@Rookie
2017-08-01T14:34:58.000000Z
字数 7767
阅读 1648
张之城的面试题
找工作
1、什么是arc?(arc是为了解决什么问题诞生的?)
首先解释ARC: automatic reference counting自动引用计数。
ARC几个要点:
在对象被创建时 retain count +1,在对象被release时 retain count -1.当retain count 为0 时,销毁对象。
程序中加入autoreleasepool的对象会由系统自动加上autorelease方法,如果该对象引用计数为0,则销毁。
那么ARC是为了解决什么问题诞生的呢?这个得追溯到MRC手动内存管理时代说起。
- MRC下内存管理的缺点:
1.当我们要释放一个堆内存时,首先要确定指向这个堆空间的指针都被release了。(避免提前释放)
2.释放指针指向的堆空间,首先要确定哪些指针指向同一个堆,这些指针只能释放一次。(MRC下即谁创建,谁释放,避免重复释放)
3.模块化操作时,对象可能被多个模块创建和使用,不能确定最后由谁去释放。
4.多线程操作时,不确定哪个线程最后使用完毕
2、请解释以下keywords的区别: assign vs weak, __block vs __weak
assign适用于基本数据类型,weak是适用于NSObject对象,并且是一个弱引用。
- assign其实也可以用来修饰对象,那么我们为什么不用它呢?因为被assign修饰的对象在释放之后,指针的地址还是存在的,也就是说指针并没有被置为nil。如果在后续的内存分配中,刚好分到了这块地址,程序就会崩溃掉。
而weak修饰的对象在释放之后,指针地址会被置为nil。所以现在一般弱引用就是用weak。
- 首先__block是用来修饰一个变量,这个变量就可以在block中被修改(参考block实现原理)
__block:使用__block修饰的变量在block代码快中会被retain(ARC下,MRC下不会retain)
__weak:使用__weak修饰的变量不会在block代码块中被retain - 同时,在ARC下,要避免block出现循环引用 __weak typedof(self)weakSelf = self;
- 首先__block是用来修饰一个变量,这个变量就可以在block中被修改(参考block实现原理)
assign适用于基本数据类型,weak是适用于NSObject对象,并且是一个弱引用。
- assign其实也可以用来修饰对象,那么我们为什么不用它呢?因为被assign修饰的对象在释放之后,指针的地址还是存在的,也就是说指针并没有被置为nil。如果在后续的内存分配中,刚好分到了这块地址,程序就会崩溃掉。
- 而weak修饰的对象在释放之后,指针地址会被置为nil。所以现在一般弱引用就是用weak。
首先__block是用来修饰一个变量,这个变量就可以在block中被修改(参考block实现原理)
__block:使用__block修饰的变量在block代码快中会被retain(ARC下,MRC下不会retain)
__weak:使用__weak修饰的变量不会在block代码块中被retain
同时,在ARC下,要避免block出现循环引用 __weak typedof(self)weakSelf = self;
3、__block在arc和非arc下含义一样吗
是不一样的。
在MRC中__block variable在block中使用是不會retain的
但是ARC中__block則是會Retain的。
取而代之的是用__weak或是__unsafe_unretained來更精確的描述weak reference的目的
其中前者只能在iOS5之後可以使用,但是比較好 (該物件release之後,此pointer會自動設成nil)
而後者是ARC的環境下為了相容4.x的解決方案。
所以上面的範例中
__block MyClass* temp = …; // MRC環境下使用
__weak MyClass* temp = …; // ARC但只支援iOS5.0以上的版本
__unsafe_retained MyClass* temp = …; //ARC且可以相容4.x以後的版本
4、使用nonatomic一定是线程安全的吗
不是的。
- atomic原子操作,系统会为setter方法加锁。 具体使用 @synchronized(self){//code }
- nonatomic不会为setter方法加锁。
- atomic:线程安全,需要消耗大量系统资源来为属性加锁
- nonatomic:非线程安全,适合内存较小的移动设备
5、+(void)load; +(void)initialize;有什么用处
在Objective-C中,runtime会自动调用每个类的两个方法。+load会在类初始加载时调用,+initialize会在第一次调用类的类方法或实例方法之前被调用。这两个方法是可选的,且只有在实现了它们时才会被调用。
共同点:两个方法都只会被调用一次。
6、为什么其他语言里叫函数调用, objective c里则是给对象发消息(或者谈下对runtime的理解)
先来看看怎么理解发送消息的含义:
曾经觉得Objc特别方便上手,面对着 Cocoa 中大量 API,只知道简单的查文档和调用。还记得初学 objective-c 时把[receiver message]当成简单的方法调用,而无视了“发送消息”这句话的深刻含义。于是[receiver message]会被编译器转化为:
objc_msgSend(receiver, selector)
如果消息含有参数,则为:
objc_msgSend(receiver, selector, arg1, arg2, ...)
