@BrandonLin
2016-07-30T18:13:12.000000Z
字数 3817
阅读 2845
Hive之数据查询
Hive
1. 排序和聚合
排序使用常规的ORDER BY来完成,Hive在处理ORDER BY请求时,并行排序,最终产生一个全局排序结果。如果全局有序不是必须的,那么可以使用Hive的非标准扩展SORT BY,它返回的是一个局部有序的结果,每个Reducer内部有序,每个Reducer产生一个有序的文件。
有时候我们想控制数据去往哪个Reducer以便进行下一步处理,这时候可以使用Hive的DISTRIBUTED BY操作。下面的语句中,年份相同的数据被分发到同一个Reducer,在Reducer内部进行排序:
FROM records2SELECT year,temperatureDISTRIBUTED BY yearSORT BY year ASC, temperature DESC;
下一步的处理就可以基于相同年份的数据被分组并排序这一点进行相应的操作,也可以将上述语句作为子查询嵌入。如果SORT BY和DISTRIBUTED BY的字段一样,可以简化为CLUSTER BY。注意区别于分桶中的CLUSTERED BY.
2. MapReduce脚本
使用类似于Hadoop Streaming的方式,TRANSFORM,MAP,REDUCE从句使得我们可以在Hive中调用外部程序(脚本)。例如,我们使用下面的Python脚本来过滤脏数据:
#!/usr/bin/env pythonimport reimport stsfor line in sys.stdin:(year,temp,q) = line.strip().split()if ( temp != "9999" and re.match("[01459]" ,q)):print "%s\t%s" % (year,temp)
上面的脚本非常独立,我们很容易测试和开发。接着如下使用这个脚本:
ADD FILE /user/root/python/is_good_quality.py;FROM recordsSELECT TRANSFORM(year,temperature ,quality)USING 'is_good_quality.py'AS year , temperature
使用类似于ADD JAR的ADD FILE添加脚本到Hive中,Hive进一步分发到集群中。该语句将表中的三个字段STREAMING到标准的输入,并接受Python处理后的标准输出,解析为year和temperature字段。
下列语句则综合了Map脚本和Reduce脚本:
FROM(FROM records2MAP year ,temperature , qualityUSING 'is_good_quality.py'AS year , temperature) map_outputREDUCE year , temperatureUSING 'max_temperature_reduce.py'AS year , temperature
3. 关联
使用Hive进行关联操作,相比于原生的MapReduce来说,容易得多。
内关联
最简单的关联操作是内关联。假设有如下两个简单表:
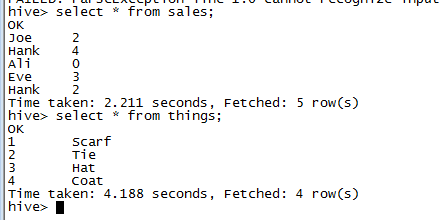
关联操作JOIN:
select *from sales join things on (sales.id=things.id)
