@xiaohaizi
2018-03-14T14:09:41.000000Z
字数 13715
阅读 3761
23、字符集与编码
java中级online
上集回顾
上集把面向对象里一个更加抽象的概念接口唠叨了一遍。相信大家通过前边的学习对java语言以及面向对象的概念有了个大致的了解。
从本集开始,将会介绍一些java已经给我们封装好的一些很有用的类以及java语法的一些高级特性。本集先介绍一下我们之后会十分频繁遇到的一个类 --- String的前传 --- 字符集与编码。当然本集的重要性不仅在于去帮助我们理解String类,对我们之后要介绍的正则表达式和java的I/O系统都是很有帮助的。
什么是字符
字符分为两种,一种叫可见字符,一种叫不可见字符。
顾名思义,可见字符就是打印出来后能看见的字符。比如a,b,我,神,。 ... 这样的人眼能看见的单个国家文字、标点符号、图形符号、数字等这样的东东,我们就叫做一个可见字符。
不可见字符也好理解,就是之前打印机或者在黑框框里打印字符的时候有时候需要换行,打个制表符啥的,或者在输出某个字符的时候就发出嘟地一声,这种我们看不到,只是为了控制输出效果的字符叫做不可见字符。
注意,字符都是单个的喔😯!。把字符连起来叫做字符串,比如abc,就是由a、b、c三个字符连起来的一个字符串。
字符集
字符集字面上理解就是字符的集合。但是在计算机系统里提到的字符集是指已编号的字符的有序集合。
我们在这里强调两点:
1. 已编号我们会为字符集合里的每一个字符进行编号,比方说在`ASCII字符集`里,我们给大写子母`A`编号为`65`,给左大括号`{`编号为`123`。另外,不同字符集的编号方式可能是不一样的。注意,我说的是可能!比如你自己发明一种字符集,把大写子母`A`编号为`111`也是可以的,只不过你自己定义的没人承认而已喽😯。2. 有序集合因为所有字符都是被编过号的,把字符按照编号顺序排列,自然就成了有序的。另外,强调一下`集合`。也就是说不同的`字符集`里收录的字符可能是不同的。比方说`ASCII字符集`收录了128个字符,而`GB2312字符集`里收录了7445个字符。
字符编码模型
一个字符集从诞生到真正让计算机使用大致要经历下边5个步骤:
明确包含字符的范围。
这个步骤就是确定
字符集里应该包含哪些字符。比如ASCII字符集收录128个字符,而GB2312字符集收录7445个字符。给步骤
1中确定的字符进行编号。对于字符集中已经确定的字符,想个办法让某个字符和某个数字建立一一对应关系。
因为
ASCII字符集包含的字符较少,只有128个,所以编号方式也简单粗暴,直接每一个字符指定一个0~127的数字,比如给字符A编号为65。但是比较复杂的字符集就会温柔一点,比如GB2312字符集用了区位码的方式来给字符编号,我们稍后详细唠叨各种字符集是怎么编号的。特别注意:本步骤中的
编号是一个纯数学编号,与计算机存储没任何关系。与下边步骤中的编码是两个完全不同的概念!!将步骤
2中的编号确定逻辑上的字符编码。计算机只能认识二进制,要把字符存到计算机里需要把字符
编号映射为二进制数据。这种映射有的是直接把编号映射为二进制数据,有的因为一些原因不能直接映射,采用一些算法来计算出该编号对应的二进制数据。但是用二进制表示
字符需要注意一下这些事:对于一段文本的二进制文件,计算机一次应该读多少位呢?
计算机里是以
字节(8位)为基本处理单位的,所以一次读的位数应该是8的倍数。不同的字符集编码有不同的规定,有的一次读一个字节,有的一次读2个,有的一次读4个。我们把计算机一次读的字节称为
编码单位(英文名叫Code Unit),也叫码元。一个字符应该占几个
码元呢?比如拿
ASCII字符集来说,它一共收录了128个字符,ASCII编码规定1个字节作为1个码元,所以ASCII字符集一个码元就可以表示一个字符。但是有的编码方式一个
码元可能占用好几个字节,而且收录的字符数量也都不同,我们下边具体介绍各种字符集的编码方式时候再具体回答这个问题。
逻辑字符编码的意思就是把步骤2中的字符编号映射为一个二进制数字,并且规定好码元大小。所以一个字符就可以表示成一个或几个码元排列起来的二进制数字,我们称之为码元序列。有的时候为了简便,我们把
逻辑字符编码就简称为编码。对于同一种字符集,因为从
编号映射到二进制数据的方式不同或者采用的码元大小不一样,同一种字符集也可能有多种编码方式。给步骤
3中确定的逻辑上的字符编码生成物理上的字符编码。对于步骤
3确定的二进制数字,是跟特定的计算机系统平台无关的逻辑意义上的编码,那么所谓的物理上的字符编码就是跟特定的计算机系统平台有关的更具体的编码。这个主要是针对`码元`是多个字节的情况,`码元`为单个字节的可以认为步骤3和步骤4是一样的。字节的排列顺序会收到不同系统的影响。我们下边在说多字节`码元`的编码方式的时候仔细说这个问题。
经过物理编码后的二进制序列,我们称之为
字节序列。当然,很多时候
码元序列和字节序列的值是一样的。面向计算机更底层,进行进一步的适应性编码处理。
这一部分涉及计算机硬件怎么优化处理,我们并不需要了解,但是出于礼貌,还是要照抄一下:
。一般包括两种:1. 一种是把字节序列映射到一套更受限制的值域内,以满足传输环境的限制,例如用于Email传输的Base64编码或者quoted-printable编码(可打印字符引用编码),都是把8位的字节映射为7位长的数据(Email协议设计为仅能传输7位的ASCII字符);2. 另一种是压缩字节序列的值,如LZW或者进程长度编码等无损压缩技术。
注意:
需要特别注意的是,我们平时简称的`编码`,如果作为动词来理解的话,可能是执行步骤`3`,也可能是步骤`3`和步骤`4`一块儿执行;如果作为名词来理解的话,也能是步骤`3`执行完一个字符对应的`码元序列`,也可能是步骤`4`执行完的实际的`字节序列`。这个`编码`这个词的含义需要放到上下文中进行理解。但是`编码`和`编号`的区别是明显的!!