如果消息的接收者能够找到对应的selector,那么就相当于直接执行了接收者这个对象的特定方法;否则,消息要么被转发,或是临时向接收者动态添加这个selector对应的实现内容,要么就干脆玩完崩溃掉。
现在可以看出[receiver message]真的不是一个简简单单的方法调用。因为这只是在编译阶段确定了要向接收者发送message这条消息,而receive将要如何响应这条消息,那就要看运行时发生的情况来决定了。
Objective-C 的 Runtime 铸就了它动态语言的特性,这些深层次的知识虽然平时写代码用的少一些,但是却是每个 Objc 程序员需要了解的。
Objc Runtime使得C具有了面向对象能力,在程序运行时创建,检查,修改类、对象和它们的方法。可以使用runtime的一系列方法实现。
顺便附上OC中一个类的数据结构 /usr/include/objc/runtime.h
`
struct objc_class {
Class isa OBJC_ISA_AVAILABILITY; //isa指针指向Meta Class,因为Objc的类的本身也是一个Object,为了处理这个关系,r untime就创造了Meta Class,当给类发送[NSObject alloc]这样消息时,实际上是把这个消息发给了Class Object
#if !__OBJC2__
Class super_class OBJC2_UNAVAILABLE; // 父类
const char *name OBJC2_UNAVAILABLE; // 类名
long version OBJC2_UNAVAILABLE; // 类的版本信息,默认为0
long info OBJC2_UNAVAILABLE; // 类信息,供运行期使用的一些位标识
long instance_size OBJC2_UNAVAILABLE; // 该类的实例变量大小
struct objc_ivar_list *ivars OBJC2_UNAVAILABLE; // 该类的成员变量链表
struct objc_method_list **methodLists OBJC2_UNAVAILABLE; // 方法定义的链表
struct objc_cache *cache OBJC2_UNAVAILABLE; // 方法缓存,对象接到一个消息会根据isa指针查找消息对象,这时会在method Lists中遍历,如果cache了,常用的方法调用时就能够提高调用的效率。
struct objc_protocol_list *protocols OBJC2_UNAVAILABLE; // 协议链表
#endif
} OBJC2_UNAVAILABLE;
OC中一个类的对象实例的数据结构(/usr/include/objc/objc.h):
typedef struct objc_class *Class;
/// Represents an instance of a class.
struct objc_object {
Class isa OBJC_ISA_AVAILABILITY;
};
/// A pointer to an instance of a class.
typedef struct objc_object *id;
向object发送消息时,Runtime库会根据object的isa指针找到这个实例object所属于的类,然后在类的方法列表以及父类方法列表寻找对应的方法运行。id是一个objc_object结构类型的指针,这个类型的对象能够转换成任何一种对象。
然后再来看看消息发送的函数:objc_msgSend函数
在引言中已经对objc_msgSend进行了一点介绍,看起来像是objc_msgSend返回了数据,其实objc_msgSend从不返回数据而是你的方法被调用后返回了数据。下面详细叙述下消息发送步骤:
检测这个 selector 是不是要忽略的。比如 Mac OS X 开发,有了垃圾回收就不理会 retain,release 这些函数了。
检测这个 target 是不是 nil 对象。ObjC 的特性是允许对一个 nil 对象执行任何一个方法不会 Crash,因为会被忽略掉。
如果上面两个都过了,那就开始查找这个类的 IMP,先从 cache 里面找,完了找得到就跳到对应的函数去执行。
如果 cache 找不到就找一下方法分发表。
如果分发表找不到就到超类的分发表去找,一直找,直到找到NSObject类为止。
如果还找不到就要开始进入动态方法解析了,后面会提到。
后面还有:
动态方法解析resolveThisMethodDynamically
消息转发forwardingTargetForSelector
详情可参考 http://www.jianshu.com/p/620022378e97
7、什么是method swizzling
Method Swizzling 原理(方法搅拌?)