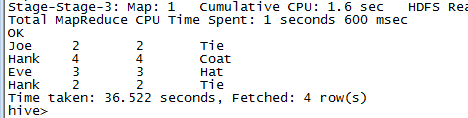
Hive只支持相等关联,也就是说join的条件判断中只能使用相等性比较。JOIN条件判断可以使用AND列出多个条件,也可以关联多个表。上面的语句相当于:
select sales.* , things.*from sales,thingswhere sales.id=thing.id
一个关联操作同一个MapReduce作业实现,但是多个关联时,使用的作业数可以少于关联数量,使用相同字段进行关联的可以在同一个作业中完成,EXPAIN可以用于查看关联操作使用了多少个作业:
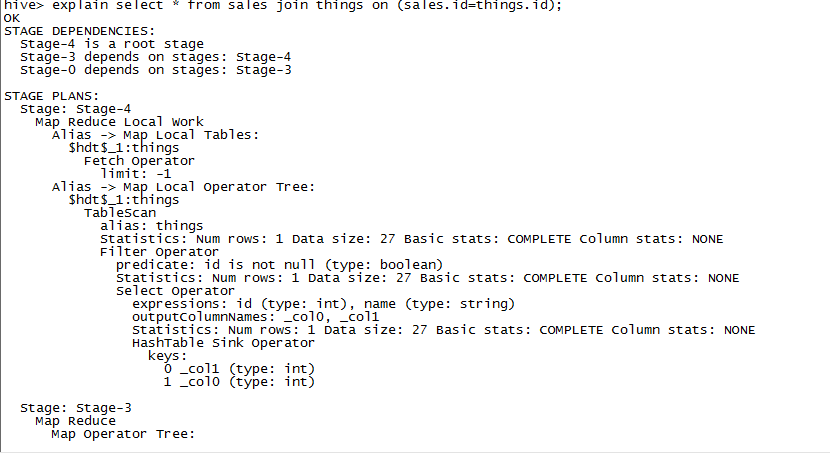
EXPLAIN EXTENED可以获取更相信的作业信息。
外关联
跟SQL中的外关联一样,Hive提供左管理和右关联,全关联:
- Left Join:
select *from sales left outer join things on (sales.id=things.id)<div class="md-section-divider"></div>
- Right Join:
select *from sales right outer join things on (sales.id=things.id)<div class="md-section-divider"></div>
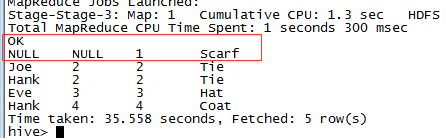
- Full Join
select *from sales full outer join things on (sales.id=things.id)<div class="md-section-divider"></div>
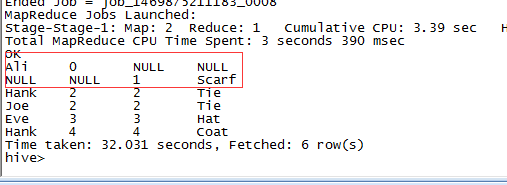
半关联
考虑这样一样子查询:
select *from thingswhere things.id in (select id from sales);<div class="md-section-divider"></div>
使用半关联可以达到一样的效果:
select *from things left semi join things on (sales.id=things.id)<div class="md-section-divider"></div>
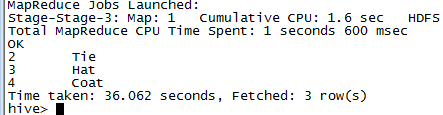
LEFT SEMI JOIN有一个限制,右边的表不能出现在select后边的语句中,只能出现在ON从句中。
Map关联
下面这个关联语句中:
select sales.* ,things.*from sales joins things on (sales.id=things.id)<div class="md-section-divider"></div>
如果有一个表足够小,可以放在内存中,例如这里的things元数据表。Hive可以将这个小的表载入到每个Mapper任务的内存中进行关联操作。称为map关联。
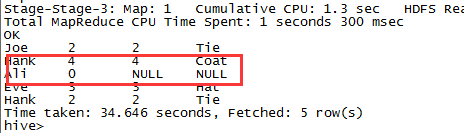
用于执行该作业的MapReduce只有Mapper,没有Reducer。因此在RIGHT 或者FULL OUTER类型的关联中,这种方式不起作用,因为这些情况下,只有在Reducer阶段对所有的输入进行聚合时才能判断是否真的没有匹配的记录。下图的LEFT关联中,从日志中我们可以看到没有启用Reducer:
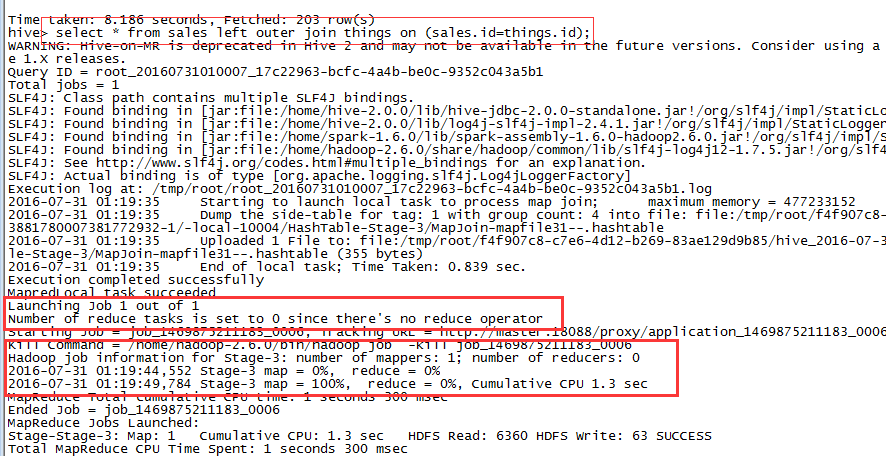
而在FULL JOIN中,启用了一个Reducer:
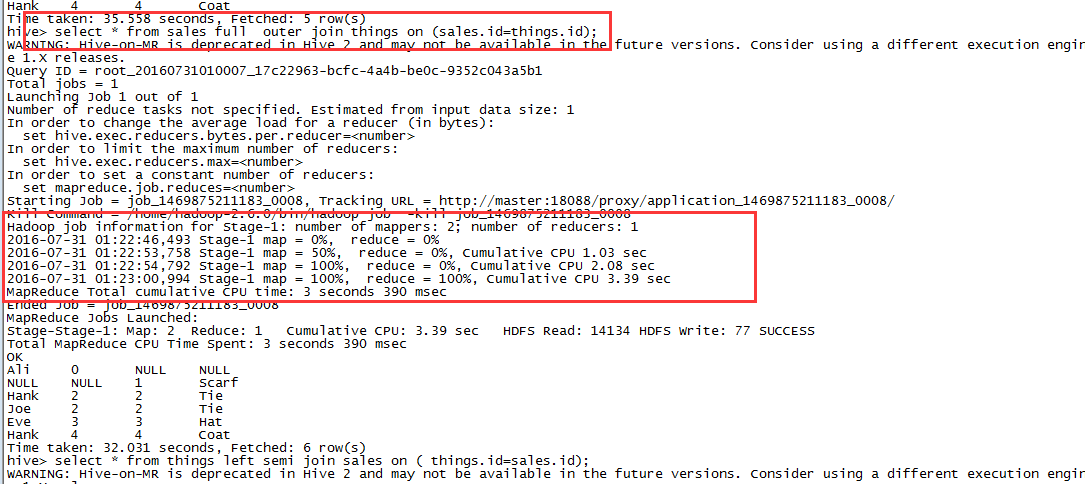
Map关联在分桶的表中可以得到进一步的提升,此时mapper只需读取对应右表中特定的bucket即可完成关联操作。要利用这种优化,需要设置hive.optimize.bucketmapjoin=true.
4. 子查询
子查询是指SELECT语句被嵌入到其他SQL语句中。Hive提供了对子查询的有限支持,运行在FROM、WHERE和SELECT中嵌入子查询。下面的语句在FROM中使用了子查询:
SELECT station, year , AVG(max_temperature)FROM(SELECT station ,year ,MAX(temperature) as max_temperatureFROM records2where temperature != 9999 and quality in (0,1,4,5,9)GROUP by station ,year) mtGROUP by station , year<div class="md-section-divider"></div>
子查询的结果需要给出名称,上述的mt表名用于外层查询。同时子查询中的字段也要给出名称,方便外层查询引用,例如max_temperature。
5. 视图
视图可以看成是通过SELECT定义的虚拟表,用于展示不同于内部存储的数据给用户,同时经常用于进行权限控制。
Hive中的视图没有物化到磁盘中,而不是在使用到视图的查询运行时,才执行视图查询。如果视图的数据经常被使用到,考虑使用CREATE TABLE ... AS SELECT创建一张表,存储视图的内容。我们使用视图来重写之前的查询:
create view valid_recordsASSELECT *from recordswhere temperature != 9999 and quality in (0,1,4,5,9)<div class="md-section-divider"></div>
视图创建后被保存到metastore中,但是不真正运行,show tables命令可以看到视图,可以使用DESCRIBE EXTENDED view_name查询视图的进一步信息,例如由什么样的SELECT创建而来。接着在视图的基础上创建另一个视图:
create view max_temperatures(station,year,max_temperature(asselect station,year,MAX(temperture)from valid_recordsgroup by station , year;<div class="md-section-divider"></div>
创建视图时显式指定了字段名,因为聚合字段Hive会自动创建诸如_c2之类的字段,也可以直接使用AS从句指定聚合后的字段名称。
最后我们从这个视图中查找最终结果:
select station ,year,avg(max_temperature)from max_temperaturesgroup by station,year;
另外,Hive的视图时只读的,因此无法通过视图更细底层的表数据。