具体字符集的编码模型
ASCII字符集
我们知道,计算机这玩意儿是在人家美国🇺🇸发明的。ASCII的意思是 American Standard Code for Information Interchange,翻译过来就是:美国信息交换标准代码。
收录字符范围
只收录了128个字符,具体是哪些后边会有一张图展示。字符编号
美国大爷们用0~127为这128个字符做了编号,其中:他们把
0~31以及127用作了特殊的用途,这些字符是打印不出来的,也就是我们看不到的,所以被称为不可见字符或者控制码。比如
10,是换行的意思,程序里遇到这个字符就会换一行输出;比如7,是代表震动,如果我们直接在程序里输出了这个字符,程序会发出嘟嘟叫的声音🔊。然后用
32~126来描述空格、标点符号、数字、大小写字母。比如
65用来代表大写的'A',123来代表左大括号{。
逻辑编码
采用了单字节作为
码元的大小,简单粗暴的把编号映射为二进制数据。比如我们随便敲一行英文字母(包括了3个英文字符):
LMN
我们可以查到:
L 对应 76 (二进制数是:1001100)M 对应 77 (二进制数是:1001101)N 对应 78 (二进制数是:1001110)
又因为一个
码元是一个字节(8个位)的,不够8个位的在高位补0。所以LMN这个文本应该被编码成下边的样子(为了大家看的方便,我把每个字节间加了个空格,实际是木有的):01001100 01001101 01001110
然后计算机在读这串二进制数据的时候会按8位拆分,所以
解码过程就是:- 先读
01001100,识别出这是一个L字符。 - 再读
01001101,识别出这是一个M字符。 - 再读
01001110,识别出这是一个N字符。
所以可以在读完这一串二进制数据后可以在显示器上显示出
LMN。二进制对人类不友好,看的眼瞎,上边的二进制代码转换成十六进制就是这样的:
4c4d4e
物理编码
由于是单字节编码,所以
字节序列和码元序列是一样的。
下图就是ASCII字符集的高清全图,大家具体可以看一下每一个数字都代表着哪个字符:
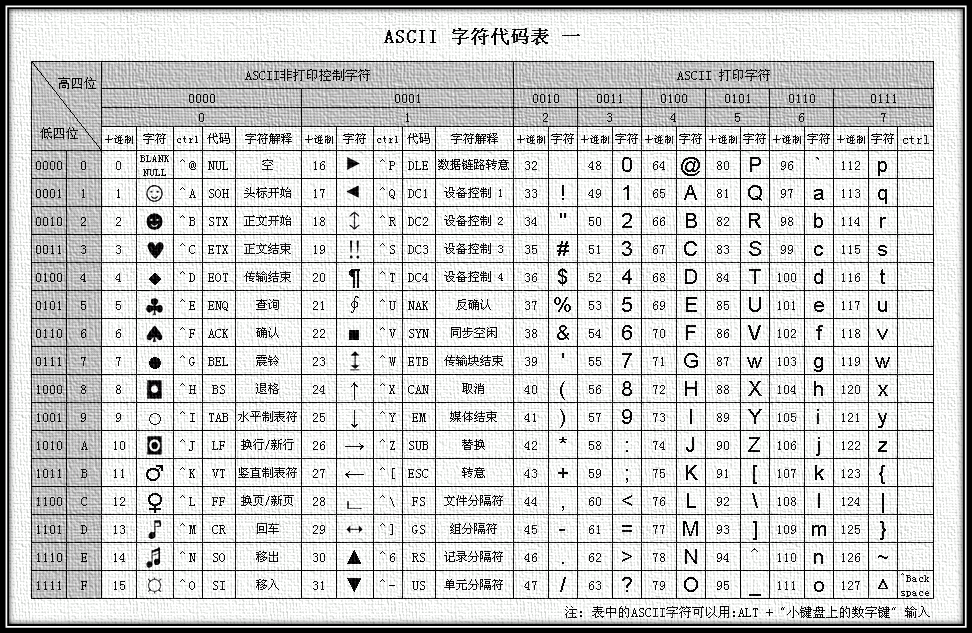
注意,一定要区分一下下边这两个概念:
`ASCII字符集`:就是带`编号`的字符的集合。`ASCII编码`:其实这是`对ASCII字符集中的字符按照编号进行编码`的简略称呼。
ISO 8859系列字符集
注意,我们用的是系列这个词,意味着其实有好多字符集。
其实ISO 8859系列字符集包括15个字符集,即ISO 8859-n,其中n=1,2,3,...,15,16(其中12未定义,所以共15个)。
之所以把这15个字符集放在一块来说,是因为它们本质上都是ASCII字符集的一个扩展。都除了收录的字符有些不一样外,其他的编码方式啥的都是一样的。
收录字符范围
除了ASCII字符集中包含的字符外,每个字符集都扩充了96个字符。字符编号
ASCII字符集中的字符编号维持不变,新增加的字符在160~255这个范围里编号。编码(逻辑编码和物理编码是一样的,就合并了)
由于字符数量仍然没有超过256个,所以仍然像ASCII字符集的编码方式一样,采用了单字节作为码元的大小,简单粗暴的把编号映射为二进制数据。由于和
ASCII字符集编码方式是一样的,这里就不举例子。