在Objective-C中调用一个方法,其实是向一个对象发送消息,查找消息的唯一依据是selector的名字。利用Objective-C的动态特性,可以实现在运行时偷换selector对应的方法实现,达到给方法挂钩的目的。
每个类都有一个方法列表,存放着selector的名字和方法实现的映射关系。IMP有点类似函数指针,指向具体的Method实现。
方法指向
我们可以利用 method_exchangeImplementations 来交换2个方法中的IMP,
我们可以利用 class_replaceMethod 来修改类,
我们可以利用 method_setImplementation 来直接设置某个方法的IMP,
……
归根结底,都是偷换了selector的IMP,如下图所示:
方法交换
详情:http://blog.csdn.net/yiyaaixuexi/article/details/9374411
8、http的post和get啥区别
1.GET请求的数据会附在URL之后(就是把数据放置在HTTP协议头中),以?分割URL和传输数据,参数之间以&相连,如:login.action?name=hyddd&password=idontknow&verify=%E4%BD%A0%E5%A5%BD。如果数据是英文字母/数字,原样发送,如果是空格,转换为+,如果是中文/其他字符,则直接把字符串用BASE64加密,得出如:%E4%BD%A0%E5%A5%BD,其中%XX中的XX为该符号以16进制表示的ASCII。
POST把提交的数据则放置在是HTTP包的包体中。
2.”GET方式提交的数据最多只能是1024字节,理论上POST没有限制,可传较大量的数据,IIS4中最大为80KB,IIS5中为100KB”??!
以上这句是我从其他文章转过来的,其实这样说是错误的,不准确的:
(1).首先是”GET方式提交的数据最多只能是1024字节”,因为GET是通过URL提交数据,那么GET可提交的数据量就跟URL的长度有直接关系了。而实际上,URL不存在参数上限的问题,HTTP协议规范没有对URL长度进行限制。这个限制是特定的浏览器及服务器对它的限制。IE对URL长度的限制是2083字节(2K+35)。对于其他浏览器,如Netscape、FireFox等,理论上没有长度限制,其限制取决于操作系统的支持。
注意这是限制是整个URL长度,而不仅仅是你的参数值数据长度。[见参考资料5]
(2).理论上讲,POST是没有大小限制的,HTTP协议规范也没有进行大小限制,说“POST数据量存在80K/100K的大小限制”是不准确的,POST数据是没有限制的,起限制作用的是服务器的处理程序的处理能力。
3.在ASP中,服务端获取GET请求参数用Request.QueryString,获取POST请求参数用Request.Form。在JSP中,用request.getParameter(\”XXXX\”)来获取,虽然jsp中也有request.getQueryString()方法,但使用起来比较麻烦,比如:传一个test.jsp?name=hyddd&password=hyddd,用request.getQueryString()得到的是:name=hyddd&password=hyddd。在PHP中,可以用GET和_POST分别获取GET和POST中的数据,而_REQUEST则可以获取GET和POST两种请求中的数据。值得注意的是,JSP中使用request和php中使用_REQUEST都会有隐患,这个下次再写个文章总结。
4.POST的安全性要比GET的安全性高。注意:这里所说的安全性和上面GET提到的“安全”不是同个概念。上面“安全”的含义仅仅是不作数据修改,而这里安全的含义是真正的Security的含义,比如:通过GET提交数据,用户名和密码将明文出现在URL上,因为(1)登录页面有可能被浏览器缓存,(2)其他人查看浏览器的历史纪录,那么别人就可以拿到你的账号和密码了,除此之外,使用GET提交数据还可能会造成Cross-site request forgery攻击。
总结一下,Get是向服务器发索取数据的一种请求,而Post是向服务器提交数据的一种请求,在FORM(表单)中,Method默认为”GET”,实质上,GET和POST只是发送机制不同,并不是一个取一个发!
9、我知道你大学毕业过后就没接触过算法数据结构了,但是请你一定告诉我什么是Binary search tree? search的时间复杂度是多少?
Binary search tree:二叉搜索树。
主要由四个方法:(用C语言实现或者Python)
1.search:时间复杂度为O(h),h为树的高度
2.traversal:时间复杂度为O(n),n为树的总结点数。
3.insert:时间复杂度为O(h),h为树的高度。
4.delete:最坏情况下,时间复杂度为O(h)+指针的移动开销。
可以看到,二叉搜索树的dictionary operation的时间复杂度与树的高度h相关。所以需要尽可能的降低树的高度,由此引出平衡二叉树Balanced binary tree。它要求左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。这样就可以将搜索树的高度尽量减小。常用算法有红黑树、AVL、Treap、伸展树等。
Written with StackEdit.
