@BrandonLin
2016-07-27T13:46:53.000000Z
字数 23557
阅读 8577
Pig完全入门
Pig Hadoop
本文内容来自Hadoop权威指南,个人阅读的时候顺带整理翻译而来,并加入了自己的理解以及实际运行的配置。涵盖了Pig的核心内容,非常值得细度。
版本记录:
- 2016-07 初稿
1. 环境配置:
wget http://mirror.bit.edu.cn/apache/pig/pig-0.15.0/pig-0.15.0.tar.gztar zxvf pig-0.15.0.tar.gzmv ./pig-0.15.0 /home
加入到PATH,/etc/profile加入:
export PIG_HOME=/home/pig-0.15.0export PATH=$PATH:$PIG_HOME/bin
source或者点操作确保生效。
确保配置了HADOOP_HOME环境变量:
echo $HADOOP_HOME
在运行pig之前,还需要NameNode启动JobHistory Server:
mr-jobhistory-daemon.sh start historyservejps
运行Grunt:
pig
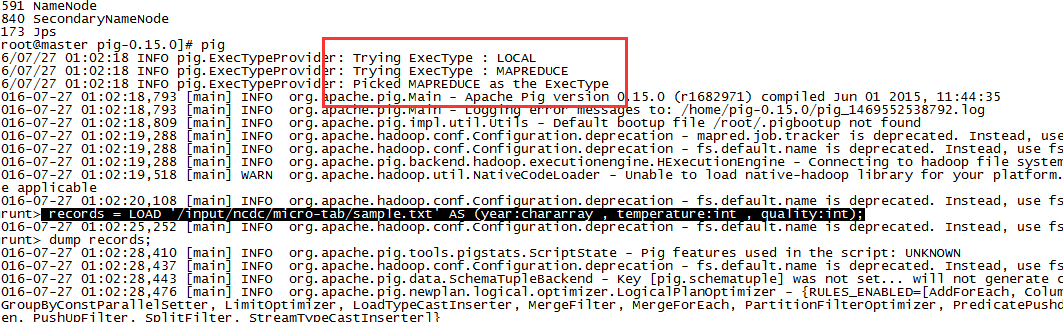
可以看到pig选择了MapReduce模式,这是默认的模式。
2. Pig完整实例
载入数据:
records = LOAD '/input/ncdc/micro-tab/sample.txt' AS (year:chararray , temperature:int , quality:int);
输出数据:
dump records;
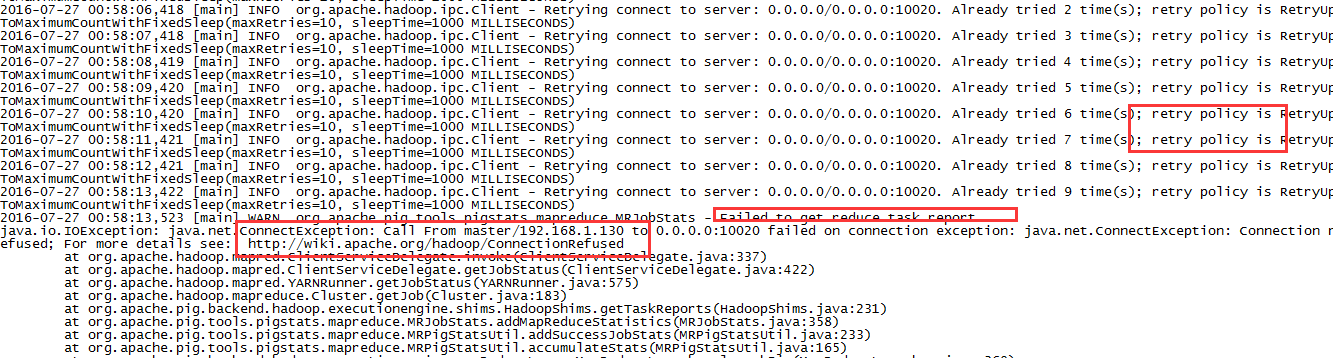
此时会提交MapReduce作业,如果没有启动作业历史服务器,MapReduce虽然执行成功,但是会报错:
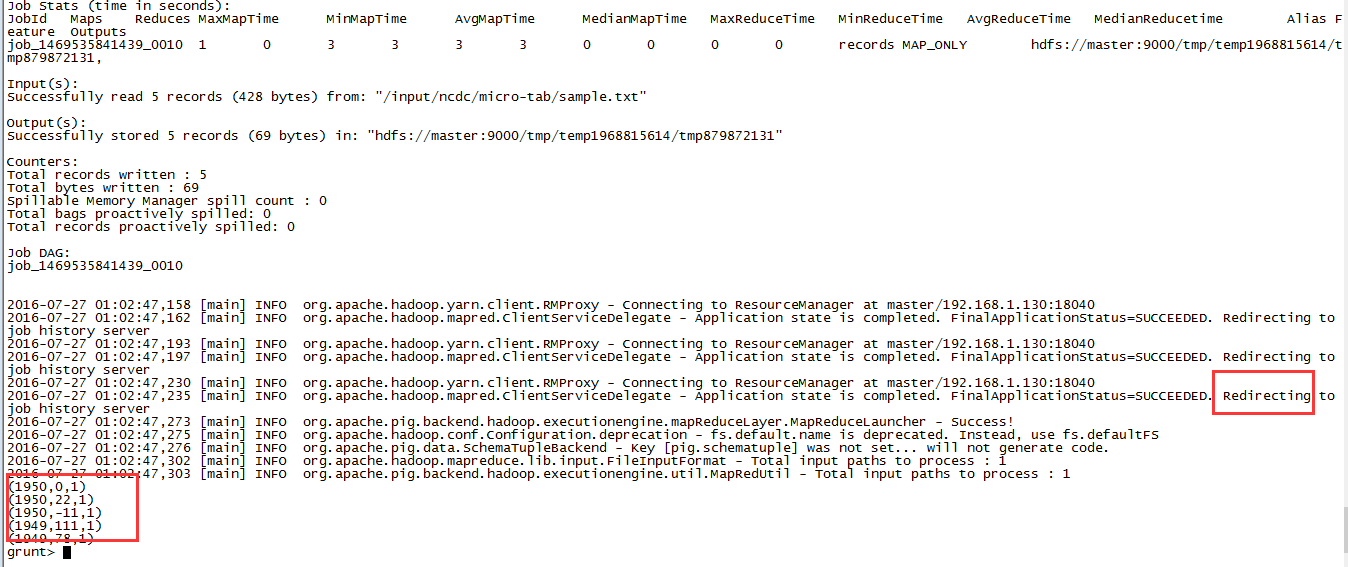
成功输出结果:
查看YARN管理界面:
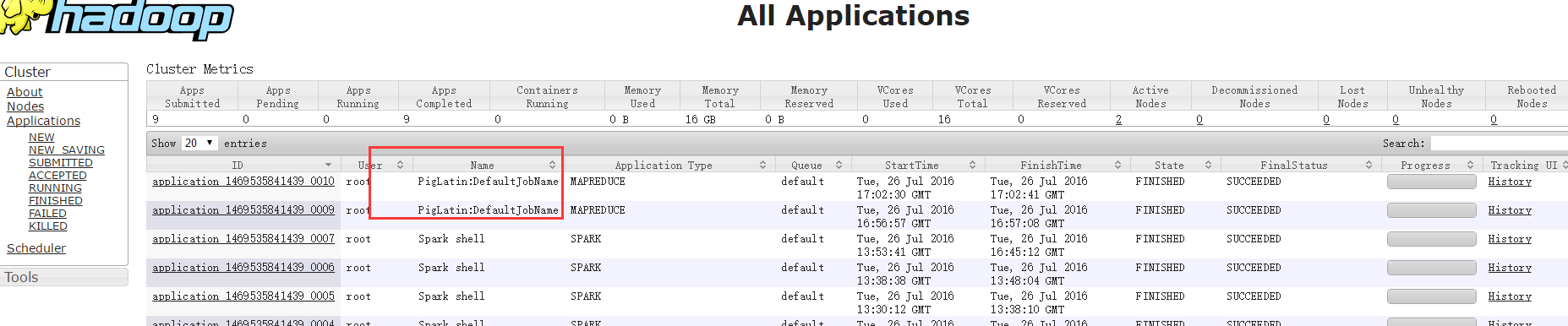
详情:
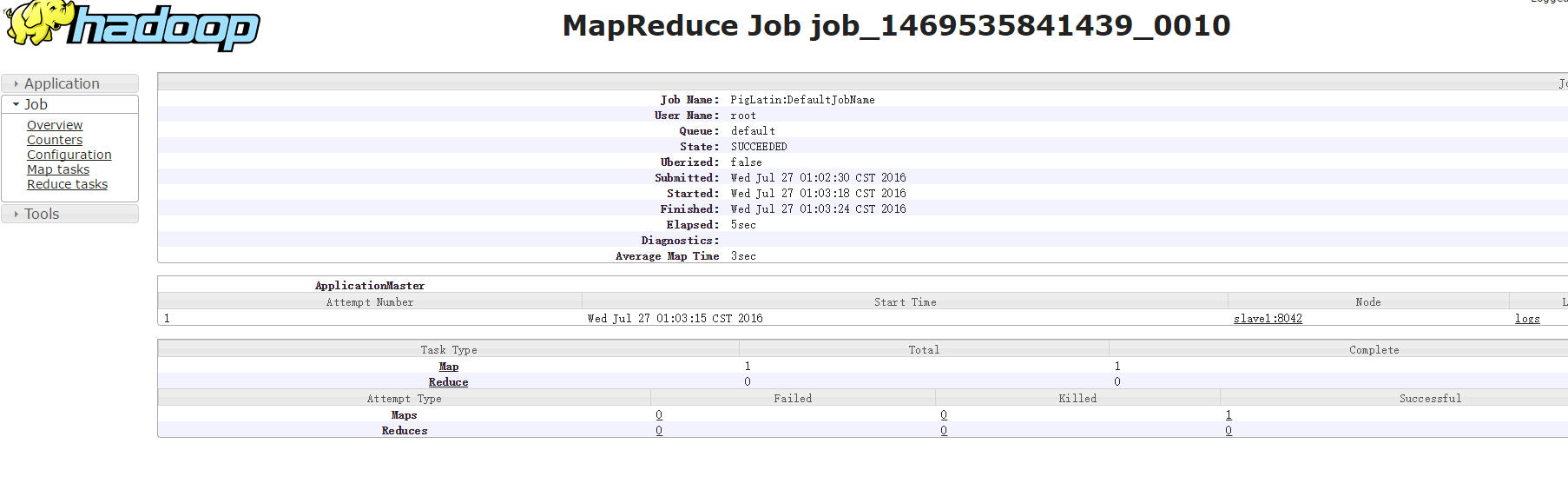
返回的records是个Relation,类似于表。Pig使用元组来表示记录。查看records的结构:
grunt> describe records;records: {year: chararray,temperature: int,quality: int}grunt>
接着我们过滤掉脏数据:
filtered_records = FILTER records BY temperatur != 9999 and quality in ( 0 ,1,4,5,9);dump filterd_records;
一样会触发MapReduce操作,输出结构到控制台。
接着进行分组:
grouped_records = GROUP filtered_records BY year;DUMP grouped_records;
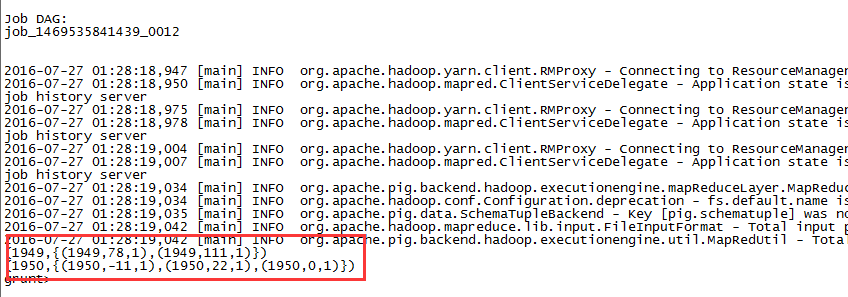
可以看到根据年份字段进行了分组,分组中是元组的列表,证实了我们前面说的Relation由元组构成。年份对应的{ },在Pig中成为bag,它是个无需的元组集合。
最后我们要从bag中找出温度最高的元组,继续之前我们看一下分组之后的结构:
grunt> describe grouped_records;grouped_records: {group: chararray,filtered_records: {(year: chararray,temperature: int,quality: int)}}grunt>
Pig给分组后的key去了一个叫group的别名,其值则为filtered_records,是个元素组成的bag,我们现在要在每一组group中找出温度最高的元组:
maxTemps = FOREACH grouped_records GENERATE group , MAX(filtered_records.temperature);dump maxTemps;

我们完成了找出最高温度的代码:
records = LOAD ("hdfs://master:9000/input/ncdc/micro-tab/sample.txt") AS (chararray : year , int: temperature, int quality ) ;filterd_records = FILTER records BY temperature != 9999 and quality in ( 0,1,4,5,9);grouped_records = GROUP filtered_records BY year;maxTemps = FOREACH grouped_records GENERATE group , MAX(filtered_records.temperature);DUMP maxTemps;
我们现在使用ILLUSTRATE这个操作子来看一下整个数据处理流程。这个操作会生成一些合理的样本值,并按照整个处理流程展示:
ILLUSTRATE maxTemps;
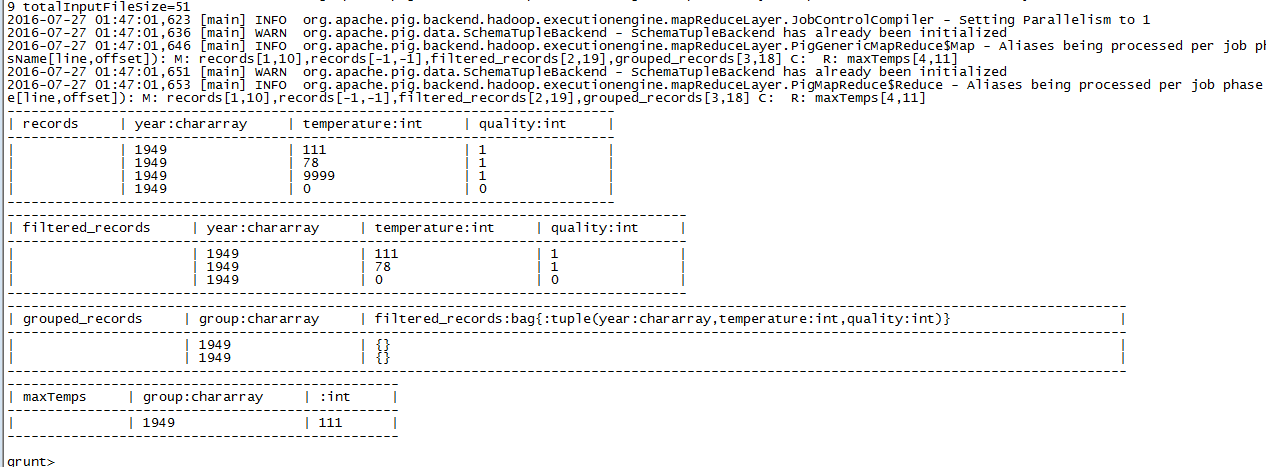
3. Pig Latin
Pig Latin拥有自己特定的语法结构,不像Hive使用基于SQL的语言。
3.1 Pig Latin与SQL
这两种语言看起来很像,例如GROUP BY ,DESCRIBE等。但是他们之间还是有一些不同点:
1) Pig是一种数据流语言(data flow programming langage),而SQL是一种声明式的变成语言。Pig变成是一步一步对数据做处理和转换,而SQL只定义了需要什么样的数据。某种程度上,Pig脚本类似于SQL的查询计划,查询计划将声明式的结果转化为系统步骤。
2)SQL中,数据存储在表中,与特定的Schema绑定。Pig的数据结构则比较宽松,我们可以在处理的过程中定义Schema。例如文本文件中的一个值,在Pig处理过程中,我可以根据需要定义其类型为int,也可以定义为chararray。Pig的核心是在元组上进行操作,Pig程序的第一步通常是从文件系统(一般为HDFS)中读取数据,使用Pig内置的函数或者UDF转化为元组。文件的格式经常使用Tab分隔,所以Pig提供了LOAD用于加载这种格式的数据。
3) 另外,Pig支持复杂的嵌套的数据结构,这一点与SQL的单一层次(平面的,flatter)的表结构很不同。另外,Pig提供的自定义函数UDF以及流式操作(用于适配不同语言编写的UDF)使得Pig更加灵活和强大。
4)但是SQL及RDBMS提供的在线、低延时的查询,在Pig中是没有的,Pig没有事务和索引的概念。Pig也无法支持毫秒级别响应的随机读取,也不支持随机更新,所有的写入操作都是批量的流式(追加)写入,跟MapReduce一样。
Apache Hive则介于Pig和RDBMS之间。跟Pig一样,Hive使用HDFS作为存储。但是Hive提供的查询语言HiveQL是基于SQL,因此更容易上手。Hive也和关系型数据库一样要求数据必须存在表中,表的Schema由Hive管理,但是不同的是,Hive允许我们把一个Schema关联到已经存在的数据(位于HDFS),因此不需要加载的步骤(读取原始数据,转化为相应的结构)。Pig可以通过HCategory与Hive一起使用。