在ISO 8859系列字符集中,我们经常使用ISO 8859-1这个字符集,这个字符集比ASCII字符集多收录了一些西欧常用字符(包括德法两国的字母),这个ISO 8859-1字符集还有一个别名,叫做Latin-1。
下边看一下ISO 8859-1字符集收录的全部字符的编码:
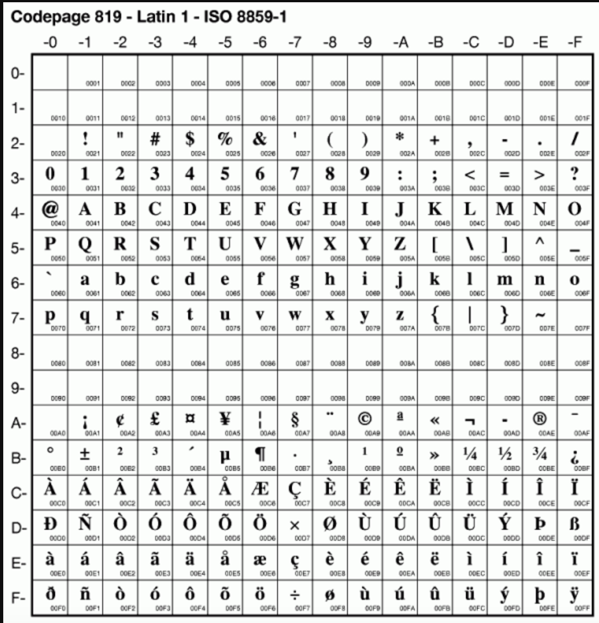
这个`ISO 8859系列字符集`中各个字符集不同的地方就是比`ASCII字符集`多收录的94个字符是不一样的,下边我们大致列举一下除`ISO 8859-1字符集`之外的字符集多收录的这94个字符是什么字:ISO 8859-2字符集,也称为Latin-2,收录了东欧字符;ISO 8859-3字符集,也称为Latin-3,收录了南欧字符;ISO 8859-4字符集,也称为Latin-4,收录了北欧字符;ISO 8859-5字符集,也称为Cyrillic,收录了斯拉夫语系字符;ISO 8859-6字符集,也称为Arabic,收录了阿拉伯语系字符;ISO 8859-7字符集,也称为Greek,收录了希腊字符;ISO 8859-8字符集,也称为Hebrew,收录了西伯莱(犹太人)字符;ISO 8859-9字符集,也称为Latin-5或Turkish,收录了土耳其字符;ISO 8859-10字符集,也称为Latin-6或Nordic,收录了北欧(主要指斯堪地那维亚半岛)的字符;ISO 8859-11字符集,也称为Thai,从泰国的TIS620标准字符集演化而来;ISO8859-12字符集,目前尚未定义(未定义的原因目前有两种说法:一是原本要设计成一个包含塞尔特语族字符集的“Latin-7”,但后来塞尔特语族变成了ISO 8859-14 / Latin-8;二是原本预留给印度天城体梵文的,但后来却搁置了);ISO 8859-13字符集,也称为Latin-7,主要函盖波罗的海(Baltic)诸国的文字符号,也补充了一些被Latin-6遗漏的拉脱维亚(Latvian)字符;ISO 8859-14字符集,也称为Latin-8,它将Latin-1中的某些符号换成塞尔特语(Celtic)的字符;ISO 8859-15字符集,也称为Latin-9,或者被戏称为Latin-0,它将Latin-1中较少用到的符号删除,换成当初遗漏的法文和芬兰字母,还把英镑和日元之间的金钱符号,换成了欧盟货币符号;ISO 8859-16字符集,也称为Latin-10,涵盖了阿尔巴尼亚语、克罗地亚语、匈牙利语、意大利语、波兰语、罗马尼亚语及斯洛文尼亚语等东南欧国家语言。
GB2312字符集
可恶的美帝根本没有考虑中国人民以及广大第三世界人民使用计算机的感受。于是中国计算机科学家决定自己设计一种字符集。
收录字符范围
它收录了汉字以及拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母。其中收录汉字6763个,其他文字符号682个。注意,
GB2312字符集并没有收录ASCII字符集中的字符哦。字符编号
由于GB2312字符集收录的字符太多,所以暴力编号不好管理,就提出了一个分区的概念。就像下图这样: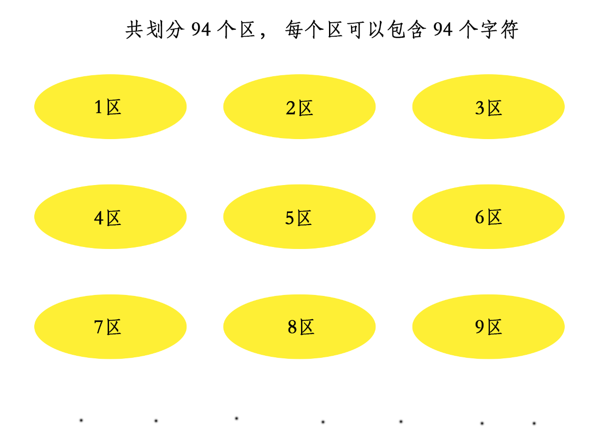
如上图,每一个黄色的椭圆块可以代表一个