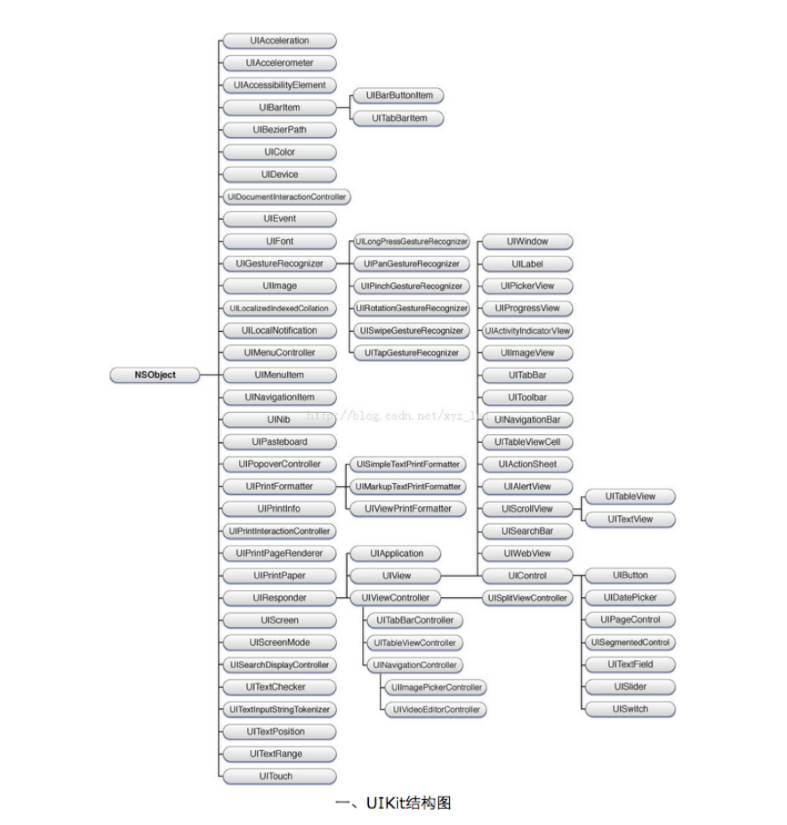
10、UIKit框架控件之间的继承关系
11、GCD有关问题:dispatch_sync(dispatch_get_main_queue(), ^{NSLog(@"Hello ?");}); 死锁的原因
这里先分清两个概念:Queue 和 Async、Sync。
Queue(队列):队列分为串行和并行。串行队列上面你按照A、B、C、D的顺序添加四个任务,这四个任务按顺序执行,结束顺序也肯定是A、B、C、D。而并行队列上面这四个任务同时执行,完成的顺序是随机的,每次都可能不一样。
Async VS Sync(异步执行和同步执行):使用dispatch_async 调用一个block,这个block会被放到指定的queue队尾等待执行,至于这个block是并行还是串行执行只和dispatch_async参数里面指定的queue是并行和串行有关。但是dispatch_async会马上返回。
使用dispatch_sync 同样也是把block放到指定的queue上面执行,但是会等待这个block执行完毕才会返回,阻塞当前queue直到sync函数返回。
所以队列是串行、并行 和 同步、异步执行调用block是两个完全不一样的概念。
这两个概念清楚了之后就知道为什么死锁了。
分两种情况:
1、当前queue是串行队列。当前queue上调用sync函数,并且sync函数中指定的queue也是当前queue。需要执行的block被放到当前queue的队尾等待执行,因为这是一个串行的queue,
调用sync函数会阻塞当前队列,等待block执行 -> 这个block永远没有机会执行 -> sync函数不返回,所以当前队列就永远被阻塞了,这就造成了死锁。(这就是问题中在主线程调用sync函数,并且在sync函数中传入main_queue作为queue造成死锁的情况)。
2、当前queue是并行队列。
在并行的queue上面调用sync函数,同时传入当前queue作为参数,并不会造成死锁,因为block会马上被执行,所以sync函数也不会一直等待不返回造成死锁。但是在并行队列上调用sync函数传入当前队列作为参数的用法,想不出什么情况下才会这样用。stackoverflow上面有一个针对这种情况的讨论。
12、instrument可以干什么
instrument模板虽多,但我觉得常用的就那几个:
Blank(空模板):创建一个空的模板,可以从Library库中添加其他模板;
Activity Monitor(活动监视器):显示器处理的CPU、内存和网络使用情况统计;
Allocations(内存分配):跟踪过程的匿名虚拟内存和堆的对象提供类名和可选保留/释放历史;
Automation(自动化):这个模板执行它模拟用户界面交互为IOS机应用从instrument启动的脚本;
Leaks(泄漏):一般的措施内存使用情况,检查泄漏的内存,并提供了所有活动的分配和泄漏模块的类对象分配统计信息以及内存地址历史记录;
Time Profiler(时间探查):执行对系统的CPU上运行的进程低负载时间为基础采样。
