@CelesteGG
2019-07-10T22:33:54.000000Z
字数 16105
阅读 1980
图像特征与图像风格迁移
数字图像处理 CNN tensorflow 风格迁移
本文为数字图像处理课程论文的工作报告,将从特征提取和风格迁移两方面出发,将自己对数字图像处理中相关内容、神经网络处理图像特征和图像内容的算法进行梳理,之后详细介绍了其中对网络中各层特征可视化以及风格迁移具体实现的完整步骤。
- 图像特征简述
- 风格迁移简述
- CNN抽取图像特征
- CNN实现风格迁移
- 实现环境配置
- 模型各层可视化
- 风格迁移的实现
- 效果分析
- 小结
图像特征
图像特征主要有图像的颜色特征、纹理特征、形状特征和空间关系特征。
颜色特征是一种全局特征,描述了图像或图像区域所对应的景物的表面性质。
纹理特征也是一种全局特征,它也描述了图像或图像区域所对应景物的表面性质。但由于纹理只是一种物体表面的特性,并不能完全反映出物体的本质属性,所以仅仅利用纹理特征是无法获得高层次图像内容的。与颜色特征不同,纹理特征不是基于像素点的特征,它需要在包含多个像素点的区域中进行统计计算。
形状特征有两类表示方法,一类是轮廓特征,另一类是区域特征。图像的轮廓特征主要针对物体的外边界,而图像的区域特征则关系到整个形状区域。
空间关系,是指图像中分割出来的多个目标之间的相互的空间位置或相对方向关系,这些关系也可分为连接/邻接关系、交叠/重叠关系和包含/包容关系等。通常空间位置信息可以分为两类:相对空间位置信息和绝对空间位置信息。前一种关系强调的是目标之间的相对情况,如上下左右关系等,后一种关系强调的是目标之间的距离大小以及方位。
风格迁移
风格本质上是指在各种空间尺度上图像中的纹理,颜色和视觉图案,而内容是图像的高级宏观结构。
图像风格化,或者称图像风格迁移,往往是指让计算机自动完成图像风格的转移,将一张具有艺术特色的图像的风格迁移到一张自然图像上,使原自然图像保留原始内容的同时具有独特的艺术风格,如卡通、动漫、漫画、油画、水彩、水墨等风格。
传统的图像艺术风格化的方法,可以分为三类:基于笔触的风格化、基于纹理合成的风格化和对物理过程建模的风格化。
在早期的图像风格化研究中,由于纹理可以用图像局部特征的统计模型来描述,而与图像的内容以及其所处位置无关,因此研究者可以成功地用复杂的数学模型归纳和生成一些纹理特征。
