@xuchongfeng
2018-01-13T13:38:57.000000Z
字数 3553
阅读 132
MapReduce: Simplified Data Processing on Large Clusters
paper-reading distributed-system 6.824 map-reduce
摘要
MapReduce是一个处理和生成大数据集的编程模型和实现。用户可以编写map函数生成一个中间结果的k/v对,编写reduce函数合并中间结果中有相同k的值。在实际环境中,很多任务可以用该模型表达。
使用该函数模型的程序会在一个普通集群中并发的执行,运行系统负责处理输入数据的分片,调度程序在集群中的执行,处理机器故障的问题。这使得没有并发和分布式系统经验的程序员可以使用整个分布式系统的资源。
mapreduce的实现运行在一个商业机器的集群中,是高度可扩展的,一次典型的mapreduce计算通常在集群中处理TB级别的数据。程序员发现系统非常好用:几百个程序已经创建,对应的是几千个任务在集群中运行。
简介
过去5年时间里,google的程序员实现了很多特定目的的计算过程用来处理原始数据。用于计算过程的原始数据包括被爬取的文档,网络请求日志等。为了计算各种统计数据,例如:倒排索引,文档的图结构的不同表示方式,每个站点爬取到的页面数的总和,某一天做多的查询,等等。每一种这样的计算在概念上是很直接的。但是,输入数据通常很大,为了在合理的时间内完成计算任务,计算需要分布在几百台机器上。如何并行化计算,分布数据,以及处理故障使得原本简单的问题变得复杂,需要大量复杂的代码处理这一类问题。
为了处理这样的复杂性,我们设计了一套新的抽象方案,这个方案允许我们只表达简单的计算过程,而隐藏了背后的并行化,数据分布,以及负载均衡。我们的抽象是受lisp等函数式编程语言中map和reduce函数激发。我们的计算过程中涉及对每个逻辑记录使用map函数生成中间结果kv对,之后对kv对中的相同k使用reduce函数。这个模型可以很轻松的并行化处理任务,同时进行再次执行为故障容忍提供保障。
这项工作的主要贡献在于通过一个简单完美的接口,就可以在普通集群中高效的并行化的分布式的处理数据。
编程模型
计算过程是输入是一个kv集合,输出是kv集合。mapreduce库的使用者只需要定义map函数和reduce函数即可。
map将输入的kv对转化为中间结果,也是kv对。mapreduce库会将中间结果中同一key值的对I发送给reduce函数。
reduce接收到I之后,将I中的value进行合并形成一个更小集合,通常reduce输出一个结果或者不输出结果。中间结果通过迭代器的方式提供给reduce任务,这样可以解决value列表过大而导致内存不够的问题。
2.1 示例
考虑一个在很多文档中计算每个单词出现次数的问题,使用者可以使用类似以下的伪代码:
map(String key, String value):// key: document name// value: document contentsfor each word w in value:EmitIntermediate(w, "1")reduce(String key, Iterator values):// key: a word// values: a list of countsint result = 0;for each v in values:result += ParseInt(v)Emit(AsString(result));
map函数生成(k, 1),reduce函数将相同k值的进行合并。
同时用户也需要指定mapreduce对象的输入输出文件的名字,以及可调的参数。用户之后调用mapreduce函数,并将之前的对象传递给它。用户的代码会和mapreduce库一起编译。
2.2 类型
虽然在上节中的数据都是字符串,理论上用户指定的map和reduce函数是可以有不同类型的。
map (k1, v1) -> list(k2, v2)reduce (k2, v2) -> list(v2)
库内使用的类型是字符串类型,用户可以对字符串类型进行转换。
更多示例
分布式grep:
map(String document, String fileLines, String grep)for line in fileLiens:if grep.match(line):Emit(document, line)reduce (String key, Iterator values)result = []for value in values:result.append(value)Emit(result)
