@sasaki
2016-01-14T10:36:01.000000Z
字数 5854
阅读 3819
SparkSQL & DataFrames
BigData Spark
版本控制
@Title SparkSQL & DataFrames@Version v1.0@Timestamp 2016-01-13 15:44@Author Nicholas@Mail redskirt@outlook.com
前言
SparkSQL的前身是Shark,给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具,Hive应运而生,它是当时唯一运行在Hadoop上的SQL-on-Hadoop工具。但是MapReduce计算过程中大量的中间磁盘落地过程消耗了大量的I/O,降低的运行效率,为了提高SQL-on-Hadoop的效率,大量的SQL-on-Hadoop工具开始产生,其中表现较为突出的是:
- MapR的Drill
- Cloudera的Impala
- Shark
SparkSQL抛弃原有Shark的代码,汲取了Shark的一些优点,如内存列存储(In-Memory Columnar Storage)、Hive兼容性等,重新开发了SparkSQL代码;由于摆脱了对Hive的依赖性,SparkSQL无论在数据兼容、性能优化、组件扩展方面都得到了极大的方便。
- 数据兼容方面 不但兼容Hive,还可以从RDD、parquet文件、JSON文件中获取数据,未来版本甚至支持获取RDBMS数据以及cassandra等NOSQL数据;
- 性能优化方面 除了采取In-Memory Columnar Storage、byte-code generation等优化技术外、将会引进Cost Model对查询进行动态评估、获取最佳物理计划等等;
- 组件扩展方面 无论是SQL的语法解析器、分析器还是优化器都可以重新定义,进行扩展。
引自:http://www.cnblogs.com/shishanyuan/p/4723604.html
一、
- SQL on Hadoop:Hive、Impala、Drill
- DataFrame
DataFrame API:Scala、Python、Java、R
DataFrame演示
scala> val sqlContext = new org.apache.spark.sql.SQLContext(sc)sqlContext: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@1d5d721f[root@master resources]# pwd/usr/spark-1.3.1-bin-hadoop2.6/examples/src/main/resources[root@master resources]# cat people.json{"name":"Michael"}{"name":"Andy", "age":30}{"name":"Justin", "age":19}scala> import sqlContext.implicits._import sqlContext.implicits._scala> val df = sqlContext.read.json("/usr/spark-1.5.1-bin-hadoop2.6/examples/src/main/resources/people.json")scala> df.collectres2: Array[org.apache.spark.sql.Row] = Array([null,Michael], [30,Andy], [19,Justin])scala> df.show+----+-------+| age| name|+----+-------+|null|Michael|| 30| Andy|| 19| Justin|+----+-------+scala> df.printSchemaroot|-- age: long (nullable = true)|-- name: string (nullable = true)scala> df.select("name")res5: org.apache.spark.sql.DataFrame = [name: string]scala> df.select(df("name"), df("age")+10).show+-------+----------+| name|(age + 10)|+-------+----------+|Michael| null|| Andy| 40|| Justin| 29|+-------+----------+scala> df.select(df("name"), df("age")>20).show+-------+----------+| name|(age > 20)|+-------+----------+|Michael| null|| Andy| true|| Justin| false|+-------+----------+scala> df.groupBy("age").count.show+----+-----+| age|count|+----+-----+|null| 1|| 19| 1|| 30| 1|+----+-----+scala> df.groupBy("age").avg().show+----+--------+| age|avg(age)|+----+--------+|null| null|| 19| 19.0|| 30| 30.0|+----+--------+val sqlContext = new org.apache.spark.sql.SQLContext(sc)case class Person(name: String)var people = sc.textFile("/workspace/xx/tmp/a").map(_.split(" ")).map(p => Person(p(0)))val peopleSchema = sqlContext.createSchemaRDD(people)peopleSchema.registerTempTable("people")var df=sqlContext.sql("select * from people")
使用SQL:
1)加载数据
2)定义case class
3)将数据映射到case class并转换为DataFrame
4)注册到表
5)写SQL(sqlContext.sql("SELECT ... FROM ..."))SparkSQL演示
