@yanglfyangl
2018-08-06T03:07:07.000000Z
字数 6101
阅读 625
啥是区块链
主要参考
简介
价值
- 只能按规则和共识机制进行更新
- 可信的我方信息共享和监督
- 避免了人工对帐
- 提高了业务处理效率。
- 无需借助第三方,实现多方可信对等的价值传输。
技术核心
- P2P协议
- 非对称加密
- 共识机制
- 块链结构
当前主流平台
| 平台 | 针对 | 准入机制 | 数据模型 | 共识算法 | 合约语言 | 底层数据库 | 数字货币 |
|---|---|---|---|---|---|---|---|
| 比特币 | 公网 | 公有链 | 基于交易 | PoW | 基于栈的脚本 | levelDB | 比特币 |
| 以太坊 | 公网 | 公有链 | 基于帐户 | PoW/PoS | Solidity | levelDB | 以太币 |
| Fabric(*) | 企业级 | 联盟链 | 基于帐户 | PBFT/SBFT | Go/Java | levelDB/CouchDB | -- |
| Corda | 金融机构 | 联盟链 | 基于交易 | Raft | Java | 关系数据库 | -- |
| BigChainDB | 分布式+区块链 | 联盟链 | 基于交易 | Quorum Voting | Cypto-condidtion | Rethink/Mongo | -- |
| TrustSQL | 云服务+企业级 | 联盟链 | 基于账户 | Raft/PBFT | JS | Mysql/MariaDB | -- |
可扩展性方案
比特币,以太坊和Fabric都采用全网共享一条区块链的单链方案。
为了提高效率
- 以太坊采用了"分片(Sharding)"方案。
- Fabric采用了"多通道"方案。
- 熊猫网络等方案
性能对比
| 平台 | TPS |
|---|---|
| 比特币 | 7 |
| 以太坊 | 25 |
| Fabric(*) | 2000 |
| Mysql(用于对比) | 10w |
发展趋势/研究方向
| 方向 | 主要思路 |
|---|---|
| 共识机制 | PoW计算消耗过大,PBFT网络消耗过大;如何找出更合适的方案 |
| 隐私保护 | 零知识证明和同态加密是未来方向(可抵抗量子攻击) |
| 部分存储 | Corda, Fabric和以太坊都按这个方向有一定的解决方案 |
| 链外交易 | 闪电网络,雷电网络;主链做为确认和仲裁的最后手段。 |
| 多链与侧链 | |
| 跨链 | Polkadot、Cosmos |
| 区块树与区块图 | 业界有人提出用树和图来解决链的问题 |
| SQL On BlockChain | 类似Sql on Spark, Sql on Hadoop等 |
| BlockChainDB | 支持区块链的数据库 |
技术介绍 -- 基础知识
SHA(256)
也称为散列函数,给定一个输入x,它会算出相应的输出H(x)。哈希函数的主要特征是:
- 输入x可以是任意长度的字符串
- 输出结果即H(x)的长度是固定的
- 计算H(x)的过程是高效的(对于长度为n的字符串x,计算出H(x)的时间复杂度应为O(n))
Merkle 树(又叫哈希树)
它是哈希大量聚集数据“块”(chunk)的一种方式,它依赖于将这些数据“块”分裂成较小单位(bucket)的数据块,每一个bucket块仅包含几个数据“块”,然后取每个bucket单位数据块再次进行哈希,重复同样的过程,直至剩余的哈希总数仅变为1:即根哈希(root hash)

这里有:详细介绍
对于比特币来说,需要的哈希算法是:
- 免碰撞,即不会出现输入x≠y,但是H(x)=H(y)
- 隐匿性,也就是说,对于一个给定的输出结果H(x),想要逆推出输入x,在计算上是不可能的。
- 不存在比穷举更好的方法,可以使哈希结果H(x)落在特定的范围。
Bloom Filter
布隆过滤器实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。(当大V逻辑时,可以考虑使用布隆过滤器了)
BloomFilter(大数据去重)+Redis(持久化)策略
NOSQL 数据库 分类

技术介绍 -- 共识算法
PoW -- Proof of Work,工作证明
你获得多少货币,取决于你挖矿贡献的有效工作,也就是说,你电脑性能越好,分给你的矿就会越多,这就是根据你的工作证明来执行货币的分配
POS -- Proof of Stake,股权证明
在POS体系中,即使你拥有了全球51%的算力,也未必能够进行51%攻击,因为,有一部分的货币并不是挖矿产生的,而是由利息产生(利息存放在POS区块中),这要求攻击者还需要持有全球超过51%的货币量。这大大提高了51%攻击的难度。
DPOS -- Delegated Proof of Stake,委任权益证明
原理是让每一个持有比特股的人进行投票,由此产生101位代表 , 我们可以将其理解为101个超级节点或者矿池,而这101个超级节点彼此的权利是完全相等的。从某种角度来看,DPOS有点像是议会制度或人民代表大会制度。如果代表不能履行他们的职责(当轮到他们时,没能生成区块),他们会被除名,网络会选出新的超级节点来取代他们。DPOS的出现最主要还是因为矿机的产生,大量的算力在不了解也不关心比特币的人身上,类似演唱会的黄牛,大量囤票而丝毫不关心演唱会的内容。
PBFT --- 实用拜占庭容错算法
所有的副本在一个被称为视图(View)的轮换过程(succession of configuration)中运作。在某个视图中,一个副本作为主节点(primary),其他的副本作为备份(backups)。视图是连续编号的整数。主节点由公式p = v mod |R|计算得到,这里v是视图编号,p是副本编号,|R|是副本集合的个数。当主节点失效的时候就需要启动视图更换(view change)过程。Viewstamped Replication算法和Paxos算法就是使用类似方法解决良性容错的。
PBFT算法的狗血剧情如下:
1.客户端向主节点发送请求调用服务操作
2.主节点通过广播将请求发送给其他副本
3.所有副本都执行请求并将结果发回客户端
4.客户端需要等待f+1个不同副本节点发回相同的结果,作为整个操作的最终结果。
同所有的状态机副本复制技术一样,PBFT对每个副本节点提出了两个限定条件:(1)所有节点必须是确定性的。也就是说,在给定状态和参数相同的情况下,操作执行的结果必须相同;(2)所有节点必须从相同的状态开始执行。在这两个限定条件下,即使失效的副本节点存在,PBFT算法对所有非失效副本节点的请求执行总顺序达成一致,从而保证安全性。
SBFT --- 简化的拜占庭容错算法
在这个算法中,区块验证者是一个知名的机构。例如在整个商业网络中可以是一个监管者。这个区块验证者创造并提出新的区块转账。
在SBFT共识中,一定数量的节点一定要接受这个区块,当然这取决于错误节点的数量。在这样的系统中,最少要有2f+1的节点必须要接受商业网络中的新区块,f就是错误节点的数量。举例来说,我们假设现在系统中有30个参与者,其中包含了5个错误节点。作为需要验证的新区块,11(2×5+1)个节点。这个错误可以是恶意的,也可能是无效的节点。优点:比工作量证明更快,有更好的扩容性。缺点:有中心化趋势。一个验证者提出下个区块。