但是这种方式的归纳和构建都是非常依赖于纹理的特性特征,而且每针对与一种纹理或者风格都需用重新进行复杂的统计和建模,十分繁琐。
因此进一步的,前人在神经网络中找到了更为巧妙的建模方式。
CNN对图像特征的抽取
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一 。卷积神经网络具有表征学习(representation learning)能力,能够按其阶层结构对输入信息进行平移不变分类(shift-invariant classification),因此也被称为“平移不变人工神经网络(Shift-Invariant Artificial Neural Networks, SIANN)。
1.CNN的结构
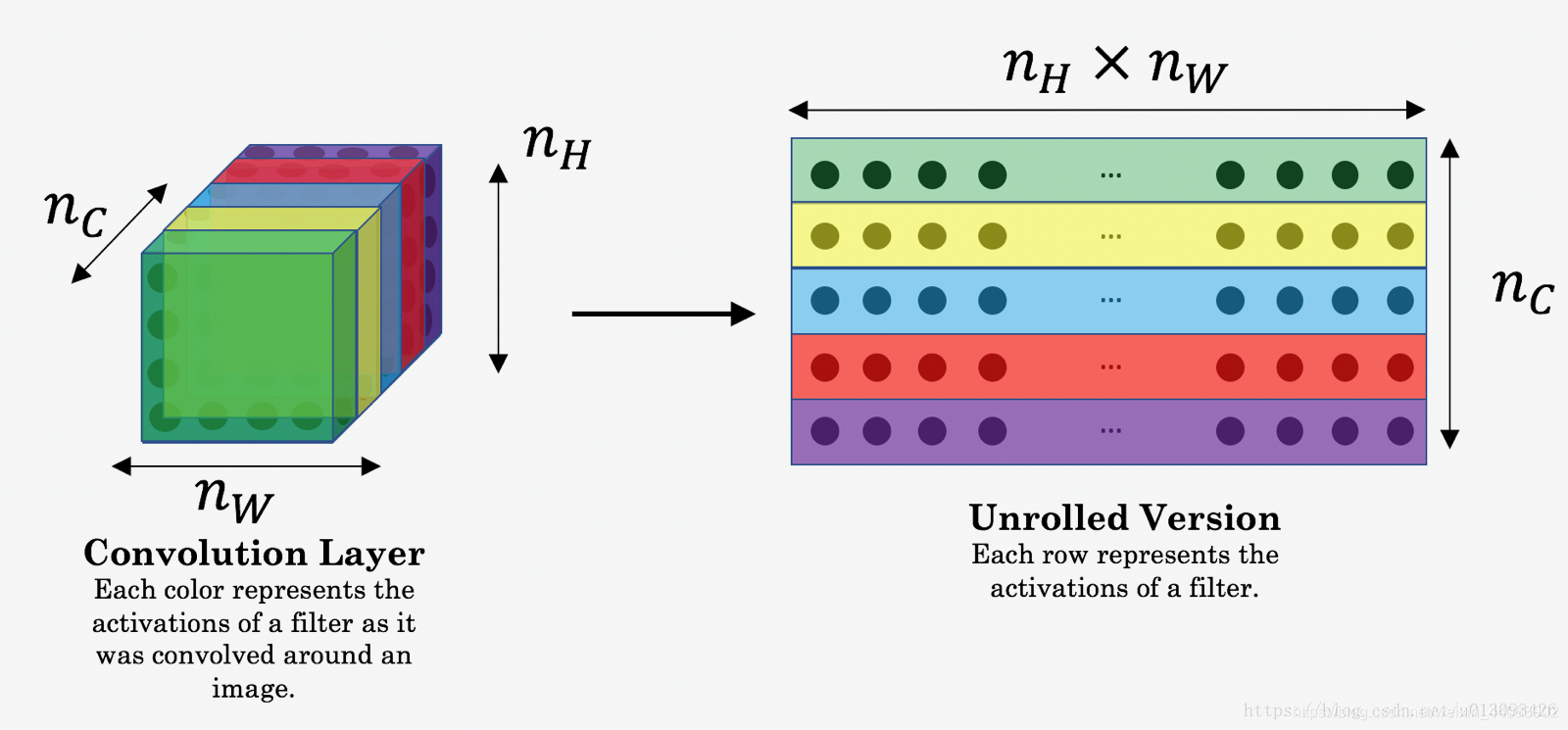
神经网络由不同的层组成,每一层都可以理解为一组图像滤波器(image filters),每一层都从输入图像提取特定特征。通过给定层输出就可以得到特征图(feature maps)。

在每个卷积层,数据都是以三维形式存在的。这个三维可以理解为二维图像和层数维度,也就是可以把它看成许多个二维图片叠在一起,其中每一层就是一个feature map。在输入层,如果是灰度图片,那就只有一个feature map;如果是彩色图片,一般就是3个feature map(红绿蓝)。层与层之间会有若干个卷积核(kernel),上一层和每个feature map跟每个卷积核做卷积,都会产生下一层的一个feature map。
2.卷积操作
假设有一个5*5的图像,使用一个3*3的卷积核(filter)进行卷积,得到一个3*3的矩阵,如下所示:
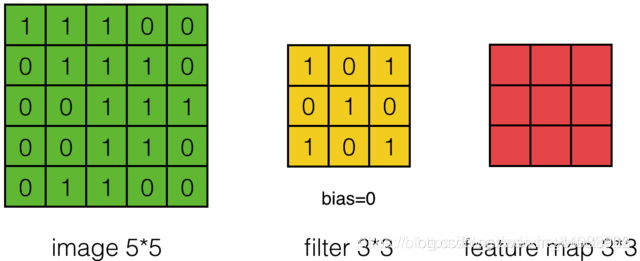
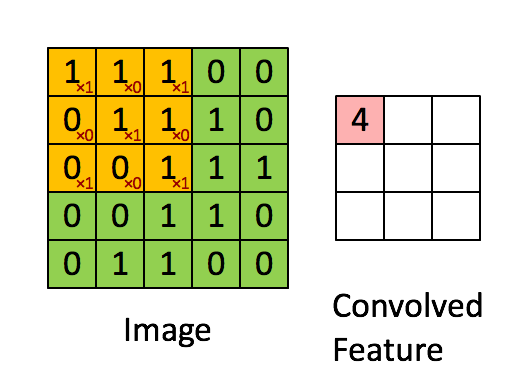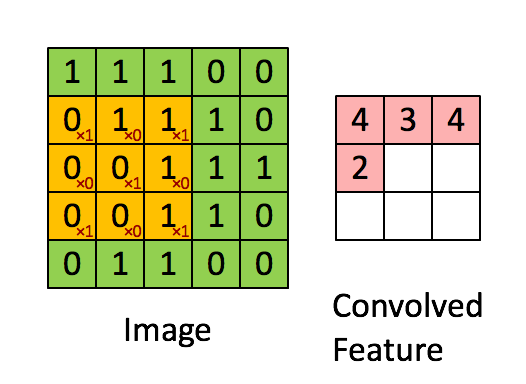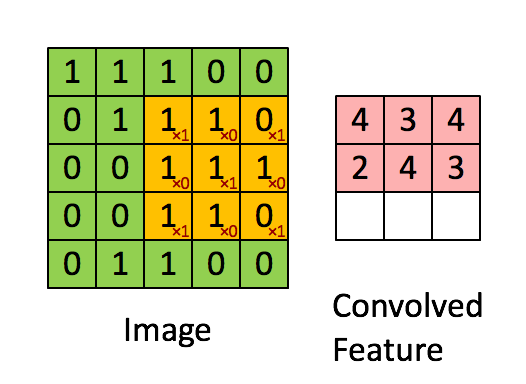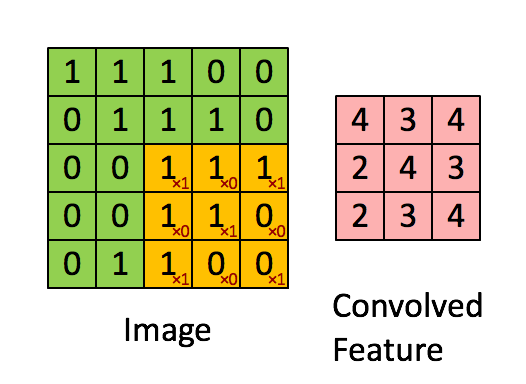
一个图像矩阵经过一个卷积核的卷积操作后,得到了另一个矩阵,这个矩阵就是特征映射(feature map)。每一个卷积核都可以提取特定的特征,不同的卷积核则提取出了不同的特征。
