@xuchongfeng
2018-01-06T12:58:35.000000Z
字数 3933
阅读 146
决策树
机器学习 决策树
决策树模型
分类决策树模型是一种描述对实例进行分类的树形结构。决策树由节点node和有向边directed edge组成。节点有两种类型:内部结点internal node和叶结点leaf node。内部结点表示一个特征或属性,叶节点表示一个类。
决策树的学习:
假设给定训练数据集
其中为输入实例,为特征个数,为类标记,为样本容量。
特征选择
信息增益
熵entropy表示随机变量不确定性的度量,设是一个取有限个值得离散随机变量,其概率分布为
则随机变量的信息熵定义为:
设有随机变量,其联合概率分布为
条件熵表示已知的情况下的不确定性
信息增益表示得知的信息而使得的信息的不确定性减少的程度
信息增益越大,说明对的分类能力很强。
符号定义:
数据集,为样本容量,
为类个数,
表示类别为的样本个数,则有
设特征有个不同的取值,根据的取值将划分为个子集
为样本个数,
设子集中属于类的样本的集合为,即,为为样本个数。
信息增益
输入:训练数据集和特征
输出:特征对训练数据集的信息增益
1) 计算数据集的经验熵
2) 计算特征对数据集的经验条件熵
3) 计算信息增益
信息增益比
由于信息增益并不能绝对的横向比较,因为对于取值比较多的特征,信息增益会比取值少的特征更大。所以使用信息增益比的概念。
决策树的生成
ID3算法
输入: 训练数据集, 特征集,阈值。
输出:决策树
1)若中所有实例属于同一类,则为单结点树,并将类作为该结点的类标记,返回;
2)若,则为单结点树,并将中实例数最大的类作为该结点的类标记,返回;
3)否则,计算中各个特征对的信息增益,选择信息增益最大的特征;
4)如果的信息增益小于阈值,则设为单结点树,并将中实例数最大的类作为该结点的类标记,返回;
5)否则,对的每一可能值,依将分割为若干非空子集,将中实例数最大的类作为标记,构建子结点,由结点及其子结点构成树,返回;
6)对第个子结点,以为训练集,以为特征集,递归地调用1-5步,得到子树,返回。
c4.5生成算法
选择特征时,使用信息增益比 替换 信息增益;
决策树的剪枝
决策树的生成容易过拟合,那么需要进行剪枝。
损失函数的定义
设树的叶结点个数为,为树的叶节点,该叶结点有个样本点,其中类的样本点有个,为叶节点上的经验熵,为参数,则决策树学习的损失函数可以定义为
可以调整树的复杂度,较小的偏向于选择较复杂的模型。决策树生成只考虑通过提供信息增益(信息增益比)对数据实现更好的拟合,而决策树剪枝通过优化损失函数减低模型复杂度。
树的剪枝算法
输入:生成算法产生的整个树,参数
输出:修剪后的子树
1)计算每个结点的经验熵;
2)递归地从树的叶结点向上回缩
设一组叶结点会缩到其父结点之前与之后的整体树分别为和,其对应的损失函数值分别为与,如果
则进行剪枝,即父结点变为新的叶结点。
3)返回2),直至不能继续为止,得到损失函数最小的子树
CART算法
分类和回归树classification and regression tree,CART。
CART算法由一下两步组成:
1)决策树生成:基于训练数据集生成决策树,生成的决策树要尽量大;
2)决策树剪枝:用验证数据集对已生成的树进行剪枝并选择最优子树,此时以最小损失函数最小作为剪枝的标准。
CART生成
回归树的生成
为输入变量,为输出变量,并且是连续变量,给定训练数据集
假设将输入空间划分为个单元,并且在每个单元上有一个固定输出值。
回归树模型
训练误差
同时单元中的的最优值为
采用启发式的方式对输入空间 选择第个变量和它取的值,作为切分变量splitting variable和切分点splitting point,则区域被切分为两个
然后寻找最优切分变量和最优切分点。
即求解
最小二乘回归树
输入:训练数据集;
输出:回归树;
1)选择最优的切分变量和切分点,求解:
2)对选定的对划分区域并决定相应的输出值:
3)继续对两个子区域调用步骤1,2,直至满足停止条件;
4)将输入空间划分为个区域,生成决策树:
基尼系数
在分类问题中,假设有个类,样本点属于第个类的概率为,则概率分布的基尼系数为
基尼系数值越大,说明样本集合的不确定越大。
对于二分类问题,。
import matplotlib.pyplot as pltimport numpy as np%matplotlib inlinex = np.arange(0, 1, 0.0001)plt.plot(x, np.where(x <= 0.5, x, 1-x), label="分类误差率")plt.plot(x, 2 * x * (1 - x), label="基尼系数")plt.plot(x, - 1/2 * (x * np.log2(x) + (1-x) * np.log2(1-x)), label="熵之半")plt.legend((u"classification error rate", u"gini rate", u"half entropy"))plt.show()
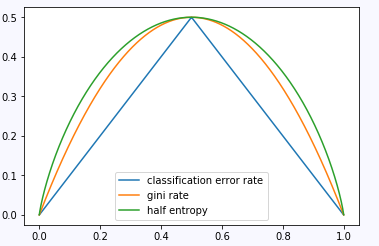
CART生成算法
输入:训练数据集,停止计算的条件;
输出:CART决策树
1)设结点的训练数据集为,计算现有特征对该数据集的基尼系数。此时对每一个特征,对其可能取的每个值,根据样本点对的测试将集合分为两个集合:和,并计算基尼系数;
2)选择基尼系数小的切分点a进行切分;
3)对子结点递归地调用1,2,直到满足停止条件;
4)生成CART决策树。
停止条件可以设置叶子节点中样本个数的阈值,或者基尼系数的阈值
CART算法的剪枝