分区,简称区。一共设计了94个区(01-94),每个区可以放94个字符(01-94)。所以定位某一个字符的方式就是在第几分区的第几位字符。比如汉字
啊,这个字被放在了第16区的第1位,所以啊对应的数字就是1601。因为是按第几区的第几位来划分,所以也叫区位码,就可以说啊字对应的区位码是1601。其实所谓的`区`和`位`,本质上和`行`和`列`是一样一样的。一个分区就代表一行,一位就代表一列。第几区第几位的意思就是第几行第几列。
哪个
分区放什么样的字符都是规定好的,有的分区也没有放东西,就空在哪。各个分区都储存了哪些字符:01-09区为特殊符号,字符包括特殊符号、数字、英文字符、制表符等,包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母等10-15区没有编码,为了以后新加入字符来扩展16-55区为一级汉字,也就是常用的汉字,按拼音排序,共3755个56-87区为二级汉字,也就是非常用汉字,按部首/笔画排序,共3008个88-94区没有编码,留着给以后扩展
由于字符太多,不能完全表示,所以截取一部分来给大家看看:
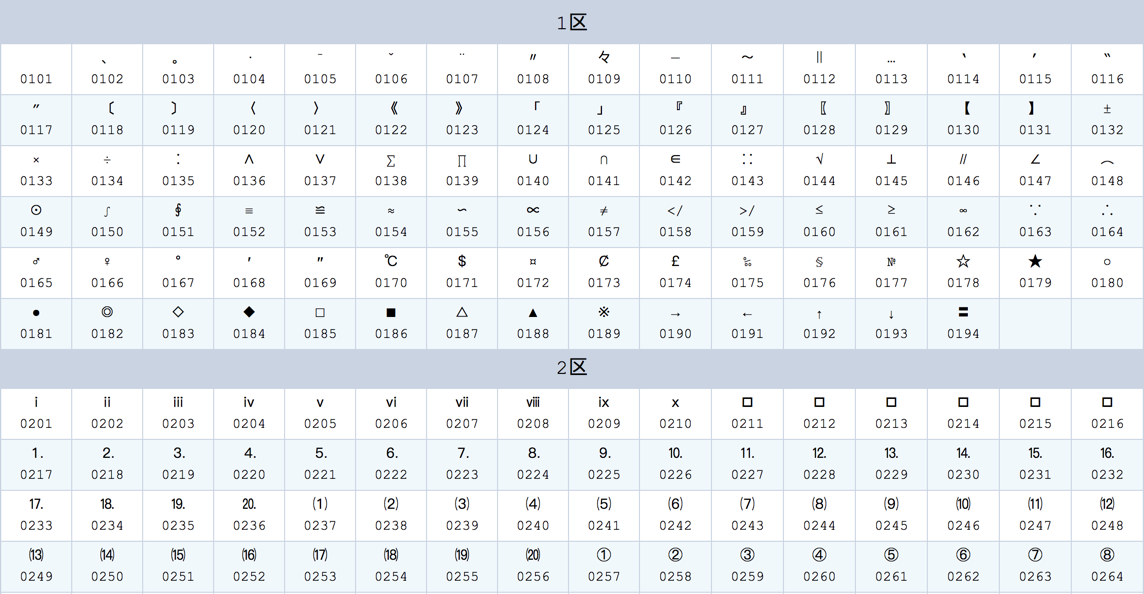
如果大家想查看某个汉字的
区位码或者查看完整区位码的图,可以到这里:GB2312区位码查询与转换编码
在对GB2312字符集进行编码前我们需要正视这个问题:`GB2312字符集`并没有收录`ASCII字符集`中的字符,如果一个英文字母出现在文本里该怎么编码成二进制数据。
我们在说
GB2312编码的意思其实是表达了这么两重意思:1. 如果该字符在`ASCII字符集`中,就按照`ASCII编码`的方式进行编码。2. 如果该字符在`GB2312字符集`中,就按照`GB2312编码`的方式进行编码。`解码`就是`编码`的逆过程。
有了上边的说明,我们再回来给
GB2312字符集中的字符进行编码的话题。我们最初的想法是:
像
ASCII字符集的编码方式一样,直接把GB2312字符集的编号,也就是区位码来当作编码。拿我的姓
王举个栗子,王字在第45区第85位,区位码就是4585,转换成二进制就是:10001 11101001
如果用两个字节来表示就是:
00010001 11101001
但是在计算机读这一串二进制数据时,比如它读到了第一个字节
00010001(十进制是17),它怎么区别这是王字的编码一部分,还是ASCII编码中的第17号字符呢?答案就是没法区分。但是我们知道
ASCII编码只用了一个字节中的0~127,其中的128~255是没有用到的,所以我们给编码后的每个字节都加128(二进制是10000000)这样就不会出现单个字节小于128的情况喽!试试:00010001+ 10000000____________10010001
11101001+ 10000000____________01101001(进位舍去)
高字节
00010001加128之后没问题,但是低字节11101001加128后出了个大问题,他俩的和超过255了,所以只能把进位舍去,结果又成了低于128的值了。显然,这样把各个字节都直接加
128还是不靠谱的。因为我们不能保证每个字节的值都小于128,所以不能保证加完后的和小于或等于255。为了解决这个问题,我们又提出了另一个方案:
不直接把