3.2 Pig程序结构:
一个Pig Latin程序包含一系列的语句(Statement),语句可以认为是一种操作或者命令。例如,GROUP BY是语句,列出Hadoop文件系统目录内容也是语句:
GROUP records BY year;ls /
语句后面的分号有时候是必须的,有时候是可选的。一般情况下,用于交互式或者调试场景的可以不用分号,例如DESCRIBE命令。
如果命令必须使用分号,则可以让代码跨域多行。例如:
records = LOAD "path"AS (year:chararray , temperature:int , quality:int);
3.3 注释
Pig有2种注释方式:
DUMP A; -- save to hdfs/*here is comment*/
Pig的保留字包括操作子(LOAD,ILLUSTRATE),命令(cat,ls),表达式(matches , FLATTEN),函数(DIFF,MAX),这些不能在代码中作为标识符。
Pig的操作子和命令不区分大小写(使得写代码容错性更好),但是对于别名(aliases)和函数名,则是大小写敏感的。
3.4 语句
Pig程序运行时,每条依据依次被解析,如果有语法错误,解释器会停止并给出错误消息。解释器为每个操作创建一个逻辑的查询计划,加入到整个程序的查询计划中。需要注意的是,创建查询计划时,没有任何数据处理真正发生。Pig将整个程序作为一个整体解析,以便找出可以优化的地方,当像DUMP之类的语句时,才真正执行数据处理。这一点有点儿Spark中Transformation Lazy Evaluation的味道。下面的这个例子中:
A = LOAD "hdfs://master:9000/input/path";B = FILTER A BY $1 == 'hadoop';C = FILTER A BY $1 != 'hadoop';STORE B INTO "output/b";STORE C INTO "output/c";
上述代码中,B和C这两个Relation都是基于A的,因此Pig执行的时候,不会读取两次,而是把整个脚本作为一个MapReduce执行,输出两个文件。这个特性叫做多查询执行(multiquery execution)。旧版本的Pig中,两个STORE语句会分别启动MapReduce,因此加载两次输入文件。新版本中可以通过-M参数来关闭这个特性。
3.5 执行计划
Pig脚本的物理计划时一系列的MapReduce作业,在local模式下,在一个JVM中执行,在MapReduce模式下,在Hadoop集群上执行。可以通过EXPLAIN命令来查看逻辑计划和物理计划:
explain maxTemps;
这个语句同时还会战术MapReduce计划,MapReduce计划展示如何将物理计划中的操作(operator)归组为MapReduce作业。Pig中主要的操作如下:
载入和存储:
- LOAD:从文件系统或者其他存储载入数据到一个relation
- STORE:保存relation到文件系统或者其他存储
- DUMP(\d): 输出一个relation到控制台
过滤:
- FILTER: 从relation中移除不想要的行
- DISTINCT: 从relation中移除重复的行
- FOREACH ... GENERATE:从relation中移除或者新增字段
- MAPREDUCE:使用relation作为输入运行一个MapReduce作业
- STREAM:使用外部程序(如Python)转换relation
- SAMPLE:从relation中采样
- ASSERT:确保relation满足特定条件,否则失败。
分组与关联:
- JOIN: 关联2个或者多个relation
- COGROUP: 对2个或多个relation的数据进行分组操作
- GROUP: 对一个单一的relation分组
- CROSS:对2个或多个relation求叉积
- CUBE:对relation中某些列的组合进行聚合
排序:
- ORDER:使用relation中的一个或多个字段排序
- RANK: 给relation中的每个元组赋一个rank值
- LIMIT: 限制relation的元组数量
组合和分隔:
- UNION:组合2个或多个relation
- SPLIT:将一个relation分隔为2个或多个
Pig中有2类语句不会加入到执行计划中。例如DESCRIBE,EXPLAIN,ILLUSTRATE之类的调试语句,DUMP也是调试语句,在数据集较小的时候打印到控制台或者结合LIMIT对数据进行限制。Pig Latin的调试操作(disgnoostic operator)如下,括号中为快捷方式:
- DESCRIBE(\de) : 打印relation的模式
- EXPLAIN(\e):输出逻辑和物理计划
- ILLUSTRATE(\i):展示逻辑计划在样本数据的执行情况
Pig提供了3个语句用于整合宏或者自定义函数到Pig脚本中:
- REGISTER:向Pig运行时注册一个JAR包
- DEFINE:为micro,UDF或者流式脚本创建一个别名
- IMPORT:导入外部文件中定义的宏到Pig脚本
因为这些操作不是基于relation的,所以不会加入到逻辑计划中,而是立即执行。
3.6 工具及文件系统操作
另外Pig提供了一些使用工具用于和文件系统和MapReduce作业进行交互:
Hadoop文件系统:
- cat: 查看一个或多个文件的内容
- cd: 改变当前目录
- copyFromLocal: 拷贝本地文件到Hadoop文件系统
- copyToLocal:从Hadoop文件系统拷贝到本地
- cp: 复制
- fs: 访问Hadoop的文件系统脚本hadoop fs
- ls: 列出文件
- mkdir: 创建目录
- mv: 移动文件或目录
- pwd:当前路径
- rm: 删除文件或目录
- rmf: 强制删除文件或目录
Hadoop MapReduce:
- kill: 杀掉一个MapReduce作业
实用工具:
- clear:清除Grunt的屏幕
- exec:在一个新的grunt中运行脚本
- help: 帮助命令
- history:查看当前grunt session的历史命令
- quint(\q):退出解释器
- run: 在当前的grunt shell中运行脚本
- set:设置Pig参数或MapReduce作业的属性
- sh:在grunt中运行shell命令
文件系统的命令可以对任何Hadoop文件系统进行操作,很像hadoop fs,他们都是对Hadoop中FileSystem接口进行封装。在Pig中,可以通过fs命令运行hadoop fs的任何命令,例如:
grunt> fs -lsgrunt> fs -help
具体使用哪个文件系统,由hadoop core site的fs.defaultFS属性决定。这些命令都很直白与LINUX或者hadoop fs非常类似,除了set这个命令。set用于控制Pig的行为。例如:
grunt> set debug on
另外job.name参数用于设置作业的名称,在YARN的管理界面中展示(前面可以看到相应的截图)。如果是以脚本的形式运行,则脚本的文件名称作为作业名称。
