@JeemyJohn
2018-07-04T13:53:36.000000Z
字数 3662
阅读 6315
DeepFM模型
推荐系统
1. 常用的CTR模型的问题
| 序号 | 模型 | 存在的问题 |
|---|---|---|
| 1 | 线性模型(LR) | 提取高阶特征的普遍方式其实是基于手工和先验知识。一方面当特征维度比较高时几乎不可行。另外一方面,这些模型也很难对在训练集中很少出现的组合特征进行建模。 |
| 2 | 因子分解机(FM) | 只能对二阶组合特征进行建模,更高阶建模理论可行,但是计算复杂度太高。 |
| 3 | 基于CNN或RNN的模型 | 基于CNN的模型比较偏向于相邻的特征提取,基于RNN的模型更适合有序列依赖的点击数据。 |
| 4 | FNN(Factorization-machine supported Neural Network) | 模型首先预训练FM,再将训练好的FM应用到DNN中。很难有效的提取出低阶特征。 |
| 5 | PNN | 在PNN网络的embedding层与全连接层之间加了一层Product Layer来完成特征组合。很难有效的提取出低阶特征。 |
| 6 | Wide&Deep模型 | 混合了宽度(wide)模型与深度模型。但是宽度模型的输入依旧依赖于特征工程。 |
2. FM模型
FM全称为Factorization Machines,中文名因子分解机。它的主要目标是:解决数据稀疏情况下的特征组合问题。
1.1 算法原理
一般的线性模型中,是各个特征独立考虑的,没有考虑特征之间的相互关系,实际上大量的特征之间是有关联的。
一般的线性模型为:
从上面的式子中看出,一般的线性模型没有考虑特征之间的关联。为了表述特征间的相关性,我们采用多项式模型。在多项式模型中,特征 与 的组合用 表示。
为了简单起见,我们讨论二阶多项式模型:
该多项是模型与线性模型相比,多了特征组合的部分,特征组合部分的参数有n(n−1)/2个。如果特征非常稀疏且维度很高的话,时间复杂度将大大增加。为了降低时间复杂度,对每一个特征,引入辅助向量 Latent Vector , 模型修改如下:
以上就是FM模型的表达式。k是超参数,即latent vector的维度,一般取30或40,也可以取其他数 具体情况具体分析。上式如果要计算的话,时间复杂度是 , 可以通过如下方式化简。对于FM的交叉项:
通过对每个特征引入latent vector , 并对表达式进行化简,可以把时间复杂度降低到O(kn)。
1.2 FM优点
- 可以再非常稀疏的数据中进行合理的参数估计;
- FM算法的时间复杂度是线性的;
- FM是一个通用模型,它可以用于任何特征为实值的情况
1.3 FM缺点
- 在传统的非稀疏数据集上,有时效果并不是很好;
- 只能学习低阶组合特征,高阶组合特征复杂度太高实践不可行;
2. DeepFM模型
对于一个基于CTR预估的推荐系统,最重要的是学习到用户点击行为背后隐含的特征组合。在不同的推荐场景中,低阶组合特征或者高阶组合特征可能都会对最终的CTR产生影响。首先给出DeepFM的系统框架图:
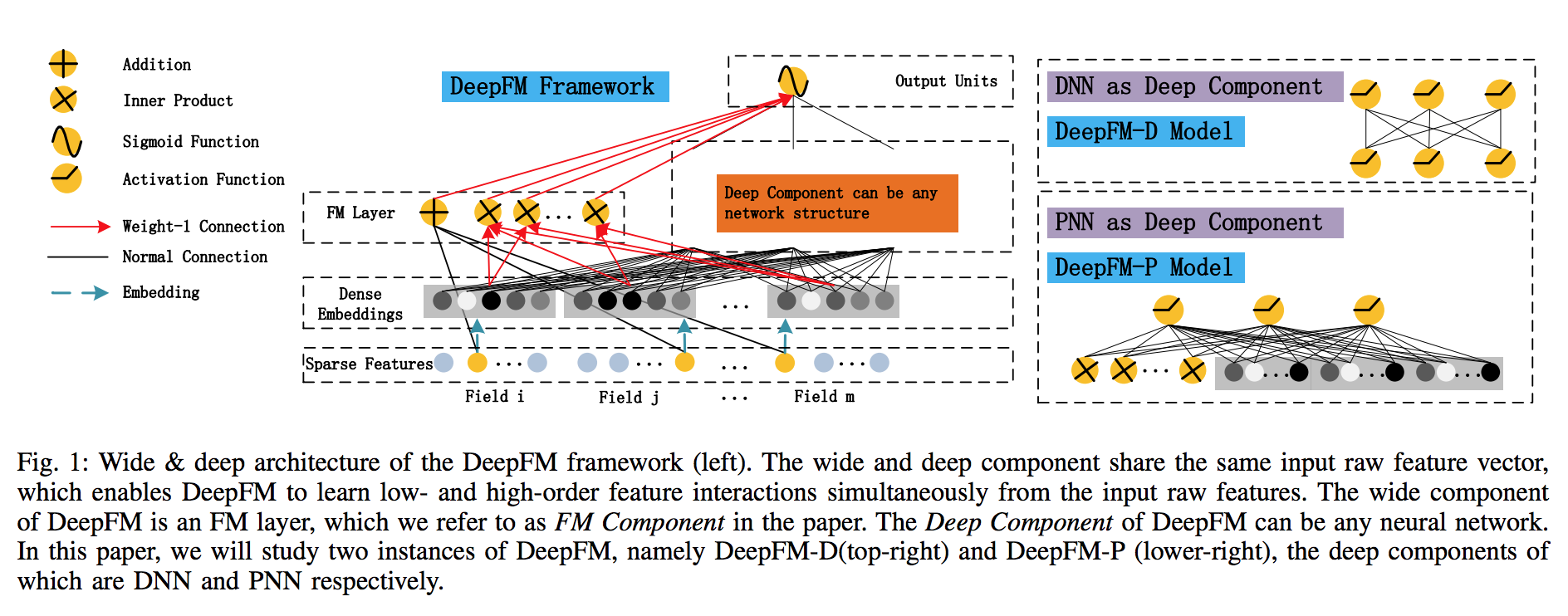
DeepFM包含两部分,左边的FM部分和右边的DNN部分。这两部分共享相同的输入。对于给定的特征 , 用于表示一阶特征的重要性,特征i的隐向量(latent vector) 用户表示和其他特征的相互影响。在FM部分,Vi用于表征二阶特征,同时在神经网络部分用于构建高阶特征。对于当前模型,所有的参数共同参与训练。DeepFM的预测结果可以写为:
是最终的预测CTR值, 是FM部分得到的结果, 是Deep端得到的结果。
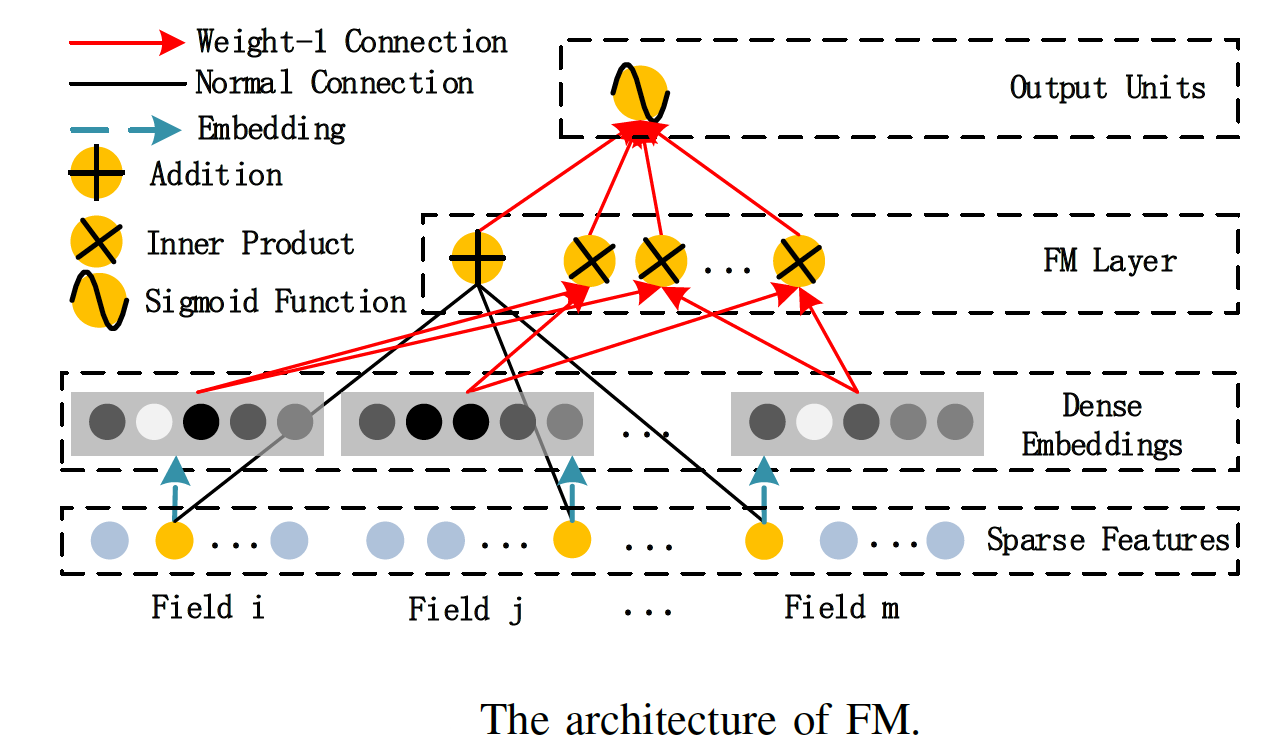
2.1 FM部分
对于FM部分,其模型如下所示:
2.2 Deep部分
对于FM部分,其模型如下所示:
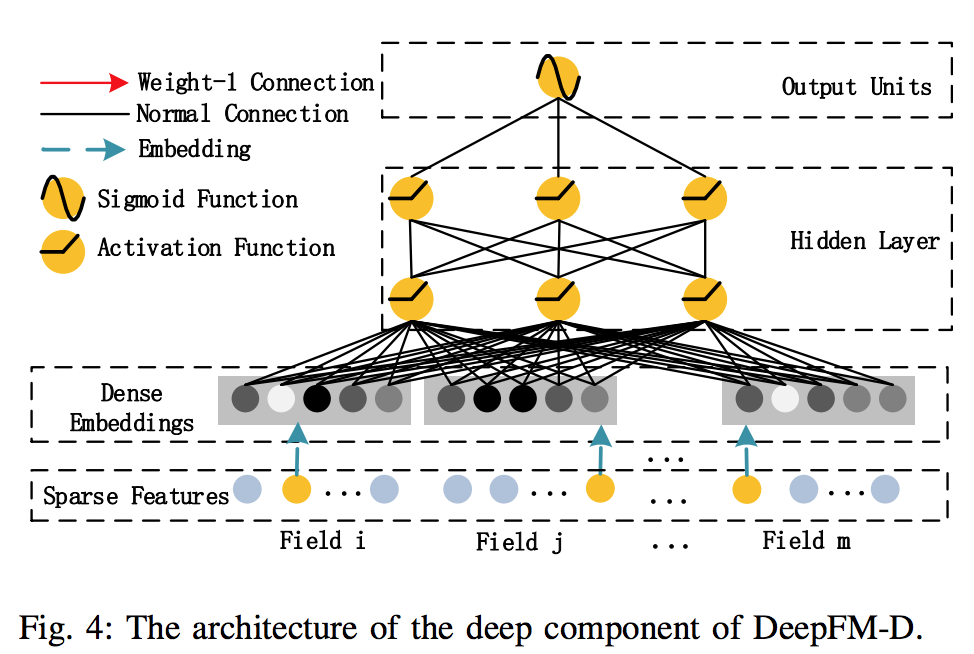
深度部分是一个前馈神经网络,可以学习高阶的特征组合。Hidden Layer设置为3层,每层单元数为200~400。使用relu函数作为激活函数,增加了dropout。当然,关于超参数的调试,这个还要具体情况具体分析,只有手动取调试才知道哪些参数组合更好。
需要注意的是原始的输入的数据是很多个字段的高维稀疏数据。因此引入一个embedding layer将输入向量压缩到低维稠密向量:
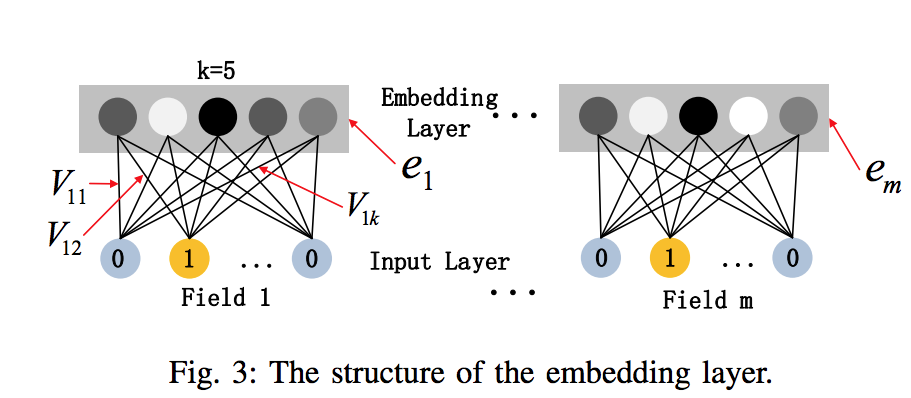
Embedding Layer有两个有趣的特性:
- 输入数据的每个字段的特征经过embedding之后,都为k维(lantent vector的维度),所以embedding后的特征维度是 m(字段数)× k;