区位码映射为编码,而把区号作为一个字节,把位号作为另一个字节。这样王字的区位号4585就可以看作45和85的拼装,然后把45和85分别转为一个字节:00101101(十进制45)01010101(十进制85)
拼起来就是:
00101101 01010101
但是这样做仍然有和
ASCII编码分不清的问题。所以需要把每个字节都加上127:
45 + 127 = 172(二进制10101100); 85 + 127 = 212(二进制11010100);所以拼接而成的结果就是:
10101100 11010100
这种拼装就没有和大于`255`的情况么?别忘了我们的两个字节是怎么生成的,每个字节的值其实是区号或者位号。我们前边说过我们一共有94个区,每个区最多有94个字符,所以字节最大值就是94,`94`和`128`相加肯定不会大于`255`呀~
你以为
2就是终极编码版本?才不是呢。因为区码范围在
1-94之间,位码也在1-94之间。所以理论上只要给区码,位码加在127~161区间的数就可以避免与ASCII编码冲突了。但是最后决定给
区码和位码都加160。为什么是160呢?我都说了在`127~161`的数都可以,不信你试试。
最后结论也就是
GB2312编码过程就是把区位码的区码和位码都加160,然后拼成两个字节。比如
王字的区位号4585,就把45和85都加160:45 + 160 = 205 (二进制`11001101`)85 + 160 = 245 (二进制`11110101`)
所以最后拼成最后的编码就是:
11001101 11110101
转成十六进制就长这样:
CDF5
最后总结一下就是:所谓
GB2312编码包含两个部分:1. 如果该字符在`ASCII字符集`中,就按照`ASCII编码`的方式进行编码。2. 如果该字符在`GB2312字符集`中,就按照`GB2312编码`的方式进行编码。
对于
GB2312中的字符进行编码是这个过程:把`区位码`的区码和位码都加`160`,然后拼成两个字节
解码过程就是上边编码的逆过程。再举个完整点的栗子,比如我们有这样一段文本:
我爱u
然后用
GB2312编码来编码这段文本的过程就是:我对应的区位码是4650,编码后的十六进制是CED2,也就是二进制:1100111011010010。爱对应的区位码是1614,编码后的十六进制是B0AE,也就是二进制:1011000010101110。u是ASCII字符集字符,编码后是75,二进制就是:01001011。- 拼合起来的结果就是:
1100111011010010101100001010111001001011
十六进制表示就是:
CED2B0AE4B
然后计算机在
解码这段二进制数据时的过程就是:- 读一个字节
CE,发现它大于127,所以这是一个两个字节的字符,所以连续读了两个字节CED2,在编码表里查到这是汉字我。 - 接着再读一个字节
B0,发现它大于127,所以连续读了两个字节B0AE,在编码表里查到这是汉字爱。 - 接着再读一个字节
4B,发现它小于127,所以在ASCII码表里查到这是英文子母u。
栗子讲完了。
由于
GB2312字符集收录的字符太多,所以只展示一点,大家看明白就好:
全部的
GB2312字符集大家可以参考GB2312简体中文编码表
GBK和GB18030字符集