上述中的exec和run命令用于运行pig脚本。不同之处在于,exec命令在一个新的grunt shell中运行脚本,结束之后脚本中定义的所有别名(aliases)就不可用。如果使用run运行,可以认为是把pig脚本中的命令当做是手动输入的,所以的历史命令都是可以看到的。例外的是,如果脚本中使用了前面提到的multiquery execution,则只能使用exec运行。
Pig缺乏原生的控制流支持,通常的做好是在其他语言中控制程序运行逻辑,调用Pig脚本。例如在Python中实现控制流。Pig脚本嵌入到宿主语言中,使用compile-build-run的API执行pig脚本,提取执行结果。嵌入式的Pig程序总是运行在JVM中,针对不同的脚本选用对应的执行引擎,例如Python的Jython,JS的Rhino。
3.7 表达式
表达式计算被返回一个值,可以嵌入到Pig语句中。下面列出了Pig的一些表达式:
| 类别 | 表达式 | 说明 | 例子 |
|---|---|---|---|
| 字面量 | Literal | 常数值 | 1.0 , '1' |
| 基于位置的字段 | $n | $0 | |
| 基于名称的字段 | f | year | |
| 全称字段 | r::f | relation r的字段f | A::year |
| 投影 | c.$n,c.f | 容器(relation,bag,tuple)中的字段 | records.$0,records.year |
| Map查找 | m#k | map中k对应的值 | items#'Coat' |
| 转换 | (t) f | 将字段f转换为类型t | (int)year |
| 算数 | x+y,x-y,x*y,x/y,x%y,+x,-x | 数学运算 | $1+$2,+1,-1 |
| 条件判断 | x?y:z | 三元操作 | quality == 0 ? 0 :1 |
| 条件判断 | CASE | 多条件分支,类似SQL | CASE q WHEN 0 THEN 'good' ELSE 'bad' END |
| 比较操作 | x == y ,x != y | quality == 0 | |
| x >y ,x<y | quality>=0 | ||
| x matches y | 正则表达式匹配 | quality matches '[01459]' | |
| x is null | temperature is null/ is not null | ||
| 布尔值 | x OR y | q ==0 OR q ==1 | |
| x AND y | |||
| NOT x | NOT q matches '[01459]' | ||
| IN x | 成员关系 | q in ( 0,1,4,5,9) | |
| 函数 | fn(f1,f2,...) | 在字段f1,f2上调用函数fn | isGood(quality) |
| Flatten | FLATTEN(f) | 嵌套内容移动到外层 | FLATTEN(group) |
3.8 Pig数据类型
前面我们遇到了简单的int类型,chararry类型,这里进一步讨论。Pig的boolean,int,long,float,double,biginteger,bigdecimal和Java中完全一样。另外还有字节数组bytearray,字符数组chararray,时间类型datetime。Pig没有java中byte,short,char对应的类型,这些可以使用int或者chararray表示。Pig另外支持tuple,bag,map三种嵌套结构。所有Pig数据类型如下:
| 类别 | 类型 | 描述 | 例子 |
|---|---|---|---|
| 布尔 | boolean | true/false | true |
| 数值 | int | 32为带符号整数 | 1 |
| long | 64位带符号整数 | 1L | |
| float | 32位浮点数 | 1.0F | |
| double | 64位浮点数 | 1.0 | |
| biginteger | 任意精度的整数 | '1000000000' | |
| bigdecimal | 任意精度的有符号小数 | '0.1111100000000000001' | |
| 文本 | chararray | UTF-16格式的字符数组 | 'a' |
| 二进制 | byetearray | 字节数组 | 字面量无法表达 |
| 时间 | datetime | 带时区的日期和时间 | 字面量无法表达,使用内置的ToDate |
| 复杂类型 | tuple | 任意类型的字段序列 | (1,'name') |
| bag | 无序的元组集合,可以重复 | {(1,'name'),(2)} | |
| map | map,key必须为字符数组,value可以任意类型 | ['a'#'name'] |
复杂类型通常从文件中构建或者relation操作之后的结果。Pig提供了内置的TOTUPLE,TOBAG,TOMAP函数,用于转换为对应的类型。
relation和bag在概念上是一样的,都是表示无序的元组集合,但是还是有一些不一样。relation是顶层结果,但是bag必须被包含在一个relation中。不能直接从bag创建relation,下面的语句是错误的:
A = {(1,2),(3,3)};
relation不能像bag那个直接通过投影转换为另一个relation:
B = A.$0; -- ERROR
要达到这样的效果,需要使用relational operator:
B = FOREACH A GENERATE $0;
3.9 Schema
Pig的schema运行我们指定relation为特定的结构,为字段指定名称和类型。Pig设计用于处理纯输入文件(不带类型信息),所以我们可以为同样的数据指定不同的schema。不同于SQL中事先定义Schema,Pig中的Schema可以在数据处理过程中定义。前面接触到的AS中定义了Schema:
grunt> records = LOAD "input/path"AS (year: int ,temperature : int ,quality:int);grunt> DESCRIBE records;records: {year: int ,temparaturn:int ,quality:int}
如果我们省略类型信息,则默认为bytearray:
grunt> records = LOAD "input/path"AS (year,temperature:int ,quality)grunt> DESCRIBE records;records: {year:bytearray,temperature:int,quality:bytearray}
也可以完全不指定schema:
grunt> records = LOAD "input/path"grunt> DESCRIBE records;Schema for records unknown;
这时候relation中的字段可以通过位置类引用,例如$0,$1.字段类型默认为bytearray:
grunt> projected_records = FOREACH records GENERATE $0 , $1 , $2;grunt> describe projected_records;projected_records: {bytearray ,bytearray ,bytearray}