- 在FM里得到的隐变量V现在作为了嵌入层网络的权重,FM模型作为整个模型的一部分与其他深度学习模型一起参与整体的学习, 实现端到端的训练。
这里的第二点如何理解呢,假设我们的k=5,首先,对于输入的一条记录,同一个field 只有一个位置是1,那么在由输入得到dense vector的过程中,输入层只有一个神经元起作用,得到的dense vector其实就是输入层到embedding层该神经元相连的五条线的权重,即 。这五个值组合起来就是我们在FM中所提到的 。 在FM部分和DNN部分,这一块是共享权重的,对同一个特征来说,得到的 是相同的。
将Embedding Layer表征如下:
是第i个字段的embedding,m是字段的个数,是输入神经网络的向量,然后通过如下方式前向传播:
需要指出的是,FM部分与深度部分共享相同的embedding带来了两个好处:
- 从原始数据中同时学习到了低维与高维特征;
- 不再需要特征工程。而Wide&Deep Model需要;
3. 实践问题
3.1 Learning相关问题
- 目标函数
在CTR预测领域,最常见的目标函数是Logloss,在衡量两个分布是否一致的时候,它和K-L散度是等价的:
过拟合
- FM部分采用L2正则防止过拟合;
- 深度神经网络部分采用Dropout防止过拟合。
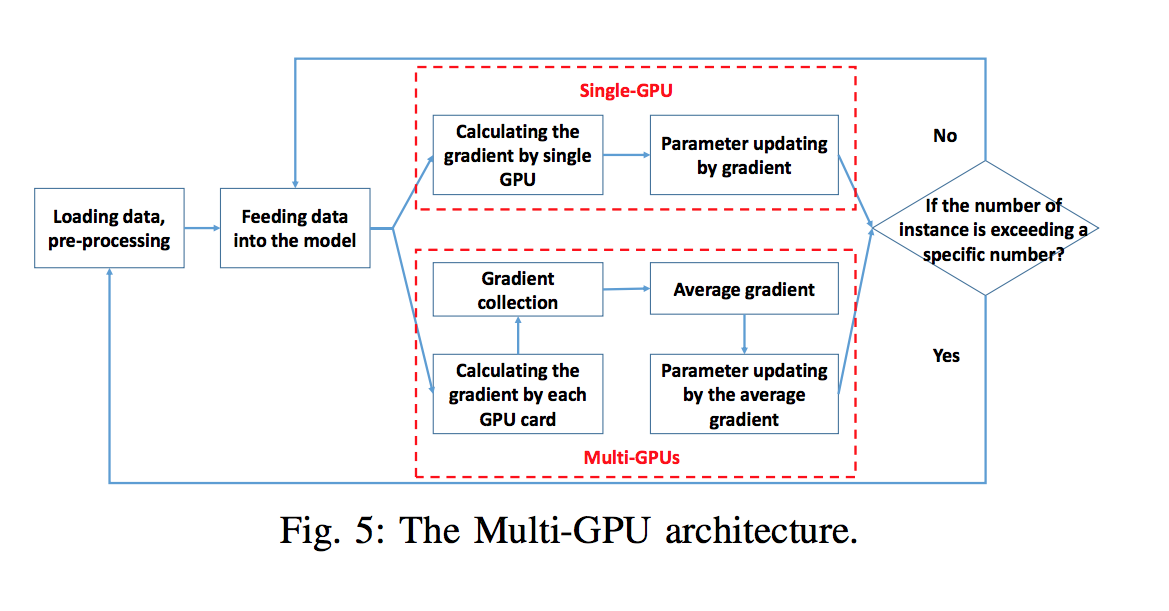
多GPU架构
首先将数据分成N(GPU卡的数量)份,然后每一份同时单独地在每一个GPU上。然后计算每个GPU上的梯度值,最后对这些梯度值取平均:
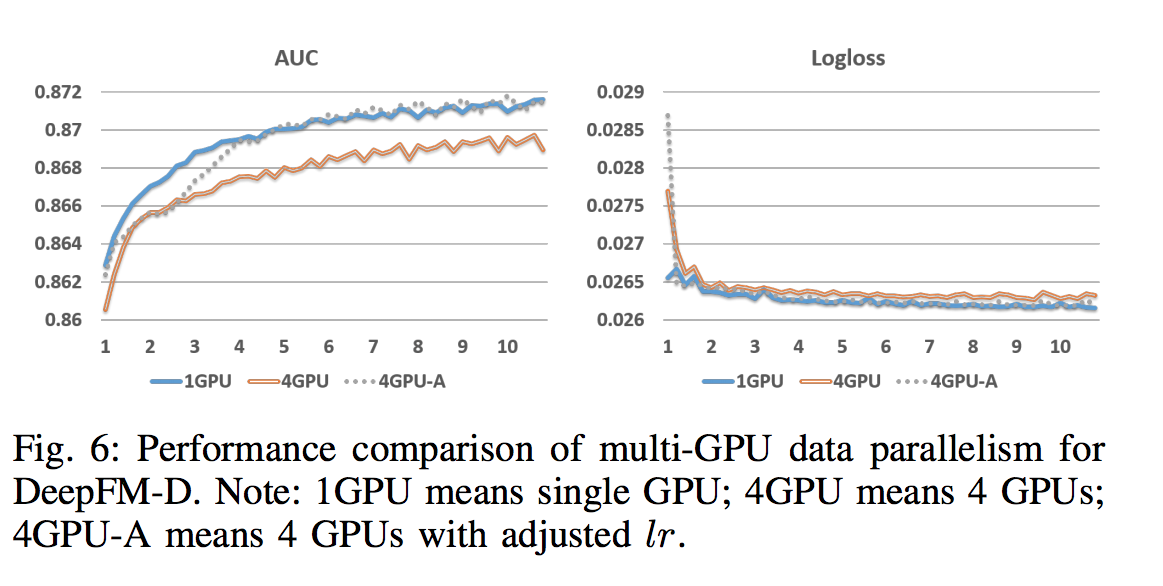
不同架构性能对比:
3.2 PNN
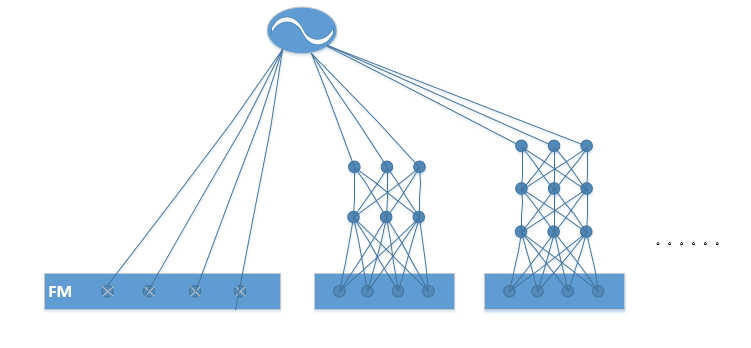
为了获取高阶的特征交叉,PNN在embedding层和隐藏层之间引入了一个交叉层,见下图中间:
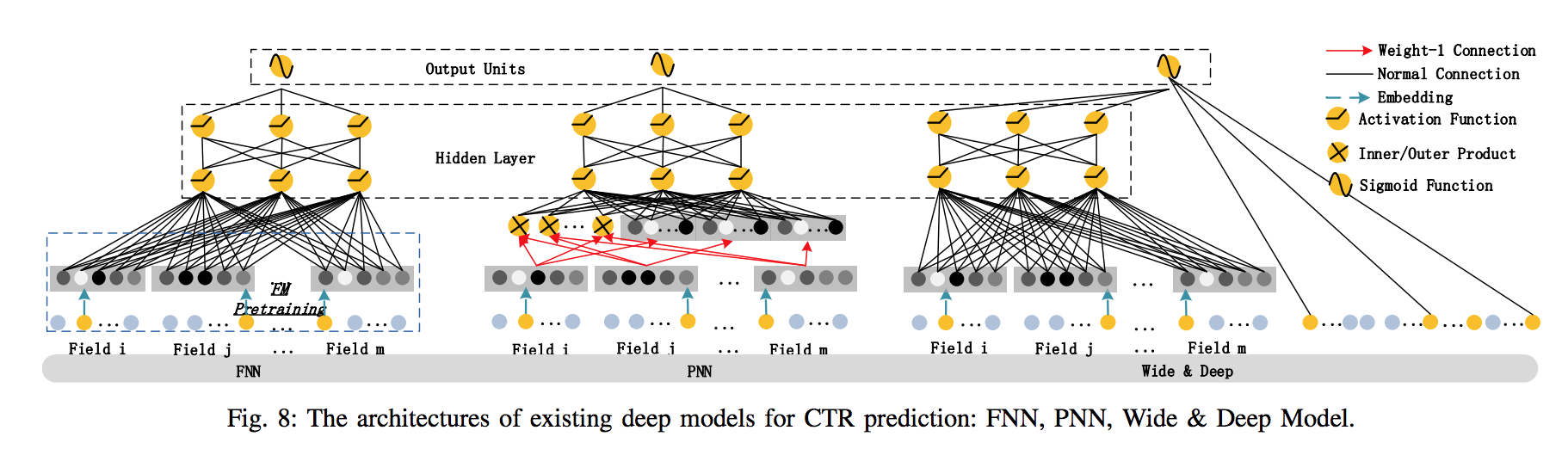
PNN的交叉层包含两种神经元:线性神经元(交叉层右边),二次神经元(交叉层左边)。线性神经元是将所有embedding层向量所有域组合在一起;二次神经元将所有embedding层向量的所有域的两两乘积。
3.3 模型对比
- 特点层面

- 性能层面
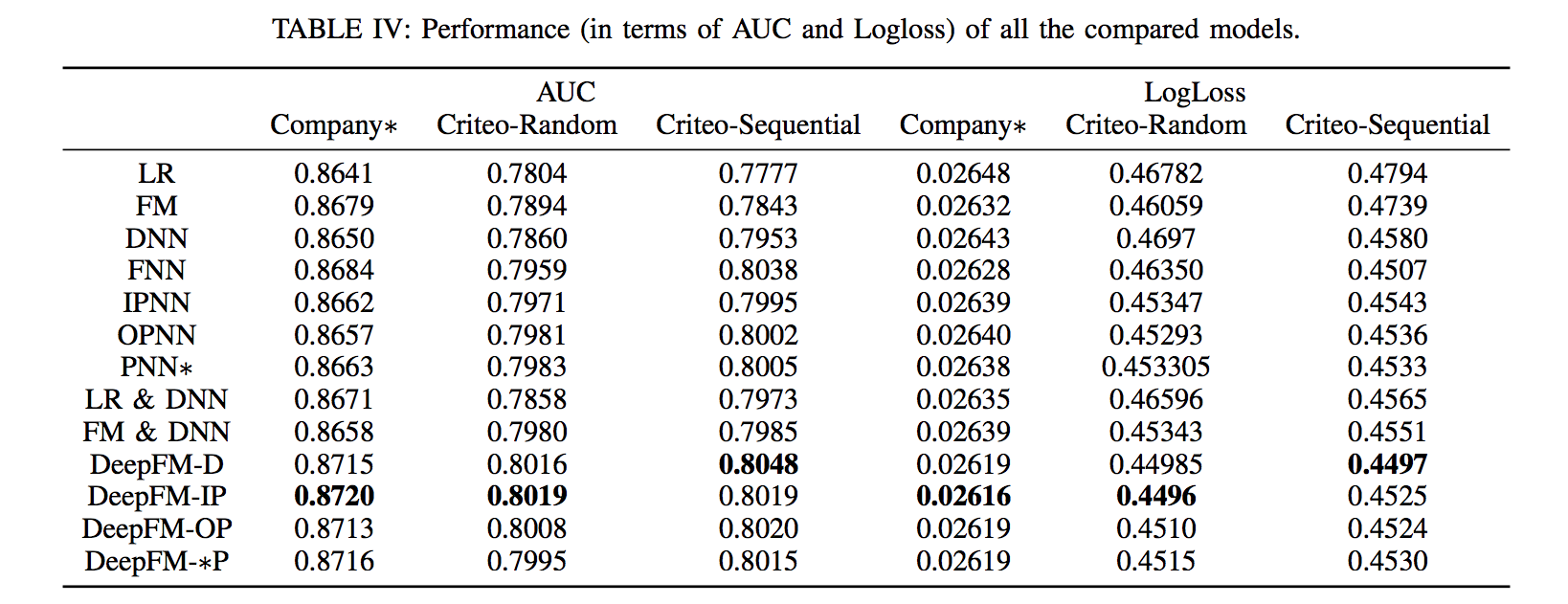
4. 改进构想