@Velaciela
2017-06-25T08:30:33.000000Z
字数 492
阅读 197
cuSAR项目框图
CUDA
SAR成像整体上是访存密集型算法。
在每个计算步骤做到都合并访存后,还可能的优化是计算步骤的合并和减少算法空间占用。
计算合并:
主要障碍是大量使用的cuFFT库函数,但库函数只有接口,对用户是黑箱,不能把前后的点乘计算整合进去。本项目在CUDA平台上实现FFT计算,并达到与cuFFT一致的速度。
通过整合FFT+点乘+IFFT三个计算步骤,将计算时间再减少2/5左右。
65536*4以上大点数实现的FFT+IFFT计算过程比cuFFT库快1/3,不在此详细说明。
空间占用:
cuFFT会分配用户不可访问的显存空间,用于计算过程中可能的数据交换和暂存。
在cuFFT库的批量计算模式下,有大量的空间占用。
对于非方阵的矩阵转置,通常做法是分配与数据等量的显存空间,进行数据交换。本项目实现的FFT计算,在8192以下小点数计算时,不需要分配算法显存空间。
针对算法特点,划分多个子矩阵(方阵),实现原址“矩阵转置”,进一步降低显存空间占用。
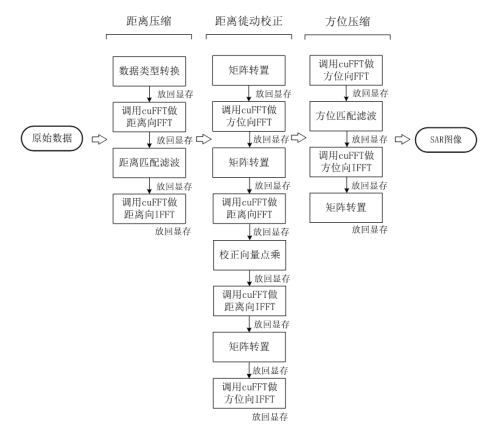
图1、基于GPU的RD SAR成像算法常规实现框图
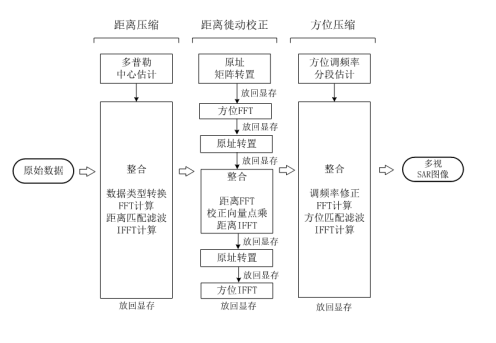
图2、本项目实现框图
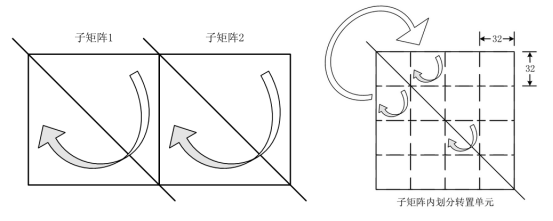
图3、针对项目算法的原址“矩阵转置”实现方式