虽然省略类型信息很方便,但是明确指定类型有利于提供清晰度和Pig的执行效率,因此一般推荐指定数据类型。
3.9.1 使用Hive Table和HCatalog
虽然在脚本中声明schema很方面,但是很难复用schema,在多个地方重复声明Schema会使得代码难以管理。Hive的组件HCatalog为解决这个问题提供了一种方案,通过提供Hive metastore的访问接口,Pig查询可以通过名字来引用Schema。看一个例子:
% pig -useHCataloggrunt> records = LOAD "records" USING org.apache.hcatalog.pig.HCatLoader();grunt> DESCRIBE records;records: P{year:chararray, temperature:int,quality:int}grunt> DUMP records;
通过将数据载入到名为records的Hive表,Pig就可以访问表的schema和数据,如上代码所示。
3.9.2 校验和null
在SQL中 ,如果插入的数据类型和schema声明的数据类型不一样,将会失败。但是在Pig中,如果无法将值转换成Schema中声明的数据类型,会采用null作为替代值。例如我们有下列的数据:
1950 0 11950 22 11950 e 1
在温度这一栏上,有个非整数的e。我们载入数据的时候声明温度为int:
grunt> records = LOAD "input/path"AS (year:int ,temperature:int ,quality:int);grunt> DUMP recods;(1950,0,1)(1950,22,1)(1950,,1)
Pig会针对这个情况给请警告信息,但是不会终止整个程序。在大型的数据集中,部分数据损坏或者格式错误是很正常的。通过在载入数据的时候做容错(自动转化为null),我们可以针对这些数据作进一步的处理:
grunt> corrupt_records = FILTER records BY temperature is null;grunt> DUMP corrtpt_recods;(1950,,1)
为了统计各种类型的记录数,我们可以这么做:
grunt> grouped = GROUP corrupt_records ALL;grunt> all_grouped = FOREACH grouped GENERATE group , count(corrupt_records);grunt> DUMP all_grouped;(all,1)
另一种常用的处理方式是使用SPLIT将数据切分为2部分,即2个relation。
grunt> SPLIT records INTO good_records IF temperature is not null, bas_records OTHERWISE;grunt> DUMP good_recods;grunt> DUMP bad_records;
但是如果我们没有明确声明字段对应的类型,这时候非法值会被当做bytearray,而不会作为null。为可能损坏的字段声明类型通常是好的实践方式。
通过元组中字段的个数来过滤也是一种方式:
A = LOAD "input/path";/** ( 2, tie)* (3)*/B = FILTER A BY SIZE(TOTUPLE(*)) > 1;/** (2,tie)*/
上面的语句会过滤掉包含空值(有值的字段数量小于等于2)的记录。
3.9.3 模式合并
在Pig中,我们经常不会对整个数据流过程中的所有relation声明模式。这时候Pig会根据其输入推断模式。例如LIMIT操作返回的relation和原来的Schema一样。其他像UNION操作试图合并多个relation,如果因为字段数量不同或者类型不兼容导致无法合并Schema,UNION之后的Schema为unknown。
relation的Schema可以通过DESCRIBE命令来查看,如果想要重新定义relation的Schema,可以使用FOREACH GENERATE和AS从句来完成。
3.10 函数
Pig中有4类函数:
1) Eval函数
Eval函数接受一个或多个表达式,返回另外一个表达式。例如内置的MAX函数,返回bag中最大的条目。有些函数时聚合函数,作用域bag类型的数据,输出标量值,MAX函数也是聚合函数。
2) Filter函数
一类特殊函数,其返回值为boolean,也可以称为Predicate函数。Filter函数通常用于过滤数据,但是也可以用于表达式或者其他操作。例如Pig内置的IsEmpty函数用于判断bag或者map是否有元素存在。
3) Load函数
Load函数定义如何从外部存储中将数据载入到relation。
4) Store函数
定义如何将relation保存到外部存储。Load和Store通常采用相同类型实现,例如PigStorage用于加载字段分隔的文件,同时可以把relation存储为相同的格式。
下表是Pig内置的部分函数:
| 类型 | 函数 | 描述 |
|---|---|---|
| Eval | AVG | 计算bag中条目的平均值 |
| CONCAT | 连接字节数组或字符数组 | |
| COUNT | 计算bag中非null的条目数 | |
| COUNT_STAR | 同COUNT,但是null值计算在内 | |
| DIFF | 计算两个bag的差集 | |
| MAX | 计算bag中的最大条目 | |
| MIN | 与MAX对应,计算bag中的最小条目 | |
| SIZE | 计算特定类型的大小,例如数值类型的大小总是1、字符数组的大小为字符数量、字节数组为字节数,对于容器类型(bag,tuple,map),返回条目的数量。 | |
| SUM | 计算bug条目之和 | |
| TOBAG | 将给定的每个表达式转化为tuple,然后加入到bag。同() | |
| TOKENIZE | 将字符数组切分为词语bag | |
| TOMAP | 转成为key-value map,同[] | |
| TOP | 取bag的top N | |
| TOTUPLE | 转换成一个元组,同{} | |
| Filter | IsEmpty | 配置容器数据类型是否为空 |
| Load/Store | PigStorage | 读写字段分隔的文本格式,每一行被拆分为字段并存储到一个元组,分隔符可指定 |
| TextLoader | 纯文本文件加载,一行对应一个只有唯一字段的元组,字段内容为行内容 | |
| JosonLoader,JsonStorage | Pig定义的JSON数据读写,每一行对应一个元组 | |
| AvroStorage | Avro数据文件读写 | |
| ParquetLoader,ParquetStorer | Parquet(一种列式文件格式)读写 | |
| OrcStorage | Hive ORCFile读取和写入 | |
| HBaseStorage | 从HBase中载入数据到relation,将relation存入到HBase |
其他函数库
如果Pig内置的函数满足不了需求,需要自己定义函数,即UDF。但是在自己动手之前,值得到Piggy Bank这个函数库看看是否有你需要的。例如Piggy Bank中就有载入CSV文件的函数,其他像Sequence File,XML文件等,也都有对应的函数。Piggy Bank作为一个Jar包,包含在Pig的发行版本中。无需任何配置即可使用。