URL访问频率的计算
map(String log, String urls):// log: document name// urls: url namefor each url u in urls:EmitIntermediate(u, "1")reduce(String url, Iterator values):// url: a url// values: a list of countsint result = 0;for each v in values:result += ParseInt(v)Emit(AsString(result));
倒排网络连接图:
map(String source, String targets):for target in targets:EmitIntermediate(target, source)reduce(String target, Iterator sources):result = list()for source in sources:result.append(source)Emit(result)
站点词数组
map(String hostname, String terms):EmitIntermediate(hostname, terms)reduce(String hostname, Iterator termVectors, Int frequency)termVectorResult = {}for termVector in termVectors:termVectorResult.merge(termVector)for <w, f> in termVector:if f < frequency:termVectorResult.remove(<w, f>)Emit(termVectorResult)
倒排索引
map(String documentId, String content):for word in content:EmitIntermediate(word, documentId)reduce(String word, Iterator documentIds)result = list()for documentId in documentIds:result.append(documentId)Emit(result)
分布式排序
实现
执行过程综述
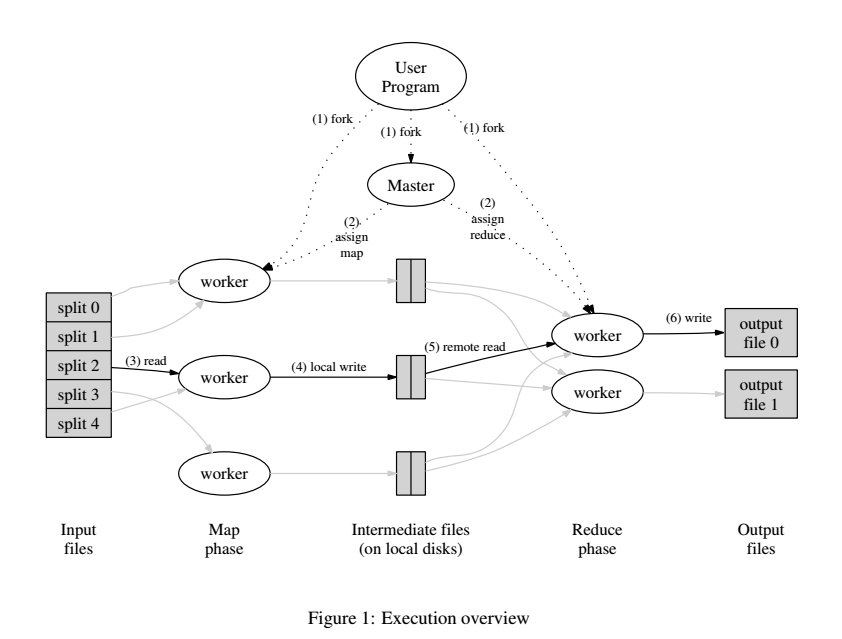
通过将数据切分成M块,map任务分布在不同的机器上,这样每一块数据会被不同的机器并行处理。reduce函数的分布,是通过将使用分片函数将中间结果进行R份的分块,R值和分片函数是由用户指定的。
上图整体的处理流程。处理流程如下:
1. mapreduce库先将输入文件切分成M块,从16MB到64MB都可以,这个由用户决定。同时在集群中多个机器上拷贝并启动程序。
2. 其中一个程序是master,负责为workers分配工作。包括M个map任务和R个reduce任务。
3. 一个worker读取内容,并发送给map函数生成中间结果,中间结果保存在内存中。
4. 在内存中的中间结果会定期地写入磁盘,通过分片函数切分成R片。这些结果的位置会发送到master, 之后这些信息会发送到reduce的worker。
5. reduce任务的worker会执行rpc调用读取map机器的中间结果,并将key进行排序,因为可能包含多个key,可能需要进行外部排序。
6. reduce对排过序的中间结果进行迭代处理,reduce结果被加入到最终的结果中。
7. 当所有的任务执行完,master唤醒用户的程序。mapreduce调用会返回用户的代码。
master的数据结构
- 记录
mapreduce任务的状态idle, in-progress,completed。 - 机器列表。
- 中间结果的位置信息, 这个是通过增量方式推送的。
错误容忍
worker故障
worker和master之间会维持心跳包,如果worker故障了,那么master会将其上执行的任务都进行reset为失败,并重新调度。
重新执行的任务,需要通知所有的reduce任务。
master故障
master会进行定期持久化数据结构,如果故障,可以从持久化的数据中恢复。master是单点的。