3.特征提取
下面通过一个简单的实例来说明图像的复杂特征的提取具体如何通过计算实现。
如下是个简单的识别命题,判断图中是否有X或O.。
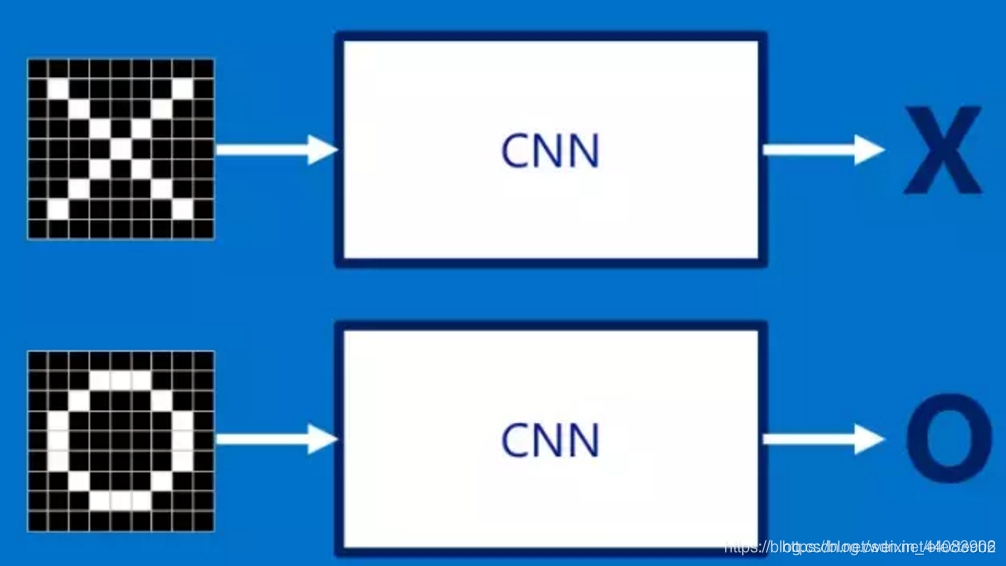
由前一节我们可知,对于CNN来说,它是利用卷积核一块一块地来进行比对。它拿来比对的这个“小块”我们就称之为Features(特征)。
标准的X-O识别似乎可以十分理想的通过某个卷积核就可以实现。
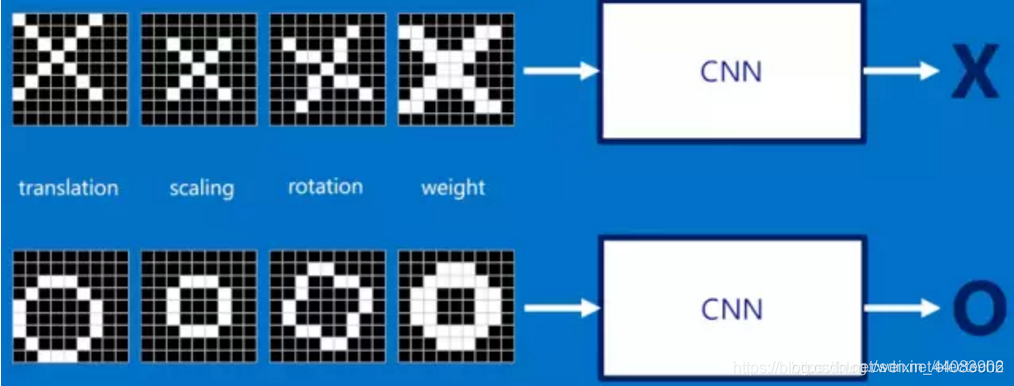
但如果图像旋转或者扭曲,问题就变得复杂起来。此时判断特征就需要不止一个卷积核来实现。
例如我们需要判断在一个随机图像中,“X”的图形特征是否存在。对于字母"X"来说,那些由对角线和交叉线组成的features基本上能够识别出大多数"X"所具有的重要特征。所以就可能需要如下三个卷积核。(像素值"1"代表白色,像素值"-1"代表黑色。)

现在给一张新的包含“X”的图像,CNN并不能准确地知道这些features到底要匹配原图的哪些部分,所以它会在原图中每一个可能的位置进行尝试,即使用该卷积核在图像上进行滑动,每滑动一次就进行一次卷积操作,得到一个特征值。
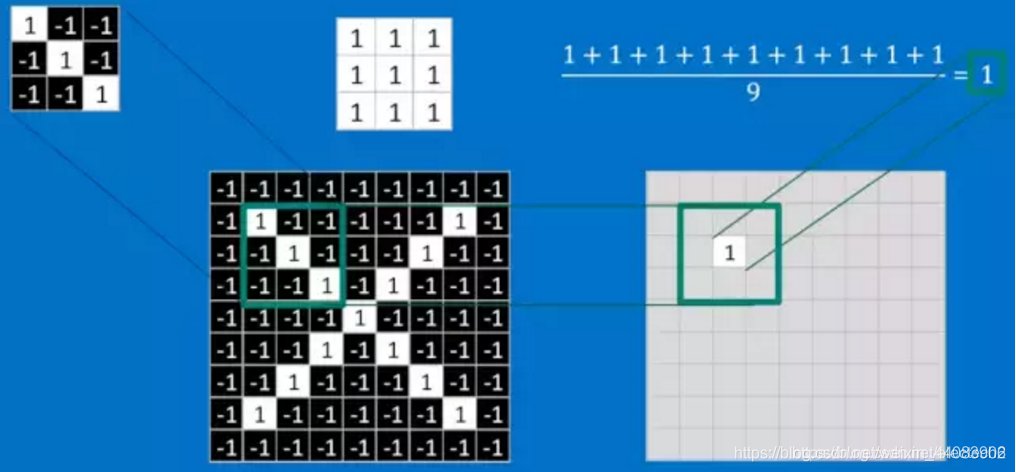
图中求平均是为了让所有特征值回归到-1到1之间。
使用全部卷积核卷积过后,得到的结果是这样的:

观察上图可知,越接近为1表示对应位置和卷积核代表的特征越接近,越是接近-1,表示对应位置和卷积核代表的反向特征越匹配,而值接近0的表示对应位置没有任何匹配或者说没有什么关联。
那么最后得到的特征矩阵就是前面所说的特征映射(feature map)。在CNN中,也称之为卷积层(convolution layer),卷积核在图像上不断滑动运算,就是卷积层所要做的事情。同时,在内积结果上取每一局部块的最大值就是最大池化层的操作。CNN 用卷积层和池化层实现了图片特征提取方法。
4.反向传播
在现实中,使用卷积神经网络进行多分类获目标检测的时候,图像构成要比上面的X和O要复杂得多,我们并不知道哪个局部特征是有效的,即使我们选定局部特征,也会因为太过具体而失去反泛化性。因此我们如何确定卷积核的值呢?