Apache DataFu是另一个丰富的Pig函数库。除了一些实用函数外,还包括基础统计、抽样、哈希相关的函数,另外有一些事跟web数据相关的,例如链接分析。
3.11 宏
宏用于定义一组相关的Pig Latin代码。例如,我们可以定义一个宏,用于对relation进行分组,然后找出每一组中的最大值:
DEFINE max_by_group(X,group_key,max_filed) RETURNS Y {A = GROUP $X BY $group_key;$Y = FOREACH A GENERATE group , MAX($X.$max_filed);}
这个宏的名称为max_by_group,X、Y分别为输入输出relation,定义了两个字段名group_key和max_filed。在宏的body内,参数和返回值通过$引用,例如$X,$group_by。使用宏的方式如下:
maxTemps = max_by_group(filtered_records,year,temperature);
运行时,Pig会使用宏定义展开宏。展开后的代码如下:
macro_max_by_group_A_0 = GROUP filtered_records BY year;maxTemp = FOREACH macro_max_by_group_A_0 GENERATE group , MAX(filtered_records.(temperature));
展开是,参数和返回值的被替代了,为了避免冲突,宏内部的别名被替换,参数引用不需要再有前缀。要展开宏,在启动pig时需要传递-dryrun参数。
宏经常在单独的pig脚本宏定义,例如我们把上述的宏定义单独放在max_temp.macro的文件中,在使用的时候使用IMPORT导入:
IMPORT 'path/to/your/max_temp.macro'
4. 用户自定义函数UDF
Pig提供了灵活的UDF供扩展,除了可以使用Java语言编写UDF外,还可以使用Python,JS,Ruby,Groovy等语言。我们这里以java为例:
4.1 Filter UDF
前面我们使用下面的代码来过滤天气数据中的脏数据:
filtered_records = FILTER records BY temperature != 9999 AND quality in (0,1,4,5,9);
现在我们把quality的判断逻辑拆分出来作为一个函数,最后结果如下:
filtered_records = FILTER records BY temperature != 9999 AND isGood(quality);
这么一来,代码更加紧凑,同时更方便以后复用逻辑,类似于重构中的提取方法。
Filter UDF都是FilterFunc的子类,而FilterFunc本身又是EvalFunc的子类。EvalFunc类定义如下:
public abstract class EvalFunc<T>{public abstract T exec(Tuple input) throws IOException;}
唯一的方法定义exec接受一个元组,返回泛型类型的值。对于FilterFunc,T是布尔值,所以exec在元组满足特定条件(不需要被丢掉)时返回true。为了实现对quality的过滤,我们实现一个FilterFunc的子类:
public class IsGoodQuality extends FilterFunc{@Overridepublic Boolean exec(Tuple tuple) throws IOException{if (tuple == null || tuple.sie == 0){return false;}try {Object object = tuple.get(0);if ( object == null){return false;}int i = (Integer) object;return i == 0 || i == 1 || i ==4 || i == 5 || i ==9;} catche ( ExecException e){throws new IOException(e);}}}
写完之后,编译该类到jar包,然后在Pig中注册:
grunt> REGISTER pig-examples.jar
注意jar包没有双引号。注册之后如下使用:
filtered_records = FILTER records BY temperature != 99 AND me.lin.IsGoodQuality(quality);
Pig把函数名称作为类名,加载对应的类,这也是为什么函数名是大小写敏感的。在分布式集群中运行时,Pig会确保JAR包分发到相应的集群节点上。内置的函数工作方式完全一样,但是会自动加上默认包名,因此无需使用完整的类名。例如,内置的函数MAX的实现在org.apache.pig.builtin.MAX类,我们调用的时候,只需MAX。
为了避免每次都是用全称,可以把自定义的包名加入到命令行参数-Dudf.import.list=me.lin,另一种方式是为这个类定义一个别名:
grunt> DEFINE isGood me.lin.IsGoodQuality();
当需要多次使用一个UDF时,这种定义很方便。在你需要向UDF的构造函数传递参数时,这种定义甚至是必须的。如果经常要使用这些定义,可以把注册Jar包和别名定义的代码加入到用户home目录中的.pigbootup文件,这个文件在每次启动pig的时候会被执行。
如果我们明确定义了quality字段为int类型,上面的UDF工作得很好,但是如果没有定义,quality默认的类型为bytearray,对应到Java API中的DataByteArray类,这个类不是Integer,在强制转换的时候会失败,导致UDF无法运行。
一种解决访问是在exec方法中进行转换。但是有更好的方式来告诉Pig我们期望函数的输入类型。EvalFunc的getArgToFuncMapping()方法用于这个目的。我们重写这个方法,告诉Pig我们希望函数传入的是整数:
@Overridepublic List<FuncSpec> getArgToFuncMapping() throw s FrontendException{List<FuncSpec> funcSpecs = new ArrayList<FuncSpec>();funcSpecs.add(new FuncSpec(this.getClass().getName(),new Schema(new Schema.FieldSchema(null,DataType.INTEGER)));return funcSpec;}
该函数返回的FuncSpec列表对应传入的tuple参数中的各个字段,在我们的例子中自有1个字段,所有我们只包含一个FuncSpec。当函数被调用时,Pig会尝试将传入的参数转化为Integer,如果无法转换,则传入null给exec,此时方法总是返回false,这是符合逻辑的。
4.2 Eval UDF
Eval是Filter UDF的通用版,看下面这个例子,对输入进行trim操作:
public class Trim extends PrimitiveEvalFunc<String,String>{@Overridepublic String exec(String input){return input.trim();}}
我们基于EvalFunc的子类PrimitiveEvalFunc来实现UDF,泛型参数定义了输入和输出的类型。这个例子中,返回的是字符串类型,Pig会自动转换成chararray,但是对于更复杂的输出,需要指定输出的Schema,因为返回值会作为新的relation参与到后续的数据流程中,定义Schema是有必要的。例如:
B = FOREACH A GENERATE myUDF($0);
这里B的Schema就由myUDF的输出Schema来决定。为了指定输出Schema,实现对应分的outputSchema方法。
Java语言的强大在于其丰富的类库,因此我们很有可能想使用第三方或者Java自带的类库来作为UDF的实现,而不用重复去定义UDF。动态调用(Dynamic invokers)提供了这种可能性。这种方式是基于反射来实现的,因此方便的同时会牺牲一定的性能,尤其是在大型数据集中重复调用UDF时,性能影响更加明显,这时候提供一个特定的UDF实现是明智的。
下面的例子展示如何使用Apache Common中的字符串工具类来实现前面的trim操作:
grunt> DEFINE trim InvokeForString('org.apache.commons.lang.StringUtils.trim','String');grunt> B = FOREACH A GENERATE trim(fruit);
因为返回结果是字符串,所以我们使用的是InvokerForString,还有相应的InvokerForInt,InvokerForLong等。第一个参数是方法的完全限定名,第二个是使用空格分隔的方法参数类。这里只有一个字符串类型,所以是'String'。
4.3 Load UDF
我们实现一个UDF,用于从输入文件中每行特定位置提取作为relation的字段,其最终使用方式如下:
records = LOAD 'input/path.txt' USING me.lin.CutLoadFunc('16-19,88-92,93-93') AS (year:int,temperature:int,quality:int);
其中CutLoadFunc构造函数传入的是表示各字段的位置,例如16-19的字符作为第一个字段的内容,同时定义了Schema。具体实现如下:
package me.lin;public class CutLoadFunc extends LoadFunc{private static final Log LOG = LogFactory.getLog( CutLoadFunc.class) ;private final List<Range> ranges;private final TupleFactory tupleFactory = TupleFactory. getInstance( ) ;private RecordReader reader;public CutLoadFunc( String cutPattern) {ranges = Range.parse( cutPattern) ;}@Overridepublic void setLocation( String location, Job job)throws IOException {FileInputFormat.setInputPaths( job, location) ;}@Overridepublic InputFormat getInputFormat( ) {return new TextInputFormat( ) ;}@Overridepublic void prepareToRead( RecordReader reader, PigSplit split){this.reader = reader;}@Overridepublic Tuple getNext( ) throws IOException {try {if ( ! reader. nextKeyValue( ) ) {return null;}Text value = ( Text) reader.getCurrentValue( ) ;String line = value.toString( ) ;Tuple tuple = tupleFactory.newTuple( ranges.size( ) ) ;for ( int i = 0; i < ranges.size( ) ; i++) {Range range = ranges.get( i) ;if ( range.getEnd( ) > line.length( ) ) {LOG.warn( String.format("Range end ( %s) is longer than line length ( %s) ",range.getEnd( ) , line.length( ) ) ) ;continue;}tuple.set( i, new DataByteArray(range.getSubstring(line)) );}return tuple;} catch ( InterruptedException e) {throw new ExecException( e) ;}}}
核心实现是如何将每一行数据转化为Pig中的元组,Pig在载入数据时,会将LOAD命令的参数传递给setLocation。这里使用的是TextInputFormat读取数据,所以我们直接把这个值设置给FileInputFormat。
Pig接着调用getInputFormat方法,为每个split创建一个RecordReader,跟MapReduce一样。接着Pig把RecordReader传递给prepareToRead方法,我们这里保存引用,以便在getNext中使用。
接着Pig将重复调用getNext方法,直到split中的最后一条记录,这时候返回null值表明没有更多数据。这个方法中实现了行内容到元组的转换,我们借助TupleFactory类来实现。
4.4 使用Schema
如果用户在LOAD命令中指定了Schema,我们还需要将数据转化成对应的类型。但是在Pig中,这些转换工作是懒性操作的,执行这个函数的时候并不会真正的转换。因此loader总是要实现为bytearray的数据类型,对应到Java API中的DataByteArray。但是通过重写getLoadCaster方法,我们将转换的逻辑以LoadCaster的形式告知Pig。在这个例子中我们没有覆盖这个方法,因为默认的实现返回的是Utf8StorageConverter提供了UTF-8数据到Pig数据类型的转换。
有些情况下,Loader的实现就能决定载入数据的Schema,而不是用户指定。例如我们可以从XML的元数据中来得到Schema。这时候,Load函数需要实现LoadMetaData接口,提供Schema给Pig运行时。但是如果用户通过AS从句指定了Schema,其优先级高于LoadMetaData提供的Schema。
Load函数可以实现LoadPushDown接口,来获取用户想要查询哪些字段,这在某些性能优化场合非常有用。通过获取查询的字段,Loader只加载用户需要的字段。
5. 数据处理操作
5.1 加载和保存数据
