@Wayne-Z
2017-11-19T02:21:24.000000Z
字数 3903
阅读 10722
FastText的demo实现及其评估
deep_learning NLP
文章及代码来源
Paper Bag of Tricks for Efficient Text Classification by Joulin et al.
代码来自github
我写本文的时候源代码还在更新,重要的就是model.py文件。
代码实现及其分析
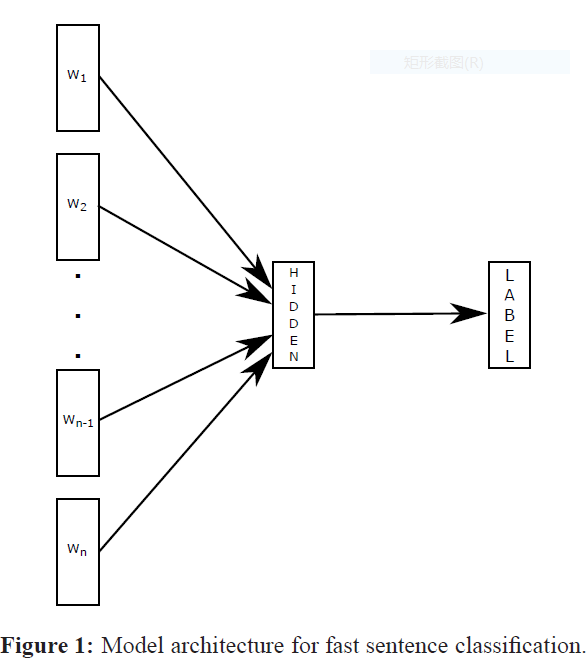
图片来自原文,前期语料的处理因语料不同而异,以yelp的json格式的语料为例,stars即星级参数作为label,以text中的评价内容作为输入层机型训练。
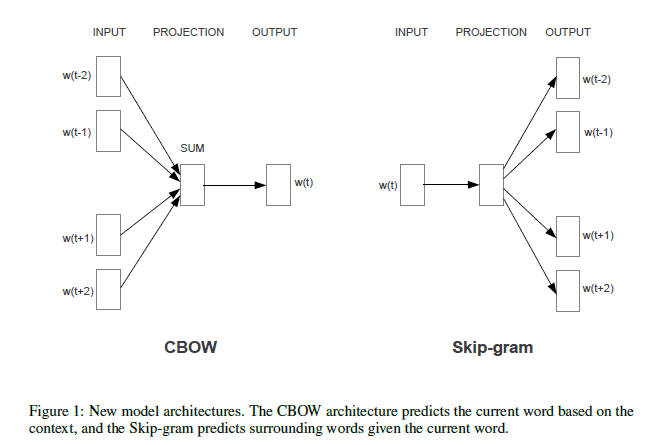
上图是MikolvMikolv在2013年发布的word2vec的文章,其中介绍了CBOW和Skip-Gram模型,经过两图比对,我们可以发现,FastText的模型其实由CBOW模型派生而来,由上下文推断演变为了全文的标签推断。在mikolov2013一文中,作者主要分析了影响运算复杂度的若干因素,最终发现,词向量的维度,数据集规模等对于整个复杂度的计算起关键性作用(此处仅提出了适用于本文文本分类的因素),这依然适用于FastText的模型。因此,本文在对数据集里面出现的词汇进行概率统计之后,采用霍夫曼编码的方式将语料进行了重新排列组合,将频率当做了概率。通过控制整个二叉堆的深度,实现了将小概率语料进行舍弃的目标,同时将关于数据集词汇数目的复杂度由线性级变成了对数级。可以看出,FastText训练的方式与过程本质上仍然与word2vec相同,主要利用的是梯度递减算法和反向传播算法。这两个算法的目的都是为了降低运算的复杂度,这也是FastText运算效率高的原因。但在实例代码中,作者在训练句向量——sentenceVector时,采用了onehot编码方式,在映射层直接调用了keras现成的函数,并标记使用函数softmax,因此在此处和原文的真正实现还存在些许差异。
def sentenceVector(tokeniser, dictionarySize, sentence, oneHotVectors, oneHotAveraged, contextHashes):result = np.array([])sequences = tokeniser.texts_to_sequences([sentence])# Zero-pad every stringpadded = pad_sequences(sequences, maxlen=SequenceLength)[0]if oneHotVectors:iptOneHot = [oneHot(dictionarySize, i) for i in padded]result = np.append(result,np.mean(iptOneHot, axis=0) if oneHotAveraged else np.concatenate(iptOneHot))if contextHashes:buckets = np.zeros(dictionarySize * 2)for t in range(SequenceLength): buckets[biGramHash(padded, t, dictionarySize)] = 1for t in range(SequenceLength): buckets[dictionarySize + triGramHash(padded, t, dictionarySize)] = 1result = np.append(result, buckets)return result······def train(dataReader, oneHot, oneHotAveraged, contextHashes):model = Sequential()model.add(Dense(EmbeddingDim, input_dim=(oneHotDimension + contextHashesDimension)))model.add(Dense(Labels, activation='softmax'))model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])trainingGenerator = mapGenerator(dataReader.trainingData(n), tokeniser, dictionarySize, oneHot, oneHotAveraged, contextHashes)validationGenerator = mapGenerator(dataReader.validationData(n), tokeniser, dictionarySize, oneHot, oneHotAveraged, contextHashes)model.fit_generator(trainingGenerator,nb_epoch=Epochs,samples_per_epoch=SamplesPerEpoch,validation_data=validationGenerator,nb_val_samples=1000)return model, tokeniser, dictionarySize
