@yanglfyangl
2018-07-12T03:37:28.000000Z
字数 4299
阅读 1444
PredictionIO 分析及使用建议
一些参考资料
Scala 常用语法
Scala基础之注解(annotation
SBT 基础学习
Spark各个知识点总结
比较两个生产级NLP库:训练Spark-NLP和spaCy的管道
干货:基于Spark Mllib的SparkNLP库。
为什么选择PredictionIO
如果我们做一个大数据平台,我们事实上是在做这些东西
1. 数据读取,准备和清洗流程。
2. 数据离线训练的算法。
3. 各种算法的组合。
4. 预测的接口。
5. 支持源数据可视化分析(目前支持IPython notebook, Zeppelin, Tableau)
5. 。。。
6. 同时,上面的过程尽量在自己的控制范围内,而不是
什么是PredictionIO

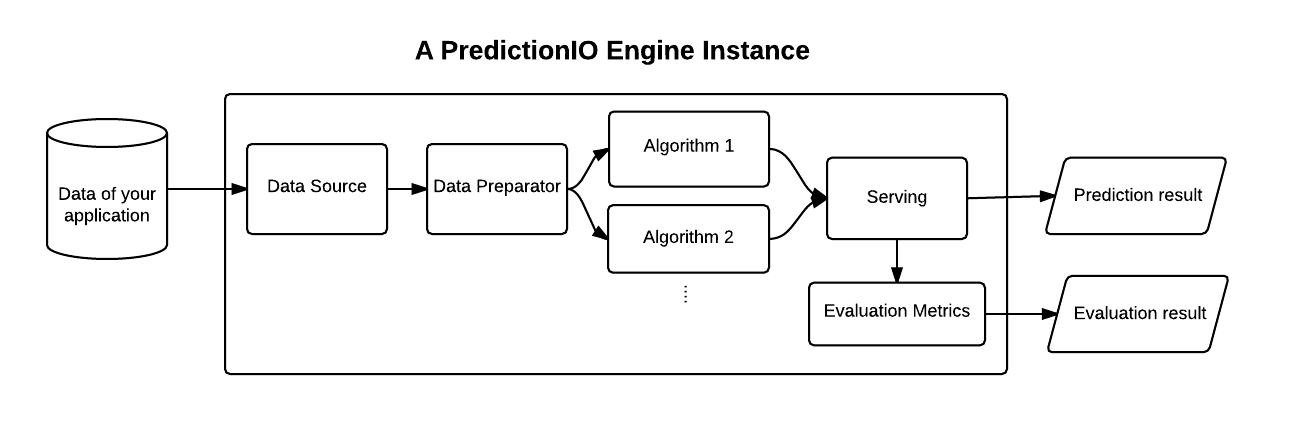
从图中可以看到,Predictionb包含了
>* 实时处理部分>* 离线计算部分
主要包含了这样几大部分:
服务组件:>* EventServer:主要负责接收外部数据>* Traning:主要用于离线数据处理或模型训练。>* PredictionServer:主要用于结果获取或预测(是不是预测要看你的模型。)基础组件:>* HBase:主要用于存Event数据。>* ES: 可以用于存处理后的数据或模型,同时也存了model version, engine version, ip mapping, evaluation results等等。。。>* HDFS: 批量导入时使用,根据模版的不同,也可能存储数据或模型.>* Spark:主要用于模型训练和数据处理。Train的结果主要包括两部分:a model and its meta-data
从数据流的角度来说,主要有这样几种
- DataSource
- Preparator
- Alogrithm
- Serving
- Evaluation
DataSource -- 自定义数据
val eventsRDD: RDD[Event] = PEventStore.find(appName = dsp.appName,entityType = Some("customer"), // MODIFIEDeventNames = Some(List("like", "dislike")), // MODIFIED// targetEntityType is optional field of an event.targetEntityType = Some(Some("product")))(sc) // MODIFIEDval ratingsRDD: RDD[Rating] = eventsRDD.map { event =>val rating = try {val ratingValue: Double = event.event match {// MODIFIEDcase "like" => 4.0 // map a like event to a rating of 4.0case "dislike" => 1.0 // map a like event to a rating of 1.0case _ => throw new Exception(s"Unexpected event ${event} is read.")}// entityId and targetEntityId is StringRating(event.entityId,event.targetEntityId.get,ratingValue)} catch {case e: Exception => {logger.error(s"Cannot convert ${event} to Rating. Exception: ${e}.")throw e}}rating}.cache()
Preparator -- 数据清洗
下面的例子是将需要train的数据中,将提前定义好的不参与train的部分去除掉。
import scala.io.Source // ADDEDclass Preparatorextends PPreparator[TrainingData, PreparedData] {def prepare(sc: SparkContext, trainingData: TrainingData): PreparedData = {// MODIFIED HEREval noTrainItems = Source.fromFile("./data/sample_not_train_data.txt").getLines.toSet// exclude noTrainItems from original trainingDataval ratings = trainingData.ratings.filter( r =>!noTrainItems.contains(r.item))new PreparedData(ratings)}}
Algorithm 之 train -- 训练