前面我们已经看了很多加载数据的例子,使用LOAD命令从外部将数据加载到relation。保存计算结果也很直接,下面的例子使用PigStorage保存分号分割的纯文本:
STORE A INTO 'out' USING PigStorage(':');cat out
5.2 过滤数据
载入数据到relation之后,下一步通常是过滤到我们不感兴趣的数据,这样可以避免大量数据在后续的流程中占用太多带宽。前面我们已经用了很多次FILTER操作来过滤数据。
FOREACH ... GENERATE
foreach参数作用域relation的每一行上,可以移除字段或者新增字段:
B = FOREACH A GENERATE $0 , $2+1 ,'Constant';
这个例子保留了第一个字段,删除了第二个字段,第三个字段做了运算,同时新增了常数字段。
FOREACH支持嵌套的GENERATE操作,下面是一个综合的例子:
-- year_stat.pigREGISTER pig-examples.jar;DEFINE isGood me.lin.IsGoodQuality();records = LOAD 'input/ncdc/all/19{1,2,3,4,5}0*'USING me.lin.CutLoadFunc('5-10,11-15,16-19,88-92,93-93')AS (usaf:chararray , wban:chararray,year:int,temperature:int,quality:int);grouped_records = GROUP records BY year PARALLEL 30;year_stats = FOREACH grouped_records {uniq_stations = DISTINCT grouped_records.usaf;goog_records = FILTER reords BY isGood(quality);GENERATE FLATTEN(group),COUNT(uniq_stations) AS station_count,COUNT(good_records) AS goo_record_count ,COUNT(records) AS record_count;}
一开始注册Jar包,定义别名。然后使用我们自定义的Load函数载入数据。GROUP对载入的数据进行分组,其中PARALLEL 30指定了Reducer的数量。接着针对每一个分组进行FOREACH操作,不同于前面出现过的FOREACH,直接使用GENERATE生成最终的Schema。这里使用了嵌套的结构,执行了3个步骤:一次组内DISTINCT,一次组内FILTER,最后结合前两步生成最终的SCHEMA。
最终的数据格式像这样:
(1920,8L,8595L,8595L)(1930,121L,89245L,89262L)
5.3 STREAM
Pig的Stream操作允许我们使用外部的程序或者脚本处理relation,这与Hadoop Stream为MapReduce提供的功能非常类似。Hadoop Stream使用标准的输入输出在框架和外部map/reduce应用(例如Python写的)之间交换数据。Pig的Stream类似,它使用PigStorage的序列化来对接标准的输入输出流,例如从标准输出流中读取数据,反序列化为relation。看一个例子:
grunt> C = STREAM A THROUGH `cat -f 2`
这个例子针对relation A中的每一条记录,输出到标准输入,cat命令从标准输入读取记录,并将处理后的数据写到标准输出,Pig Stream从标准输出中获取计算结果。序列化的方式可以通过扩展PigStreamingBase来来实现自定义。
Pig Straming在处理自定义的处理脚本时非常强大,可以使得业务逻辑非常独立,容易测试,缩短开发周期。例如前面对quality的判断,使用Python来写的话:
#!/usr/bin/env pythonimport reimport sysfor line in sys.stdin:(year,temp,q)=line.strip().split()if ( temp != "9999" and re.match("[01459]",q));print "%s\t%s" % (year ,temp)
要对这个功能进行测试,非常容易,而不像Java API那样繁琐,能够跑通一个测试例需要费很大的功夫。要使用这个自定义函数,脚本需要上传到集群中,使用下面的语句来完成:
DEFINE is_goog_quality `is_good_quality.py`SHIP('path/to/your/python/file.py');
然后使用下面语句:
records = LOAD("input/path") AS (year:chararray,temperature:int,quality:int);filtered_records = STREAM records THROUGH is_good_qualityAS (year:chararray,temperature:int);
5.4 分组和关联
5.4.1 JOIN
MapReduce中,要进行关联操作可不简单。而Pig内置了join操作,使得关联非常简单,虽然相比SQL,在Pig中使用关联的频率低得多。
考虑有如下两个relation:
grunt> DUMP A;( 2, Tie)( 4, Coat)( 3, Hat)( 1, Scarf)grunt> DUMP B;( Joe, 2)( Hank, 4)( Ali, 0)( Eve, 3)( Hank, 2)
现在我们根据数值字段进行关联:
grunt> C = JOIN A BY $0 , B BY $1;grunt> DUMP C;( 2, Tie, Hank, 2)( 2, Tie, Joe, 2)( 3, Hat, Eve, 3)( 4, Coat, Hank, 4)
这些典型的内关联,如果关联的两个relation中,一个非常大,另一个比较小,可以存放在内存中。这时候应该使用fragment replicate join这种特殊的关联类型。这种关联会将小的数据集分发到所有Mapper中,在map端完成大数据集(fragmented,分块过的)的关联。要使用这种关联,需要在语句中指定:
C = JOIN A BY $0 , B BY $1 USING 'replicated';
其中第一个relation A是大的那个数据集,紧接着跟着一个或多个小的数据集,这些数据集一起可以放在内存中。
Pig也支持外关联:
C = JOIN A BY $0 LEFT OUTTER,B BY $1;
5.4.2 COGROUP
COGROUP在JOIN的基础之上进行了分组,返回的元组中,第一个值是分组的key,往后的值是来自关联表中key对应的bag。例如,A、B数据如下:
grunt> DUMP A;( 2, Tie)( 4, Coat)( 3, Hat)( 1, Scarf)grunt> DUMP B;( Joe, 2)( Hank, 4)( Ali, 0)( Eve, 3)( Hank, 2)
通过下面的语句进行COGROUP:
D = COGROUP A BY $0, B BY $1;
D结果如下:
(0 , {} , {(Alia,0)})(1 , {( 1, Scarf)},{})...
