:772)at scala.collection.immutable.Map$Map1.foreach(Map.scala:109)at scala.collection.TraversableLike$WithFilter.foreach(TraversableLike.scala:771)at kafka.server.AbstractFetcherManager.addFetcherForPartitions(AbstractFetcherManager.scala:77)at kafka.consumer.ConsumerFetcherManager$LeaderFinderThread.doWork(ConsumerFetcherManager.scala:95)at kafka.utils.ShutdownableThread.run(ShutdownableThread.scala:60)
每个分区都由一系列有序的、不可变的消息组成,这些消息被连续的追加到分区中。分区中的每个消息都有一个连续的序列号叫做offset,用来在分区中唯一的标识这个消息。
解决:猜测可能是某个Broker Down掉未切换Leader导致,可是查看Kafka进程发现所有节点都运行正常,在所有节点尝试重启Kafka后异常消失。
Mysql相关
配置远程访问
MariaDB [(none)]> GRANT ALL ON *.* TO root@'%' IDENTIFIED BY 'root' WITH GRANT OPTION;Query OK, 0 rows affected (0.05 sec)MariaDB [(none)]> flush privileges;Query OK, 0 rows affected (0.01 sec)#这句话的意思 ,允许任何IP地址(上面的 % 就是这个意思)的电脑 用admin帐户 和密码(admin)来访问这个MySQL Server#必须加类似这样的帐户,才可以远程登陆。 root帐户是无法远程登陆的,只可以本地登陆
Mysql修改密码
[root@iZ28vbkq2xxZ ~]# mysqladmin -u root -p password 'Redskirt0608_'Enter password:[root@iZ28vbkq2xxZ ~]# mysql -u root -p
远程复制数据库
mysqldump --user=YOURNAME --password=YOUR_PASSWORD --host=YOUR_HOST --opt YOUR_DATABASE|mysql --user=YOUR_NAME --password=YOUR_PASSWORD -C YOUR_DATABASE