def train(sc: SparkContext, data: PreparedData): ECommModel = {require(!data.rateEvents.take(1).isEmpty, // MODIFIEDs"rateEvents in PreparedData cannot be empty." + // MODIFIED" Please check if DataSource generates TrainingData" +" and Preprator generates PreparedData correctly.")...val mllibRatings = data.rateEvents // MODIFIED.map { r =>...((uindex, iindex), (r.rating,r.t)) //MODIFIED}.filter { case ((u, i), v) => //过滤异常值// keep events with valid user and item index(u != -1) && (i != -1)}.reduceByKey { case (v1, v2) => // MODIFIED //去重// if a user may rate same item with different value at different times,// use the latest value for this case.// Can remove this reduceByKey() if no need to support this case.val (rating1, t1) = v1val (rating2, t2) = v2// keep the latest valueif (t1 > t2) v1 else v2}.map { case ((u, i), (rating, t)) => // MODIFIED// MLlibRating requires integer index for user and itemMLlibRating(u, i, rating) // MODIFIED}.cache()...}
Algorithm 之 predict -- 预测
def predict(model: RandomForestModel, // CHANGEDquery: Query): PredictedResult = {val label = model.predict(Vectors.dense(Array(query.attr0, query.attr1, query.attr2)))PredictedResult(label)}
Serving -- 对外服务
如果预测结果可以直接返回的话,不需要做什么处理。
但比如说需要加黑名单什么的,可以在这里进行处理。
下面的例子是将被禁用的商品过滤掉的一个操作。
import scala.io.Source // ADDEDclass Servingextends LServing[Query, PredictedResult] {overridedef serve(query: Query,predictedResults: Seq[PredictedResult]): PredictedResult = {// MODIFIED HERE// Read the disabled item from file.val disabledProducts: Set[String] = Source.fromFile("./data/sample_disabled_items.txt").getLines.toSetval itemScores = predictedResults.head.itemScores// Remove items from the original predictedResultPredictedResult(itemScores.filter(ps => !disabledProducts(ps.item)))}}
上生产环境的几大Q/A
Q: 这个系统稳定吗
A:不能说100%稳定,目前的版本是0.12,但Star数为11k,Fork数为1.8K,从经验上来说,Apache旗下开源的项目,这个数字是可以开始考虑线上使用了,但不排除有坑。
Q:高可用怎么做
A:我们可以部署多台,前端通过Nginx或LVS进行负载。同时,负责training的节点与负责predict的节点分开(参考mysql的读写分离策略)
Q:我们有些服务并不是预测,而是统计,怎么做?
A:即使这样,我们也可以利用现有的框架,在训练的时候,进行统计计算。计算结果存入HBase。在统计的时候,从HBase中读出数据返回。同时,用定时器定期来跑Pio train就可以了。
Q:会不会有资源上的上限
A:PredictionIO本身是个框架,存储资源是依赖Hbase或ES,计算资源是依赖Spark。可以通过Nginx或Lvs进行负载均衡,所以理论上来说是可以横向扩展的。
Q:怎么与云上资源进行配合呢
A:可以考虑这样
- 框架由我们自己控制。
- 使用云上的spark和es资源。
- 算法中基础部分,使用spark的。
- 如果需要使用云上一些算法,可以在Serve层调用。