这就引出了反向传播算法。反向传播,就是对比预测值和真实值,继而返回去修改网络参数的过程,一开始我们随机初始化卷积核的参数,然后以误差为指导通过反向传播算法,自适应地调整卷积核的值,从而最小化模型预测值和真实值之间的误差。
因此CNN可以在神经网络中完成强大的特征提取功能。
基于CNN的风格迁移的实现
1.前提
当卷积神经网络被训练在物体识别上时,随着网络层次的增加,输入图像被转化为越来越关注图片的实际内容,而不是具体的像素值。因此,我们可以将网络中高层的特征响应作为图像的内容表示。

为了获得输入图像风格的表示,我们使用了一种最初设计用来捕捉纹理信息的特征空间(feature space)。这个特征空间是在网络的每一层的滤波器(filters)的响应之上构建的,它包含了不同的过滤器响应在特征图(feature maps)的空间范围内的相关性。通过包含多个层的特征关联,我们获得了一个静态的、多层的输入图像的风格表达,它捕捉了图像的纹理信息,而不是全局的排列。
和内容一样,样式同样可以可视化,我们可以通过我们的特征空间(feature spaces)来构建给定输入图像的图像的样式表示。从图中可以看出,从样式特征重新构建的图像会产生输入图像的纹理化版本,以颜色和局部结构来捕捉它的整体外观。此外,来自输入图像的图像结构的大小和复杂性也随着层次结构的增加而增加,这一结果可以通过不断增长的接受域大小和特性的复杂性来解释。
而这一认识,就可以为图像风格迁移,也就是图像风格化迁移算法=图像重建算法+纹理建模算法这一概念的实现埋单。
具体实现步骤
首先,我们使用CNN网络中的一些层的输出来表示图片的内容特征和风格特征。
将内容图片输入网络,计算内容图片在网络指定层([‘conv4_2’])上的输出值。
计算内容的损失。我们这样定义内容损失:内容图片在指定层上提取出的特征矩阵,与噪声图片在对应层上的特征矩阵的差值的L2范数。即求两两之间的像素差值的平方.
最小化内容图像以及混合图像激活特征的差距,使得混合图像和内容图像的轮廓相似。
对应每一层的内容损失函数:
其中,F是噪声图片的特征矩阵,P是内容图片的特征矩阵。M是P的长*宽,N是信道数。
最终的内容损失为,每一层的内容损失加权和。将风格图片输入网络,计算风格图片在网络指定层([('conv1_1',1.),('conv2_1',1.),('conv3_1',1.),('conv4_1',1.),('conv5_1',1.)])上的输出值。
计算风格的损失。我们使用风格图像在指定层上的特征矩阵的GRAM矩阵来衡量其风格,风格损失可以定义为风格图像和噪音图像特征矩阵的格莱姆矩阵的差值的L2范数。
格拉姆矩阵通过计算展开后的矩阵和其转置矩阵的向量积
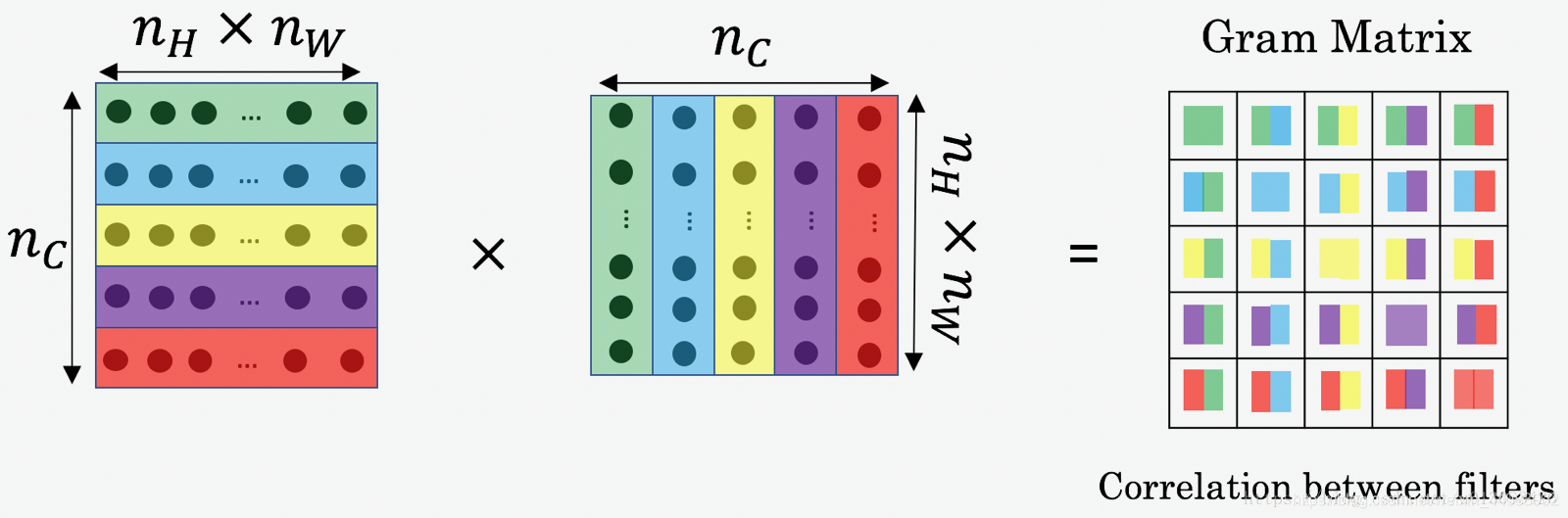
格拉姆矩阵本质上是风格层中特征激活向量的点乘矩阵。如果格拉姆矩阵中的一个元素值接近于0,则意味着给定层的特征没有被激活。因此,最小化损失函数,我们可以将风格图片的纹理和特征迁移到混合图像上。
对于每一层的风格损失函数:
其中和是特征矩阵的长和宽,是特征矩阵的信道数。G为噪音图像特征的Gram矩阵,A为风格图片特征的GRAM矩阵。
最终的风格损失为
每一层的风格损失加权和,是l层的权重。
6.最终用于训练的损失函数为内容损失和风格损失的加权和。
7. 当训练开始时,我们根据内容图片和噪声,生成一张噪声图片。并将噪声图片输入网络,计算loss,再根据loss调整噪声图片。将调整后的图片重新输入给网络,重新计算loss,经过反复迭代,最终得到一张混合效果的风格迁移图片。
---
环境配置
这是第一次在电脑使用如下配置时,需要给电脑准备的运行环境,下面顺便介绍笔者顺利配置好所需要的环境的一种成功的流程。
运行配置:
- windows10+Spyder(Python3.5)
- TensorFlow14.03库
- numpy库
- scipy库
- VGG-19 model
- matplotlib库
环境搭建:
(在我本身的环境搭建过程中,绝大部分细节我都没有截图,于是一些常见错误也没有保留下来,但是一些重点会在文中赘述)
此次,由于会使用anancoda直接搭建环境,对原电脑配置的python不做要求。
先直接在anaconda官网下载链接上下载对应电脑操作系统版本的Anaconda安装包,安装包较大。官网下载软件流程较为简单,可以通过该链接 来学习。
为了系统使用有规律且易于配置环境,建议将整个Anaconda安装在默认安装目录,例如我的电脑是AUSU的笔记本,其安装路径是"C:\Users\asus\Anaconda3",安装完成后会,开始菜单就会显示我们的整个Anaconda目录下的软件。
安装以后我们可以直接启动Anaconda Promot,然后进行下一步配置。
首先创建一个虚拟环境,可以命名为tensorflow 。
conda create -n tensorflow
系统显示已经建立好名为tensorflow的虚拟环境,就可以激活该虚拟环境
activate tensorflow
之后的操作都在该虚拟环境中。
在该tensorflow下建立的虚拟环境会存储在Anaconda3安装路径下的envs文件夹中。(例如C:\Users\asus\Anaconda3\envs\tensorflow)
因为我们需要在其后用pip获取TensorFlow库,官网下载非常慢,我们先为它配置tensorflow的清华镜像源。
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --set show_channel_urls yes
使用的是python3.5,直接在该环境下输入
python=3.5
anaconda会自动获取官网对应版本python3.5并进行下载安装,下载过程中会有键入y继续,然后显示安装完成。
其后下载TensorFlow库
pip install --upgrade --ignore-installed tensorflow
这一步中我的运行在下载中报错,报错提示说因为pip的版本过低,此时只要更新pip
pip install --upgrade pip
接着再次进行前面一步下载TensorFlow库步骤。
待tensorflow下载完成以后,根据实际代码需求需要将它配置给python的其他编辑器,比如PyCharm,Jupiter Notebook,Spyder等,
可以直接使用
ipython
spyer
等命令,此时就会在tensorflow虚拟环境下打开它们。比如我在调开的Spyder中,验证TensorFlow库是否已经配置给编译环境,键入
import tensorflow as tf
hello = tf.constant("Hello Tensorflow!")
sess = tf.Session()
print (sess.run(hello))
sess.close()
其后输出
b'Hello Tensorflow!'
证明TensorFlow库已经能够实现调用。
在菜单栏中也会加载出Spyder(tensorflow)。于是从菜单栏的按钮,我们可以快捷进入在相同虚拟环境下的Spyder编辑器,后期的程序处理都可以直接选择这个入口。
不过PyCharm的配置,需要主动在编辑器中选择在虚拟环境目录下的python3.5并加载相应库,没有最终使用PyCharm,使用可以自行参考[PyCharm配置][42]。
紧接着剩下的numpy、scipy等库,我们都可以通过Anaconda的主界面来安装,非常方便。
另外,matplotlib库虽然在anaconda中可以下载,但是在实际的Spyder编译过程中仍然出现子库不存在,所以可以选择在Anaconda Promot 中进入环境重新获取
最后,需要将网络上训练好的VGG-19模型下载下来放入正确位置。[VGG-19下载链接][53]
由于我使用Spyder编译器,为了实现模型调用,我们需要将 模型文件放入主目录下的(C:\Users\asus.spyder-py3)中。
到此,我们的环境配置基本结束!