有了GB2312大家很高兴,但是没过多久大家就发现中国字太多了,连中国前总理朱镕基的"镕"字都没有收录。
GBK字符集就是在GB2312的基础上,对它收录的字符做了一个扩充,共收录 21886 个汉字和图形符号。
GB18030字符集在GBK的基础上又做了个扩充,收录汉字70244个。
它们的和GB2312属于同祖同宗,就不介绍它们的字符编码模型了~
Big5字符集
又称大五码或五大码,宏碁(Acer)、神通(MiTAC)、佳佳、零壹 (Zero One)、大众 (FIC)创立,故称大五码。是台湾同学发明的。具体的字符编码模型我们也不需要了解哈~
unicode字符集
世界上像中国这样定义字符集的国家有很多,所以各国人民商量了一下,发布了一个文件,叫The Unicode Standard,这个文件废除了ASCII字符集以外的所有字符集,定义了一个大家都通用的字符集,就是Unicode字符集。
收录字符范围
收录地球上能想到的所有字符,而且还在不断扩充。字符编号
因为收录的字符太多,而且还可能不断地添加新字符,暴力编号显然不便于管理。所以Unicode字符集设计者们提出了一个平面(英文名叫Plane)的概念。
一共设计了17(编号从
0~16)个平面,每个平面可以包含65536(0~65535)个编号。各个平面的编号范围见下图(十六进制表示):
在这设计的17个平面中,其中第0个平面是包含了当前世界上最常用的一些字符。所以这第0个平面也叫做
BMP(英文Basic Multilingual Plane的缩写),翻译过来就是基本多语言平面。它是我们最经常用到的。我们在说某个
unicode字符集中的字符的编号的时候通常会用下边的这种方式:U+十六进制编号
举个栗子,
王字的十六进制编号是738B,所以我们就写成:U+738B
这个
U+738B就代表一个unicode字符的编号。另外,
unicode字符集的编号兼容了ASCII字符集的编号和ISO 8859-1字符集的编号。unicode字符集中的U+0000~U+007F(即十进制的0~127)与ASCII字符集是一致的,U+0000~U+00FF(即十进制的0~255)与ISO 8859-1字符集(Latin-1字符集)也是一致的。比如大写字母A的编号都是65,左大括号{的编号都是123。下边截图列出一部分汉字的
unicode编号,注意是用十六进制表示的: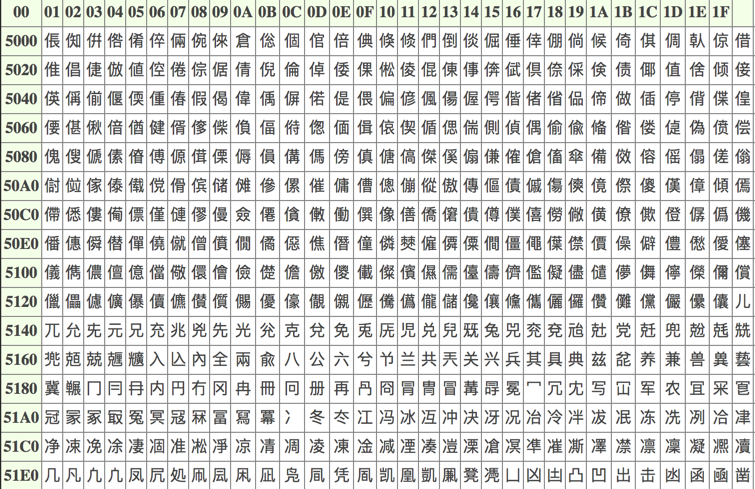
逻辑编码
先纠正一个问题,很多人认为unicode字符集本身就是一种编码方式,占了2个字节,这种说法是错误的。字符集和编码方式是两个完全不同的概念。我们平常说的unicode值指代的是字符的编号,而不是编码。在谈到编码方式的时候不得不再次强调一下
码元的概念,我们说码元的大小就是计算机一次读取字节的大小。给
unicode字符集编码的时候目前码元大小有1个字节、2个字节、4个字节这么三种情况,分别对应的编码方式是UTF-8、UTF-16、UTF-32这三种,下边我们分别分析:1. UTF-8逻辑编码方案
这种编码方案的
码元采用一个字节。但是一个字节最多只能表示256个字符,所以有的字符需要多个字节来表示,但这就产生了一个问题:计算机如何区分哪个字符是用一个`码元`(此处是1字节)表示,哪个字符使用多个`码元`表示的?