RAFT -- Repliated status machine architecture
RAFT核心思想很容易理解,如果数个数据库,初始状态一致,只要之后的进行的操作一致,就能保证之后的数据一致。由此RAFT使用的是Log进行同步,并且将服务器分为三中角色:Leader,Follower,Candidate,相互可以互相转换。
RAFT从大的角度看,分为两个过程:
1. 选举Leader
2. Leader生成Log,并与Follower进行Headbeats同步
详细介绍 Raft算法,从学习到忘记
PAXOS -- 基于消息传递的一致性算法
PAXOS是一种基于消息传递且具有高度容错特性的一致性算法。
算法本身用语言描述极其精简:
phase 1
a) proposer向网络内超过半数的acceptor发送prepare消息
b) acceptor正常情况下回复promise消息
phase 2
a) 在有足够多acceptor回复promise消息时,proposer发送accept消息
b) 正常情况下acceptor回复accepted消息

Quorum Voting
"法定投票" 有三种身份 Maker, Voter, Observer。身份有 Maker 的节点有权利打包交易并生成区块。其他节点收到区块后会查看区块头里的 Maker 签名,校验生成此区块的节点是否拥有 Maker 身份。拥有 Voter 身份的节点可以为收到的区块投票。一个区块只有收到一定数量的投票后才能被所有节点校验通过。Observer 身份没有任何特殊的权限,只能做一个记录区块的节点。
技术介绍 -- 合约语言
比特币脚本 UTXO
//标准脚本,每个指令的结果都是入栈或者出栈OP_DUP OP_HASH160 <PubkeyHash> OP_EQUALVERIFY OP_CHECKSIG//如下是带签名和公钥的脚本<Sig> <PubKey> OP_DUP OP_HASH160 <PubkeyHash> OP_EQUALVERIFY OP_CHECKSIG
参考自 理解比特币脚本
Solidity
Solidity是一种语法类似JavaScript的高级语言。它被设计成以编译的方式生成以太坊虚拟机代码
更详细的区块链介绍
- 以太坊底层是基于帐户,而非UTXO的,所以有一个特殊的Address的类型。用于定位用户,定位合约,定位合约的代码(合约本身也是一个帐户)。
- 由于语言内嵌框架是支持支付的,所以提供了一些关键字,如payable,可以在语言层面直接支持支付,而且超级简单。
- 存储是使用网络上的区块链,数据的每一个状态都可以永久存储,所以需要确定变量使用内存,还是区块链。
- 运行环境是在去中心化的网络上,会比较强调合约或函数执行的调用的方式。因为原来一个简单的函数调用变为了一个网络上的节点中的代码执行,分布式的感觉。
- 最后一个非常大的不同则是它的异常机制,一旦出现异常,所有的执行都将会被回撤,这主要是为了保证合约执行的原子性,以避免中间状态出现的数据不一致。
示例HellowWorld:


技术介绍 -- 底层数据库
LevelDB
Leveldb是一个google实现的非常高效的kv数据库,目前的版本1.2能够支持billion级别的数据量了。LevelDB 是单进程的服务,性能非常之高,在一台4核Q6600的CPU机器上,每秒钟写数据超过40w,而随机读的性能每秒钟超过10w(此处随机读是完全命中内存的速度,如果是不命中 速度大大下降
)
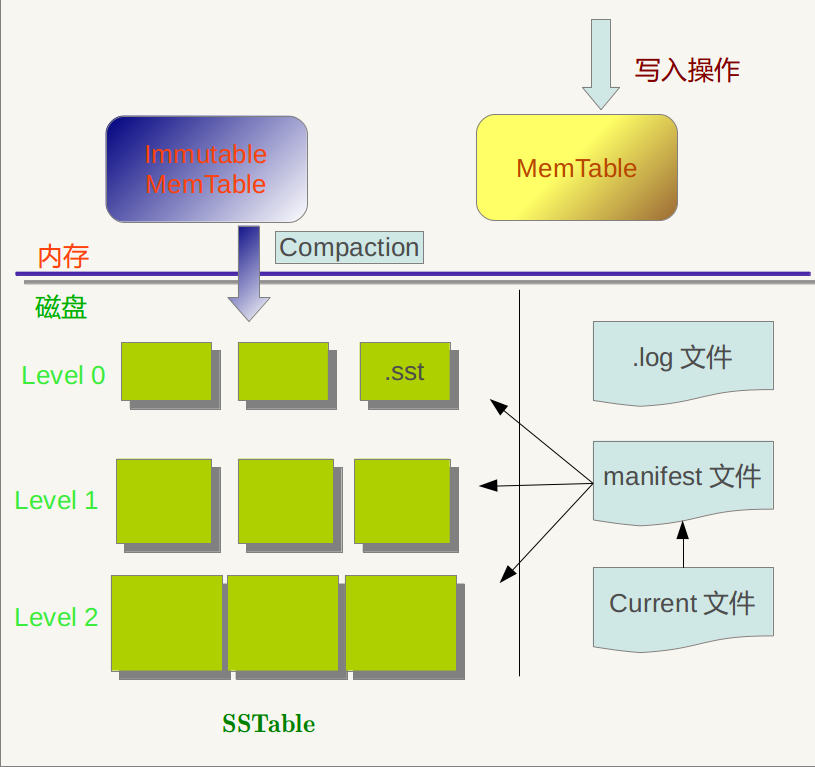
CouchDB
曾经的Apache三剑客:HBase, Cassandra, CouchDB;