各层可视化的代码实现
载入函数库
import tensorflow as tfimport numpy as npimport matplotlib.pyplot as pltimport scipy.ioimport scipy.misc
定义一些函数并进行卷积计算
def _conv_layer(input, weights, bias):conv = tf.nn.conv2d(input, tf.constant(weights), strides=(1, 1, 1, 1),padding='SAME')return tf.nn.bias_add(conv, bias)#池化def _pool_layer(input):return tf.nn.max_pool(input, ksize=(1, 2, 2, 1), strides=(1, 2, 2, 1),padding='SAME')#减像素均值操作def preprocess(image, mean_pixel):return image - mean_pixel#加像素均值操作def unprocess(image, mean_pixel):return image + mean_pixel#读取def imread(path):return scipy.misc.imread(path).astype(np.float)#保存def imsave(path, img):img = np.clip(img, 0, 255).astype(np.uint8)scipy.misc.imsave(path, img)print ("Functions for VGG ready")
定义VGG的网络结构,用来存储网络的权重和偏置参数
def net(data_path, input_image):#拿到每一层对应的参数layers = ('conv1_1', 'relu1_1', 'conv1_2', 'relu1_2', 'pool1','conv2_1', 'relu2_1', 'conv2_2', 'relu2_2', 'pool2','conv3_1', 'relu3_1', 'conv3_2', 'relu3_2', 'conv3_3','relu3_3', 'conv3_4', 'relu3_4', 'pool3','conv4_1', 'relu4_1', 'conv4_2', 'relu4_2', 'conv4_3','relu4_3', 'conv4_4', 'relu4_4', 'pool4','conv5_1', 'relu5_1', 'conv5_2', 'relu5_2', 'conv5_3','relu5_3', 'conv5_4', 'relu5_4')data = scipy.io.loadmat(data_path)#原网络在训练的过程中,对每张图片三通道都执行了减均值的操作,这里也要减去均值mean = data['normalization'][0][0][0]mean_pixel = np.mean(mean, axis=(0, 1))#print(mean_pixel)#取到权重参数W和bweights = data['layers'][0]#print(weights)net = {}current = input_image#取到w和bfor i, name in enumerate(layers):kind = name[:4]if kind == 'conv':kernels, bias = weights[i][0][0][0][0]# matconvnet: weights are [width, height, in_channels, out_channels]\n",# tensorflow: weights are [height, width, in_channels, out_channels]\n",#这里width和height是颠倒的,所以要做一次转置运算kernels = np.transpose(kernels, (1, 0, 2, 3))#将bias转换为一个维度bias = bias.reshape(-1)current = _conv_layer(current, kernels, bias)elif kind == 'relu':current = tf.nn.relu(current)elif kind == 'pool':current = _pool_layer(current)net[name] = currentassert len(net) == len(layers)return net, mean_pixel, layersprint ("Network for VGG ready")#cwd = os.getcwd()#这里用的是绝对路径VGG_PATH = "C:/Users/asus/.spyder-py3/imagenet-vgg-verydeep-19.mat"#需要可视化的图片路径,这里使用的是经典的梵高的星月夜图片IMG_PATH = "C:/Users/asus/.spyder-py3/images/StarryNight.jpg"input_image = imread(IMG_PATH)#获取图像shapeshape = (1,input_image.shape[0],input_image.shape[1],input_image.shape[2])
开始会话,计算和生成各层特征图
with tf.Session() as sess:image = tf.placeholder('float', shape=shape)#调用net函数nets, mean_pixel, all_layers = net(VGG_PATH, image)#减均值操作input_image_pre = np.array([preprocess(input_image, mean_pixel)])layers = all_layers # For all layers \n",# layers = ('relu2_1', 'relu3_1', 'relu4_1')\n",for i, layer in enumerate(layers):print ("[%d/%d] %s" % (i+1, len(layers), layer))features = nets[layer].eval(feed_dict={image: input_image_pre})print (" Type of 'features' is ", type(features))print (" Shape of 'features' is %s" % (features.shape,))#Plot response \n",#画出每一层if 1:plt.figure(i+1, figsize=(10, 5))plt.matshow(features[0, :, :, 0], cmap=plt.cm.gray, fignum=i+1)plt.title("" + layer)plt.colorbar()plt.show()
最终生成的特征图共有36个,篇幅有限,此处仅展示各个卷积层的第一幅特征图。其中输入图像的原图为梵高的《星月夜》。




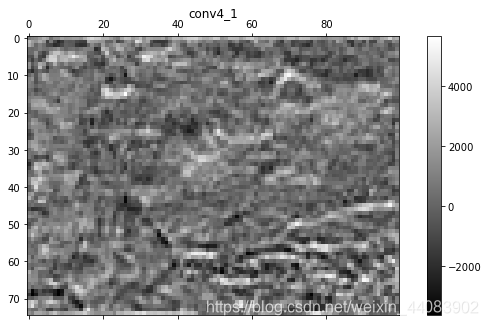

由此可以清晰地看出,卷积层由前向后通过卷积核不断对Feature maps继续进行抽象地提取特征,图像像素尺寸不断减小。
风格迁移的代码实现
导入用到的函数库
import tensorflow as tfimport numpy as npimport scipy.ioimport scipy.miscimport os
设置图像大小,因为已经提前定义,所以在放置图片时需要首先处理好图片的尺寸为像素600*800
IMAGE_W = 800IMAGE_H = 600
下面分别载入内容图片,风格图片,已经生成的结果图片。文件夹images是在主目录下的(C:\Users\asus.spyder-py3)中,其中放入图片都已经分割成600*800的格式了
CONTENT_IMG = './images/NPUac.jpg'STYLE_IMG = './images/MONET1.jpg'OUTOUT_DIR = './results'OUTPUT_IMG = 'results.png'VGG_MODEL = 'imagenet-vgg-verydeep-19.mat'
定义随机噪声与内容图像的比例
INI_NOISE_RATIO = 0.7
定义内容图像和风格图像的权重为1:500
CONTENT_STRENGTH = 1STYLE_STRENGTH = 500
定义训练的迭代次数
ITERATION = 300
匹配内容和风格图像在卷积神经网络中的层次
CONTENT_LAYERS =[('conv4_2',1.)]STYLE_LAYERS=[('conv1_1',1.),('conv2_1',1.),('conv3_1',1.),('conv4_1',1.),('conv5_1',1.)]