UTF-8编码是用首字节的开头几位来辨别是用几个字节编码的:1. 如果首字节以0开头,肯定是单字节编码(单个码元);2. 如果首字节以110开头,肯定是双字节编码(2个码元);3. 如果首字节以1110开头,肯定是三字节编码(3个码元)。... 以此类推另外,如果某个字符是由多个字节编码的,那除了首字节外,其余字节都需要用10开头,以区别单字解释编码和多字节编码的首字节。上边字节的首字母0、110、1110以及10相当于UTF-8编码中各个字节的前缀,因此称之为`前缀码`。其中,前缀码110、1110及10中的0,是前缀码中的`终结标志`。这些`前缀码`只是用来标记的,不用来代表真实的字符编号。所以其实真正有效的用来代表`unicode字符`真实的字符编号的位数是:1. 单字节中有效编码位数是7位(除去首字节前缀0)2. 双字节中有效编码位数是11位(除去首字节前缀110和第二字节的前缀10)3. 三字节中有效编码位数是16位(除去首字节前缀1110和第二、三字节的前缀10)... 依次类推
用表格表示一下就是这样的:
描述 有效编码位数 高位字节 低位字节 低位字节 低位字节 低位字节 单字节编码 7 0xxxxxxx 双字节编码 11 110xxxxx 10xxxxxx 3字节编码 16 1110xxxx 10xxxxxx 10xxxxxx 4字节编码 21 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx 5字节编码 26 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx ... 所以我们对某个
unicode字符进行编码的时候,就可以这么办:查看该
unicode字符对应的编号位数,查看它应该采用几个字节来进行编码。选取好用几个字节来进行编码后,采用上表的模版,保持前缀不变,把字符编号填到非前缀位上,高位用0补足即可。
举个栗子,比如字符
u,它的编码过程是:u的unicode编号是117(二进制1110101),占7个位,所以用1个字节编码就够了。- 采用1字节编码模板
0xxxxxxx,把里头的xxxxxx替换成1110101就好了。
所以
u字符的UTF-8的编码结果就是:01110101
再比如汉字
啊,它的编码过程是:啊的unicode编号是21834(二进制101010101001010`),占15个位,需要用15个字节编码。所以采用3字节编码模板
1110xxxx 10xxxxxx 10xxxxxx,把二进制数据填进去,高位补0。
所以
啊字符的UTF-8的编码结果就是(字节之间的空格是方便我们阅读,实际是没有的,下边就不强调这个了):11100101 10010101 10001010
用友好一点的十六进制表示就是:
E5958A
2. UTF-16逻辑编码方案
这种编码方案的
码元采用2个字节。我们知道
unicode字符集基本多语言平面(也就是第0平面),编号范围是:0 ~ 65535(十六进制:0xFFFF)。其余的16个平面(1~16平面)编号范围为:65536~1114111(十六进制:0x10000~0x10FFFF)。但是2个字节最多只能表示65536个字符,所以1个两字节的
码元最多只能直接表示基本多语言平面的编号,所以在表示其余的16个平面的字符时需要用多个码元。所以UTF-16编码方案和UTF-8编码方案一样,也会有这个问题:计算机如何区分哪个字符是用一个`码元`(此处是2字节)表示,哪个字符使用多个`码元`表示的?
UTF-16提出了一个代理区的概念来解决这个问题。他们规定基本多语言平面的
56320 ~ 57343(十六进制0xDC00 ~ 0xDFFF)这个区间的编号为代理区,这个区间的编号并不对应字符。有了
代理区的概念之后,UTF-16提出的完整解决方案就是:1. 对于基本多语言平面(也就是第0平面)中不属于`代理区`编码的字符,使用一个码元(2字节),编号直接映射为字符编码。2. 对于第1~16平面,采用两个码元来进行编码,具体编码原理见下文。1). 第一个码元的取值范围是0xD800~0xDBFF(二进制为`11011000 00000000` ~ `11011011 11111111`,十进制为55296 ~ 56319),第二个码元的取值范围为0xDC00~0xDFFF(二进制为1101 1100 0000 0000 ~ 1101 1111 1111 1111,十进制为56320 ~ 57343)。2). 根据第1)步确定的码元的取之范围,可以得出它的二进制表现形式:`110110pp ppxxxxxx 110111xx xxxxxxxx`可以看到,它的有效编码位数只有20位,其中4位`pppp`代表该编码所在平面(1~16),16位`xxxxxxxxxxxxxxxx`代表在该平面的位置。然后这有效编码位数的20位一共可以表示2的20次方,也就是1048576个编码,正好把16个平面的字符都表示完。
看下怎么对字符
u进行UTF-16编码:u字符的unicode编号是117(二进制1110101),这个编号小于65536,在基本多语言平面中,所以采用直接将编号转为编码的方式进行编码,但是码元是两字节的,所以高位补0就行。字符
u的UTF-16的编码结果就是:00000000 01110101
注意:
UTF-16编码最少采用2个字节,导致了像英文字母这样在0~127编号的字符也得用2个字节编码。而UTF-8只需要1个字节来编码0~127编号的字符。所以UTF-16在编码0~127编号的字符的时候会比UTF-8浪费。
再看