Rethink
和MongoDB类似最大的特点就是时实。
它采取一个新的访问数据库的模型,用监听事件的方式来通知数据的变化。而不是轮训的方式。
import rethinkdb as rconn = r.connect('127.0.0.1', db='exampledb')r.table('exampletable').filter(r.row['colname']=='value').changes()# 当得到变化通知时继续做后续的工作。
MariaDB
MariaDB 5 是 MySQL 的一个分支
技术介绍 -- 网络模型
熊猫网络模型
熊猫网络模型是基于双链技术账户区块链和交易区块链提出的一种新架构,主要分为两个部分:
- 账户信息:由账户区块链来维护所负责的账户信息,包括户主信息及余额等。所有对账户的修改都会被区块链记录,防止被篡改。
- 交易区块链:由许多交易区块链构成,负责处理所有交易。用户需要进行交易时,把交易发送给交易区块链,交易区块链根据交易的输入和输出方分别向涉及到的账户区块链发送账户上传请求,收到账户信息后进行交易,并把账户信息返回给两个账户区块链完成清算。
熊猫网络模型可以用在大型应用上,例如央行数字货币。
央行有两个功能:
- 其一是发行货币,通过控制货币的发行来调控国家的经济,维护货币的稳定;
- 其二是监控经济活动。
货币发行由央行定,而熊猫模型可以对货币流通进行追踪,发现交易中的违法行为,追踪违法者的账户信息。每一家金融机构至少有一条账户区块链和一条交易区块链,交易经过交易区块链,但账户信息存在账户区块链。央行可以在每条链上放一个节点,所有账户和交易信息都会保存在央行节点之上,节点之间运行拜占庭协议来保持数据的一致性。央行可用链上数据来进行监管和大数据分析,这是新型的监管科技(RegTech)。
技术介绍 -- 平台介绍
BigchainDB
BigChainDB填补了去中心生态系统中的一个空白:
- 是一个可用的去中心数据库
- 它具有每秒百万次写操作,存储PB级别的数据和亚秒级响应时间的性能。
BigChainDB的设计起始于分布式数据库,通过创新加入了很多区块链的特性,像去中心控制、不可改变性、数字资产的创建和移动。
BigChainDB继承了现代分布式数据库的特性:
- 吞吐量和容量都是与节点数量线性相关
- 功能齐全的NoSQL查询语言
- 高效的查询和权限管理。
因为构建在已有的分布式数据库上,它在代码层面也继承了企业级的健壮性。可扩展的容量意味着具有法律效力的合同和认证可以直接存储在区块链数据库里。权限管理系统支持从私有企业级区块链数据库到开放公有的区块链数据库配置
Frabic

包括三大组件
- 区块链服务(Blockchain)
- 链码服务(Chaincode)
- 成员权限管理(Membership)
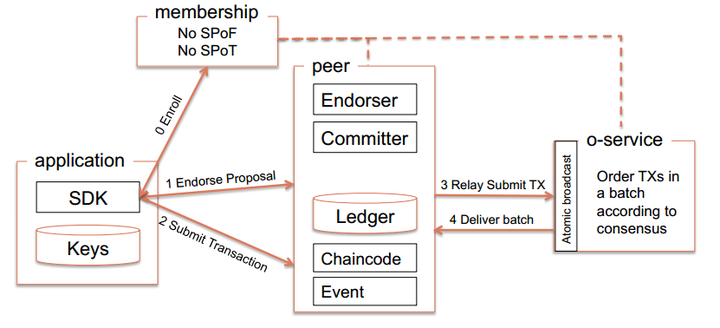
主要术语有如下:
- Orderers:提供共识服务的网络节点,例如,使用Kafka或PBFT。
- Peers:维护账本的网络节点,通常在Hyperledger Fabric架构中存在各种角色,如endorser和committer。
- 通道:Order 服务提供Peer节点供订阅的主题(如发布-订阅消息队列),每个主题是一个通道。
- peer可以在订阅多个通道,并且只能访问订阅通道上的交易。
- 账本:账本保存Orders提交经节点确认的交易记录。 ●成员:访问和使用账本的网络节点。
- 链:基本上,一个链由1个通道+ 1个账本+ N个成员组成。
非链的成员无法访问该链上的交易。链的成员可以由应用程序动态指定。
区块链即服务
使用场景