N-gram也是一种常用的方法。其原理就是默认在上下文中一个词汇的出现与前面N个词汇的出现存在关联性。本文采用Binary-gram作为一种额外特征,用于提高测试的精度。同时,由于词向量维度较大的,在数据集也偏大的情况下,为提高运算效率,本文通过采用高维度的哈希算法,一方面避免了哈希值重复的情况,一方面通过哈希值来进行映射和存储Binary-gram的运算结果也极大提高了运算效率,代码实例中有bigramhash和trigramhash两种方式可以选择。
def biGramHash(sequence, t, buckets):t1 = sequence[t - 1] if t - 1 >= 0 else 0return (t1 * Prime1) % bucketsdef triGramHash(sequence, t, buckets):t1 = sequence[t - 1] if t - 1 >= 0 else 0t2 = sequence[t - 2] if t - 2 >= 0 else 0return (t2 * Prime1 * Prime2 + t1 * Prime1) % bucketspython
代码实现时的困难
一个是语料的处理,yelp语料大小1G左右,还可打开看看格式,但是像Amazon的十几年的语料加起来80G,在windows平台上都不知道怎么打开···因此在文本处理上可能要花费一些时间。
代码兼容版本的问题也出现了,深度学习的python库keras在不同平台有些许的瑕疵,因而不够健壮,因而还需要一调再调,有时候莫名其妙就跑起来了。
实现结果
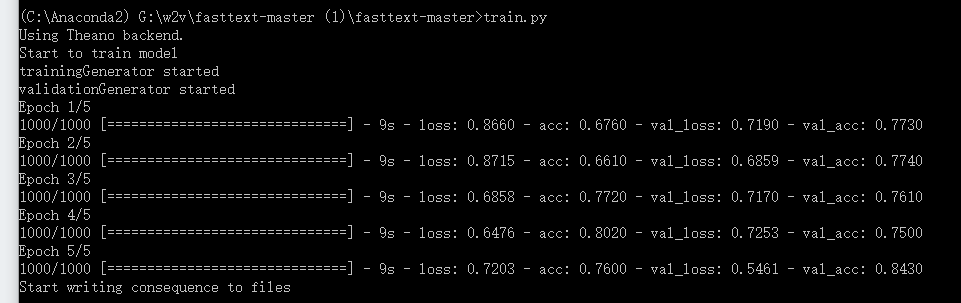
yelp的语料共计1g,训练结果如下: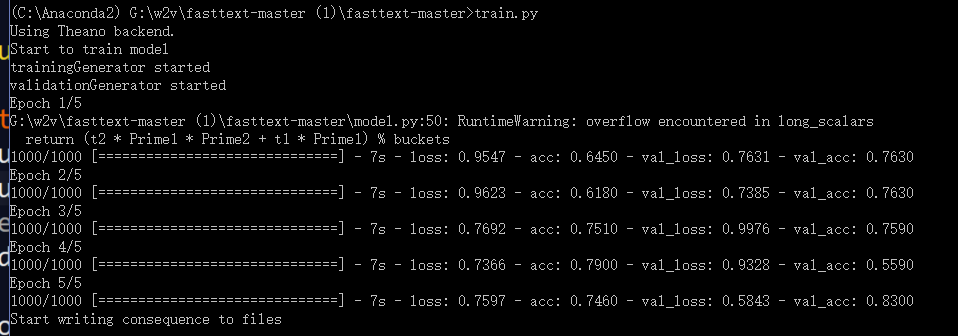
在打开了bigramhash的实验中,共用时35s,但是此时我们也看到,损失也是有一些的,关闭了之后,我们可以看到,消耗的时间可能要就一些,但是精度有所提高,
语料分析
yelp的语料来自于Yelp Dataset Challenge,本文和代码实例采用的都是review dataset,格式如下
{'type': 'review','business_id': (encrypted business id),'user_id': (encrypted user id),'stars': (star rating, rounded to half-stars),'text': (review text),'date': (date, formatted like '2012-03-14'),'votes': {(vote type): (count)},}
我们主要利用stars来作为训练的label,将text对应的内容用one-hot的编码方式,转化为sentence vector,然后再对Hidden层中的各个参数进行训练。
Amazon的语料来自Amazon product data,最开始被用于Maculey的的文章(http://cseweb.ucsd.edu/~jmcauley/pdfs/www16b.pdf),也是json格式的文本,集合了十几年来的客户评论和vote情况,我们也是根据vote时的yes或no来标记label,然后将Ranked opinions作为samples进行训练。
评估
从上文的结果上看,在没有调整参数的情况下,FastText的训练效果就已经非常可观,速度也是不错的。这次的文本分类模型,其实已经非常简单了,原文只用了NLP处理的两个经典技巧,就实现了如此高效的文本分类,无论是精度还是效率都可以说达到了极致,究其原因可能是因为文本和label之间还是存在很高的线性关系,采用的语料主要以review以及opinion为主,要预测的结果也只是评级的label或者是yes or no,可以说任务也比其他的text classification要简单(其它的文本分类可能不会按照赞、踩、一般这样的方式去处理),因而一些特征词等等可能会因为出现频率高等原因而有效提高分类的效率,而简单的2分类或者3分类任务也要比word2vec原先的CBOW模型处理上下文的问题要简单得多。因此,FastText模型可能略有些取巧的成分在其中,至少在目前看到的所有代码实例中,都是为简单的label进行的设计,泛化的能力可能较差。
