@xiaohaizi
2022-02-08T03:51:40.000000Z
字数 148111
阅读 1087
前言
本MySQL系列文章首发于微信公众号“我们都是小青蛙”,小孩子希望它们能在各位小伙伴工作面试过程中起到一定作用,希望对大家有帮助。

作者介绍:小孩子,目前创作:
- 《MySQL是怎样使用的:快速入门MySQL》书籍
- 《MySQL是怎样运行的:从根儿上理解MySQL》书籍
- 《计算机是怎样运行的:从根儿上理解计算机》掘金小册

MySQL索引是怎么推导出来的
公众号文章
写本文的起因
《MySQL是怎样运行的》于2020年11.1日发行至今近一年的时间,已经印刷近两万册,十分感谢各位小伙伴的捧场。不过最近在答疑群里一直有小伙伴说:“书看的时候很爽,以为自己啥都会了,不过过一段时间后就都忘了,面试一问好像都学过,但是就是想不起来具体的内容是个啥”。
小孩子在这里需要强调一下,这不是一本入门的书籍,不是随便翻翻就可以学会,需要大家拿出一个完整的时间,找一个笔记本好好记一下笔记才可以学会的。
另外,书里涉及大量的细节,比方说我们致力于将记录、页面、索引、表空间中涉及的结构的每一个字节都是干什么的给大家讲清楚,但记住这些细节并不是重点,细节是用来辅助大家理解脉络的。我们尝试过在没有细节的情况下去讲述MySQL是怎样执行查询的,但大家一定会如站在空中楼阁,表面看起来很光鲜,但时刻都有掉下去的危险。
本文来尝试以最简单的脉络来帮各位理出一条线,大家有了这条线作为主心骨,就不用怕淹没在细节的海洋中无法自拔了。
第1~2章
前两章非常简单,主要介绍如何启动MySQL服务器和客户端,以及启动选项和系统变量。没有什么难度,就不花篇幅唠叨了。
第3章
我们需要明白“字符”是面向人类的概念,计算机需要用一个二进制字节序列来表示字符,由于二进制字节序列和字符的映射关系谁都可以规定,所以市面上产生了各种各样的字符集。
数字之间可以比较大小,字符之间也可以比较大小,不过比较字符时取决于人的好恶。比方说有人觉得'A'和'a'是相等的,有人就觉得不相等。所以我们在比较字符前需要事先规定好一个规则来说明谁大谁小,这个规则就是所谓的比较规则。
MySQL支持若干种字符集,不同字符集也可以有不同的比较规则,我们可以通过一定语法来进行配置。
第4章
大家需要知道一条记录实际上是分两部分存储的:

重点需要知道在记录的额外信息中有一个两字节的称为next_record指针,通过该指针各条记录可以组成一个单向链表:
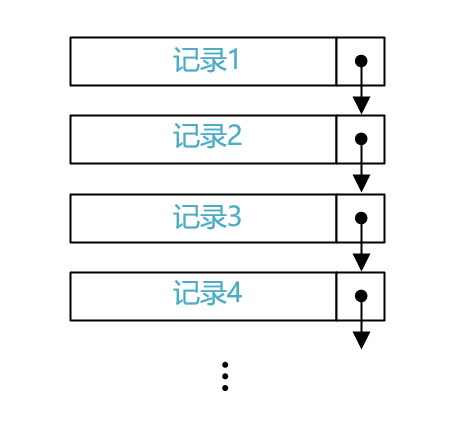
单向链表中的记录的主键值是按照从小到大的顺序排序的,也就是说这个单向链表是有序的。
第5章
大家需要知道记录是放在页里边的, InnoDB是以页为单位从磁盘上加载数据的。页面可以配置成4KB、8KB、16KB、32KB、64KB几种大小,不过默认是16KB的。
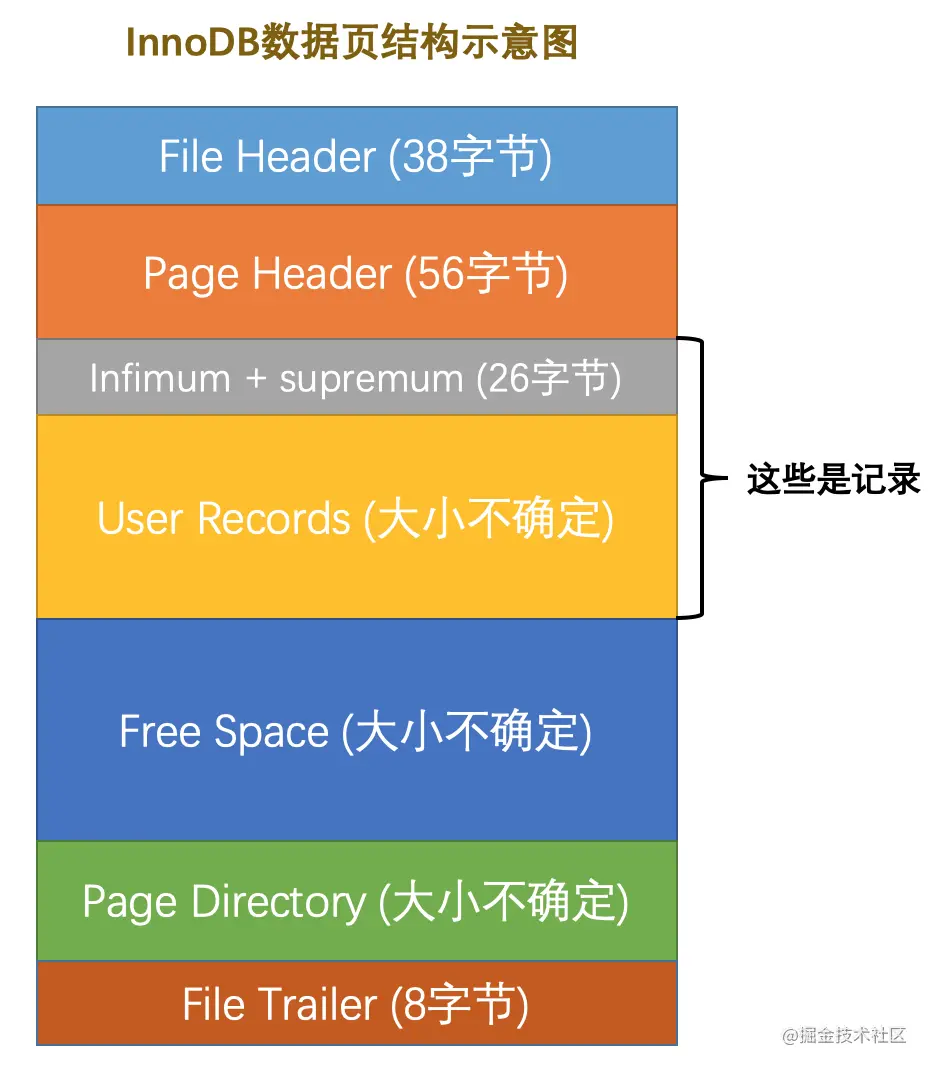
对于存储记录的数据页来说,它的结构如下图所示:
下边假设某个页中存储了16条用户插入的记录,该数据页的效果图如下所示:
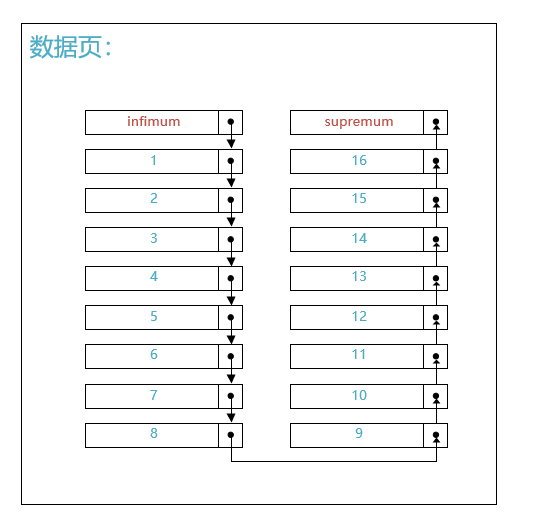
其中Infimum记录和Supremum记录是InnoDB给我们自动生成的两个伪记录,并且规定:
Infimum记录作为本页面中最小的记录Supremum记录作为本页面中最大的记录
如上图所示,各条记录之间按照主键值大小组成了一个单向链表。
接下来我们面临的问题是如何从一个按照主键值大小进行排序的单向链表中快速定位到指定的主键值在哪里。很遗憾,链表做不到呀~
为了解决快速搜索的问题,设计InnoDB的大叔引入了一个称作页目录的东西。具体的做法就是将单向链表中的记录分成若干个组,如下图所示:
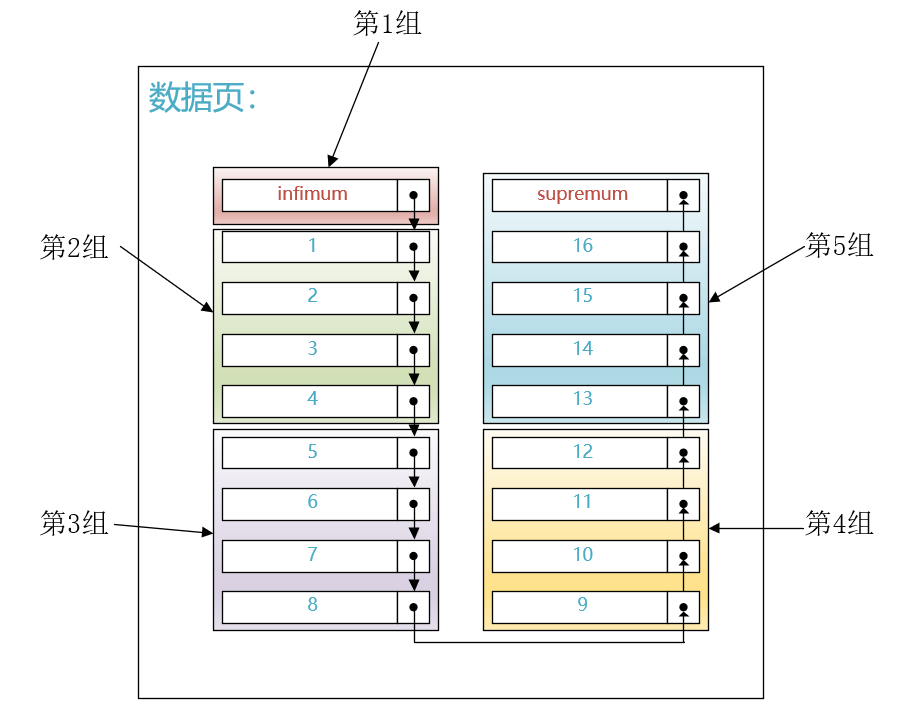
然后将把每个组最大的那条记录在页面中的地址(就是距离页面第0个字节处的偏移量)取出来单独放到页面中的一个部分。每个地址占用2个字节,多个地址就可以组成一个数组结构,如下图所示:
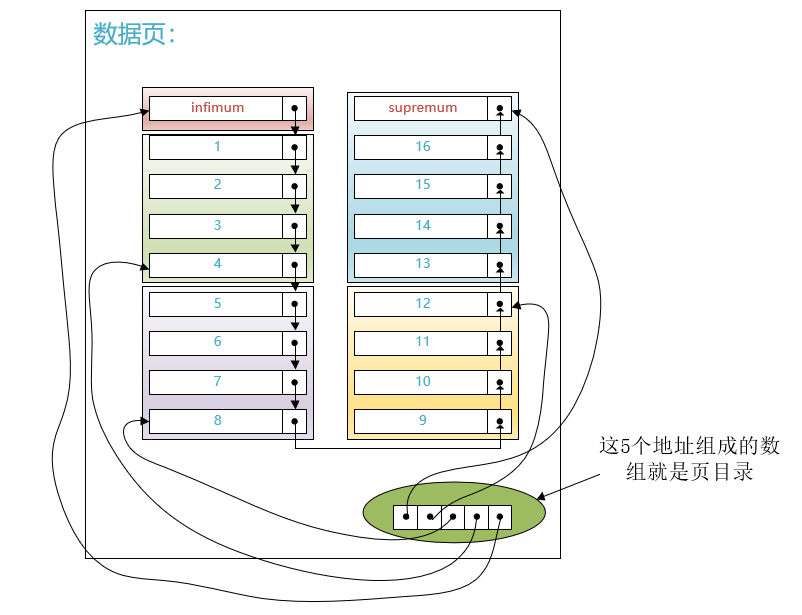
可见,页目录本质上就是一个指针数组,指针指向的记录是有序的,我们就可以针对这个页目录进行二分搜索。比方说我们想找主键值为6的记录,那就可以通过页目录先进行二分查找,定位到主键值6其实是在第3组里,然后再遍历第3组中的记录,就可以定位到具体的主键值6的记录在哪里了。
稍微总结一下,通过第5章的学习,我们应该知道如何在单个页面中快速定位某个主键值的记录了,大致分两步:
第一步:通过页目录定位到该记录所在的组。
第二部:遍历该组中的记录来找到待查询的主键值(由于一个组中最多有8条记录,所以遍历一个组中的记录的代价还是很小的)。
第6章
现在大家已经知道如何在单个页面中通过页目录来快速定位某个主键值对应的记录了。
一个页里可以放置若干条记录,如果记录太多,就得分散到不同的页中。
页中存储的除了记录以外,还有若干额外信息,其中包括两个指针(这两个指针在上图中的File Header中):
- 一个指针指向上一个页
- 一个指针指向下一个页
这样多个页之间也可以通过双向链表连接起来,而且InnoDB会保证每个页中存储记录的主键值肯定不大于下一个页中存储记录的主键值,也就是说由页面组成的双向链表也是按照它们中存储记录的主键值大小进行排序的。
现在我们做一个大胆的假设:假设一个页里只能存储4条记录,然后有16条记录分散在4个页里,页之间按照它们中存储的主键值进行排序为双向链表,如下图所示:
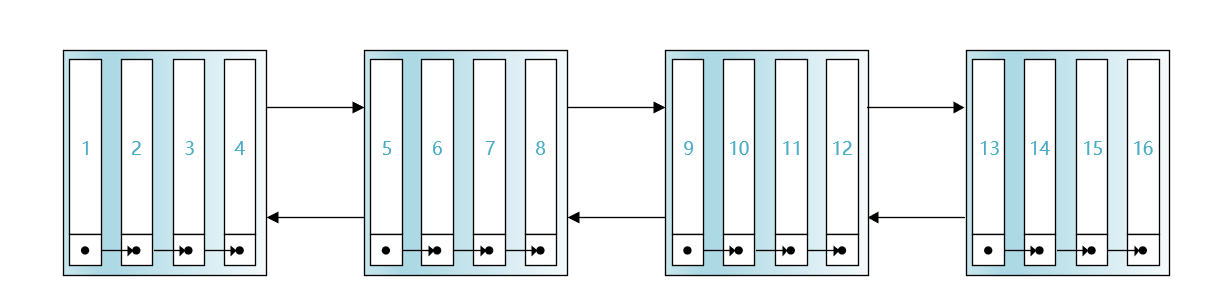
现在如果我们想查找主键值为6的记录该怎么办呢?很遗憾,我们不知道主键值为6的记录在哪个页里,只能从第一个页开始,一个页一个页的找。
遍历很低效,InnoDB采取的方案就是将每个页的主键值最小的用户插入的记录的主键值拿出来,然后和该页的页号拼接成一个新的记录,为了和用户插入的记录做区分,我们把用户插入的记录称作用户记录,把这个新拼接成的记录称作目录项记录。
目录项记录也按照主键值排序成单向链表,也可以通过页目录来快速定位主键值等于某个值的目录项记录。
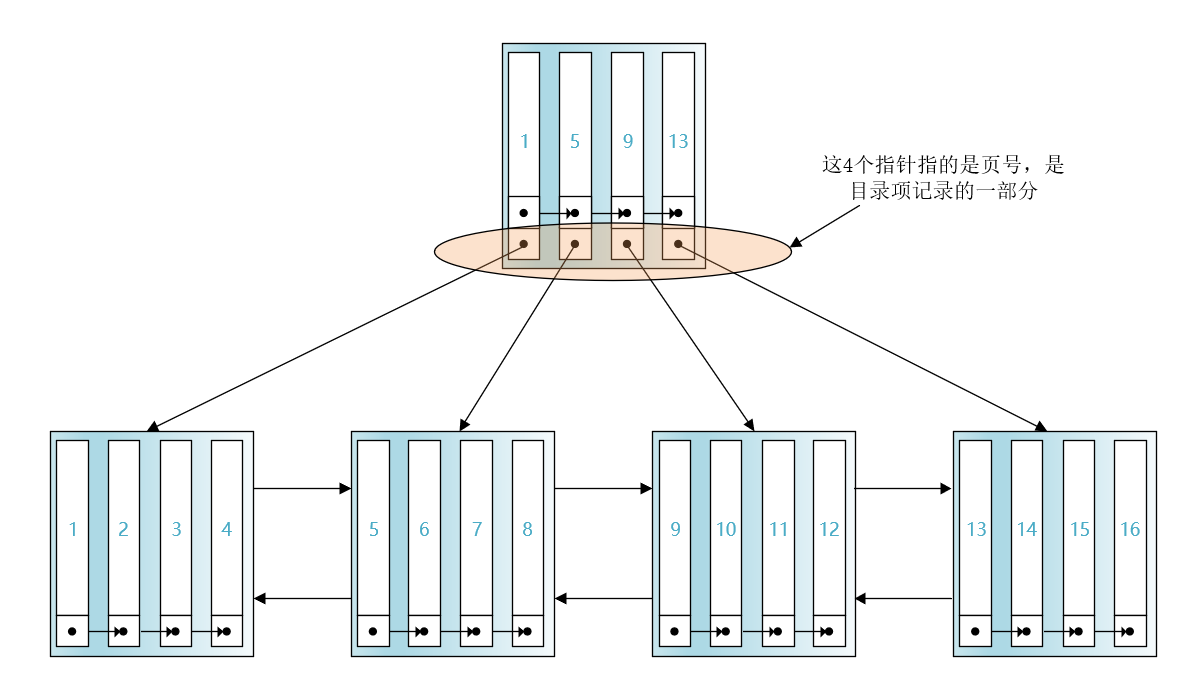
引入了目录项记录以及存储目录项记录的页之后,我们再查找主键值为6的记录就分为2步了:
先在存储目录项记录的页中通过页目录进行二分查找,快速定位用户记录所在的页。因为5 < 6 < 9,我们就知道了主键值为6的用户记录是在主键值为5的目录项记录所指向的页中。
然后在主键值为5的目录项记录所指向的页中,再通过页目录进行二分查找快速定位到主键值为6的用户记录。
表中的记录是可以不断扩充的,每增加一个存储用户记录的页,就需要在存储目录项记录的页中增加一条目录项记录,而页的大小是有限的(默认是16KB),所以存储目录项记录的页也可能被填满,这时候就需要再申请新的存储目录项记录的页,如下图所示:

多个存储目录项记录的页之间也是用双向链表连接的,而且它们也是按照各自页中目录项记录的主键值进行排序的。但是对于多个存储目录项记录的页来说,我们怎么知道我们要找的记录应该在哪个存储目录项记录的页中呢?
这时设计InnoDB的大叔开始了套娃操作,即再将各个存储目录项记录的页中最小的主键值给提取出来,与相应的页号组成更高一层的目录项记录,再填充到新的页里,如下图所示:
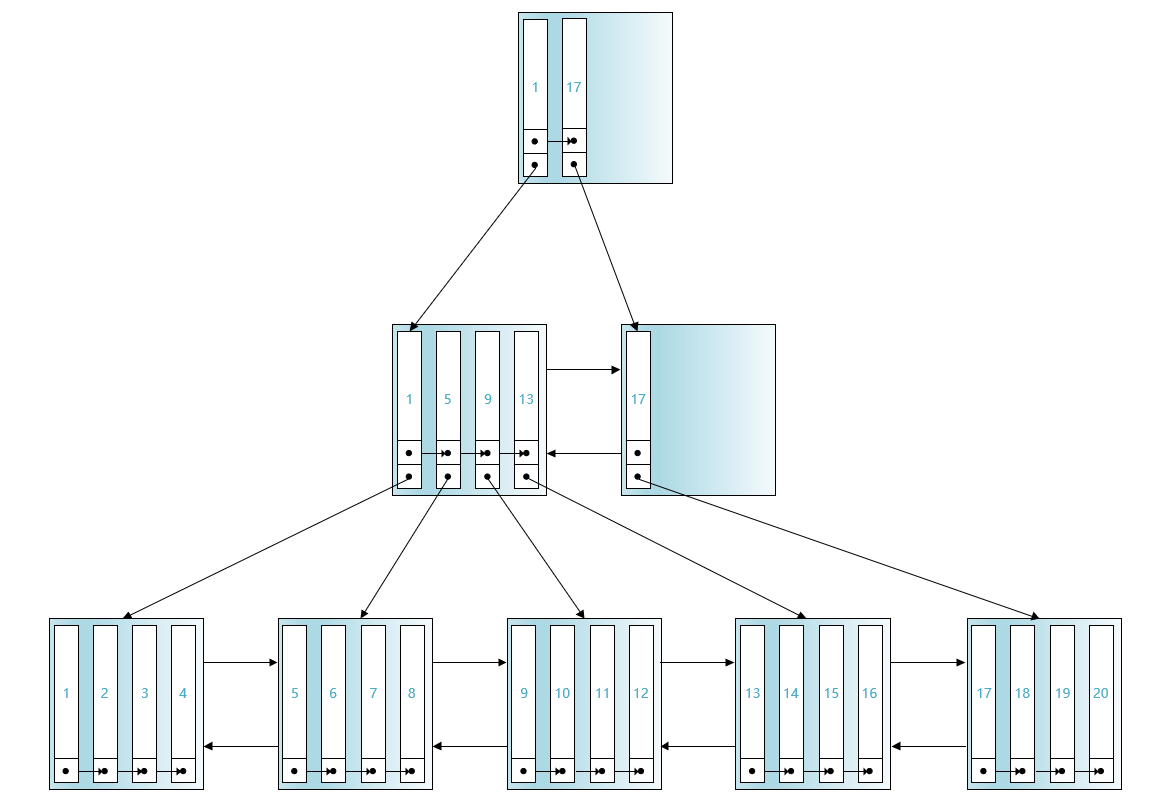
更高一层的目录项记录也按照主键值大小连成了单向链表,这些更高一层的目录项记录所在的页中也有页目录结构。
这样的话各个页面就分为了3层。设计InnoDB的大叔把最下边的存放用户记录的一层称作第0层,第0层往上是第1层,再往上是第2层。
现在如果我们想查找主键值为6的记录的话,那么查找过程就分为了3步:
第1步: 先通过第二层页面的页目录进行二分查找,可以快速定位到第1层目录项记录所在的页。因为1 < 6 < 17,我们就知道我们该去第1层中的最左边的那个页中进行进一步的查找。
第2步:在第1层的存储目录项记录的页中通过页目录进行二分查找,快速定位用户记录所在的页。因为5 < 6 < 9,我们就知道了主键值为6的用户记录是在主键值为5的目录项记录所指向的页中。
第3步:然后在主键值为5的目录项记录所指向的页中,再通过页目录进行二分查找快速定位到主键值为6的用户记录。
设计InnoDB的大叔给上边的结构给了个名:B+树(因为像一颗倒过来的树)。InnoDB中的B+树还有另一个别名:索引。B+树的第0层,也就是最下边那层的页面称作叶子节点,其余的页面被称作非叶子节点或者内节点。其中最高层的节点也被称作根节点或者根页面。
至此,我们了解了索引结构是如何诞生的。
上边介绍按照主键进行排序的B+树索引结构被称作聚簇索引,聚簇索引的叶子节点存放着完整的用户记录(即各个列的值)。我们也可以给自己感兴趣的列或者列组合建立B+树索引,不过此时B+树中就会按照我们给定的列或列组合进行排序(这里指的是每一层页面的排序以及页面中记录的排序),我们把这种给自己感兴趣的列建立的索引称作二级索引或者辅助索引。二级索引的叶子节点中只存放建立索引时指定的列的值以及该记录对应的主键值。
小结一下
下边的小结并不仅仅针对聚簇索引,也针对二级索引。我们将用键值来表示聚簇索引中的主键值或者二级索引中的二级索引列值。
记录是按照键值大小组成一个单向链表的。
记录是被存放在页面中的,页面中维护着一个页目录结构,通过页目录可以对键值进行二分查找,从而加快在单个页面中的查询速度。
多个页面可以按照键值大小组成双向链表,为了快速定位到需查找的键值在哪个页面中,我们引入了目录项记录以及存储目录项记录的页。
存储目录项记录的页大小也有限,我们引入了更高层次的目录项记录,从而形成了套娃结构。我们把这个套娃结构称作
B+树,也就是InnoDB中的索引。
好了,前6章的整体脉络就是上边这些了,大家抓住这些主线,然后进行针对性的阅读,补充更多的细节。一旦理解了这个脉络,之后想忘也忘不掉了。
MySQL的server层和存储引擎层是如何交互的
标签: 公众号文章
SQL的全称是Structured Query Language,翻译成中国话就是结构化查询语言。这是一种声明式的语法,何为声明式?可以联想一下我们生活中的老板,老板在布置任务的时候会告诉你:小王啊,今天把这些砖从A地搬到B地啊,然后就没然后了。老板并不关心你是用手抬,还是用车拉,老板只关心结果:你把砖搬过去就好了。我们之于数据库而言,就是一个老板,SQL语句就是我们给数据库下达的任务,至于具体数据库怎么执行我们并不关心,我们只关心最后数据库给我们返回的结果。
对于设计数据库的人而言,语句怎么执行就得好好考虑了,老板不操心,事儿总还得干。设计MySQL的大叔人为的把MySQL分为server层和存储引擎层,但是什么操作是在server层做的,什么操作是在存储引擎层做的大家可能有些迷糊。本文将以一个实例来展示它们二者各自负责的事情。
准备工作
为了故事的顺利发展,我们先创建一个表:
CREATE TABLE hero (id INT,name VARCHAR(100),country varchar(100),PRIMARY KEY (id),KEY idx_name (name)) Engine=InnoDB CHARSET=utf8;
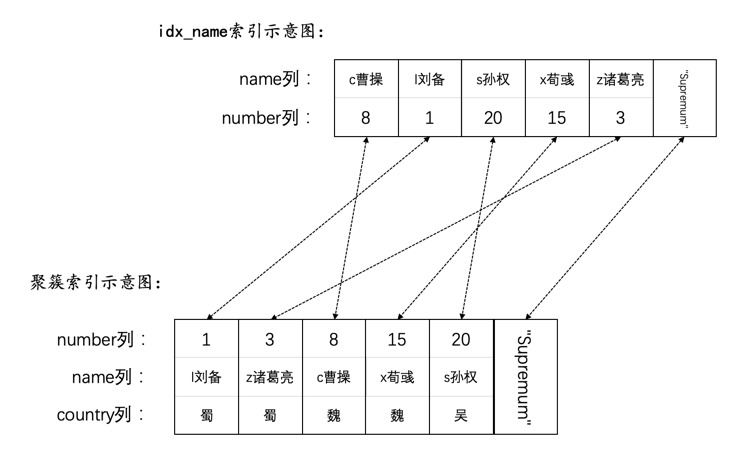
我们为hero表的id列创建了聚簇索引,为name列创建了一个二级索引。这个hero表主要是为了存储三国时的一些英雄,我们向表中插入一些记录:
INSERT INTO hero VALUES(1, 'l刘备', '蜀'),(3, 'z诸葛亮', '蜀'),(8, 'c曹操', '魏'),(15, 'x荀彧', '魏'),(20, 's孙权', '吴');
现在表中的数据就是这样的:
mysql> SELECT * FROM hero;+----+------------+---------+| id | name | country |+----+------------+---------+| 1 | l刘备 | 蜀 || 3 | z诸葛亮 | 蜀 || 8 | c曹操 | 魏 || 15 | x荀彧 | 魏 || 20 | s孙权 | 吴 |+----+------------+---------+5 rows in set (0.00 sec)
准备工作就做完了。
正文
一条语句在执行之前需要生成所谓的执行计划,也就是该语句将采用什么方式来执行(使用什么索引,采用什么连接顺序等等),我们可以通过Explain语句来查看这个执行计划,比方说对于下边语句来说:
mysql> EXPLAIN SELECT * FROM hero WHERE name < 's孙权' AND country = '蜀';+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+------------------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+------------------------------------+| 1 | SIMPLE | hero | NULL | range | idx_name | idx_name | 303 | NULL | 2 | 20.00 | Using index condition; Using where |+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+------------------------------------+1 row in set, 1 warning (0.03 sec)
输出结果的key列值为idx_name,type列的值为range,表明会针对idx_name二级索引进行一个范围查询。很多同学在这里有一个疑惑:到底是一次性把所有符合条件的二级索引都取出来之后再统一进行回表操作,还是每从二级索引中取出一条符合条件的记录就进行回表一次?其实server层和存储引擎层的交互是以记录为单位的,上边这个语句的完整执行过程就是这样的:
server层第一次开始执行查询,把条件
name < 's孙权'交给存储引擎,让存储引擎定位符合条件的第一条记录。存储引擎在二级索引
idx_name中定位name < 's孙权'的第一条记录,很显然第一条符合该条件的二级索引记录的name列的值为'c曹操'。然后需要注意,我们看到EXPLAIN语句的输出结果的Extra列有一个Using index condition的提示,这表明会将有关idx_name二级索引的查询条件放在存储引擎层判断一下,这个特性就是所谓的索引条件下推(Index Condition Pushdown,简称ICP)。很显然这里的ICP条件就是name < 's孙权'。有的同学可能会问这不就是脱了裤子放屁么,name值为'c曹操'的这条记录就是通过name < 's孙权'这个条件定位的,为啥还要再判断一次?这就是设计MySQL 的大叔的粗暴设计,十分简单,没有为啥~小贴士:对于使用二级索引进行等值查询的情况有些许不同,比方说上边的条件换成`name = 's孙权'`,对于等值查询的这种情况,设计MySQL的大叔在InnoDB存储引擎层有特殊的处理方案,是不作为ICP条件进行处理的。
然后拿着该二级索引记录中的主键值去回表,把完整的用户记录都取到之后返回给
server层(也就是说得到一条二级索引记录后立即去回表,而不是把所有的二级索引记录都拿到后统一去回表)。我们的执行计划输出的
Extra列有一个Using Where的提示,意味着server层在接收到存储引擎层返回的记录之后,接着就要判断其余的WHERE条件是否成立(就是再判断一下country = '蜀'是否成立)。如果成立的话,就直接发送给客户端。小贴士:什么?发现一条记录符合条件就发送给了客户端?那为什么我的客户端不是一条一条的显示查询结果,而是一下子全部展示呢?这是客户端软件的鬼,人家规定在接收完全部的记录之后再展示而已。
如果不成立的话,就跳过该条记录。
接着server层向存储引擎层要求继续读刚才那条记录的下一条记录。
因为每条记录的头信息中都有
next_record的这个属性,所以可以快速定位到下一条记录的位置,然后继续判断ICP条件,然后进行回表操作,存储引擎把下一条记录取出后就将其返回给server层。然后重复第3步的过程,直到存储引擎层遇到了不符合
name < 's孙权'的记录,然后向server层返回了读取完毕的信息,这时server层将结束查询。
这个过程用语言描述还是有点儿啰嗦,我们写一个超级简化版的伪代码来瞅瞅(注意,是超级简化版):
first_read = true; //是否是第一次读取while (true) {if (first_read) {first_read = false;err = index_read(...); //调用存储引擎接口,定位到第一条符合条件的记录;} else {err = index_next(...); //调用存储引擎接口,读取下一条记录}if (err = 存储引擎的查询完毕信息) {break; //结束查询}if (是否符合WHERE条件) {send_data(); //将该记录发送给客户端;} else {//跳过本记录}}
上述的伪代码虽然很粗糙,但也基本表明了意思哈~ 之后有机会我们再唠叨唠叨使用临时表的情况已经使用filesort的情况是怎么执行的。
MySQL查询成本和扫描区间(MySQL中IS NULL、IS NOT NULL、!=不能用索引?胡扯!)
标签: 公众号文章
前情回顾
经过前面的学习我们知道了对于InnoDB存储引擎来说,表中的数据都存储在所谓的B+树中,我们每多建立一个索引,就相当于多建立一棵B+树。
对于聚簇索引对应的B+树来说,叶子节点处存储了完整的用户记录(所谓完整用户记录,就是指一条聚簇索引记录中包含所有用户定义的列已经一些内建的列),并且这些聚簇索引记录按照主键值从小到大排序。
对于二级索引对应的B+树来说,叶子节点处存储了不完整的用户记录(所谓不完整用户记录,就是指一条二级索引记录只包含索引列和主键),并且这些二级索引记录按照索引列的值从小到大排序。
我们向表中存储了多少条记录,每一棵B+树的叶子节点中就包含多少条记录(注意是“每一棵”,包括聚簇索引对应的B+树以及二级索引对应的B+树)。
示例
我们举个例子:
CREATE TABLE t (id INT UNSIGNED NOT NULL AUTO_INCREMENT,key1 INT,common_field VARCHAR(100),PRIMARY KEY (id),KEY idx_key1 (key1)) Engine=InnoDB CHARSET=utf8;
这个表就包含2个索引(也就是2棵B+树):
以
id列为主键对应的聚簇索引。为
key1列建立的二级索引idx_key1。
我们向表中插入一些记录:
INSERT INTO t VALUES(1, 30, 'b'),(2, 80, 'b'),(3, 23, 'b'),(4, NULL, 'b'),(5, 11, 'b'),(6, 53, 'b'),(7, 63, 'b'),(8, NULL, 'b'),(9, 99, 'b'),(10, 12, 'b'),(11, 66, 'b'),(12, NULL, 'b'),(13, 66, 'b'),(14, 30, 'b'),(15, 11, 'b'),(16, 90, 'b');
所以现在s1表的聚簇索引示意图就是这样:
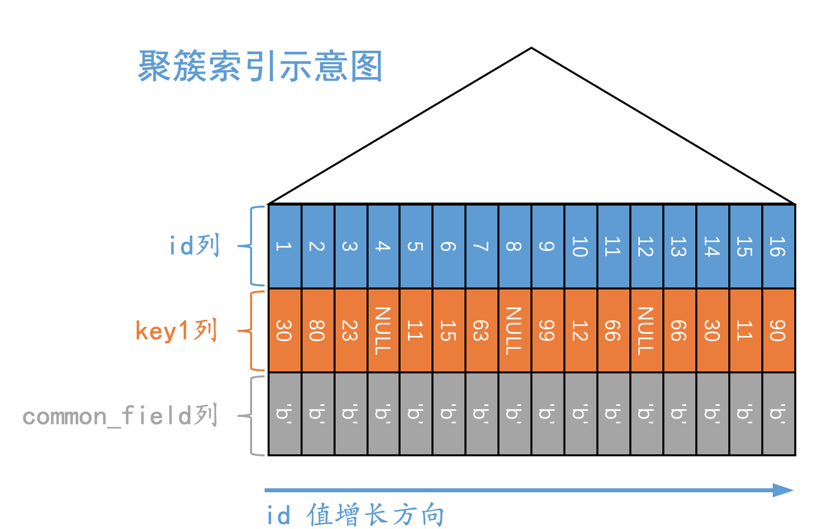
s1表的二级索引示意图就是这样:
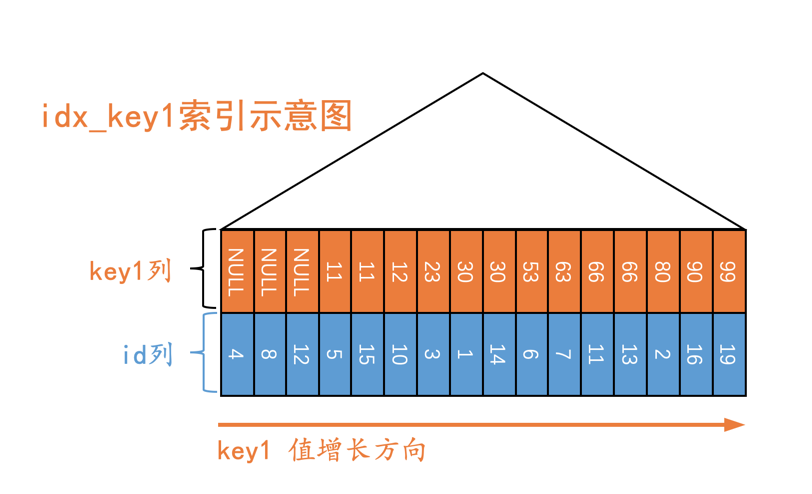
从图中可以看出,值为NULL的二级索引记录都被放到了B+树的最左边,这是因为设计InnoDB的大叔们有规定:
We define the SQL null to be the smallest possible value of a field.
也就是认为NULL值是最小的。
小贴士:
原谅我们把B+树的结构做了一个如此这般的简化,我们省略了页面的结构,省略了所有的内节点(只画了了三角形替代),省略了记录之间的链表,因为这些不是本文的重点,画成如果所示的样子只是为了突出叶子节点处的记录是按照给定索引的键值进行排序的。
查询是怎么执行的
比方说我们现在执行下边这个查询语句:
SELECT * FROM t WHERE key1 = 53;
那么语句的执行过程就如下图所示:
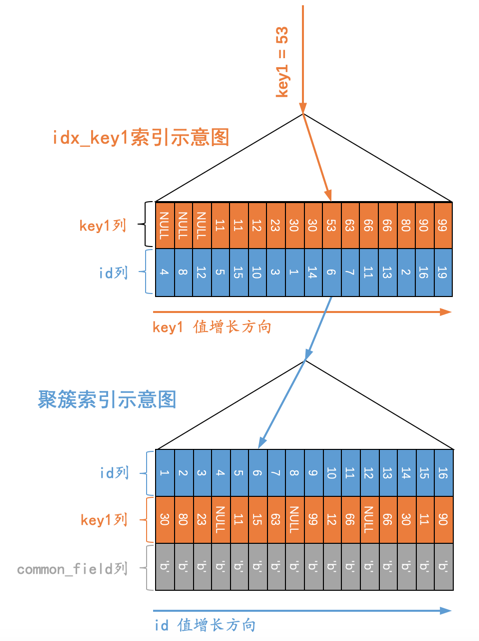
用文字描述一下这个过程也就是:
先通过二级索引
idx_key1对应的B+树快速定位到key1列值为53的那条二级索引记录。然后通过二级索引记录上的主键值,也就是
6到执行回表操作,也就是到聚簇索引中再找到id列值为6的聚簇索引记录。
小贴士:
B+树叶子节点中的记录都是按照键值按照从小到大的顺序排好序的,通过B+树索引定位到叶子节点中的一条记录是非常快速的。
像下边这个查询:
SELECT * FROM t WHERE key1 > 20 AND key1 < 50;
它的执行示意图就是这样:
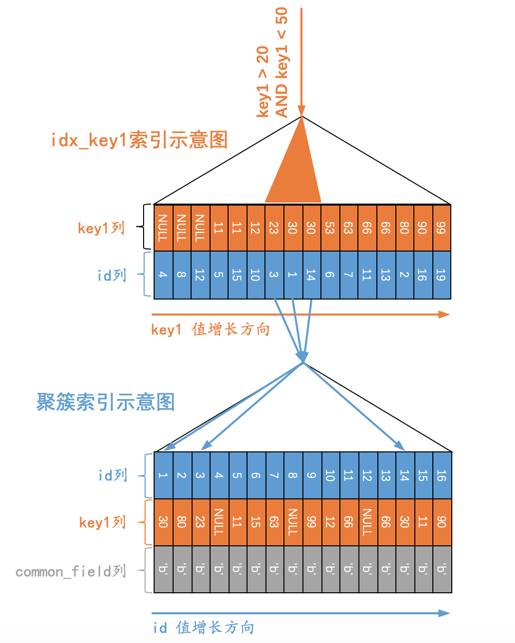
用文字表述就是这样:
先通过二级索引
idx_key1对应的B+树快速定位到满足key1 > 20的第一条记录,也就是我们图中所示的key1值为23的那条记录,然后根据该二级索引中的主键值3执行回表操作,得到完整的用户记录后发送到客户端。然后根据上一步骤中获取到的
key1列值为23的二级索引记录的next_record属性,找到紧邻着的下一条二级索引记录,也就是key1列值为30的记录,然后执行回表操作,得到完整用户记录后发送到客户端。然后再找上一步骤中获取到的
key1列值为30的二级索引记录的下一条记录,该记录的key1列值也为30,继续执行回表操作将完整的用户记录发送到客户端。然后再找上一步骤中获取到的
key1列值为30的二级索引记录的下一条记录,该记录的key1列值为53,不满足key1 < 50的条件,所以查询就此终止。
从上边的步骤中也可以看出来:需要扫描的二级索引记录越多,需要执行的回表操作也就越多。如果需要扫描的二级索引记录占全部记录的比例达到某个范围,那优化器就可能选择使用全表扫描的方式执行查询(一个极端的例子就是扫描全部的二级索引记录,那么将对所有的二级索引记录执行回表操作,显然还不如直接全表扫描)。
所以现在的结论就是:判定某个查询是否可以使用索引的条件就是需要扫描的二级索引记录占全部记录的比例是否比较低,较低的话说明成本较低,那就可以使用二级索引来执行查询,否则要采用全表扫描。
扫描区间和边界条件
对于下边这个查询来说:
SELECT * FROM t WHERE key1 > 20 AND key1 < 50;
如果我们使用idx_key1执行该查询的话,那么就需要扫描key1值在(20, 50)这个区间中的所有二级索引记录,我们就把(20, 50)称作使用idx_key1执行上述查询时的扫描区间,把key1 > 20 AND key1 < 50称作形成该扫描区间的边界条件。
只要索引列和常数使用=、<=>、IN、NOT IN、IS NULL、IS NOT NULL、>、<、>=、<=、BETWEEN、!=或者LIKE操作符连接起来,就可以产生所谓的扫描区间。这里头有一些比较容易让人忽略的扫描区间:
IN操作符的语义和若干个等值匹配操作符=之间用OR连接起来的语义是一样的,它们都会产生多个单点扫描区间,比如下边这两个语句的语义上的效果是一样的:SELECT * FROM single_table WHERE key1 IN ('a', 'b');SELECT * FROM single_table WHERE key1 = 'a' OR key1 = 'b';
!=产生的扫描区间比较有趣,也容易被大家忽略,比如:SELECT * FROM single_table WHERE key1 != 'a';
此时使用idx_key1执行查询时对应的扫描区间就是:
(-∞, 'a')和('a', +∞)。LIKE操作符比较特殊,只有在匹配完整字符串或者匹配字符串前缀时才可以产生合适的扫描区间。比较字符串的大小其实就相当于依次比较每个字符的大小,那么:
先比较字符串的第一个字符,第一个字符小的那个字符串就比较小。
如果两个字符串的第一个字符相同,再比较第二个字符,第二个字符比较小的那个字符串就比较小。
如果两个字符串的前两个字符都相同,那就接着比较第三个字符;依此类推。
对于某个索引列来说,字符串前缀相同的记录肯定是相邻的。比方说我们有一个搜索条件是
key1 LIKE 'a%',而对于二级索引idx_key1来说,所有字符串前缀为'a'的二级索引记录肯定是相邻的,这也就意味着我们只要定位到第一条key1值的字符串前缀为'a'的记录,然后就可以沿着记录所在的单向链表向后扫描,直到某条二级索引记录的字符串前缀不为'a'为止很显然,
key1 LIKE 'a%'形成的扫描区间相当于是['a', 'b') (注意,这里是相当于,其实里边还有一些曲折的故事我们没说)。
其实对于任何查询语句来说,优化器都会按照下边的思路去判断该使用何种方式执行查询:
分析使用不同索引执行查询时对应的扫描区间都是什么。
采用某些手段来分析以下在使用扫描不同索引的扫描区间时对应的成本分别是多少。
小贴士:
我们这里定性的分析成本,而不是定量分析,定量分析可以到书中具体查看。大家粗略的认为扫描区间中的记录越多,成本就越高就好了。比较使用不同索引执行查询的成本以及全表扫描的成本哪个更低,选择成本最低的那个方案去执行查询,这个方案就是所谓的
执行计划。
具体的查询条件分析
我们分别看一下WHERE子句中出现IS NULL、IS NOT NULL、!=这些条件时优化器是怎么做决策的。
IS NULL的情况
比方说这个查询:
SELECT * FROM t WHERE key1 IS NULL;
优化器在真正执行查询前,会首先少量的访问一下索引,调查一下key1在[NULL, NULL]这个区间的记录有多少条:
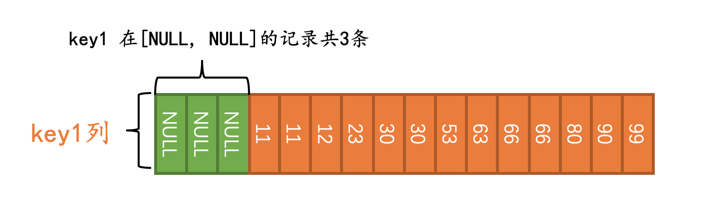
小贴士:
[NULL, NULL]这个区间代表区间里只有一个NULL值。
优化器经过调查得知,需要扫描的二级索引记录占总记录条数的比例是3/16,它觉得这个查询使用二级索引来执行比较靠谱,所以在执行计划中就显示使用这个idx_key1来执行查询:

IS NOT NULL的情况
比方说这个查询:
SELECT * FROM t WHERE key1 IS NOT NULL;
优化器在真正执行查询前,会首先少量的访问一下索引,调查一下key1在(NULL, +∞)这个区间内记录有多少条:
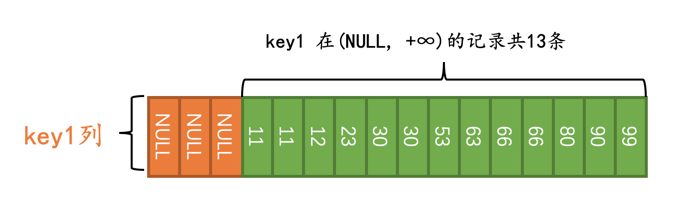
小贴士:
我们这里把NULL当作是最小值对待,你可以认为它比-∞都小。另外注意区间(NULL, +∞)是开区间,也就意味这不包括NULL值。
优化器经过调查得知,需要扫描的二级索引记录占总记录条数的比例是13/16,跟显然这个比例已经非常大了,所以优化器决定使用全表扫描的方式来执行查询:

那怎么才能让使用IS NOT NULL条件的查询使用到二级索引呢?这还不简单,让表中符合IS NOT NULL条件的记录少不就行了,我们可以执行一下:
UPDATE t SET key1 = NULL WHERE key1 < 80;
这样再去执行这个查询:
SELECT * FROM t WHERE key1 IS NOT NULL;
优化器在真正执行查询前,会首先少量的访问一下索引,调查一下key1在(NULL, +∞)这个区间内记录有多少条::
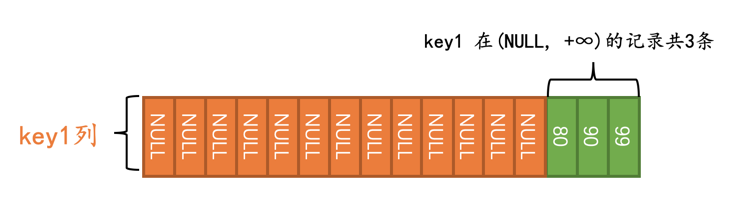
优化器经过调查得知,需要扫描的二级索引记录占总记录条数的比例是3/16,它觉得这个查询使用二级索引来执行比较靠谱,所以在执行计划中就显示使用这个idx_key1来执行查询:

!= 的情况
比方说这个查询:
SELECT * FROM t WHERE key1 != 80;
优化器在真正执行查询前,会首先少量的访问一下索引,调查一下key1在(NULL, 80)和(80, +∞)这两个区间内记录有多少条:
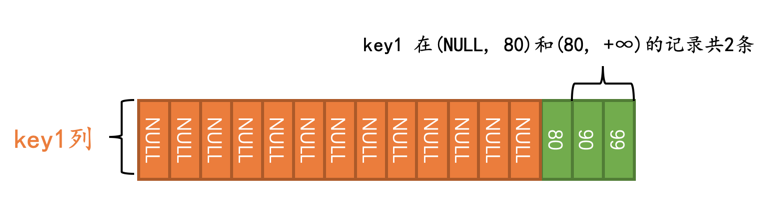
优化器经过调查得知,需要扫描的二级索引记录占总记录条数的比例是2/16,它觉得这个查询使用二级索引来执行比较靠谱,所以在执行计划中就显示使用这个idx_key1来执行查询:
且慢!为啥执行计划的rows列的值为3呢???这是个什么鬼,明明只有2条记录符合条件嘛。哈哈,我们罗列一下每个区间找到的符合条件的记录数量:
(NULL, 80)区间中有0条记录满足条件key1 != 80。(80, +∞)区间中有2条记录满足条件key1 != 80。
可是设计优化器的大叔在这里有个规定:当某个扫描区间符合给定条件的记录数量为0时,硬生生的把它掰成1。也就是说实际优化器认为在(NULL, 80)这个扫描区间中有1条记录符合条件key1 != 80。所以执行计划的rows列才显示了3。
小贴士:
下边是设计优化器的大叔自己对当某个扫描区间符合给定条件的记录数量为0时硬生生的把它掰成1的解释(能看懂的就看,看不懂赶紧跳过):
The MySQL optimizer seems to believe an estimate of 0 rows is always accurate and may return the result 'Empty set' based on that. The accuracy is not guaranteed, and even if it were, for a locking read we should anyway perform the search to set the next-key lock. Add 1 to the value to make sure MySQL does not make the assumption!
总结
至此,我们分别分析了拥有IS NULL、IS NOT NULL、!=这三个条件的查询是在什么情况下使用二级索引来执行的,核心结论就是:成本决定执行计划,跟使用什么查询条件并没有什么关系。优化器会首先针对可能使用到的二级索引划分几个扫描区间,然后分别调查这些区间内有多少条记录,在这些扫描区间内的二级索引记录的总和占总共的记录数量的比例达到某个值时,优化器将放弃使用二级索引执行查询,转而采用全表扫描。
小贴士:
其实扫描区间划分的太多也会影响优化器的决策,比方说IN条件中有太多个参数,将会降低优化器决定使用二级索引执行查询的几率。
另外,优化器调查在某个扫描区间内的索引记录的条数的方式有两种,一种是所谓的index dive(这种方式在数据少的时候是精确的,在数据多时会有些偏差),一种是依赖index statistics,也就是统计数据来做调查(这种方式的统计是很不精确的,有时候偏差是超级巨大的),反正不论采用哪种方式,优化器都会将各个扫描区间中的索引记录数量给计算出来。关于这两种调查方式在《MySQL是怎样运行:从根儿上理解MySQL》中都给出了详细的算法,当然都占用了相当大的篇幅,写在公众号文章里就有点杀鸡用牛刀了。
听说有一个最左原则?这回终于讲清楚了
标签: 公众号文章
准备工作
为了故事的顺利发展,我们需要先建立一个表:
CREATE TABLE single_table (id INT NOT NULL AUTO_INCREMENT,key1 VARCHAR(100),key2 INT,key3 VARCHAR(100),key_part1 VARCHAR(100),key_part2 VARCHAR(100),key_part3 VARCHAR(100),common_field VARCHAR(100),PRIMARY KEY (id),KEY idx_key1 (key1),UNIQUE KEY uk_key2 (key2),KEY idx_key3 (key3),KEY idx_key_part(key_part1, key_part2, key_part3)) Engine=InnoDB CHARSET=utf8;
我们为这个single_table表建立了1个聚簇索引和4个二级索引,分别是:
为id列建立的聚簇索引。
为key1列建立的idx_key1二级索引。
为key2列建立的uk_key2二级索引,而且该索引是唯一二级索引。
为key3列建立的idx_key3二级索引。
为key_part1、key_part2、key_part3列建立的idx_key_part二级索引,这也是一个联合索引。
然后我们需要为这个表插入10000行记录,除id列外其余的列都插入随机值就好了,具体的插入语句我就不写了,自己写个程序插入吧(id列是自增主键列,不需要我们手动插入)。
我们画一下single_table表的聚簇索引的示意图:
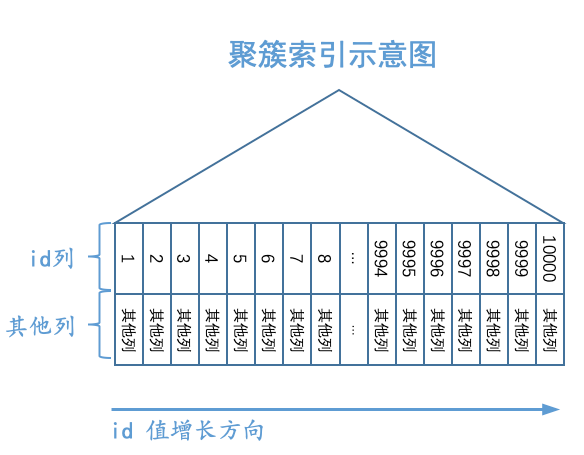
如图所示,我们把聚簇索引对应的复杂的B+树结构搞了一个极度精简版。可以看到,我们忽略掉了页的结构,直接把所有的叶子节点中的记录都放在一起展示,为了方便,我们之后就把聚簇索引叶子节点中的记录称为聚簇索引记录。虽然这个图很简陋,但是我们还是突出了聚簇索引一个非常重要的特点:聚簇索引记录是按照主键值由小到大的顺序排序的。当然,追求视觉上极致简洁的我们觉得图中的“其他列”也可以被略去,只需要保留id列即可,再次简化的B+树示意图就如下所示:

好了,再不能简化了,再简化就要把id列也删去了,就剩一个三角形了,那就真尴尬了。
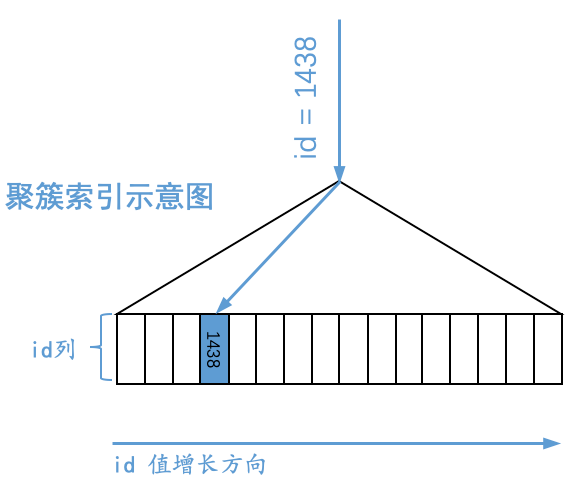
通过聚簇索引对应的B+树,我们可以很容易的定位到主键值等于某个值的聚簇索引记录,比方说我们想通过这个B+树定位到id值为1438的记录,那么示意图就如下所示:
下边以二级索引idx_key1为例,画一下二级索引简化后的B+树示意图:
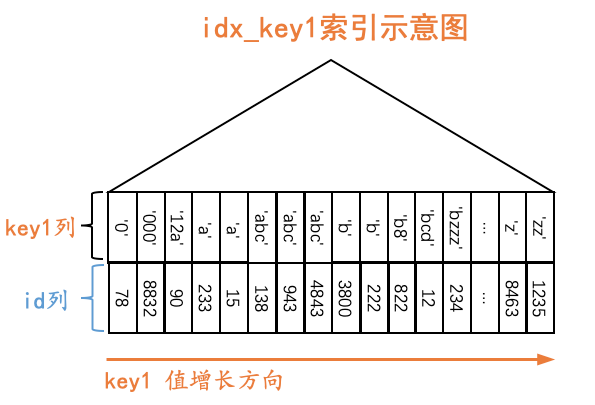
如图所示,我们在二级索引idx_key1对应的B+树中保留了叶子节点的记录,这些记录包括key1列以及id列,这些记录是按照key1列的值由小到大的顺序排序的,如果key1列的值相同,则按照id列的值进行排序。为了方便,我们之后就把二级索引叶子节点中的记录称为二级索引记录。
如果我们想查找key1值等于某个值的二级索引记录,那么可以通过idx_key1对应的B+树,很容易的定位到第一条key1列的值等于某个值的二级索引记录,然后沿着记录所在单向链表向后扫描即可。比方说我们想通过这个B+树定位到第一条key1值为'abc'的记录,那么示意图就如下所示:
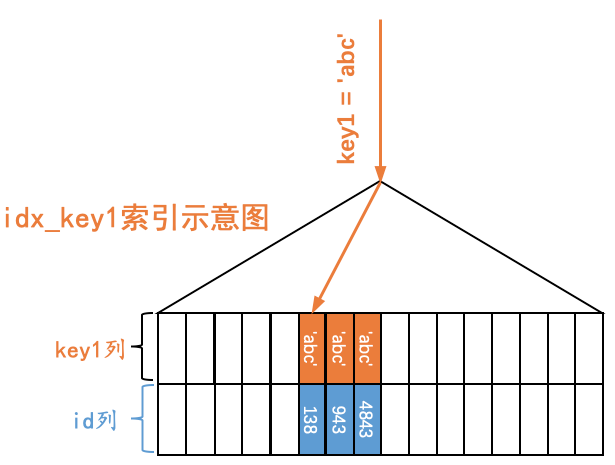
扫描区间和边界条件
对于某个查询来说,最粗暴的执行方案就是扫描表中的所有记录,针对每一条记录都判断一下该记录是否符合搜索条件,如果符合的话就将其发送到客户端,否则就跳过该记录。这种执行方案也被称为全表扫描。对于使用InnoDB存储引擎的表来说,全表扫描意味着从聚簇索引第一个叶子节点的第一条记录开始,沿着记录所在的单向链表向后扫描,直到最后一个叶子节点的最后一条记录为止。虽然全表扫描是一种很笨的执行方案,但却是一种万能的执行方案,所有的查询都可以使用这种方案来执行。
我们之前介绍了利用B+树查找索引列值等于某个值的记录,这样可以明显减少需要扫描的记录数量。其实由于B+树的叶子节点中的记录是按照索引列值由小到大的顺序排序的,所以我们只扫描在某个区间或者某些区间中的记录也可以明显减少需要扫描的记录数量。比方说对于下边这个查询语句来说:
SELECT * FROM single_table WHERE id >= 2 AND id <= 100;
这个语句其实是想查找所有id值在[2, 100]这个区间中的聚簇索引记录,那么我们就可以通过聚簇索引对应的B+树快速地定位到id值为2的那条聚簇索引记录,然后沿着记录所在的单向链表向后扫描,直到某条聚簇索引记录的id值不在[2, 100]这个区间中为止(其实也就是直到id值不符合id<=100这个条件为止)。与扫描全部的聚簇索引记录相比,扫描id值在[2, 100]这个区间中的记录已经很大程度的减少了需要扫描的记录数量,所以提升了查询效率。为简便起见,我们把这个例子中需要扫描的记录的id值所在的区间称为扫描区间,把形成这个扫描区间的查询条件,也就是id >= 2 AND id <= 100称为形成这个扫描区间的边界条件。
小贴士:其实对于全表扫描来说,相当于我们需要扫描id值在(-∞, +∞)这个区间中的记录,也就是说全表扫描对应的扫描区间就是(-∞, +∞)。
对于下边这个查询:
SELECT * FROM single_table WHERE key2 IN (1438, 6328) OR (key2 >= 38 AND key2 <= 79);
我们当然可以直接使用全表扫描的方式执行该查询,但是观察到该查询的搜索条件涉及到了key2列,而我们又正好为key2列建立了uk_key2索引,如果我们使用uk_key2索引执行这个查询的话,那么相当于从下边的三个扫描区间中获取二级索引记录:
- [1438, 1438],对应的边界条件就是key2 IN (1438)
- [6328, 6328],对应的边界条件就是key2 IN (6328)
- [38, 79],对应的边界条件就是key2 >= 38 AND key2 <= 79
这些扫描区间对应到数轴上的示意图就如下图所示:
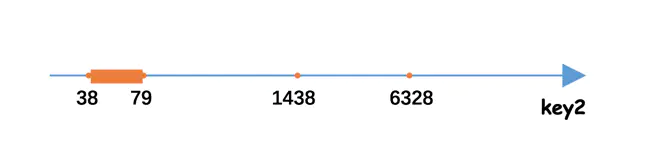
为方便起见,我们把像[1438, 1438]、[6328, 6328]这样只包含一个值的扫描区间称为单点扫描区间,把[38, 79]这样包含多个值的扫描区间称为范围扫描区间。另外,由于我们的查询列表是*,也就是需要读取完整的用户记录,所以从上述的扫描区间中每获取一条二级索引记录时,就需要根据该二级索引记录的id列的值执行回表操作,也就是到聚簇索引中找到相应的聚簇索引记录。
小贴士:其实我们不仅仅可以使用uk_key2执行上述查询,使用idx_key1、idx_key3、idx_keypart都可以执行上述查询。以idx_key1为例,很显然我们无法通过搜索条件形成合适的扫描区间来减少需要扫描的idx_key二级索引记录数量,只能扫描idx_key1的全部二级索引记录。针对获取到的每一条二级索引记录,都需要执行回表操作来获取完整的用户记录。我们也可以说此时使用idx_key1执行查询时对应的扫描区间就是(-∞, +∞)。这样子虽然行得通,但我们图啥呢?最粗暴的全表扫描方式已经要扫描全部的聚簇索引记录了,你这里除了要访问全部的聚簇索引记录,还要扫描全部的idx_key1二级索引记录,这不是费力不讨好么。在这个过程中没有减少需要扫描的记录数量,反而效率比全表扫描更差,所以如果我们想使用某个索引来执行查询,但是又无法通过搜索条件形成合适的扫描区间来减少需要扫描的记录数量时,那么我们是不考虑使用这个索引执行查询的。
并不是所有的搜索条件都可以成为边界条件,比方说下边这个查询:
SELECT * FROM single_table WHERE key1 < 'a' AND key3 > 'z' AND common_field = 'abc';
那么:
如果我们使用idx_key1执行查询的话,那么相应的扫描区间就是(-∞, 'a'),形成该扫描区间的边界条件就是key1 < 'a',而key3 > 'z' AND common_field = 'abc'就是普通的搜索条件,这些普通的搜索条件需要在获取到idx_key1的二级索引记录后,再执行回表操作,获取到完整的用户记录后才能去判断它们是否成立。
如果我们使用idx_key3执行查询的话,那么相应的扫描区间就是('z', +∞),形成该扫描区间的边界条件就是key3 > 'z',而key1 < 'a' AND common_field = 'abc'就是普通的搜索条件,这些普通的搜索条件需要在获取到idx_key3的二级索引记录后,再执行回表操作,获取到完整的用户记录后才能去判断它们是否成立。
使用联合索引执行查询时对应的扫描区间
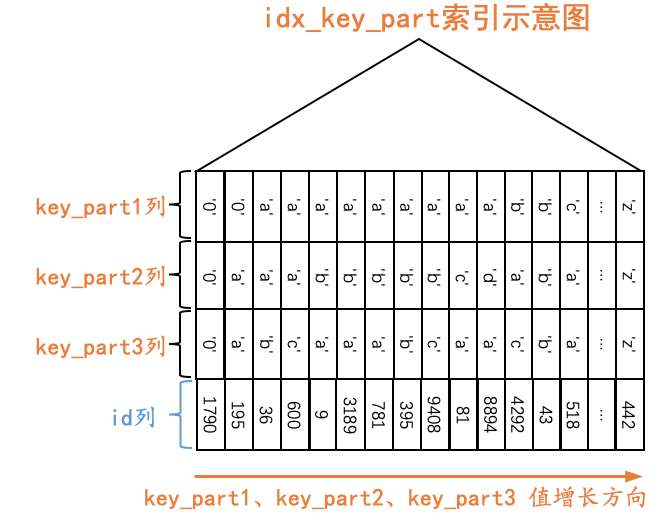
联合索引的索引列包含多个列,B+树每一层页面以及每个页面中的记录采用的排序规则较为复杂,以single_table表的idx_key_part联合索引为例,它采用的排序规则如下所示:
- 先按照key_part1列的值进行排序。
- 在key_part1列的值相同的情况下,再按照key_part2列的值进行排序。
- 在key_part1和key_part2列的值都相同的情况下,再按照key_part3列的值进行排序。
我们画一下idx_key_part索引的示意图:
对于下边这个查询Q1来说:
Q1:SELECT * FROM single_table WHERE key_part1 = 'a';
由于二级索引记录是先按照key_part1列的值进行排序的,所以所有符合key_part1 = 'a'条件的记录肯定是相邻的,我们可以定位到第一条符合key_part1 = 'a'条件的记录,然后沿着记录所在的单向链表向后扫描,直到某条记录不符合key_part1 = 'a'条件为止(当然,对于获取到的每一条二级索引记录都要执行回表操作,我们这里就不展示回表操作了),如下图所示。
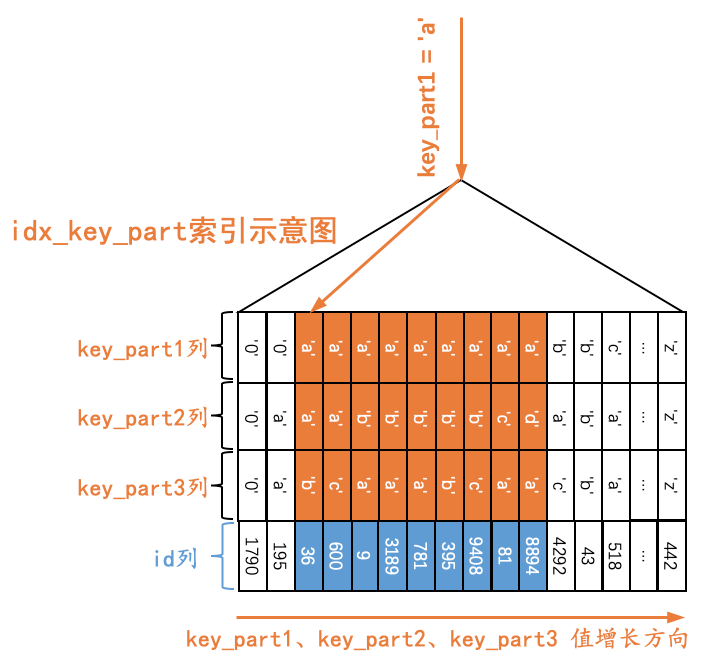
也就是说,如果我们使用idx_key_part索引执行查询Q1时,对应的扫描区间就是['a', 'a'],形成这个扫描区间的条件就是key_part1 = 'a'。
对于下边这个查询Q2来说:
Q2:SELECT * FROM single_table WHERE key_part1 = 'a' AND key_part2 = 'b';
由于二级索引记录是先按照key_part1列的值进行排序的;在key_part1列的值相等的情况下,再按照key_part2列进行排序。所以符合key_part1 = 'a' AND key_part2 = 'b'条件的二级索引记录肯定是相邻的,我们可以定位到第一条符合key_part1='a' AND key_part2='b'条件的记录,然后沿着记录所在的单向链表向后扫描,直到某条记录不符合key_part1='a'条件或者key_part2='b'条件为止(当然,对于获取到的每一条二级索引记录都要执行回表操作,我们这里就不展示回表操作了),如下图所示。

也就是说,如果我们使用idx_key_part索引执行查询Q2时,可以形成扫描区间[('a', 'b'), ('a', 'b')],形成这个扫描区间的条件就是key_part1 = 'a' AND key_part2 = 'b'。
对于下边这个查询Q3来说:
Q3:SELECT * FROM single_table WHERE key_part1 = 'a' AND key_part2 = 'b' AND key_part3 = 'c';
由于二级索引记录是先按照key_part1列的值进行排序的;在keypart1列的值相等的情况下,再按照key_part2列进行排序;在key_part1和key_part2列的值都相等的情况下,再按照key_part3列进行排序。所以符合key_part1 = 'a' AND key_part2 = 'b' AND key_part3 = 'c'条件的二级索引记录肯定是相邻的,我们可以定位到第一条符合key_part1='a' AND key_part2='b' AND key_part3='c'条件的记录,然后沿着记录所在的单向链表向后扫描,直到某条记录不符合key_part1='a'条件或者key_part2='b'条件或者key_part3='c'条件为止(当然,对于获取到的每一条二级索引记录都要执行回表操作),我们就不画示意图了。如果我们使用idx_key_part索引执行查询Q3时,可以形成扫描区间[('a', 'b', 'c'), ('a', 'b', 'c')],形成这个扫描区间的条件就是key_part1 = 'a' AND key_part2 = 'b' AND key_part3 = 'c'。
对于下边这个查询Q4来说:
Q4:SELECT * FROM single_table WHERE key_part1 < 'a';
由于二级索引记录是先按照key_part1列的值进行排序的,所以所有符合key_part1 < 'a'条件的记录肯定是相邻的,我们可以定位到第一条符合key_part1 < 'a'条件的记录(其实就是idx_key_part索引第一个叶子节点的第一条记录),然后沿着记录所在的单向链表向后扫描,直到某条记录不符合key_part1 < 'a'为止(当然,对于获取到的每一条二级索引记录都要执行回表操作,我们这里就不展示回表操作了),如下图所示。
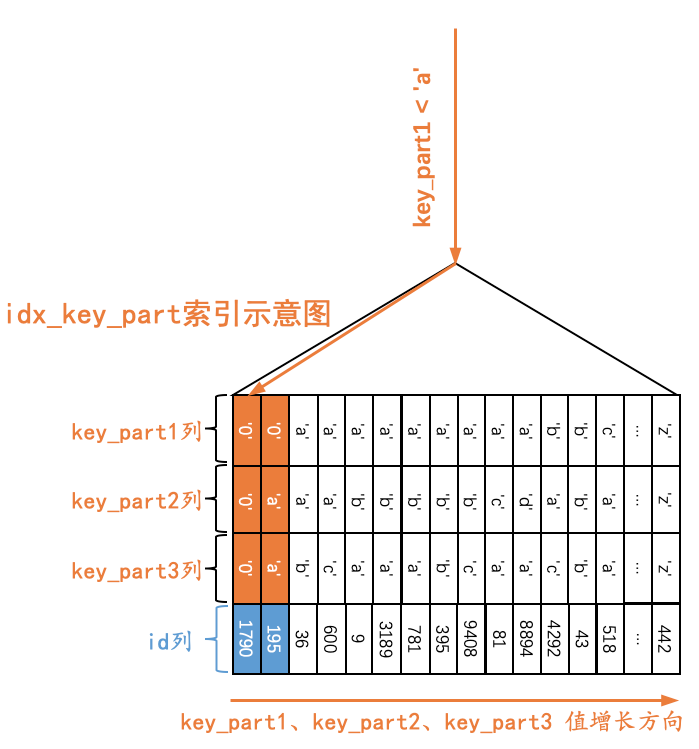
也就是说,如果我们使用idx_key_part索引执行查询Q4时,可以形成扫描区间(-∞, 'a'),形成这个扫描区间的条件就是key_part1 < 'a'。
对于下边这个查询Q5来说:
Q5:SELECT * FROM single_table WHERE key_part1 = 'a' AND key_part2 > 'a' AND key_part2 < 'd';
由于二级索引记录是先按照key_part1列的值进行排序的;在key_part1列的值相等的情况下,再按照key_part2列进行排序。也就是说在符合key_part1 = 'a'条件的二级索引记录中,是按照key_part2列的值进行排序的,那么此时符合key_part1 = 'a' AND key_part2 > 'a' AND key_part2 < 'd'条件的二级索引记录肯定是相邻的。我们可以定位到第一条符合key_part1='a' AND key_part2 > 'a' AND key_part2 < 'c'条件的记录,然后沿着记录所在的单向链表向后扫描,直到某条记录不符合key_part1='a'条件或者key_part2 > 'a'条件或者key_part2 < 'd'条件为止(当然,对于获取到的每一条二级索引记录都要执行回表操作,我们这里就不展示回表操作了),如下图所示。
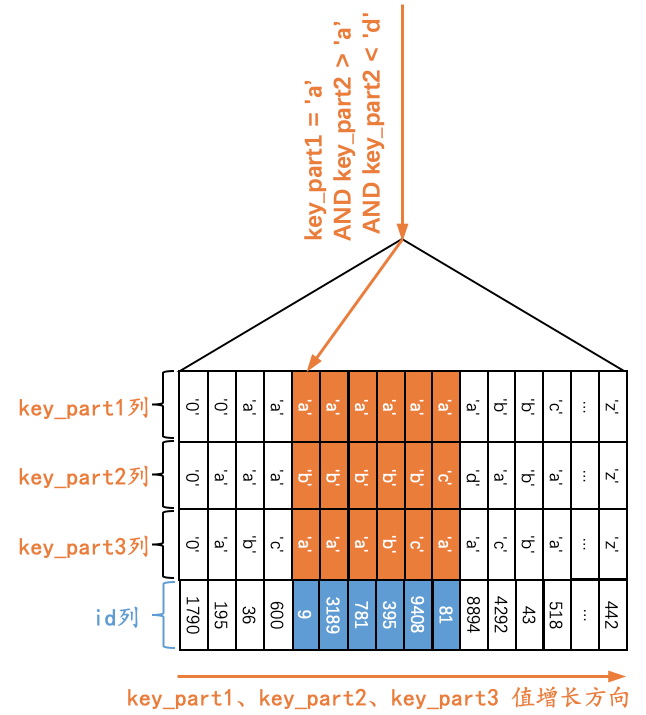
也就是说,如果我们使用idx_key_part索引执行查询Q5时,可以形成扫描区间(('a', 'a'), ('a', 'd')),形成这个扫描区间的条件就是key_part1 = 'a' AND key_part2 > 'a' AND key_part2 < 'd'。
对于下边这个查询Q6来说:
Q6:SELECT * FROM single_table WHERE key_part2 = 'a';
由于二级索引记录不是直接按照key_part2列的值排序的,所以符合key_part2 = 'a'的二级索引记录可能并不相邻,也就意味着我们不能通过这个key_part2 = 'a'搜索条件来减少需要扫描的记录数量。在这种情况下,我们是不会使用idx_key_part索引执行查询的。
对于下边这个查询Q7来说:
Q7:SELECT * FROM single_table WHERE key_part1 = 'a' AND key_part3 = 'c';
由于二级索引记录是先按照key_part1列的值进行排序的,所以符合key_part1 = 'a'条件的二级索引记录肯定是相邻的,但是对于符合key_part1 = 'a'条件的二级索引记录来说,并不是直接按照key_part3列进行排序的,也就是说我们不能根据搜索条件key_part3 = 'c'来进一步减少需要扫描的记录数量。那么如果我们使用idx_key_part索引执行查询的话,可以定位到第一条符合key_part1='a'条件的记录,然后沿着记录所在的单向链表向后扫描,直到某条记录不符合key_part1 = 'a'条件为止。所以在使用idx_key_part索引执行查询Q7的过程中,对应的扫描区间其实是['a', 'a'],形成该扫描区间的搜索条件是key_part1 = 'a',与key_part3 = 'c'无关。
小贴士:针对获取到的每一条二级索引记录,如果没有开启索引条件下推特性的话,则必须先进行回表操作,获取到完整的用户记录后再判断key_part3 = 'c'这个条件是否成立;如果开启了索引条件下推特性的话,可以立即判断该二级索引记录是否符合key_part3 = 'c'这个条件,如果符合则再进行回表操作,如果不符合则不进行回表操作,直接跳到下一条二级索引记录。索引条件下推特性是在MySQL 5.6中引入的,默认是开启的。
对于下边这个查询Q8来说:
Q8:SELECT * FROM single_table WHERE key_part1 < 'b' AND key_part2 = 'a';
由于二级索引记录是先按照key_part1列的值进行排序的,所以符合key_part1 < 'b'条件的二级索引记录肯定是相邻的,但是对于符合key_part1 < 'b'条件的二级索引记录来说,并不是直接按照key_part2列进行排序的,也就是说我们不能根据搜索条件key_part2 = 'a'来进一步减少需要扫描的记录数量。那么如果我们使用idx_key_part索引执行查询的话,可以定位到第一条符合key_part1<'b'条件的记录(其实就是idx_key_part索引第一个叶子节点的第一条记录),然后沿着记录所在的单向链表向后扫描,直到某条记录不符合key_part1 < 'b'条件为止,如下图所示。
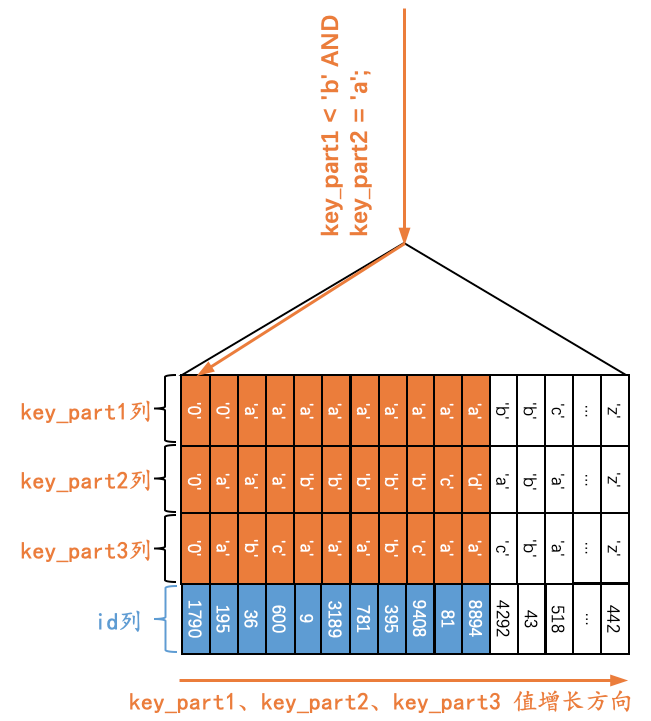
所以在使用idx_key_part索引执行查询Q8的过程中,对应的扫描区间其实是[-∞, 'b'),形成该扫描区间的搜索条件是key_part1 < 'b',与key_part2 = 'a'无关。
对于下边这个查询Q9来说:
Q9:SELECT * FROM single_table WHERE key_part1 <= 'b' AND key_part2 = 'a';
很显然Q8和Q9长得非常像,只不过在涉及key_part1的条件中,Q8中的条件是key_part1 < 'b',Q9中的条件是key_part1 <= 'b'。很显然符合key_part1 <= 'b'条件的二级索引记录是相邻的,但是对于符合key_part1 <= 'b'条件的二级索引记录来说,并不是直接按照key_part2列进行排序的。但是,我这里说但是哈,对于符合key_part1 = 'b'的二级索引记录来说,是按照key_part2列的值进行排序的。那么我们在确定需要扫描的二级索引记录的范围时,当二级索引记录的key_part1列值为'b'时,我们也可以通过key_part2 = 'a'这个条件来减少需要扫描的二级索引记录范围,也就是说当我们扫描到第一条不符合 key_part1 = 'b' AND key_part2 = 'a'条件的记录时,就可以结束扫描,而不需要将所有key_part1列值为'b'的记录扫描完,示意图如下:
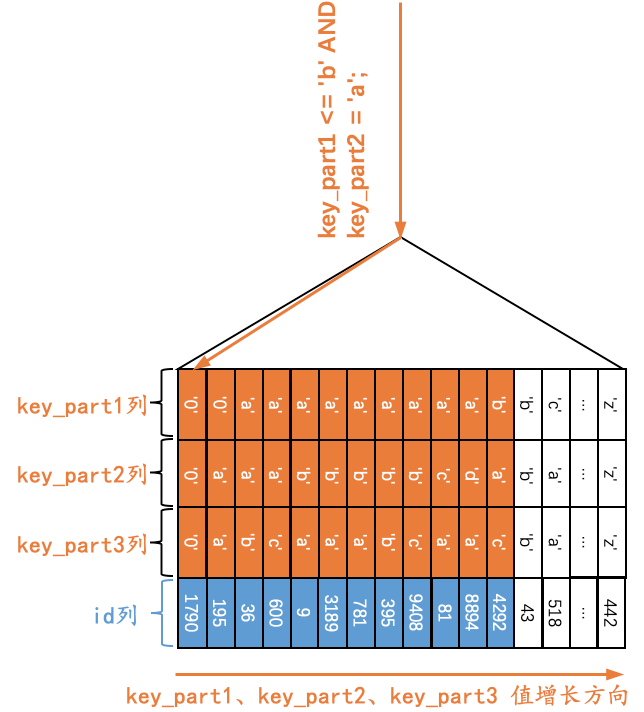
也就是说,如果我们使用idx_key_part索引执行查询Q9时,可以形成扫描区间((-∞, -∞), ('b', 'a')),形成这个扫描区间的条件就是key_part1 <= 'b' AND key_part2 = 'a'。对比查询Q8,我们必须将所有符合key_part1 < 'b'的记录都扫描完,key_part2 = 'a'这个条件在查询Q8中并不能起到减少需要扫描的二级索引记录范围的作用。
可能将查询Q9转换为下边的这个形式后更容易理解使用idx_key_part索引执行它时对应的扫描区间以及形成扫描区间的条件:
SELECT * FROM single_table WHERE (key_part1 < 'b' AND key_part2 = 'a') OR (key_part1 = 'b' AND key_part2 = 'a');
设计MySQL的大叔为何偏爱ref
标签(空格分隔): 公众号文章
回忆一下查询成本
对于一个查询来说,有时候可以通过不同的索引或者全表扫描来执行它,MySQL优化器会通过事先生成的统计数据,或者少量访问B+树索引的方式来分析使用各个索引时都需要扫描多少条记录,然后计算使用不同索引的查询成本,最后选择成本最低的那个来执行查询。
小贴士:我们之前称那种通过少量访问B+树索引来分析需要扫描的记录数量的方式称为index dive,不知道大家还有没有印象。
一个很简单的思想就是:使用某个索引执行查询时,需要扫描的记录越少,就越可能使用这个索引来执行查询。
创建场景
假如我们现在有一个表t,它的表结构如下所示:
CREATE TABLE t (id INT NOT NULL AUTO_INCREMENT PRIMARY KEY,key1 VARCHAR(100),common_field VARCHAR(100),INDEX idx_key1 (key1)) ENGINE=InnoDB CHARSET=utf8;
这个表包含3个列:
- id列是自增主键
- key1列用于存储字符串,我们为key1列建立了一个普通的二级索引
- common_field列用于存储字符串
现在该表中共有10000条记录:
mysql> SELECT COUNT(*) FROM t;+----------+| COUNT(*) |+----------+| 10000 |+----------+1 row in set (2.65 sec)
其中key1列为'a'的记录有2310条:
mysql> SELECT COUNT(*) FROM t WHERE key1 = 'a';+----------+| COUNT(*) |+----------+| 2310 |+----------+1 row in set (0.83 sec)
key1列在'a'到'i'之间的记录也有2310条:
mysql> SELECT COUNT(*) FROM t WHERE key1 > 'a' AND key1 < 'i';+----------+| COUNT(*) |+----------+| 2310 |+----------+1 row in set (1.31 sec)
现在我们有如下两个查询:
查询1:SELECT * FROM t WHERE key1 = 'a';查询2:SELECT * FROM t WHERE key1 > 'a' AND key1 < 'i';
按理说上边两个查询需要扫描的记录数量是一样的,MySQL查询优化器对待它们的态度也应该是一样的,也就是要么都使用二级索引idx_key1执行它们,要么都使用全表扫描的方式来执行它们。不过现实是貌似查询优化器更喜欢查询1,而比较讨厌查询2。查询1的执行计划如下所示:
# 查询1的执行计划mysql> EXPLAIN SELECT * FROM t WHERE key1 = 'a'\G*************************** 1. row ***************************id: 1select_type: SIMPLEtable: tpartitions: NULLtype: refpossible_keys: idx_key1key: idx_key1key_len: 303ref: constrows: 2310filtered: 100.00Extra: NULL1 row in set, 1 warning (0.04 sec)
查询2的执行计划如下所示:
# 查询2的执行计划mysql> EXPLAIN SELECT * FROM t WHERE key1 > 'a' AND key1 < 'i'\G*************************** 1. row ***************************id: 1select_type: SIMPLEtable: tpartitions: NULLtype: ALLpossible_keys: idx_key1key: NULLkey_len: NULLref: NULLrows: 9912filtered: 23.31Extra: Using where1 row in set, 1 warning (0.03 sec)
很显然,查询优化器决定使用idx_key1二级索引执行查询1,而使用全表扫描来执行查询2。
为什么?凭什么?同样是扫描相同数量的记录,凭什么我range访问方法就要比你ref低一头?设计MySQL的大叔,你为何这么偏心...
解密偏心原因
世界上没有无缘无故的爱,也没有无缘无故的恨。这事儿还得从索引结构说起。比方说idx_key1二级索引结构长这样:
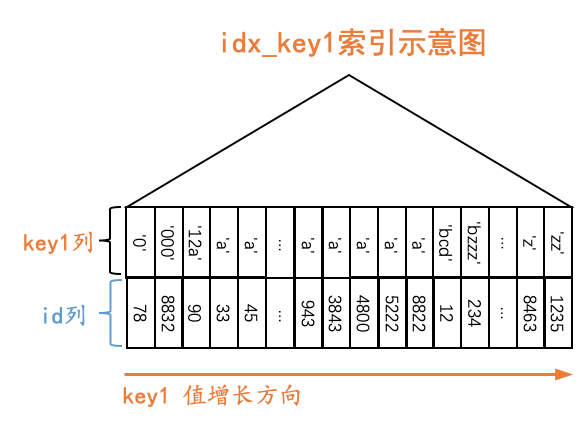
原谅我们把索引对应的B+树结构弄了一个极度精简版,我们忽略掉了页的结构,只保留了叶子节点的记录。虽然极度精简,但是我们还是保留了一个极其重要的特性:B+树叶子节点中的记录是按照索引列的值从小到大排序的。对于二级索引idx_key1来说:
- 二级索引叶子节点的记录只保留key1列和id列
- 二级索引记录是先按照key1列的值从小到大的顺序进行排序的。
- 如果key1列的值相同,则按照主键值,也就是id列的值从小到大的顺序进行排序。
也就是说,对于所有key1值为'a'的二级索引记录来说,它们都是按照id列的值进行排序的。对于查询1:
查询1: SELECT * FROM t WHERE key1 = 'a';
由于查询列表是* ,也就是说我们需要通过读取到的二级索引记录的id值执行回表操作,到聚簇索引中找到完整的用户记录(为了去获取common_field列的值)后才可以将记录发送到客户端。对于所有key1列值等于'a'的二级索引记录,由于它们是按照id列的值排序的,所以:
前一次回表的id值所属的聚簇索引记录和下一次回表的id值所属的聚簇索引记录很大可能在同一个数据页中
即使前一次回表的id值所属的聚簇索引记录和下一次回表的id值所属的聚簇索引记录不在同一个数据页中,由于回表的id值是递增的,所以我们很大可能通过顺序I/O的方式找到下一个数据页,也就是说这个过程中很大可能不需要很大幅度的移动磁头就可以找到下一个数据页。这可以减少很多随机I/O带来的性能开销。
综上所属,执行语句1时,回表操作带来的性能开销较小。
而对于查询2来说:
查询2: SELECT * FROM t WHERE key1 > 'a' AND key1 < 'i';
由于需要扫描的二级索引记录对应的id值是无序的,所以执行回表操作时,需要访问的聚簇索引记录所在的数据页很大可能就是无序的,这样会造成很多随机I/O。所以如果使用idx_key1来执行查询1和查询2,执行查询1的成本很显然会比查询2低,这也是设计MySQL的大叔更钟情于ref而不是range的原因。
MySQL的内部实现
MySQL优化器在计算回表的成本时,在使用二级索引执行查询并且需要回表的情境下,对于ref和range是很明显的区别对待的:
对于range来说,需要扫描多少条二级索引记录,就相当于需要访问多少个页面。每访问一个页面,回表的I/O成本就加1。
比方对于查询2来说,需要回表的记录数是2310,因为回表操作而计算的I/O成本就是2310。
对于ref来说,回表开销带来的I/O成本存在天花板,也就是定义了一个上限值:
double worst_seeks;
这个上限值的取值是从下边两个值中取较小的那个:
- 全表记录数的十分之一(此处的全表记录数属于统计数据,是一个估计值)
- 聚簇索引所占页面的3倍
比方对于查询1来说,回表的记录数是2310,按理说计算因回表操作带来的I/O成本也应该是2310。但是由于对于ref访问方法,计算回表操作时带来的I/O成本时存在天花板,会从全表记录的十分之一(也就是9912/10=991,9912为估计值)以及聚簇索引所占页面的3倍(本例中聚簇索引占用的页面数就是97,乘以3就是291)选择更小的那个,本例中也就是291。
小贴士:在成本分析的代码中,range和index、all是被分到一类里的,ref是亲儿子,单独分析了一波。不过我们也可以看到,设计MySQL的大叔在计算range访问方法的代价时,直接认为每次回表都需要进行一次页面I/O,这是十分粗暴的,何况我们的实际聚簇索引总共才97个页面,它却将回表成本计算为2310,这也是很不精确的。当然,由于目前的算法无法预测哪些页面在内存中,哪些不在,所以也就将就将就用吧~
MySQL中NULL值引起的小锅
标签: 公众号文章
这一系列文章主要说明了一个道理:MySQL查询优化器决策是否使用某个索引执行查询时的依据是使用该索引的成本是否足够低,而成本很大程度上取决于需要扫描的二级索引记录数量占表中所有记录数量的比例。
innodb_stats_method的作用
我们知道索引列不重复的值的数量这个统计数据对于MySQL查询优化器十分重要,因为通过它可以计算出在索引列中平均一个值重复多少行,它的应用场景主要有两个:
单表查询中单点区间太多,比方说这样:
SELECT * FROM tbl_name WHERE key IN ('xx1', 'xx2', ..., 'xxn');
当
IN里的参数数量过多时,采用index dive的方式直接访问B+树索引去同步统计每个单点区间对应的记录的数量就太耗费性能了,所以直接依赖统计数据中的平均一个值重复多少行来计算单点区间对应的记录数量。连接查询时,如果有涉及两个表的等值匹配连接条件,该连接条件对应的被驱动表中的列又拥有索引时,则可以使用
ref访问方法来对被驱动表进行查询,比方说这样:SELECT * FROM t1 JOIN t2 ON t1.column = t2.key WHERE ...;
在真正执行对
t2表的查询前,t1.comumn的值是不确定的,所以我们也不能通过index dive的方式直接访问B+树索引去同步统计每个单点区间对应的记录的数量,所以也只能依赖统计数据中的平均一个值重复多少行来计算单点区间对应的记录数量。
在统计索引列不重复的值的数量时,有一个比较烦的问题就是索引列中出现NULL值怎么办,比方说某个索引列的内容是这样:
+------+| col |+------+| 1 || 2 || NULL || NULL |+------+
此时计算这个col列中不重复的值的数量就有下边的分歧:
有的人认为
NULL值代表一个未确定的值,所以设计MySQL的大叔才认为任何和NULL值做比较的表达式的值都为NULL,就是这样:mysql> SELECT 1 = NULL;+----------+| 1 = NULL |+----------+| NULL |+----------+1 row in set (0.00 sec)mysql> SELECT 1 != NULL;+-----------+| 1 != NULL |+-----------+| NULL |+-----------+1 row in set (0.00 sec)mysql> SELECT NULL = NULL;+-------------+| NULL = NULL |+-------------+| NULL |+-------------+1 row in set (0.00 sec)mysql> SELECT NULL != NULL;+--------------+| NULL != NULL |+--------------+| NULL |+--------------+1 row in set (0.00 sec)
所以每一个
NULL值都是独一无二的,也就是说统计索引列不重复的值的数量时,应该把NULL值当作一个独立的值,所以col列的不重复的值的数量就是:4(分别是1、2、NULL、NULL这四个值)。有的人认为其实
NULL值在业务上就是代表没有,所有的NULL值代表的意义是一样的,所以col列不重复的值的数量就是:3(分别是1、2、NULL这三个值)。有的人认为这
NULL完全没有意义嘛,所以在统计索引列不重复的值的数量时压根儿不能把它们算进来,所以col列不重复的值的数量就是:2(分别是1、2这两个值)。
设计MySQL的大叔蛮贴心的,他们提供了一个名为innodb_stats_method的系统变量,相当于在计算某个索引列不重复值的数量时如何对待NULL值这个锅甩给了用户,这个系统变量有三个候选值:
nulls_equal:认为所有NULL值都是相等的。这个值也是innodb_stats_method的默认值。如果某个索引列中
NULL值特别多的话,这种统计方式会让优化器认为某个列中平均一个值重复次数特别多,所以倾向于不使用索引进行访问。nulls_unequal:认为所有NULL值都是不相等的。如果某个索引列中
NULL值特别多的话,这种统计方式会让优化器认为某个列中平均一个值重复次数特别少,所以倾向于使用索引进行访问。nulls_ignored:直接把NULL值忽略掉。
反正这个锅是甩给用户了,当你选定了innodb_stats_method值之后,优化器即使选择了不是最优的执行计划,那也跟设计MySQL的大叔们没关系了哈~ 当然对于用户的我们来说,最好不在索引列中存放NULL值才是正解。
两种不同的统计数据存储方式
InnoDB提供了两种存储统计数据的方式:
永久性的统计数据
这种统计数据存储在磁盘上,也就是服务器重启之后这些统计数据还在。
非永久性的统计数据
这种统计数据存储在内存中,当服务器关闭时这些这些统计数据就都被清除掉了,等到服务器重启之后,在某些适当的场景下才会重新收集这些统计数据。
设计MySQL的大叔们给我们提供了系统变量innodb_stats_persistent来控制到底采用哪种方式去存储统计数据。在MySQL 5.6.6之前,innodb_stats_persistent的值默认是OFF,也就是说InnoDB的统计数据默认是存储到内存的,之后的版本中innodb_stats_persistent的值默认是ON,也就是统计数据默认被存储到磁盘中。
不过InnoDB默认是以表为单位来收集和存储统计数据的,也就是说我们可以把某些表的统计数据(以及该表的索引统计数据)存储在磁盘上,把另一些表的统计数据存储在内存中。怎么做到的呢?我们可以在创建和修改表的时候通过指定STATS_PERSISTENT属性来指明该表的统计数据存储方式:
CREATE TABLE 表名 (...) Engine=InnoDB, STATS_PERSISTENT = (1|0);ALTER TABLE 表名 Engine=InnoDB, STATS_PERSISTENT = (1|0);
当STATS_PERSISTENT=1时,表明我们想把该表的统计数据永久的存储到磁盘上,当STATS_PERSISTENT=0时,表明我们想把该表的统计数据临时的存储到内存中。如果我们在创建表时未指定STATS_PERSISTENT属性,那默认采用系统变量innodb_stats_persistent的值作为该属性的值。
问题
有同学在小册群中反应在使用基于磁盘的统计数据时,将innodb_stats_method系统变量设置成不同的值,但是发现对应的统计数据却并未发生预想的变化(可以通过SHOW INDEX FROM tbl_name或者查看mysql数据库下的innodb_index_stats表),这到底是因为啥呢?
原因
我一开始也对这个现象有点儿疑惑🤔,于是不得不再次打开看吐了的源码来看。
比较两条记录是否相同的函数是
cmp_rec_rec_with_match,如下图所示: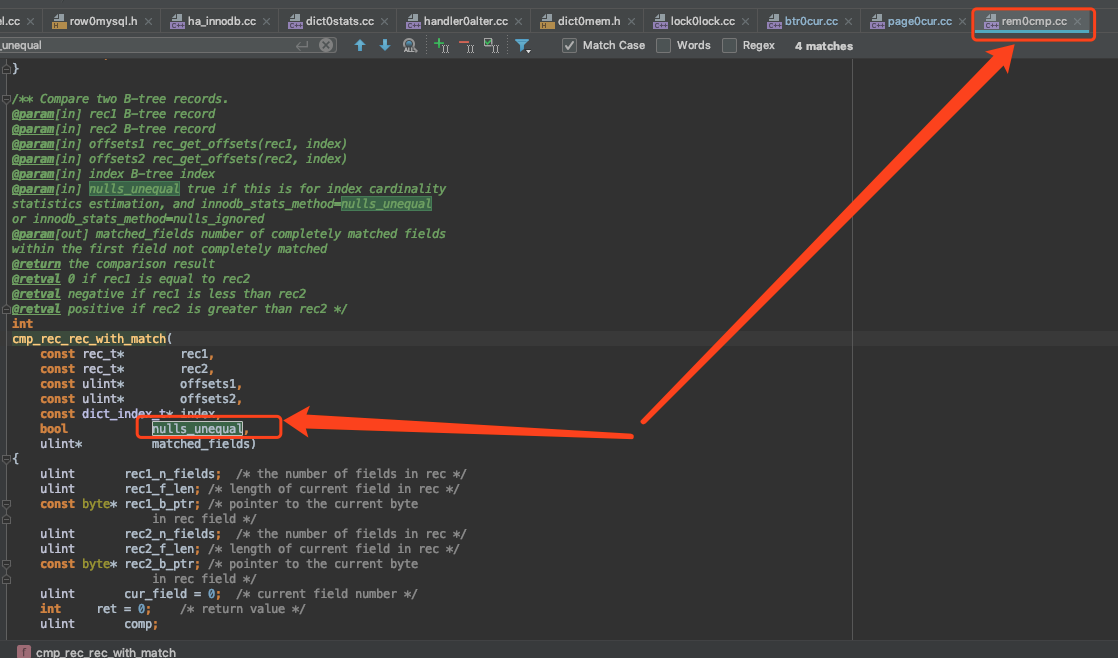
其中的
nulls_unequal参数是用来区别是否将两个null值认为是相等的。在计算基于磁盘的统计数据时,是这样调用该函数的:
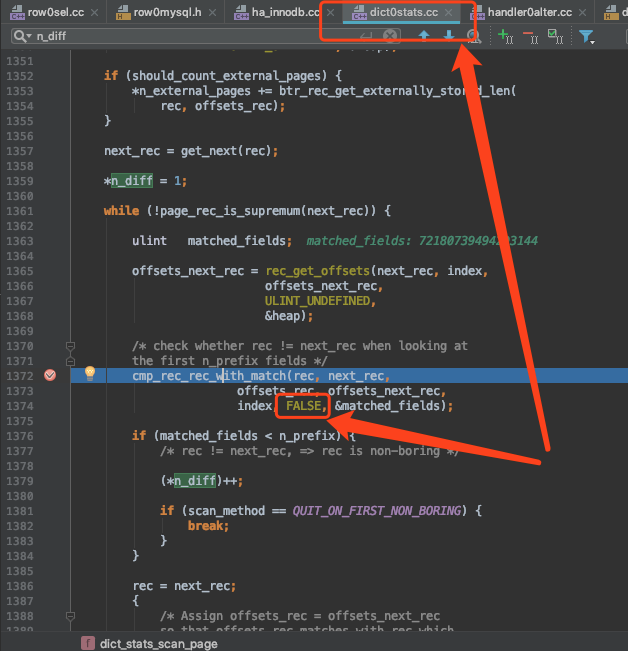
可以看到
nulls_unequal参数是硬编码为FALSE。在计算基于内存的统计数据时,是这样调用该函数的:
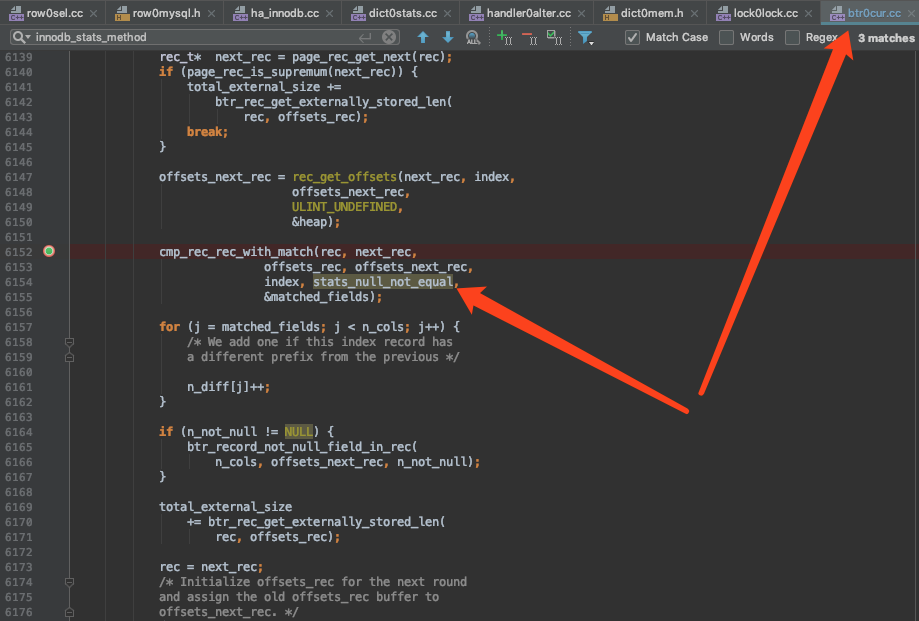
可以看到这种调用的方式就是正常的。
从实践来看,在计算基于内存的统计数据时,改变系统变量innodb_stats_method的值是起作用的,但是在计算基于磁盘的统计数据时,改变该系统变量的值是无效的。我也并不知道设计InnoDB的大叔为什么这么写,翻了翻代码也没看见这么写有什么特别的注释,之后还特意去看了MySQL文档中关于统计数据收集的相关章节,也没发现有特别声明这两者的区别。可能是一个bug?或者有啥深层次的含义?有知道的同学可以留言哈~
MySQL使用索引执行IN子句
标签: 公众号文章
对于开发小伙伴来说,对MySQL中的包含IN子句的语句肯定熟悉的不能再熟悉了,几乎天天用,时时用。可是很多小伙伴不知道包含IN子句的语句是怎样执行的,在一些查询优化的场景中就开始找不着北了,本篇文章就来唠叨一下MySQL中的IN语句是怎样执行的(以MySQL 5.7的InnoDB存储引擎为例)。
准备工作
为了故事的顺利发展,我们先创建一个表:
CREATE TABLE t (id INT NOT NULL AUTO_INCREMENT,key1 VARCHAR(100),common_field VARCHAR(100),PRIMARY KEY (id),KEY idx_key1 (key1)) Engine=InnoDB CHARSET=utf8;
可以看到表t中包含两个索引:
- 以
id列为主键的聚簇索引 - 为
key1列建立的二级索引
这个表里边现在有10000条数据:
mysql> SELECT COUNT(*) FROM t;+----------+| COUNT(*) |+----------+| 10000 |+----------+1 row in set (0.00 sec)
从B+树中定位记录
我们现在想执行下边这个语句:
SELECT * FROM t WHEREkey1 >= 'b' AND key1 <= 'c';
假设优化器选择使用二级索引来执行查询,那么查询语句的执行示意图就如下图所示:
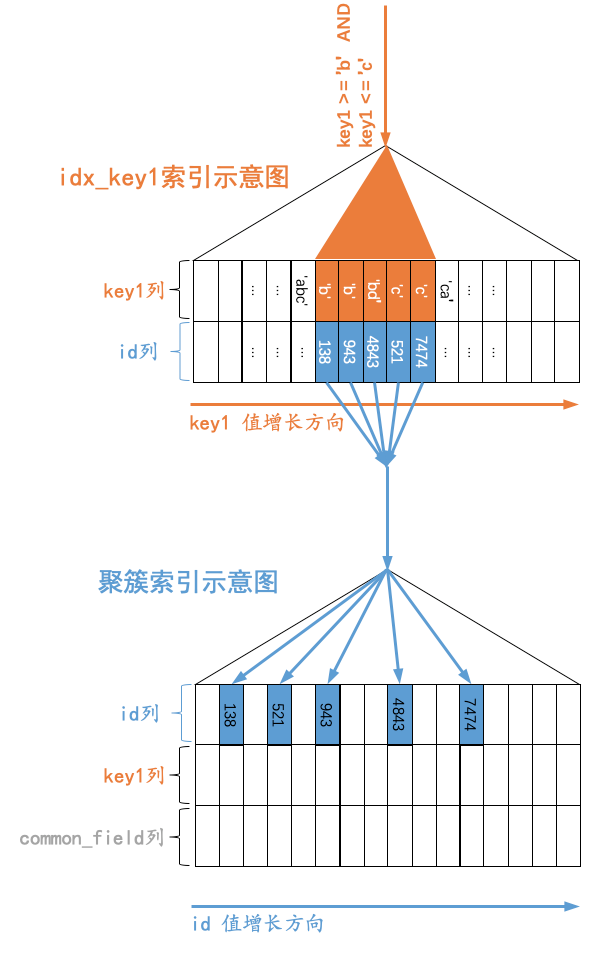
小贴士:原谅我把索引对应的复杂的B+树结构搞了一个极度精简版,为了突出重点,我们忽略掉了页的结构,直接把所有的叶子节点的记录都放在一起展示。我们想突出的重点就是:B+树叶子节点中的记录是按照索引列值大小排序的,对于的聚簇索引来说,它对应的B+树叶子节点中的记录就是按照id列排序的,对于idx_key1二级索引来说,它对应的B+树叶子节点中的记录就是按照key1列排序的。
我们想查询key1列的值在['b', 'c']这个区间中的记录,那么就需要:
先通过
idx_key1索引对应的B+树快速定位到key1列值为'b'、并且最靠左的那条二级索引记录,该二级索引记录中包含着对应的主键值,根据这个主键值再到聚簇索引中定位到完整的记录(这个过程称之为回表),将其返回给server层,server层再发送给客户端。记录按照键值由小到大的顺序排列成一个单链表的形式,所以我们可以沿着这个单链表接着定位到下一条二级索引记录,并且执行回表操作,将完整的记录交给server层之后发送给客户端。
继续沿着记录的单向链表查找,重复上述过程,直到找到的二级索引记录的key1列的值不满足
key1 <= 'c'的这个条件,如图所示,也就是当我们在idx_key1二级索引中找到了key1='ca'的那条记录后,发现它不符合key1 <= 'c'的条件,所以就停止查找。
上述过程就是通过B+树查找一个键值在某一个范围区间的记录的过程。
包含IN子句的执行过程
如果我们想执行下边这个语句:
SELECT * FROM t WHEREkey1 IN ('b', 'c');
如果优化器选择使用二级索引执行上述语句,那它是如何执行的呢?
优化器会将IN子句中的条件看成是2个范围区间(虽然这两个区间中都仅仅包含一个值):
['b', 'b']['c', 'c']
那么在语句执行过程中就需要通过B+树去定位两次记录所在的位置:
先定位键值在范围区间
['b', 'b']的记录:先通过
idx_key1索引对应的B+树快速定位到key1列值为'b'、并且最靠左的那条二级索引记录,之后回表将其发送给server 层后再发送给客户端。再沿着记录组成的单链表把符合
key1=b的二级索引记录找到,并且回表后发送给server层,之后再发送给客户端。重复上述过程,直到找到的二级索引记录的key1列的值不满足
key1 = 'b'的这个条件为止。
再定位键值在范围区间
['c', 'c']的记录:查找过程类似,就不多赘述了。
所以如果你写的IN语句中的参数越多,意味着需要通过B+树定位记录的次数就越多。
IN子句中参数值重复的情况
比方说下边这条语句:
SELECT * FROM t WHEREkey1 IN ('b', 'b', 'b', 'b', 'b', 'b', 'b', 'b', 'b');
虽然IN子句中包含好多个参数,但MySQL在语法解析的时候只会为其生成一个范围区间,那就是:['b', 'b']。
IN子句的参数顺序问题
比方说下边这条语句:
SELECT * FROM t WHERE key1 IN ('c', 'b');
IN ('c', 'b')和IN ('b', 'c')有啥差别么?也就是存储引擎在对待IN ('c', 'b')子句时,会先去找key1 = 'c'的记录,再去找key1 = 'b'的记录么?如果是这样的话,下边两条语句岂不是可能发生死锁:
事务T1中的语句一:SELECT * FROM t WHEREkey1 IN ('b', 'c') FOR UPDATE;事务T2中的语句二:SELECT * FROM t WHEREkey1 IN ('c', 'b') FOR UPDATE;
放心,在生成范围区间的时候,自然是将范围区间排了序,也就是即使条件是IN ('c', 'b'),那优化器也会先让存储引擎去找键值在['b', 'b']这个范围区间中的记录,然后再去找键值在['c', 'c']这个范围区间中的记录。
系统变量eq_range_index_dive_limit对IN子句的影响
大家一定要记着:MySQL优化器决定使用某个索引执行查询的仅仅是因为:使用该索引时的成本足够低。也就是说即使我们有下边的语句:
SELECT * FROM t WHEREkey1 IN ('b', 'c');
MySQL优化器需要去分析一下如果使用二级索引idx_key1执行查询的话,键值在['b', 'b']和['c', 'c']这两个范围区间的记录共有多少条,然后通过一定方式计算出成本,与全表扫描的成本相对比,选取成本更低的那种方式执行查询。
在计算查询成本的这一步骤中大家需要注意,对于包含IN子句条件的查询来说,需要依次分析一下每一个范围区间中的记录数量是多少。MySQL优化器针对IN子句对应的范围区间的多少而指定了不同的策略:
如果IN子句对应的范围区间比较少,那么将率先去访问一下存储引擎,看一下每个范围区间中的记录有多少条(如果范围区间的记录比较少,那么统计结果就是精确的,反之会采用一定的手段计算一个模糊的值,当然算法也比较麻烦,我们就不展开说了,小册里有说),这种在查询真正执行前优化器就率先访问索引来计算需要扫描的索引记录数量的方式称之为index dive。
如果IN子句对应的范围区间比较多,这样就不能采用index dive的方式去真正的访问二级索引idx_key1(因为那将耗费大量的时间),而是需要采用之前在背地里产生的一些统计数据去估算匹配的二级索引记录有多少条(很显然根据统计数据去估算记录条数比index dive的方式精确性差了很多)。
那什么时候采用index dive的统计方式,什么时候采用index statistic的统计方式呢?这就取决于系统变量eq_range_index_dive_limit的值了,我们看一下在我的机器上该系统变量的值:
mysql> SHOW VARIABLES LIKE 'eq_range_index_dive_limit';+---------------------------+-------+| Variable_name | Value |+---------------------------+-------+| eq_range_index_dive_limit | 200 |+---------------------------+-------+1 row in set (0.20 sec)
可以看到它的默认值是200,这也就意味着当范围区间个数小于200时,将采用index dive的统计方式,否则将采用index statistic的统计方式。
不过这里需要大家特别注意,在MySQL 5.7.3以及之前的版本中,eq_range_index_dive_limit的默认值为10。所以如果大家采用的是5.7.3以及之前的版本的话,很容易采用索引统计数据而不是index dive的方式来计算查询成本。当你的查询中使用到了IN查询,但是却实际没有用到索引,就应该考虑一下是不是由于 eq_range_index_dive_limit 值太小导致的。
MySQL的COUNT语句是怎么执行的
标签: 公众号文章
众多开发小伙伴在写业务逻辑的时候都会有一个统计行数的需求,此时COUNT函数便成为了首选。但是大家发现,随着数据量的增长,COUNT执行的越来越慢,本文从源码的角度来帮助小伙伴们分析一下MySQL中的COUNT函数是如何执行的。
需要声明一点,本文所使用的MySQL源码版本是5.7.22,并且只针对InnoDB存储引擎。在深入介绍之前需要大家具有一些前置知识,才可以顺利讨论。
前置知识1——InnoDB的B+树索引
为了故事的顺利发展,我们引入一个表:
CREATE TABLE t (id INT UNSIGNED NOT NULL AUTO_INCREMENT,key1 INT,common_field VARCHAR(100),PRIMARY KEY (id),KEY idx_key1 (key1)) Engine=InnoDB CHARSET=utf8;
这个表就包含2个索引(也就是2棵B+树):
以
id列为主键对应的聚簇索引。为
key1列建立的二级索引idx_key1。
我们向表中插入一些记录:
INSERT INTO t VALUES(1, 30, 'b'),(2, 80, 'b'),(3, 23, 'b'),(4, NULL, 'b'),(5, 11, 'b'),(6, 53, 'b'),(7, 63, 'b'),(8, NULL, 'b'),(9, 99, 'b'),(10, 12, 'b'),(11, 66, 'b'),(12, NULL, 'b'),(13, 66, 'b'),(14, 30, 'b'),(15, 11, 'b'),(16, 90, 'b');
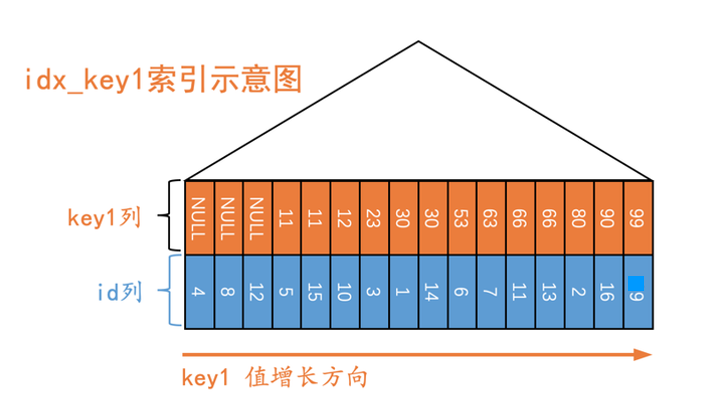
所以现在t表的聚簇索引示意图就是这样:

t表的二级索引示意图就是这样:
小贴士:
原谅我们画了一个极度简化版的B+树:我们省略了B+树中的页面节点,省略了每层页面节点之间的双向链表,省略了页面中记录的单向链表,省略了页面中的页目录结构,还有省略了好多东西。但是我们保留B+树最为核心的一个特点:记录是按照键值大小进行排序的。即对于聚簇索引来说,记录是按照id列进行排序的;对于二级索引idx_key1来说,记录是按照key1列进行排序的,在key1列相同时再按照id列进行排序。
从上边聚簇索引和二级索引的结构中大家可以发现:每一条聚簇索引记录都可以在二级索引中找到唯一的一条二级索引记录与其相对应。
前置知识2——server层和存储引擎的交互
以下边这个查询为例:
SELECT * FROM t WHERE key1 > 70 AND common_field != 'a';
假设优化器认为通过扫描二级索引idx_key1中key1值在(70, +∞)这个区间中的二级索引记录的成本更小,那么查询将以下述方式执行:
server层先让InnoDB去查在key1值在(70, +无穷)区间中的第一条记录。
InnoDB通过二级索引idx_key1对应的B+树,从B+树根页面一层一层向下定位,快速找到(70, +无穷)区间的第一条二级索引记录,然后根据该二级索引记录进行回表操作,找到完整的聚簇索引记录,然后返回给server层。
server层判断InnoDB返回的记录符不符合搜索条件
key1 > 70 AND common_field != 'a',如果不符合的话就跳过该记录,否则将其发送到客户端。
小贴士:
此处将记录发送给客户端其实是发送到本地的网络缓冲区,缓冲区大小由net_buffer_length控制,默认是16KB大小。等缓冲区满了才真正发送网络包到客户端。
然后server层向InnoDB要下一条记录。
InnoDB根据上一次找到的二级索引记录的next_record属性,获取到下一条二级索引记录,回表后将完整的聚簇索引记录返回给server层。
server继续判断,不符合搜索条件即跳过该记录,否则发送到客户端。
... 一直循环上述过程,直到InnoDB找不到下一条记录,则向server层报告查询完毕。
server层收到InnoDB报告的查询完毕请求,停止查询。
可见,一般情况下server层和存储引擎层是以记录为单位进行交互的。
我们看一下源码中读取一条记录的函数调用栈:
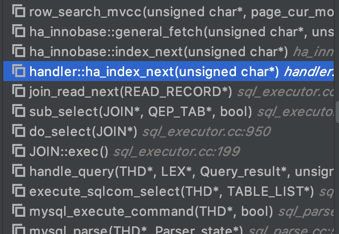
其中的handler::ha_index_next便是server层向存储引擎要下一条记录的接口。
其中的row_search_mvcc是读取一条记录最重要的函数,这个函数长的吓人,有一千多行:
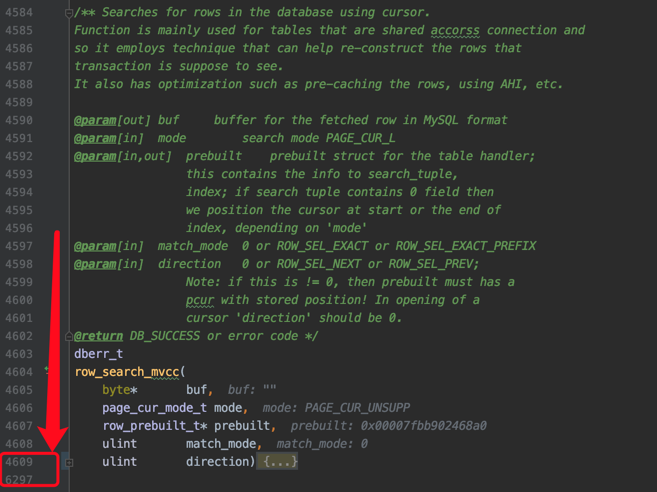
每读取一条记录,都要做非常多的工作,诸如进行多版本的可见性判断,要不要对记录进行加锁的判断,要是加锁的话加什么锁的选择,完成记录从InnoDB的存储格式到server层存储格式的转换等等等等十分繁杂的工作。
小贴士:
不知道你们公司有没有写这么长函数的同学,如果有的话你想不想打他。
前置知识3——COUNT是个啥
COUNT是一个汇总函数(聚集函数),它接收1个表达式作为参数:
COUNT(expr)
COUNT函数用于统计在符合搜索条件的记录中,指定的表达式expr不为NULL的行数有多少。这里需要特别注意的是,expr不仅仅可以是列名,其他任意表达式都是可以的。
比方说:
SELECT COUNT(key1) FROM t;
这个语句是用于统计在single_table表的所有记录中,key1列不为NULL的行数是多少。
再看这个:
SELECT COUNT('abc') FROM t;
这个语句是用于统计在single_table表的所有记录中,'abc'这个表达式不为NULL的行数是多少。很显然,'abc'这个表达式永远不是NULL,所以上述语句其实就是统计single_table表里有多少条记录。
再看这个:
SELECT COUNT(*) FROM t;
这个语句就是直接统计single_table表有多少条记录。
总结+注意:COUNT函数的参数可以是任意表达式,该函数用于统计在符合搜索条件的记录中,指定的表达式不为NULL的行数有多少。
MySQL中COUNT是怎样执行的
做了那么多铺垫,终于到了MySQL中COUNT是怎样执行的了。
以下边这个语句为例:
SELECT COUNT(*) FROM t;
这个语句是要去查询表t中共包含多少条记录。由于聚簇索引和二级索引中的记录是一一对应的,而二级索引记录中包含的列是少于聚簇索引记录的,所以同样数量的二级索引记录可以比聚簇索引记录占用更少的存储空间。如果我们使用二级索引执行上述查询,即数一下idx_key1中共有多少条二级索引记录,是比直接数聚簇索引中共有多少聚簇索引记录可以节省很多I/O成本。所以优化器会决定使用idx_key1执行上述查询:
mysql> EXPLAIN SELECT COUNT(*) FROM t;+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-------------+| 1 | SIMPLE | t | NULL | index | NULL | idx_key1 | 5 | NULL | 16 | 100.00 | Using index |+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-------------+1 row in set, 1 warning (0.02 sec)
在执行上述查询时,server层会维护一个名叫count的变量,然后:
server层向InnoDB要第一条记录。
InnoDB找到idx_key1的第一条二级索引记录,并返回给server层(注意:由于此时只是统计记录数量,所以并不需要回表)。
由于COUNT函数的参数是
*,MySQL会将*当作常数0处理。由于0并不是NULL,server层给count变量加1。server层向InnoDB要下一条记录。
InnoDB通过二级索引记录的next_record属性找到下一条二级索引记录,并返回给server层。
server层继续给count变量加1。
... 重复上述过程,直到InnoDB向server层返回没记录可查的消息。
server层将最终的count变量的值发送到客户端。
我们看一下源码里给count变量加1的代码是怎么写的:

其大意就是判断一下COUNT里的表达式是不是NULL,如果不是NULL的话就给count变量加1。
我们再来看一下arg_is_null的实现:

其中最重要的是我们标蓝的那一行,item[i]表示的就是COUNT函数中的参数,我们调试一下对于COUNT(*)来说,表达式*的值是什么:

可以看到,*表达式的类型其实是Item_int,这表示MySQL其实会把*当作一个整数处理,它的值是0(见图中箭头)。也就是说我们在判断表达式*是不是为NULL,也就是在判断整数0是不是为NULL,很显然不为NULL。
那COUNT(1),COUNT(id),COUNT(非主键列)呢?
那在执行COUNT(1)呢?比方说下边这个语句:
SELECT COUNT(1) FROM t;
我们看一下:

可以看到,常数1对应的类型其实是PTI_num_literal_num,它其实是Item_int的一个包装类型,本质上还是代表一个整数,它的值是1(见图中箭头)。也就是说我们其实是在判断表达式1是不是为NULL,很显然不为NULL。
再看一下COUNT(id):
SELECT COUNT(id) FROM t;
我们看一下:
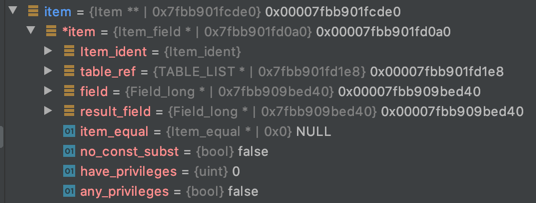
可以看到,id对应的类型是Item_field,代表一个字段。
对于COUNT(*)、COUNT(1)或者任意的COUNT(常数)来说,读取哪个索引的记录其实并不重要,因为server层只关心存储引擎是否读到了记录,而并不需要从记录中提取指定的字段来判断是否为NULL。所以优化器会使用占用存储空间最小的那个索引来执行查询。
对于COUNT(id)来说,由于id是主键,不论是聚簇索引记录,还是任意一个二级索引记录中都会包含主键字段,所以其实读取任意一个索引中的记录都可以获取到id字段,此时优化器也会选择占用存储空间最小的那个索引来执行查询。
而对于COUNT(非主键列)来说,我们指定的列可能并不会包含在每一个索引中。这样优化器只能选择包含我们指定的列的索引去执行查询,这就可能导致优化器选择的索引并不是最小的那个。
总结一下
对于COUNT(*)、COUNT(常数)、COUNT(主键)形式的COUNT函数来说,优化器可以选择最小的索引执行查询,从而提升效率,它们的执行过程是一样的,只不过在判断表达式是否为NULL时选择不同的判断方式,这个判断为NULL的过程的代价可以忽略不计,所以我们可以认为COUNT(*)、COUNT(常数)、COUNT(主键)所需要的代价是相同的。
而对于COUNT(非主键列)来说,server层必须要从InnoDB中读到包含非主键列的记录,所以优化器并不能随心所欲的选择最小的索引去执行。
我想改进一下?
我们知道,InnoDB的记录都是存储在数据页中的(页面大小默认为16KB),而每个数据页的Page Header部分都有一个统计当前页面中记录数量的属性PAGE_N_RECS。那有的同学说了:在执行COUNT函数的时候直接去把各个页面的这个PAGE_N_RECS属性加起来不就好了么?
答案是:行不通的!对于普通的SELECT语句来说,每次查询都要从记录的版本链上找到可见的版本才算是读到了记录;对于加了FOR UPDATE或LOCK IN SHARE MODE后缀的SELECT语句来说,每次查询都要给记录添加合适的锁。所以这个读取每一条记录的过程(就是上边给出的row_search_mvcc函数)在InnoDB的目前实现中是无法跳过的,InnoDB还是得老老实实的读一条记录,返给server层一条记录。
那如果我的业务中有COUNT需求,但是由于数据量太大导致即使优化器即使通过扫描二级索引记录的方式也还是太慢怎么办?既然业务上有需求,当然还是业务第一喽,我们可以在另一个地方存储一份待统计数据的行数,每次增删改记录都维护一下。
这样的解决方案显著增加了开发小伙伴的工作量,部分开发小伙伴肯定不太乐意,那就去怼你的产品经理吧:这么大数据量要TM什么精确值,你来告诉我这么大数据量要TM什么的TM的精确值?
MySQL的LIMIT这么差劲的吗
标签: 公众号文章
最近有多个小伙伴在答疑群里问了小孩子关于LIMIT的一个问题,下边我来大致描述一下这个问题。
问题
为了故事的顺利发展,我们得先有个表:
CREATE TABLE t (id INT UNSIGNED NOT NULL AUTO_INCREMENT,key1 VARCHAR(100),common_field VARCHAR(100),PRIMARY KEY (id),KEY idx_key1 (key1)) Engine=InnoDB CHARSET=utf8;
表t包含3个列,id列是主键,key1列是二级索引列。表中包含1万条记录。
当我们执行下边这个语句的时候,是使用二级索引idx_key1的:
mysql> EXPLAIN SELECT * FROM t ORDER BY key1 LIMIT 1;+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-------+| 1 | SIMPLE | t | NULL | index | NULL | idx_key1 | 303 | NULL | 1 | 100.00 | NULL |+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-------+1 row in set, 1 warning (0.00 sec)
这个很好理解,因为在二级索引idx_key1中,key1列是有序的。而查询是要取按照key1列排序的第1条记录,那MySQL只需要从idx_key1中获取到第一条二级索引记录,然后直接回表取得完整的记录即可。
但是如果我们把上边语句的LIMIT 1换成LIMIT 5000, 1,则却需要进行全表扫描,并进行filesort,执行计划如下:
mysql> EXPLAIN SELECT * FROM t ORDER BY key1 LIMIT 5000, 1;+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+| 1 | SIMPLE | t | NULL | ALL | NULL | NULL | NULL | NULL | 9966 | 100.00 | Using filesort |+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+1 row in set, 1 warning (0.00 sec)
有的同学就很不理解了:LIMIT 5000, 1也可以使用二级索引idx_key1呀,我们可以先扫描到第5001条二级索引记录,对第5001条二级索引记录进行回表操作不就好了么,这样的代价肯定比全表扫描+filesort强呀。
很遗憾的告诉各位,由于MySQL实现上的缺陷,不会出现上述的理想情况,它只会笨笨的去执行全表扫描+filesort,下边我们唠叨一下到底是咋回事儿。
server层和存储引擎层
大家都知道,MySQL内部其实是分为server层和存储引擎层的:
server层负责处理一些通用的事情,诸如连接管理、SQL语法解析、分析执行计划之类的东西
存储引擎层负责具体的数据存储,诸如数据是存储到文件上还是内存里,具体的存储格式是什么样的之类的。我们现在基本都使用InnoDB存储引擎,其他存储引擎使用的非常少了,所以我们也就不涉及其他存储引擎了。
MySQL中一条SQL语句的执行是通过server层和存储引擎层的多次交互才能得到最终结果的。比方说下边这个查询:
SELECT * FROM t WHERE key1 > 'a' AND key1 < 'b' AND common_field != 'a';
server层会分析到上述语句可以使用下边两种方案执行:
方案一:使用全表扫描
方案二:使用二级索引idx_key1,此时需要扫描key1列值在('a', 'b')之间的全部二级索引记录,并且每条二级索引记录都需要进行回表操作。
server层会分析上述两个方案哪个成本更低,然后选取成本更低的那个方案作为执行计划。然后就调用存储引擎提供的接口来真正的执行查询了。
这里假设采用方案二,也就是使用二级索引idx_key1执行上述查询。那么server层和存储引擎层的对话可以如下所示:
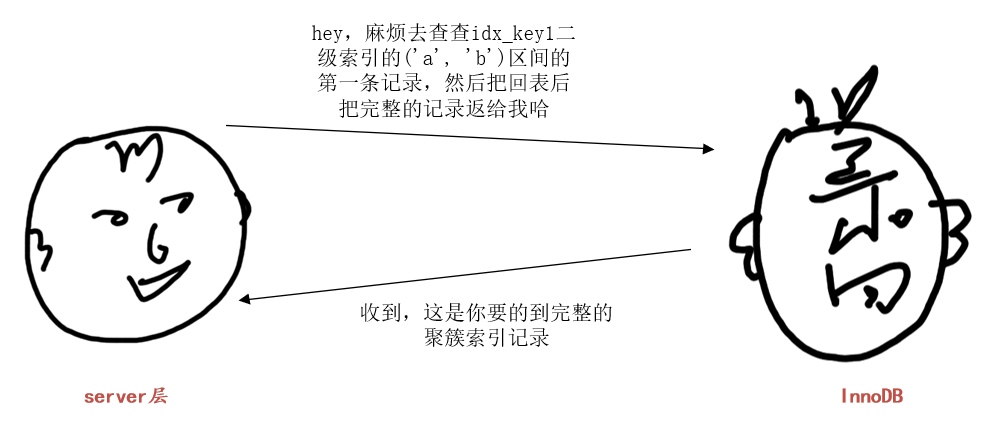
server层:“hey,麻烦去查查idx_key1二级索引的('a', 'b')区间的第一条记录,然后把回表后把完整的记录返给我哈”
InnoDB:“收到,这就去查”,然后InnoDB就通过idx_key1二级索引对应的B+树,快速定位到扫描区间('a', 'b')的第一条二级索引记录,然后进行回表,得到完整的聚簇索引记录返回给server层。
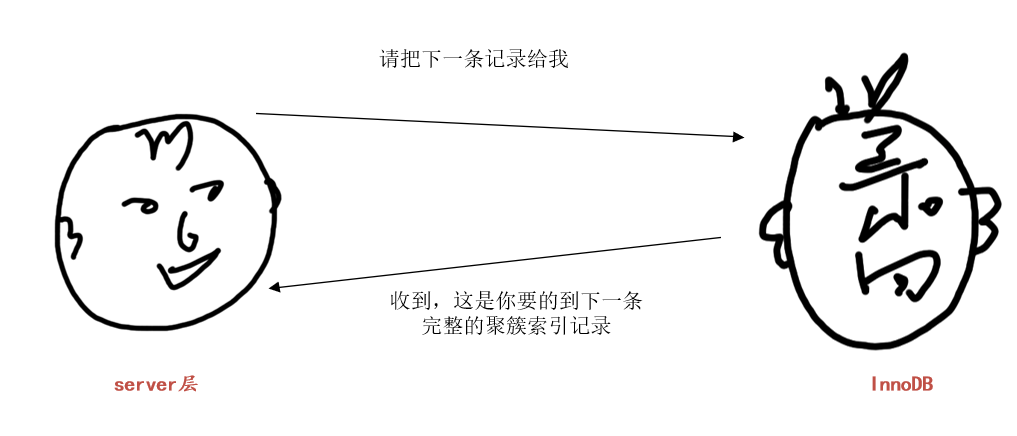
server层收到完整的聚簇索引记录后,继续判断common_field!='a'条件是否成立,如果不成立则舍弃该记录,否则将该记录发送到客户端。然后对存储引擎说:“请把下一条记录给我哈”
小贴士:
此处将记录发送给客户端其实是发送到本地的网络缓冲区,缓冲区大小由net_buffer_length控制,默认是16KB大小。等缓冲区满了才真正发送网络包到客户端。
InnoDB:“收到,这就去查”。InnoDB根据记录的next_record属性找到idx_key1的('a', 'b')区间的下一条二级索引记录,然后进行回表操作,将得到的完整的聚簇索引记录返回给server层。
小贴士:
不论是聚簇索引记录还是二级索引记录,都包含一个称作next_record的属性,各个记录根据next_record连成了一个链表,并且链表中的记录是按照键值排序的(对于聚簇索引来说,键值指的是主键的值,对于二级索引记录来说,键值指的是二级索引列的值)。
server层收到完整的聚簇索引记录后,继续判断common_field!='a'条件是否成立,如果不成立则舍弃该记录,否则将该记录发送到客户端。然后对存储引擎说:“请把下一条记录给我哈”
... 然后就不停的重复上述过程。
直到:
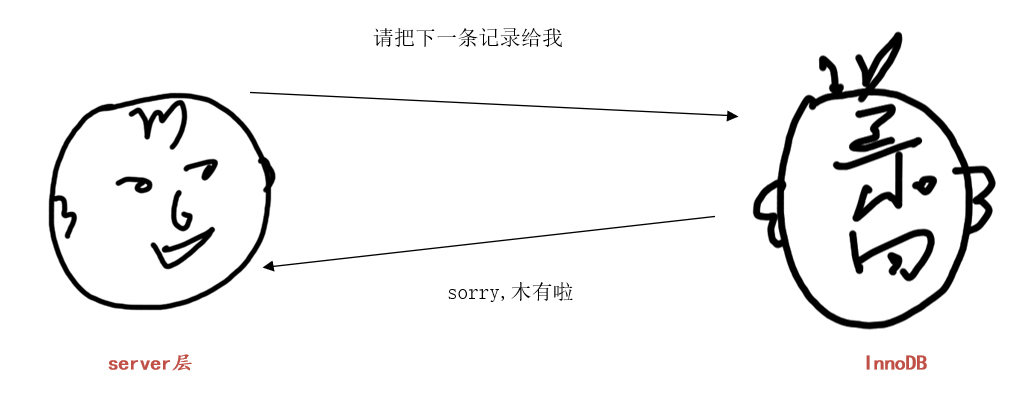
也就是直到InnoDB发现根据二级索引记录的next_record获取到的下一条二级索引记录不在('a', 'b')区间中,就跟server层说:“好了,('a', 'b')区间没有下一条记录了”
server层收到InnoDB说的没有下一条记录的消息,就结束查询。
现在大家就知道了server层和存储引擎层的基本交互过程了。
那LIMIT是什么鬼?
说出来大家可能有点儿惊讶,MySQL是在server层准备向客户端发送记录的时候才会去处理LIMIT子句中的内容。拿下边这个语句举例子:
SELECT * FROM t ORDER BY key1 LIMIT 5000, 1;
如果使用idx_key1执行上述查询,那么MySQL会这样处理:
server层向InnoDB要第1条记录,InnoDB从idx_key1中获取到第一条二级索引记录,然后进行回表操作得到完整的聚簇索引记录,然后返回给server层。server层准备将其发送给客户端,此时发现还有个
LIMIT 5000, 1的要求,意味着符合条件的记录中的第5001条才可以真正发送给客户端,所以在这里先做个统计,我们假设server层维护了一个称作limit_count的变量用于统计已经跳过了多少条记录,此时就应该将limit_count设置为1。server层再向InnoDB要下一条记录,InnoDB再根据二级索引记录的next_record属性找到下一条二级索引记录,再次进行回表得到完整的聚簇索引记录返回给server层。server层在将其发送给客户端的时候发现limit_count才是1,所以就放弃发送到客户端的操作,将limit_count加1,此时limit_count变为了2。
... 重复上述操作
直到limit_count等于5000的时候,server层才会真正的将InnoDB返回的完整聚簇索引记录发送给客户端。
从上述过程中我们可以看到,由于MySQL中是在实际向客户端发送记录前才会去判断LIMIT子句是否符合要求,所以如果使用二级索引执行上述查询的话,意味着要进行5001次回表操作。server层在进行执行计划分析的时候会觉得执行这么多次回表的成本太大了,还不如直接全表扫描+filesort快呢,所以就选择了后者执行查询。
怎么办?
由于MySQL实现LIMIT子句的局限性,在处理诸如LIMIT 5000, 1这样的语句时就无法通过使用二级索引来加快查询速度了么?其实也不是,只要把上述语句改写成:
SELECT * FROM t, (SELECT id FROM t ORDER BY key1 LIMIT 5000, 1) AS dWHERE t.id = d.id;
这样,SELECT id FROM t ORDER BY key1 LIMIT 5000, 1作为一个子查询单独存在,由于该子查询的查询列表只有一个id列,MySQL可以通过仅扫描二级索引idx_key1执行该子查询,然后再根据子查询中获得到的主键值去表t中进行查找。
这样就省去了前5000条记录的回表操作,从而大大提升了查询效率!
吐个槽
设计MySQL的大叔啥时候能改改LIMIT子句的这种超笨的实现呢?还得用户手动想欺骗优化器的方案才能提升查询效率~
MySQL:为什么查询列表中多了它,GROUP BY语句就会报错呢?
标签: 公众号文章
事前准备
为了故事的顺利发展,我们先得建一个表:
CREATE TABLE student_score (number INT(11) NOT NULL,name VARCHAR(30) NOT NULL,subject VARCHAR(30) NOT NULL,score TINYINT(4) DEFAULT NULL,PRIMARY KEY (number,subject)) ENGINE=InnoDB DEFAULT CHARSET=utf8;
这个student_score表是用来存储学生成绩的,我们为这个条填充一些数据,填充后的效果就像这样:
mysql> SELECT * FROM student_score;+----------+-----------+-----------------------------+-------+| number | name | subject | score |+----------+-----------+-----------------------------+-------+| 20180101 | 杜子腾 | 母猪的产后护理 | 78 || 20180101 | 杜子腾 | 论萨达姆的战争准备 | 88 || 20180102 | 杜琦燕 | 母猪的产后护理 | 100 || 20180102 | 杜琦燕 | 论萨达姆的战争准备 | 98 || 20180103 | 范统 | 母猪的产后护理 | 59 || 20180103 | 范统 | 论萨达姆的战争准备 | 61 || 20180104 | 史珍香 | 母猪的产后护理 | 55 || 20180104 | 史珍香 | 论萨达姆的战争准备 | 46 |+----------+-----------+-----------------------------+-------+8 rows in set (0.00 sec)
GROUP BY是在干什么?
我们知道MySQL提供了一系列的聚集函数,诸如:
COUNT:统计记录数。MAX:查询某列的最大值。MIN:查询某列的最小值。SUM:某列数据的累加总和。AVG:某列数据的平均数。
比方说我们想查看一下student_score表中所有人成绩的平均数就可以这么写:
mysql> SELECT AVG(score) FROM student_score;+------------+| AVG(score) |+------------+| 73.1250 |+------------+1 row in set (0.00 sec)
如果我们只想查看《母猪的产后护理》这个科目的平均成绩,那加个WHERE子句就好了:
mysql> SELECT AVG(score) FROM student_score WHERE subject = '母猪的产后护理';+------------+| AVG(score) |+------------+| 73.0000 |+------------+1 row in set (0.00 sec)
同理,我们也可以单独查看《论萨达姆的战争准备》这门课程的平均成绩:
mysql> SELECT AVG(score) FROM student_score WHERE subject = '论萨达姆的战争准备';+------------+| AVG(score) |+------------+| 73.2500 |+------------+1 row in set (0.00 sec)
这时候问题来了,如果这个student_score表中存储了20门科目的成绩信息,那我们怎么单独的得到这20门课程的平均成绩呢?单独写20个查询语句?那要是有100门课呢?
很显然,不能傻兮兮的写一百个语句,设计MySQL的大叔给我们提供了分组的概念。我们可以按照某个列将表中的数据进行分组,比方说我们现在按照subject列对表中数据进行分组,那么所有的记录就会被分成2组,如图所示:
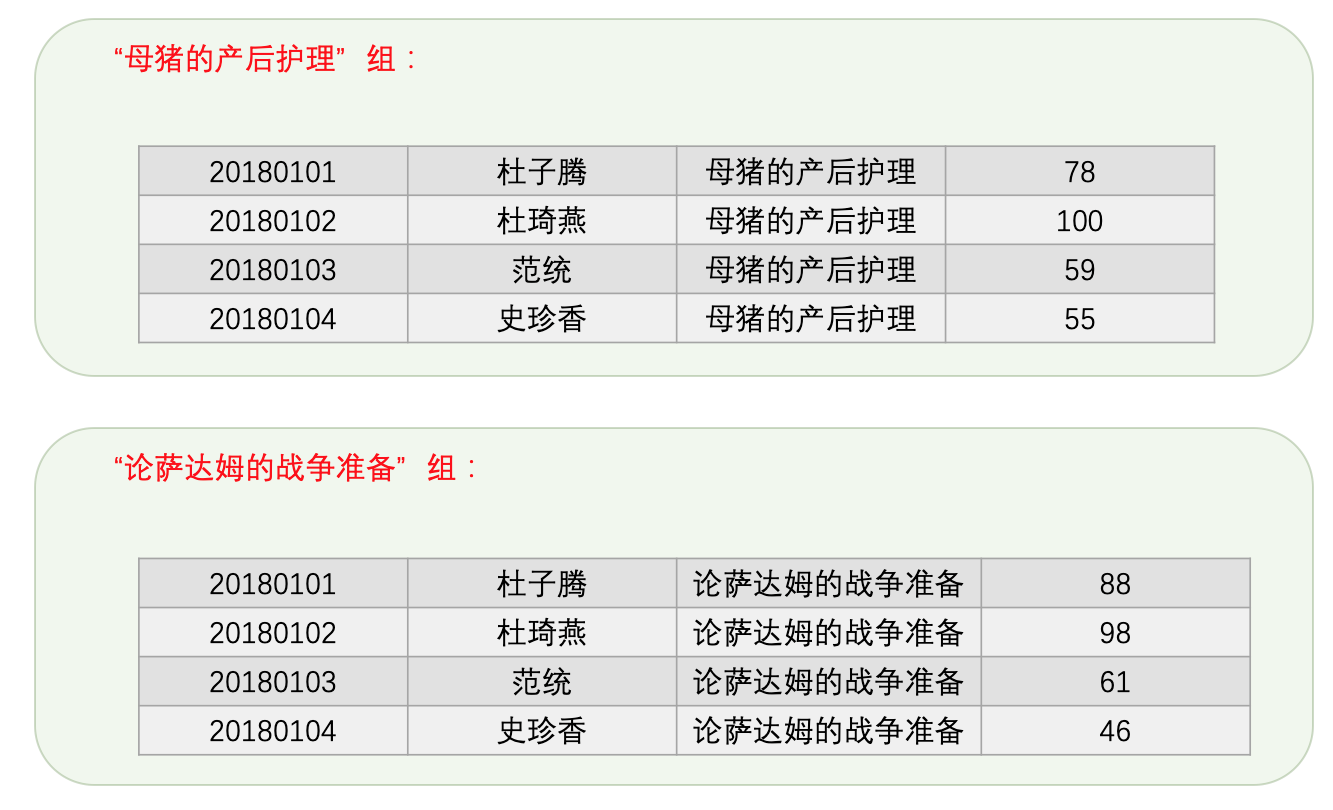
让MySQL产生这样子的分组的语句就是GROUP BY子句,我们只要在GROUP BY后边把需要分组的列写上就好,然后在查询列表处就可以针对每一个分组来写相应的聚集函数去统计该分组,就像这样:
mysql> SELECT subject, AVG(score) FROM student_score GROUP BY subject;+-----------------------------+------------+| subject | AVG(score) |+-----------------------------+------------+| 母猪的产后护理 | 73.0000 || 论萨达姆的战争准备 | 73.2500 |+-----------------------------+------------+2 rows in set (0.00 sec)
报错
可以从上边带有GROUP BY子句的查询语句中看出来,我们只在查询列表处放了分组列subject以及对该分组中的记录调用的聚集函数AVG,那如果我们把不是分组列的字段也放到查询列表中会出现啥情况:
mysql> SELECT subject, name, AVG(score) FROM student_score GROUP BY subject;ERROR 1055 (42000): Expression #2 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'dahaizi.student_score.name' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_bymysql>
可以看到报错了,为啥会报错呢?回想一下我们使用GROUP BY子句的初衷,我们只是想把记录分为若干组,然后再对各个组分别调用聚集函数去做一些统计工作。本例中的查询列表处放置了既非分组列、又非聚集函数的name列,那我们想表达啥意思呢?从各个分组中的记录中取一个记录的name列?该取哪条记录为好呢?比方说对于'母猪的产后护理'这个分组中的记录来说,name列的值应该取杜子腾,还是杜琦燕,还是范统,还是史珍香呢?这个我们也不知道,所以把非分组列放到查询列表中会引起争议,导致结果不确定,所以设计MySQL的大叔才会为上述语句报错。
不过有的同学会说,假如分组后的某个分组的某个非分组列的值都一样,那我把该非分组列加入到查询列表中也没啥问题呀。比方说按照subject列进行分组后,假如在'母猪的产后护理'的分组中各条记录的name列的值都相同,在'论萨达姆的战争准备'的分组中各条记录的name列的值也都相同,那么我们把name列放在查询列表中也没啥问题。可能设计MySQL的大叔觉得这种说法也有点儿道理,他们竟然同意在一些情况下把非分组列也放到查询列表中,这就设计到一个称之为sql_mode的系统变量,我们先看一下在我的电脑上这个系统变量的值:
mysql> SHOW VARIABLES LIKE 'sql_mode';+---------------+-------------------------------------------------------------------------------------------------------------------------------------------+| Variable_name | Value |+---------------+-------------------------------------------------------------------------------------------------------------------------------------------+| sql_mode | ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION |+---------------+-------------------------------------------------------------------------------------------------------------------------------------------+1 row in set (0.02 sec)
哇唔,好长的一段。不过大家不必在意,我们只关心其中一个称之为ONLY_FULL_GROUP_BY的家伙。只要sql_mode的值里边有这个东东,MySQL服务器就“比较正常”(也就是不允许非分组列放到查询列表中),但是如果我们把这个东东从sql_mode系统变量中移除(移除这个东东只要重新设置一下这个系统变量,把这个东东从值里边去除掉就好,我们现在不必要关心值里边儿后边那一坨东西是干嘛的,照着抄下来就好):
mysql> set sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION';Query OK, 0 rows affected (0.00 sec)
然后再执行上边那个曾经报错的语句:
mysql> SELECT subject, name, AVG(score) FROM student_score GROUP BY subject;+-----------------------------+-----------+------------+| subject | name | AVG(score) |+-----------------------------+-----------+------------+| 母猪的产后护理 | 杜子腾 | 73.0000 || 论萨达姆的战争准备 | 杜子腾 | 73.2500 |+-----------------------------+-----------+------------+2 rows in set (0.00 sec)
看,这回就不会报错了。但这是个好事儿么?个人觉得不是,因为MySQL服务器也不能保证结果集中的name列的值到底是分组中的哪条记录的。大家在日常工作中,也希望尽量不要用这个投机取巧的功能,没啥乱用,而且容易产生错误。
小贴士:不同MySQL版本中sql_mode的值可能默认包含ONLY_FULL_GROUP_BY这个家伙,也可能不包含ONLY_FULL_GROUP_BY这个家伙,也就是说不同MySQL版本中可能默认不支持查询列表中包含非分组列,也可能默认支持查询列表中包含非分组列。
MySQL冷知识:t1.id=t2.id=t3.id看着咋这么怪呢?
标签: 公众号文章
为了故事的顺利发展,我们先创建几个表:
CREATE TABLE t1 (id INT);CREATE TABLE t2 (id INT);CREATE TABLE t3 (id INT);
然后往这些表里插入一些数据(具体的插入语句就不写了),达到的效果就是这样:
mysql> SELECT * FROM t1;+----+| id |+----+| 1 || 2 || 3 |+----+3 rows in set (0.00 sec)mysql> SELECT * FROM t2;+----+| id |+----+| 1 || 2 || 3 |+----+3 rows in set (0.00 sec)mysql> SELECT * FROM t3;+----+| id |+----+| 1 || 2 || 3 |+----+3 rows in set (0.00 sec)
如果我们想对这三个表执行连接操作,把三个表中id列相同的记录都拿出来,有的同学可能会这样写:
SELECT t1.id AS t1_id, t2.id AS t2_id, t3.id AS t3_idFROM t1, t2, t3WHERE t1.id = t2.id = t3.id;
这样写会得到啥效果呢?我们看一下:
mysql> SELECT t1.id AS t1_id, t2.id AS t2_id, t3.id AS t3_id-> FROM t1, t2, t3-> WHERE t1.id = t2.id = t3.id;+-------+-------+-------+| t1_id | t2_id | t3_id |+-------+-------+-------+| 1 | 1 | 1 || 2 | 2 | 1 || 3 | 3 | 1 |+-------+-------+-------+3 rows in set (0.00 sec)mysql>
噫,发生了奇怪的事情,结果集中的第一条记录是符合我们预期的,但是剩下两条记录不符合我们预期,其中t3.id的值和t1.id、t2.id是不一样的,这是什么鬼呢?
哈哈,其实条件t1.id = t2.id = t3.id的真实含义是这样的:
(t1.id = t2.id) = t3.id
也就是说我们需要分两步理解这个表达式:
先运算
t1.id = t2.id,它其实是一个布尔表达式,得到的结果是0或者1。上一步骤得到的结果(也就是0或者1)再和
t3.id做比较。
让我们再分析一下上边的例子:
对于结果集的第一条记录来说,
t1.id的值为1、t2.id的值为1、t3.id的值为1。先比较
t1.id = t2.id是否成立,很显然1 = 1的结果是TRUE,MySQL中用1表示这个布尔表达式的结果。然后通过布尔表达式的结果
1再和t3.id比较,很显然1 = 1成立。
对于结果集的第二条记录来说,
t1.id的值为2、t2.id的值为2、t3.id的值为1。先比较
t1.id = t2.id是否成立,很显然2 = 2的结果是TRUE,MySQL中用1表示这个布尔表达式的结果。然后通过布尔表达式的结果
1再和t3.id比较,很显然1 = 1成立。
对于结果集的第三条记录来说,
t1.id的值为3、t2.id的值为3、t3.id的值为1。先比较
t1.id = t2.id是否成立,很显然3 = 3的结果是TRUE,MySQL中用1表示这个布尔表达式的结果。然后通过布尔表达式的结果
1再和t3.id比较,很显然1 = 1成立。
噫,原来t1.id = t2.id = t3.id是这个意思呀,那我们想要实现把三个表中id列值相同的记录取出来的效果该咋写?这么写:
SELECT t1.id AS t1_id, t2.id AS t2_id, t3.id AS t3_idFROM t1, t2, t3WHERE t1.id = t2.id AND t1.id = t3.id;
我们看下效果:
mysql> SELECT t1.id AS t1_id, t2.id AS t2_id, t3.id AS t3_id-> FROM t1, t2, t3-> WHERE t1.id = t2.id AND t1.id = t3.id;+-------+-------+-------+| t1_id | t2_id | t3_id |+-------+-------+-------+| 1 | 1 | 1 || 2 | 2 | 2 || 3 | 3 | 3 |+-------+-------+-------+3 rows in set (0.00 sec)
这样的话,MySQL才会把三个表中id列值相同的记录取出来呢~ 一定要记住这个知识点喔,小心哪天写三表连接的时候写错了还找不到原因呢~
小贴士:本文的这个问题是有《MySQL是怎样运行的:从根儿上理解MySQL》的微信讨论群里昵称为“白衬衫老胡同”的同学提问的,说实话我也把这个知识点忘掉了,在此感谢他的问题~
MySQL乱码
标签: 公众号文章
字符集转换概述
我们有必要说明一下,字符其实是面向人类的一个概念,计算机可并不关心字符是什么,它只关心这个字符对应的字节编码是什么。对于一个字节序列,计算机怎么知道它是使用什么字符集编码的呢?计算机不知道,所以其实在计算机中表示一个字符串时,都需要附带上它对应的字符集是什么,就像这样(以C++语言为例):
class String {byte* content;CHARSET_INFO* charset;}
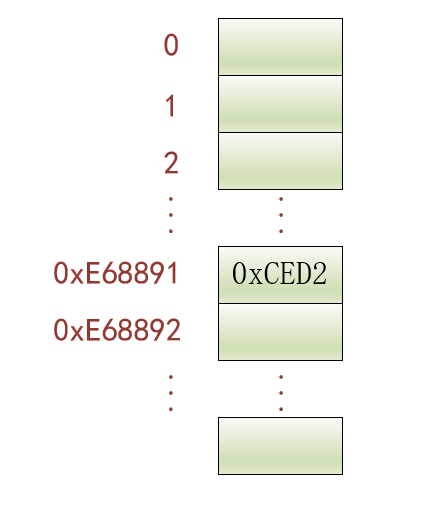
比方说我们现在有一个以utf8字符集编码的汉字'我',那么意味着计算机中不仅仅要存储'我'的utf8编码0xE68891,还需要存储它是使用什么字符集编码的信息,就像这样:
{content: 0xE68891;charset: utf8;}
计算机内部包含将一种字符集转换成另一种字符集的函数库,也就是某个字符在某种字符集下的编码可以很顺利的转换为另一种字符集的编码,我们将这个过程称之为字符集转换。比方说我们可以将上述采用utf8字符集编码的字符'我',转换成gbk字符集编码的形式,就变成了这样:
{content: 0xCED2;charset: gbk;}
小贴士:我们上边所说的'编码'可以当作动词,也可以当作名词来理解。当作动词的话意味着将一个字符映射到一个字节序列的过程,当作名词的话意味着一个字符对应的字节序列。大家根据上下文理解'编码'的含义。
MySQL客户端和服务器是怎么通信的
MySQL客户端发送给服务器的请求以及服务器发送给客户端的响应其实都是遵从一定格式的,我们把它们通信过程中事先规定好的数据格式称之为MySQL通信协议,这个协议是公开的,我们可以简单的使用wireshark等截包软件十分方便的分析这个通信协议。在了解了这个通信协议之后,我们甚至可以动手制作自己的客户端软件。市面上的MySQL客户端软件多种多样,我们并不想各个都分析一下,现在只选取在MySQL安装目录的bin目录下自带的mysql程序(此处的mysql程序指的是名字叫做mysql的一个可执行文件),如图所示:

我们在计算机的黑框框中执行该可执行文件,就相当于启动了一个客户端,就像这样:
小贴士:我们这里的'黑框框'指的是Windows操作系统中的cmd.exe或者UNIX系统中的Shell。
我们通常是按照下述步骤使用MySQL的:
- 启动客户端并连接到服务器
- 客户端发送请求。
- 服务器接收到请求
- 服务器处理请求
- 服务器处理请求完毕生成对该客户端的响应
- 客户端接收到响应
下边我们就详细分析一下每个步骤中都影响到了哪些字符集。
启动客户端并连接到服务器过程
每个MySQL客户端都维护者一个客户端默认字符集,这个默认字符集按照下边的套路进行取值:
自动检测操作系统使用的字符集
MySQL客户端会在启动时检测操作系统当前使用的字符集,并按照一定规则映射成为MySQL支持的一些字符集(通常是操作系统当前使用什么字符集,就映射为什么字符集,有一些特殊情况,比方说如果操作系统当前使用的是ascii字符集,会被映射为latin1字符集)。
当我们使用UNIX操作系统时
此时会调用操作系统提供的
nl_langinfo(CODESET)函数来获取操作系统当前正在使用的字符集,而这个函数的结果是依赖LC_ALL、LC_CTYPE、LANG这三个环境变量的。其中LC_ALL的优先级比LC_CTYPE高,LC_CTYPE的优先级比LANG高。也就是说如果设置了LC_ALL,不论有没有设置LC_CTYPE或者LANG,最终都以LC_ALL为准;如果没有设置LC_ALL,那么就以LC_CTYPE为准;如果既没有设置LC_ALL也没有设置LC_CTYPE,就以LANG为准。比方说我们将环境变量LC_ALL设置为zh_CN.UTF-8,就像这样:export LC_ALL=zh_CN.UTF-8
那么我们在黑框框里启动MySQL客户端时,MySQL客户端就会检测到这个操作系统使用的是
utf8字符集,并将客户端默认字符集设置为utf8。当然,如果这三个环境变量都没有设置,那么
nl_langinfo(CODESET)函数将返回操作系统默认的字符集,比方说在我的macOS 10.15.3操作系统中,该默认字符集为:US-ASCII
此时MySQL客户端的默认字符集将会被设置为
latin1。另外,我们这里还需要强调一下,我们使用的黑框框展示字符的时候有一个自己特有的字符集,比如在我的mac上使用
iTerm2作为黑框框,我们可以打开:Preferences->Profiles->Terminal选项卡,可以看到iTerm2使用utf8来展示字符:
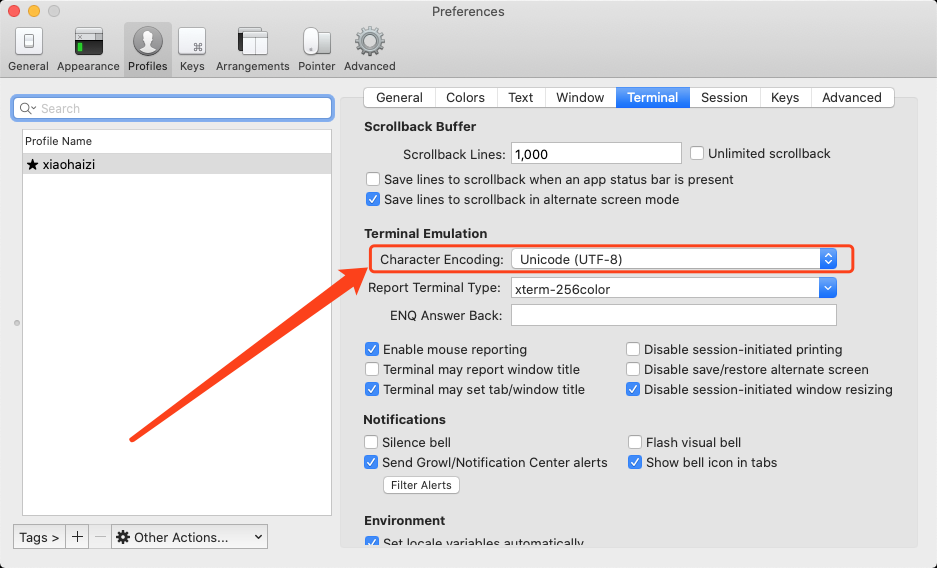
我们一般要把黑框框展示字符时采用的编码和操作系统当前使用的编码保持一致,如果不一致的话,我们敲击的字符可能都无法显示到屏幕上。比方说如果我此时把LC_ALL属性设置成GBK,那么我们再向黑框框上输入汉字的话,屏幕都不会显示了,就像这样(如下图所示,我敲击了汉字'我'的效果):

当我们使用Windows操作系统时
此时会调用操作系统提供的
GetConsoleCP函数来获取操作系统当前正在使用的字符集。在Windows里,会把当前cmd.exe使用的字符集映射到一个数字,称之为代码页(英文名:code page),我们可以通过右键点击cmd.exe标题栏,然后点击属性->选项,如下图所示,当前代码页的值是936,代表当前cmd.exe使用gbk字符集:

更简便一点,我们可以运行chcp命令直接看到当前code page是什么:
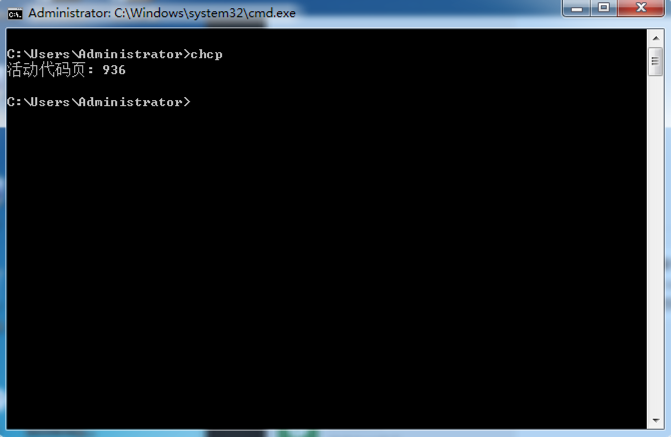
这样我们在黑框框里启动MySQL客户端时,MySQL客户端就会检测到这个操作系统使用的是gbk字符集,并将客户端默认字符集设置为gbk。我们前边提到的utf8字符集对应的代码页为65001,如果当前代码页的值为65001,之后再启动MySQL客户端,那么客户端的默认字符集就会变成utf8。
如果MySQL不支持自动检测到的操作系统当前正在使用的字符集,或者在某些情况下不允许自动检测的话,MySQL会使用它自己的内建的默认字符集作为客户端默认字符集。这个内建的默认字符集在
MySQL 5.7以及之前的版本中是latin1,在MySQL 8.0中修改为了utf8mb4。使用了
default-character-set启动参数如果我们在启动MySQL客户端是使用了
default-character-set启动参数,那么客户端的默认字符集将不再检测操作系统当前正在使用的字符集,而是直接使用启动参数default-character-set所指定的值。比方说我们使用如下命令来启动客户端:mysql --default-character-set=utf8
那么不论我们使用什么操作系统,操作系统目前使用的字符集是什么,我们都将会以utf8作为MySQL客户端的默认字符集。
在确认了MySQL客户端默认字符集之后,客户端就会向服务器发起登陆请求,传输一些诸如用户名、密码等信息,在这个请求里就会包含客户端使用的默认字符集是什么的信息,服务器收到后就明白了稍后客户端即将发送过来的请求是采用什么字符集编码的,自己生成的响应应该以什么字符集编码了(剧透一下:其实服务器在明白了客户端使用的默认字符集之后,就会将character_set_client、character_set_connection以及character_set_result这几个系统变量均设置为该值)。
客户端发送请求
登陆成功之后,我们就可以使用键盘在黑框框中键入我们想要输入的MySQL语句,输入完了之后就可以点击回车键将该语句当作请求发送到服务器,可是客户端发送的语句(本质是个字符串)到底是采用什么字符集编码的呢?这其实涉及到应用程序和操作系统之间的交互,我们的MySQL客户端程序其实是一个应用程序,它从黑框框中读取数据其实是要调用操作系统提供的读取接口。在不同的操作系统中,调用的读取接口其实是不同的,我们还得分情况讨论一下:
对于UNIX操作系统来说
在我们使用某个输入法软件向黑框框中输入字符时,该字符采用的编码字符集其实是操作系统当前使用的字符集。比方说当前
LC_ALL环境变量的值为zh_CN.UTF-8,那么意味着黑框框中的字符其实是使用utf8字符集进行编码。稍后MySQL客户端程序将调用操作系统提供的read函数从黑框框中读取数据(其实就是所谓的从标准输入流中读取数据),所读取的数据其实就是采用utf8字符集进行编码的字节序列,稍后将该字节序列作为请求内容发送到服务器。这样其实会产生一个问题,如果客户端的默认字符集和操作系统当前正在使用的字符集不同,那么将产生比较尴尬的结果。比方说我们在启动客户端是携带了
--default-character-set=gbk的启动参数,那么客户端的默认字符集将会被设置成gbk,而如果操作系统此时采用的字符集是utf8。比方说我们的语句中包含汉字'我',那么客户端调用read函数读到的字节序列其实是0xE68891,从而将0xE68891发送到服务器,而服务器认为客户端发送过来的请求都是采用gbk进行编码的,这样就会产生问题(当然,这仅仅是发生乱码问题的前奏,并不意味着产生乱码,乱码只有在最后一步,也就是客户端应用程序将服务器返回的数据写到黑框框里时才会发生)。对于Windows操作系统来说
在Windows操作系统中,从黑框框中读取数据调用的是Windows提供的
ReadConsoleW函数。在该函数执行后,MySQL客户端会得到一个宽字符数组(其实就是一组16位的UNICODE),然后客户端需要把该宽字符数组再次转换成客户端使用的默认字符集编码的字节序列,然后才将该字节序列作为请求的内容发送到服务器。这样在UNIX操作系统中可能产生的问题,在Windows系统中却可以避免。比方说我们在启动客户端是携带了
--default-character-set=gbk的启动参数,那么客户端的默认字符集将会被设置成gbk,假如此时操作系统采用的字符集是utf8。比方说我们的语句中包含汉字'我',那么客户端调用ReadConsoleW函数先读到一个代表着我字的宽字符数组,之后又将其转换为客户端的默认字符集,也就是gbk字符集编码的数据0xCED2,然后将0xCED2发送到服务器。此时服务器也认为客户端发送过来的请求就是采用gbk进行编码的,这样就完全正确了~
服务器接收请求
服务器接收到到的请求本质上就是一个字节序列,服务器将其看作是采用系统变量character_set_client代表的字符集进行编码的字节序列。character_set_client是一个SESSION级别的系统变量,也就是说每个客户端和服务器建立连接后,服务器都会为该客户端维护一个单独的character_set_client变量,每个客户端在登录服务器的时候都会将客户端的默认字符集通知给服务器,然后服务器设置该客户端专属的character_set_client。
我们可以使用SET命令单独修改character_set_client对应的值,就像这样:
SET character_set_client=gbk;
需要注意的是,character_set_client对应的字符集一定要包含请求中的字符,比方说我们把character_set_client设置成ascii,而请求中发送了一个汉字'我',将会发生这样的事情:
mysql> SET character_set_client=ascii;Query OK, 0 rows affected (0.00 sec)mysql> SHOW VARIABLES LIKE 'character%';+--------------------------+------------------------------------------------------+| Variable_name | Value |+--------------------------+------------------------------------------------------+| character_set_client | ascii || character_set_connection | utf8 || character_set_database | utf8 || character_set_filesystem | binary || character_set_results | utf8 || character_set_server | utf8 || character_set_system | utf8 || character_sets_dir | /usr/local/Cellar/mysql/5.7.21/share/mysql/charsets/ |+--------------------------+------------------------------------------------------+8 rows in set (0.00 sec)mysql> SELECT '我';+-----+| ??? |+-----+| ??? |+-----+1 row in set, 1 warning (0.00 sec)mysql> SHOW WARNINGS\G*************************** 1. row ***************************Level: WarningCode: 1300Message: Invalid ascii character string: '\xE6\x88\x91'1 row in set (0.00 sec)
如图所示,最后提示了'E6、88、91'并不是正确的ascii字符。
小贴士:可以将character_set_client设置为latin1,看看还会不会报告WARNINGS,以及为什么~
服务器处理请求
服务器在处理请求时会将请求中的字符再次转换为一种特定的字符集,该字符集由系统变量character_set_connection表示,该系统变量也是SESSION级别的。每个客户端在登录服务器的时候都会将客户端的默认字符集通知给服务器,然后服务器设置该客户端专属的character_set_connection。
不过我们之后可以通过SET命令单独修改这个character_set_connection系统变量。比方说客户端发送给服务器的请求中包含字节序列0xE68891,然后服务器针对该客户端的系统变量character_set_client为utf8,那么此时服务器就知道该字节序列其实是代表汉字'我',如果此时服务器针对该客户端的系统变量character_set_connection为gbk,那么在计算机内部还需要将该字符转换为采用gbk字符集编码的形式,也就是0xCED2。
有同学可能会想这一步有点儿像脱了裤子放屁的意思,但是大家请考虑下边这个查询语句:
mysql> SELECT 'a' = 'A';
请问大家这个查询语句的返回结果应该是TRUE还是FALSE?其实结果是不确定。这是因为我们并不知道比较两个字符串的大小到底比的是什么!我们应该从两个方面考虑:
考虑一:这些字符串是采用什么字符集进行编码的呢?
考虑二:在我们确定了编码这些字符串的字符集之后,也就意味着每个字符串都会映射到一个字节序列,那么我们怎么比较这些字节序列呢,是直接比较它们二进制的大小,还是有别的什么比较方式?比方说
'a'和'A'在utf8字符集下的编码分别为0x61和0x41,那么'a' = 'A'是应该直接比较0x61和0x41的大小呢,还是将0x61减去32之后再比较大小呢?其实这两种比较方式都可以,每一种比较方式我们都称作一种比较规则(英文名:collation)。
MySQL中支持若干种字符集,我们可以使用SHOW CHARSET命令查看,如下图所示(太多了,只展示几种,具体自己运行一下该命令):
mysql> SHOW CHARSET;+----------+---------------------------------+---------------------+--------+| Charset | Description | Default collation | Maxlen |+----------+---------------------------------+---------------------+--------+| big5 | Big5 Traditional Chinese | big5_chinese_ci | 2 || latin1 | cp1252 West European | latin1_swedish_ci | 1 || latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 || ascii | US ASCII | ascii_general_ci | 1 || gb2312 | GB2312 Simplified Chinese | gb2312_chinese_ci | 2 || gbk | GBK Simplified Chinese | gbk_chinese_ci | 2 || utf8 | UTF-8 Unicode | utf8_general_ci | 3 || utf8mb4 | UTF-8 Unicode | utf8mb4_general_ci | 4 || utf16 | UTF-16 Unicode | utf16_general_ci | 4 || utf16le | UTF-16LE Unicode | utf16le_general_ci | 4 || utf32 | UTF-32 Unicode | utf32_general_ci | 4 || binary | Binary pseudo charset | binary | 1 || gb18030 | China National Standard GB18030 | gb18030_chinese_ci | 4 |+----------+---------------------------------+---------------------+--------+41 rows in set (0.04 sec)
其中每一种字符集又对应着若干种比较规则,我们以utf8字符集为例(太多了,也只展示几个):
mysql> SHOW COLLATION WHERE Charset='utf8';+--------------------------+---------+-----+---------+----------+---------+| Collation | Charset | Id | Default | Compiled | Sortlen |+--------------------------+---------+-----+---------+----------+---------+| utf8_general_ci | utf8 | 33 | Yes | Yes | 1 || utf8_bin | utf8 | 83 | | Yes | 1 || utf8_unicode_ci | utf8 | 192 | | Yes | 8 || utf8_icelandic_ci | utf8 | 193 | | Yes | 8 || utf8_latvian_ci | utf8 | 194 | | Yes | 8 || utf8_romanian_ci | utf8 | 195 | | Yes | 8 |+--------------------------+---------+-----+---------+----------+---------+27 rows in set (0.00 sec)
其中utf8_general_ci是utf8字符集默认的比较规则,在这种比较规则下是不区分大小写的,不过utf8_bin这种比较规则就是区分大小写的。
在我们将请求中的字节序列转换为character_set_connection对应的字符集编码的字节序列后,也要配套一个对应的比较规则,这个比较规则就由collation_connection系统变量来指定。我们现在通过SET命令来修改一下 和
collation_connection的值分别设置为utf8和utf8_general_ci,然后比较一下'a'和'A':
mysql> SET character_set_connection=utf8;Query OK, 0 rows affected (0.00 sec)mysql> SET collation_connection=utf8_general_ci;Query OK, 0 rows affected (0.00 sec)mysql> SELECT 'a' = 'A';+-----------+| 'a' = 'A' |+-----------+| 1 |+-----------+1 row in set (0.00 sec)
可以看到在这种情况下这两个字符串就是相等的。
我们现在通过SET命令来修改一下 和
collation_connection的值分别设置为utf8和utf8_bin,然后比较一下'a'和'A':
mysql> SET character_set_connection=utf8;Query OK, 0 rows affected (0.00 sec)mysql> SET collation_connection=utf8_bin;Query OK, 0 rows affected (0.00 sec)mysql> SELECT 'a' = 'A';+-----------+| 'a' = 'A' |+-----------+| 0 |+-----------+1 row in set (0.00 sec)
可以看到在这种情况下这两个字符串就是不相等的。
当然,如果我们并不需要单独指定将请求中的字符串采用何种字符集以及比较规则的话,并不用太关心character_set_connection和collation_connection设置成啥,不过需要注意一点,就是character_set_connection对应的字符集必须包含请求中的字符。
服务器处理请求完毕生成对该客户端的响应
为了故事的顺利发展,我们先创建一个表:
CREATE TABLE t (c VARCHAR(100)) ENGINE=INNODB CHARSET=utf8;
然后向这个表插入一条记录:
INSERT INTO t VALUE('我');
现在这个表中的数据就如下所示:
mysql> SELECT * FROM t;+------+| c |+------+| 我 |+------+1 row in set (0.00 sec)
我们可以看到该表中的字段其实是使用utf8字符集编码的,所以底层存放格式是:0xE68891,将它读出后需要发送到客户端,是不是直接将0xE68891发送到客户端呢?这可不一定,这个取决于character_set_result系统变量的值,该系统变量也是一个SESSION级别的变量。服务器会将该响应转换为character_set_result系统变量对应的字符集编码后的字节序列发送给客户端。每个客户端在登录服务器的时候都会将客户端的默认字符集通知给服务器,然后服务器设置该客户端专属的character_set_result。
我们也可以使用SET命令来设置character_set_result的值。不过也需要注意,character_set_result对应的字符集应该包含响应中的字符。
这里再强调一遍,character_set_client、character_set_connection和character_set_result这三个系统变量是服务器的系统变量,每个客户端在与服务器建立连接后,服务器都会为这个连接维护这三个变量,如图所示(我们假设连接1的这三个变量均为utf8,连接1的这三个变量均为gbk,连接1的这三个变量均为ascii,):

一般情况下character_set_client、character_set_connection和character_set_result这三个系统变量应该和客户端的默认字符集相同,SET names命令可以一次性修改这三个系统变量:
SET NAMES 'charset_name'
该语句和下边三个语句等效:
SET character_set_client = charset_name;SET character_set_results = charset_name;SET character_set_connection = charset_name;
不过这里需要大家特别注意,SET names语句并不会改变客户端的默认字符集!
客户端接收到响应
客户端收到的响应其实仍然是一个字节序列。客户端是如何将这个字节序列写到黑框框中的呢,这又涉及到应用程序和操作系统之间的一次交互。
对于UNIX操作系统来说,MySQL客户端向黑框框中写入数据使用的是操作系统提供的
fputs、putc或者fwrite函数,这些函数基本上相当于直接就把接收到的字节序列写到了黑框框中(请注意我们用词:'基本上相当于',其实内部还会做一些工作,但是我们这里就不想再关注这些细节了)。此时如果该字节序列实际的字符集和黑框框展示字符所使用的字符集不一致的话,就会发生所谓的乱码(大家注意,这个时候和操作系统当前使用的字符集没啥关系)。比方说我们在启动MySQL客户端的时候使用了
--default-character-set=gbk的启动参数,那么服务器的character_set_result变量就是gbk。然后再执行SELECT * FROM t语句,那么服务器就会将字符'我'的gbk编码,也就是0xCDE2发送到客户端,客户端直接把这个字节序列写到黑框框中,如果黑框框此时采用utf8字符集展示字符,那自然就会发生乱码。对于Windows操作系统来说,MySQL客户端向黑框框中写入数据使用的是操作系统提供的
WriteConsoleW函数,该函数接收一个宽字符数组,所以MySQL客户端调用它的时候需要显式地将它从服务器收到的字节序列按照客户端默认的字符集转换成一个宽字符数组。正因为这一步骤的存在,所以可以避免上边提到的一个问题。比方说我们在启动MySQL客户端的时候使用了
--default-character-set=gbk的启动参数,那么服务器的character_set_result变量就是gbk。然后再执行SELECT * FROM t语句,那么服务器就会将字符'我'的gbk编码,也就是0xCDE2发送到客户端,客户端将这个字节序列先从客户端默认字符集,也就是gbk的编码转换成一个宽字符数组,然后再调用WriteConsoleW函数写到黑框框,黑框框自然可以把它显示出来。
乱码问题应该如何分析
好了,介绍了各个步骤中涉及到的各种字符集,大家估计也看的眼花缭乱了,下边总结一下我们遇到乱码的时候应该如何分析,而不是胡子眉毛一把抓,随便百度一篇文章,然后修改某个参数,运气好修改了之后改对了,运气不好改了一天也改不好。知其然也要知其所以然,在学习了本篇文章后,大家一定要有节奏的去分析乱码问题:
我使用的是什么操作系统
对于UNIX系统用户来说,要搞清楚我使用的黑框框到底是使用什么字符集展示字符,就像是
iTerm2中的character encoding属性:
同样还要搞清楚操作系统当前使用什么字符集,运行locale命令查看:王大爷喊你输入呢,跟这儿>localeLANG=""LC_COLLATE="zh_CN.UTF-8"LC_CTYPE="zh_CN.UTF-8"LC_MESSAGES="zh_CN.UTF-8"LC_MONETARY="zh_CN.UTF-8"LC_NUMERIC="zh_CN.UTF-8"LC_TIME="zh_CN.UTF-8"LC_ALL="zh_CN.UTF-8"王大爷喊你输入呢,跟这儿>
没有什么特别极端的特殊需求的话,一定要保证上述两个字符集是相同的,否则可能连汉字都输入不进去!
对于Windows用户来说
搞清楚自己使用的黑框框的代码页是什么,也就是操作系统当前使用的字符集是什么。
搞清楚客户端的默认字符集是什么
启动MySQL客户端的时候有没有携带
--default-character-set参数,如果携带了,那么客户端默认字符集就以该参数指定的值为准。否则分析自己操作系统当前使用的字符集是什么。搞清楚客户端发送请求时是以什么字符集编码请求的
对于UNIX系统来说,我们可以认为请求就是采用操作系统当前使用的字符集进行编码的。
对于Windows系统来说,我们可以认为请求就是采用客户端默认字符集进行编码的。
通过执行
SHOW VARIABLES LIKE 'character%'命令搞清楚:character_set_client:服务器是怎样认为客户端发送过来的请求是采用何种字符集编码的character_set_connection:服务器在运行过程中会采用何种字符集编码请求中的字符character_set_result:服务器会将响应使用何种字符集编码后再发送给客户端的
客户端收到响应之后:
对于服务器发送过来的字节序列来说:
在UNIX操作系统上,可以认为会把该字节序列直接写到黑框框里。此时应该搞清楚我们的黑框框到底是采用何种字符集展示数据。
在Windows操作系统上,该字节序列会被认为是由客户端字符集编码的数据,然后再转换成宽字符数组写入到黑框框中。
请认真分析上述的每一个步骤,然后发出惊呼:小样,不就是个乱码嘛,还治不了个你!
字符从UTF-8转成GBK发生了什么?
标签: 公众号文章
字符是什么
字符是面向人类的概念,大致可分为两种,一种叫可见字符,一种叫不可见字符。
顾名思义,可见字符就是打印出来后能看见的字符。比如a、b、我这样的人眼能看见的单个国家文字、标点符号、图形符号、数字等这样的东东,我们就叫做一个可见字符。
不可见字符也好理解,就是之前打印机或者在黑框框里打印字符的时候有时候需要换行,打个制表符啥的,或者在输出某个字符的时候就发出嘟地一声,这种我们看不到,只是为了控制输出效果的字符叫做不可见字符。
注意,字符都是单个的喔!。把字符连起来叫做字符串,比如abc,就是由a、b、c三个字符连起来的一个字符串。
计算机怎么表示字符
计算机只能处理二进制数据,它并不认识字符。为了让计算机能处理字符,人们人为地在字符和二进制数字之间建立起了映射关系,映射的过程可以被称作编码,字符和二进制数字的映射关系也可以被称作编码方案。由于谁都可以制作编码方案,不同地人制作出了不同地编码方案。制作一种编码方案说清楚两个事就可以:
- 要对哪些字符进行编码
- 具体地每个字符和哪个二进制数字关联起来
虽然说谁都可以制作编码方案,但随着时间的流逝,只有为数不多的编码方案流行起来,比方说:
ASCII:收录128个字符,用7个二进制位就可以进行编码。但通常计算机以字节作为基本的存储空间分配单位,所以在ASCII编码方案中,通常使用1个字节对1个字符进行编码。
ISO 8859-1:收录256个字符,可用1个字节进行编码,兼容ASCII编码方案。
GBK:收录21886个字符,用
1~2个字节进行编码,兼容ASCII编码方案。UNICODE:收录目前世界上各式各样的字符。每个字符都对应一个数字,被称作Unicode值。该Unicode值可以被表示为多种形式,称作Unicode Transformation Formats,简称UTF。比方说:
- UTF-8:目前采用1~4个字节来表示一个Unicode值(随着Unicode中字符的扩充,可能使用更多的字节编码一个字符),并且兼容ASCII编码方案。
- UTF-16:目前采用2个或4个字节来表示一个Unicode值。
- UTF-32:目前采用4个字节来表示一个Unicode值
由于我们之前详细唠叨过不同编码方案是如何编码字符的,所以本文就不再赘述了。本文来唠叨一下不同字符编码方案之间是如何相互转换的。
字符编码方案的转换
对于字符'我'来说:
- 在
UTF-8中的编码值的二进制形式为:
11100110 10001000 10010001
共3个字节,写成十六进制的形式就是:0xE68891。
- 在
GBK中的编码值的二进制形式为:
11001110 11010010
共2字节,写成十六进制的形式就是:0xCED2
在某个需要将字符串的字符编码方案从UTF-8转成GBK的场景中,怎么把0xE68891转换成0xCED2呢?
解决这个问题其实很简单,我们可以制作一个大型数组, 数组大小就是源编码方案中包含的字符数量,这样在源编码方案中的每个字符的编码值都对应数组的一个下标。这样每个数组下标都对应一个字符,我们只需要将相应字符的目标编码方案的编码值填入到该下标对应的数组元素中。比方说:
也就是说对于某个字符来说,数组下标就是源编码方案的编码值,数组元素值就是目标编码方案的编码值。这样就可以很轻松的完成某个字符的编码方案转换功能。
这个方案是有很大缺点的,因为UTF-8中包含的字符数量是远超GBK的,这就导致我们申请的数组的存储空间有绝大部分是被浪费掉的。其实数组里只需要把GBK编码方案中的字符编码都存储上即可,这样可以显著减小数组大小,但是由于我们又要要求根据字符的UTF-8编码值作为下标找到对应的GBK编码值,这时候就有点儿犯难。。。
其实GBK编码方案中包含的字符只会被包含在UTF-8编码方案的几部分中:
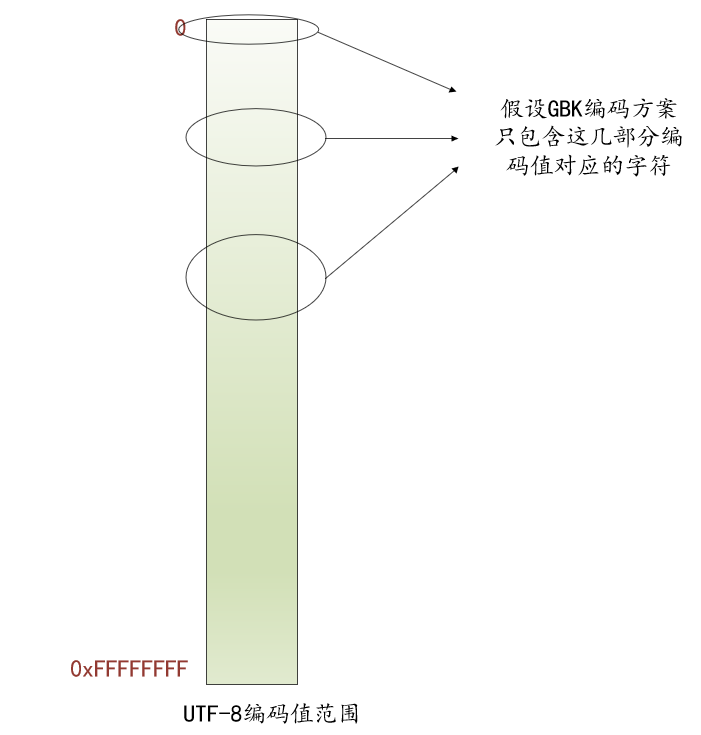
如上图所示,画圈部分的UTF-8编码值对应的字符就已经可以覆盖GBK编码方案中的字符了。当然,画圈部分的UTF-8编码值对应的某些字符也可能GBK编码方案并不包含,但这并不会有什么大问题,只是在申请数组的存储空间的时候浪费掉一些而已。
这样针对每一个圈,我们都可以建立一个数组,数组大小就是圈中UTF-8编码值的数量,每个圈对应数组的下标0都对应该圈包含的第1个UTF-8编码值,数组元素值就是相应下标对应的UTF-8编码值对应字符的GBK编码值。这样就可以极大程度减少数组占用的存储空间大小了。
那如果是UTF-16转GBK呢?
简单,再仿造上述步骤建立从UTF-16的编码值映射到GBK编码值的数组呗!
那如果是BIG5转GBK呢?
简单,再仿造上述步骤建立从BIG5的编码值映射到GBK编码值的数组呗!
那如果是UTF-16转BIG5呢?
还得建立相应的数组...
好像很烦噢,字符编码方案多种多样,想实现任意两个编码方案都可以相互转换的话,那我们得建立多少数组呀!如下图所示:
而且编码方案也可以随时增加,没新增一种编码方案都要考虑到与其他编码方案如何相互转换的问题实在太繁琐了。有没有什么好的方案呢?
有!比方有5个人分别会说汉语、英语、法语、俄语、阿拉伯语,如果想让他们之间任意两个人可以相互沟通,其实也没必要让每个人都学会其他4种语言,只需要规定大家都会同一门语言,比方说汉语!这样大家只需要学习一门外语即可相互沟通(会汉语的甚至都不用再学一遍外语了)!
在将某个字符从一种编码方案转换成另一种编码方案时,我们不必单独维护从源编码方案到目标编码方案的转换数组,只需要先将源编码方案转换成一种中间编码方案,再将中间编码方案转换成目标编码方案。这样对于任何一种编码方案来说,仅需维护它与中间编码方案的转换数组即可。这个中间编码方案指的就是Unicode!如下图所示:
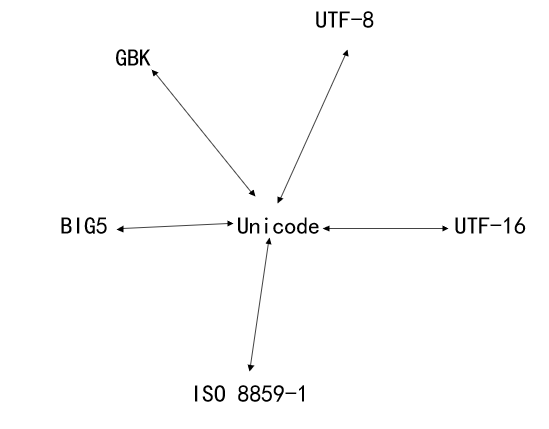
这样在将UTF-8编码值转换为GBK编码值时,需完成两步:
- 先将UTF-8编码值转换为Unicode值
- 再将Unicode值转换为GBK编码值
MySQL的实现
不像我们应用程序员直接调用某个库的进行字符编码转换的函数,MySQL为了尽量减少依赖,自己实现了各种字符编码方案以及它们之间的转换。我们下边以'我'字为例,看一下它是怎么实现从UTF-8编码方案转换成GBK编码方案的。
从UTF-8编码值获取对应的Unicode值
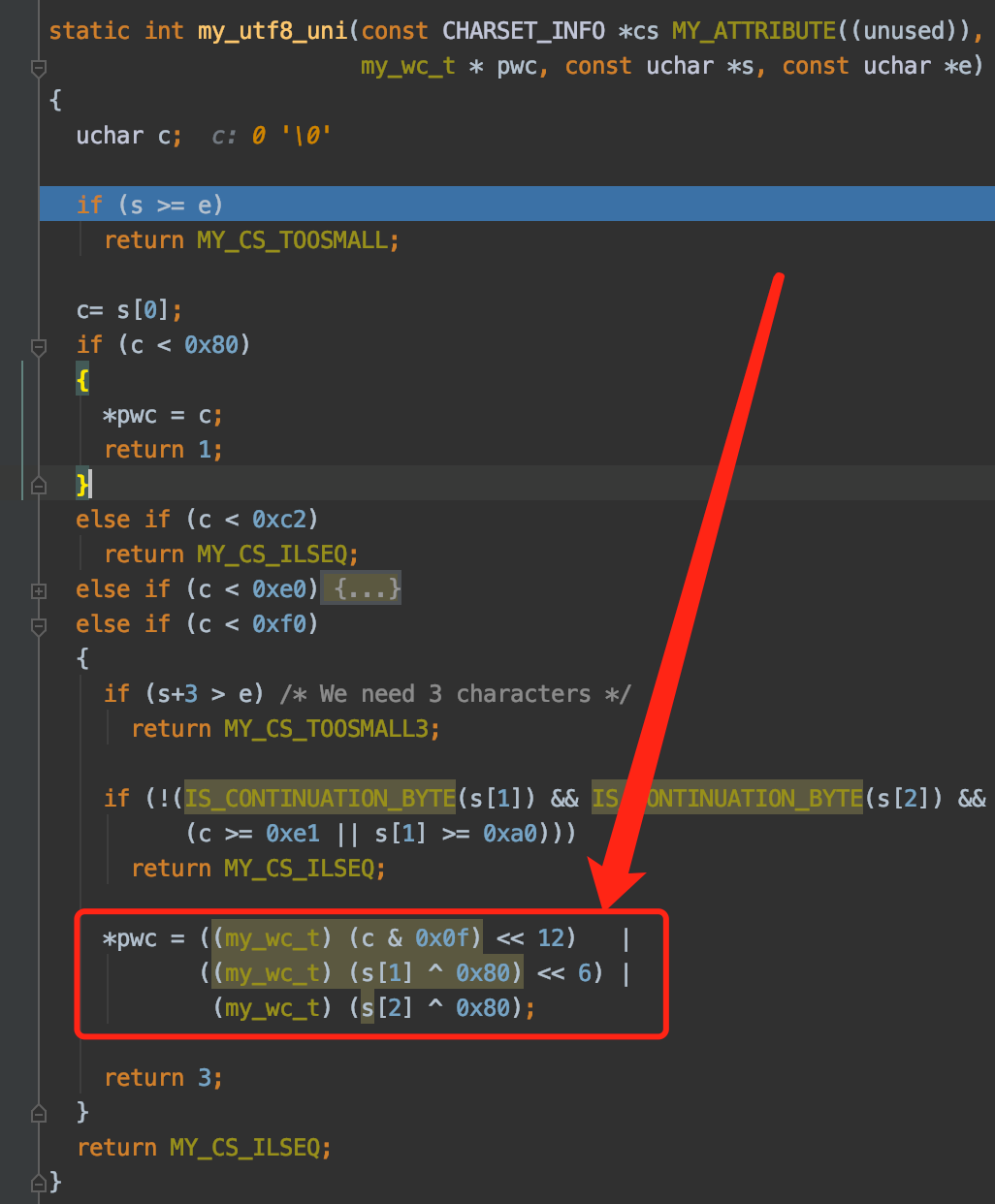
my_utf8_uni是用于获取UTF-8编码字符对应的Unicode值的函数,红色箭头指向的是实际操作过程。比方说字符'我'的UTF-8编码值是0xE68891,那就需要做如下操作:
((0xE6 & 0x0f) << 12) |((0x88 ^ 0x80) << 6) |(0x91 ^ 0x80)
得到的结果是十进制的25105,这个25105就是字符'我'对应的Unicode值
从Unicode值获取对应GBK编码值
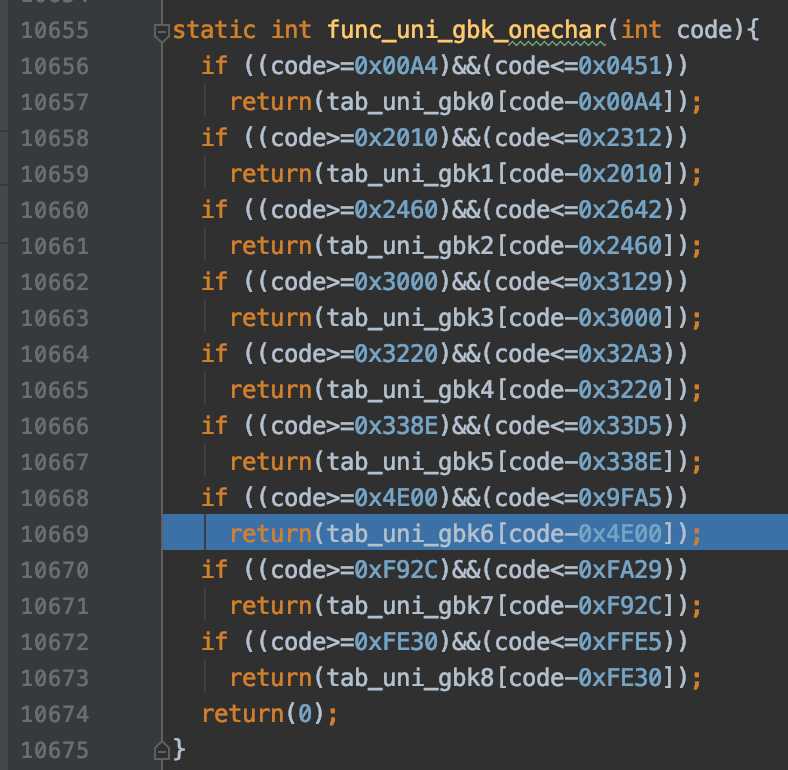
func_uni_gbk_onechar是根据Unicode值获取对应的GBK编码值的函数。从该函数的实现中可以看到,设计MySQL的大叔把包含在GBK编码方案中的字符对应的Unicode值分成了9个组,分别是tab_uni_gbk0~tab_uni_gbk8,当然,这些组中也包含了一些不属于GBK编码方案的字符对应的Unicode值,比方说第一个组tab_uni_gbk0:

其中值为0的元素对应的字符就是不包含在GBK编码方案中的。
如果让每一个组中仅包含GBK字符的话,这会导致组划分的过多。出于在组的数量和浪费的存储空间方面做出取舍,就形成了现在这种划分了9个组的方案。
由于字符'我'对应的Unicode值25105其实是在tab_uni_gbk6中的,我们看一下数组tab_uni_gbk6的下标为25105-0x4E00,也就是5137的元素的值是什么:
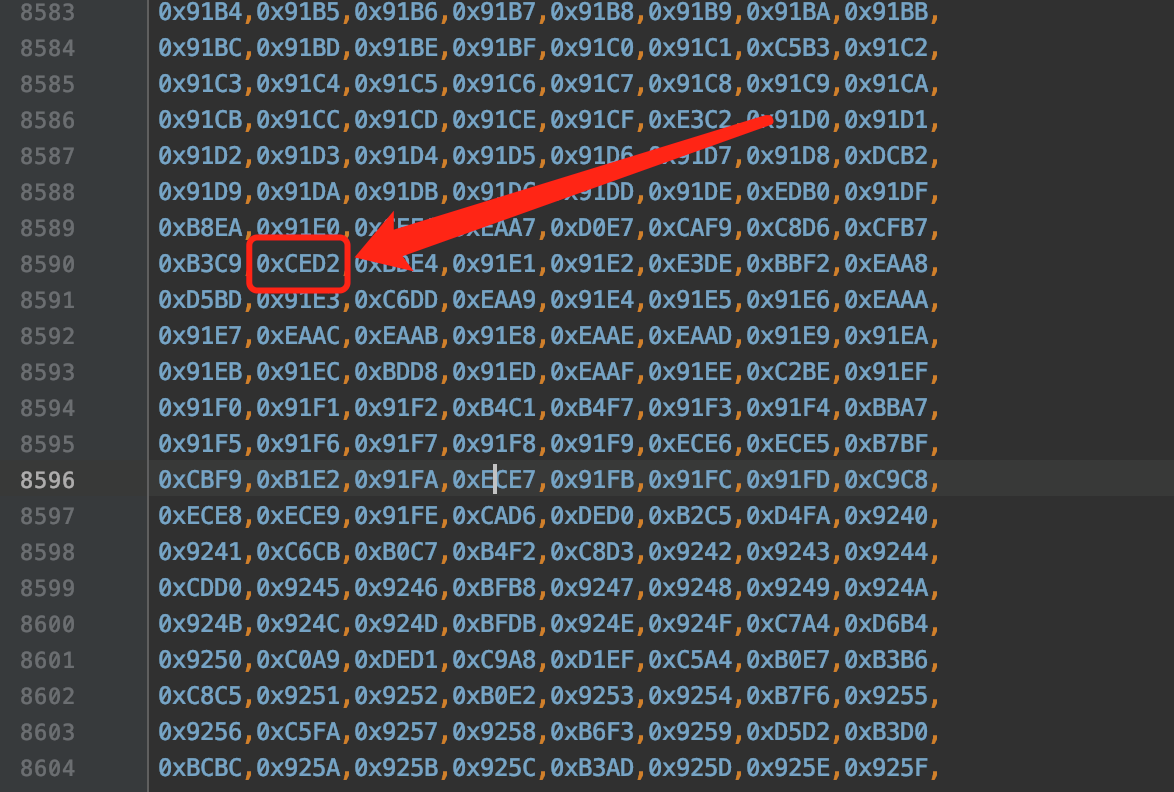
是他!是他!就是他!就是我们的0xCED2!
MySQL的定点数类型
标签: 公众号文章
上一篇文章我们唠叨了浮点数,知道了浮点数存储小数是不精确的。本篇继续唠叨一下MySQL中的另一种存储小数的方式 —— 定点数。
定点数类型
正因为用浮点数表示小数可能会有不精确的情况,在一些情况下我们必须保证小数是精确的,所以设计MySQL的大叔们提出一种称之为定点数的数据类型,它也是存储小数的一种方式:
| 类型 | 占用的存储空间(单位:字节) | 取值范围 |
|---|---|---|
DECIMAL(M, D) |
取决于M和D | 取决于M和D |
其中:
M表示该小数最多需要的十进制有效数字个数。注意是
有效数字个数,比方说对于小数-2.3来说有效数字个数就是2,对于小数0.9来说有效数字个数就是1。D表示该小数的小数点后的十进制数字个数。这个好理解,小数点后有几个十进制数字,
D的值就是什么。
举个例子看一下,设置了M和D的单精度浮点数的取值范围的变化:
| 类型 | 取值范围 |
|---|---|
DECIMAL(4, 1) |
-999.9~999.9 |
DECIMAL(5, 1) |
-9999.9~9999.9 |
DECIMAL(6, 1) |
-99999.9~99999.9 |
DECIMAL(4, 0) |
-9999~9999 |
DECIMAL(4, 1) |
-999.9~999.9 |
DECIMAL(4, 2) |
-99.99~99.99 |
可以看到,在D相同的情况下,M越大,该类型的取值范围越大;在M相同的情况下,D越大,该类型的取值范围越小。当然,M和D的取值也不是无限大的,M的取值范围是1~255,D的取值范围是0~30,而且D的值必须不大于M。M和D都是可选的,如果我们省略了它们,那它们的值按照机器支持的最大值来存储。
我们说定点数是一种精确的小数,为了达到精确的目的我们就不能把它转换成二进制小数之后再存储(因为有很多十进制小数转为二进制小数后需要进行舍入操作,导致二进制小数表示的数值是不精确的)。其实转念一想,所谓的小数只是把两个十进制整数用小数点分割开来而已,我们只要把小数点左右的两个十进制整数给存储起来,那不就是精确的了么。比方说对于十进制小数2.38来说,我们可以把这个小数的小数点左右的两个整数,也就是2和38分别保存起来,那么不就相当于保存了一个精确的小数么,这波操作是不是很6。
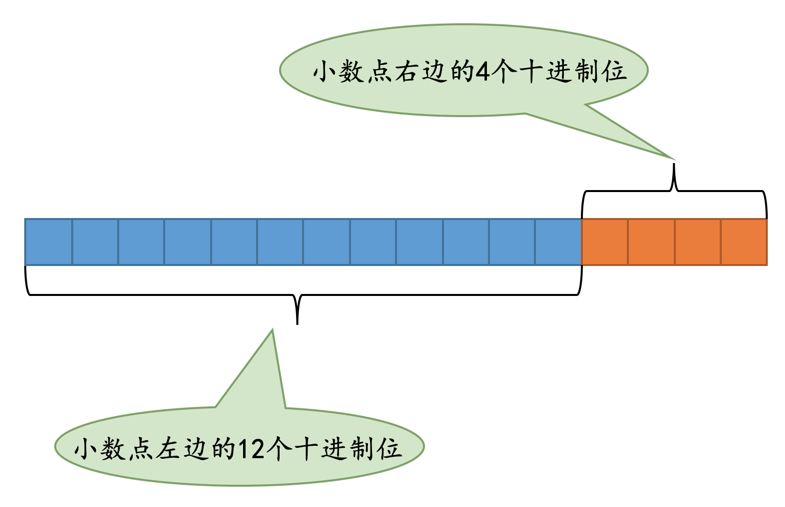
当然事情并没有这么简单,对于给定M、D值的DECIMAL(M, D)类型,比如DEMCIMAL(16, 4)来说:
首先确定小数点左边的整数最多需要存储的十进制位数是12位,小数点右边的整数需要存储的十进制位数是4位,如图所示:
从小数点位置出发,每个整数每隔9个十进制位划分为1组,效果就是这样:
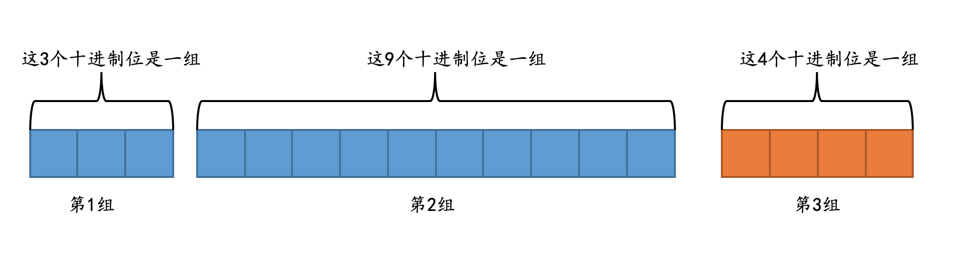
从图中可以看出,如果不足9个十进制位,也会被划分成一组。
针对每个组中的十进制数字,将其转换为二进制数字进行存储,根据组中包含的十进制数字位数不同,所需的存储空间大小也不同,具体见下表:
组中包含的十进制位数 占用存储空间大小(单位:字节) 1或2 1 3或4 2 5或6 3 7或8或9 4 所以
DECIMAL(16, 4)共需要占用8个字节的存储空间大小,这8个字节由下边3个部分组成:- 第1组包含3个十进制位,需要使用2个字节存储。
- 第2组包含9个十进制位,需要使用4个字节存储。
- 第3组包含4个十进制位,需要使用2个字节存储。
将转换完成的比特位序列的最高位设置为1。
这些步骤看的有一丢丢懵逼吧,别着急,举个例子就都清楚了。比方说我们使用定点数类型DECIMAL(16, 4)来存储十进制小数1234567890.1234,这个小数会被划分成3个部分:
1 234567890 1234
也就是:
- 第1组中包含整数
1。 - 第2组中包含整数
234567890。 - 第3组中包含整数
1234。
然后将每一组中的十进制数字转换成对应的二进制数字:
第1组占用2个字节,整数
1对应的二进制数就是(字节之间实际上没有空格,只不过为了大家理解上的方便我们加了一个空格):00000000 00000001
二进制看起来太难受,我们还是转换成对应的十六进制看一下:
0x0001
第2组占用4个字节,整数
234567890对应的十六进制数就是:0x0DFB38D2
第3组占用2个字节,整数
1234对应的十六进制数就是:0x04D2
所以将这些十六进制数字连起来之后就是:
0x00010DFB38D204D2
最后还要将这个结果的最高位设置为1,所以最终十进制小数1234567890.1234使用定点数类型DECIMAL(16, 4)存储时共占用8个字节,具体内容为:
0x80010DFB38D204D2
有的同学会问,如果我们想使用定点数类型DECIMAL(16, 4)存储一个负数怎么办,比方说-1234567890.1234,这时只需要将0x80010DFB38D204D2中的每一个比特位都执行一个取反操作就好,也就是得到下边这个结果:
0x7FFEF204C72DFB2D
从上边的叙述中我们可以知道,对于DECIMAL(M, D)类型来说,给定的M和D的值不同,所需的存储空间大小也不同。可以看到,与浮点数相比,定点数需要更多的空间来存储数据,所以如果不是在某些需要存储精确小数的场景下,一般的小数用浮点数表示就足够了。
对于定点数类型DECIMAL(M, D)来说,M和D都是可选的,默认的M的值是10,默认的D的值是0,也就是说下列等式是成立的:
DECIMAL = DECIMAL(10) = DECIMAL(10, 0)DECIMAL(n) = DECIMAL(n, 0)
另外M的范围是1~65,D的范围是0~30,且D的值不能超过M。
Innodb到底是怎么加锁的
标签: 公众号文章
上一篇文章中缺失一点儿东西,再补全一下。
学完本文后:妈妈再也不用担心我不知道InnoDB是怎么加锁的了!
流传较广,但是错误的一个观点
不知道从什么时候开始,下边这个错误的观点开始被广泛的流传:
在使用加锁读的方式读取使用InnoDB存储引擎的表时,当在执行查询时没有使用到索引时,行锁会被转换为表锁。
这里强调一点,对于任何INSERT、DELETE、UPDATE、SELECT ... LOCK IN SHARE MODE、SELECT ... FOR UPDATE语句来说,InnoDB存储引擎都不会加表级别的S锁或者X锁(我们这里不讨论表级意向锁的添加),只会加行级锁。所以即使对于全表扫描的加锁读语句来说,也只会对表中的记录进行加锁,而不是直接加一个表锁。
另外,很多小伙伴都会问:“这个语句加什么锁”,其实这是一个伪命题,因为一个语句需要加什么锁受到很多方面的影响,如果有人问你某某语句会加什么锁,那你可以直接回怼:真不专业!
我们稍后给大家详细分析一下影响加锁的因素都有哪些,以及从源码的角度看一下InnoDB到底是如何加锁的,希望小伙伴看完后会惊呼:真tm的简单!
不过在进行讨论前我们需要申明一下,我们讨论的只是InnoDB加的事务锁,即为了避免脏写、脏读、不可重复读、幻读这些现象带来的一致性问题而加的锁,并不是为了在多线程访问共享内存区域时而加的锁(比方说两个不同事务所在的线程想读写同一个页面时,需要进行加锁保护),也不包括server层添加的MDL锁。
本文所参考的源码版本为5.7.22。
事务锁到底是什么
锁是一个内存结构,InnoDB中用lock_t这个结构来定义:

不论是行锁,还是表锁都用这个结构来表示。我们给大家画个图:
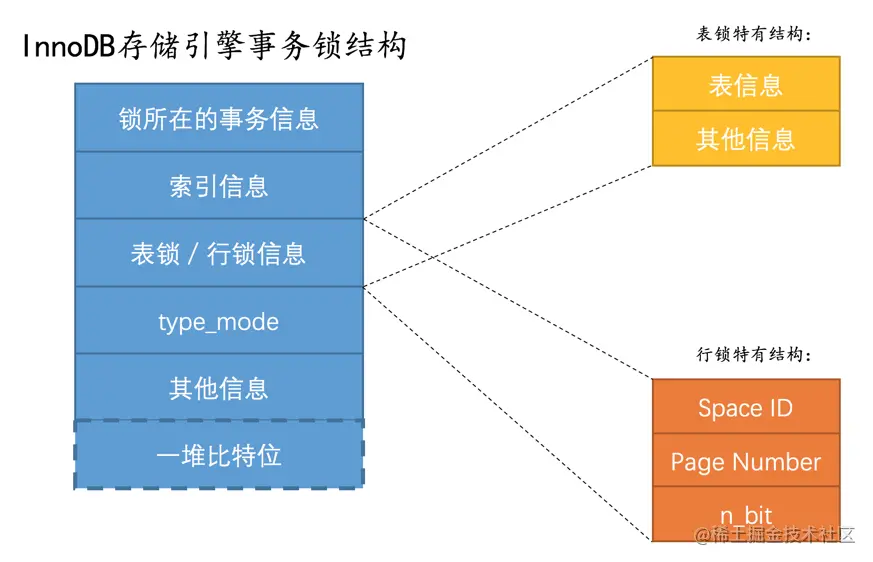
其中的type_mode是用于区分这个锁结构到底是行锁还是表锁,如果是表锁的话是意向锁、直接对表加锁、还是AUTO-INC锁,如果是行锁的话,具体是正经记录锁、gap锁还是next-key锁。
小贴士:
在InnoDB的实现中,InnoDB的行锁是与记录一一对应的。即使是对于gap锁来说,在实现上也是为某条记录生成一个锁结构,然后该锁结构的类型是gap锁而已,并不是专门为某个区间生成一个锁结构。该gap锁的功能就是每当有别的事务插入记录时,会检查一下待插入记录的下一条记录上是否已经有一个gap锁的锁结构,如果有的话就进入阻塞状态。
我们平时所说的加锁就是在内存中生成这样的一个锁结构(除了生成锁结构,还有一种称作隐式锁的加锁方式,不用生成锁结构)。当然,如果为1条记录加锁就要生成一个锁结构,那岂不是太浪费了!设计InnoDB的大叔提出了一种优化方案,即同一个事务,在同一个页面上加的相同类型的锁都放在同一个锁结构里。
各种类型的锁是如果通过type_mode区分、各种锁都有什么作用,以及如何减少生成锁结构的细节我们这里就不展开了,那又要花费超长的篇幅,大家可以到《MySQL是怎样运行的:从根儿上理解MySQL》书籍中查看,我们下边来看具体的加锁细节。
准备工作
为了故事的顺利发展,我们先创建一个表hero:
CREATE TABLE hero (number INT,name VARCHAR(100),country varchar(100),PRIMARY KEY (number),KEY idx_name (name)) Engine=InnoDB CHARSET=utf8;
然后向这个表里插入几条记录:
INSERT INTO hero VALUES(1, 'l刘备', '蜀'),(3, 'z诸葛亮', '蜀'),(8, 'c曹操', '魏'),(15, 'x荀彧', '魏'),(20, 's孙权', '吴');
然后现在hero表就有了两个索引(一个二级索引,一个聚簇索引),示意图如下:
加锁受哪些因素影响
一条语句加什么锁受多种因素影响,如果你不能确认下边这些因素的时候,最好不要抢先发言说"XXX语句对XXX记录加了什么锁":
- 事务的隔离级别
- 语句执行时使用的索引类型(比如聚簇索引、唯一二级索引、普通二级索引)
- 是否是精确匹配
- 是否是唯一性搜索
- 具体执行的语句类型(SELECT、INSERT、DELETE、UPDATE)
- 是否开启innodb_locks_unsafe_for_binlog系统变量
- 记录是否被标记删除
这里边有几个概念大家可能不是很清楚,我们先解释一下。
扫描区间
比方说下边这个查询:
SELECT * FROM hero WHERE name <= 'l刘备' AND country = '魏';
MySQL可以使用下边两种方式来执行上述查询:
使用二级索引idx_name执行上述查询,那么就需要扫描name值在
(-∞, 'l刘备']这个区间中的所有二级索引记录,针对获取到的每一条二级索引记录,都需要执行回表操作来获取相应的聚簇索引记录。直接扫描所有的聚簇索引记录,即进行全表扫描。此时相当于扫描number值在
(-∞, +∞)这个区间中的所有聚簇索引记录。
优化器会计算上述二种方式哪个成本更低,选用成本更低的那种来执行查询。
当优化器使用二级索引执行查询时,我们把(-∞, 'l刘备']称作扫描区间,意味着需要扫描name列值在这个区间中的所有二级索引记录,我们也可以把形成这个扫描区间的条件name <= 'l刘备'称作是形成这个扫描区间的边界条件;当优化器使用全表扫描执行查询时,我们把(-∞, +∞)称作扫描区间,意味着需要扫描number值在这个区间中的所有聚簇索引记录。
在执行一个查询的过程中,可能会用到多个扫描区间,如下所示:
SELECT * FROM hero WHERE name < 'l刘备' OR name > 'x荀彧';
如果优化器采用二级索引idx_name执行上述查询时,那么对应的扫描区间就是(-∞, l刘备)以及('x荀彧', +∞),即需要扫描name值在上述两个扫描区间中的记录。
每当InnoDB需要扫描一个扫描区间中的记录时,都需要分两步:
先通过索引对应的B+树,从根页面开始一路向下定位,直到定位到叶子节点中在扫描区间中的第一条记录。
之后就可以不需要继续从根节点定位了,而是通过记录的
next_record属性直接找到扫描区间的下一条记录即可(页面之间通过双向链表连接,找完一个页面中的记录后,可以顺着双向链表再去下一个页面中去找属于同一个扫描区间的记录)。
也就是说在扫描某个扫描区间的记录时,只有定位第1条记录的时候稍微麻烦点儿,其他记录只需要顺着链表(单个页面中的记录连成一个单向链表,不同的页面之间是双向链表)扫描即可。
精确匹配
对于形成扫描区间的边界条件来说,如果是等值匹配的条件,我们就把对这个扫描区间的匹配模式称作精确匹配。比方说:
SELECT * FROM hero WHERE name = 'l刘备' AND country = '魏';
如果使用二级索引idx_name执行上述查询时,扫描区间就是['l刘备', 'l刘备'],形成这个扫描区间的边界条件就是name = 'l刘备'。我们就把在使用二级索引idx_name执行上述查询时的匹配模式称作精确匹配。
而对于下边这个查询来说
SELECT * FROM hero WHERE name <= 'l刘备' AND country = '魏';
显然就不是精确匹配了。
唯一性搜索
如果在扫描某个扫描区间的记录前,就能事先确定该扫描区间最多只包含1条记录的话,那么就把这种情况称作唯一性搜索。我们看一下代码中判定扫描某个扫描区间的记录是否是唯一性搜索的代码是怎么写的:

其中:
- 匹配模式是精确匹配
- 使用的索引是聚簇索引或唯一二级索引
- 如果索引中包含多个列,则每个列在生成扫描区间时都应该被用到
- 如果使用的索引是唯一二级索引,那么在搜索时不能搜索某个索引列为NULL的记录(因为对于唯一二级索引来说,是可以存储多个值为NULL的记录的)。
上边几点都比较好理解,我们稍微解释一下第3点。比方说我们为某个表的a、b两列建立了一个唯一二级索引uk_a_b(a, b),那么对于搜索条件a=1形成的扫描区间来说,不能保证该扫描区间最多只包含一条记录;对于搜索条件a=1 AND b= 1形成的扫描区间来说,才可以保证该扫描区间中仅包含1条记录(不包括记录的delete_flag=1的记录)。
row_search_mvcc
我们知道MySQL其实是分成server层和存储引擎层两部分,每当执行一个查询时,server层负责生成执行计划,即选取即将使用的索引以及对应的扫描区间。我们这里以InnoDB为例,针对每一个扫描区间,都会:
server层向InnoDB要扫描区间的第1条记录
InnoDB通过B+树定位到扫描区间的第1条记录(如果定位的是二级索引记录并有回表需求则回表获取完整的聚簇索引记录),然后返回给server层
server层判断记录是否符合搜索条件,如果符合则发送给客户端,不符合则跳过。继续向InnoDB要下一条记录。
小贴士:
此处将记录发送给客户端其实是发送到本地的网络缓冲区,缓冲区大小由net_buffer_length控制,默认是16KB大小。等缓冲区满了才真正发送网络包到客户端。
InnoDB根据记录的单向链表以及页面之间的双向链表找到下一条记录(如果定位的是二级索引记录并有回表需求则回表获取完整的聚簇索引记录),返回给server层。
server层处理该记录,并向InnoDB要下一条记录
... 不停执行上述过程,直到InnoDB读到一条不符合边界条件的记录为止
可见一般情况下,server层和存储引擎层是以记录为单位进行通信的,而InnoDB读取一条记录最重要的函数就是row_search_mvcc:
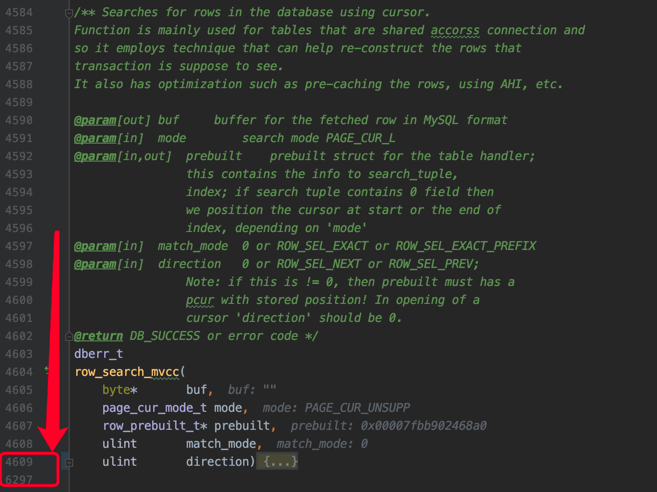
可以看到这个函数长到吓人,有一千多行。
小贴士:
不知道你们公司有没有在一个函数中把业务逻辑写到一千多行的同事,如果有的话你想不想打他。
在row_search_mvcc里,对一条记录进行诸如多版本的可见性判断,要不要对记录进行加锁的判断,要是加锁的话加什么锁的选择,完成记录从InnoDB的存储格式到server层存储格式的转换等等等等十分繁杂的工作。
其实对于UPDATE、DELETE语句来说,执行它们前都需要先在B+树中定位到相应的记录,所以它们也会调用row_search_mvcc。
InnoDB对记录的加锁操作主要是在row_search_mvcc中的,像SELECT ... LOCK IN SHARE MODE、SELECT ... FOR UPDATE、UPDATE、DELETE这样的语句都会调用row_search_mvcc完成加锁操作。SELECT ... LOCK IN SHARE MODE会为记录添加S型锁,SELECT ... FOR UPDATE、UPDATE、DELETE会为记录添加X型锁。
InnoDB每当读取一条记录时,都会调用一次row_search_mvcc,在做了足够长的铺垫之后,我们终于可以看一下在row_search_mvcc函数中是怎么对某条记录进行加锁的。
语句到底是怎么加锁的
首先看一个十分重要的变量:
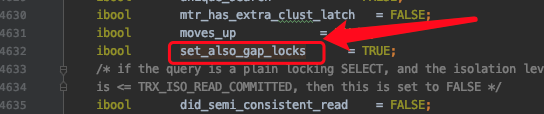
set_also_gap_locks表示是否要给记录添加gap锁(next-key锁可以看成是正经记录锁和gap锁的组合),它的默认值是TRUE,表示默认会给记录添加gap锁。
set_also_gap_locks可能会在下边这个地方发生变化:
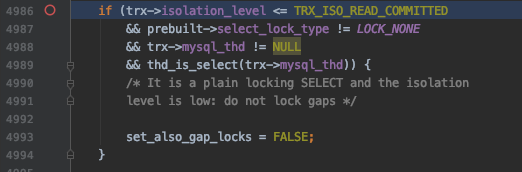
即如果当前执行的是SELECT ... LOCK IN SHARE MODE或者SELECT ... FOR UPDATE这样的加锁读语句(非DELETE或UPDATE语句),并且隔离级别不大于READ COMMITTED 时,将set_also_gap_locks设置为FALSE。
其中prebuilt->select_lock_type表示加锁的类型,LOCK_NONE表示不加锁,LOCK_S表示加S锁(比方说执行SELECT ... LOCK IN SHARE MODE时),LOCK_X表示加X锁(比方说执行SELECT ... FOR UPDATE、DELETE、UPDATE时)。
对普通的SELECT的处理和意向锁的添加
再往后看:
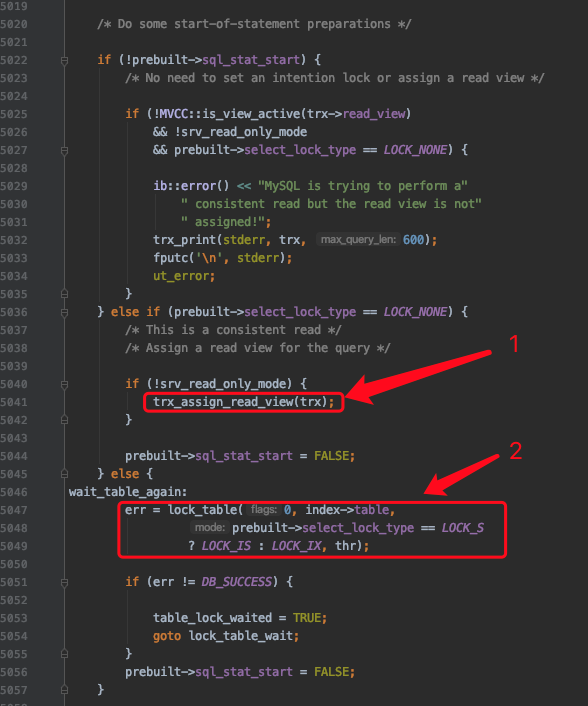
其中:
- 标号1的箭头是对普通的SELECT的处理,在查询开启前需要生成ReadView。
小贴士:
具体的讲就是对于Repeatable Read隔离级别来说,只在首次执行SELECT语句时生成Readview,之后的SELECT语句都复用这个ReadView;对于Read Committed隔离级别来说,每次执行SELECT语句时都会生成一个ReadView。这一点并不是在上边截图中的代码里实现的。
- 标号2的箭头是对加锁读的语句的处理,在首次读取记录(prebuilt->sql_stat_start表示是否是首次读取)前,需要添加表级别的意向锁(IS或IX锁)。
下边是真正处理记录并给记录加锁的流程,我们给这些流程编个号。
1. 定位扫描区间的第一条记录
下边开始通过B+树定位某个扫描区间中的第一条记录了(对于一个扫描区间来说,只执行一次下述函数,因为只要定位到扫描区间的第一条记录之后,就可以沿着记录所在的单向链表进行查询了):
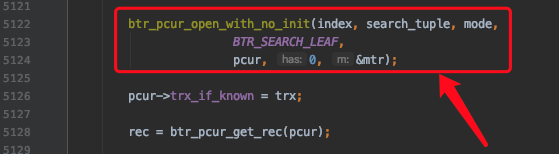
其中btr_pcur_open_with_no_init是用于定位扫描区间中的第一条记录的函数。
2. 对于ORDER BY ... DESC条件形成的扫描区间的第一条记录的处理
在B+树的每层节点中,记录是按照键值从小到大的方式进行排序的。对于某个扫描区间来说,InnoDB通常是定位到扫描区间中最左边的那条记录,也就是键值最小的那条记录,然后沿着从左往右的方式向后扫描。
但是对于下边这个查询来说:
SELECT * FROM hero WHERE name < 's孙权' AND country = '魏' ORDER BY name DESC FOR UPDATE ;
如果优化器决定使用二级索引idx_name执行上述查询的话,那么对应的扫描区间就是(-∞, 's孙权')。由于上述查询要求记录是按照从大到小的顺序返回给用户,所以InnoDB定位到扫描区间中的第一条记录应该是该扫描区间中最右边的那条记录,也就是键值最大的那条记录(在执行btr_pcur_open_with_no_init时就定位到最右边的那条记录),我们看一下idx_name二级索引示意图:
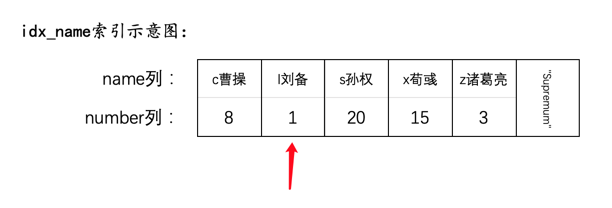
很显然,name值为'l刘备'的二级索引记录是扫描区间(-∞, 's孙权')中最右边的记录。
对于从右向左扫描扫描区间中记录的情况,针对从扫描区间中定位到的最右边的那条记录,需要做如下处理:
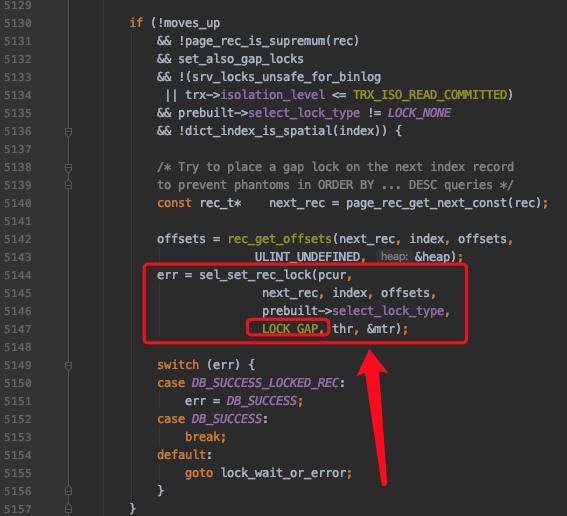
其中sel_set_rec_lock就是对一条记录进行加锁的函数。
可以看到,对于加锁读来说,在隔离级别不小于REPEATABLE READ并且也没有开启innodb_locks_unsafe_for_binlog系统变量的情况下,会对扫描区间中最右边的那条记录的下一条记录加一个类型为LOCK_GAP的锁,这个类型为LOCK_GAP的锁其实就是gap锁。
在本例中,假设事务的隔离级别是REPATABLE READ。扫描区间(-∞, 's孙权')中最右边的那条记录就是name值为'l刘备'的二级索引记录,接下来就应该为该记录的下一条记录,也就是name值为's孙权'的二级索引记录加一个gap锁。
小贴士:
大家可以读一下上述代码的注释,其实这样加锁主要是为了阻止幻读。另外,这一步骤的加锁仅仅针对从右向左的扫描区间中的最右边的那条记录,之后扫描该扫描区间中的其他记录时就不做这一步的操作了。
3. 真正的加锁流程才开始——对Infimum和Supremum记录的处理
步骤1是用来定位扫描区间中的第一条记录,针对一个扫描区间只执行1次。
步骤2是针对从右向左扫描的扫描区间中最右边的那条记录的下一条记录进行加锁,针对一个扫描区间也执行1次。
从第3步骤开始以及往后的步骤,扫描区间中的每一条记录都要经历。
先看一下如果当前记录是Infimum记录或者Supremum记录时的处理:
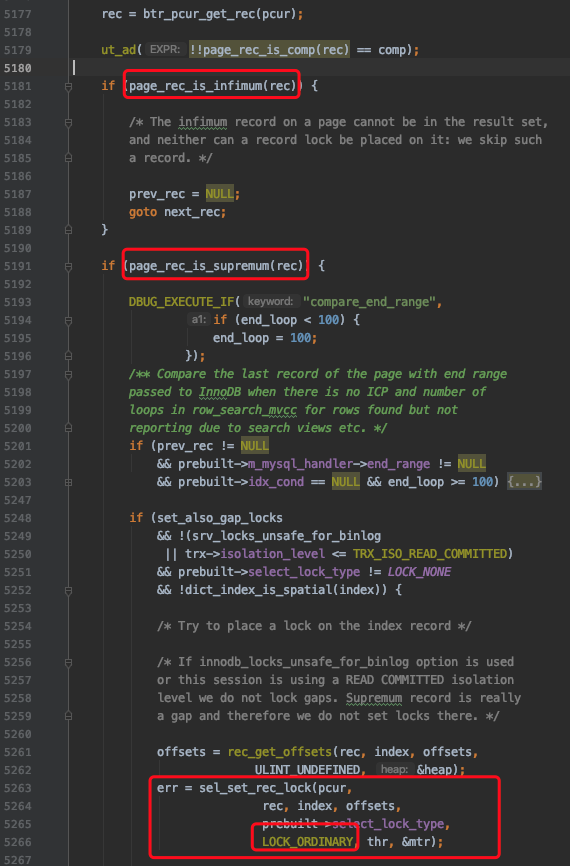
从上边的代码中可以看出,如果当前读取的记录是Infimum记录,则啥也不做,直接去读下一条记录。
如果当前读取的记录是Supremum记录,则在下边这些条件成立的时候就会为记录添加一个类型为LOCK_ORDINARY的锁,其实也就是next-key锁:
set_also_gap_locks是TRUE(这个变量只在前边设置过,当隔离级别不大于READ COMMITTED的SELECT语句的加锁读会设置为FALSE,否则为TRUE)
未开启
innodb_locks_unsafe_for_binlog系统变量并且事务的隔离级别不小于REPEATABLE READ。本次读取属于加锁读
所使用的不是空间索引。
其实由于Supremum记录本身是一条伪记录,别的事务并不会更新或删除它,所以给它添加next-key锁起到的效果和给它添加gap锁是一样的。
小贴士:
Infimum记录和Supremum记录是InnoDB自动为B+树中的每个页面都添加的两条虚拟记录,也可以被称作伪记录。Infimum记录和Supremum记录分别占用13字节的存储空间,被放置在页面中固定的位置。其中Infimum记录被看作最小的记录,Supremum记录被看作最大的记录,Infimum记录属于页面中的记录单向链表的头节点,Supremum记录属于页面中的记录单向链表的尾节点。更多关于页面结构的内容小伙伴们可以参考《MySQL是怎样运行的:从根儿上理解MySQL》书籍哈~
4. 真正的加锁流程才开始——对精确匹配的特殊处理
如果当前记录不是Infimum记录或者Supremum记录,下边进入对匹配模式是精确匹配的一个特殊处理:
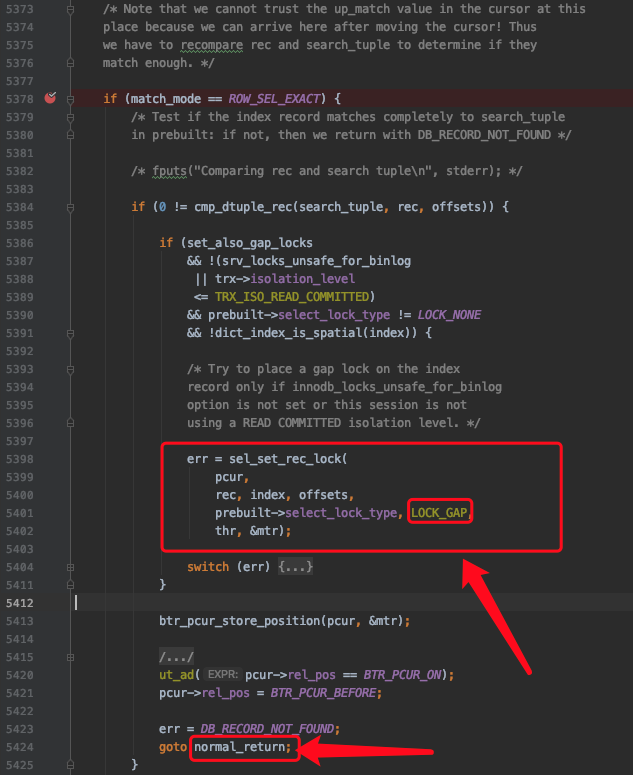
可以看到,对于匹配模式是精确匹配的扫描区间来说,如果执行本次row_search_mvcc获取到的记录不在扫描区间中(0 != cmp_dtuple_rec(search_tuple, rec, offsets)),则需要进行一些特殊处理,即:
对于加锁读来说,如果事务的隔离级别不小于Repeatable Read并且未开启innodb_locks_unsafe_for_binlog系统变量,那么就对该记录加一个gap锁,并且直接返回(代码中直接跳转到normal_return处),就不进行后续的加锁操作了。
我们举一个例子,比方说当前事务的隔离级别为Repeatable Read,执行如下语句:
SELECT * FROM hero WHERE name = 's孙权' FOR UPDATE;
如果使用二级索引idx_name执行上述查询,那么对应的扫描区间就是['s孙权', 's孙权']。该语句会首先对name值是's孙权'的记录进行加锁,不过该记录是在扫描区间中的,上述代码并不处理这种正常情况,关于正常情况的加锁我们稍后分析。
当读取完's孙权'的记录后,InnoDB会根据记录的next_record属性找到下一条二级索引记录,即name值为'x荀彧'的二级索引记录,该记录不在扫描区间['s孙权', 's孙权']中,即符合 0 != cmp_dtuple_rec(search_tuple, rec, offsets)条件,那么就执行上述代码的加锁流程 —— 对name值为'x荀彧'的二级索引记录加一个gap锁。另外,err被赋值为DB_RECORD_NOT_FOUND,这意味着向server层报告当前扫描区间的记录都已经扫描完了,server层在收到这个信息后就会停止向Innodb索要下一条记录的请求,即结束本扫描区间的查询。
小贴士:
这一步骤是对精确匹配的扫描区间的一个特殊处理,即当server层收到InnoDB返回的扫描区间的最后一条记录,server层仍会向InnoDB索要下一条记录。InnoDB仍会沿着记录所在的链表向后读取,此次读取到的记录就不在扫描区间中了,如例子中的name值为'x荀彧'的二级索引记录就不在扫描区间['s孙权', 's孙权']中。如果这是一个精确匹配的扫描区间,那么就进行如步骤4所示的特殊处理,如果不是的话,就继续执行第5步,也就是走正常的加锁流程。
5. 真正的加锁流程才开始——这回真的开始了
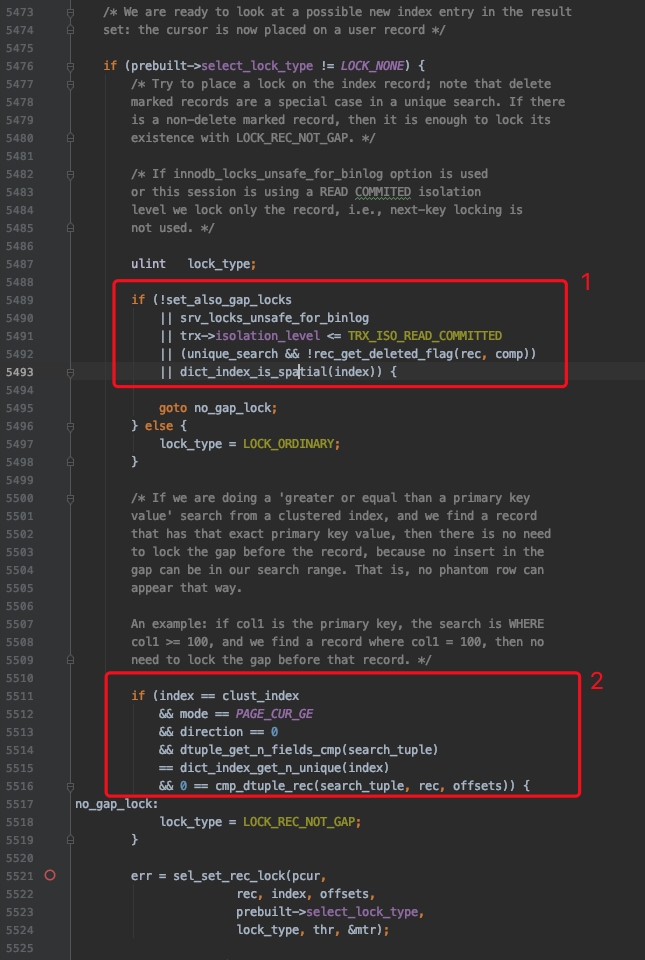
我们在代码中画了2个红框,这两个红框是对记录是不对记录加gap锁的场景。我们具体看一下。
对于1号红框来说:
set_also_gap_locks是FALSE(这个变量只在前边设置过,当隔离级别不大于READ COMMITTED的SELECT语句的加锁读会设置为FALSE,否则为TRUE)
开启
innodb_locks_unsafe_for_binlog系统变量事务的隔离级别不大于READ COMMITTED
唯一性搜索并且该记录的delete_flag不为1
该索引是空间索引
也就是说只要上边任意一个条件成立,该记录就不应该被加gap锁,而应该添加正经记录锁。其余情况就应该加next-key锁(gap锁和正经记录锁的合体)了。
紧接着2号红框就又叙述了一个不加gap锁的场景:
对于>= 主键的这种边界条件来说,如果当前记录恰好是开始边界,就仅需对该记录加正经记录锁,而不需添加gap锁。
1号红框的内容比较好理解,我们举个例子看一下2号红框是在说什么。比方说下边这个查询:
SELCT * FROM hero WHERE number >= 8 FOR UPDATE;
我们假设这个语句在隔离级别为REPEATABLE READ。
很显然,优化器会扫描[8, +∞)的聚簇索引记录。首先要通过B+树定位到扫描区间[8, +∞)的第一条记录,也就是number值为8的聚簇索引记录,这条记录就是扫描区间[8, +∞)的开始边界记录。按理说在REPEATABLE READ隔离级别下应该添加next-key锁,但由于2号红框中代码的存在,仅会给number值为8的聚簇索引记录添加正经记录锁。
小贴士:
2号方框的优化主要是基于“主键值是唯一的”这条约束,在一个事务执行了上述查询之后,其他事务是不能插入number值为8的记录的,这也用不着gap锁了。
除了1号方框和2号方框的场景,其余场景都给记录加next-key锁就好喽~
6. 判断索引条件下推的条件是否成立
如果是使用二级索引执行查询,并且有索引条件下推(Index Condition Pushdown,简称ICP)的条件的话,判断下推的条件是否成立:
这里大家特别注意一下,在使用二级索引执行查询,对于非精确匹配的扫描区间来说,形成扫描区间的边界条件也会被当作ICP条件下推到存储引擎判断,比方说下边这个查询:
mysql> EXPLAIN SELECT * FROM hero WHERE name > 's孙权' AND name < 'z诸葛亮' FOR UPDATE;+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+| 1 | SIMPLE | hero | NULL | range | idx_name | idx_name | 303 | NULL | 1 | 100.00 | Using index condition |+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+-----------------------+1 row in set, 1 warning (0.03 sec)
可以看到优化器决定使用idx_name执行上述查询,对应的扫描区间就是('s孙权', 'z诸葛亮'),形成这个扫描区间的边界条件就是name > 's孙权' AND name < 'z诸葛亮'。在执行计划的Extra列中出现了Using index condition,表明将边界条件name > 's孙权' AND name < 'z诸葛亮'作为ICP条件下推到了存储引擎。
不下推不要紧,一下推的话row_search_idx_cond_check就会判断当前记录是否已经不在扫描区间中了,如果不在扫描区间中的话,该函数就会返回ICP_OUT_OF_RANGE。这样的话,err被赋值为DB_RECORD_NOT_FOUND,这意味着向server层报告当前扫描区间的记录都已经扫描完了,server层在收到这个信息后就会停止向Innodb索要下一条记录的请求,即结束本扫描区间的查询。
当然,如果本次查询没有ICP条件,row_search_idx_cond_check直接返回ICP_MATCH,那就没有上述的麻烦事儿,继续向下走。
7. 回表对记录加锁
如果row_search_mvcc读取的是二级索引记录,则还需进行回表,找到相应的聚簇索引记录后需对该聚簇索引记录加一个正经记录锁:
其中,row_sel_get_clust_rec_for_mysql便是用于回表的函数,对聚簇索引进行加锁的逻辑在该函数中实现,我们这里就不展开了。
需要注意的是,即使是对于覆盖索引的场景下,如果我们想对记录加X型锁(也就是使用SELECT ... FOR UPDATE、DELETE、UPDATE语句时)时,也需要对二级索引记录执行回表操作,并给相应的聚簇索引记录添加正经记录锁。
8. row_search_mvcc返回,判断是否已经到达边界
每当处理完一条记录后,还需要判断一下这条记录还在不在扫描区间中,判断的代码如下:
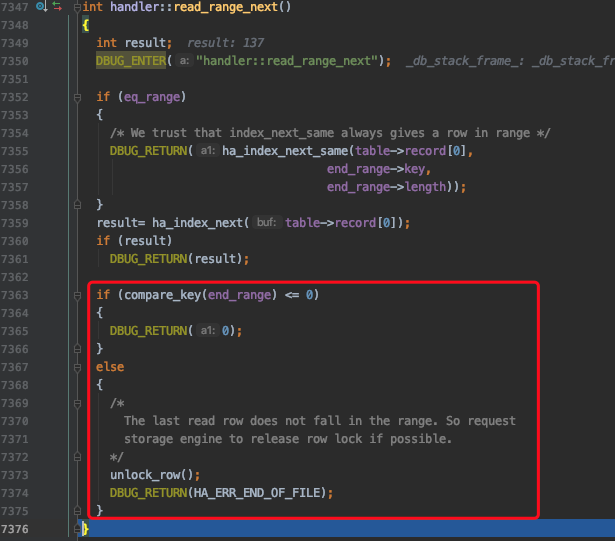
如果当前记录还在扫描区间中,就给server层正常返回,如果不在了,就给server层返回一个HA_ERR_END_OF_FILE信息,表示当前扫描区间的记录都已经扫描完了,server层在收到这个信息后就会停止向Innodb索要下一条记录的请求,即结束本扫描区间的查询。
小贴士:
之前在处理精确匹配以及ICP条件时可能把err变量赋值为DB_RECORD_NOT_FOUND,其实后续代码会将这种情况也转换为给server层返回HA_ERR_END_OF_FILE信息。
9. 然后,再处理下一条记录
server层收到InnoDB的一条记录后,如果收到InnoDB通知的本扫描区间已经扫描完毕的信息,则结束本扫描区间的查询;否则继续向InnoDB要下一条记录,也就是需要继续执行一遍row_search_mvcc函数了。
不过此时并不是定位扫描区间中的第一条记录,而是根据记录所在的链表去取下一条记录即可,所以直接从步骤3开始执行就好了,又开始了新的一条记录的加锁流程。。。
循环往复,直到server层收到本扫描区间所有记录都扫描完了的信息为止。
还有一些释放锁的场景
大家在步骤8判断当前记录是否已经不再扫描区间中时可以看到,如果当前记录不在扫描区间中,会执行一个unlock_row的函数,这个函数主要是用于在隔离级别不大于READ COMMITTED时释放当前记录上的锁(如果是二级索引记录还要释放相应的聚簇索引记录上的锁)。
释放锁的场景并不是只有这么一个,在row_search_mvcc中也有几处释放锁的场景,我们这里就不多唠叨了。
总结一下
其实大家再回头看row_search_mvcc里的关于加锁的代码就会发现,其实流程还是很简单的:
步骤1. 定位扫描区间的第一条记录。
步骤2. 如果扫描区间是从右到左扫描,那么需要给扫描区间最右边的记录的下一条记录添加一个gap锁(在隔离级别不小于
REPEATABLE READ并且也没有开启innodb_locks_unsafe_for_binlog系统变量的情况下)。步骤3. 对于
Infimum记录是不加锁的,对于Supremum记录加next-key锁(在隔离级别不小于REPEATABLE READ并且也没有开启innodb_locks_unsafe_for_binlog系统变量的情况下)。步骤4. 对于精确匹配的扫描区间来说,当扫描区间中的记录都被读完后,需对扫描区间后的第一条记录加一个gap锁即可,并且向server层返回可结束本扫描区间的查询的信息(在隔离级别不小于
REPEATABLE READ并且也没有开启innodb_locks_unsafe_for_binlog系统变量的情况下)。步骤5. 事务的隔离级别不大于READ COMMITTED,开启
innodb_locks_unsafe_for_binlog系统变量,唯一性搜索并且该记录的delete_flag不为1,对于>= 主键的这种边界条件来说,当前记录恰好是开始边界记录,则对记录加正经记录锁,否则添加next-key锁。步骤6. 判断ICP条件是否成立。如果当前记录是二级索引记录,并且已经不在扫描区间中,则向server层返回可结束本扫描区间的查询的信息。
步骤7. 如果对二级索引记录进行加锁,还需要对相应的聚簇索引记录加
正经记录锁(使用覆盖索引,并且加S型锁的记录可跳过此步骤)。步骤8. 判断当前记录是否已不在扫描区间中,如果不在的话,则向server返回可结束本扫描区间的查询的信息。
步骤9. 如果server层收到可结束本扫描区间的查询的信息,则结束本扫描区间的查询,否则继续向InnoDB要下一条记录,InnoDB根据记录所在的链表获取到下一条记录后,从
步骤3开始新一轮的轮回。
好了,到现在为止大家应该明白为什么最开始说的即使是全表扫描的加锁读,加的也是行锁而不是表锁了。在使用InnoDB存储引擎时,当进行全表扫描时,其实就是相当于扫描主键值在(-∞, +∞)这个扫描区间中的聚簇索引记录,针对每一条聚簇索引记录,都需要执行一次row_search_mvcc函数,都需要进行如上所述的各种判断,最后决定给扫描的记录加什么锁。
语句加锁分析
标签: MySQL是怎样运行的
事前准备
建立一个存储三国英雄的hero表:
CREATE TABLE hero (number INT,name VARCHAR(100),country varchar(100),PRIMARY KEY (number),KEY idx_name (name)) Engine=InnoDB CHARSET=utf8;
然后向这个表里插入几条记录:
INSERT INTO hero VALUES(1, 'l刘备', '蜀'),(3, 'z诸葛亮', '蜀'),(8, 'c曹操', '魏'),(15, 'x荀彧', '魏'),(20, 's孙权', '吴');
语句加锁分析
说了这么久,还是没说一条语句该加什么锁(心里是不是有点mmp啊[坏笑])。在进一步分析之前,我们先给hero表的name列建一个索引:
ALTER TABLE hero ADD INDEX idx_name (name);
然后现在hero表就有了两个索引(一个二级索引,一个聚簇索引),示意图如下:
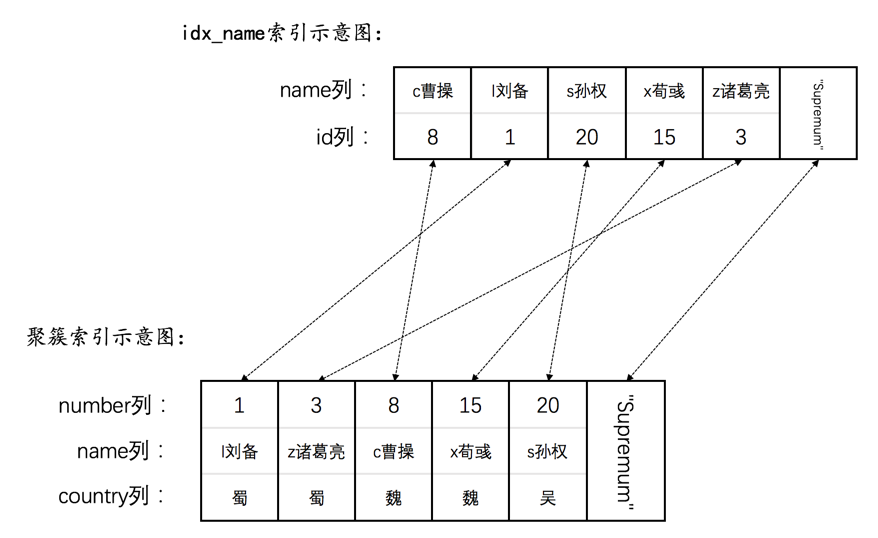
其实啊,“XXX语句该加什么锁”本身就是个伪命题,一条语句需要加的锁受到很多条件制约,比方说:
事务的隔离级别
语句执行时使用的索引(比如聚簇索引、唯一二级索引、普通二级索引)
查询条件(比方说
=、=<、>=等等)具体执行的语句类型
在继续详细分析语句的加锁过程前,大家一定要有一个全局概念:加锁只是解决并发事务执行过程中引起的脏写、脏读、不可重复读、幻读这些问题的一种解决方案(MVCC算是一种解决脏读、不可重复读、幻读这些问题的一种解决方案),一定要意识到加锁的出发点是为了解决这些问题,不同情景下要解决的问题不一样,才导致加的锁不一样,千万不要为了加锁而加锁,容易把自己绕进去。当然,有时候因为MySQL具体的实现而导致一些情景下的加锁有些不太好理解,这就得我们死记硬背了~
我们这里把语句分为3种大类:普通的SELECT语句、锁定读的语句、INSERT语句,我们分别看一下。
普通的SELECT语句
普通的SELECT语句在:
READ UNCOMMITTED隔离级别下,不加锁,直接读取记录的最新版本,可能发生脏读、不可重复读和幻读问题。READ COMMITTED隔离级别下,不加锁,在每次执行普通的SELECT语句时都会生成一个ReadView,这样解决了脏读问题,但没有解决不可重复读和幻读问题。REPEATABLE READ隔离级别下,不加锁,只在第一次执行普通的SELECT语句时生成一个ReadView,这样把脏读、不可重复读和幻读问题都解决了。不过这里有一个小插曲:
# 事务T1,REPEATABLE READ隔离级别下mysql> BEGIN;Query OK, 0 rows affected (0.00 sec)mysql> SELECT * FROM hero WHERE number = 30;Empty set (0.01 sec)# 此时事务T2执行了:INSERT INTO hero VALUES(30, 'g关羽', '魏'); 并提交mysql> UPDATE hero SET country = '蜀' WHERE number = 30;Query OK, 1 row affected (0.01 sec)Rows matched: 1 Changed: 1 Warnings: 0mysql> SELECT * FROM hero WHERE number = 30;+--------+---------+---------+| number | name | country |+--------+---------+---------+| 30 | g关羽 | 蜀 |+--------+---------+---------+1 row in set (0.01 sec)
在
REPEATABLE READ隔离级别下,T1第一次执行普通的SELECT语句时生成了一个ReadView,之后T2向hero表中新插入了一条记录便提交了,ReadView并不能阻止T1执行UPDATE或者DELETE语句来对改动这个新插入的记录(因为T2已经提交,改动该记录并不会造成阻塞),但是这样一来这条新记录的trx_id隐藏列就变成了T1的事务id,之后T1中再使用普通的SELECT语句去查询这条记录时就可以看到这条记录了,也就把这条记录返回给客户端了。因为这个特殊现象的存在,你也可以认为InnoDB中的MVCC并不能完完全全的禁止幻读。SERIALIZABLE隔离级别下,需要分为两种情况讨论:在系统变量
autocommit=0时,也就是禁用自动提交时,普通的SELECT语句会被转为SELECT ... LOCK IN SHARE MODE这样的语句,也就是在读取记录前需要先获得记录的S锁,具体的加锁情况和REPEATABLE READ隔离级别下一样,我们后边再分析。在系统变量
autocommit=1时,也就是启用自动提交时,普通的SELECT语句并不加锁,只是利用MVCC来生成一个ReadView去读取记录。为啥不加锁呢?因为启用自动提交意味着一个事务中只包含一条语句,一条语句也就没有啥
不可重复读、幻读这样的问题了。
锁定读的语句
我们把下边四种语句放到一起讨论:
语句一:
SELECT ... LOCK IN SHARE MODE;语句二:
SELECT ... FOR UPDATE;语句三:
UPDATE ...语句四:
DELETE ...
我们说语句一和语句二是MySQL中规定的两种锁定读的语法格式,而语句三和语句四由于在执行过程需要首先定位到被改动的记录并给记录加锁,也可以被认为是一种锁定读。
READ UNCOMMITTED/READ COMMITTED隔离级别下
在READ UNCOMMITTED下语句的加锁方式和READ COMMITTED隔离级别下语句的加锁方式基本一致,所以就放到一块儿说了。值得注意的是,采用加锁方式解决并发事务带来的问题时,其实脏读和不可重复读在任何一个隔离级别下都不会发生(因为读-写操作需要排队进行)。
对于使用主键进行等值查询的情况
使用
SELECT ... LOCK IN SHARE MODE来为记录加锁,比方说:SELECT * FROM hero WHERE number = 8 LOCK IN SHARE MODE;
这个语句执行时只需要访问一下聚簇索引中
number值为8的记录,所以只需要给它加一个S型正经记录锁就好了,如图所示: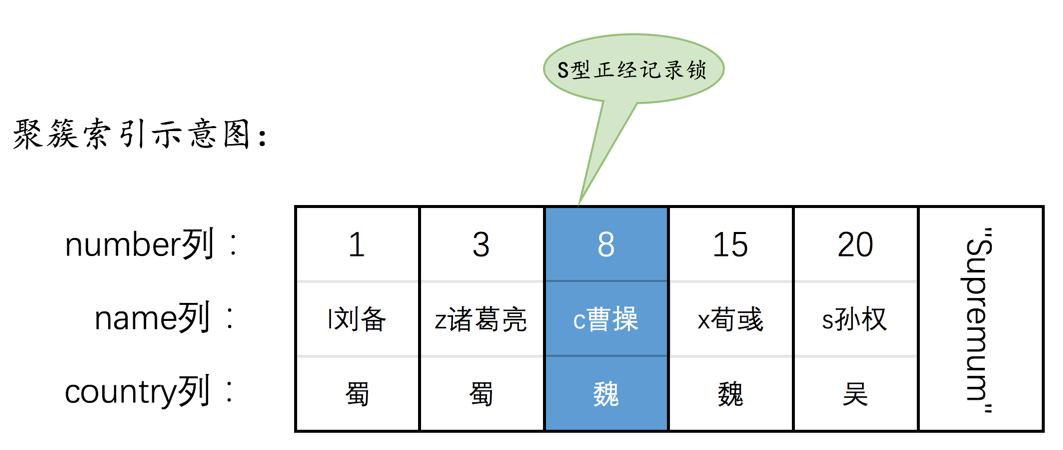
使用
SELECT ... FOR UPDATE来为记录加锁,比方说:SELECT * FROM hero WHERE number = 8 FOR UPDATE;
这个语句执行时只需要访问一下聚簇索引中
number值为8的记录,所以只需要给它加一个X型正经记录锁就好了,如图所示: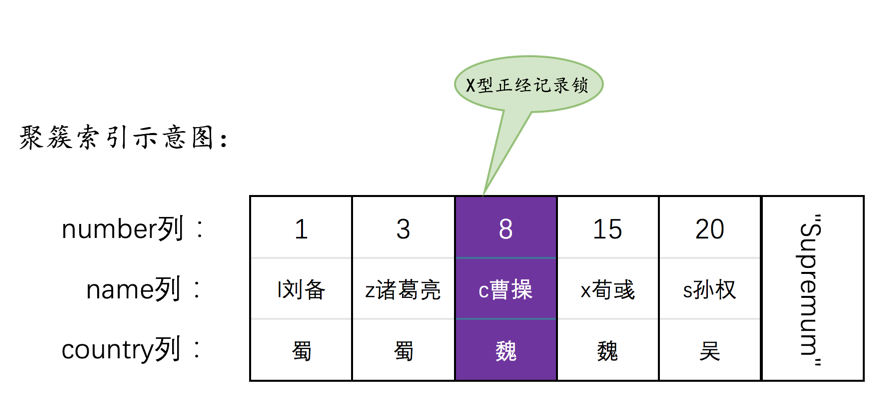
小贴士:为了区分S锁和X锁,我们之后在示意图中就把加了S锁的记录染成蓝色,把加了X锁的记录染成紫色。
使用
UPDATE ...来为记录加锁,比方说:UPDATE hero SET country = '汉' WHERE number = 8;
这条
UPDATE语句并没有更新二级索引列,加锁方式和上边所说的SELECT ... FOR UPDATE语句一致。如果
UPDATE语句中更新了二级索引列,比方说:UPDATE hero SET name = 'cao曹操' WHERE number = 8;
该语句的实际执行步骤是首先更新对应的
number值为8的聚簇索引记录,再更新对应的二级索引记录,所以加锁的步骤就是:为
number值为8的聚簇索引记录加上X型正经记录锁(该记录对应的)。为该聚簇索引记录对应的
idx_name二级索引记录(也就是name值为'c曹操',number值为8的那条二级索引记录)加上X型正经记录锁。
画个图就是这样:
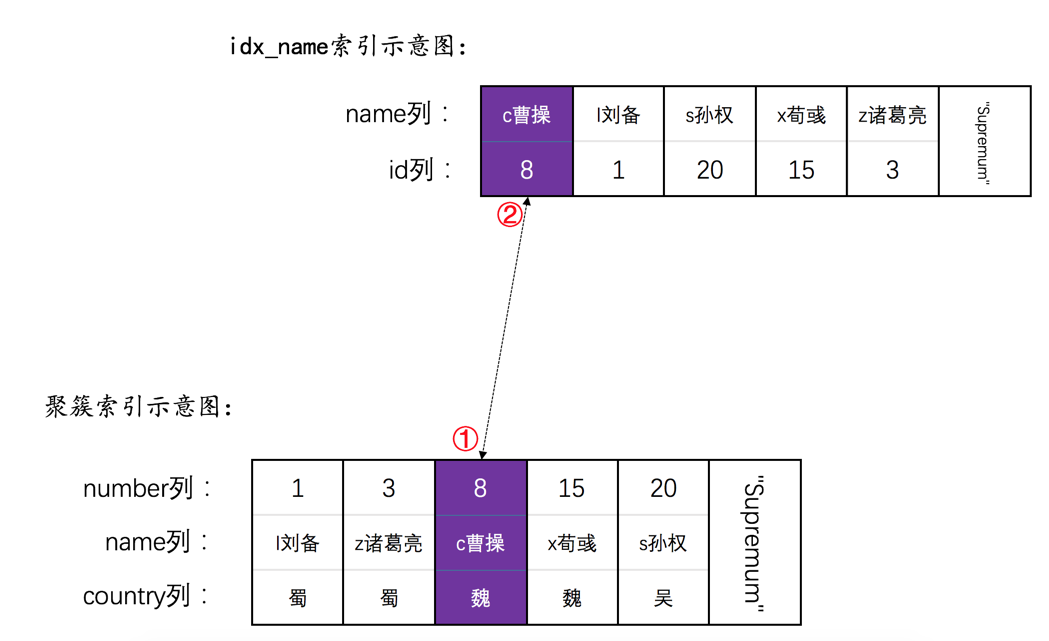
小贴士:我们用带圆圈的数字来表示为各条记录加锁的顺序。
使用
DELETE ...来为记录加锁,比方说:DELETE FROM hero WHERE number = 8;
我们平时所说的“DELETE表中的一条记录”其实意味着对聚簇索引和所有的二级索引中对应的记录做
DELETE操作,本例子中就是要先把number值为8的聚簇索引记录执行DELETE操作,然后把对应的idx_name二级索引记录删除,所以加锁的步骤和上边更新带有二级索引列的UPDATE语句一致,就不画图了。
对于使用主键进行范围查询的情况
使用
SELECT ... LOCK IN SHARE MODE来为记录加锁,比方说:SELECT * FROM hero WHERE number <= 8 LOCK IN SHARE MODE;
这个语句看起来十分简单,但它的执行过程还是有一丢丢小复杂的:
先到聚簇索引中定位到满足
number <= 8的第一条记录,也就是number值为1的记录,然后为其加锁。判断一下该记录是否符合
索引条件下推中的条件。我们前边介绍过一个称之为
索引条件下推(Index Condition Pushdown,简称ICP)的功能,也就是把查询中与被使用索引有关的查询条件下推到存储引擎中判断,而不是返回到server层再判断。不过需要注意的是,索引条件下推只是为了减少回表次数,也就是减少读取完整的聚簇索引记录的次数,从而减少IO操作。而对于聚簇索引而言不需要回表,它本身就包含着全部的列,也起不到减少IO操作的作用,所以设计InnoDB的大叔们规定这个索引条件下推特性只适用于二级索引。也就是说在本例中与被使用索引有关的条件是:number <= 8,而number列又是聚簇索引列,所以本例中并没有符合索引条件下推的查询条件,自然也就不需要判断该记录是否符合索引条件下推中的条件。判断一下该记录是否符合范围查询的边界条件
因为在本例中是利用主键
number进行范围查询,设计InnoDB的大叔规定每从聚簇索引中取出一条记录时都要判断一下该记录是否符合范围查询的边界条件,也就是number <= 8这个条件。如果符合的话将其返回给server层继续处理,否则的话需要释放掉在该记录上加的锁,并给server层返回一个查询完毕的信息。对于
number值为1的记录是符合这个条件的,所以会将其返回到server层继续处理。将该记录返回到
server层继续判断。server层如果收到存储引擎层提供的查询完毕的信息,就结束查询,否则继续判断那些没有进行索引条件下推的条件,在本例中就是继续判断number <= 8这个条件是否成立。噫,不是在第3步中已经判断过了么,怎么在这又判断一回?是的,设计InnoDB的大叔采用的策略就是这么简单粗暴,把凡是没有经过索引条件下推的条件都需要放到server层再判断一遍。如果该记录符合剩余的条件(没有进行索引条件下推的条件),那么就把它发送给客户端,不然的话需要释放掉在该记录上加的锁。然后刚刚查询得到的这条记录(也就是
number值为1的记录)组成的单向链表继续向后查找,得到了number值为3的记录,然后重复第2,3,4、5这几个步骤。
小贴士:上述步骤是在MySQL 5.7.21这个版本中验证的,不保证其他版本有无出入。
但是这个过程有个问题,就是当找到
number值为8的那条记录的时候,还得向后找一条记录(也就是number值为15的记录),在存储引擎读取这条记录的时候,也就是上述的第1步中,就得为这条记录加锁,然后在第3步时,判断该记录不符合number <= 8这个条件,又要释放掉这条记录的锁,这个过程导致number值为15的记录先被加锁,然后把锁释放掉,过程就是这样: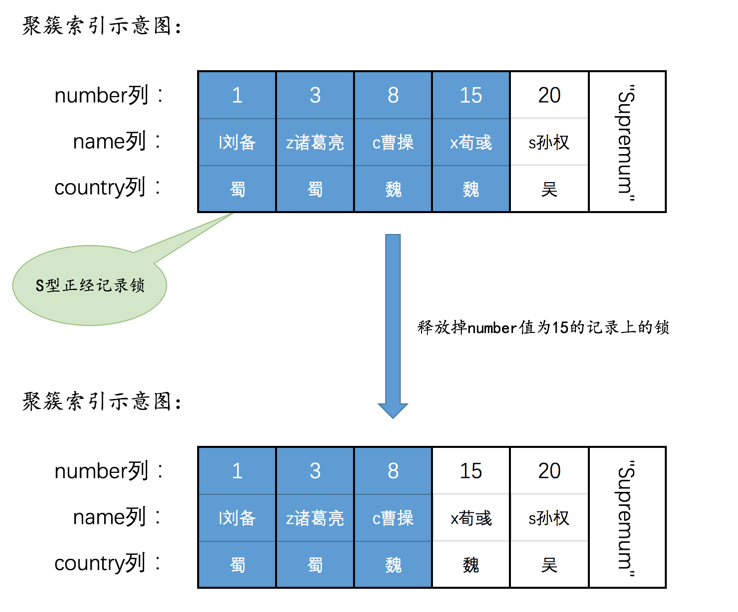
这个过程有意思的一点就是,如果你先在事务
T1中执行:# 事务T1BEGIN;SELECT * FROM hero WHERE number <= 8 LOCK IN SHARE MODE;
然后再到事务
T2中执行:# 事务T2BEGIN;SELECT * FROM hero WHERE number = 15 FOR UPDATE;
是没有问题的,因为在
T2执行时,事务T1已经释放掉了number值为15的记录的锁,但是如果你先执行T2,再执行T1,由于T2已经持有了number值为15的记录的锁,事务T1将因为获取不到这个锁而等待。我们再看一个使用主键进行范围查询的例子:
SELECT * FROM hero WHERE number >= 8 LOCK IN SHARE MODE;
这个语句的执行过程其实和我们举的上一个例子类似。也是先到聚簇索引中定位到满足
number >= 8这个条件的第一条记录,也就是number值为8的记录,然后就可以沿着由记录组成的单向链表一路向后找,每找到一条记录,就会为其加上锁,然后判断该记录符不符合范围查询的边界条件,不过这里的边界条件比较特殊:number >= 8,只要记录不小于8就算符合边界条件,所以判断和没判断是一样一样的。最后把这条记录返回给server层,server层再判断number >= 8这个条件是否成立,如果成立的话就发送给客户端,否则的话就结束查询。不过InnoDB存储引擎找到索引中的最后一条记录,也就是Supremum伪记录之后,在存储引擎内部就可以立即判断这是一条伪记录,不必要返回给server层处理,也没必要给它也加上锁(也就是说在第1步中就压根儿没给这条记录加锁)。整个过程会给number值为8、15、20这三条记录加上S型正经记录锁,画个图表示一下就是这样: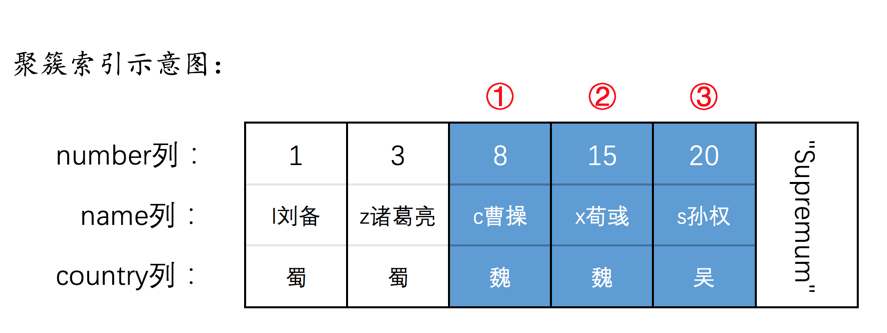
使用
SELECT ... FOR UPDATE语句来为记录加锁:和
SELECT ... FOR UPDATE语句类似,只不过加的是X型正经记录锁。使用
UPDATE ...来为记录加锁,比方说:UPDATE hero SET country = '汉' WHERE number >= 8;
这条
UPDATE语句并没有更新二级索引列,加锁方式和上边所说的SELECT ... FOR UPDATE语句一致。如果
UPDATE语句中更新了二级索引列,比方说:UPDATE hero SET name = 'cao曹操' WHERE number >= 8;
这时候会首先更新聚簇索引记录,再更新对应的二级索引记录,所以加锁的步骤就是:
为
number值为8的聚簇索引记录加上X型正经记录锁。然后为上一步中的记录索引记录对应的
idx_name二级索引记录加上X型正经记录锁。为
number值为15的聚簇索引记录加上X型正经记录锁。然后为上一步中的记录索引记录对应的
idx_name二级索引记录加上X型正经记录锁。为
number值为20的聚簇索引记录加上X型正经记录锁。然后为上一步中的记录索引记录对应的
idx_name二级索引记录加上X型正经记录锁。
画个图就是这样:
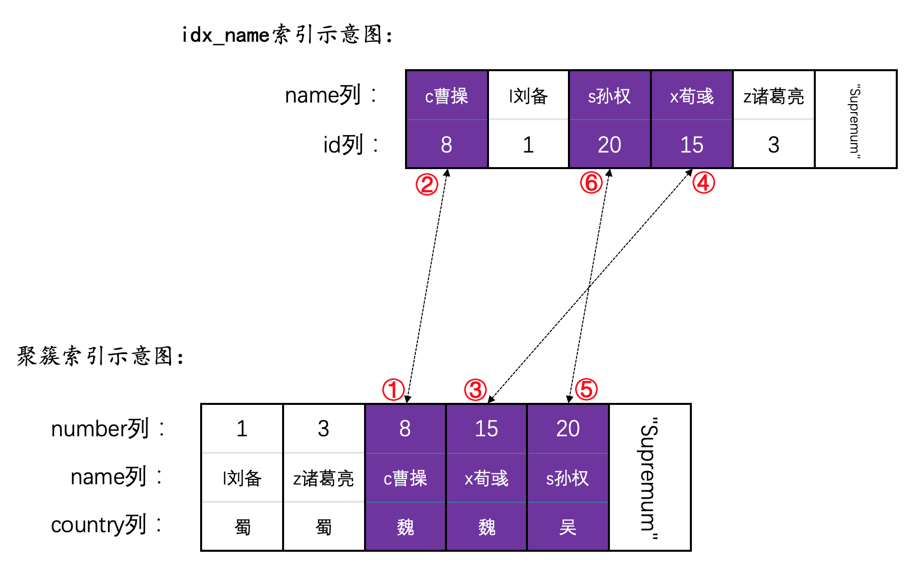
如果是下边这个语句:
UPDATE hero SET country = '汉' WHERE number <= 8;
则会对
number值为1、3、8聚簇索引记录以及它们对应的二级索引记录加X型正经记录锁,加锁顺序和上边语句中的加锁顺序类似,都是先对一条聚簇索引记录加锁后,再给对应的二级索引记录加锁。之后会继续对number值为15的聚簇索引记录加锁,但是随后InnoDB存储引擎判断它不符合边界条件,随即会释放掉该聚簇索引记录上的锁(注意这个过程中没有对number值为15的聚簇索引记录对应的二级索引记录加锁)。具体示意图就不画了。使用
DELETE ...来为记录加锁,比方说:DELETE FROM hero WHERE number >= 8;
和
DELETE FROM hero WHERE number <= 8;
这两个语句的加锁情况和更新带有二级索引列的
UPDATE语句一致,就不画图了。
对于使用二级索引进行等值查询的情况
小贴士:在READ UNCOMMITTED和READ COMMITTED隔离级别下,使用普通的二级索引和唯一二级索引进行加锁的过程是一样的,所以我们也就不分开讨论了。
使用
SELECT ... LOCK IN SHARE MODE来为记录加锁,比方说:SELECT * FROM hero WHERE name = 'c曹操' LOCK IN SHARE MODE;
这个语句的执行过程是先通过二级索引
idx_name定位到满足name = 'c曹操'条件的二级索引记录,然后进行回表操作。所以先要对二级索引记录加S型正经记录锁,然后再给对应的聚簇索引记录加S型正经记录锁,示意图如下: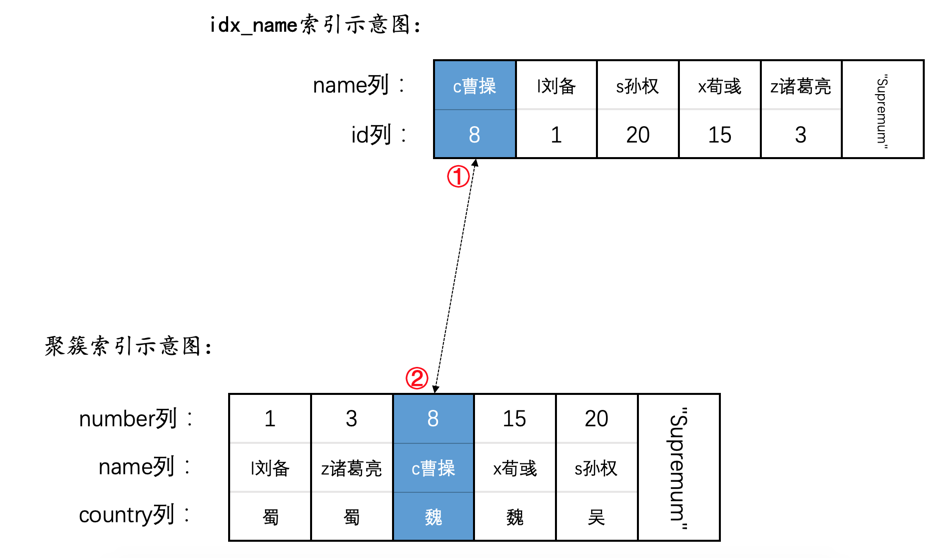
这里需要再次强调一下这个语句的加锁顺序:先对
name列为'c曹操'二级索引记录进行加锁。再对相应的聚簇索引记录进行加锁。
小贴士:我们知道idx_name是一个普通的二级索引,到idx_name索引中定位到满足name= 'c曹操'这个条件的第一条记录后,就可以沿着这条记录一路向后找。可是从我们上边的描述中可以看出来,并没有对下一条二级索引记录进行加锁,这是为什么呢?这是因为设计InnoDB的大叔对等值匹配的条件有特殊处理,他们规定在InnoDB存储引擎层查找到当前记录的下一条记录时,在对其加锁前就直接判断该记录是否满足等值匹配的条件,如果不满足直接返回(也就是不加锁了),否则的话需要将其加锁后再返回给server层。所以这里也就不需要对下一条二级索引记录进行加锁了。
现在要介绍一个非常有趣的事情,我们假设上边这个语句在事务
T1中运行,然后事务T2中运行下边一个我们之前介绍过的语句:UPDATE hero SET name = '曹操' WHERE number = 8;
这两个语句都是要对
number值为8的聚簇索引记录和对应的二级索引记录加锁,但是不同点是加锁的顺序不一样。这个UPDATE语句是先对聚簇索引记录进行加锁,后对二级索引记录进行加锁,如果在不同事务中运行上述两个语句,可能发生一种贼奇妙的事情 ——事务
T1持有了聚簇索引记录的锁,事务T2持有了二级索引记录的锁。事务
T1在等待获取二级索引记录上的锁,事务T2在等待获取聚簇索引记录上的锁。
两个事务都分别持有一个锁,而且都在等待对方已经持有的那个锁,这种情况就是所谓的
死锁,两个事务都无法运行下去,必须选择一个进行回滚,对性能影响比较大。使用
SELECT ... FOR UPDATE语句时,比如:SELECT * FROM hero WHERE name = 'c曹操' FOR UPDATE;
这种情况下与
SELECT ... LOCK IN SHARE MODE语句的加锁情况类似,都是给访问到的二级索引记录和对应的聚簇索引记录加锁,只不过加的是X型正经记录锁罢了。使用
UPDATE ...来为记录加锁,比方说:与更新二级索引记录的
SELECT ... FOR UPDATE的加锁情况类似,不过如果被更新的列中还有别的二级索引列的话,对应的二级索引记录也会被加锁。使用
DELETE ...来为记录加锁,比方说:与
SELECT ... FOR UPDATE的加锁情况类似,不过如果表中还有别的二级索引列的话,对应的二级索引记录也会被加锁。
对于使用二级索引进行范围查询的情况
使用
SELECT ... LOCK IN SHARE MODE来为记录加锁,比方说:SELECT * FROM hero FORCE INDEX(idx_name) WHERE name >= 'c曹操' LOCK IN SHARE MODE;
小贴士:因为优化器会计算使用二级索引进行查询的成本,在成本较大时可能选择以全表扫描的方式来执行查询,所以我们这里使用FORCE INDEX(idx_name)来强制使用二级索引idx_name来执行查询。
这个语句的执行过程其实是先到二级索引中定位到满足
name >= 'c曹操'的第一条记录,也就是name值为c曹操的记录,然后就可以沿着这条记录的链表一路向后找,从二级索引idx_name的示意图中可以看出,所有的用户记录都满足name >= 'c曹操'的这个条件,所以所有的二级索引记录都会被加S型正经记录锁,它们对应的聚簇索引记录也会被加S型正经记录锁。不过需要注意一下加锁顺序,对一条二级索引记录加锁完后,会接着对它相应的聚簇索引记录加锁,完后才会对下一条二级索引记录进行加锁,以此类推~ 画个图表示一下就是这样: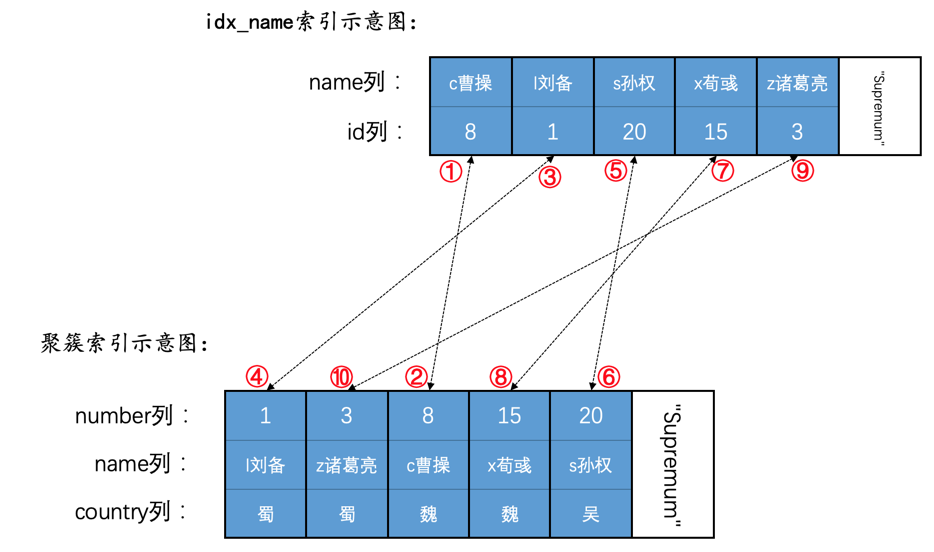
再来看下边这个语句:
SELECT * FROM hero FORCE INDEX(idx_name) WHERE name <= 'c曹操' LOCK IN SHARE MODE;
这个语句的加锁情况就有点儿有趣了。前边说在使用
number <= 8这个条件的语句中,需要把number值为15的记录也加一个锁,之后又判断它不符合边界条件而把锁释放掉。而对于查询条件name <= 'c曹操'的语句来说,执行该语句需要使用到二级索引,而与二级索引相关的条件是可以使用索引条件下推这个特性的。设计InnoDB的大叔规定,如果一条记录不符合索引条件下推中的条件的话,直接跳到下一条记录(这个过程根本不将其返回到server层),如果这已经是最后一条记录,那么直接向server层报告查询完毕。但是这里头有个问题呀:先对一条记录加了锁,然后再判断该记录是不是符合索引条件下推的条件,如果不符合直接跳到下一条记录或者直接向server层报告查询完毕,这个过程中并没有把那条被加锁的记录上的锁释放掉呀!!!。本例中使用的查询条件是name <= 'c曹操',在为name值为'c曹操'的二级索引记录以及它对应的聚簇索引加锁之后,会接着二级索引中的下一条记录,也就是name值为'l刘备'的那条二级索引记录,由于该记录不符合索引条件下推的条件,而且是范围查询的最后一条记录,会直接向server层报告查询完毕,重点是这个过程中并不会释放name值为'l刘备'的二级索引记录上的锁,也就导致了语句执行完毕时的加锁情况如下所示: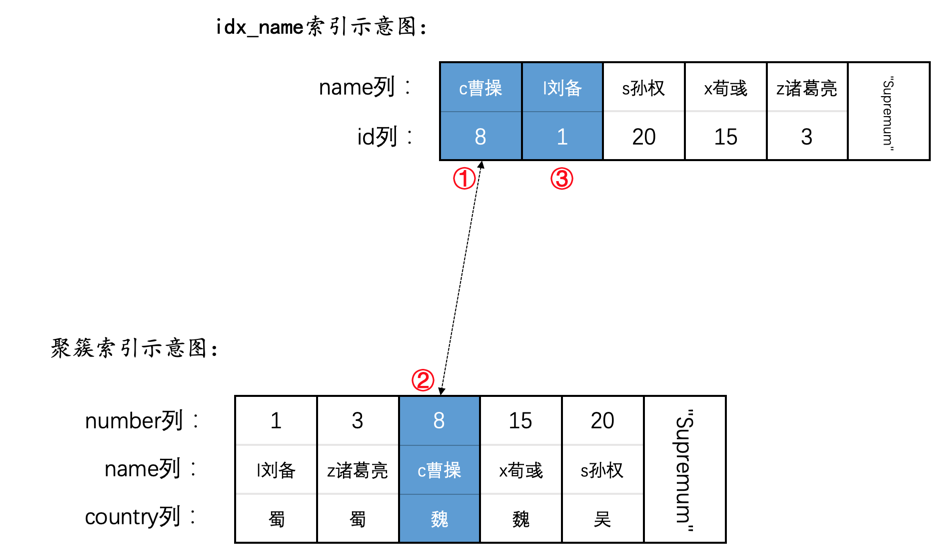
这样子会造成一个尴尬情况,假如
T1执行了上述语句并且尚未提交,T2再执行这个语句:SELECT * FROM hero WHERE name = 'l刘备' FOR UPDATE;
T2中的语句需要获取name值为l刘备的二级索引记录上的X型正经记录锁,而T1中仍然持有name值为l刘备的二级索引记录上的S型正经记录锁,这就造成了T2获取不到锁而进入等待状态。小贴士:为啥不能释放不符合索引条件下推中的条件的二级索引记录上的锁呢?这个问题我也没想明白,人家就是这么规定的,如果有明白的小伙伴可以加我微信 xiaohaizi4919 来讨论一下哈~ 再强调一下,我使用的MySQL版本是5.7.21,不保证其他版本中的加锁情景是否完全一致。
使用
SELECT ... FOR UPDATE语句时:和
SELECT ... FOR UPDATE语句类似,只不过加的是X型正经记录锁。使用
UPDATE ...来为记录加锁,比方说:UPDATE hero SET country = '汉' WHERE name >= 'c曹操';
小贴士:FORCE INDEX只对SELECT语句起作用,UPDATE语句虽然支持该语法,但实质上不起作用,DELETE语句压根儿不支持该语法。
假设该语句执行时使用了
idx_name二级索引来进行锁定读,那么它的加锁方式和上边所说的SELECT ... FOR UPDATE语句一致。如果有其他二级索引列也被更新,那么也会为对应的二级索引记录进行加锁,就不赘述了。不过还有一个有趣的情况,比方说:UPDATE hero SET country = '汉' WHERE name <= 'c曹操';
我们前边说的
索引条件下推这个特性只适用于SELECT语句,也就是说UPDATE语句中无法使用,那么这个语句就会为name值为'c曹操'和'l刘备'的二级索引记录以及它们对应的聚簇索引进行加锁,之后在判断边界条件时发现name值为'l刘备'的二级索引记录不符合name <= 'c曹操'条件,再把该二级索引记录和对应的聚簇索引记录上的锁释放掉。这个过程如下图所示: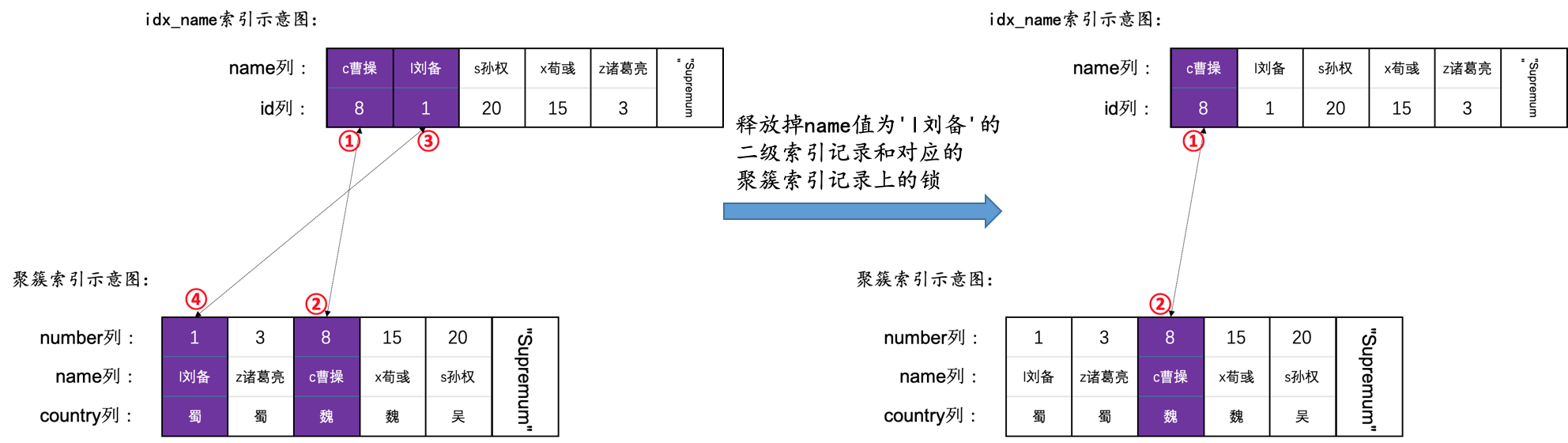
使用
DELETE ...来为记录加锁,比方说:DELETE FROM hero WHERE name >= 'c曹操';
和
DELETE FROM hero WHERE name <= 'c曹操';
如果这两个语句采用二级索引来进行
锁定读,那么它们的加锁情况和更新带有二级索引列的UPDATE语句一致,就不画图了。
全表扫描的情况
比方说:
SELECT * FROM hero WHERE country = '魏' LOCK IN SHARE MODE;
由于country列上未建索引,所以只能采用全表扫描的方式来执行这条查询语句,存储引擎每读取一条聚簇索引记录,就会为这条记录加锁一个S型正常记录锁,然后返回给server层,如果server层判断country = '魏'这个条件是否成立,如果成立则将其发送给客户端,否则会释放掉该记录上的锁,画个图就像这样:
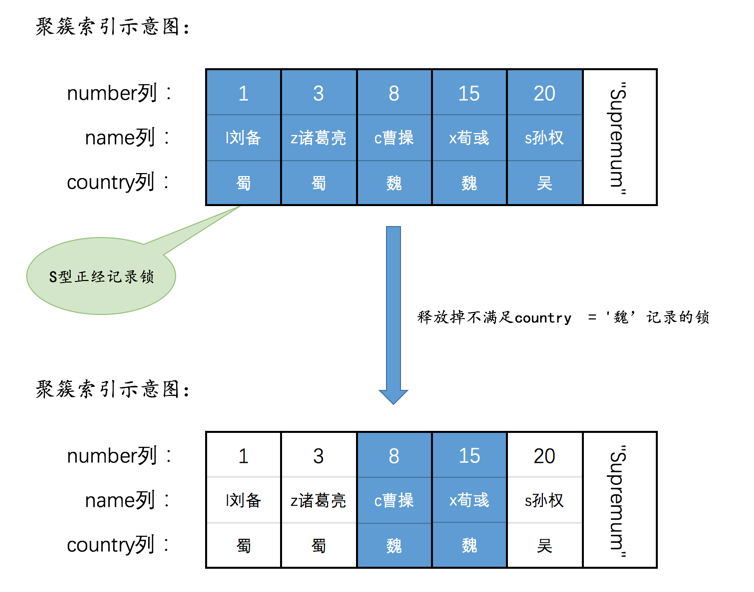
使用SELECT ... FOR UPDATE进行加锁的情况与上边类似,只不过加的是X型正经记录锁,就不赘述了。
对于UPDATE ...和DELETE ...的语句来说,在遍历聚簇索引中的记录,都会为该聚簇索引记录加上X型正经记录锁,然后:
如果该聚簇索引记录不满足条件,直接把该记录上的锁释放掉。
如果该聚簇索引记录满足条件,则会对相应的二级索引记录加上
X型正经记录锁(DELETE语句会对所有二级索引列加锁,UPDATE语句只会为更新的二级索引列对应的二级索引记录加锁)。
REPEATABLE READ隔离级别下
REPEATABLE READ隔离级别与READ UNCOMMITTED和READ COMMITTED这两个隔离级别相比,最主要的就是要解决幻读问题,幻读的解决还得靠我们上边讲过的gap锁。
对于使用主键进行等值查询的情况
使用
SELECT ... LOCK IN SHARE MODE来为记录加锁,比方说:SELECT * FROM hero WHERE number = 8 LOCK IN SHARE MODE;
我们知道主键具有唯一性,在一个事务中下次再执行这个查询语句的时候肯定不会有别的事务插入多条
number值为8的记录,所以这种情况下和READ UNCOMMITTED/READ COMMITTED隔离级别下一样,我们只需要为这条number值为8的记录加一个S型正经记录锁就好了,如图所示:但是如果我们查询了查询的主键值不存在,比方说:
SELECT * FROM hero WHERE number = 7 LOCK IN SHARE MODE;
由于
number值为7的记录不存在,为了禁止幻读现象,在当前事务提交前我们需要预防别的事务插入number值为7的新记录,所以需要在number值为8的记录上加一个gap锁,也就是不允许别的事务插入number值在(3, 8)这个区间的新记录。画个图表示一下: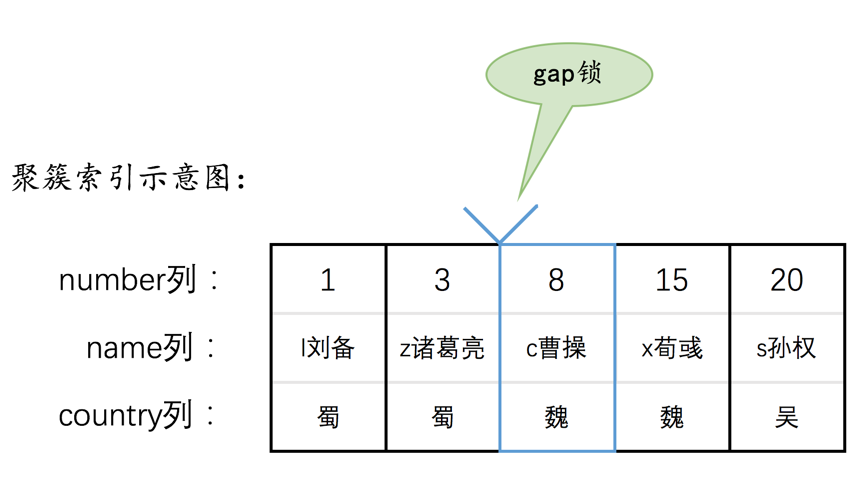
如果在READ UNCOMMITTED/READ COMMITTED隔离级别下一样查询了一条主键值不存在的记录,那么什么锁也不需要加,因为在READ UNCOMMITTED/READ COMMITTED隔离级别下,并不需要禁止幻读问题。
其余语句的使用主键进行等值查询的情况与READ UNCOMMITTED/READ COMMITTED隔离级别类似,这里就不赘述了。
对于使用主键进行范围查询的情况
使用
SELECT ... LOCK IN SHARE MODE来为记录加锁,比方说:SELECT * FROM hero WHERE number >= 8 LOCK IN SHARE MODE;
因为要解决幻读问题,所以禁止别的事务插入
number值符合number >= 8的记录,又因为主键本身就是唯一的,所以我们不用担心在number值为8的前边有新记录插入,只需要保证不要让新记录插入到number值为8的后边就好了,所以:- 为
number值为8的记录加一个S型正经记录锁。 - 为
number值大于8的记录都加一个S型next-key锁(包括Supremum伪记录)。
画个图就是这样子:

小贴士:为什么不给Supremum记录加gap锁,而要加next-key锁呢?其实设计InnoDB的大叔在处理Supremum记录上加的next-key锁时就是当作gap锁看待的,只不过为了节省锁结构(我们前边说锁的类型不一样的话不能被放到一个锁结构中)才这么做的而已,大家不必在意。
同样的,下边这个范围查询也是有点特殊:
SELECT * FROM hero WHERE number <= 8 LOCK IN SHARE MODE;
因为没有使用
索引记录下推,所以在加锁时会把number值为1、3、8、15这四条记录都加上S型next-key锁,不过之后server层判断number值为15的记录不满足number <= 8条件后,与READ UNCOMMITTED/READ COMMITTED隔离级别下的处理方式不同,REPEATABLE READ隔离级别下并不会把锁释放掉,所以现在的加锁的图示就是这样: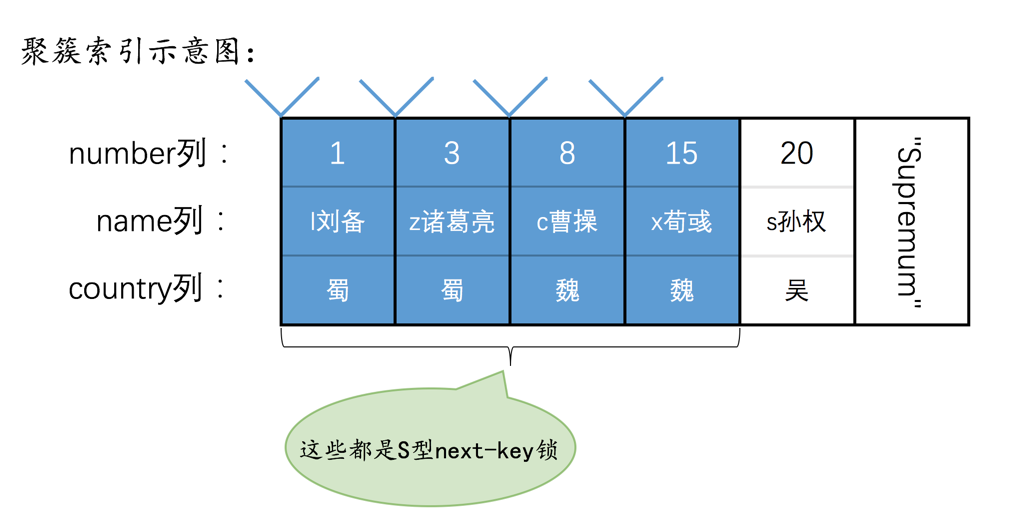
这样如果别的事务想要插入的新记录的
number值在(-∞, 1)、(1, 3)、(3, 8)、(8, 15)之间的话,是会进入等待状态的。使用
SELECT ... FOR UPDATE语句时:和
SELECT ... FOR UPDATE语句类似,只不过需要将上边提到的S型next-key锁替换成X型next-key锁。使用
UPDATE ...来为记录加锁:如果
UPDATE语句未更新二级索引列,比方说:UPDATE hero SET country = '汉' WHERE number >= 8;
这条
UPDATE语句并没有更新二级索引列,加锁方式和上边所说的SELECT ... FOR UPDATE语句一致。如果
UPDATE语句中更新了二级索引列,比方说:UPDATE hero SET name = 'cao曹操' WHERE number >= 8;
对聚簇索引加锁的情况和
SELECT ... FOR UPDATE一致,也就是对number值为8的记录加X型正经记录锁,对number值15、20的记录以及Supremum记录加X型next-key锁。但是也会对number值为8、15、20的二级索引记录加X型正经记录锁,画个图表示一下: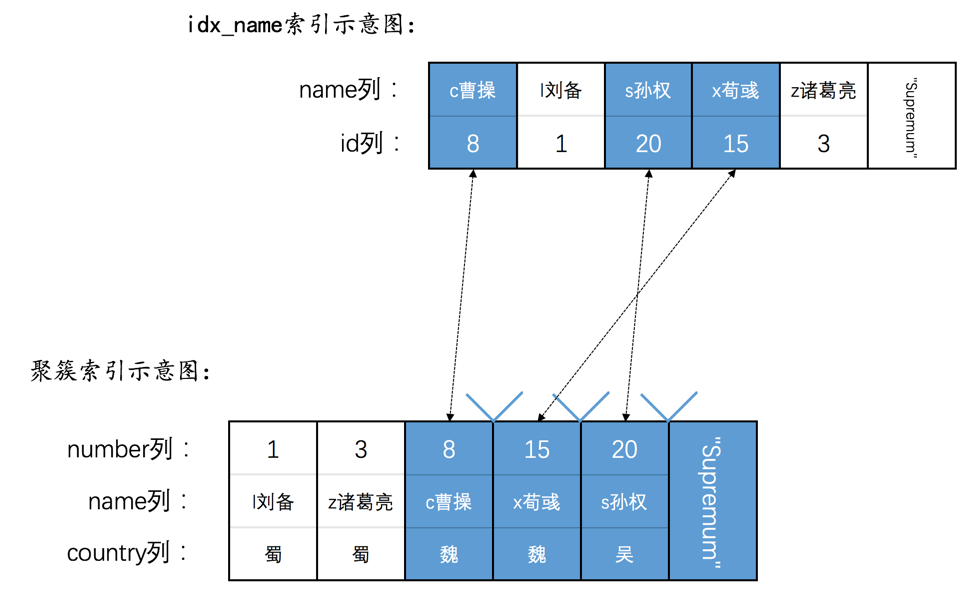
如果是下边这个语句:
UPDATE hero SET country = '汉' WHERE number <= 8;
则会对
number值为1、3、8、15的聚簇索引记录加X型next-key,但是由于number值为15的聚簇索引记录不满足number <= 8的条件,虽然在REPEATABLE READ隔离级别下不会将它的锁释放掉,但是也并不会对这条聚簇索引记录对应的二级索引记录加锁,也就是说只会为二级索引记录的number值为1、3、8的记录加X型正经记录锁,图就不画了。使用
DELETE ...来为记录加锁,比方说:DELETE FROM hero WHERE number >= 8;
和
DELETE FROM hero WHERE number <= 8;
这两个语句的加锁情况和更新带有二级索引列的
UPDATE语句一致,就不画图了。
对于使用唯一二级索引进行等值查询的情况
由于hero表并没有唯一二级索引,我们把原先的idx_name修改为一个唯一二级索引:
ALTER TABLE hero DROP INDEX idx_name, ADD UNIQUE KEY uk_name (name);
使用
SELECT ... LOCK IN SHARE MODE来为记录加锁,比方说:SELECT * FROM hero WHERE name = 'c曹操' LOCK IN SHARE MODE;
由于唯一二级索引具有唯一性,在一个事务中下次再执行这个查询语句的时候肯定不会有别的事务插入多条
name值为c曹操的记录,所以这种情况下和READ UNCOMMITTED/READ COMMITTED隔离级别下一样,我们只需要为这条name值为'c曹操'的二级索引记录加一个S型正经记录锁,然后再为它对应的聚簇索引记录加一个S型正经记录锁就好了,其实和READ UNCOMMITTED/READ COMMITTED隔离级别下加锁方式是一样的,我们画个图看看: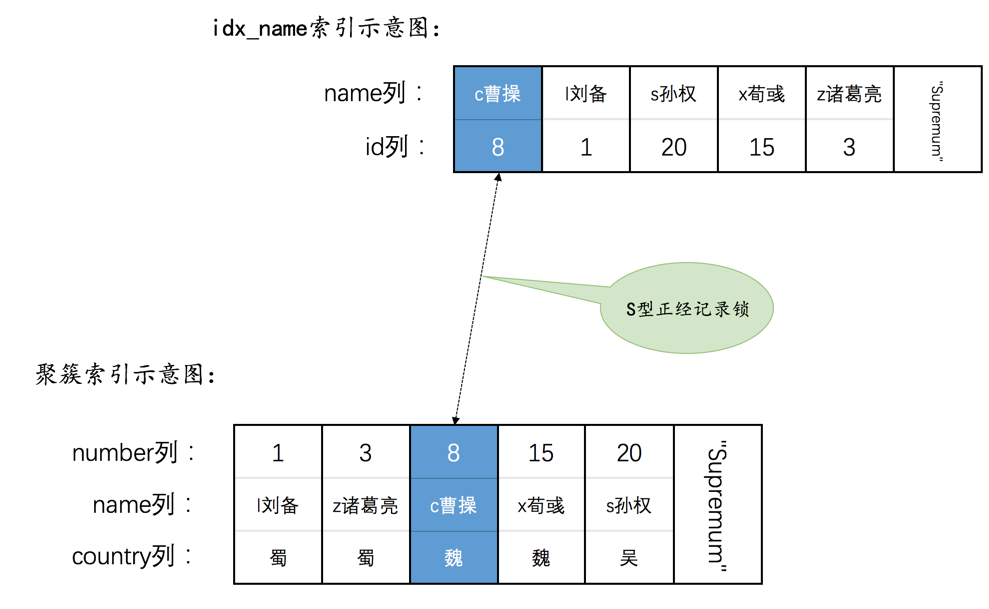
注意,是先对二级索引记录加锁,再对聚簇索引加锁。
如果对唯一二级索引等值查询的值并不存在,比如:
SELECT * FROM hero WHERE name = 'g关羽' LOCK IN SHARE MODE;
在唯一二级索引
uk_name中,键值比'g关羽'大的第一条记录的键值为l刘备,所以需要在这条二级索引记录上加一个gap锁,如图所示: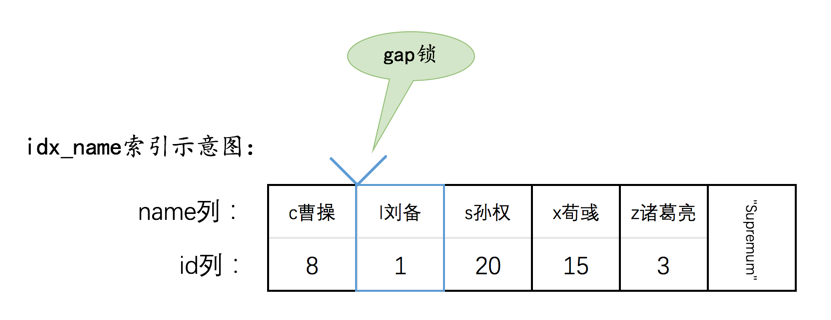
注意,这里只对二级索引记录进行加锁,并不会对聚簇索引记录进行加锁。
使用
SELECT ... FOR UPDATE语句时,比如:SELECT * FROM hero WHERE name = 'c曹操' FOR UPDATE;
这种情况下与
SELECT ... LOCK IN SHARE MODE语句的加锁情况类似,都是给访问到的二级索引记录和对应的聚簇索引记录加锁,只不过加的是X型正经记录锁罢了。使用
UPDATE ...来为记录加锁,比方说:与
SELECT ... FOR UPDATE的加锁情况类似,不过如果被更新的列中还有别的二级索引列的话,这些对应的二级索引列也会被加锁。使用
DELETE ...来为记录加锁,比方说:与
SELECT ... FOR UPDATE的加锁情况类似,不过如果表中还有别的二级索引列的话,这些对应的二级索引列也会被加锁。
对于使用唯一二级索引进行范围查询的情况
使用
SELECT ... LOCK IN SHARE MODE来为记录加锁,比方说:SELECT * FROM hero FORCE INDEX(idx_name) WHERE name >= 'c曹操' LOCK IN SHARE MODE;
这个语句的执行过程其实是先到二级索引中定位到满足
name >= 'c曹操'的第一条记录,也就是name值为c曹操的记录,然后就可以沿着这条记录的链表一路向后找,从二级索引idx_name的示意图中可以看出,所有的用户记录都满足name >= 'c曹操'的这个条件,所以所有的二级索引记录都会被加S型next-key锁,它们对应的聚簇索引记录也会被加S型正经记录锁,二级索引的最后一条Supremum记录也会被加S型next-key锁。不过需要注意一下加锁顺序,对一条二级索引记录加锁完后,会接着对它响应的聚簇索引记录加锁,完后才会对下一条二级索引记录进行加锁,以此类推~ 画个图表示一下就是这样: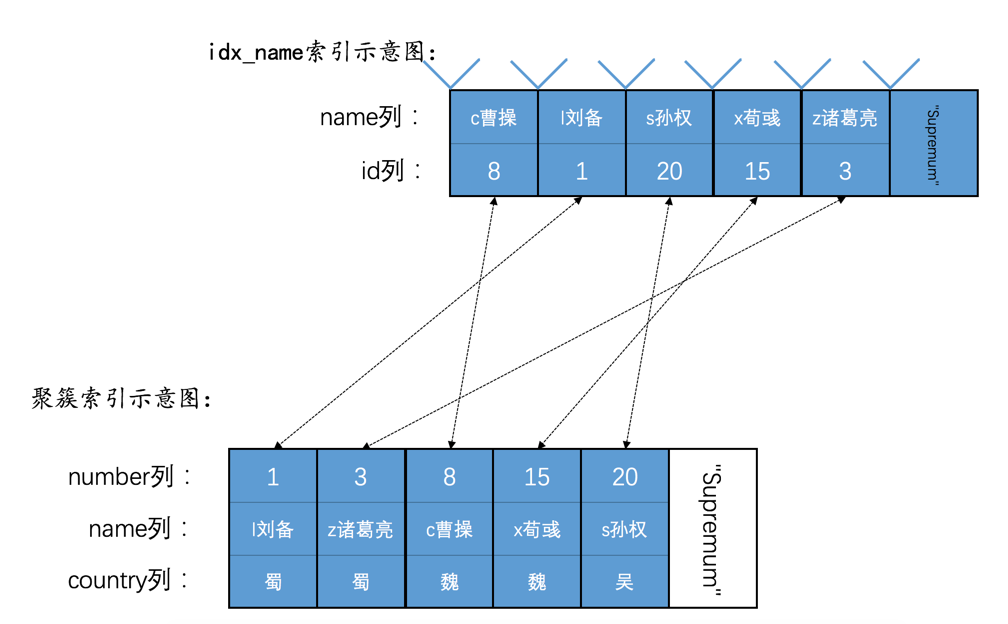
等等等等,不是
idx_name是唯一二级索引么?唯一二级索引本身就能保证其自身的值是唯一的,那为啥还要给name值为'c曹操'的记录加上S型next-key锁,而不是S型正经记录锁呢?其实我也不知道,按理说只需要给这条二级索引记录加S型正经记录锁就好了,我也没想明白设计InnoDB的大叔是怎么想的,有知道的小伙伴赶紧添加我微信:xiaohaizi4919联系我哈~再来看下边这个语句:
SELECT * FROM hero WHERE name <= 'c曹操' LOCK IN SHARE MODE;
这个语句先会为
name值为'c曹操'的二级索引记录加S型next-key锁以及它对应的聚簇索引记录加S型正经记录锁。然后还要给name值为'l刘备'的二级索引加S型next-key锁,server层判断前边在说为
number <= 8这个条件进行加锁时,会把number值为15的记录也加一个锁,之后server层判断不符合条件后再释放掉,现在换成二级索引就不用为下一条记录加锁了么?是的,这主要是因为我们开启了索引条件下推,对于二级索引记录来说,可以先在存储引擎层判断给定条件name <= 'c曹操'是否成立,如果不成立就不返回给server层了,从而避免了不必要的加锁。使用
SELECT ... FOR UPDATE语句时:和
SELECT ... FOR UPDATE语句类似,只不过加的是X型正经记录锁。使用
UPDATE ...来为记录加锁,比方说:UPDATE hero SET country = '汉' WHERE name >= 'c曹操';
这条
UPDATE语句并没有更新二级索引列,加锁方式和上边所说的SELECT ... FOR UPDATE语句一致。如果有其他二级索引列也被更新,那么也会为这些二级索引记录进行加锁,就不赘述了。不过还有一个有趣的情况,比方说:UPDATE FORCE INDEX(idx_name)hero SET name = 'c曹操' WHERE number <= 8;
我们前边说的
索引条件下推这个特性只适用于SELECT语句,也就是说UPDATE语句中无法使用,那么这个语句就会为name值为'c曹操'和'l刘备'的二级索引记录以及它们对应的聚簇索引进行加锁,然后server层判断name值为'l刘备'的记录不符合name <= 'c曹操'条件,再把对应的二级索引记录和聚簇索引记录上的锁释放掉。使用
DELETE ...来为记录加锁,比方说:DELETE FROM hero WHERE number >= 8;
和
DELETE FROM hero WHERE number <= 8;
这两个语句的加锁情况和更新带有二级索引列的
UPDATE语句一致,就不画图了。
INSERT语句
前边说INSERT语句一般情况下不加锁,不过如果即将插入的间隙已经被其他事务加了gap锁,那么本次INSERT操作会阻塞,并且当前事务会在该间隙上加一个插入意向锁。除此之外,在下边两种特殊情况下也会进行加锁操作:
遇到duplicate key
外键检查
其他的锁
系统锁和事务锁
死锁简介
有一点大家需要注意一下,我们平时所说的“DELETE表中的一条记录”其实意味着对聚簇索引和所有的二级索引中对应的记录做DELETE操作;“UPDATE表中的一条记录”其实意味着对聚簇索引和所有受影响的二级索引中对应的记录做DELETE操作(有时候UPDATE语句中不更新);
“DELETE或者UPDATE表中的一条记录”其实意味着对聚簇索引和所有的二级索引中对应的记录做DELETE或者UPDATE操作,“向表中INSERT一条记录”其实意味着向聚簇索引和所有的二级索引中都插入一条记录。以DELETE操作为例,在执行“删除表中的一条记录”操作时,需要先获取到对应的聚簇索引记录和对应的二级索引记录上的X锁,换句话说,平时所说的“删除表中的一条记录”其实要对好多条记录进行加锁。
MySQL如何查看事务加锁情况
标签: 公众号文章
小贴士:本篇文章算是回答一些同学的提问,以MySQL 5.7为例。
我们都知道MySQL的InnoDB存储引擎是支持事务功能的,不过在很多同学的潜意识中,只有把若干语句包含在BEGIN/START TRANSACTION、COMMIT中间,才算是开启一个事务,就像这样:
BEGIN;语句1;语句2;...语句n;COMMIT;
其实不是这样的,每个涉及到使用InnoDB作为存储引擎的表的语句,都会在事务中执行。我们稍后详细看一下。
自动提交与手动提交
设计MySQL的大叔提供了一个称之为autocommit的系统变量,如下所示:
mysql> SHOW VARIABLES LIKE 'autocommit';+---------------+-------+| Variable_name | Value |+---------------+-------+| autocommit | ON |+---------------+-------+1 row in set (0.15 sec)
该系统变量含义如下:
当
autocommit的值为ON时,意味着开启自动提交,则每个SQL语句将形成一个独立的事务,当该语句执行完成时,对应的事务也就提交了。有同学有疑问,如果在
autocommit的值为ON时,我写的一条SQL语句中既没有增加/修改/删除记录,也没有对记录加锁,比方说这样的一条利用MVCC进行读取的SELECT语句:mysql> SELECT * FROM hero;+--------+------------+---------+| number | name | country |+--------+------------+---------+| 1 | l刘备 | 蜀 || 3 | z诸葛亮 | 蜀 || 8 | c曹操 | 魏 || 15 | x荀彧 | 魏 || 20 | s孙权 | 吴 || 22 | g关羽 | 蜀 || 30 | d典韦 | 魏 |+--------+------------+---------+7 rows in set (0.02 sec)mysql>
那这条语句也相当与在事务中执行的么?是的,其实区别语句是否在事务中执行的依据其实是代码中是否调用了
trx_start_low这个函数,有感兴趣的同学可以去看看代码哈~当
autocommit的值为OFF时,意味着禁用自动提交,我们写的若干个增删改查语句都算作是一个事务中的语句,直到我们手动的使用COMMIT语句来提交这个事务。
如果我们当前会话的系统变量autocommit的值为ON,意味着开启了自动提交。此时如果我们想把若干个语句放到一个事务中执行,那就需要显式地写出BEGIN或者START TRANSACTION语句来禁用自动提交。
查看事务加锁的几种方法
有同学会使用information_schema数据库下的一些表来观察当前数据库中的一些事务和锁的情况,诸如:innodb_locks、innodb_lock_wait。但是千万要记住:在使用它们之前一定先得知道它们是干啥的,然后再去使用。不要在连这些表是干啥的情况下就去贸然使用,最后还能得出一个结论~。下边我们看看这几个表都是干嘛使的:
innodb_locks表:该表中会记录一些锁信息:- 如果一个事务想要获取某个锁但未获取到,该锁信息将被记录。
- 如果一个事务因为获取到了某个锁,但是这个锁阻塞了别的事务的话,该锁信息会被记录。
这里需要大家注意的是:只有当系统中发生了某个事务因为获取不到锁而阻塞的情况才会向该表中写入记录。如果未发生阻塞,比方说我们在
T1中执行:# T1mysql> BEGIN;Query OK, 0 rows affected (0.00 sec)mysql> SELECT * FROM hero WHERE number = 1 for update;+--------+---------+---------+| number | name | country |+--------+---------+---------+| 1 | l刘备 | 蜀 |+--------+---------+---------+1 row in set (0.01 sec)
很显然
T1已经获取到了hero表中number值为1的聚簇索引记录的X型正经记录锁(number列为主键),但是由于并未发生阻塞,该锁的信息并不会记录在innodb_locks表中:mysql> SELECT * FROM innodb_locks;Empty set, 1 warning (0.02 sec)
innodb_lock_wait:表明当前系统中因为等待哪些锁而让事务进入阻塞状态。比方说接着上边的例子,我们在
事务T2中接着执行:# T2mysql> BEGIN;Query OK, 0 rows affected (0.00 sec)mysql> SELECT * FROM hero WHERE number = 1 lock in share mode;# 进入阻塞状态
因为获取不到
hero表中number值为1的聚簇索引记录的S型正经记录锁,所以事务T2进入阻塞状态,那么在innodb_lock_wait表中会留下一条记录:mysql> select * from innodb_lock_wait;+-------------------+-------------------------+-----------------+------------------+| requesting_trx_id | requested_lock_id | blocking_trx_id | blocking_lock_id |+-------------------+-------------------------+-----------------+------------------+| 281479631936736 | 281479631936736:272:3:2 | 38938 | 38938:272:3:2 |+-------------------+-------------------------+-----------------+------------------+1 row in set, 1 warning (0.01 sec)
因为此时
T2发生了阻塞,在innodb_locks表中也可以体现出来:mysql> SELECT * FROM innodb_locks;+-------------------------+-----------------+-----------+-----------+--------------------+------------+------------+-----------+----------+-----------+| lock_id | lock_trx_id | lock_mode | lock_type | lock_table | lock_index | lock_space | lock_page | lock_rec | lock_data |+-------------------------+-----------------+-----------+-----------+--------------------+------------+------------+-----------+----------+-----------+| 281479631936736:272:3:2 | 281479631936736 | S | RECORD | `xiaohaizi`.`hero` | PRIMARY | 272 | 3 | 2 | 1 || 38938:272:3:2 | 38938 | X | RECORD | `xiaohaizi`.`hero` | PRIMARY | 272 | 3 | 2 | 1 |+-------------------------+-----------------+-----------+-----------+--------------------+------------+------------+-----------+----------+-----------+2 rows in set, 1 warning (0.02 sec)
不过我们看到,在查询innodb_locks和innodb_lock_wait表的时候都伴随着一个warning,我们看一下系统在警告神马:
mysql> SHOW WARNINGS\G*************************** 1. row ***************************Level: WarningCode: 1681Message: 'INFORMATION_SCHEMA.INNODB_LOCKS' is deprecated and will be removed in a future release.1 row in set (0.01 sec)
其实是因为innodb_locks和innodb_lock_wait在我目前使用的版本(MySQL 5.7.21)中被标记为过时的,并且提示在未来的版本中可能被移除,其实也就是不鼓励我们使用这两个表来获取相关的锁信息。
另外,我们还可以使用SHOW ENGINE INNODB STATUS这个命令来查看当前系统中每个事务都加了哪些锁:
mysql> SHOW ENGINE INNODB STATUS\G...此处省略很多信息------------TRANSACTIONS------------Trx id counter 38944Purge done for trx's n:o < 38452 undo n:o < 0 state: running but idleHistory list length 262Total number of lock structs in row lock hash table 2LIST OF TRANSACTIONS FOR EACH SESSION:---TRANSACTION 281479631937824, not started0 lock struct(s), heap size 1160, 0 row lock(s)---TRANSACTION 38938, ACTIVE 1875 sec2 lock struct(s), heap size 1160, 1 row lock(s)MySQL thread id 29, OS thread handle 123145576628224, query id 690 localhost 127.0.0.1 rootTrx read view will not see trx with id >= 38938, sees < 38938...此处省略很多信息
由于输出的内容太多,为方便起见,我们只保留了关于TRANSACTIONS的相关信息,这里列出了每个事务获取锁的情况。如果我们想看到更详细的加锁情况,可以开启innodb_status_output_locks:
mysql> SET GLOBAL innodb_status_output_locks = ON;Query OK, 0 rows affected (0.01 sec)
那每个锁的详细情况就被列出来了:
mysql> SHOW ENGINE INNODB STATUS\G...此处省略很多信息------------TRANSACTIONS------------Trx id counter 38945Purge done for trx's n:o < 38452 undo n:o < 0 state: running but idleHistory list length 262Total number of lock structs in row lock hash table 2LIST OF TRANSACTIONS FOR EACH SESSION:---TRANSACTION 281479631937824, not started0 lock struct(s), heap size 1160, 0 row lock(s)---TRANSACTION 38938, ACTIVE 2122 sec2 lock struct(s), heap size 1160, 1 row lock(s)MySQL thread id 29, OS thread handle 123145576628224, query id 690 localhost 127.0.0.1 rootTrx read view will not see trx with id >= 38938, sees < 38938TABLE LOCK table `xiaohaizi`.`hero` trx id 38938 lock mode IXRECORD LOCKS space id 272 page no 3 n bits 80 index PRIMARY of table `xiaohaizi`.`hero` trx id 38938 lock_mode X locks rec but not gapRecord lock, heap no 2 PHYSICAL RECORD: n_fields 5; compact format; info bits 00: len 4; hex 80000001; asc ;;1: len 6; hex 000000009624; asc $;;2: len 7; hex 80000001d00110; asc ;;3: len 7; hex 6ce58898e5a487; asc l ;;4: len 3; hex e89c80; asc ;;...此处省略很多信息
当然,我们现在并不准备唠叨输出内容中的每个字段都是啥意思,之后有时间再撰文描述吧~
MySQL介于普通读和锁定读的加锁方式—— semi-consistent read
标签: 公众号文章
事前准备
为了故事的顺利发展,我们先建一个表,并向表中插入一些记录,下边是SQL语句:
CREATE TABLE hero (number INT,name VARCHAR(100),country varchar(100),PRIMARY KEY (number),KEY idx_name (name)) Engine=InnoDB CHARSET=utf8;INSERT INTO hero VALUES(1, 'l刘备', '蜀'),(3, 'z诸葛亮', '蜀'),(8, 'c曹操', '魏'),(15, 'x荀彧', '魏'),(20, 's孙权', '吴');
现在hero表中的记录情况就如下所示:
mysql> SELECT * FROM hero;+--------+------------+---------+| number | name | country |+--------+------------+---------+| 1 | l刘备 | 蜀 || 3 | z诸葛亮 | 蜀 || 8 | c曹操 | 魏 || 15 | x荀彧 | 魏 || 20 | s孙权 | 吴 |+--------+------------+---------+5 rows in set (0.01 sec)
现象
在小册答疑群里有一位同学提了一个问题:说是在READ COMMITTED隔离级别下发生了一件百思不得其解的事儿。好的,首先构造环境,将当前会话默认的隔离级别设置成READ COMMITTED:
mysql> SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;Query OK, 0 rows affected (0.00 sec)
事务T1先执行:
# T1中,隔离级别为READ COMMITTEDmysql> BEGIN;Query OK, 0 rows affected (0.00 sec)mysql> SELECT * FROM hero WHERE country = '魏' FOR UPDATE;+--------+---------+---------+| number | name | country |+--------+---------+---------+| 8 | c曹操 | 魏 || 15 | x荀彧 | 魏 |+--------+---------+---------+2 rows in set (0.01 sec)
country列并不是索引列,所以本条语句执行时肯定是使用扫描聚簇索引的全表扫描方式来执行,EXPLAIN语句也证明了我们的想法:
mysql> EXPLAIN SELECT * FROM hero WHERE country = '魏' FOR UPDATE;+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+| 1 | SIMPLE | hero | NULL | ALL | NULL | NULL | NULL | NULL | 5 | 20.00 | Using where |+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+1 row in set, 1 warning (0.02 sec)
我们之前学过MySQL语句的加锁分析,知道在READ COMMITTED隔离级别下,如果采用全表扫描的方式执行查询语句时,InnoDB存储引擎将依次对每条记录加正经记录锁,在server层测试该记录是否符合WHERE条件,如果不符合则将加在该记录上的锁释放掉。本例中使用FOR UPDATE语句,肯定加的是X型正经记录锁。只有两条记录符合WHERE条件,所以最终其实只对这两条符合条件的记录加了X型正经记录锁(就是number列值为8和15的两条记录)。当然,我们可以使用SHOW ENGINE INNODB STATUS命令证明我们的分析:
mysql> SHOW ENGINE INNODB STATUS\G... 省略了很多内容------------TRANSACTIONS------------Trx id counter 39764Purge done for trx's n:o < 39763 undo n:o < 0 state: running but idleHistory list length 36Total number of lock structs in row lock hash table 1LIST OF TRANSACTIONS FOR EACH SESSION:---TRANSACTION 281479653009568, not started0 lock struct(s), heap size 1160, 0 row lock(s)---TRANSACTION 281479653012832, not started0 lock struct(s), heap size 1160, 0 row lock(s)---TRANSACTION 39763, ACTIVE 468 sec2 lock struct(s), heap size 1160, 2 row lock(s)MySQL thread id 19, OS thread handle 123145470611456, query id 586 localhost 127.0.0.1 rootTABLE LOCK table `xiaohaizi`.`hero` trx id 39763 lock mode IXRECORD LOCKS space id 287 page no 3 n bits 72 index PRIMARY of table `xiaohaizi`.`hero` trx id 39763 lock_mode X locks rec but not gapRecord lock, heap no 4 PHYSICAL RECORD: n_fields 5; compact format; info bits 00: len 4; hex 80000008; asc ;;1: len 6; hex 000000009b4a; asc J;;2: len 7; hex 80000001d3012a; asc *;;3: len 7; hex 63e69bb9e6938d; asc c ;;4: len 3; hex e9ad8f; asc ;;Record lock, heap no 5 PHYSICAL RECORD: n_fields 5; compact format; info bits 00: len 4; hex 8000000f; asc ;;1: len 6; hex 000000009b4a; asc J;;2: len 7; hex 80000001d30137; asc 7;;3: len 7; hex 78e88d80e5bda7; asc x ;;4: len 3; hex e9ad8f; asc ;;... 省略了很多内容
其中id为39763的事务就是指T1,可以看出它为heap no值为4和5的两条记录加了X型正经记录锁(lock_mode X locks rec but not gap)。
然后再开启一个隔离级别也为READ COMMITTED的事务T2,在其中执行:
# T2中,隔离级别为READ COMMITTEDmysql> BEGIN;Query OK, 0 rows affected (0.00 sec)mysql> SELECT * FROM hero WHERE country = '吴' FOR UPDATE;(进入阻塞状态)
很显然,这条语句也会采用全表扫描的方式来执行,会依次去获取每一条聚簇索引记录的锁。不过因为number值为8的记录已经被T1加了X型正经记录锁,T2想得却得不到,只能眼巴巴的进行阻塞状态,此时的SHOW ENGINE INNODB STATUS也能证明我们的猜想(只截取了一部分):
---TRANSACTION 39764, ACTIVE 34 sec fetching rowsmysql tables in use 1, locked 1LOCK WAIT 3 lock struct(s), heap size 1160, 1 row lock(s)MySQL thread id 20, OS thread handle 123145471168512, query id 590 localhost 127.0.0.1 root Sending dataSELECT * FROM hero WHERE country = '吴' FOR UPDATE------- TRX HAS BEEN WAITING 34 SEC FOR THIS LOCK TO BE GRANTED:RECORD LOCKS space id 287 page no 3 n bits 72 index PRIMARY of table `xiaohaizi`.`hero` trx id 39764 lock_mode X locks rec but not gap waitingRecord lock, heap no 4 PHYSICAL RECORD: n_fields 5; compact format; info bits 00: len 4; hex 80000008; asc ;;1: len 6; hex 000000009b4a; asc J;;2: len 7; hex 80000001d3012a; asc *;;3: len 7; hex 63e69bb9e6938d; asc c ;;4: len 3; hex e9ad8f; asc ;;
可以看到T2正在等待获取heap no为4的记录上的X型正经记录锁(lock_mode X locks rec but not gap waiting)。
以上是很正常的阻塞逻辑,我们都可以分析出来,不过如果在T2中执行下边的UPDATE语句:
# T2中,隔离级别为READ COMMITTEDmysql> BEGIN;Query OK, 0 rows affected (0.00 sec)mysql> UPDATE hero SET name = 'xxx' WHERE country = '吴';Query OK, 1 row affected (0.02 sec)Rows matched: 1 Changed: 1 Warnings: 0
WTF? 竟然没有阻塞,就这么随意地执行成功了?同样的WHERE条件,同样的执行计划,怎么SELECT ... FOR UPDATE和UPDATE语句的加锁情况不一样?
原因
哈哈,是的,的确不一样。其实MySQL支持3种类型的读语句:
普通读(也称一致性读,英文名:Consistent Read)。
这个就是指普通的SELECT语句,在末尾不加
FOR UPDATE或者LOCK IN SHARE MODE的SELECT语句。普通读的执行方式是生成ReadView直接利用MVCC机制来进行读取,并不会对记录进行加锁。小贴士:对于SERIALIZABLE隔离级别来说,如果autocommit系统变量被设置为OFF,那普通读的语句会转变为锁定读,和在普通的SELECT语句后边加LOCK IN SHARE MODE达成的效果一样。
锁定读(英文名:Locking Read)。
这个就是事务在读取记录之前,需要先获取该记录对应的锁。当然,获取什么类型的锁取决于当前事务的隔离级别、语句的执行计划、查询条件等因素,具体可参见:
半一致性读(英文名:Semi-Consistent Read)。
这是一种夹在普通读和锁定读之间的一种读取方式。它只在
READ COMMITTED隔离级别下(或者在开启了innodb_locks_unsafe_for_binlog系统变量的情况下)使用UPDATE语句时才会使用。具体的含义就是当UPDATE语句读取已经被其他事务加了锁的记录时,InnoDB会将该记录的最新提交的版本读出来,然后判断该版本是否与UPDATE语句中的WHERE条件相匹配,如果不匹配则不对该记录加锁,从而跳到下一条记录;如果匹配则再次读取该记录并对其进行加锁。这样子处理只是为了让UPDATE语句尽量少被别的语句阻塞。小贴士:半一致性读只适用于对聚簇索引记录加锁的情况,并不适用于对二级索引记录加锁的情况。
很显然,我们上边所唠叨的例子中是因为事务T2执行UPDATE语句时使用了半一致性读,判断number列值为8和15这两条记录的最新提交版本的country列值均不为UPDATE语句中WHERE条件中的'吴',所以直接就跳过它们,不对它们加锁了。
本知识点容易被忽略,各位同学在工作过程中分析的时候别忘记考虑一下Semi-Consistent Read喔,码字不易,有帮助帮着转发喔,么么哒~
死锁分析
标签: 公众号文章
如果我们的业务处在一个非常初级的阶段,并发程度比较低,那么我们可以几年都遇不到一次死锁问题的发生,反之,我们业务的并发程度非常高,那么时不时爆出的死锁问题肯定让我们非常挠头。不过在死锁问题发生时,很多没有经验的同学的第一反应就是成为一直鸵鸟:这玩意儿很高深,我也看不懂,听天由命吧,又不是一直发生。其实如果大家认真研读了我们之前写了3篇关于MySQL中语句加锁分析的文章,加上本篇关于死锁日志的分析,那么解决死锁问题应该也不是那么摸不着头脑的事情了。
准备工作
为了故事的顺利发展,我们需要建一个表:
CREATE TABLE hero (id INT,name VARCHAR(100),country varchar(100),PRIMARY KEY (id),KEY idx_name (name)) Engine=InnoDB CHARSET=utf8;
我们为hero表的id列创建了聚簇索引,为name列创建了一个二级索引。这个hero表主要是为了存储三国时的一些英雄,我们向表中插入一些记录:
INSERT INTO hero VALUES(1, 'l刘备', '蜀'),(3, 'z诸葛亮', '蜀'),(8, 'c曹操', '魏'),(15, 'x荀彧', '魏'),(20, 's孙权', '吴');
现在表中的数据就是这样的:
mysql> SELECT * FROM hero;+----+------------+---------+| id | name | country |+----+------------+---------+| 1 | l刘备 | 蜀 || 3 | z诸葛亮 | 蜀 || 8 | c曹操 | 魏 || 15 | x荀彧 | 魏 || 20 | s孙权 | 吴 |+----+------------+---------+5 rows in set (0.00 sec)
准备工作就做完了。
创建死锁情景
我们先创建一个发生死锁的情景,在Session A和Session B中分别执行两个事务,具体情况如下:
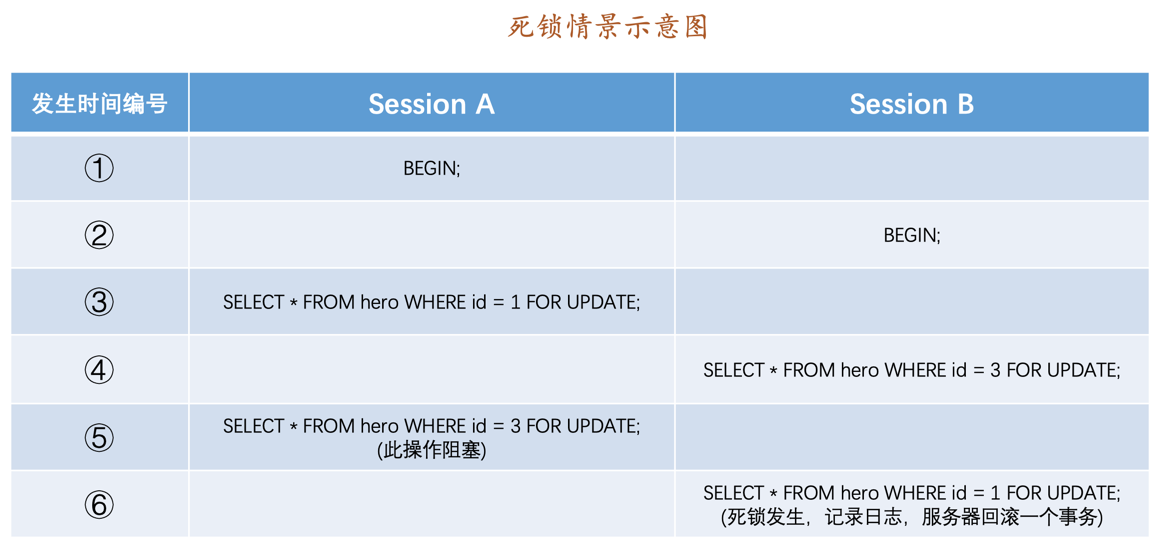
我们分析一下:
从第③步中可以看出,
Session A中的事务先对hero表聚簇索引的id值为1的记录加了一个X型正经记录锁。从第④步中可以看出,
Session B中的事务对hero表聚簇索引的id值为3的记录加了一个X型正经记录锁。从第⑤步中可以看出,
Session A中的事务接着想对hero表聚簇索引的id值为3的记录也加了一个X型正经记录锁,但是与第④步中Session B中的事务加的锁冲突,所以Session A进入阻塞状态,等待获取锁。从第⑥步中可以看出,
Session B中的事务想对hero表聚簇索引的id值为1的记录加了一个X型正经记录锁,但是与第③步中Session A中的事务加的锁冲突,而此时Session A和Session B中的事务循环等待对方持有的锁,死锁发生,被MySQL服务器的死锁检测机制检测到了,所以选择了一个事务进行回滚,并向客户端发送一条消息:ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction
以上是我们从语句加了什么锁的角度出发来进行死锁情况分析的,但是实际应用中我们可能压根儿不知道到底是哪几条语句产生了死锁,我们需要根据MySQL在死锁发生时产生的死锁日志来逆向定位一下到底是什么语句产生了死锁,从而再优化我们的业务。
查看死锁日志
设计InnoDB的大叔给我们提供了SHOW ENGINE INNODB STATUS命令来查看关于InnoDB存储引擎的一些状态信息,其中就包括了系统最近一次发生死锁时的加锁情况。在上边例子中的死锁发生时,我们运行一下这个命令:
mysql> SHOW ENGINE INNODB STATUS\G...省略了好多其他信息------------------------LATEST DETECTED DEADLOCK------------------------2019-06-20 13:39:19 0x70000697e000*** (1) TRANSACTION:TRANSACTION 30477, ACTIVE 10 sec starting index readmysql tables in use 1, locked 1LOCK WAIT 3 lock struct(s), heap size 1160, 2 row lock(s)MySQL thread id 2, OS thread handle 123145412648960, query id 46 localhost 127.0.0.1 root statisticsselect * from hero where id = 3 for update*** (1) WAITING FOR THIS LOCK TO BE GRANTED:RECORD LOCKS space id 171 page no 3 n bits 72 index PRIMARY of table `dahaizi`.`hero` trx id 30477 lock_mode X locks rec but not gap waitingRecord lock, heap no 3 PHYSICAL RECORD: n_fields 5; compact format; info bits 00: len 4; hex 80000003; asc ;;1: len 6; hex 000000007517; asc u ;;2: len 7; hex 80000001d0011d; asc ;;3: len 10; hex 7ae8afb8e8919be4baae; asc z ;;4: len 3; hex e89c80; asc ;;*** (2) TRANSACTION:TRANSACTION 30478, ACTIVE 8 sec starting index readmysql tables in use 1, locked 13 lock struct(s), heap size 1160, 2 row lock(s)MySQL thread id 3, OS thread handle 123145412927488, query id 47 localhost 127.0.0.1 root statisticsselect * from hero where id = 1 for update*** (2) HOLDS THE LOCK(S):RECORD LOCKS space id 171 page no 3 n bits 72 index PRIMARY of table `dahaizi`.`hero` trx id 30478 lock_mode X locks rec but not gapRecord lock, heap no 3 PHYSICAL RECORD: n_fields 5; compact format; info bits 00: len 4; hex 80000003; asc ;;1: len 6; hex 000000007517; asc u ;;2: len 7; hex 80000001d0011d; asc ;;3: len 10; hex 7ae8afb8e8919be4baae; asc z ;;4: len 3; hex e89c80; asc ;;*** (2) WAITING FOR THIS LOCK TO BE GRANTED:RECORD LOCKS space id 171 page no 3 n bits 72 index PRIMARY of table `dahaizi`.`hero` trx id 30478 lock_mode X locks rec but not gap waitingRecord lock, heap no 2 PHYSICAL RECORD: n_fields 5; compact format; info bits 00: len 4; hex 80000001; asc ;;1: len 6; hex 000000007517; asc u ;;2: len 7; hex 80000001d00110; asc ;;3: len 7; hex 6ce58898e5a487; asc l ;;4: len 3; hex e89c80; asc ;;*** WE ROLL BACK TRANSACTION (2)------------...省略了好多其他信息
我们只关心最近发生的死锁信息,所以就把以LATEST DETECTED DEADLOCK这一部分给单独提出来分析一下。下边我们就逐行看一下这个输出的死锁日志都是什么意思:
首先看第一句:
2019-06-20 13:39:19 0x70000697e000
这句话的意思就是死锁发生的时间是:2019-06-20 13:39:19,后边的一串十六进制
0x70000697e000表示的操作系统为当前session分配的线程的线程id。然后是关于死锁发生时第一个事务的有关信息:
*** (1) TRANSACTION:# 为事务分配的id为30477,事务处于ACTIVE状态已经10秒了,事务现在正在做的操作就是:“starting index read”TRANSACTION 30477, ACTIVE 10 sec starting index read# 此事务使用了1个表,为1个表上了锁(此处不是说为该表加了表锁,只要不是进行一致性读的表,都需要加锁,具体怎么加锁请看加锁语句分析或者小册章节)mysql tables in use 1, locked 1# 此事务处于LOCK WAIT状态,拥有3个锁结构(2个行锁结构,1个表级别X型意向锁结构,锁结构在小册中重点介绍过),heap size是为了存储锁结构而申请的内存大小(我们可以忽略),其中有2个行锁的结构LOCK WAIT 3 lock struct(s), heap size 1160, 2 row lock(s)# 本事务所在线程的id是2(MySQL自己命名的线程id),该线程在操作系统级别的id就是那一长串数字,当前查询的id为46(MySQL内部使用,可以忽略),还有用户名主机信息MySQL thread id 2, OS thread handle 123145412648960, query id 46 localhost 127.0.0.1 root statistics# 本事务发生阻塞的语句select * from hero where id = 3 for update# 本事务当前在等待获取的锁:*** (1) WAITING FOR THIS LOCK TO BE GRANTED:# 等待获取的表空间ID为151,页号为3,也就是表hero的PRIMAY索引中的某条记录的锁(n_bits是为了存储本页面的锁信息而分配的一串内存空间,小册中有详细介绍),该锁的类型是X型正经记录锁(rec but not gap)RECORD LOCKS space id 171 page no 3 n bits 72 index PRIMARY of table `dahaizi`.`hero` trx id 30477 lock_mode X locks rec but not gap waiting# 该记录在页面中的heap_no为2,具体的记录信息如下:Record lock, heap no 3 PHYSICAL RECORD: n_fields 5; compact format; info bits 0# 这是主键值0: len 4; hex 80000003; asc ;;# 这是trx_id隐藏列1: len 6; hex 000000007517; asc u ;;# 这是roll_pointer隐藏列2: len 7; hex 80000001d0011d; asc ;;# 这是name列3: len 10; hex 7ae8afb8e8919be4baae; asc z ;;# 这是country列4: len 3; hex e89c80; asc ;;
从这个信息中可以看出,
Session A中的事务为2条记录生成了锁结构,但是其中有一条记录上的X型正经记录锁(rec but not gap)并没有获取到,没有获取到锁的这条记录的位置是:表空间ID为151,页号为3,heap_no为2。当然,设计InnoDB的大叔还贴心的给出了这条记录的详细情况,它的主键值为80000003,这其实是InnoDB内部存储使用的格式,其实就代表数字3,也就是该事务在等待获取hero表聚簇索引主键值为3的那条记录的X型正经记录锁。然后是关于死锁发生时第二个事务的有关信息:
其中的大部分信息我们都已经介绍过了,我们就挑重要的说:
*** (2) TRANSACTION:TRANSACTION 30478, ACTIVE 8 sec starting index readmysql tables in use 1, locked 13 lock struct(s), heap size 1160, 2 row lock(s)MySQL thread id 3, OS thread handle 123145412927488, query id 47 localhost 127.0.0.1 root statisticsselect * from hero where id = 1 for update# 表示该事务获取到的锁信息*** (2) HOLDS THE LOCK(S):RECORD LOCKS space id 171 page no 3 n bits 72 index PRIMARY of table `dahaizi`.`hero` trx id 30478 lock_mode X locks rec but not gapRecord lock, heap no 3 PHYSICAL RECORD: n_fields 5; compact format; info bits 0# 主键值为30: len 4; hex 80000003; asc ;;1: len 6; hex 000000007517; asc u ;;2: len 7; hex 80000001d0011d; asc ;;3: len 10; hex 7ae8afb8e8919be4baae; asc z ;;4: len 3; hex e89c80; asc ;;# 表示该事务等待获取的锁信息*** (2) WAITING FOR THIS LOCK TO BE GRANTED:RECORD LOCKS space id 171 page no 3 n bits 72 index PRIMARY of table `dahaizi`.`hero` trx id 30478 lock_mode X locks rec but not gap waitingRecord lock, heap no 2 PHYSICAL RECORD: n_fields 5; compact format; info bits 0# 主键值为10: len 4; hex 80000001; asc ;;1: len 6; hex 000000007517; asc u ;;2: len 7; hex 80000001d00110; asc ;;3: len 7; hex 6ce58898e5a487; asc l ;;4: len 3; hex e89c80; asc ;;
从上边的输出可以看出来,
Session B中的事务获取了hero表聚簇索引主键值为3的记录的X型正经记录锁,等待获取hero表聚簇索引主键值为1的记录的X型正经记录锁(隐含的意思就是这个hero表聚簇索引主键值为1的记录的X型正经记录锁已经被SESSION A中的事务获取到了)。看最后一部分:
*** WE ROLL BACK TRANSACTION (2)
最终InnoDB存储引擎决定回滚第2个食物,也就是
Session B中的那个事务。
思索分析的思路
查看死锁日志时,首先看一下发生死锁的事务等待获取锁的语句都是啥。
本例中,发现
SESSION A发生阻塞的语句是:select * from hero where id = 3 for update
SESSION B发生阻塞的语句是:select * from hero where id = 1 for update
然后切记:到自己的业务代码中找出这两条语句所在事务的其他语句。
找到发生死锁的事务中所有的语句之后,对照着事务获取到的锁和正在等待的锁的信息来分析死锁发生过程。
从死锁日志中可以看出来,
SESSION A获取了hero表聚簇索引id值为1的记录的X型正经记录锁(这其实是从SESSION B正在等待的锁中获取的),查看SESSION A中的语句,发现是下边这个语句造成的(对照着语句加锁分析那三篇文章):select * from hero where id = 1 for update;
还有
SESSION B获取了hero表聚簇索引id值为3的记录的X型正经记录锁,查看SESSION B中的语句,发现是下边这个语句造成的(对照着语句加锁分析那三篇文章):select * from hero where id = 3 for update;
然后看
SESSION A正在等待hero表聚簇索引id值为3的记录的X型正经记录锁,这个是由于下边这个语句造成的:select * from hero where id = 3 for update;
然后看
SESSION B正在等待hero表聚簇索引id值为1的记录的X型正经记录锁,这个是由于下边这个语句造成的:select * from hero where id = 1 for update;
然后整个死锁形成过程就根据死锁日志给还原出来了。
两条一样的INSERT语句竟然引发了死锁?
标签: 公众号文章
两条一样的INSERT语句竟然引发了死锁,这究竟是人性的扭曲,还是道德的沦丧,让我们不禁感叹一句:卧槽!这也能死锁,然后眼中含着悲催的泪水无奈的改起了业务代码。
好的,在深入分析为啥两条一样的INSERT语句也会产生死锁之前,我们先介绍一些基础知识。
准备一下环境
为了故事的顺利发展,我们新建一个用了无数次的hero表:
CREATE TABLE hero (number INT AUTO_INCREMENT,name VARCHAR(100),country varchar(100),PRIMARY KEY (number),UNIQUE KEY uk_name (name)) Engine=InnoDB CHARSET=utf8;
然后向这个表里插入几条记录:
INSERT INTO hero VALUES(1, 'l刘备', '蜀'),(3, 'z诸葛亮', '蜀'),(8, 'c曹操', '魏'),(15, 'x荀彧', '魏'),(20, 's孙权', '吴');
现在hero表就有了两个索引(一个唯一二级索引,一个聚簇索引),示意图如下:
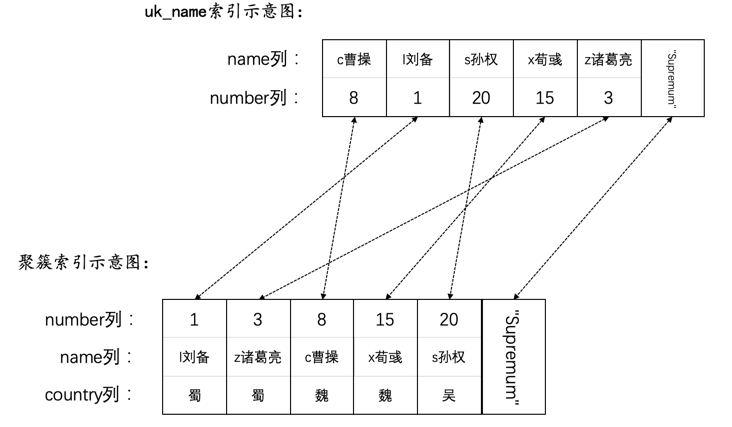
INSERT语句如何加锁
读过《MySQL是怎样运行的:从根儿上理解MySQL》的小伙伴肯定知道,INSERT语句在正常执行时是不会生成锁结构的,它是靠聚簇索引记录自带的trx_id隐藏列来作为隐式锁来保护记录的。
但是在一些特殊场景下,INSERT语句还是会生成锁结构的,我们列举一下:
1. 待插入记录的下一条记录上已经被其他事务加了gap锁时
每插入一条新记录,都需要看一下待插入记录的下一条记录上是否已经被加了gap锁,如果已加gap锁,那INSERT语句应该被阻塞,并生成一个插入意向锁。
比方说对于hero表来说,事务T1运行在REPEATABLE READ(后续简称为RR,后续也会把READ COMMITTED简称为RC)隔离级别中,执行了下边的语句:
# 事务T1mysql> BEGIN;Query OK, 0 rows affected (0.00 sec)mysql> SELECT * FROM hero WHERE number < 8 FOR UPDATE;+--------+------------+---------+| number | name | country |+--------+------------+---------+| 1 | l刘备 | 蜀 || 3 | z诸葛亮 | 蜀 |+--------+------------+---------+2 rows in set (0.02 sec)
这条语句会对主键值为1、3、8的这3条记录都添加X型next-key锁,不信的话我们使用SHOW ENGINE INNODB STATUS语句看一下加锁情况,图中箭头指向的记录就是number值为8的记录:
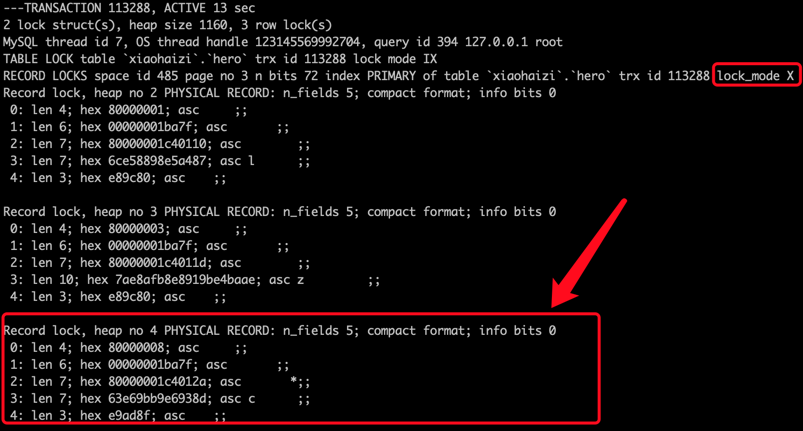
小贴士:
至于SELECT、DELETE、UPDATE语句如何加锁,我们已经在之前的文章中分析过了,这里就不再赘述了。
此时事务T2想插入一条主键值为4的聚簇索引记录,那么T2在插入记录前,首先要定位一下主键值为4的聚簇索引记录在页面中的位置,发现主键值为4的下一条记录的主键值是8,而主键值是8的聚簇索引记录已经被添加了gap锁(next-key锁包含了正经记录锁和gap锁),那么事务T2就需要进入阻塞状态,并生成一个类型为插入意向锁的锁结构。
我们在事务T2中执行一下INSERT语句验证一下:
mysql> BEGIN;Query OK, 0 rows affected (0.00 sec)mysql> INSERT INTO hero VALUES(4, 'g关羽', '蜀');
此时T2进入阻塞状态,我们再使用SHOW ENGINE INNODB STATUS看一下加锁情况:

可见T2对主键值为8的聚簇索引记录加了一个插入意向锁(就是箭头处指向的lock_mode X locks gap before rec insert intention),并且处在waiting状态。
好了,验证过之后,我们再来看看代码里是如何实现的:
lock_rec_insert_check_and_lock函数用于看一下别的事务是否阻止本次INSERT插入,如果是,那么本事务就给被别的事务添加了gap锁的记录生成一个插入意向锁,具体过程如下:
小贴士:
lock_rec_other_has_conflicting函数用于检测本次要获取的锁和记录上已有的锁是否有冲突,有兴趣的同学可以看一下。
2. 遇到重复键时
如果在插入新记录时,发现页面中已有的记录的主键或者唯一二级索引列与待插入记录的主键或者唯一二级索引列值相同(不过可以有多条记录的唯一二级索引列的值同时为NULL,这里不考虑这种情况了),此时插入新记录的事务会获取页面中已存在的键值相同的记录的锁。
如果是主键值重复,那么:
- 当隔离级别不大于RC时,插入新记录的事务会给已存在的主键值重复的聚簇索引记录添加S型正经记录锁。
- 当隔离级别不小于RR时,插入新记录的事务会给已存在的主键值重复的聚簇索引记录添加S型next-key锁。
如果是唯一二级索引列重复,那不论是哪个隔离级别,插入新记录的事务都会给已存在的二级索引列值重复的二级索引记录添加S型next-key锁,再强调一遍,加的是next-key锁!加的是next-key锁!加的是next-key锁!这是rc隔离级别中为数不多的给记录添加gap锁的场景。
小贴士:
本来设计InnoDB的大叔并不想在RC隔离级别引入gap锁,但是由于某些原因,如果不添加gap锁的话,会让唯一二级索引中出现多条唯一二级索引列值相同的记录,这就违背了UNIQUE约束。所以后来设计InnoDB的大叔就很不情愿的在RC隔离级别也引入了gap锁。
我们也来做一个实验,现在假设上边的T1和T2都回滚了,现在将隔离级别调至RC,重新开启事务进行测试。
mysql> SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;Query OK, 0 rows affected (0.01 sec)# 事务T1mysql> BEGIN;Query OK, 0 rows affected (0.00 sec)mysql> INSERT INTO hero VALUES(30, 'x荀彧', '魏');ERROR 1062 (23000): Duplicate entry 'x荀彧' for key 'uk_name'
然后执行SHOW ENGINE INNODB STATUS语句看一下T1加了什么锁:

可以看到即使现在T1的隔离级别为RC,T1仍然给name列值为'x荀彧'的二级索引记录添加了S型next-key锁(图中红框中的lock mode S)。
如果我们的INSERT语句还带有ON DUPLICATE KEY... 这样的子句,如果遇到主键值或者唯一二级索引列值重复的情况,会对B+树中已存在的相同键值的记录加X型锁,而不是S型锁(不过具体锁的具体类型是和前面描述一样的)。
好了,又到了看代码求证时间了,我们看一下吧:

row_ins_scan_sec_index_for_duplicate是检测唯一二级索引列值是否重复的函数,具体加锁的代码如下所示:
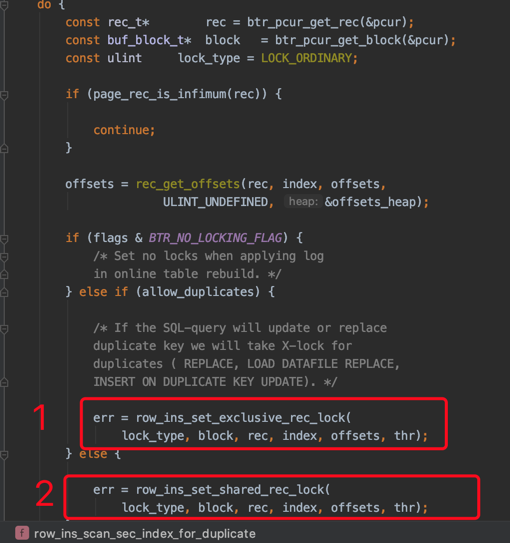
如上图所示,在遇到唯一二级索引列重复的情况时:
- 1号红框表示对带有
ON DUPLICATE ...子句时的处理方案,具体就是添加X型锁。 - 2号红框表示对正常INSERT语句的处理方案,具体就是添加S型锁。
不过不论是那种情况,添加的lock_typed的值都是LOCK_ORDINARY,表示next-key锁。
在主键重复时INSERT语句的加锁代码我们就不列举了。
3. 外键检查时
当我们向子表中插入记录时,我们分两种情况讨论:
当子表中的外键值可以在父表中找到时,那么无论当前事务是什么隔离级别,只需要给父表中对应的记录添加一个
S型正经记录锁就好了。当子表中的外键值在父表中找不到时:那么如果当前隔离级别不大于RC时,不对父表记录加锁;当隔离级别不小于RR时,对父表中该外键值所在位置的下一条记录添加gap锁。
由于外键不太常用,例子和代码就都不举例了,有兴趣的小伙伴可以打开《MySQL是怎样运行的:从根儿上理解MySQL》查看例子。
死锁要出场了
好了,基础知识预习完了,该死锁出场了。
看下边这个平平无奇的INSERT语句:
INSERT INTO hero(name, country) VALUES('g关羽', '蜀'), ('d邓艾', '魏');
这个语句用来插入两条记录,不论是在RC,还是RR隔离级别,如果两个事务并发执行它们是有一定几率触发死锁的。为了稳定复现这个死锁,我们把上边一条语句拆分成两条语句:
INSERT INTO hero(name, country) VALUES('g关羽', '蜀');INSERT INTO hero(name, country) VALUES('d邓艾', '魏');
拆分前和拆分后起到的作用是相同的,只不过拆分后我们可以人为的控制插入记录的时机。如果T1和T2的执行顺序是这样的:

也就是:
- T1先插入name值为
g关羽的记录,可以插入成功,此时对应的唯一二级索引记录被隐式锁保护,我们执行SHOW ENGINE INNODB STATUS语句,发现啥一个行锁(row lock)都没有(因为SHOW ENGINE INNODB STATUS不显示隐式锁):

- 接着T2也插入name值为
g关羽的记录。由于T1已经插入name值为g关羽的记录,所以T2在插入二级索引记录时会遇到重复的唯一二级索引列值,此时T2想获取一个S型next-key锁,但是T1并未提交,T1插入的name值为g关羽的记录上的隐式锁相当于一个X型正经记录锁(RC隔离级别),所以T2向获取S型next-key锁时会遇到锁冲突,T2进入阻塞状态,并且将T1的隐式锁转换为显式锁(就是帮助T1生成一个正经记录锁的锁结构)。这时我们再执行SHOW ENGINE INNODB STATUS语句:
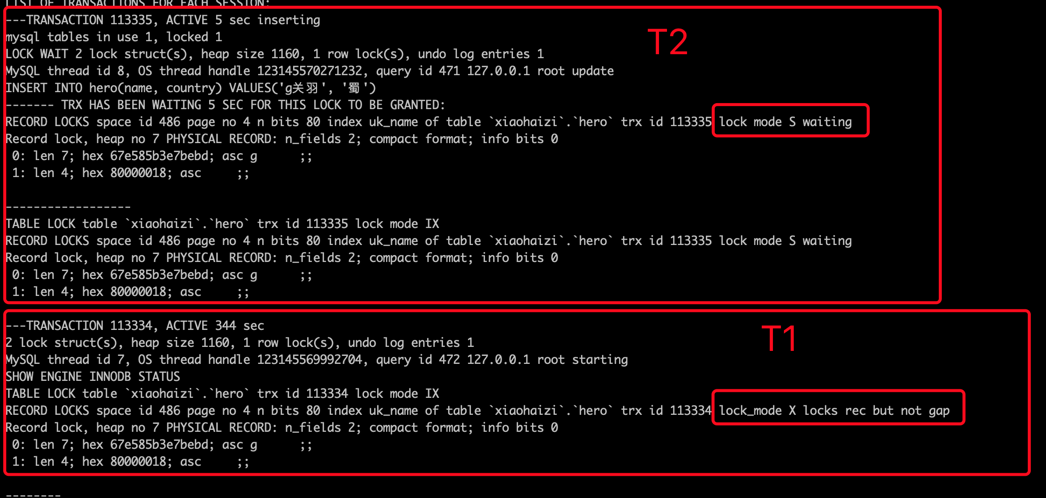
可见,T1持有的name值为g关羽的隐式锁已经被转换为显式锁(X型正经记录锁,lock_mode X locks rec but not gap);T2正在等待获取一个S型next-key锁(lock mode S waiting)。
- 接着T1再插入一条name值为
d邓艾的记录。在插入一条记录时,会在页面中先定位到这条记录的位置。在插入name值为d邓艾的二级索引记录时,发现现在页面中的记录分布情况如下所示:
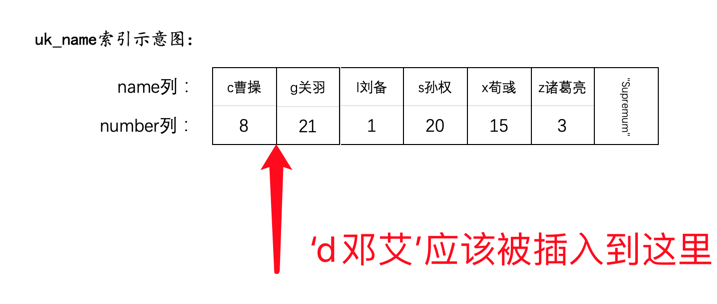
很显然,name值为'd邓艾'的二级索引记录所在位置的下一条二级索引记录的name值应该是'g关羽'(按照汉语拼音排序)。那么在T1插入name值为d邓艾的二级索引记录时,就需要看一下name值为'g关羽'的二级索引记录上有没有被别的事务加gap锁。
有同学想说:目前只有T2想在name值为'g关羽'的二级索引记录上添加S型next-key锁(next-key锁包含gap锁),但是T2并没有获取到锁呀,目前正在等待状态。那么T1不是能顺利插入name值为'g关羽'的二级索引记录么?
我们看一下执行结果:
# 事务T2mysql> INSERT INTO hero(name, country) VALUES('g关羽', '蜀');ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction
很显然,触发了一个死锁,T2被InnoDB回滚了。
这是为啥呢?T2明明没有获取到name值为'g关羽'的二级索引记录上的S型next-key锁,为啥T1还不能插入入name值为d邓艾的二级索引记录呢?
这我们还得回到代码上来,看一下插入新记录时是如何判断锁是否冲突的:
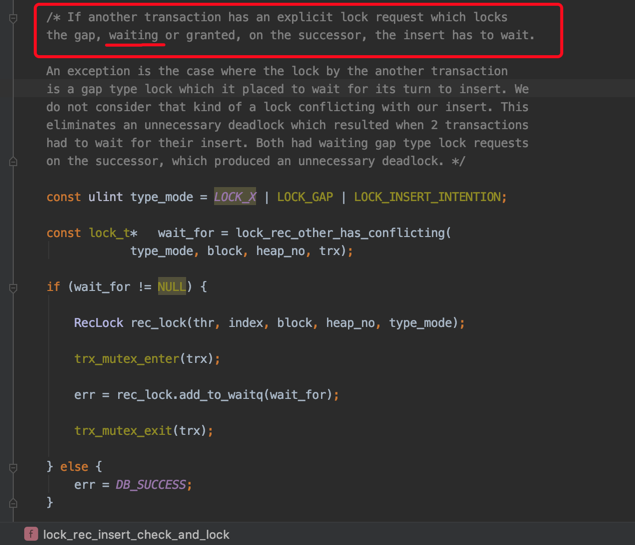
看一下画红框的注释,意思是:只要别的事务生成了一个显式的gap锁的锁结构,不论那个事务已经获取到了该锁(granted),还是正在等待获取(waiting),当前事务的INSERT操作都应该被阻塞。
回到我们的例子中来,就是T2已经在name值为'g关羽'的二级索引记录上生成了一个S型next-key锁的锁结构,虽然T2正在阻塞(尚未获取锁),但是T1仍然不能插入name值为d邓艾的二级索引记录。
这样也就解释了死锁产生的原因:
- T1在等待T2释放name值为
'g关羽'的二级索引记录上的gap锁。 - T2在等待T1释放name值为
'g关羽'的二级索引记录上的X型正经记录锁。
两个事务相互等待对方释放锁,这样死锁也就产生了。
怎么解决这个死锁问题?
两个方案:
- 方案一:一个事务中只插入一条记录。
- 方案二:先插入name值为
'd邓艾'的记录,再插入name值为'g关羽'的记录
为啥这两个方案可行?屏幕前的大脑瓜是不是也该转一下分析一波呗~
binlog那些事儿(一)
标签: 公众号文章
上一篇文章中有同学留言说想让小孩子写写MySQL的两阶段提交。
动手写的时候想到:是不是很多同学连XA事务是什么也不清楚,甚至很多同学连binlog是什么也不清楚~
好吧,这篇文章先来唠叨一下MySQL中的binlog到底是什么。
binlog的作用
binlog是binary log的缩写,即二进制日志。binlog中记载了数据库发生的变化,比方说新建了一个数据库或者表、表结构发生改变、表中的数据发生了变化时都会记录相应的binlog日志。
binlog主要用在下边两个方面:
- 用途一: 用于复制。
现在人们张口闭口就是亿级并发,虽然是夸张,但单台物理机器所能同时处理的请求是有限的却是一个事实。为了提高并发处理请求的能力,一般将MySQL服务部署在多台物理机器中,这些服务器中维护相同的数据副本。
其中一个典型的部署方案就是一主多从,即一台主服务器(Master)和多台从服务器(Slave)。对于改变数据库状态的请求(DDL、DML等),就将它们发送给主服务器,对于单纯的查询(如SELECT语句)请求,就将它们发送给从服务器。为了让各个从服务器中存储的数据和主服务器中存储的数据一致,每当我们改变了主服务器中的数据后,就需要将改变的信息同步给各个从服务器。binlog日志中正好记录了数据库发生的各种改变的信息,从服务器读取主服务器产生的binlog日志,然后执行这些binlog日志中所记录的数据库变化语句,从而达到主从服务器数据一致的效果。
用途二: 用于恢复。
工作中我们可能有意无意的就将数据库里的数据给“毁”了,比方说写DELETE语句不加WHERE子句,那一整个表的数据都就没了!为了数据的安全性,我们需要定时备份数据库(mysqldump命令),不过这种全量备份我们不可能每秒都做一遍,而是每天或者每个月做一次全量备份。那如果在两次全量备份中间手贱写了不加WHERE条件的DELETE语句该怎么办呢?只能将数据库恢复到前一次全量备份时的样子吗?还好我们有
binlog日志,我们可以从上一次全量备份开始,执行自改次备份后产生的binlog日志,直到我们写DELETE语句之前的binlog日志为止。这样就可以完成数据库恢复的功能。
怎么配置binlog
MySQL服务器并不一定会生成binlog日志,我们可以通过查看log_bin系统变量来判断当前MySQL服务器是否生成binlog日志:
mysql> show variables like 'log_bin';+---------------+-------+| Variable_name | Value |+---------------+-------+| log_bin | ON |+---------------+-------+1 row in set, 1 warning (0.02 sec)
上例中bin_log系统变量的值为ON,表明当前服务器生成binlog,若为OFF表明当前服务器不生成binlog。
如果当前服务器不生成binlog,我们想开启binlog,那么就需要重启服务器,设置log-bin启动选项:
--log-bin[=base_name]
binlog日志并不是仅写到一个文件中,而是写入一组文件中,这组文件的命名是这样的:
basename.000001basename.000002basename.000003basename.000004...
也就是这组日志文件名称都包含一个basename,然后以一个数字结尾。
启动选项log-bin[=base_name]中的base_name就是这组binlog日志文件名称都包含的部分。如果我们不指定base_name(即单纯的使用--log-bin),那MySQL服务器会默认将主机名-bin作为binlog日志文件的basename。
我们看一下例子。
如果启动服务器的命令是:
mysqld --log-bin
表示开启binlog,并将binlog写入MySQL服务器的数据目录下。我的主机名是xiaohaizi,那MySQL服务器程序生成的binlog日志文件名就像是这样:
xiaohaizi-bin.000001xiaohaizi-bin.000002xiaohaizi-bin.000003xiaohaizi-bin.000004...
如果启动命令是:
mysqld --log-bin=xx
表示开启binlog,并将binlog写入MySQL服务器的数据目录下,binlog日志文件名就像是这样:
xx.000001xx.000002xx.000003xx.000004...
我们可以在将启动选项log-bin[=base_name]的base_name指定为一个绝对路径,那么binlog日志就不会被放到默认的数据目录中,而是写到我们指定的绝对路径下了。比方说启动命令是:
mysqld --log-bin=/Users/xiaohaizi/xx
这样binlog日志就会被写入/Users/xiaohaizi/路径下,binlog日志文件名就像是这样:
xx.000001xx.000002xx.000003xx.000004...
小贴士:
log-bin启动选项也可以放在配置文件中,我们这里就不赘述了。
binlog在文件系统中的内容
我们刚强调,binlog日志不是单个文件,而是一组包含共同basename的文件。比方说现在我的机器上有以下4个binlog文件:
xiaohaizi-bin.000001xiaohaizi-bin.000002xiaohaizi-bin.000003xiaohaizi-bin.000004
这些binlog文件并不能直接被当作文本打开,毕竟人家的名字是binlog,存储的是二进制数据。
除了真正存储binlog日志的文件外,MySQL服务器还会在相同的路径下生成一个关于binlog的索引文件,在我的系统上它的名称就是:
xiaohaizi-bin.index
这个索引文件是一个文本文件,我们可以直接打开:
shell> cat xiaohaizi-bin.index./xiaohaizi-bin.000001./xiaohaizi-bin.000002./xiaohaizi-bin.000003./xiaohaizi-bin.000004
可以看到,这个索引文件只是简单的将各个binlog文件的路径存储了起来而已。
查看binlog的语句
binlog中记录数据库发生更改的各种事件(events),这些事件的种类非常多,完整的事件类型如下所示:
enum Log_event_type {UNKNOWN_EVENT= 0,START_EVENT_V3= 1,QUERY_EVENT= 2,STOP_EVENT= 3,ROTATE_EVENT= 4,INTVAR_EVENT= 5,LOAD_EVENT= 6,SLAVE_EVENT= 7,CREATE_FILE_EVENT= 8,APPEND_BLOCK_EVENT= 9,EXEC_LOAD_EVENT= 10,DELETE_FILE_EVENT= 11,NEW_LOAD_EVENT= 12,RAND_EVENT= 13,USER_VAR_EVENT= 14,FORMAT_DESCRIPTION_EVENT= 15,XID_EVENT= 16,BEGIN_LOAD_QUERY_EVENT= 17,EXECUTE_LOAD_QUERY_EVENT= 18,TABLE_MAP_EVENT = 19,PRE_GA_WRITE_ROWS_EVENT = 20,PRE_GA_UPDATE_ROWS_EVENT = 21,PRE_GA_DELETE_ROWS_EVENT = 22,WRITE_ROWS_EVENT = 23,UPDATE_ROWS_EVENT = 24,DELETE_ROWS_EVENT = 25,INCIDENT_EVENT= 26,HEARTBEAT_LOG_EVENT= 27,IGNORABLE_LOG_EVENT= 28,ROWS_QUERY_LOG_EVENT= 29,WRITE_ROWS_EVENT = 30,UPDATE_ROWS_EVENT = 31,DELETE_ROWS_EVENT = 32,GTID_LOG_EVENT= 33,ANONYMOUS_GTID_LOG_EVENT= 34,PREVIOUS_GTIDS_LOG_EVENT= 35,ENUM_END_EVENT/* end marker */};
其中的一些我们熟悉的事件:
WRITE_ROWS_EVENT:插入记录。
UPDATE_ROWS_EVENT:更新记录。
DELETE_ROWS_EVENT:删除记录。
像创建、修改数据库或者表结构这些语句也都可以找到对应类型的事件,我们这里就不一一展开了。
为了查看我们的binlog中包含了哪些事件,可以使用下边这个语句(带中括号[]的表示可以省略的语句):
SHOW BINLOG EVENTS[IN 'log_name'][FROM pos][LIMIT [offset,] row_count]
其中:
[IN 'log_name']:log_name表示我们要查看哪个binlog日志文件的内容。[FROM pos]:pos表示我们要查看binlog文件的起始偏移量(通过指定这个值可以直接去查看某个偏移量处的事件)。LIMIT [offset,] row_count:这个LIMIT子句的含义和我们写SQL语句中LIMIT子句的含义是一样的,offset表示我们要从哪个事件开始查看,row_count表示我们要查看多少个事件。
下边该做一下测试了。
如果我们直接执行SHOW BINLOG EVENTS,表示查看第1个binlog日志文件的内容,在我的机器上就是xiaohaizi-bin.000001这个文件的内容:
mysql> SHOW BINLOG EVENTS;+----------------------+-----+----------------+-----------+-------------+---------------------------------------+| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |+----------------------+-----+----------------+-----------+-------------+---------------------------------------+| xiaohaizi-bin.000001 | 4 | Format_desc | 3 | 123 | Server ver: 5.7.21-log, Binlog ver: 4 || xiaohaizi-bin.000001 | 123 | Previous_gtids | 3 | 154 | || xiaohaizi-bin.000001 | 154 | Anonymous_Gtid | 3 | 219 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' || xiaohaizi-bin.000001 | 219 | Query | 3 | 296 | BEGIN || xiaohaizi-bin.000001 | 296 | Table_map | 3 | 367 | table_id: 138 (xiaohaizi.s1) || xiaohaizi-bin.000001 | 367 | Update_rows | 3 | 634 | table_id: 138 flags: STMT_END_F || xiaohaizi-bin.000001 | 634 | Xid | 3 | 665 | COMMIT /* xid=65 */ || xiaohaizi-bin.000001 | 665 | Stop | 3 | 688 | |+----------------------+-----+----------------+-----------+-------------+---------------------------------------+8 rows in set (0.01 sec)
可以看到共输出了8个列,其中:
Log_name:表示binlog日志的文件名。Pos:表示该事件在binlog日志文件中的起始偏移量。Event_type:表示这个事件的类型。Server_id:表示产生该事件的server_id(server_id是一个系统变量,我们可以通过配置让不通的MySQL服务器拥有不通的server_id)。End_log_pos:表示下一个事件的在binlog日志文件中的起始偏移量。Info:关于本事件的一些说明。
如果您对MySQL了解不多的话,那上边执行SHOW BINLOG EVENTS语句的输出的大部分事件可能都比较懵,可能能看懂两个事件:
- 起始偏移量为219(Pos=219)的事件是一个表明开始事务(BEGIN)的事件。
- 起始偏移量为367(Pos=367)的事件是一个更新记录的事件(UPDATE)。
好了现在先不细究各种类型的事件都代表什么,我们目前只需要知道binlog日志是由若干个事件组成的就好了。
如果我们想看其他binlog日志的详细情况,那就需要用到IN子句了:
mysql> SHOW BINLOG EVENTS IN 'xiaohaizi-bin.000004';+----------------------+-----+----------------+-----------+-------------+-------------------------------------------+| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |+----------------------+-----+----------------+-----------+-------------+-------------------------------------------+| xiaohaizi-bin.000004 | 4 | Format_desc | 3 | 123 | Server ver: 5.7.21-log, Binlog ver: 4 || xiaohaizi-bin.000004 | 123 | Previous_gtids | 3 | 154 | || xiaohaizi-bin.000004 | 154 | Anonymous_Gtid | 3 | 219 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' || xiaohaizi-bin.000004 | 219 | Query | 3 | 327 | use `xiaohaizi`; create table tt1 (c int) || xiaohaizi-bin.000004 | 327 | Anonymous_Gtid | 3 | 392 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' || xiaohaizi-bin.000004 | 392 | Query | 3 | 469 | BEGIN || xiaohaizi-bin.000004 | 469 | Table_map | 3 | 520 | table_id: 167 (xiaohaizi.tt1) || xiaohaizi-bin.000004 | 520 | Write_rows | 3 | 560 | table_id: 167 flags: STMT_END_F || xiaohaizi-bin.000004 | 560 | Xid | 3 | 591 | COMMIT /* xid=71 */ || xiaohaizi-bin.000004 | 591 | Anonymous_Gtid | 3 | 656 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' || xiaohaizi-bin.000004 | 656 | Query | 3 | 733 | BEGIN || xiaohaizi-bin.000004 | 733 | Table_map | 3 | 784 | table_id: 167 (xiaohaizi.tt1) || xiaohaizi-bin.000004 | 784 | Update_rows | 3 | 830 | table_id: 167 flags: STMT_END_F || xiaohaizi-bin.000004 | 830 | Xid | 3 | 861 | COMMIT /* xid=73 */ |+----------------------+-----+----------------+-----------+-------------+-------------------------------------------+14 rows in set (0.00 sec)
这样我们就看到了xiaohaizi-bin.000004这个binlog日志文件中存储了哪些事件了。
大家可以自行测试一下FROM子句和LIMIT子句的用法,这里就不展示了。
mysqlbinlog工具的使用
由于binlog是二进制格式的,我们不能直接以文本的形式查看。使用SHOW BINLOG EVENTS又只能看到粗略的信息,如果我们想查看binlog日志文件的详细信息的话,就需要使用MySQL给我们提供的实用工具——mysqlbinlog。
像mysqld、mysql这些可执行文件一样,mysqlbinlog也被放在了MySQL安装目录下的bin目录下。
我们可以将想查看的binlog日志文件路径作为mysqlbinlog的参数,就能查看文本形式的事件详细信息了。比方说我们看一下xiaohaizi-bin.000001:
shell> mysqlbinlog ./xiaohaizi-bin.000001/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=1*/;/*!50003 SET @OLD_COMPLETION_TYPE=@@COMPLETION_TYPE,COMPLETION_TYPE=0*/;DELIMITER /*!*/;# at 4#211202 20:01:14 server id 3 end_log_pos 123 CRC32 0xa308715b Start: binlog v 4, server v 5.7.21-log created 211202 20:01:14 at startupROLLBACK/*!*/;BINLOG 'irWoYQ8DAAAAdwAAAHsAAAAAAAQANS43LjIxLWxvZwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACKtahhEzgNAAgAEgAEBAQEEgAAXwAEGggAAAAICAgCAAAACgoKKioAEjQAAVtxCKM='/*!*/;# at 123#211202 20:01:14 server id 3 end_log_pos 154 CRC32 0x0d6a1ce6 Previous-GTIDs# [empty]# at 154#211202 20:07:07 server id 3 end_log_pos 219 CRC32 0xab157b64 Anonymous_GTID last_committed=0 sequence_number=1 rbr_only=yes/*!50718 SET TRANSACTION ISOLATION LEVEL READ COMMITTED*//*!*/;SET @@SESSION.GTID_NEXT= 'ANONYMOUS'/*!*/;# at 219#211202 20:07:07 server id 3 end_log_pos 296 CRC32 0xedb6b609 Query thread_id=2 exec_time=0 error_code=0SET TIMESTAMP=1638446827/*!*/;SET @@session.pseudo_thread_id=2/*!*/;SET @@session.foreign_key_checks=1, @@session.sql_auto_is_null=0, @@session.unique_checks=1, @@session.autocommit=1/*!*/;SET @@session.sql_mode=1436549152/*!*/;SET @@session.auto_increment_increment=1, @@session.auto_increment_offset=1/*!*/;/*!\C utf8 *//*!*/;SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=33/*!*/;SET @@session.lc_time_names=0/*!*/;SET @@session.collation_database=DEFAULT/*!*/;BEGIN/*!*/;# at 296#211202 20:07:07 server id 3 end_log_pos 367 CRC32 0x43cd57ee Table_map: `xiaohaizi`.`s1` mapped to number 138# at 367#211202 20:07:07 server id 3 end_log_pos 634 CRC32 0xe2981d9e Update_rows: table id 138 flags: STMT_END_FBINLOG '67aoYRMDAAAARwAAAG8BAAAAAIoAAAAAAAEACXhpYW9oYWl6aQACczEACAMPDw8PDw8PDiwBLAEsASwBLAEsASwB/u5XzUM=67aoYR8DAAAACwEAAHoCAAAAAIoAAAAAAAEAAgAI//8ApAMAABgAZmt3YW91b2syY2sxY2RlMzA2bzZ2NHcxCQAxMzA4NzI2NzgTAHBqdHFxc2dsMngxMjd4MWZjdngBAG0MAHBycmp3bmtxbjV1aRoANHN3cWJsNXEzd3V2bzUyZGdscmI1eWlmencJAGxzMjFoNHZhNwCkAwAAGABma3dhb3VvazJjazFjZGUzMDZvNnY0dzEJADEzMDg3MjY3OBMAcGp0cXFzZ2wyeDEyN3gxZmN2eAEAbQwAcHJyandua3FuNXVpGgA0c3dxYmw1cTN3dXZvNTJkZ2xyYjV5aWZ6dwIAeHieHZji'/*!*/;# at 634#211202 20:07:07 server id 3 end_log_pos 665 CRC32 0xe586ffeb Xid = 65COMMIT/*!*/;# at 665#211202 20:07:19 server id 3 end_log_pos 688 CRC32 0x8c69bad2 StopSET @@SESSION.GTID_NEXT= 'AUTOMATIC' /* added by mysqlbinlog */ /*!*/;DELIMITER ;# End of log file/*!50003 SET COMPLETION_TYPE=@OLD_COMPLETION_TYPE*/;/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=0*/;
哇唔,好大一片输出!
其中以# at xx开头的表示这是一个事件的开始,诸如:
# at 4:表示在偏移量为4的地方有一个事件,下边是该事件的详细信息。# at 123表示在偏移量为123的地方有一个事件,下边是该事件的详细信息。
...
具体的格式我们就先不展开了。
binlog的文件格式
本来我们还想唠叨一下binlog日志文件是怎么设计的,每一个事件是怎样表示的。可是回头一看好像已经写了很多内容了,小孩子太累了,之后抽时间再给大家写吧...
还有MySQL的主从复制是怎么跑起来的?XA事务是什么?为啥要两阶段提交?
再会~
binlog那些事儿(二)
标签: 公众号文章
读完上一篇文章,我们应该知道:
binlog日志用于主从复制以及数据恢复。
启动选项
--log-bin[=basename]可以控制MySQL服务器是否生成binlog,并且控制binlog日志文件所在路径以及文件名称。为了记录binlog,MySQL服务器在文件系统上创建了一系列存储真实binlog数据的文件(这些文件都以数字编号),以及binlog索引文件。
binlog日志文件中记载了数据库发生更改的若干事件。
使用SHOW BINLOG EVENTS语句可以查看某个binlog日志文件中存储的各种事件。
mysqlbinlog实用工具可以用文本形式查看某个binlog日志文件所记载各种事件。
掌握了上述内容之后,我们可以继续展开了。
binlog日志版本
binlog是自MySQL 3.23.14版本开始诞生的,到现在为止,共经历了4个版本:
- v1
- v2
- v3
- v4
其中的v4版本从MySQL 5.0就开始使用,直到今天。
所以本文着重介绍v4版本的binlog格式,其他版本就不关注了。
binlog日志文件结构概览
废话少说,先看一下一个binlog日志文件的基本格式:
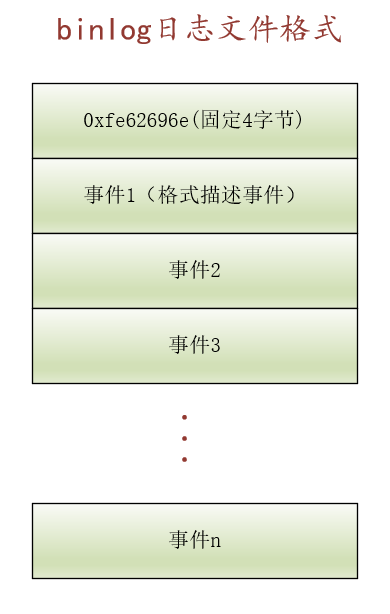
从上图中可以看出:
- 每个binlog日志文件的前4个字节是固定的,即:
0xfe626963。
小贴士:
0xfe626963中的0x626963的ascii码是'bin',0xfe626963也被称作魔数(magic number),如果一个文件不以0xfe626963开头,那这个文件肯定不算是一个binlog日志。很多软件都会在磁盘文件的某个地方添加一个类似的魔数来表明该文件是本软件处理的文件格式,比方说Intel处理器的BIOS会将磁盘上的第一个扇区加载到内存中,这个扇区的最后两个字节必须为魔数0x55aa,Java的class文件字节码的开头四个字节为魔数0xCAFEBABE。
每个binlog日志文件都是由若干事件构成的。
每个binlog日志文件所存储的第1个事件都是一个称作
格式描述事件(format description event)的特殊事件,我们稍后详细唠叨一下这个特殊事件。
其中,每个事件都可以被分成event header和event data两个部分,我们以上图的事件2为例展示一下:

其中:
event header部分描述了该事件是什么类型、什么时候生成的、由哪个服务器生成的等信息。
event data部分描述了该事件所特有的一些信息,比方说在插入一条记录时,需要将这条记录的内容记录在event data中。
event header结构
每个事件都会包括一个通用的event header,我们看一下这个event header的结构:

event header中包含了如下几部分内容:
- timestamp(4字节):产生该事件时的时间戳。
- typecode(1字节):该事件的类型,事件的类型在枚举结构
Log_event_type中列举出来(上一篇文章或者本文后续部分都有提到这个结构)。比方说格式描述事件的typecode就是15。 - server_id(4字节):产生该事件的主机的server_id。
- event_length(4字节):该事件总大小(包括event header + event data)。
- next_position(4字节):下一个事件的位置。
- flags(2字节):该事件的一些附加属性(称作flags)。
- extra_headers(不确定大小):目前这个字段尚未使用(也就是占用的大小为0),可能在将来的版本中使用,大家目前忽略这个字段就好了。
event data
event data由2部分组成,分别是:
- 固定大小部分
- 可变大小部分
不过并不是所有事件都有这两个部分,有的事件可以仅有其中的一个部分或者两个部分都没有。
上一篇文章中唠叨过,MySQL中支持几十种binlog事件,不同事件具有不同的event data部分。
我们先看一下binlog的事件类型有多少(上一篇文章中引用MySQL internal文档中的内容,有点陈旧,所以这次直接从MySQL5.7.22的源码中获取Log_event_type结构):
enum Log_event_type{/**Every time you update this enum (when you add a type), you have tofix Format_description_event::Format_description_event().*/UNKNOWN_EVENT= 0,START_EVENT_V3= 1,QUERY_EVENT= 2,STOP_EVENT= 3,ROTATE_EVENT= 4,INTVAR_EVENT= 5,LOAD_EVENT= 6,SLAVE_EVENT= 7,CREATE_FILE_EVENT= 8,APPEND_BLOCK_EVENT= 9,EXEC_LOAD_EVENT= 10,DELETE_FILE_EVENT= 11,/**NEW_LOAD_EVENT is like LOAD_EVENT except that it has a longersql_ex, allowing multibyte TERMINATED BY etc; both types share thesame class (Load_event)*/NEW_LOAD_EVENT= 12,RAND_EVENT= 13,USER_VAR_EVENT= 14,FORMAT_DESCRIPTION_EVENT= 15,XID_EVENT= 16,BEGIN_LOAD_QUERY_EVENT= 17,EXECUTE_LOAD_QUERY_EVENT= 18,TABLE_MAP_EVENT = 19,/**The PRE_GA event numbers were used for 5.1.0 to 5.1.15 and aretherefore obsolete.*/PRE_GA_WRITE_ROWS_EVENT = 20,PRE_GA_UPDATE_ROWS_EVENT = 21,PRE_GA_DELETE_ROWS_EVENT = 22,/**The V1 event numbers are used from 5.1.16 until mysql-trunk-xx*/WRITE_ROWS_EVENT_V1 = 23,UPDATE_ROWS_EVENT_V1 = 24,DELETE_ROWS_EVENT_V1 = 25,/**Something out of the ordinary happened on the master*/INCIDENT_EVENT= 26,/**Heartbeat event to be send by master at its idle timeto ensure master's online status to slave*/HEARTBEAT_LOG_EVENT= 27,/**In some situations, it is necessary to send over ignorabledata to the slave: data that a slave can handle in case thereis code for handling it, but which can be ignored if it is notrecognized.*/IGNORABLE_LOG_EVENT= 28,ROWS_QUERY_LOG_EVENT= 29,/** Version 2 of the Row events */WRITE_ROWS_EVENT = 30,UPDATE_ROWS_EVENT = 31,DELETE_ROWS_EVENT = 32,GTID_LOG_EVENT= 33,ANONYMOUS_GTID_LOG_EVENT= 34,PREVIOUS_GTIDS_LOG_EVENT= 35,TRANSACTION_CONTEXT_EVENT= 36,VIEW_CHANGE_EVENT= 37,/* Prepared XA transaction terminal event similar to Xid */XA_PREPARE_LOG_EVENT= 38,/**Add new events here - right above this comment!Existing events (except ENUM_END_EVENT) should never change their numbers*/ENUM_END_EVENT /* end marker */};
可见在MySQL 5.7.22这个版本中,共支持38种不同的binlog事件类型。把每一种事件格式都唠叨清楚要花费很多篇幅,并且没有多大的必要,我们下边只举一个具体的例子进行描述。
举一个具体的例子——格式描述事件
每个binlog日志文件都以格式描述事件作为第一个事件,它对应的Log_event_type就是FORMAT_DESCRIPTION_EVENT。我们看一下这种事件的结构:

从图中我们可以知道,格式描述事件共占用119字节,是由event header和event data两部分构成的,其中event header是各个事件都有的部分,我们上边详细唠叨过event header中各个字段的含义,这里就不赘述了。另外,在event data部分,格式描述事件的event data中只有固定长度部分,没有可变长度部分,其中的各个字段含义如下:
binlog_version:使用的binlog版本。server_version:产生此事件的MySQL服务器的版本。create_timestamp:产生此事件时的时间戳,该字段的值和event header中timestamp中的值一样。header_length:此事件的event header占用的存储空间大小。post-header length:使用1个字节来表示每个事件的event data部分占用的存储空间大小(不包括校验和相关字段),当前我使用的MySQL版本为5.7.22,共包含38种不同的事件,post-header length字段就占用了38个字节。checksum_alg:表示计算事件校验和的算法(该字段为1时表示采用CRC32算法)。checksum:表示本事件的校验和。
唠叨了很多,大家真正打开一个binlog日志文件来看一下:
魔数: FE62696Etimestamp: 8AB5A861typecode: 0Fserver_id: 03000000event_length: 77000000next_postion: 7B000000flags: 0000binlog_version: 0400server_version: 352E37 2E32312D 6C6F6700 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 000000create_timestamp: 8AB5A861header_length: 13post-header length(共38种): 380D0008 00120004 04040412 00005F00 041A0800 00000808 08020000 000A0A0A 2A2A0012 3400checksum_alg: 01checksum: 5B7108A3
小贴士:
其他事件的event data部分大家可以参考一下MySQL internal文档。另外,也可以使用mysqlbinlog,配合--hexdump启动选项来直接分析binlog的二进制格式。
基于语句(Statement)和基于行(Row)的binlog
同一条SQL语句,随着启动选项binlog-format的不同,可能生成不同类型的binlog事件:
当以启动选项
--binlog-format=STATEMENT启动MySQL服务器时,生成的binlog称作基于语句的日志。此时只会将一条SQL语句将会被完整的记录到binlog中,而不管该语句影响了多少记录。当以启动选项
--binlog-format=ROW启动MySQL服务器时,生成的binlog称作基于行的日志。此时会将该语句所改动的记录的全部信息都记录上。当以启动选项
--binlog-format=MIXED启动MySQL服务器时,生成的binlog称作基于行的日志。此时在通常情况下采用基于语句的日志,在某些特殊情况下会自动转为基于行的日志(这些具体情况请参考:https://dev.mysql.com/doc/refman/8.0/en/binary-log-mixed.html)。
小贴士:
我们也可以通过修改会话级别的binlog_format系统变量的形式来修改只针对本客户端执行语句生成的binlog日志的格式。
基于语句的binlog
假如服务器启动时添加了--binlog-format=STATEMENT启动选项,我们执行如下语句:
UPDATE s1 SET common_field = 'xx' WHERE id > 9990;
然后使用mysqlbinlog实用工具查看一下相应的binlog内容:
mysqlbinlog --verbose xiaohaizi-bin.000007...这里省略了很多内容# at 308#211207 21:00:27 server id 3 end_log_pos 440 CRC32 0x713f80ae Query thread_id=2 exec_time=0 error_code=0use `xiaohaizi`/*!*/;SET TIMESTAMP=1638882027/*!*/;update s1 set common_field= 'xx' where id > 9990/*!*/;...这里省略了很多内容
可见,基于语句的binlog只将更新语句是什么记录下来了。
基于行的binlog
假如服务器启动时添加了--binlog-format=ROW启动选项,我们执行如下语句:
UPDATE s1 SET common_field = 'xxx' WHERE id > 9990;
然后使用mysqlbinlog实用工具查看一下相应的binlog内容:
mysqlbinlog --verbose xiaohaizi-bin.000008...这里省略了很多内容### UPDATE `xiaohaizi`.`s1`### WHERE### @1=9991### @2='7cgwfh14w6nql61pvult6ok0ccwe'### @3='799105223'### @4='c'### @5='gjjiwstjysv1lgx'### @6='zg1hsvqrtyw2pgxgg'### @7='y244x02'### @8='xx'### SET### @1=9991### @2='7cgwfh14w6nql61pvult6ok0ccwe'### @3='799105223'### @4='c'### @5='gjjiwstjysv1lgx'### @6='zg1hsvqrtyw2pgxgg'### @7='y244x02'### @8='xxx'### UPDATE `xiaohaizi`.`s1`### WHERE### @1=9992### @2='2sfq3oftc'### @3='815047282'### @4='ub'### @5='73hw14kbaaoa'### @6='fxnqzef3rrpc7qzxcjsvt14nypep4rqi'### @7='10vapb6'### @8='xx'### SET### @1=9992### @2='2sfq3oftc'### @3='815047282'### @4='ub'### @5='73hw14kbaaoa'### @6='fxnqzef3rrpc7qzxcjsvt14nypep4rqi'### @7='10vapb6'### @8='xxx'...这里省略了很多内容
可见,基于行的binlog将更新语句执行过程中每一条记录更新前后的值都记录下来了。
基于语句的binlog的问题
在有主从复制的场景中,使用基于语句的日志可能会造成主服务器和从服务器维护的数据不一致的情况。
比方说我们有一个表t:
CREATE TABLE t (id INT UNSIGNED NOT NULL AUTO_INCREMENT,c VARCHAR(100),PRIMARY KEY(ID));
如果我们执行如下语句:
INSERT INTO t(c) SELECT c FROM other_table;
这个语句是想将other_table表中列c的值都插入到表t的列c中,而表t的id列是自增列,可以自动生成。
如果主库和从库的服务器执行SELECT c FROM other_table返回记录的顺序不同的话(不同服务器版本、不同的系统变量配置都可能导致同一条语句返回结果的顺序不同),那么针对表t相同id值的记录来说,列c就可能具有不同的值,这就会造成主从之间数据的不一致。
而如果将binlog的格式改为基于行的日志的话,由于主库在执行完语句后将该语句插入的每条完整的记录都写入binlog日志,就不会造成主从之间不一致了。
好像又写了很多枯燥的内容...
下次不写这么枯燥的了,我看着都有点儿烦~
redo、undo、buffer pool、binlog,谁先谁后,有点儿乱
标签: 公众号文章
这篇文章我们来讨论一下一条DML语句从客户端发出后,服务器都做了哪些处理。
小贴士:
虽然SELECT语句的处理也很复杂,但SELECT语句并不会修改数据库中的数据,也就不会记录诸如redo、undo、binlog这些日志,本文主要是想讨论redo、undo、binlog这些日志是在什么时候生成的,啥时候写到磁盘的。
为了增强文章的真实性(总是有一些小伙伴问小孩子为什么和CSDN上的某某文章陈述的不一样),我们会列举一些关键步骤的代码,本文用到的源码版本为MySQL 5.7.22。
另外,我们假设屏幕前的小伙伴已经知道什么是buffer pool,什么是redo日志,什么是undo日志,什么是binlog,以及MySQL为什么需要它们。我们不会再展开各种日志的格式、写入方式等细节问题,有不清楚的小伙伴可以查看《MySQL是怎样运行的:从根儿上理解MySQL》,包教包会,不会来问小孩子。
预备知识
我们讨论的是基于InnoDB存储引擎的表,数据会被保存在硬盘上的表空间(文件系统中的一个或多个文件)中。
InnoDB会将磁盘中的数据看成是若干个页的集合,页的大小默认是16KB。其中某些页面用于存储关于系统的一些属性,某些页面用于存储undo日志,某些页面用于存储B+树的节点(也就是包含记录的页面),反正总共有十来种不同类型的页面。
不过不论是什么类型的页面,每当我们从页面中读取或写入数据时,都必须先将其从硬盘上加载到内存中的buffer pool中(也就是说内存中的页面其实就是硬盘中页面的一个副本),然后才能对内存中页面进行读取或写入。如果要修改内存中的页面,为了减少磁盘I/O,修改后的页面并不立即同步到磁盘,而是作为脏页继续呆在内存中,等待后续合适时机将其刷新到硬盘(一般是有后台线程异步刷新)。
准备工作
为了故事的顺利发展,我们先建立一个表:
CREATE TABLE hero (number INT,name VARCHAR(100),country varchar(100),PRIMARY KEY (number),KEY idx_name (name)) Engine=InnoDB CHARSET=utf8;
然后向这个表里插入几条记录:
INSERT INTO hero VALUES(1, 'l刘备', '蜀'),(3, 'z诸葛亮', '蜀'),(8, 'c曹操', '魏'),(15, 'x荀彧', '魏'),(20, 's孙权', '吴');
然后现在hero表就有了两个索引(一个二级索引,一个聚簇索引),示意图如下:
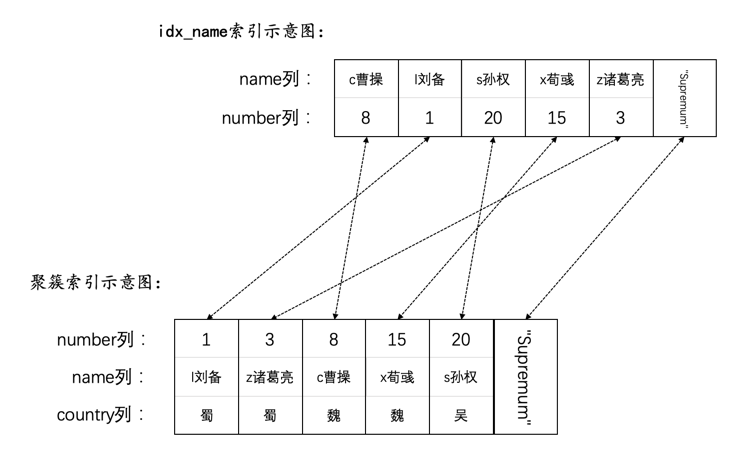
执行计划的生成
假设我们想执行下边这条UPDATE语句:
UPDATE hero SET country = '汉' WHERE name >= 'x荀彧';
MySQL优化器首先会分析一下使用不同索引执行查询的成本,然后选取成本最低的那个索引去执行查询。
对于上述语句来说,可选的执行方案有2种:
- 方案一:使用全表扫描执行查询,即扫描全部聚簇索引记录,我们可以认为此时的扫描区间就是
(-∞, +∞)。 - 方案二:使用二级索引idx_name执行查询,此时的扫描区间就是
['x荀彧', +∞)。
优化器会计算上述两种方案的成本,选取成本最低的方案作为最终的执行计划。
我们作为用户,可以通过EXPLAIN语句来看一下这个语句的执行计划(当然也可以通过MySQL提供的optimizer trace功能查看具体执行计划分析流程):
mysql> explain UPDATE hero SET country = '汉' WHERE name >= 'x荀彧';+----+-------------+-------+------------+-------+---------------+----------+---------+-------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+-------+---------------+----------+---------+-------+------+----------+-------------+| 1 | UPDATE | hero | NULL | range | idx_name | idx_name | 303 | const | 2 | 100.00 | Using where |+----+-------------+-------+------------+-------+---------------+----------+---------+-------+------+----------+-------------+1 row in set, 1 warning (0.01 sec)
可以看到,MySQL优化器决定采用方案二,即扫描二级索引idx_name在['x荀彧', +∞)这个扫描区间种的记录。
真正开始执行
MySQL分为server层和存储引擎层,我们前边的多篇文章有唠叨这两层之间的关系。考虑到没有看过前边文章的小伙伴,我们再不厌其烦的唠叨一下在执行上述UPDATE语句时server层和InnoDB层之间是如何沟通的。优化器的执行计划中得到了若干个扫描区间(本例中只有1个扫描区间['x荀彧', +∞)),针对每个扫描区间,都会执行下边的步骤:
处理扫描区间的第一条记录
步骤1:首先server层根据执行计划,向InnoDB层索要二级索引idx_name的扫描区间
['x荀彧', +∞)的第一条记录。步骤2:Innodb存储引擎便会通过二级索引idx_name对应的B+树,从B+树根页面一层一层向下查找(在页面中查找是通过页目录的槽进行二分查找的,这个过程很快),快速在叶子节点中定位到扫描区间
['x荀彧', +∞)的第一条二级索引记录。接着根据这条二级索引记录中的主键值执行回表操作(即通过聚簇索引的B+树根节点一层一层向下找,直到在叶子节点中找到相应记录),将获取到的聚簇索引记录返回给server层。步骤3:server层得到聚簇索引记录后,会看一下更新前的记录和更新后的记录是否一样,如果一样的话就不更新了,如果不一样的话就把更新前的记录和更新后的记录都当作参数传给InnoDB层,让InnoDB真正的执行更新记录的操作。
步骤4:InnoDB收到更新请求后,先更新记录的聚簇索引记录,再更新记录的二级索引记录。最后将更新结果返回给server层。
处理扫描区间的第二条记录
步骤1:server层继续向InnoDB索要下一条记录。
步骤2:此时由于已经通过B+树定位到二级索引扫描区间
['x荀彧', +∞)的第一条二级索引记录,而记录又是被串联成单向链表,所以InnoDB直接通过记录头信息的next_record的属性即可获取到下一条二级索引记录。然后通过该二级索引的主键值进行回表操作,获取到完整的聚簇索引记录再返回给server层。步骤3:server层得到聚簇索引记录后,会看一下更新前的记录和更新后的记录是否一样,如果一样的话就不更新了,如果不一样的话就把更新前的记录和更新后的记录都当作参数传给InnoDB层,让InnoDB真正的执行更新记录的操作。
步骤4:InnoDB收到更新请求后,先更新记录的聚簇索引记录,再更新记录的二级索引记录。最后将更新结果返回给server层。
处理扫描区间的剩余记录
该扫描区间中的其他记录的处理就和第2条记录的处理过程是一样一样的了,这里就不赘述了。
详细的更新过程
MySQL使用mysql_update函数处理我们上述的更新语句:
最主要的处理流程写在了一个循环里:
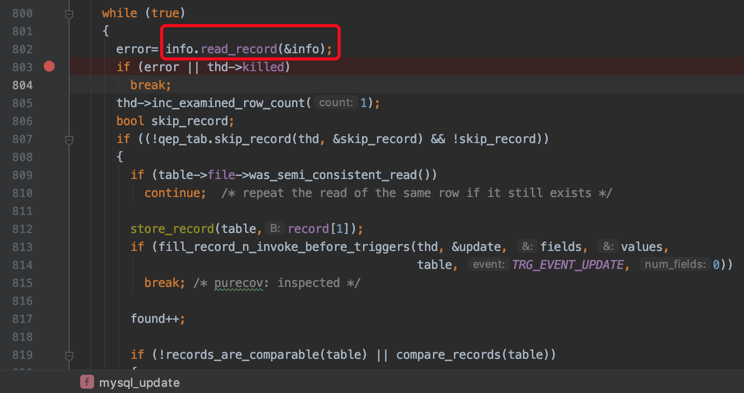
上图所示的while循环就是依次处理各条记录的过程。
其中info.read_record是用于获取扫描区间的一条记录,读取到该记录后随后展开详细的更新操作。处理完了之后再回到这个while循环的起点,通过info.read_record获取下一条记录,然后进行详细的更新操作。
也就是说,其实处理每一条记录的过程都是类似的,只不过定位扫描区间的第一条记录会有点儿麻烦(需要从B+树根页面一层一层向下找)。
我们下边聚焦于一条记录的更新过程,看看这个过程都发生了什么。
将记录所在的页面加载到buffer pool
我们想更新一条记录,首先就得在B+树中定位这条记录——即进行一次加锁读(上图中的info.read_record函数用于调用Innodb读取记录的接口,关于对一条记录加锁的过程我们在之前的文章中分析过,这里就不赘述了。)。
如果该记录所在的页面已经在内存的buffer pool中,那就可以直接读取,否则还需要将该记录所在的页面读取到内存中的buffer pool中。
小贴士:
再一次强调,不论我们想读写任何页面,都需要先将该页面从硬盘加载到buffer pool中。在定位扫描区间的第一条记录时,我们首先要读取B+树根页面中的记录,所以首先需要先把B+树根页面加载到buffer pool中,然后再读取下一层的页面,然后再读取下下层的页面,直到叶子节点。每当要读取的页面不在buffer pool中,都得将其先加载到buffer pool后才能使用。
Innodb使用row_search_mvcc处理读取一条记录的过程(不论是加锁读还是一致性读都调用这个函数),在该函数内btr_pcur_open_with_no_init用于从B+树定位记录:
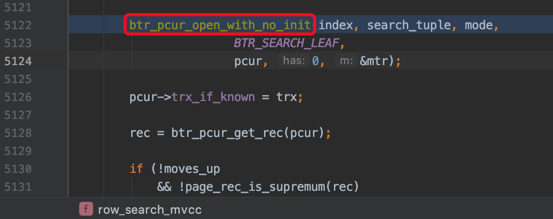
在定位记录时就需要将记录所在的页面加载到buffer pool,完成这个过程的函数是:
检测更新前后记录是否一样
在mysql_update函数中,当通过info.read_record读取到一条记录之后,就要分析一下这条记录更新前后是否发生变化:
上图中的compare_records用于比较记录更新前后是否一样。
如果更新前和更新后的记录是一样的,那就直接跳过该记录,否则继续向下处理。
调用存储引擎接口进行更新

上图中的ha_update_row就是要存储引擎去更新记录,其中的table->record[1]代表旧记录,table->record[0]代表新记录。
更新聚簇索引记录
InnoDB会首先更新聚簇索引记录,然后再更新二级索引记录。
我们先看更新聚簇索引记录时都发生了什么。更新聚簇索引的函数如下所示:
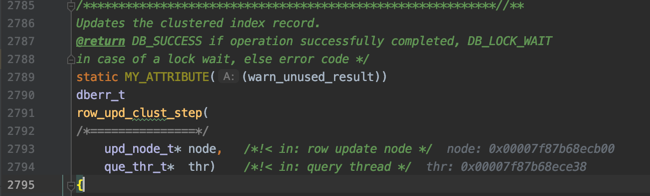
下边首先会尝试在同一个页面中更新记录,这被称作乐观更新,调用btr_cur_optimistic_update函数:

如果不能在本页面中完成更新(比方说更新后的记录非常大啊,本页面容纳不下),就会尝试悲观更新:
本例中使用乐观更新即可。
记录undo日志
更新记录前,首先要记录相应的undo日志,调用trx_undo_report_row_operation来记录undo日志:
首先我们要知道,MySQL的undo日志是要写到一种专门存储undo日志的页面中的。如果一个事务写入的undo日志非常多,需要占用多个Undo页面,那这些页面会被串联成一个链表,称作Undo页面链表。
trx_undo_page_report_modify函数用于真正的向Undo页面中写入undo日志。另外,由于我们这里是在修改页面,一个事务执行过程中凡是修改页面的地方,都需要记录相应的redo日志,所以在这个函数的末尾,有一个记录修改这个Undo页面的redo日志的函数trx_undof_page_add_undo_rec_log:

有同学在这里肯定会疑惑:是先将undo日志写入Undo页面,然后再记录修改该页面对应的redo日志吗?
先说答案:是的。
不过这里修改后的页面并没有加入buffer pool的flush链表,记录的redo日志也没有加入到redo log buffer。当这个函数执行完后,才会:
- 先将这个过程产生的redo日志写入到redo log buffer。
- 再将这个过程修改的页面加入到buffer pool的flush链表中。
上述过程是在mtr_commit中完成的:
小贴士:
设计MySQL的大叔把对底层页面的一次原子修改称作一个Mini Trasaction,即MTR。一个MTR中包含若干条redo日志,在崩溃恢复时,要么全部恢复该MTR对应的redo日志,要么全部不恢复。
也就是说实际上虽然先修改Undo页面,后写redo日志,但是此时InnoDB并不认为Undo页面是脏页,就不会将其刷新到硬盘,redo日志也没有写入到redo log buffer,这些redo日志也不会被刷新到redo日志文件。只有当MTR提交时,才先将redo日志复制到redo log buffer,再将修改的Undo页面加入到flush链表。
所以我们可以粗略的认为修改Undo页面的redo日志是先写的,而修改页面的过程是后发生的。
小贴士:
有后台线程不断的将redo log buffer中的redo日志刷新到硬盘的redo日志文件,也有后台线程不断的将buffer pool里的脏页(只有加入到flush链表后的页面才能算作是脏页)刷新到硬盘中的表空间中。设计InnoDB的大叔规定,在刷新一个脏页到硬盘时,该脏页对应的redo日志应该被先刷新到redo日志文件。而redo日志是顺序刷新的,也就是说,在刷新redo log buffer的某条redo日志时,在它之前的redo日志也都应该被刷新到redo日志文件。
修改页面内容
上一步骤是先把undo日志写到Undo页面中以及记录相应的redo日志,接下来该真正修改聚簇索引记录了。
首先更新系统字段trx_id以及roll_pointer:

然后真正的修改记录内容:

小贴士:
由于本例中的更新语句更新前后的各个字段占用的存储空间大小是不变的,所以可以直接就地(in place)更新。
然后记录更新的redo日志:

像向Undo页面写入undo日志一样,InnoDB规定更新一个页面中的一条记录也属于一个MTR。在该MTR提交时,也是先将MTR中的redo日志复制到redo log buffer,然后再将修改的页面加入到flush链表。
所以我们也可以认为在这个过程中,先记录修改页面的redo日志,然后再真正的修改页面。
至此,一条聚簇索引记录就更新完毕了。
更新二级索引记录
更新二级索引记录的函数如下所示:
更新二级索引记录时不会再记录undo日志,但由于是在修改页面内容,会先记录相应的redo日志。
由于本例子中并不会更新二级索引记录,所以就跳过本步骤了。
记录binlog
在一条更新语句执行完成后(也就是将所有待更新记录都更新完了),就需要该语句对应的binlog日志了(下图中的thd->binlog_query函数):
不过值得注意的是,此时记录的binlog日志并不会被写到binlog日志文件中,而是被暂时保存到内存的某个地方,等之后事务提交的时候才会真正将该事物执行过程中产生的所有binlog统一写入binlog日志文件。
提交事务的时候
终于要唠叨到所谓的两阶段提交(two phase commit)啦~
在事务提交时,binlog才会被真正刷新到binlog日志文件中,redo日志也会被刷新到redo日志文件中。不过由于这个部分涉及较多的知识点,所以我们本篇先不唠叨了,留在下一篇里吧
哈哈>_>
总结
本篇文章唠叨了执行一条UPDATE语句过程中都发生了什么事情。当优化器分析出成本最小的执行计划后,就开始对执行计划中的各个扫描扫描区间中的记录进行更新。具体更新一条记录的流程如下:
- 先在B+树中定位到该记录(这个过程也被称作加锁读),如果该记录所在的页面不在buffer pool里,先将其加载到buffer pool里再读取。
- 读取到记录后判断记录更新前后是否一样,一样的话就跳过该记录,否则进行后续步骤。
- 首先更新聚簇索引记录。
更新聚簇索引记录时:
①先向Undo页面写undo日志。不过由于这是在更改页面,所以修改Undo页面前需要先记录一下相应的redo日志。
②真正的更新记录。不过在真正更新记录前也需要记录相应的redo日志。 - 更新其他的二级索引记录。
至此,一条记录就更新完了。
然后开始记录该语句对应的binlog日志,此时记录的binlog并没有刷新到硬盘上的binlog日志文件,在事务提交时才会统一将该事务运行过程中的所有binlog日志刷新到硬盘。
剩下的就是所谓的两阶段提交的事情了,我们下节再会~
XA事务与两阶段提交
标签: 公众号文章
什么是分布式事务
我们平常使用事务的时候,基本流程是这样的:
- 使用
BEGIN/START TRANSACTION来开启一个事务。 - 然后可以继续向服务器发送一些增删改查语句,这些语句都属于这个事务的一部分。
- 之后可以向服务器发送
COMMIT语句来表明这个事务的所有语句都已经发送完了,服务器可以提交这个事务了。
小贴士:
如果auto_commit系统变量值为1,并且我们未显式使用BEGIN/START TRANSACTION开启事务,那MySQL也会将单条语句当作是一个事务来执行。
我们知道MySQL分为server层和存储引擎层,而事务具体是在存储引擎层实现的。有的存储引擎支持事务,有的不支持。
对于支持事务的存储引擎来说,它们提供了相应的开启事务、提交事务的接口。server层只需要调用这些接口,来让存储引擎执行事务。
除了MySQL自带的支持事务的存储引擎InnoDB外,其他一些公司也为MySQL开发了一些支持事务的存储引擎,比方说阿里的XEngine,Facebook的Rocksdb等。
在书写包含在一个事务中的语句时,不同语句可能会涉及不同存储引擎的表,这时如果我们想保持整个事务要么全部执行,要么全部不执行的话,本质上就需要保证各个存储引擎的事务全部提交,或者全部回滚。不能存在某些存储引擎事务提交了,某些存储引擎事务回滚了的情况。
稍微总结一下就是:我们有一个大的事务,我们可以称其为全局事务,这个全局事务由若干的小的事务组成。要实现这个大的事务,就必须让它对应的若干个小的事务全部完成,或者全部回滚。我们也可以把这个大的全局事务称作分布式事务。
除了上述涉及多个存储引擎的全局事务之外,分布式事务还有更多的应用场景。比方说我们的数据分布在多个MySQL服务器中;甚至有的数据分布在MySQL服务器中,有的数据分布在Oracle服务器中;甚至有些服务器在中国,有些服务器在美国。我们想完成一个操作,这个操作会更新多个系统里的数据,此时如果我们想让这个操作具有原子性,就需要保证让各个系统中的小事务要么全部提交,要么全部回滚。这时的这个跨多个系统的操作也可以被称作分布式事务。
跨行转账是一个典型的分布式事务的实例。各个银行都有自己的服务,如果狗哥在招商银行存了10块钱,他想把这10块钱转给猫爷在建设银行的账户,那么招商银行先得给狗哥账户扣10块,然后建设银行给猫爷账户增10块。而招商银行和建设银行根本就不是一个系统,招商银行给狗哥扣钱的业务放到了自己的一个事务里,建设银行给猫爷加钱的业务放到了自己的一个事务里,这两个事务其实在各自的系统中并没有什么关系,完全有可能招商银行的事务提交了,而建设银行的事务由于系统宕机而失败了,这就导致狗哥扣了钱,却没有转给猫爷的惨剧发生。所以我们必须引入一些机制,来实现分布式事务。
XA规范
有一个名叫X/Open(这名儿听着就挺霸气)的组织提出了一个名为XA的规范。
小贴士:为节省同志们去搜索这份规范的宝贵时间,大家在“我们都是小青蛙”公众号输入“XA”即可下载该规范。
有人说XA的含义是Extended Architecture。令人迷惑的是,我竟然没在上述规范中找到XA到底是个啥意思(很尴尬😅),大家把它理解成一个名字就好了,其实叫成王尼玛也没啥问题。
这个XA规范提出了2个角色:
- 一个全局事务由多个小的事务组成,所以我们得在某个地方找一个总揽全局的家伙,这个家伙用于和各个小事务进行沟通,指导它们是提交还是回滚。这个家伙被称作事务协调器(Transaction Coordinator)或者资源管理器(Resource Manager)。
不论是事务协调器,还是资源管理器这样的名字念起来都比较拗口,有催眠功效,我们后续就把事务协调器或者资源管理器称作大哥了哈。
- 管理一个小事务的家伙被称作事务管理器(Transaction Manager)。
事务管理器念起来也比较拗口,我们就把它称作小弟了哈。
要提交一个全局事务,那么属于该全局事务的若干个小事务就应该全部提交,只要有任何一个小事务无法提交,那么整个全局事务就应该全部回滚。所以此时大哥不能让各个小弟逐个提交,因为不能保证后面提交的小弟是否可能发生错误。此时XA规范中指出,要提交一个全局事务,必须分为2步:
Prepare阶段:当
大哥准备提交一个全局事务时,会依次通知各个小弟说:“现在事务中的语句都已经执行完了,我们准备提交了,你这里有没有什么问题?”。如果小弟觉得自己没有问题,就把在事务执行过程中所产生的redo日志都刷新到硬盘,然后对大哥说:“没有问题”。如果小弟遇到了啥突发情况不能提交(比方说磁盘满了,不能写redo了),就对大哥说:“不行,提交不了了”。Commit阶段:如果在Prepare阶段各个
小弟给大哥的答复都是:“OK,木有问题”,那大哥就要真正通知各个小弟去提交事务了。如果在Prepare阶段某个小弟给大哥的回复是:“NO,做不了”,那大哥就得通知所有小弟:“遇到突发情况,所有人立即回滚”。小弟收到通知便都回滚了。不过在大哥通知各个小弟是要提交之前,都需在某个地方记录一下这个全局事务已经提交,以及各个小弟都是什么的信息。
XA规范把上述全局事务提交时所经历的两个阶段称作两阶段提交。
小贴士:
如果一个全局事务仅包含一个小弟的话,那两阶段提交可以退化成1阶段提交。
大家可以看到,XA规范引入了一个在事务提交时的Prepare阶段,这个阶段就是让各个事务做好提交前的准备,具体就是把语句执行过程中产生的redo日志都刷盘。如果语句执行过程中的redo日志都刷盘了,那么即使之后系统崩溃,那么在重启的时候还是可以恢复到该事务各个语句都执行完的样子。
这样的话,在Prepare阶段结束后,即使某个小弟因为某些原因而崩溃,在之后重启恢复时,也可以把自己再次恢复成Prepare状态。在崩溃恢复结束后,大哥可以继续让小弟提交或者回滚。
以上就是XA规范的核心内容,下边可以来唠叨一下MySQL对上述XA规范的实现了。
MySQL中的XA事务
MySQL中的XA事务分为外部XA和内部XA,我们分别来看一下。
外部XA
在MySQL的外部XA实现中,MySQL服务器充当小弟,而连接服务器的客户端程序充当大哥。
与使用BEGIN语句开启,使用COMMIT提交的常规事务不同,如果我们想在MySQL中使用XA事务,需要一些特殊的语句:
XA {START|BEGIN} xid:该语句用于开启一个XA事务,此时该XA事务处于ACTIVE状态。
在一台MySQL服务器上,每个XA事务都必须有一个唯一的id,被称作xid。这个xid是由发起XA事务的应用程序(客户端)自己指定的,只要我们自己保证它唯一就好了。
这个xid其实是由gtrid、bqual、formatID三个部分组成的:
xid: gtrid [, bqual [, formatID ]]
其中gtrid(global transaction id)是指全局事务id,是一个字符串,bqual是指分支限定符,formatID是指gtrid和bqual所使用的格式。
不过我们这里并不打算详纠啥是个分支,还限定符,以及啥格式之类的,我们可以在指定xid的时候省略bqual和formatID的值,MySQL会使用默认的值(bqual默认是空字符串'',formatID默认是1)。也就是说我们文章后续内容指定xid时仅指定gtrid就好了,也就是指定一个字符串即可。
XA END xid:在使用XA START xid开启了一个XA事务后,客户端就可以接着发送属于这个XA事务的各条语句,等所有语句都发送完毕后,就可以接着发送XA END xid来告知服务器由xid标识的XA事务的所有语句都输入完了。此时该XA事务处于IDLE状态。XA PREPARE xid:对于处于IDLE状态的XA事务,应用程序就可以询问MySQL服务器是否准备好提交这个XA事务了,此时就可以给服务器发送XA PREPARE xid语句。当MySQL服务器收到此语句后,就需要做准备提交前的工作了,比如把该事务执行过程中所产生的redo日志刷新到磁盘等。此时XA事务处于PREPARE状态。XA COMMIT xid [ONE PHASE]:对于处于PREPARE状态的XA事务,应用程序可以发送XA COMMIT xid来让MySQL服务器提交XA事务。如果此XA事务尚处于IDEL状态,那应用程序可以不发送XA PREPARE xid,而直接发送XA COMMIT xid ONE PHASE来让MySQL服务器直接提交事务即可。此XA事务处于COMMITE状态。XA ROLLBACK xid:应用程序通过发送此语句来让MySQL服务器回滚xid所标识的事务。此时XA事务处于ABORT状态。XA RECOVER:应用程序想看一下当前MySQL服务器上已经处于Prepare状态的XA事务有哪些,就可以发送该语句。
介绍了在MySQL中使用外部XA的一些语句,接下来可以画一个XA事务的状态转换图了:

哔哔了很多,赶紧来做个实验:
mysql> XA START 'a'; //XA事务进入ACTIVE状态Query OK, 0 rows affected (0.00 sec)mysql> DELETE FROM x WHERE id = 1; //XA事务中包含的语句Query OK, 1 row affected (0.00 sec)mysql> XA END 'a'; //XA事务进入IDEL状态Query OK, 0 rows affected (0.00 sec)mysql> XA PREPARE 'a'; //XA事务进入PREPARE状态Query OK, 0 rows affected (0.01 sec)mysql> XA COMMIT 'a'; //XA事务进入COMMIT状态Query OK, 0 rows affected (0.01 sec)
MySQL的外部XA除了被用于跨行转账这种经典的分布式事务应用场景,还被广泛应用于所谓的数据库中间件。
现在各个公司由于表中数据太多,这些数据会被分散在不通服务器中存储。由应用程序员分别和不同的MySQL服务器打交道实在费劲,所以有一种称作数据库中间件的东西开始问世。即应用程序只将SQL语句发送给数据库中间件,中间件分析一下该SQL访问的数据都在哪些不同的服务器中存储着,并且计算出不通服务器应该执行哪些SQL语句。然后就可以对不同的服务器分别开启XA事务,并且让把不同服务器需要执行的语句分别发送到不同的服务器中。等应用程序员告知中间件准备提交事务时,中间件先给各个服务器发送XA PREPARE语句,如果各个服务器都返回OK的话,接着就给各个服务器发送XA COMMIT语句来提交XA事务,等各个服务器把提交成功的消息返回给中间件,中间件就可以通知应用程序事务提交成功了。
内部XA
对于一台服务器来说,即使客户端使用BEGIN/START TRANSACTION语句开启的普通事务,该事务所包含的语句也有可能涉及多个存储引擎。此时MySQL内部采用XA规范来保证所有支持事务的存储引擎要么全部提交,要么全部回滚,这也被称作MySQL的内部XA。
另外有一点值得注意的是,内部XA除了解决这种设计多个存储引擎的事务之外,还解决保证binlog和存储引擎所做的修改是一致的问题。我们稍后重点展开一下这个问题。
在MySQL内部执行一个事务时,存储引擎会修改相应的数据,server层会记录语句对应的binlog。这是两个要么都完成,要么都步完成的事情。否则的话:
如果存储引擎修改了相应数据并且提交了事务,而server层却未写入binlog。在有主从复制的场景中,意味着这个事务不会在从库中得已执行,从而造成主从之间的数据不一致。
如果server层写入了binlog,但存储引擎却回滚了事务。在有主从复制的场景中,意味着这个事务会在从库中得已执行,从而造成主从之间的数据不一致。
那我们需要保证:如果存储引擎提交了事务,server层的binlog日志必须也被写入到硬盘上;如果存储引擎回滚了事务,server层的binlog日志必须不能被写入到硬盘上。
MySQL采用内部XA来实现上述内容,下边以Innodb存储引擎为例,具体讨论一下Innodb事务的提交和binlog日志写入的过程。
有binlog参与的内部XA事务
小贴士:
后续会用到很多undo日志结构的内容,这些内容都在《MySQL是怎样运行的:从根儿上理解MySQL》书籍中有详细叙述,如果不了解的话,看起来可能会有点儿困难,建议先将undo日志章节内容看熟。
当客户端执行COMMIT语句或者在自动提交的情况下,MySQL内部开启一个XA事务,分两阶段来完成XA事务的提交:
- Prepare阶段:存储引擎将该事务执行过程中产生的redo日志刷盘,并且将本事务的状态设置为
PREPARE。binlog啥也不干。下边看一下具体的代码。
binlog_prepare是在PREPARE阶段对binlog所做的一些操作:
binlog_prepare函数基本啥也没干,我们就不展开说了。
innobase_xa_prepare是InnoDB存储引擎实现的XA规范的prepare接口:
这个函数做了很多事情,我们得好好唠叨一下。
首先我们知道事务执行过程中需要写undo日志,这些undo日志被写到若干个页面中,这些页面也被称作Undo页面,这些页面会串成一个链表,称作Undo页面链表。在一个事务对应的Undo页面链表的首个页面中,记录了一些关于这个事务的一些属性,我们贴个图看一下:
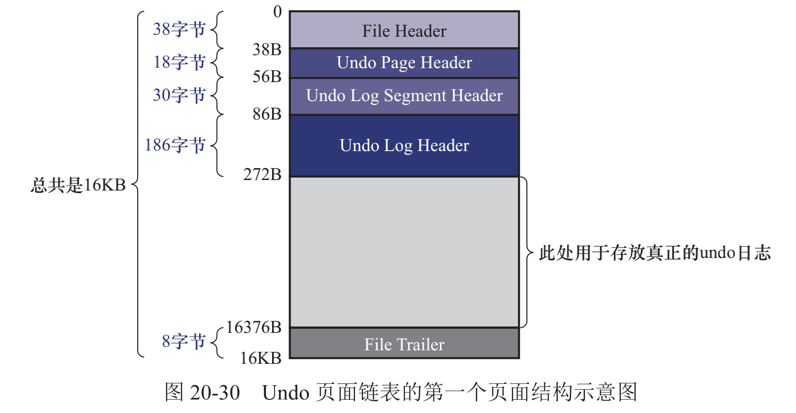
我们先看一下其中的Undo Log Segment Header部分:
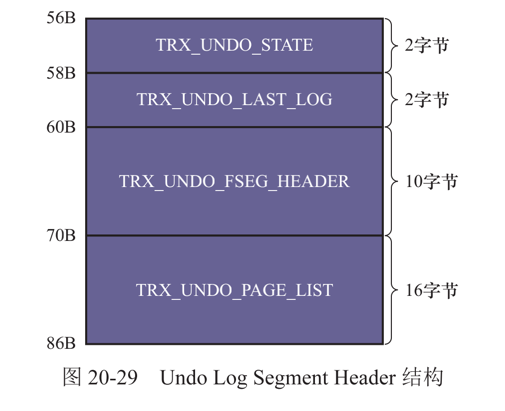
其中的TRX_UNDO_STATE字段就表明该事务目前处于什么状态。当处于Prepare阶段时,调用innobase_xa_prepare函数会将TRX_UNDO_STATE字段的值设置为TRX_UNDO_PREPARED(整数5),表明当前事务处在Prepare阶段。
我们再看一下Undo Log Header部分:

这个部分体现着这个Undo页面链表所属的事务的各种信息,包括事务id。其中两个属性和我们今天主题特别搭:
TRX_UNDO_XID_EXISTS:表示有没有xid信息。XID信息:表示具体的xid是什么。
当处于Prepare阶段时,调用innobase_xa_prepare函数会将TRX_UNDO_XID_EXISTS设置为TRUE,并将本次内部XA事务的xid(这个xid是MySQL自己生成的)写入XID信息处。
小贴士:
再一次强调,修改Undo页面也是在修改页面,事务凡是修改页面就需要先记录相应的redo日志。
记录了关于该事务的各种属性之后,接下来该将到现在为止所产生的所有redo日志进行刷盘,刷盘的函数如下所示:
在将redo日志刷盘之后,即使之后系统崩溃,在重启恢复的时候也可以将处于Prepare状态的事务完全恢复。
小贴士:
在MySQL 5.7中,有一个称之为组提交(group commit)的优化。即设计InnoDB的大叔觉得各个事务分别刷自己的redo日志和binlog效率太低,他们把并发执行的多个事务所产生的redo日志和binlog在后续的Commit阶段集中起来统一刷新,这样可能提升效率,所以在MySQL 5.7以及之后的版本中,上述在Prepare阶段刷新redo日志的操作会被推迟到Commit阶段才真正执行。关于组提交的优化措施我们并不想过多展开,大家忽略这个优化就好了,这里就认为在Prepare阶段事务就已经将执行过程中产生的redo日志刷盘就OK。
- Commit阶段:先将事务执行过程中产生的binlog刷新到硬盘,再执行存储引擎的提交工作。
将binlog刷盘的函数如下:
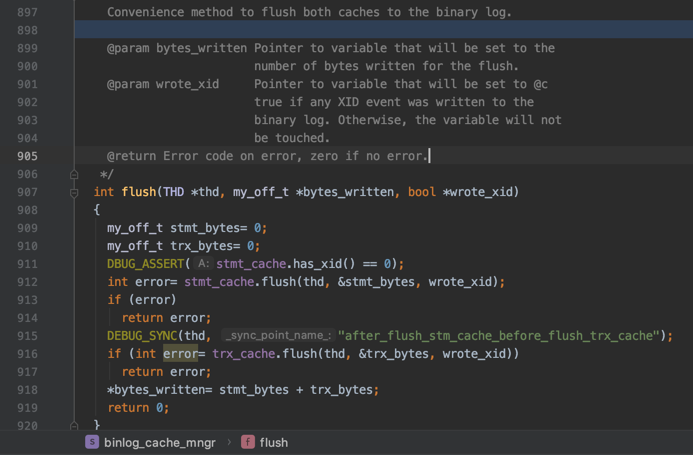
InnoDB存储引擎提交事务使用innobase_commit函数完成存储引擎层面的事务提交:
innobase_commit函数做了很多事情,我们挑一些重要的来说。
首先是更新Undo页面链表的状态,将我们上边说的Undo Log Segment Header部分的STATE字段更新一下。更新规则如下:

也就是说如果当前事务产生的undo日志比较少,那么就继续让别的事务复用该Undo页面链表,将STATE设置为TRX_UNDO_CACHED;如果Undo页面链表用于存储INSERT操作产生的undo日志,那么就将STATE设置为TRX_UNDO_TO_FREE,稍后会释放Undo页面链表占用的页面;如果Undo页面链表用于存储其他操作产生的undo日志,那么就将STATE设置为TRX_UNDO_TO_PURGE,等待purge线程后台回收该Undo页面链表。
小贴士:
UPDATE、DELETE操作产生的undo日志可能会用于其他事务的MVCC操作,所以不能立即删除。
对于存储UPDATE、DELETE操作产生的undo日志的Undo页面链表,还要将其加入所谓的History链表,关于这个History链表是啥,我们这里就不展开了。
每个Undo页面链表的首个页面的页号会被存储在表空间的某个地方,以便崩溃恢复的时候可以根据该页来进行恢复。如果此时在事务提交时,Undo页面链表的状态被设置为TRX_UNDO_CACHED,那存储Undo页面链表的首个页面的页号的地方也就不需要做改动;如果此时在事务提交时,Undo页面链表的状态被设置为TRX_UNDO_CACHED,那存储Undo页面链表的首个页面的页号的地方就得被设置为空,这样这个地方就可以被其他事务使用了。
至此,这个事务就算是提交完了。
崩溃恢复
每当系统重启时,都会先进入恢复过程。
此时首先按照已经刷新到磁盘的redo日志修改页面,把系统恢复到崩溃前的状态。
然后在表空间中找一下各个Undo页面链表的首个页面的页号,然后就可以读取该页面的各种信息。我们再把这个页面的内容给大家看一下:
通过这个页面,我们可以知道该Undo页面链表对应的事务状态是什么:
如果是
TRX_UNDO_ACTIVE状态,也就是活跃状态,直接按照undo日志里记载的内容将其回滚就好了。如果是
TRX_UNDO_PREPARE状态,那么是提交还是回滚就取决于binlog的状态了,我们稍后再说。如果是其他状态,就将该事务提交即可。
对于处于PREPARE状态的事务,存储引擎既可以提交,也可以回滚,这取决于目前该事务对应的binlog是否已经写入硬盘。这时就会读取最后一个binlog日志文件,从日志文件中找一下有没有该PREPARE事务对应的xid记录,如果有的话,就将该事务提交,否则就回滚好了。
最后
这一篇文章有点儿长,不点赞/在看/分享,真的好么~
推荐资料与书籍
一些资料
MySQL官方文档:https://dev.mysql.com/doc/refman/5.7/en/
MySQL官方文档是写作本书时参考最多的一个资料。说实话,文档写的非常通俗易懂,唯一的缺点就是太长了,导致大家看的时候无从下手。MySQL Internals Manual:https://dev.mysql.com/doc/internals/en/
介绍MySQL如何实现各种功能的文档,写的比较好,但是太少了,有很多章节直接跳过了。
A Critique of ANSI SQL Isolation Levels:https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/tr-95-51.pdf
深入分析隔离级别的一篇论文,特经典。
何登成的github:https://github.com/hedengcheng/tech
登博的博客非常好,对事务、优化这讨论的细节也非常多,不过由于大多是PPT结构,字太少,对上下文不清楚的同学可能会一脸懵逼。
orczhou的博客:http://www.orczhou.com/
Jeremy Cole的博客:https://blog.jcole.us/innodb/
Jeremy Cole大神不仅写作了
innodb_ruby这个非常棒的解析InnoDB存储结构的工具,还对这些存储结构写了一系列的博客,在我几乎要放弃深入研究表空间结构的时候,是他老人家的博客把我又从深渊里拉了回来。那海蓝蓝(李海翔)的博客:https://blog.csdn.net/fly2nn
taobao月报:http://mysql.taobao.org/monthly/
因为MySQL的源码非常多,经常让大家无从下手,而taobao月报就是一个非常好的源码阅读指南。
吐槽一下,这个taobao月报也只能当作源码阅读指南看,如果真的不看源码光看月报,那只能当作天书看,十有八九被绕进去出不来了。
MySQL Server Blog:http://mysqlserverteam.com/
MySQL team的博客,一手资料,在我不知道看什么的时候给了很多启示。
mysql_lover的博客:https://blog.csdn.net/mysql_lover/
Jørgen's point of view:https://jorgenloland.blogspot.com/
mariadb的关于查询优化的文档:https://mariadb.com/kb/en/library/query-optimizations/
不得不说mariadb的文档相比MySQL的来说就非常有艺术性了(里边儿有很多漂亮的插图),我很怀疑MySQL文档是程序员直接写的,mariadb的文档是产品经理写的。当我们想研究某个功能的原理,在MySQL文档干巴巴的说明中找不到头脑时,可以参考一下mariadb娓娓道来的风格。
Reconstructing Data Manipulation Queries from Redo Logs:https://www.sba-research.org/wp-content/uploads/publications/WSDF2012_InnoDB.pdf
关于InnoDB事务的一个PPT:https://mariadb.org/wp-content/uploads/2018/02/Deep-Dive_-InnoDB-Transactions-and-Write-Paths.pdf
非官方优化文档:http://www.unofficialmysqlguide.com/optimizer-trace.html
这个文档非常好,非常非常好~
MySQL8.0的源码文档:https://dev.mysql.com/doc/dev/mysql-server
一些书籍
《数据库查询优化器的艺术》李海翔著
大家可以把这本书当作源码观看指南来看,不过讲的是5.6的源码,5.7里重构了一些,不过大体的思路还是可以参考的。
《MySQL运维内参》周彦伟、王竹峰、强昌金著
内参里有许多代码细节,是一个阅读源码的比较好的指南。
《Effective MySQL:Optimizing SQL Statements》Ronald Bradford著
小册子,可以一口气看完,对了解MySQL查询优化的大概内容还是有些好处滴。
《高性能MySQL》瓦茨 (Baron Schwartz) / 扎伊采夫 (Peter Zaitsev) / 特卡琴科 (Vadim Tkachenko) 著
经典,对于第三版的内容来说,如果把第2章和第3章的内容放到最后就更好了。不过作者更愿意把MySQL当作一个黑盒去讲述,主要是说明了如何更好的使用MySQL这个软件,这一点从第二版向第三版的转变上就可以看出来,第二版中涉及的许多的底层细节都在第三版中移除了。总而言之它是MySQL进阶的一个非常好的入门读物。
《数据库事务处理的艺术》李海翔著
同《数据库查询优化器的艺术》。
《MySQL技术内幕 : InnoDB存储引擎 第2版》姜承尧著
学习MySQL内核进阶阅读的第一本书。
《MySQL技术内幕 第5版》 Paul DuBois 著
这本书是对于MySQL使用层面的一个非常详细的介绍,也就是说它并不涉及MySQL的任何内核原理,甚至连索引结构都懒得讲。像是一个老妈子在给你不停的唠叨吃饭怎么吃,喝水怎么喝,怎么上厕所的各种絮叨。整体风格比较像MySQL的官方文档,如果有想从使用层面从头了解MySQL的同学可以尝试的看看。
《数据库系统概念》(美)Abraham Silberschatz / (美)Henry F.Korth / (美)S.Sudarshan 著
这本书对于入门数据库原理来说非常好,不过看起来学术气味比较大一些,毕竟是一本正经的教科书,里边有不少的公式啥的。
《事务处理 概念与技术》Jim Gray / Andreas Reuter 著
这本书只是象征性的看了1~5章,说实话看不太懂,总是get不到作者要表达的点。不过听说业界非常推崇这本书,而恰巧我也看过一点,就写上了,有兴趣的同学可以去看看。
