@xxzhushou
2018-01-09T09:49:26.000000Z
字数 3242
阅读 33238
如何使用Tesseract-OCR(v3.02.02)训练字库
叉叉脚本 ocr
为什么要训练字库
从脚本引擎v1.8.00起,叉叉正式支持Tesseract-OCR(v3.02.02)识别,并且内置了一个轻量的默认字库,但很多小伙伴反映内置字库识别率低,外置下载字库又太大了,使用起来不能顺心。
幸好Tesseract识别支持自己训练的字库,自己训练出来的字库一般具有轻量、有针对性、识别率高的特点,那么本教程就手把手教你如何制作适合自己脚本的字库文件,并且如何用IDE工具调试偏色保证识别效果。
准备工作
下载Tesseract-OCR官方命令行工具:https://sourceforge.net/projects/tesseract-ocr-alt/files/tesseract-ocr-setup-3.02.02.exe/download 下载完成后安装,安装完成后,打开cmd命令行,输入
tesseract -v,如果安装成功,将会出现这样的提示界面:
下载jTessBoxEditor:https://osdn.net/projects/sfnet_vietocr/downloads/jTessBoxEditor/jTessBoxEditor-1.5.zip/ 下载完成后解压即可。
训练字库
准备字体图片tif文件
字体图片有两种主要获取方式,适用不同的字库制作需要:
方法一:获取游戏字体文件
一般游戏字体文件分两种,一种是直接加载ttf等标准字体文件,另一种是使用bmfont,也就是图片(一般是png)加额外的配置文件来加载字体。后者一般是用于少数的字体展示,例如数字0-9、字母a-Z。

某游戏的bmfont字体文件,本质上就是一张png图片,加plist配置文件
不论是哪种,目标依然是要将这些字体文件转换成一张tif图片,如果是bmfont类型直接用转换工具例如PS导出tif格式即可(图片处理成白底黑字),这里讨论ttf格式的制作办法。
以部落X突为例,对apk包进行解压缩,可以在assets/font目录下发现一个熟悉的字体文件Supercell-Magic_5.ttf:
这个正是游戏里普遍使用的英文数字字体文件,打开并安装字体文件到PC,然后打开PS,随便新建一个合适大小的纯白底色图片,然后选择文本框将0-9数字输入(如果需要识别其他符号例如.、:,也可一并输入,英文字符同理):
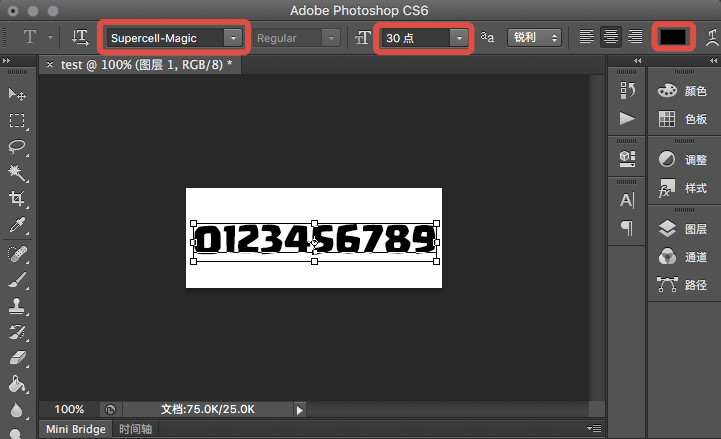
注意事项:安装字体后,选择对应的字体,底图需要纯白,字体颜色为纯黑。另外底图尺寸不要太小,字体大小适中即可。
最后PS导出图片选择TIFF格式,即可得到游戏的字体图片tif文件。
方法二:游戏内截图
这个方法适用于无法获得游戏资源文件(加密或经过压缩处理等),或者每次展现的字体都有区别的情况(游戏内提示的验证码、手写字体等)。
基本原理是将出现的字符图片尽量可能多的截图并收集起来,最终通过处理拼成一张白底黑字的大图,例如某游戏的验证码:

通过对数字部分的截取和分割,由大量验证码数字组成新的tif图片:

一个重要原则是,尽量使用分辨率较高的tif图片制作字库,同时保证tif图片里字体展示清晰,这样生成的字库识别率会更高。
生成box文件
准备好字体图片tif文件后,可以开始正式制作我们识别用的字库了。第一步是先生成box文件,为了统一起见,将上面得到的tif文件,命名为num.font.exp0.tif,在cmd中切换到tif文件所在目录,然后输入以下命令行:
tesseract num.font.exp0.tif num.font.exp0 batch.nochop makebox
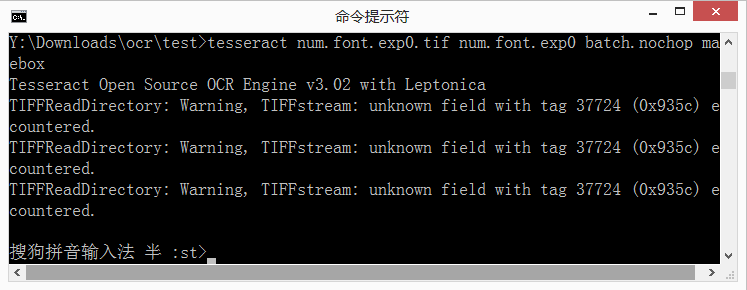
命令可能会产生一些warning输出,属于正常现象,可以忽略。
命令执行成功的话,同目录下会生成num.font.exp0.box文件;否则,请确认命令是否正确输入。
使用jTessBoxEditor工具修正(可选)
box文件本质上就是一堆配置信息,记载了字符和字符在tif文件中的框选位置信息。这一步是可选的,熟悉流程操作后可以直接用编辑器打开上一步产生的box文件直接修改,这里借助jTessBoxEditor工具确认。
直接双击运行jTessBoxEditor目录下的train.bat文件运行java程序,然后点击Box Editor窗口,点击Open加载tif文件。
如果jTessBoxEditor没有运行起来,尝试直接在cmd中切换到解压目录后,输入命令行启动:
java -jar jTessBoxEditor.jar
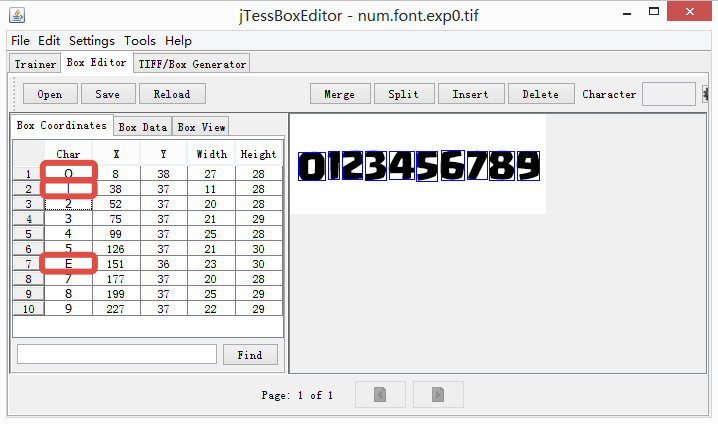
默认生成的box不一定可靠,这里数字0、1、6识别成字母O、l、E了,需要手动修改。
加载box文件可以发现有三个字符默认识别错误了,需要进行修改,直接点击对应错误的字母,替换正确数字即可:
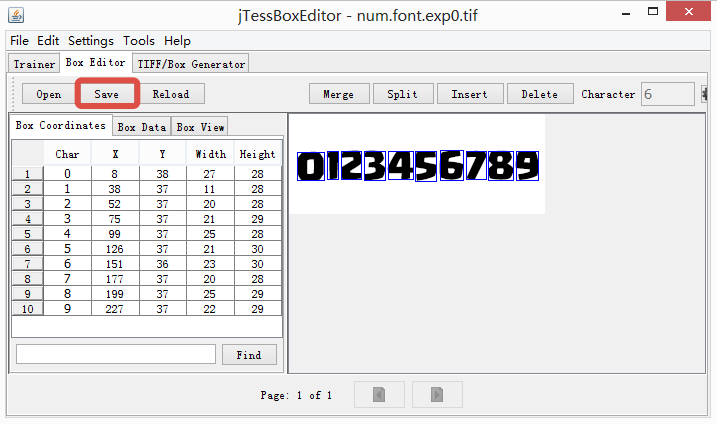
确认框选位置没有错误,对应字符也正确的情况下,点击save按钮完成box修正。
打包字库文件
打包字库需要一个额外文件font_properties,这个文件指定字库的样式,每一行格式是:
<font-name/字体名称> <italic/斜体> <bold/粗体> <fixed/等宽体> <serif/衬线体> <fraktur/尖角体>
其中italic、bold、fixed、serif和fraktur用1/0代表是/否,例如:timesitalic 1 0 0 1 0
在这里,不需要特殊设置,直接创建一个font_properties文件,填写font 0 0 0 0 0即可。
接下来无技术含量,撸起袖子就是依次输入:
tesseract num.font.exp0.tif num.font.exp0 nobatch box.trainunicharset_extractor num.font.exp0.boxmftraining -F font_properties -U unicharset -O num.unicharset num.font.exp0.trcntraining num.font.exp0.trrename normproto num.normprotorename inttemp num.inttemprename pffmtable num.pffmtablerename shapetable num.shapetablecombine_tessdata num.
这段命令也可以直接保存成.bat文件,后续修改tif或者box文件后直接运行.bat文件即可重新生成字库文件。
注意期间有没有错误输出(注意关键词error),附正确生成的流程示例:

如无意外,本地下即可看到num.traineddata文件,就是我们使用自定义字体图片tif文件训练得到的字库文件了。
脚本加载使用
生成的自定义字库可以在叉叉中直接使用,将num.traineddata文件放到xsp工程的res/目录下,测试代码示例:
-- 横屏home右init("0", 1)-- 测试自定义字库local ocr, msg = createOCR({type = "tesseract",path = "res/", -- 自定义字库暂时只能放在脚本res/目录下lang = "num" -- 使用生成的num.traineddata文件})if ocr ~= nil then-- 测试1080p分辨率下的coc村庄资源获取local rect = {1528, 46, 1800, 76}local diff = {"0xffffff-0x0f0f0f"}local code, text = ocr:getText({rect = rect,diff = diff})if code == 0 thensysLog("recognize succeed: gold = " .. text)elsesysLog("recognize failed: code = " .. tostring(code))endelsesysLog("createOCR failed: " .. msg)end
测试输出结果:
recognize succeed: gold = 4 908
IDE调试偏色和二值化效果
即将发布,敬请期待!