定义图片均值
```MEAN_VALUES = np.array([123, 117, 104]).reshape((1,1,1,3))定义网络```pythondef build_net(n_type, n_in, n_wb=None):if n_type == 'conv':return tf.nn.relu(tf.nn.conv2d(n_in, n_wb[0], strides=[1, 1, 1, 1], padding='SAME')+ n_wb[1])elif n_type == 'pool':return tf.nn.avg_pool(n_in, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')定义并获取获取VGG-19模型训练好的权重值weights和偏差值bias<div class="md-section-divider"></div>```pythondef get_weight_bias(vgg_layers, i,):weights = vgg_layers[i][0][0][0][0][0]weights = tf.constant(weights)bias = vgg_layers[i][0][0][0][0][64]bias = tf.constant(np.reshape(bias, (bias.size)))return weights, bias
根据VGG19的网络,重建卷积神经网络模型
def build_vgg19(path):net = {}vgg_rawnet = scipy.io.loadmat(path)vgg_layers = vgg_rawnet['layers'][0]net['input'] = tf.Variable(np.zeros((1, IMAGE_H, IMAGE_W, 3)).astype('float32'))net['conv1_1'] = build_net('conv',net['input'],get_weight_bias(vgg_layers,0))net['conv1_2'] = build_net('conv',net['conv1_1'],get_weight_bias(vgg_layers,2))net['pool1'] = build_net('pool',net['conv1_2'])net['conv2_1'] = build_net('conv',net['pool1'],get_weight_bias(vgg_layers,5))net['conv2_2'] = build_net('conv',net['conv2_1'],get_weight_bias(vgg_layers,7))net['pool2'] = build_net('pool',net['conv2_2'])net['conv3_1'] = build_net('conv',net['pool2'],get_weight_bias(vgg_layers,10))net['conv3_2'] = build_net('conv',net['conv3_1'],get_weight_bias(vgg_layers,12))net['conv3_3'] = build_net('conv',net['conv3_2'],get_weight_bias(vgg_layers,14))net['conv3_4'] = build_net('conv',net['conv3_3'],get_weight_bias(vgg_layers,16))net['pool3'] = build_net('pool',net['conv3_4'])net['conv4_1'] = build_net('conv',net['pool3'],get_weight_bias(vgg_layers,19))net['conv4_2'] = build_net('conv',net['conv4_1'],get_weight_bias(vgg_layers,21))net['conv4_3'] = build_net('conv',net['conv4_2'],get_weight_bias(vgg_layers,23))net['conv4_4'] = build_net('conv',net['conv4_3'],get_weight_bias(vgg_layers,25))net['pool4'] = build_net('pool',net['conv4_4'])net['conv5_1'] = build_net('conv',net['pool4'],get_weight_bias(vgg_layers,28))net['conv5_2'] = build_net('conv',net['conv5_1'],get_weight_bias(vgg_layers,30))net['conv5_3'] = build_net('conv',net['conv5_2'],get_weight_bias(vgg_layers,32))net['conv5_4'] = build_net('conv',net['conv5_3'],get_weight_bias(vgg_layers,34))net['pool5'] = build_net('pool',net['conv5_4'])return net
创建内容图像的损失函数。损失函数选用的是均方误差模型,最小化内容图像以及混合图像激活特征的差距,使得混合图像和内容图像的轮廓相似。
普通图像p的feature maps集合为P, 随机噪声图像x的feature maps集合为F
def build_content_loss(p, x):print(type(p),np.shape(p))# net['conv4_2']-- <class 'numpy.ndarray'> (1, 75, 100, 512)print(type(x),np.shape(x))# net['conv4_2']-- <class 'tensorflow.python.framework.ops.Tensor'> (1, 75, 100, 512)M = p.shape[1]*p.shape[2]N = p.shape[3]loss = (1./(2* N**0.5 * M**0.5 )) * tf.reduce_sum(tf.pow((x - p),2))return loss
风格图像损失函数的定义,同样使用均方误差模型。计算风格输出层张量的格拉姆矩阵,格拉姆矩阵本质上是风格层中特征激活向量的点乘矩阵。如果格拉姆矩阵中的一个元素值接近于0,则意味着给定层的特征没有被激活。因此,最小化损失函数,我们可以将风格图片的纹理和特征迁移到混合图像上。
风格图像a的feature maps集合A, 随机噪声图像x的feature maps集合G
def build_style_loss(a, x):def _gram_matrix(x, area, depth):x1 = tf.reshape(x,(area,depth))g = tf.matmul(tf.transpose(x1), x1)return gdef _gram_matrix_val(x, area, depth):x1 = x.reshape(area,depth)g = np.dot(x1.T, x1)return gM = a.shape[1]*a.shape[2]N = a.shape[3]G = _gram_matrix(x, M, N)A = _gram_matrix_val(a, M, N)loss = (1./(4 * N**2 * M**2)) * tf.reduce_sum(tf.pow((G - A),2))return loss