啊字的栗子:啊的unicode编号是21834(二进制101010101001010),这个编号小于65536,在基本多语言平面中,所以采用直接将编号转为编码的方式进行编码,但是码元`是两字节的,所以高位补0就行。字符
啊的UTF-16的编码结果就是:01010101 01001010
我费了老大劲找了个生僻汉字
𨢻,看他的编码过程:𨢻的unicode编号是166075(二进制101000100010111011),这个编号不小于65536`,在第2平面中,所以到第二步来处理。- 根据
110110pp ppxxxxxx 110111xx xxxxxxxx这个式子,因为在第2平面中,所以pppp对应的二进制就是0010,这个字在第2平面的第60514(二进制1110110001100010)位,所以xxxxxxxxxxxxxxxx就可以被替换成1110110001100010。
所以字符
𨢻的UTF-16的编码结果就是:11011100 10111011 11011000 01100010
3. UTF-32逻辑编码方案
这种编码方案的
码元采用4个字节。因为整个
unicode字符集目前编码范围是17个平面,每平面65536个编号,所以一共是1114112个数。4个字节就可以表示4294967296个数,所以使用一个码元(4字节)就可以表示所有的编号喽。比如
u字符,u字符的unicode编号是117(二进制1110101),所以就直接被编号为:00000000 00000000 00000000 01110101
再看
𨢻字符,它的unicode编号是166075(二进制101000100010111011`),所以就直接被编号为:00000000 00000001 01000100 010111011
物理编码
在谈这个之前需要介绍一下字节序的概念。字节序(Byte-Order)就是指存放多字节数据的字节(byte)的顺序。什么叫`多字节数据`?`多字节数据`就是计算机在读取二进制数据时一次要读好几个字节。比如我们之前介绍java的数据类型中,`short`就是一次要读四个字节,`int`就是一次要读四个字节,`long`就是一次要读8个字节。`short`、`int`和`long`类型的数据就是`多字节数据`。但是比如`byte`类型的数据就不是`多字节数据`。
如果数据都是单字节的,那怎么存储无所谓了。字节序是硬件层面的东西,对于软件来说通常是透明的,但是我们现在就是要说明白怎么储存,没办法,硬着头皮看吧~。
比方说我们在java代码里定义了一个
int类型的十六进制值:int i = 0xaabbccdd; //二进制数据就是 10101010 10111011 11001100 11011101
那么左边的
0xaa(10101010)就是高字节,当然这个高低是相对的,比如0xbb和0xcc相比是高字节,0xcc和0xdd相比也是高字节,0xbb和0xdd相比是高字节。现在我们可以根据变量
i这货在内存里到底是怎么放的来定义大端序(Big-Endian)和小端序(Little-Endian)喽。大端序(Big-Endian)就是高字节存放在地址的低端 低字节存放在地址高端。就是这样:
写出来就是:0xaabbccdd
小端序(Little-Endian)就是高字节存放在地址的高端 低字节存放在地址低端。就是这样:
写出来就是:0xaabbccdd
也就是说,如果
i变量在内存里的顺序是0xaabbccdd的话,这种书写方式就是大端序。如果
i变量在内存里的顺序是0xddbbccaa的话,这种书写方式就是小端序。如果怕记不住的话,可以这么理解:
`大端序`就是按照人类理解的顺序进行存储的,从左至右,从高字节到低字节。`小端序`就是按照反人类理解的顺序进行存储的,从左至右,从低字节到高字节。
一些操作系统比如Windows、FreeBsd、Linux是采用Little-Endian的;一些操作系统比如Mac OS是采用Big-Endian的。
有了
大端序、小端序的概念之后,我们再看码元大于一个字节的编码方式的具体不同:UTF-16Be编码
就是
UTF-16的逻辑编码。就是说高字节在左边,低字节在右边。比如
啊字的UTF-16Be编码就是:01010101 01001010
转成十六进制就是:
554A
UTF-16Le编码
就是
UTF-16的逻辑编码采用小端序的字节序列。就是说高字节在右边,低字节在左边。比如
啊字的UTF-16Le编码就是:01001010 01010101
转成十六进制就是:
4A55
UTF-32Be编码和UTF-32Le编码
与上边的
UTF-16Be编码和UTF-16Le编码是一样的意思。文件头加表明字节序的字符
因为有
大端序和小端序之分,所以在采用UTF-16和UTF-32编码时需要在文本文件开始指定使用大端序还是小端序。指定方式如下:如果是
大端序编码,需要在文件开始加一个字符U+FEFF。当然,UTF-16编码会把这个字符编码成2个字节,UTF-32编码会编码4个字节。如果是
小端序编码需要在文件开始加一个字符U+FFFE。当然,UTF-16编码会把这个字符编码成2个字节,UTF-32编码会编码4个字节。注意,有的windows程序,比如记事本啥的,在采用`UTF-8`编码的时候,会在文件开头加上一个`U+FEFF`字符,编码值是`0xEFBBBF`(十六进制)。但是`UTF-8`是没有字节序一说的,windows没事找事添加的,大家知道就行了,如果用记事本敲代码导致了出错,就往编码这想想。
总结
字符集和编码是两个概念!!!!!!!!!!
总结完了。
题外话
真累啊!
本集只是字符集的一个Introduction,想了解更多知识,到这里看:刨根究底学编程,这片文章介绍非常仔细,收益匪浅,大家如果有闲钱可以去赞赏一下链接里的作者。