[root@master resources]# cat people.txtMichael, 29Andy, 30Justin, 19scala> case class Person(name: String, age: Int)defined class Personscala> val people = sc.textFile("/usr/spark-1.5.1-bin-hadoop2.6/examples/src/main/resources/people.txt").map(_.split(",")).map(p => Person(p(0), p(1).trim().toInt)).toDF()people: org.apache.spark.sql.DataFrame = [name: string, age: int]scala> people.registerTempTable("people")scala> sqlContext.sql("SELECT name FROM people").show+-------+| name|+-------+|Michael|| Andy|| Justin|+-------+scala> sqlContext.sql("SELECT name FROM people WHERE age > 20 AND name = 'Andy'").show+----+|name|+----+|Andy|+----+scala> sqlContext.sql("SELECT name FROM people").map(r => "name: " + r(0)).collect().foreach(println)name: Michaelname: Andyname: Justinscala> sqlContext.sql("SELECT name FROM people").map(r => "name: " + r.getAs[String]("name")).collect().foreach(println)name: Michaelname: Andyname: Justin
SparkSQL可以跨各种数据源进行分析,只要支持DataSource。
parquet作为默认的DataSource。save的四种模式
- SaveMode.ErrorIfExists(默认)
- SaveMode.Append
- SaveMode.Overwrite
- SaveMode.Ignore
持久化DataFrame到Table
DataFrame.saveAsTable,目前只支持从HiveContext创建出来的DataFrame。DataFrame与Parquet:读Parquet、存Parquet
scala> people.write.parquet("people.parquet")SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".SLF4J: Defaulting to no-operation (NOP) logger implementationSLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.[root@master people.parquet]# pwd/usr/spark-1.5.1-bin-hadoop2.6/people.parquet[root@master people.parquet]# ls_common_metadata _metadata part-r-00000-ab66c978-3caf-4689-a36b-bd164a1a12fe.gz.parquet part-r-00001-ab66c978-3caf-4689-a36b-bd164a1a12fe.gz.parquet _SUCCESS# 读取parquetscala> val parquetFile = sqlContext.read.parquet("people.parquet")parquetFile: org.apache.spark.sql.DataFrame = [name: string, age: int]# parquetFile也是一个DataFrame,进而也可以进行SQL操作scala> parquetFile.registerTempTable("people_")scala> sqlContext.sql("SELECT name, age FROM people_").show16/01/14 17:10:15 WARN ParquetRecordReader: Can not initialize counter due to context is not a instance of TaskInputOutputContext, but is org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl16/01/14 17:10:15 WARN ParquetRecordReader: Can not initialize counter due to context is not a instance of TaskInputOutputContext, but is org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl+-------+---+| name|age|+-------+---+|Michael| 29|| Andy| 30|| Justin| 19|+-------+---+
分区发现
基于Parquet的DataFrame能自动发现分区表。Schema合并
- 自动动态合并Schema
- spark.sql.parquet.mergeSchema
scala> val df1 = sc.makeRDD(1 to 5).map(i => (i, i * 2)).toDF("single", "double")df1: org.apache.spark.sql.DataFrame = [single: int, double: int]scala> val df2 = sc.makeRDD(6 to 10).map(i => (i, i * 3)).toDF("single", "triple")df2: org.apache.spark.sql.DataFrame = [single: int, triple: int]scala> df2.printSchemaroot|-- single: integer (nullable = false)|-- triple: integer (nullable = false)scala> df1.write.parquet("data/test_table/key=1")scala> df2.write.parquet("data/test_table/key=2")scala> val df3 = sqlContext.read.option("mergeSchema", "true").parquet("data/test_table")df3: org.apache.spark.sql.DataFrame = [single: int, triple: int, double: int, key: int]scala> df3.printSchemaroot|-- single: integer (nullable = true)|-- triple: integer (nullable = true)|-- double: integer (nullable = true)|-- key: integer (nullable = true)
DataFrame和SQL共享相同的优化和执行引擎。
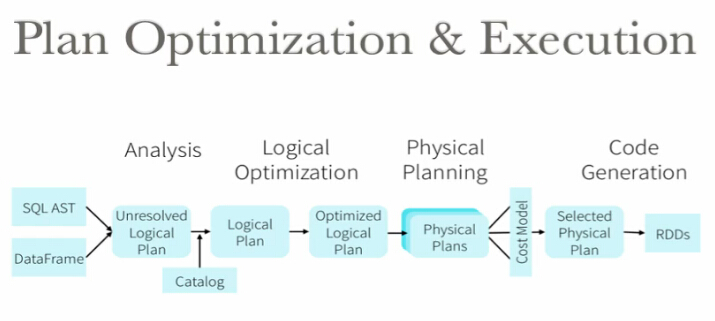
Data Visualization: Apache Zeppelin