上述结果是外部join分组的结果,这是COGROUP默认的关联方式,也可以显式指定,上述语句等同于:
D = COGROUP A BY $0 OUTER, B BY $1 OUTER;
也可以指定内关联:
D = COGROUP A BY $0 INNER, B BY $1 ;
下面的例子统计每个天气检测站的最高气温:
-- max_temp_station_name.pigREGISTER pig-examples.jat;DEFINE isGood me.lin.IsGoodQuality();stations = LOAD('/input/ncdc/metadata/station-fixed-width.txt')USING me.lin.CutLoadFunc('1-6,8-12,14-42')AS ( usaf: chararray , wban:chararray, name:chararray);trimmed_stations = FOREARCH stations GENERATE usaf , wban, TRIM(name);records = LOAD 'input/ncdc/all/191*'USING me.lin.CutLoadFunc('5-10,11015,88-92,93-93')AS (usaf:chararray , wban:chararray, temperature:int , quality:int);filtered_records = FILTER records BY temperature != 9999 AND isGood(quality);grouped_records = GROUP filtered_records BY (usaf , wban) PARALLEL 30;maxTemps = FOREACH grouped_records GENERATEFLATTEN(group), MAX(filtered_records.temperature);max_temp_named = JOIN maxTemps BY (usaf ,wban), trimmed_records BY (usaf ,wban) PARALLEL 30;max_temp_result = FOREACH max_temp_named GENERATE $0 ,$1, $5,$2;STORE max_temp_result INTO 'max_temp_by_station';
核心逻辑是先找出每一组的最大值,然后根据usaf,wban关联名字的relation,找出对应的名称。这里名字的元数据量比较小,可以使用前面界面的fragement replicate join来进一步提高性能。
5.4.3 CROSS
Pig的叉积操作将第一个relation中的每一个元组,与第二个relation中的每一个元组关联。
C = CROSS A , B
叉积(向量积)产生的Relation可能会非常大,应该尽量避免使用这种操作。
5.4.4 GROUP
COGROUP对2个或者多个relation进行分组,GROUP则对一个relation进行分组。GROUP支持使用UDF作为key来分组。例如:
GRROUP A BY SIZE($1)
GROUP操作创建一个relation,第一个字段为分组的key,其别名为group。第二个字段是该key对应的bag。有2中特殊的分组,ALL和ANY。ALL分组将所有元组分为一组,组的key为all,可以把它当做分组函数为常数all的分组。注意没有BY:
GROUP A ALL;
ANY则将relation中的元组随机分组,在采用的时候这个方法很有用。
5.5 排序
Pig中的relation是无需的,可以使用ORDER操作来排序。
B = ORDER A BY $0 , $1 DESC;
上述先根据$0正序排列,再根据$1倒序。
但是在排序的relation上进行其他操作,Pig不对计算结果提供任何顺序保证。例如:
C = FOREACH B GENERATE *;
这里的结构与B完全一样,但是顺序不一定与B保持一致,使用DUMP或STORE操作C时,顺序是无法预测的。但是如果在排过序的relation上马上进行LIMIT操作,则返回的结果是有序的:
D = LIMTI B 2;
如果LIMIT比relation中的元组数量还多,则整个relation都返回。在数据处理中,应该尽可能早地使用FILTER或者LIMIT过滤不需要的数据,可以在性能上有所提升。
5.6 合并与分割
有时候我们想要把两个或多个relation合并为一个,这时候可以使用UNION语句,类似于SQL中的UNION操作,假设我们有如下两个Relation:
-- A(2,3)(1,2)(2,4)-- B(z,x,8)(w,y,1)
执行UNION:
C = UNION A , B;-- C(2,3)(z,x,8)(1,2)(2,4)(w,y,1)
由于Relation是无需的,所以UNION的结果也是无序的,也就是顺序不可预测。合并两个Schema不同的Relation是可能的,上面的例子就是这样。Pig会尝试合并两个Schema,如果两个Schema不兼容,则UNION的结构没有Schema,即unknown。
SPLIT是UNION的反方向,用于将一个relation分隔成多个。前面我们见过如下的例子:
SPLIT records INTOgood_records IF temperature is not null,bas_records OTHERWISE;
6.Pig最佳实践
在开发Pig应用时,有一些很实用的技巧,这里介绍几个。
6.1 并行度
在MapReduce中,并行度与数据集大小相匹配是很重要的。默认情况下,Pig为每1GB的输入数据分配一个Reducer,总数不超过999个。可以通过设置pig.exec.reducers.bytes.per.reducer属性来配置每个Reducer分配多少数据,最大Reducer数可以通过属性pig.exec.reducers.max来配置。
在Pig脚本中,可以使用PARALLEL从句指定reducer的数量:
-- 指定GROUP操作使用30个reducergrouped_records = GROUP records BY year PARALLEL 30;
也可以在grunt中设置默认的并行度:
grunt> set default_parallel 30
map任务数量由输入文件来控制,不受并行度的影响,默认为一个HDFS Block对应一个map任务。
6.2 匿名Relation
在Pig中,我们经常使用DUMP输出最近的一个relation,Pig有一个快捷方式执行前一个relation: @ 。下面的语句输出前一个relation:
DUMP @
另外可以使用=>语法创建一个没有别名的relation,此时只能通过@来访问:
=> LOAD "input/path"DUMP @
6.3 参数替代
使用同一个脚本,但是使用不同的参数,这个需求很常见。Pig运行我们在运行时传递参数给脚本,使用$前缀来标识参数。
-- max_temp_param.pigrecords = LOAD '$input' AS ......STORE maxTemps INTO '$output'
在运行脚本的时候,使用-param选项指定参数:
pig -param input=/user/home/... \-param output=/output/max \/path/to/your/file.pig
另外也可以把参数统一配置在文件中,然后使用-param_file选项指定:
#input fileinput = /user/home/...output = /output/max
运行的时候指定参数:
pig -param_file /path/to/your/file max_temp.pig
param_file选项可以重复多次,也可以组合param和param_file。如果同一个参数在多个地方定义,以最后一个为准。
参数的替换在脚本运行之前进行预处理。可以在运行脚本的时候指定-dryrun选项。在dry run模式下,Pig会执行参数替换和宏展开,生成参数替换后的脚本,但不会执行程序(dry run)。在运行之前,我们可以使用这种方式来检查脚本是否有问题。
6.4 动态参数
我们也可以在运行pig脚本时,使用命令动态配置参数,例如:
pig -param input=/user/home`data "+%Y-%m-%d"`out max_temp.pig
输入参数会根据当前时间动态生成。date命令的输出格式如下:

7.参考及阅读材料
本文来自《Hadoop权威指南》,阅读过程中整理而成,感谢作者。