使用scipy.misc库,对读写图像函数进行定义
def read_image(path):image = scipy.misc.imread(path)image = scipy.misc.imresize(image,(IMAGE_H,IMAGE_W))image = image[np.newaxis,:,:,:]image = image - MEAN_VALUESreturn imagedef write_image(path, image):image = image + MEAN_VALUESimage = image[0]image = np.clip(image, 0, 255).astype('uint8')scipy.misc.imsave(path, image)
模型训练的主函数如下
def main():net = build_vgg19(VGG_MODEL)sess = tf.Session()sess.run(tf.global_variables_initializer())#写入内容图片和风格图片,用随机函数生成随机噪声图片noise_img = np.random.uniform(-20, 20, (1, IMAGE_H, IMAGE_W, 3)).astype('float32')content_img = read_image(CONTENT_IMG)style_img = read_image(STYLE_IMG)#build_content_loss()的第一个参数由content_img获得;第二个参数由噪声图像x计算而得,x在迭代中更新sess.run([net['input'].assign(content_img)])cost_content = sum(map(lambda lay: lay[1]*build_content_loss(sess.run(net[lay[0]]), net[lay[0]]), CONTENT_LAYERS))#build_style_loss()的第一个参数由style_img获得;STYLE_LAYERS包含5层,权重自定义,这里lay[1]都是1sess.run([net['input'].assign(style_img)])cost_style = sum(map(lambda lay: lay[1]*build_style_loss(sess.run(net[lay[0]]), net[lay[0]]), STYLE_LAYERS))#定义混合图片的混合计算式cost_total = cost_content + STYLE_STRENGTH * cost_style#选用Adam算法的优化器optimizer = tf.train.AdamOptimizer(2.0)#定义自动训练train = optimizer.minimize(cost_total)sess.run(tf.global_variables_initializer())sess.run(net['input'].assign( INI_NOISE_RATIO * noise_img + (1.-INI_NOISE_RATIO) * content_img))#net['input']是一个tf变量由于tf.Variable()从而每次迭代更新;而vgg19中的weights和bias都是tf常量不会被更新if not os.path.exists(OUTOUT_DIR):os.mkdir(OUTOUT_DIR)#定义训练的迭代以及图像保存的周期,迭代次数在前面设置,图片生成png格式for i in range(ITERATION):sess.run(train)if i%15==0:result_img = sess.run(net['input'])print(sess.run(cost_total))write_image(os.path.join(OUTOUT_DIR, '%s.png' % (str(i).zfill(4))), result_img)if __name__ == '__main__':main()
根据我们的上述代码,模型正常运行时,会在每次迭代15次(预设值)后,输出cost_total的计算值,并在主目录的result文件夹下生成一个png图片。
效果分析
上述代码中,写入了具体的加载图片,是一个对莫奈的一张风景画的风格进行学习,并将其迁移到一张西工大的风景图片上的实现。
风格图片
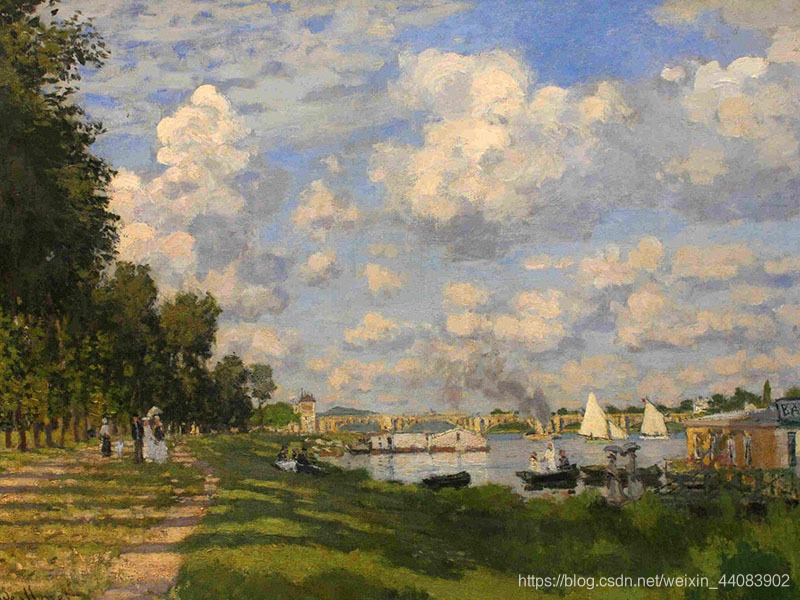
内容图片(这是一张西工大长安校区游泳馆的照片)

学习生成的过程图片


最终经历三百次迭代后的效果

在这一种风格的学习中,VGG-19模型的学习效果表现可以说是不错,完成了直观上比较完美的风格迁移。
除此之外,为了验证模型学习效果,我还进行了多组不同迭代次数和风格、内容图片的迁移训练,其对比结果将展示如下:
1.艺术风格:凡高《starrynight》迁移对象:《长安游泳馆》迭代次数:500
2.艺术风格:凡高《starrynight》迁移对象:《npu启真湖》迭代次数:100
( 梵高的绘画风格中,特有卷曲的排布的线条和星月夜的用色被这一模型学习的效果非常的好。)
3.艺术风格:毕加索抽象风格 迁移对象:《长安游泳馆》迭代次数:300
4.艺术风格:毕加索抽象风格 迁移对象:《npu启真湖》迭代次数:1050
(毕加索这一幅抽象画,主要风格表现在线条上:以整体的细致纹理来表现面积为主。迭代训练300次以后的图片,其效果并不佳,尝试加大训练次数以后,其线性特征在局部不断强化,表现为原有线条的加深和图片明度、对比度的提高,但是呈现出来的整体风格也比较勉强,没有出现大面积较长而规律排布的细线条特征。)
5.艺术风格:毕加索印象《PARTY》迁移对象:《长安游泳馆》迭代次数:100
6.艺术风格:毕加索印象《PARTY》迁移对象:《npu启真湖》迭代次数:500
(下面每三张图为一组,一共六组,分别对应图1.内容图片。图2.合成图片。图3.风格图片)



小结
不同特征的提取通过设置合理卷积核来实现
内容可以通过卷积高层网络网络捕获
风格通过卷积网络的不同网络层激活函数的内部相关性计算
图像风格迁移建立在图像重建和纹理建模上
上面复现的迁移模型更适用于具有强烈纹理和高度自相似性的样式参考图像
神经网络算法下的该算法速度较慢,仍可以进一步封装和优化
##参考文献
Johnson J, Alahi A, Fei-Fei L. Perceptual losses for real-time style transfer and super-resolution[C]//European Conference on Computer Vision. Springer International Publishing, 2016: 694-711.
Gatys L A, Ecker A S, Bethge M. A neural algorithm of artistic style[J]. arXiv preprint arXiv:1508.06576, 2015
Chuan Li, Michael Wand; Combining Markov Random Fields and Convolutional Neural Networks for Image Synthesis,The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 2479-2486
https://github.com/ckmarkoh/neuralart_tensorflow
风格迁移简史
卷积层特征提取
